




思科QuantumFlow处理器及其战略研究(7):体系结构(报文观点)
作者 陈怀临 | 2009-02-06 15:44 | 类型 专题分析 | 6条用户评论 »
系列目录 思科的QuantumFlow多核处理器
从网络数据报文的观点来观察思科的QFP,QFP就是一个数据报文的从层2一直到层7的数据处理与转发的引擎。在基于QFP的思科ASR1000系统中,读者要非常值得注意的一个观点是:QFP扮演的是一个集中式数据处理的角色。换言之,系统中所有的数据的,从线卡(SPA–>SIP)和控制平面卡(RP),都是通过系统的背板Backplane互联ESI,而进入QFP。QFP处理后,决定是应该转发给某个线卡并发送出去,或者是应该转发个控制平面卡。QFP扮演着一个集中式数据控制和处理的角色。具有HA的ASR1000系列,具有两个ESP卡。美国ESP卡上有一个QFP。这两个QFP/ESP的关系是一个Active,另外一个Standby。所有的数据报文都是进出当前的主QFP处理器。辅QFP,通过一个专用的SPI4.2 10Gbps的通道,与主QFP通信,做状态备份。
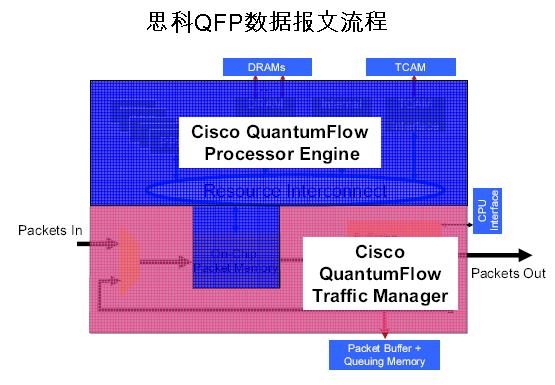
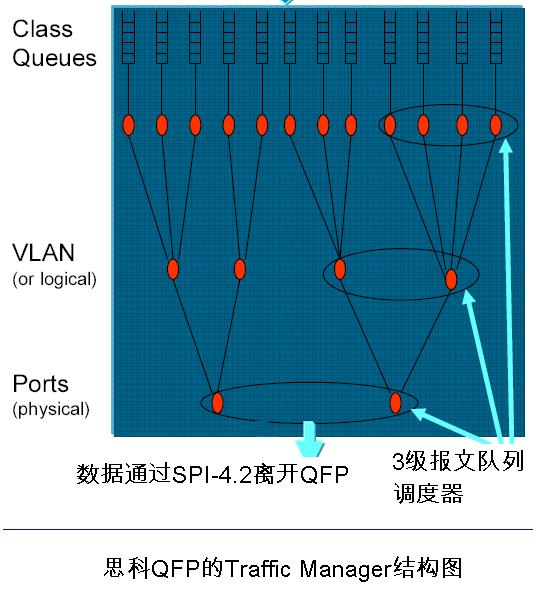
如上图所示,从报文的观点来观察,QFP的逻辑分为两大部分。第一个部分是QFP-Processor Engine。第二部分是QFP-Traffic。第一个部分主要就是那40个Tensilica的Xtensa ISA的处理器单元。第二部分是由一些数据缓存,队列(Queue)和相应的调度算法逻辑组成。下图所示为Traffic Manager的一个逻辑结构图。
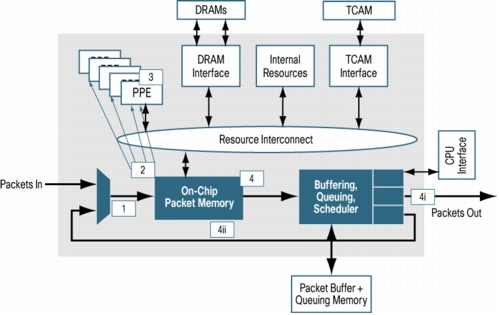
1. 当一个数据报文通过一个相应的SPI-4.2数据通道抵达后,QFP的报文分发部件(Dispatcher)会将报文层2的Frame所以数据都传送到QFP的内部报文缓存里(On-Chip Packet Memory)。也就是说,不仅仅是报文的头(Header),是包括数据(Payload)都存放在QFP芯片内部的缓存中处理。这部分的功能还包含一些基本的数据报文的处理和分析工作 2. QFP的报文分发部件将这个新的数据报文分配给一个计算单元(一个CPU核的一个硬件线程)。这个线程将从头到尾的负责这个数据报文的处理序列,其中包括: 进入时:要进行Netflow,MQC/NBAR Classify, Firewall, RPF, mark/Police, NAT, WCCP, Deep Inspection, 等等。 转发功能:QFP当然首先是一个路由器的数据平面的一个引擎。所以要处理这个报文该往哪里转发的问题。因此QFP的Processor Engine要完成如下工作: IPV4的FIB,MPLS, Multicast等等。 当要离开QFP Processor Engine时,还需要 Netflow,MQC/NBAR Classify, Firewall, NAT, Police/Mark和Crypto 等功能。为什么要考虑加密呢,因为,有可能是VPN tunnel的数据报文。 这时,一个数据报文就已经完成所有的软件处理可以被释放给QFP的Traffic Manager做最后的调度并发出离开QFP了。这个数据报文会被传送到相应的Traffic Manager的队列中。这个过程与这个报文是一个Trhough Traffic(要去另外一个线卡端口),或者是一个去控制平面(RP)的报文,或者是一个HA报文,有关系。不同的报文类型将被放到不同的队列中。从而Traffic Manager的队列调度器可以通过不同的调度算法去相应的发送一个报文。 3. QFP的Traffic Manager的队列调度功能将决定一个报文的去向。目前,Traffic Manager可以支持128K个队列。强大的队列调度器可以应用许多QoS算法在系统的数据报文上。值得注意的两点是:如果一个数据报文被一个Processor Engine的线程处理完之后,还需要再来一遍,Traffic Manager负责相应的队列中的数据报文再次转发到On-chip数据报文缓存中;如果一个数据报文需要加密,Traffic Manager会通过相应的SPI通道启动QFP外部(在ESP板子上)的加密部件。 | |
 (3个打分, 平均:5.00 / 5) (3个打分, 平均:5.00 / 5) |
雁过留声
“思科QuantumFlow处理器及其战略研究(7):体系结构(报文观点)”有6个回复
阅完此系列文章,深感国内厂商和cisco的技术差距之大啊……
冰冻三尺,非一日之寒。。。。。。
大家对Netflow估计不太熟悉。Netflow其实就是思科自己的一个网络管理模块(协议),用来统计和收集各种数据的。对应华为的VRP,就是NetStream;Juniper,就是Jflow;Alcatel-Lucent, 就是Cflowd.说白了,名字和细节略有不同,但目的和做的东西都差不太多。。。
[...] 简而言之,是MIPS多核+TCAM的组合。 TCAM是各大通信公司,特别是路由器公司的七寸。你算法再好,你也的Lookup快不是。读者可以试想下一代RMI的XLR或者XLP芯片有了TCAM的接口(Interface)。有兴趣的读者可以阅读笔者撰写的“思科QuantumFlow处理器及其战略研究(7):体系结构(报文观点)” MIPS的问题: 基于MIPS的32位操作系统,或者网络系统,具有非常大的局限性。这就是MIPS的天生缺点。2G之上的空间必须在Priviledge模式运行。这对于网络大系统,例如在下面读者aaa的评论中提及的:“aaa 于 2009-06-07 6:35 am 大地址空间,大内存的需要越来越迫切,尤其在高端的系统.64bit core 是一种发展趋势.”。这是一个非常精确的评论。从笔者的眼中,aaa读者的此言一出,笔者立刻能判断其工作的相关性质,工作范畴和能力。可谓评论中之精华。MIPS 64位系统是已经采用和将要采用MIPS ISA的系统和公司要非常注意的一个事情。要知道,问题不在MIPS本身,而在于你现在的历史代码,历史系统是否准备好(READY)了没有?32位系统朝64位系统的迁移绝非一日之功。要下定决心,但要非常慎重。 [...]
MIPS的2G以上空间也并非全是Memory。
0xA0000000到0xBFFFFFFF是给I/O用的,又与0×80000000到0x9FFFFFFF物理上重叠,实际上0×80000000以上空间只有1GB可以映射为Memory。
当QFP的高级功能打开时,如PDI,它的真正的处理流量是否还是线速?128K个队列是否真的能被有效调度?