我也来说说我的思科QFP体系分析。希望Cisco的兄弟指点指点。
首席说过的一些QFP的一些分析我在这就不啰嗦了。
0. QFP是一个体系,而不是指单一的芯片。构成一个路由系统(ASR1000)需要cisco的4颗核心ASIC
multi-core packet processor chip
Traffic Manager(BQS)
Cypto
SPA aggregation ASIC
1. QFP ISA与微体系结构方面,Will已经说得很清楚了,Xtensa ISA与Cisco自己定制的微结构。
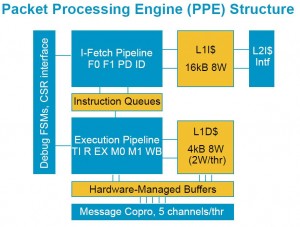
2. cache & on-chip packet memory
每个PPE拥有自己的
L1 D-cache 4KB 8way,但每个Thread专用2个way
L1 I-cache 16KB 8way。
40个PPE共享两个256KB的L2 I-Cache,L2作为D-Cache没有它的理由,数据包的局部性如何?
Will的报告上写得很明白,首席就是看不出来。
这两个256KB的L2 I-Cache如何组织的呢?难道是其中20个PPE用一个L2 I-Cache,另外的用第二个?
on-chip packet memory应该是1.2MB左右,为什么呢?Will的报告说总共20Mb SRAM,刨掉L1和L2 cache基本上就1.2MB。
3. TLB & cache coherency
TLB除了读写访问控制和地址翻译,还包括memory ordering属性控制。relaxed order和strong order。
支持软件cache coherency操作,比如flush, flush and invalidate…。我猜不支持hardware enforced的cache coherency?貌似支持cache预热或者叫stashing,也就是从crossbar来的消息响应数据能主动放入cache并valid cahce tag。
4. memory模型
weak order模型。但提供barrier, 串行化,原子操作支持。
5. 编程模型
Flat memory program model,这个大大的方便了C编程。Cisco的一个设计目标就是用C编写转发代码,而不是微码。外部RLDRAM通过TLB直接映射到处理器Thread地址空间,on-chip packet memory也可以直接映射到Thread地址空间,通过TLB同样可以映射外部memory作为C代码的栈空间(stack),同样内部硬件加速器需要的寄存器(Control status registers)可以映射到Thread地址空间。
6. IPC
我猜IPC=1,文中说1200MIPS,PPE最高频率是1.2GHz。
7.包处理体系
基于中心share memory的pool型,不是pipeline型。它包括DISTRIBUTOR, on-chip packet memory, PPEs pool(40个处理器core),lookup engine, TCAM, lock manager and sequencer, GATHER/DMA, BQS.等等,当然离不开片外memory。
二层整个包对PPE可见,不仅仅是包头。这些硬件资源通过resource interconnect和memory interconnect进行通信。
8.互联体系
核心互联结构是基于crossbar switch的资源互联(resource interconnect)以及memory互联(memory interconnect)。
这个首席描述的不准确。有些memory操作没有必要走中心的resource interconnect,而是通过独立的memory interconnect通道,这样可以减小访存latency。比方说lookup engine和hash engine的memory访问。再比方说,L2 I-Cache也是通过独立的memory访问通道进行访存。这个memory控制器应该是个多端口,多Bank体系。如何保证高的内存bandwith和低的latency是高速网络处理器设计的核心问题之一。所以首席把L2 cache搁到这个crossbar上是不对的。
crossbar资源互联(resource interconnect)至少有DISTRIBUTOR, on-chip-packet memory, PPEs, lock manager, GATHER, memory controller, TCAM controller, lookup engine。
资源互联(resource interconnect)是基于message passing机制的。消息报文包括源、目的地址,命令和数据。通过message request(消息请求包)和message respond(消息响应包)来完成通信。
Will的报告已经告诉我们PPE如何连接到crossbar上。每个PPE通过一个message coprocessor(消息协处理器)和一个buffer与crossbar互联。每线程5个通道。
| 





QFP应该是业务处理器或协处理器
全业务打开不知道Cisco的QFP性能如何?
>>2.40个PPE共享两个256KB的L2 I-Cache,L2作为D-Cache没有它的理由,数据包的局部性如何?
Will的报告上写得很明白,首席就是看不出来。
这两个256KB的L2 I-Cache如何组织的呢?难道是其中20个PPE用一个L2 I-Cache,另外的用第二个?
256KB的L2-Cache用作I-cache显得没必要。一般来说,64KB(16K-Instructions)的I_cache应该满足fast-path的需求。
如果是SPMD的编程模型,40PPE应该用同样的code,没必要划出两个指令空间来。
>>3. Flat memory program model,这个大大的方便了C编程。Cisco的一个设计目标就是用C编写转发代码,而不是微码。外部RLDRAM通过TLB直接映射到处理器Thread地址空间,on-chip packet memory也可以直接映射到Thread地址空间,通过TLB同样可以映射外部memory作为C代码的栈空间(stack),同样内部硬件加速器需要的寄存器(Control status registers)可以映射到Thread地址空间
这只是Memory-mapped的特点, 和栈的支持无关。如果每个Thread都有自己的栈,用TLB是无法解决的。猜一下, 请CISCO的人指正。
如果是SPMD的编程模型,每个THREAD在一个连续空间里分配相同大下的栈。每条栈指令应该是只存相对地址,寻址时用(Processor_ID,Thread_ID)计算出高位,即每个Thread栈的starting address,再加上相对地址得出。
可比小看这东西,从硬件设计得角度来说,很容易做。难点在软件上,当初也是花了一定的功夫,才把architecture, programming module, and code generation 搞定的。总之, 要想程序员用C编的爽, 作系统设计时,编译原理一定要懂。
我一直在想,
为什么思科在他们的文档上写Layer2 cache (dual 256KB)?
为什么不是single 512KB?
然道是因为L2 cache读端口太多的原故?如果是一个L2 cache那么这40个PPE都必须有它的读通道。
〉〉0. QFP是一个体系,而不是指单一的芯片。构成一个路由系统(ASR1000)需要cisco的4颗核心ASIC
multi-core packet processor chip
Traffic Manager(BQS)
Cypto
SPA aggregation ASIC
其实我对QFP还是很失望的。在IXP-2800诞生的8年后,还需要4块芯片来搞定10G/20G的东西。
十年前,我们的豪言壮语是用一块芯片搞定上述三块(Cypto除外)达到10G的线速。
革命尚为成功,Cisco还需努力啊。
关于栈的使用,应该尽量避免。因为要touch外存。
从分析得知,Thread的dcache很小。
我相信大部分还是基于寄存器的局部变量,和参数传递。
注意每个线程仅仅1KB d-cache,也就是说distributor一次最多从报文中加载1024字节的数据。
个人觉得从体系和扩展性来看,
把SPA aggregation ASIC从NP中拧出来还是不错的design Tradeoff。把又脏又杂的活交给它。
Aggregation接口类型应该是不少吧。
栈也可以用1.2MB的SRAM来做。 当然是shallow stack. Let’s say 1K per thread, and in toal it only occupies 40KB.
In general, each PPE only needs 40-Bytes IP/TCP header and the payload should remain in the DDR memory without loading into PPE L1 cache; otherwsie there is no way to guarantee the 10G/20G linerate.
如果是SPMD的编程模型,每个THREAD在一个连续空间里分配相同大下的栈。每条栈指令应该是只存相对地址,寻址时用(Processor_ID,Thread_ID)计算出高位,即每个Thread栈的starting address,再加上相对地址得出。
hardwired 不是更简单?
How to do hardwired? For example,
push 0×100 //! push 0×100 onto the stack
is the same for all 40×4=160 threads.
When thread_i executes this instruction, what is its stack address?
Please also note the size of each stack should be also configurable. I.e., it can be 1K, 2K 4K etc.
杰克说的挺对的,MIPS-like的CPU是没有PUSH/POP指令的,RISC CPU一般是在函数入口和出口对SP/FP做加减来建删栈的。hardwired的堆栈地址能节省线程切换TLB的时间,是一种空间换效率的tradeoff。
小刘,你最近对首席是极尽攻击之能事嘛。。。:)
谢谢你的QFP和其他关系芯片,体系结构的文章,讨论。
Will在Stanford曾经给过一个比较详细的Talk。但很tricky。没有给出Slides。。。
我miss了其seminar。如果有去过的人,晒一晒。
首席,我可没有攻击你啊,真冤。
还是叫我老刘吧,年纪也不小了。
Hotchips20 QFP report
http://www.hotchips.org/archives/hc20/3_Tues/HC20.26.720.pdf
[杰克说的挺对的,MIPS-like的CPU是没有PUSH/POP指令的,RISC CPU一般是在函数入口和出口对SP/FP做加减来建删栈的。]
exactly,实际上CISC的PUSH/POP,最后microcode也是跟risc做的同样的操作。当然,8051和8086这样的处理器……就当我没说吧。
咔咔咔。读者有没有真动过刀枪写过MIPS,PPC等的trace的?:-)。PPC的EABI比较清晰。我基本上是1个星期能搞定。MIPS的可确实不是很好写。。。折腾了我很久。。。才没有bug。。。
我对MIPS,PPC,xScale, x86都接触过。但确实还是对PPC感觉更好一些。。。。。。
有关注过IBM 最近宣称的wire speed processor的牛牛吗,能否介绍、评论一下
什么trace?call back trace?
华为的代码到处都是,一个assert出一堆。
PPC EABI还是很简单。
老刘不错嘛。感觉是第一线战斗上来的。还知道EABI:-)。我还以为是个学术派选手呢。。。
是,就是指call trace,例如出错之后,。。。MIPS的不好写。当然,我估计当年水平比较差:-)。老刘是匪军任部的?:-)
当年玩过不少处理器,什么PPC, ARM, NP…..
嗨现在只能蜗居了。
太难用了wordpress
PPC的backtrace最简单了,就是一个单链表,MIPS的栈结构的确复杂很多,必须要scan当前函数源代码来决定是否在栈里有ra,而且还有用于更复杂调用的FP指针。ABI么,看看GDB基本就都明白了,连带参数,局部变量都能给你show出来。
现在Linux kernel应当有MIPS backtrace支持了吧。
反正kernel一崩溃,就show reg值和 函数调用再加代码的二进制片段。不晓得是不是楼上说的backtrace?
好像大家还是停留在Single-threaded的编程模式里。
There are total 160 threads and 160 runtime stacks corresponding to each thread.
Question 1: how to determine the starting address of each thread stack. Question 2: how to generate the same code for all 160 threads, i.e., the binary is the same but runtime behaviour is different.
>>hardwired的堆栈地址能节省线程切换TLB的时间,是一种空间换效率的tradeoff。
NPU thread switching doesn’t need to do TLB update, and it must finish within ONE or a few cycles.
I guess you are thinking of OS level process switching which is very different from NPU type of OS-less type of fast thread switching.
试想一下,一个两级的地址mapping不是能解决你的问题吗?
第一级为TLB,虚地址->offset。
通过PPE ID以及ThreadID得到第二级mapping表,当然这个二级映射表在外存。
第二级对不同的thread可以映射到不同的起始地址。再用这个offset一加不就得到你要的物理地址吗?
第一级就像per-cpu寄存器。高位用PPE ID和ThreadID寻址。数据结构需要固定大小为per-thread.
有了第二级,各个thread的stack起始地址可以任意指定,大小也可以任意配置。
老刘正解,因为RISC不存在x86的PUSH/POP之类的指令,MIPS的指令都是通过base+offset方式来做L/S的,所以只要每个thread自己的BASE是不同的,就算是相同的指令,相同的偏移量,得到的物理地址也是不同的。利用PPE ID和Thread ID来硬连线到物理地址,可以简化设计,节省TLB数量。对于超多核+多线程设计来说,TLB数量是很有限的,一般单核的多个thread共享一套MMU,不对某些小的region做hardwired,会浪费很多TLB,使设计复杂化。
thread切换时间上总是有代价的,只有当访问外存所需要的等待时间超过了thread来回切换的总时间时,才有必要做切换。假如你不做hardwired,4个thread就需要四条TLB来影射stack,还有其他类似的小内存块区都要四倍的TLB来影射,总的TLB数量就很可观了。而目前每个PPE的可配置DTLB也就四个,所以我会说hardwired设计是为了节省TLB重载。
数通兄,
从这个二级mapping表读取stack基址并用简单的加法器得出最终的地址。一个疑问是这个操作是在何处呢?在内存资源的前端?还是在PPE模块呢?
假设
1)在内存资源的前端
每个PPE Thread发出外存访问请求,PPE互联接口把PPE id、Thread id和offset,R/W通过消息请求包发给内存资源单元。内存资源前端用ppe id, thread id得到二级表外存地址,从外存读入并放入它的局部cache(cache miss case)。并用它的加法器得出最终地址。以后的stack访问都能从这个cache中得到基址。
2)在PPE模块
如果这个二级表放到PPE中,优点是速度快,缺点是浪费资源,还需要额外的同步。
数通兄,
1)这两个L2-Icache是分别为20个PPE使用吗?
2)D-Cache支持hardware enforced cache coherecy吗?
To 27#,
各个thread的stack起始地址可以任意指定,大小也可以任意配置
起始地址和大小固定不是更好吗?NP上写C code,再怎么灵活,也不能跟在X86上写application比啊。
介绍一下其他厂商的做法吧。
杰克,
你说得对,要是我设计这个软件系统,我也会用固定的base和相同的大小。这不是为了给MT兄解释嘛。:)
to老刘
就像杰克说的,没有二级映射的必要,每个thread的base和大小都是固定的方式是最适合的。L2IC当然是所有PPE共享的,snooping代价大,流水线作业也可以避免coherence的。
这么说Cisco干脆把这个base也写死了,直接hardwired高位。简单呀,让我晃然大悟。
数通兄,
那为什么需要两个256KB L2-ICache,而不是一个512KB呢?疑惑的说。
“流水线作业也可以避免coherence的”,你的意思每个报文如果通过多个Thread分段处理也能保证coherency? 如何做到的说?
Will’s United States Patent US7551617
兄弟,我也参考了这篇专利当我写这个分析报告。
在你写以前,是否找一台试试“show platform hardware …”,那么…
我要是有这个盒子,我早就会show出来看看。
没有呀,只能纸上谈兵。
哪位兄台能晒一晒show的信息?
To 32#,
各个thread的stack起始地址可以任意指定,大小也可以任意配置, for example 1K, 2K, and 4K, 8K, that it. You can think it as a configurable setting. It should be flexible but not any satck size.
To #27, 原理对了,但你又扯到了TLB. 请考虑一个没有TLB的实现方案。注意,thread switching takes one cycle and there is no time to do TLB look up and update. Under this case, how do you determine the thread’s stack starting address without TLB?
>>“流水线作业也可以避免coherence的”,你的意思每个报文如果通过多个Thread分段处理也能保证coherency? 如何做到的说?
I think it means several PPEs are composed as a pileine, i.e., functional pipelining.
There is no coherence among 4 threads per PPE since they work on different packets belong to different flows.
我就是这个意思。因为共有160个Thread,我就这么叫。
那为什么需要两个256KB L2-ICache,而不是一个512KB呢?疑惑的说。
“流水线作业也可以避免coherence的”,你的意思每个报文如果通过多个Thread分段处理也能保证coherency? 如何做到的说?
—数通兄:L2IC为什么要snooping?取指是主动去取,打补丁好像也不用啊?Thread分段处理怎么能保证cohernecy?同问,数通兄详解下。
To 40#
同意你的base和size可任意配置的说法。有没有可能是在编译器生成时base和size打入bin文件,加载时通过控制软件给各个Thread的?
我猜数通兄说的是D-Cache snooping,I-Cache snooping没有这个必要。
木匠也是从一线战斗部队上来的,都知道热补丁,注意这不是冷补丁。
有没有C的人出来劈一下?
热补丁,注意这不是冷补丁。
给解释解释这两句行话吧。呵呵
看看H3C网站关于热补丁介绍。
我要是有空的话,可以写一篇文章关于《如何实现热补丁》。
256Kx2的L2-I$也是我困惑的,cpp-arch也只说单个IIC大小是256K,被多个PPE Cluster共享,没提为什么要两片。也许是为了以后出Lite版本?
Snooping是说的D$,标点没用好,sorry。
软件控制coherence和ordering能简化硬件设计。
流水是指X11类似的NPU,CPP是并行的,一个thread管一个packet,coherence是能避免的。
Stack可配置有什么好处么?栈里面就存这么点东西,给个足够大的page不就行了?难不成给了你64KB,你非不要,说我就要1KB的,可配base的?这不是给硬件设计找麻烦么?64KBx40也就才2.5MB,放在固定外存里,出问题也好debug。CPP又不是通用CPU,不需要那么灵活。
你就算从cache里取个指令,都是要先过MMU的,为什么不用TLB来搞Stack呢?反正切换thread也不用换那条固定的TLB,不损失时间的。
关于流水线,我原来的理解跟你一样,一个thread处理一个完整的包,这样确实很简单,也能避免coherency issue。
数通兄,
能不能点一点这个packet processor的memory subsystem? 感兴趣的说。比方说memory controller大致的结构。
To 老刘:
就是hotfix?
To 数通人:
有时候一个packet, 一个thread处理不完吧。
All IP, 关于IBM WSP可以看看这个blog
http://blog.sina.com.cn/s/blog_60509bd00100hjeo.html
谢谢aaa
To 刘兄 46#:
呵呵,算不上一线部队,撑死了是个小乡村里游击队的新丁:)
To 数通兄 50#:
thread是分段处理的,一个包过来后并不是一个thread全部处理。
Stack可配置我是认为可以对以后的业务没有这方面的约束,非动态可调所以对硬件设计不会有大影响。但是从aaa提供的链接看,你是对的:)
也谢谢aaa
20 PPEs per 256K L2-I$
one packet per thread, CPP is a parallel NPU. there is no reason that one packet can’t be handled by just one thread.
DRAM/GPM/TCAM are interconnected with PPEs through RIC as Resources.
MIPS没有backtrace功能,去年搞的时候,google了好一阵子,都没找到实现方法。最后采用解析程序的Frame Debug信息,得出SP,及Ra的信息,然后在用户栈里计算出正确的Ra.
完全源码解析Debug信息,包括File,Line,Symbol,Frame,基本上自己实现了一个GDB,就是没加程序中断了。
今年在Google上看到,backtrace有另一种做法,解析源码,找到addif sp xxx, sw ra,xxx,然后在SP里找,看上去很精简,不过运行时查执行代码,及stack buf,会不会crash啊?
LS, mips 34k has a optional back trace buffer
上面那几楼, 你们讨论的thread是不是一个东西哦?
58#的,34k的那个是怎么实现的?