




PAN硬件体系结构浅析
作者 陈怀临 | 2009-12-30 12:02 | 类型 行业动感, 通讯产品 | 54条用户评论 »
|
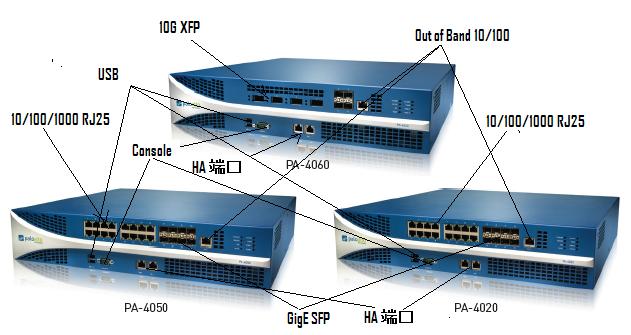
PAN(Palo Alto Networks)的系统是一个系统,而非一堆硬件。软件是其灵魂。但其肉身也值得发烧友看一看。 下面是PAN4K的家族图:
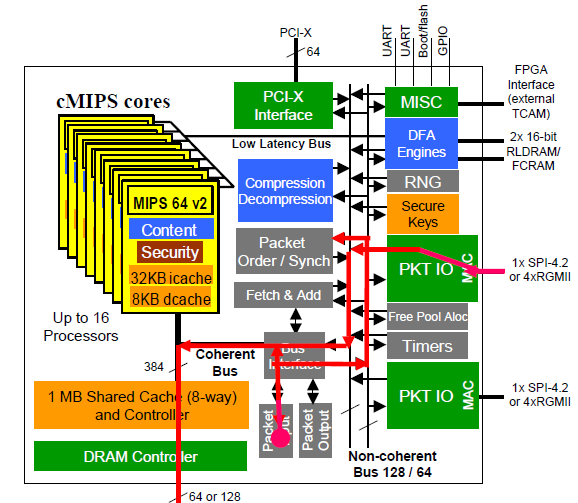
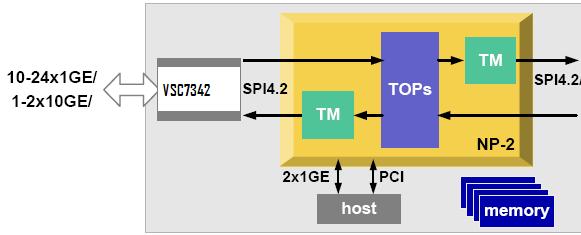
总体而言,PAN的4000系列是一个Dual Core XEON的Intel CPU 的PC主板(控制平面),然后通过PCI-E的Interconnect把数据卡(数据平面)有机的攒在一起。 这种体系结构其实现在也很common。关于基于Intel架构的嵌入式系统结构在《弯曲评论》上也曾经有过讨论。现在看来PAN就是这样做的。其实许多人都在这样做。这也是通常说的Pizza Box的意思。 下面两张图一是PAN4K的控制平面裸奔,另外一张是数据平面裸奔。可以很清楚的看见,在数据平面上,赫然有EZChip的NP2,和地球人都知道的Cavium的16个Core的Octeon CN3860。
另外,一定要注意,在数据平面的右下方,有一个Xilinx的FPGA。很有可能使PAN做AppID Lookup的。 在数据平面图的接口方面,左边从上到下一次是:2×4双层RJ45(8千兆),2×4双层RJ45(8千兆),2×4单层SFP(8千兆),(光模块,用来接入与路由器互联,例如)和一个RJ45 Out of Band Mgt。从而在这张图中,有16个10/100/1000 端口;8个GigE端口和一个管理口。从图中可以看到,PHY,Mac和Switch芯片都是来自Vitesse公司。另外,这张数据平面图显然不是PAN最高端的4060,而更像是4050。4060的接口上4个XFP和4个SFP光模块,没有这么多的RJ25电接口。该图中的PHY很像是Vitesse的4端口的VSC8224芯片。因此左上角有4个PHY,4×4=16个端口。 PAN系统由于只用了一个10G的EZChip NP2,所以不可能做40G。这也是为啥PAN能而且目前只能声称10GFW的原因。另外,这里的10G是指单向。也可以说20G的throughput。 有兴趣的读者可参阅EZChip NP2 Product Brief。 4个VSC PHY芯片左边黑色的VSC芯片应该是个MAC芯片,例如,VSC7324系列。原因如下:16+8=24个 GigE port,EZChip NP2自己内部的Mac带不动了。NP2只能支持10个通过RGMII(total 10G)把外部的PHY忽悠进来。所以在PAN 4K的系统中,很有可能是用外部的Mac,然后通过MAC的SPI4.2 interface接入EZChip。 换言之,Packet是SPI 进入EZ,SPI离开EZ去Cavium Octane。EZ有两个10G的SPI 4.2 Interface。因此,EZChip的RGMII和XGMII interface在PAN系统中估计没有用。
在主板方面,要注意的是其内接硬盘。原因似乎也很简单。IDP要有大量的Log数据。主板CPU的一些基本参数应该是:Intel Xeon LV Sossaman Dual-Core – 1.66GHz;Bus speed (MHz) 667;L2 cache size (KB) 2048。Xeon LV的微结构应该是Pentium-M。有兴趣的读者可以参阅陈首席的“Intel CPU与微结构映射关系图”
PAN对外宣传4K的性能指标为: 10 Gbps firewall throughput 有兴趣的读者可以参与PAN产品规约。PAN系统可以识别800多个App ID。 | |
 (没有打分) (没有打分) |


雁过留声
“PAN硬件体系结构浅析”有54个回复
“在接口方面,显然左边是4个10G的Interface”
照片上并没有10GbE接口,是千兆电和千兆SFP接口,交换芯片和物理层芯片都是Vitesse的。
主板上的硬盘并非大量Log数据需要一块硬盘,因为它就是一块普通的工控机主板,可以拿来就用,国内这么干的公司也很多。
两个板子之间互联的PCI-E是x?与DPI的深度和粒度有关系。
不对呀。左上方的应该是2个2SFP。下面的那个长一点的是4个10G XFP才对。否则,其他的4000系列是16个GigE。Port更多。。。
左边从上到下一次是:
2×4双层RJ45(8千兆),2×4双层RJ45(8千兆),2×4双层SFP(8千兆),和一个RJ45串口。
从产品形态上看,我认为这家公司是不具备独立的硬件设计能力的,否则不会把两个板子搞在一起,他们是找了个现成的工控机,然后找了个第三方的Cavium平台单板,做个新外壳,灌上自己的软件就上。怎么连,从图上看不出来,很有可能是通过网线连在一起,国内这么搞的公司挺多的。
“和一个RJ45串口”,这一点看的不太清楚,应该是个带外管理网口,因为旁边有个PHY芯片。
RJ45串口 is console.
PA4000应该是给带内管理的口,明显旁边有个phy
From official datasheet “10/100/1000 out-of-band management”. It only has DB9 console.
硬件平台可以关注下立华莱康,看看现在有多少产品都是现成的硬件平台吧。
http://www.ls-china.com.cn
所谓物业有专攻,做硬件牛的做平台也是很不错的选择。
PAN的优势在于软件。
不关注安全很久了。
这玩意儿很像2006年搞过的一个东东啊。
2M条流,10G throughput的话,1片NP2是搞不定的。
或者NP2只用来做简单的IPv4转发?只要加了classification和statistics,它就做不到10G duplex线速转发了。
确实很好奇在这个系统里NPU做了些什么功能。
从照片上看,网络接口板是:8个GE电口,2组4口模块;8个SFP接口,4个双层。没有10g XFP接口,那家伙很大(比SFP).
X86部分就是一个双CPU的服务器板子,没有什么特殊,两个板子之间的连接也看不到PCI-E.
看来是拿出来忽悠人的!
这两张照片一个对应的是PA-4020、PA-4050,没有10g 接口,16个千兆;PA-4060有4个XFP和4个SFP.
内部如何连接,高人指点一下。
我先来猜测一下。
EZCHip and Cavium: SPI4.2
EzChip and Intel: PCI-E
(大家要注意:EZChip通过其PCI-E与控制平面互联;换言之,要把Cavium其实理解为一个数据平面上的Service Processor。数据平面的骨干是NP2,而非Octane)。当然,主板上可以通过PCI-X来控制Octane。dan PCI-X更是一个控制总线。这也是为什么EZChip有可能,或者极大可能,是通过PCI-E,迅速的将First Packet倒腾到Xeon上。)
感觉是个大杂烩,开发难度也非常大,要有懂EZCHIP微码的,FPGA逻辑设计的,CAVIUM微码的,即使只做软件,能把这几种平台都搞懂,搞定,也不是简单的事情。 所以觉得这个结构不是方向,过于复杂,个人觉得直接使用高性能多核+x86更有例如软件开发,而且多核上面也使用标准的SMP linux。
TNND,会不会淘来的这张图其实是4020的I/O卡,所以只有一个EZChip?而其他两款的I/O是2个EZchip。感觉不应该。PAN应该没有启动TM。PAN应该没有在QoS上发力。
谢谢xscope和大家。正确的应该是:
左边从上到下一次是:
2×4双层RJ45(8千兆),
2×4双层RJ45(8千兆),
2×4单层SFP(8千兆),(光模块,用来挂入或与路由器互联,例如)
和一个RJ45 Out of Band Mgt。
从而,16个10/100/1000 port;4个GigE port和一个管理口(有一个Phy在板子上)。
EZ2做数据转发,FPGA做内容过滤,多核做普通的防火墙。
为啥整这么多片子,估计是找不着更合适的方案满足设计需求。 跟整个系统架构的基本设计没啥关系。
这个和hillstone的东西很类似啊。
我的想法有点不一样。我猜测是这样的:
×NP2做FW Throughput Traffi转发。
×Cavium做IPS Session管理。
×主板CPU做FW First Packet和VPN。
×FPGA做AppID Lookup. 挂了TCAM。天哪!
Anyway,乱猜一通:-)希望不要猜中。
主板CPU做FW First Packet和VPN
这个效率差了点,而且不够fashion,8年前就这样了。哈哈
CPU 管管路由,配置,日志就差不多了,
也是。这个杰克好像挺熟悉某些事情的样子。小样,不知是谁的马甲。
是,如果Intel CPU做IPSEC,有点寒碜PAN了。估计IPSEC是Cavium做了。这估计no doubt了。 IKE在Intel上面做。
我对first packet持保留意见。在Intel上做比较简单。否则,一但将来多线卡。session管理比较麻烦了。。。。。。
我也是猜的,让首席失望了,哈哈。只是觉得首席的方法太保守,至于这个多线卡的问题,我觉得到时候应该有不同的解决方案,不可能只是简单的加个chassis,
CPU做first packet的话,那一开始的内容过滤也要在CPU上做了,这个。。。。
不知道这个日志详细到什么程度,
CPU上的操作系统还有玄机?等待高人指点。
首席,我猜这个Cavium极有可能是做FAST PATH之类的事情,这种架构还是不错的。对于应用分析而言,只需要特定的包传到HOST即可,所以无论是PCIE,还是GE连接方式,都不是问题。这种方式还可以做到OFF-LINE方式分析。HOST既可以做管理,也可以运行第三方的模块。具体怎么弄,要看齐模块划分了。目前Cavium作为插卡的方式,通过PCIE插入到X86 HOST里,已经不新鲜了。在这种架构下,让我来做Panabit的话,我能做到很高的性能,如果有市场的话,呵呵。Cavium有一个不好的地方时,它的SSO单元在灵活性方面有些欠缺,所以又可能需要在数据包进入Cavium之前,做一些前置性工作已弥补这种不足(我不知道5860是否有所改善,38XX是存在这个问题的)。另外使用这种方式做QOS,可能也会存在瓶颈问题,我不知道PaloAlto是否可以做QOS。好在实际中,做QOS一般是做带宽限制,所以可以将要限制的PACKET单独用一个CORE做即可。弓老师所一体化引擎和策略框架,如果要做到很和谐,的确是不容易的,比如刚才说的带宽限制的问题,虽然可以拿独立的Core做,但是我总觉得从架构角度讲,不够和谐。
Cavium的IPSEC加密卡芯片很厉害啊。Octeon处理器里面也有可以用于IPSEC的加密引擎。
我理解这是个三角关系:
NP2和CAVIUM是主力,CAVIUM是首包处理和SESSION的主力,NP2是转发和后续报文处理的主力,但是否session和后续报文处理全部都放在了NP2上,不一定,也许小部分还是用了cavium的一点,这可能也是内部的一个玄机;FPGA是用于扩展和弥补NP2和CAVIUM不能处理的需要高速处理的功能,毕竟NP2的代码空间有限,cavium的转发能力有限,需要FPGA的帮助
硬盘的使用可能会因为硬盘的寿命带来一些可靠性的问题,如果改成外部高可靠的存贮更好一点,当然,也许PAN软件系统对此有充分的可靠性设计
总体看,这个硬件架构虽不高明,但基本上实用,兼顾合理成本下技术的成熟度、稳定性、可靠性、功能和性能。要实现目前的需求和后续可能的需求,NP+multi-MIPS+FPGA+多核主控是一个目前看合理的选择,因为目前的芯片没有能做到把上面的主力芯片功能都集成在一起的,也许过几年有更牛的芯片出来,那架构也可以更好了
To 24:
如果这样的话,真的没啥亮点了。我觉得这个X86可能不算是一体化引擎的一部分,做内容过滤悬了点,当个方向盘也不错了。
To 26:
PAN最牛B的东西我猜应该在那个FPGA里,我觉得目前的工程方案是系统架构设计的一个折中,目前真没有一个芯片能把这些活全搅了。
to 杰克:硬件上的highlights可能得从更细节的层面去分析,FPGA可能是一个key point,但无论如何,很highlights的地方可能不多,更多的还是在软件系统上
实现可视化基础上的log & report需要大量计算资源,x86就是干这个用的;Cavium是实现stream engine的核心,new sessions per second指标看似不高,但APP识别的工作是一并做完的;建好 session后的大部分工作就可以
甩给EZChip了,这就是所谓的先慢后快。
心里明白,装糊涂。
网上看到的TILERA TILE GX100,估计这一个芯片就把这所有的东西都搞了 http://www.tilera.com/products/TILE-Gx.php
大家说的有道理。估计First Path是指Octane上。Xeon单纯的管理和Routing。另外,IKE也下放到Octane上了?
看了一下PAN的产品datasheet。似乎在Routing,QoS,HA方面有待加强?
那个黑色的VSC芯片应该是个MAC吧,例如,VSC7324系列。原因如下:16+8=24个 GigE port,EZChip NP2自己内部的Mac带不动了。NP2只能支持10个通过RGMII(total 10G)把外部的PHY忽悠进来。
所以在PAN 4K的系统中,很有可能是用外部的Mac,然后通过MAC的SPI4.2 interface接入EZChip。
换言之,Packet是SPI 进入EZ,SPI离开EZ。EZ有两个10G的SPI 4.2 Interface。因此,EZChip的RGMII和XGMII interface在PAN系统中估计没有用到。
天哪。
总体来说Octeon性能不是很好,…
加了一张EZChip与Vitesse Mac的连接图。EZChip两个SPI4.2.一个Packet进;一个Packet 出(去Cavium)。10G的in and out。
我今天确认了一下。My fault。 NP2没有PCI-E,和PCI-X interface。就是单纯的PCI 33/66.
所以PAN的NP2应该就是与主板上的PCI interface或者加了一个PCI-E switch整起来的。
我会相应的把文章修改一下。并放一张NP2的arch 图。
我想请问下为什么现在TM都是放在egress而不是在ingress也放一个
从概念上讲,也不是放在egress。而是这样的。
Ingress->Classification,Policing,Marking->Forwarding Lookup and Decision–>Service Processing–>Traffic Engineering–>Engress
理顺这个关系后,你就觉得自然了。
换言之,你的问题也可以问:为什么TM放在Ingress后面?
理论上TM放在做TM的策略的决定点后做,所以不同的业务需求这个点是可能不同的,所以具体实现是根据TM是纯软件、引擎内嵌TM架构限制(都允许在流程中的那些点进TM)、外部TM硬件连接方式(串/旁挂)拉确定合适的架构,这个地方的架构设计,包括位置选择,是一个要求支持良好的QOS的产品的难点之一,包括可以设置多个TM,不一定只设置一个
谢谢首席,这个流程我还是清楚的,但是你那个FLOW如果要做基于基于SLA的限速我觉得做起来很麻烦,而且还有HOL的问题,放在前段,包来的时候就有个优先级的队列岂不是更好
关于哪个芯片干什么,貌似PAN的网站上已经说了,不知道我理解得对不对,还是说不能信他们公开说的? 下面是PAN网站上关于Parallel Processing Hardware的说明,分三个部分:
1、Networking: routing, flow lookup, stats counting, NAT, and similar functions are performed on network-specific hardware
我的想法是:这是在说NP-2
2、User-ID, App-ID, and policy all occur on a multi-core security engine with hardware acceleration for encryption, decryption, and decompression.
我的想法是:这是在说Octeon,因为里面提到了Multi-core,还有加解密,解压缩
3、Content-ID content analysis uses dedicated, specialized content scanning engine
我的想法是:这是在说FPGA,做内容分析,应该是类似于流量消减的功能
关于Intel CPU的工作,我的看法依然是根据官网上的说法:
依据1、First, Palo Alto Networks engineers designed separate data and control planes. This separation means that heavy utilization of one won’t negatively impact the other – for example, an administrator could be running a very processor-intensive report, and yet the ability to process packets would be completely unhindered, due to the separation of data and control planes.
依据2、On the controlplane, a dedicated management processor (with dedicated disk and RAM) drives the configuration management, logging, and reporting without touching data processing hardware.
从上面的说法看,Intel CPU肯定连数据包长什么样都不知道,否则的话,在very processor-intensive的时候还能不影响数据平面,天方夜谭
以上拙见,如有误,只能说我被PAN忽悠了,各位别扔砖
另外有个不明白的地方要请教各位:
从上面我说的来看,flow lookup是在NP-2做的,我将这里的flow理解为session,但这样一来,Octeon里不用维护session么?
我觉得肯定是有的,原因有如下两点:
1、Octeon做策略查找了,对于一个session中的包,不可能每包都做策略查找,所以Octeon里肯定有session。
2、我觉得要识别出User-ID, APP-ID,有时候光分析一个Packet是不行的,要分析多个Packet才能知道属于哪个应用,但是,不同session的包应该被视为没有任何关联,要不弄混,必须得维护session。
想到这,我仔细看了一个Panabit朋友的评论,Cavium的SSO单元的确在灵活性方面有些欠缺,很不灵活,比如说Queue的选用上。因为Octeon支持PKT_INST_HDR, 所以我觉得这里用NP-2是为了弥补Octeon的不足,Octeon只是做一个前置的负载均衡及高速转发,以及与高速转发相关的stats counting
修正一下,应该是NP-2只是做一个前置的负载均衡及高速转发,以及与高速转发相关的stats counting,上面写错了,哈哈哈
首席能否多发些J的资料,如M120,M320什么的。爱立信的核心网用的也是Juniper的片子。
39(aaa): HOL(Head of Line) Blocking的问题在Ingress端,如果没有复杂(高级的)Packet Scheduler(或者是TM),通常是Desti不同的Packet(更精确的说,是打碎之后的Cell)放在不同的Queue里。从而Fabric可以避免HOL。Again,在Ingress或者Engress都可以存在Packet Scheduling,可以存在Classification,BA和MF。换言之,TM不一定ONLY在Processing之后,Engerss之前。一定要想开点:-)。举个例子,通常我们说:Oh,Yeah,学校老师说了,Classification一定是Ingress做的,例如EZChip。Right?例如,一些基本的BA和MF(术语都是骗人的。其实就是那些Layer-2, Layer-3的Header bits)。但是你想想,在Ingress就一定能把Classification做完吗?答案是: NO。例如对网络安全系统,对VPN Tunnel traffic,对一些logic interface traffic,对zone based ACL,都要在中后期,你(CPU)才能判断出一个packet的更多信息,从而完成classification,pollicing,marking and so on。 In summary,QoS是发生在Packet进来和出去的任何一个环节。没有一个固定的模式。一切都看系统的市场需要,然后做相应的设计。当然,许多系统————通常————是:在Ingress进来之后,Forwaring Lookup之前,做Classifciation,Policing,。。。。,然后Fabric Switch,然后到Engress段,做Packet Queuing AND Advanced Packet Scheduling. 从概念和实践上讲,只要存在Queue,就存在Packet(cell)scheduler。只不过许多是Internal,不是一个Feature。而我们通常说的TM是一个Feature。可以用control plan,data plane来控制而已 。。。
40,41(狼):谢谢。你是对的。从公开资料来看,PAN系统的一个大弱点是:QoS基本上没有。换言之,对EZChip的利用率不高。因此,地APPID的Classification不可能是在NP2做的。EZChip对Session的管理应该是:看一个Packet是否已经属于一个Session。If yes,through traffic;否则,新session;让Octeon来做First Packet。
首席,久闻首席大明,坊间流传甚广,尤其是对安全和路由器系统的分析,及其深刻,以及弯网各位创始大哥和发帖高手,对国外最新技术信息,及时分析共享,甘做后生阶梯,实乃我大宋大幸,能否分析一下JUNIPER的TRIO芯片,尤其是MX系列的MX系列单板MX-MPC1/2…,包括16*10GE MPC-3D-16XGE…的单板,给小弟们学习一下,谢谢!
晕倒,“坊间流传甚广”,没说是“八大胡同流传甚广”。。。MNSR估计是新同学。《弯曲评论》的读者是藏龙卧虎。所以,往往是我们抛出一个Topic,评论里面才是精华。要多注意评论。。。。。。
另外,我比较开朗,喜欢开玩笑,例如自嘲自捧意淫等。你习惯了就好了。大家就是要开心。。。
Life’s a icecream; enjoy it before it melt.
这几天为啥不见我的客客贤弟?
是的,是新鲜人,会更努力的多看评论,但似乎没有juniper MX系列新单板的分析,首席能否出手抛玉引砖一下,学后不胜感激
貌似这两张图不是装在一个盒子里的,不是一个系统!
PAN规模太小,在目前竞争激烈的的安全市场难成大器,尽管其理念及产品都很有特色。就像CSCO独霸企业交换市场多年一样,压制force10/foundry/extreme很多年。
倒是很关心HUAWEI 8000e系列防火墙的架构,看起来像是NE40e路由器改版,不知和华赛9300系列有何关系?也是用XLR做slow path?用NP做fast path? 流量/会话怎么分担到不同XLR上?
先分析一下ezchip出的100G np比分析trio靠谱
16*10GE MPC-3D-16XGE用的是不是就是100G NP
http://www.juniper.net/us/en/local/pdf/whitepapers/2000331-en.pdf
Junos Trio chipset含4种芯片(数目大于4个,因为有些芯片要用多片):inerface/lookup/queue/buffer.
系统架构似乎没有看到变化,与juniper I-chip之前的多片架构划分相同,以前是将buffer和queue共享同一种ASIC。
http://www.slideshare.net/junipernetworks/juniper-new-network-launch-press-conference
研究了一早上总算搞清楚x86和octeon这两个板子怎么连的了,通过PCIE互联。
x86板照片左上部位有个黑色的中型长度的插槽是PCIE x4 slot;对应octeon单板照片左下部位GE管理口的正右方也有个向板子背面焊接的PCIE x4 slot,能看到背面的pin针。两个插槽位置正好对应,可以通过自制两端金手指的单板相连。
这样xeon和octeon间就有单向10G(PCIE x4,可能是gen1吧)带宽,这个带宽对于x86主要完成可视化相关工作应该说足够了。
PCIE连到octeon板上后,应该通过照片slot正下方的intel芯片转成XAUI,也许连到FPGA上吧。FPGA包含SPI-4.2(octeon)转XAUI的功能。
我总结一下可能的硬件连接方案:
OcteonNP2Vitesse SwitchRJ45+SFP (数据通道)
OcteonFPGAIntel 10G MACx86 (管理通道)
上个评论中尖括号都被自动去掉了,我用全角重发一次:
Octeon<-SPI4.2->NP2<-SPI4.2->Vitesse Switch<->RJ45+SFP (数据通道)
Octeon<-SPI4.2->FPGA<-XAUI->Intel 10G MAC<-PCIE连通2个单板->x86 (管理通道)