作者 陈怀临 | 2009-01-11 12:01 | 类型 专题分析 |
27条用户评论 »
 2008年2月25日,思科发布业界新闻,发布其最新一代的,也是世界上最强大的,网络处理器QuantumFlow。其新闻稿的英文原文可参阅如下链接:思科新闻稿 2008年2月25日,思科发布业界新闻,发布其最新一代的,也是世界上最强大的,网络处理器QuantumFlow。其新闻稿的英文原文可参阅如下链接:思科新闻稿
SAN JOSE, Calif., February 25, 2008 – Cisco® today introduced the Cisco QuantumFlow Processor, the most advanced piece of networking silicon in the world and the industry’s first fully integrated and programmable networking chipset. More than half a decade in the making, the Cisco QuantumFlow Processor consists of 40 cores on a single chip and can perform up to 160 simultaneous processes, making it uniquely geared for today’s network environments and several generations beyond what is currently available in network processors.
The Cisco QuantumFlow Processor was designed by a team of more than 100 Cisco engineers and has led to more than 40 patent submissions. Many of the same engineers who developed the Cisco Silicon Packet Processor (SPP) for the Cisco Carrier Routing System (CRS-1), which debuted in 2004, also worked on the Cisco QuantumFlow Processor. Continued advancements in technology, design and expertise enabled the team to increase the transistor density on the chip from a then networking-industry-leading 185 million on the Cisco SPP to more than 800 million on the Cisco QuantumFlow processor. Such density puts it in the tier of some of the most advanced processors developed by leading semiconductor companies.
下面是笔者尝试做的中文翻译:
思科公司今天发布其QuantumFlow处理器,工业界最强大的,第一个完全集成的,可编程的网络处理芯片。经过5年多的工程开发,Cisco的QuantumFlow处理器在一个芯片内部含有40个CPU处理器的核,可以同时做160个数据处理。其超强的计算能力使得QuantumFlow处理器成为当今网络计算的宠儿,并领先业界中其他的网络处理器数代之遥。
思科的QuantumFlow处理器的设计团队有100多个工程师组成。其设计研发过程中,团队共提交了40多个专利申请。QuantumFlow的研发工程师许多来自思科2004年发布的多核网络处理器SPP(Silicon Packet Processor)设计团队。SPP被思科用在业界最高端的路由器CRS-1(CRS:CarrierRouting System)上。新技术的不断发展,持续的设计改进和优秀的技术能力使得QuantumFlow的研发团队在该芯片上的晶体管密度提高到8亿个晶体管,而原来SPP芯片为1亿8千5百万个晶体管。QuantumFlow的高密度集成使得其成为半导体业界最复杂的芯片之一。
【笔者注:】
×《弯曲评论》相关文章:
–关于QuantumFlow:www.tektalk.cn/?s=quantumFlow
–关于CRS:www.tektalk.cn/?s=crs+cisco
|
|
| |
雁过留声






CRS用的SPP,而非QuantumFlow,而且,很可能QuantumFlow没想象的强大,要不为什么CISCO在ASR1000和ASR9000以及76的最新板卡ES+40上选择EZCHIP呢?
SPP 04年搞出来,CRS宣称80M PPS的处理能力,还是很强大的.
Cisco把这个QuantumFlow搞出来说明:
1、Cisco还是很有钱的,为了一个路由器产品自己开发出这么一个多核产品来。不知道这个MCPU每年有多大的量,Cisco肯定不会把这个宝贝买个竞争对手的,就行当年SUN不肯把自己的UltrSparc芯片买个别人一样,呵呵。
2、Cisco还是有很多技术大牛,就把这么一个怪物搞出来。
我一直没有想明白Cisco的系统架构师们在设计这个芯片的时候为什么是定位40个CPU Core,而不是10个或者20个再者30个这么一个指标,或者在向里面多赛一些到80核。另外,这个东东提供4个10G的业务处理能力,如果仅仅是线速转发到可以理解,但是如果是对报文进行复杂的业务处理,不知道这个CPU访问内存速度能否满足要求。
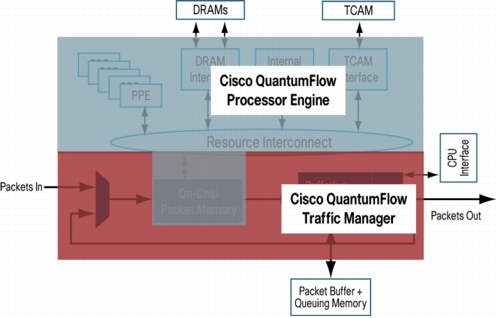
另外,DF的那么多CPUCore是如何连接到Crossbar Switch?在图中有on-chip Packet memory,不知道能够提供多大,一个报文在CPU系统内部时间是和业务处理复杂度相关,难道都能够把packet的报文放在这个On-chip的memory里面?那这个memory要多大?这玩意是否就是一个Cache?另外,不知道它内部Cache是如何设计得。
最后还是非常敬佩Cisco的架构师们,设计出这么一个复杂的CPU,并且在这么复杂CPU上开发出成熟商用系统。非常希望了解他们在这个多核上软件业务系统是如何构建的。
BTW:设想一下QF的下一个版本是什么样子,首先主频尽可能提高,保障在一定时间内能够处理更多条业务指令,工艺是45nm或者更低,把字符串搜索引擎集成进去。把每个CPU作为TWO ISSUE,降低CPU Core的数目。把Cache做大,把功耗降到50W.
看来是为了 处理应用层数据开发的 for IPS
以后又是为了推广 enhance service 这个概念 在ER上考虑到业务应用 安全 等需求开发的。
接下来就看 juniper如何应对了。。。
*不可能把packet的payload都直接放在其内部的On-chip Memory里。通常是packet descriptor。payload应该通常是通过一个DMA Engine直接进入DRAM或者L2 Cache。当然,QF的这个On-chip Memor感觉很大。我是这样想的:800million的晶体管。是谁占用了巨大的die size?很有可能这个On-Chip的Memory是一个大户。当然,Xtensa的Cache也是大户,这就不用讲了。TCAM是外挂的,大家应该已经注意到了。QF有DRAM(估计是DDR2)和TCAM的interface。
×不可能core越多越好。onchip memory越大越好。功耗就做不下来。另外,还设计大量的signal integrity的问题。不是那么简单。
一点一点研究。这真是个艺术品。
陈老大有没有搞到芯片资料??
什么意思? “我搞到芯片资料”?
我是在通过思科公开的资料做的分析和整理。我有QF的规约,还需要来猜测其内存是DDR2还是DDR3?另外,其内部的interconnect其实是最神秘的。希望能分析出来。
看来 思科在技术方面又领先了 从朋友那得知juniper的SRX系列使用的是 XLR732+EZchip’s NP-2 or NP-3。而且换了CEO 可能会由技术型转型到偏市场和服务型。
不是看很看好那个Kevin Johnson
陈老大 能否对 C J的前景 和策略 作一番猜测??
EZchip我在01~02年看过他们的NP,很强很暴力.
想不到能活到今天, IBM的NP4GS3,MOT的c-port都该死翘翘了吧?
还有intel的IXP28xx现在还有roadmap吗?
IBM的早卖给HIFN了,HIFN 2006年就停止开发了。Intel的2800授权给Netronome了,Intel不再开发了,Netronome还有路标。
IBM micro(chip)部门这些年一直不太好,网络泡沫时NP,本来指望它能带来赢利.结果就这下场.
Intel IXP本来还不错,挨了AMD一刀.就放弃了xscale和IXP.这念头日子不好混罗.
首席,你这是不是在给H or Z做预研啊?
没有。华为,中兴人才济济,兵多将广,我算哪根葱。自己对这些东西就是有兴趣而已。
首席还是超牛的,别谦虚了。您的技术加上H/Z的销售铁军,创造几个亿的销售价值绝对No problem!
其实只要首席想去华为中兴应该求之不得,实际上华为在美国也有分公司,或者单挑个产品线应该没有任何问题,待遇能比你现在不差,就看你有没有意了,做一番事业需要天时地利人和。
“其实只要首席想去华为中兴应该求之不得”。 过客,你可千万不要乱说。否则华为的人看见了会不高兴的。我前段时间被他们骂的狗血喷头。。。
Hi 首席:
Question one: What is the radical difference between the architecture of multicore like Cavium and EZchip’s NP.
Do you think the two kinds of CPU(NP) have more and more similarites in the future?
Question two:Like multicore(NP),every core process one packet at the same time, how packet order is maintained between different cores?
问题1: EZChip更适合于放在线卡,即战斗在最前线;Octane是一个服务处理器,更适合于经过Ezchip之后的深沉处理。例如,stateful的服务。你可以看见到处用Octane的产品,但板子上可以没有Ezchip。但你非常少的看见一个只有Ezchip的pizza box。你可以简单的吧Ezchip看见ASIC加速逻辑;Octane更是一个从层1-7还外加许多”乱七八糟“的硬件加速逻辑,如DFA,Crypto,TCP Offload等等。
问题2:这个问题比较高级。对于单纯的路由forwarding。事情简单。在此略过。对于stateful的session based的应用,如果拿QFP来看,PPE的那40个core是不管的。负责ordering issue的是其traffic manager。Traffic Manager负责packet的调度–例如,属于同一个session的packet的管理。。。。。。不同的公司(芯片)有不同的做法。但大致都差不多,例如Octone的POW。
to 16楼:
你怎么被人家骂的狗血喷头?不太可能吧…..
闯王进城之后,人们的心理发生了什么变化,是一个永远值得研究的课题。。。
SPP QFP 统称为CPP. 架构上为上层提供统一的可以移植的接口, 不过这东西倒是蛮复杂的, 以至于Viking更换了处理器,
ASR1K: SPP更多倾向吞吐量、时延等,其最大目的就是快速转发报文,其次能实现一些业务的随板分布式应用。QFP就是针对Edge的灵活业务支撑开发的,两个芯片的设计原则上就有差异,要软件上统一确实很难。是否有更加详细的分析?
另,像Cisco、Juniper等是否有统一转发软件平台支撑各种多核CPU,如RMI、Cavium、FSL,还有其自己开发的?
雁过留声: 是HW的兄弟吧?
您好,首席,
请教个移植不解的问题:目前业界流行的多核技术,CAVIUM/RMI/X86,他们之间关键的区别在哪里,非常感谢!!
从应用的层面概念上讲:C和R是NSP--Network Service Processor,while x86是CPU。
从体系结构的概念上讲,C是多核。R是多核多线程。X是多核多线程。
再细分,R是FMT;X是SMT。
可以听听我关于TLP的录音。
陈怀临 于 2009-02-13 5:34 下午
问题1: EZChip更适合于放在线卡,即战斗在最前线;Octane是一个服务处理器,更适合于经过Ezchip之后的深沉处理。例如,stateful的服务。你可以看见到处用Octane的产品,但板子上可以没有Ezchip。但你非常少的看见一个只有Ezchip的pizza box。你可以简单的吧Ezchip看见ASIC加速逻辑;Octane更是一个从层1-7还外加许多”乱七八糟“的硬件加速逻辑,如DFA,Crypto,TCP Offload等等。
问题2:这个问题比较高级。对于单纯的路由forwarding。事情简单。在此略过。对于stateful的session based的应用,如果拿QFP来看,PPE的那40个core是不管的。负责ordering issue的是其traffic manager。Traffic Manager负责packet的调度–例如,属于同一个session的packet的管理。。。。。。不同的公司(芯片)有不同的做法。但大致都差不多,例如Octone的POW。
cavium cn5860的POW是CORE之间通信,不知道首席何意?
额…. 理解有偏差…..
问题1, QFP放LC上不就是CRS-1的SPP么
问题2, 就不用多说了, 为什么会认为PPE的那40个CORE不管呢?