数据中心的虚拟接入是新一代数据中心的重点课题,各方已经争夺的如火如荼。目前网络上的中文资料还不多,根据自己的经验写了一点对虚拟接入的理解,意在丟砖,引出真正的大佬。
一、为什么虚拟化数据中心需要一台新的交换机
随着虚拟化技术的成熟和x86 CPU性能的发展,越来越多的数据中心开始向虚拟化转型。虚拟化架构能够在以下几方面对传统数据中心进行优化:
- 提高物理服务器CPU利用率;
- 提高数据中心能耗效率;
- 提高数据中心高可用性;
- 加快业务的部署速度
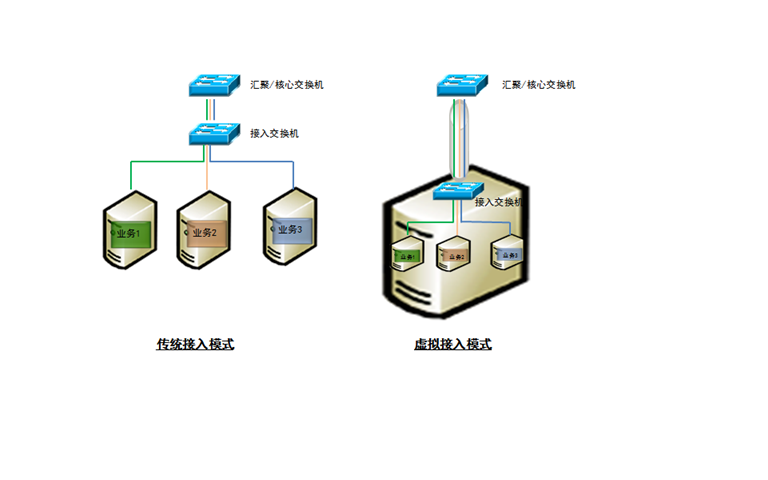
正是由于这些不可替代的优点,虚拟化技术正成为数据中心未来发展的方向。然而一个问题的解决,往往伴随着另一些问题的诞生,数据网络便是其中之一。随着越来越多的服务器被改造成虚拟化平台,数据中心内部的物理网口越来越少,以往十台数据库系统就需要十个以太网口,而现在,这十个系统可能是驻留在一台物理服务器内的十个虚拟机,共享一条上联网线。
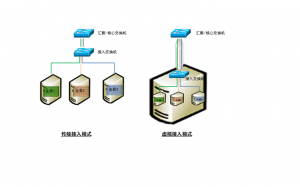
这种模式显然是不合适的,多个虚拟机收发的数据全部挤在一个出口上,单个操作系统和网络端口之间不再是一一对应的关系,从网管人员的角度来说,原来针对端口的策略都无法部署,增加了管理的复杂程度。
其次,目前的主流虚拟平台上,都没有独立网管界面,一旦出现问题网管人员与服务器维护人员又要陷入无止尽的扯皮中。当初虚拟化技术推行的一大障碍就是责任界定不清晰,现在这个问题再次阻碍了虚拟化的进一步普及。
接入层的概念不再仅仅针对物理端口,而是延伸到服务器内部,为不同虚拟机之间的流量交换提供服务,将虚拟机同网络端口重新关联起来。
二、仅仅在服务器内部实现简单交换是不能的
既然虚拟机需要完整的数据网络服务,为什么在软件里不加上呢?
没错,很多人已经为此做了很多工作。作为X86平台虚拟化的领导厂商,VMWare早已经在其vsphere平台内置了虚拟交换机vswitch,甚至更进一步,实现了分布式虚拟交互机VDS(vnetwork distributed switch),为一个数据中心内提供一个统一的网络接入平台,当虚拟机发生vmotion时,所有端口上的策略都将随着虚拟机移动。
VMWare干得貌似不错,实际上在当下大多数情况下也能够满足要求了。但如果谈到大规模数据中心精细化管理,内置在虚拟化平台上的软件交换机还有很多问题没有解决。首先,目前的vswitch至多只是一个简单的二层交换机,没有QoS、没有二层安全策略、没有流量镜像,不是说VMWare没有能力实现这些功能,但一直以来这些功能好像都被忽略了;其次,网管人员仍然没有独立的管理介面,同一台物理服务器上不同虚机的流量在离开服务器网卡后仍然混杂在一起,对于上联交换机来说,多个虚拟机的流量仍然共存在一个端口上。
虚拟平台上的软件交换机虽然能够提供基本的二层服务,但是由于这个交换机的管理范围被限制在物理服务器网卡之下,它没法在整个数据中心提供针对虚拟机的端到端服务,只有一个整合了虚拟化软件、物理服务器网卡和上联交换机的解决方案才能彻底解决所有的问题。
这个方案涉及范围如此之广,决定这又是一个只有业界大佬才能参与的游戏。
三、谁在开发新型交换机?
HP,Cisco。
一个是PC服务器王者,近年开始在网络领域攻城略地,势头异常凶猛;一个是网络大佬,借着虚拟化浪潮推出服务器产品,顽强地挤进这片红海。
针对前文所说的问题,两家抛出了各自的解决方案,目的都是重整虚拟服务器同数据网络之间那条薄弱的管道,将以往交换机上强大的功能延伸进虚拟化的世界,从而掌握下一代数据中心网络的话语权。
Cisco和VN-TAG
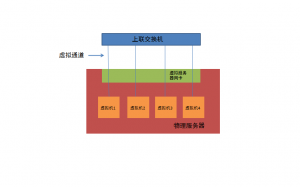
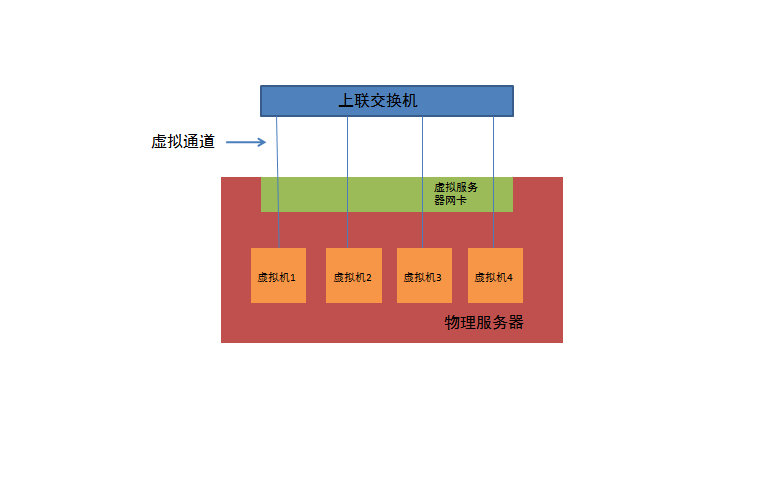
虚拟化平台软件如VMWare ESX部署之后,会模拟出一整套硬件资源,包括CPU、硬盘、显卡,以及网卡,虚拟机运行在物理服务器的内存中,通过这个模拟网卡对外交换数据,实际上这个网卡并不存在,我们将其定义为一个虚拟网络接口VIF(Virtual Interface)。VN-tag是由Cisco和VMWare共同提出的一项标准,其核心思想是在标准以太网帧中增加一段专用的标记—VN-Tag,用以区分不同的VIF,从而识别特定虚拟机的流量。
VN-Tag添加在目的和源MAC地址之后,在这个标签中定义了一种新的地址类型,用以表示一个虚拟机的VIF,每个虚拟机的VIF是唯一的。一个以太帧的VN-Tag中包含一对这样新地址dvif_id和svif_id,用以表示这个帧从何而来,到何处去。当数据帧从虚拟机流出后,就被加上一个VN-Tag标签,当多个虚拟机共用一条物理上联链路的时候,基于VN-Tag的源地址dvif_id就能区分不同的流量,形成对应的虚拟通道,类似传统网络中在一条Trunk链路中承载多条VLAN。只要物理服务器的上联交换机能够识别VN-Tag,就能够在交换机中直接看到不同的VIF,这一下就把对虚拟机网络管理的范围从服务器内部转移到上联网络设备上。

思科针对VN-Tag推出了名为Palo的虚拟服务器网卡,Palo卡为不同的虚拟机分配并打上VN-Tag标签,上联交换机与服务器之间虽然只有一条网线,但通过VN-Tag上联交换机能区分不同虚拟机产生的流量,并在物理交换机上生成对应的虚拟接口VEth,和虚拟机的VIF一一对应,好像把虚拟机的VIF和物理交换机的VEth直接对接起来,全部交换工作都在上联交换机上进行,即使是同一个物理服务器内部的不同虚拟机之间的流量交换,也通过上联交换机转发。这样的做法虽然增加了网卡I/O,但通过VN-Tag,将网络的工作重新交回到网络设备。而且,考虑到万兆接入的普及,服务器的对外网络带宽不再是瓶颈,此外,利用Cisco Nexus 2000这种远端板卡设备,网管人员还能够直接在一个界面中管理数百台虚拟机,每个虚拟机就好象在传统的接入环境中一样,直接连接到一个交换机网络端口。
目前,思科推出的UCS服务器已经能够支持VN-tag,当Palo卡正确安装之后,会对上层操作系统虚拟出多个虚拟通道,每个通道对应一个VIF,在VMWare EXS/ESXi软件中可以将虚拟机绕过vswitch,直接连接到这些通道上,而在UCS管理界面上则能够看到对应的虚拟机,使网管人员能够直接对这些端口进行操作。
Cisco同VMWare已经将向IEEE提出基于VN-Tag的802.1Qbh草案,作为下一代数据中心虚拟接入的基础。
HP和VEPA
Cisco提出的VN-Tag,在IT业界引起的震动远远大于在客户那得到的关注,如果802.1Qbh成为唯一的标准,Cisco等于再一次制定了游戏规则,那些刚刚在交换机市场上屯下重兵的厂商,在未来数据中心市场上将追赶得异常痛苦。此外,VN-Tag是交换机加网卡的一揽子方案,还能够帮助Cisco快速切入服务器市场,对其他人来说是要多不爽有多不爽。
很容易猜到,这其中最不爽的就是HP,在交换机和服务器领域跟Cisco明刀明枪地干上之后,被这样摆上一道,换谁也不可能无动于衷。HP的应对很直接,推出一个类似的方案,替代VN-Tag。
HP的办法称为VEPA(Virtual Ethernet Port Aggregator),其目的是在部署了虚拟化环境的服务器上实现同VN-tag类似的效果,但VEPA采取了一条截然不同的思路来搭建整个方案。
简单来说,VEPA的核心机制就是两条:修改生成树协议、重用Q-in-Q。
VEPA的目标也是要将虚拟机之间的交换行为从服务器内部移出到上联交换机上,当两个处于同一服务器内的虚拟机要交换数据时,从虚拟机A出来的数据帧首先会经过服务器网卡送往上联交换机,上联交换机通过查看帧头中带的MAC地址(虚拟机MAC地址)发现目的主机在同一台物理服务器中,因此又将这个帧送回原服务器,完成寻址转发。整个数据流好象一个发卡一样在上联交换机上绕了一圈,因此这个行为又称作“发卡弯”。
虽然“发卡弯”实现了对虚拟机的数据转发,但这个行为违反了生成树协议的一项重要原则,即数据帧不能发往收到这个帧的端口,而目前虚拟接入环境基本是一个大二层,因此,在接入层,不可能使用路由来实现这个功能,这就造成了VEPA的机制与生成树协议之间的矛盾。
但是VEPA没有vPC,在接入层还是要跑生成树。HP的办法就是重写生成树协议,或者说在下联端口上强制进行反射数据帧的行为(Reflective Relay)。这个方式看似粗暴,但一劳永逸地解决了生成树协议和VEPA机制的冲突,只要考虑周全,不失为一步妙棋。
除了将虚拟机的数据交换转移到物理服务器上之外,VN-Tag还做了一项重要的工作,就是通过dvif_id和svif_id这对新定义的地址对不同虚机流量进行区分。HP在这里的搞法同样简单直接,VEPA使用Q-in-Q在基本的802.1q标记外增加了一层表示不同虚拟机的定义,这样在VLAN之外,VEPA还能够通过Q-in-Q区分不同的虚拟机,只要服务器网卡能够给数据帧打上Q-in-Q标记,上联交换机能够处理Q-in-Q帧,基本就可以将不同的虚拟机流量区分开来,并进行处理。
至此,VEPA看起来已近能够实现同VN-Tag类似的功能,因此HP也将VEPA形成草案,作为802.1Qbg的基础提交至IEEE。不得不说,VEPA是个非常聪明的设计,不管是对生成树行为的修改,还是利用Q-in-Q都不是什么不得了的创新,目前的交换机厂商只要把软件稍微改改,就能够快速推出支持802.1Qbg的产品,重新搭上数据中心这班快车,追上之前被Cisco甩下的距离。
VN-Tag和VEPA
自从Cisco祭出VN-Tag大旗后,各种争议就没停过,直到HP推出VEPA,这场口水仗达到高潮,随着2011年,802.1Qbh和802.1Qbg标准化进程的加快,围绕虚拟接入下一代标准的争夺将进入一个新的阶段。
这也不难理解,随着数据中心内虚拟机数量的不断增加,越来越多的物理网口转化为虚拟的VIF,如果一家网络厂商没法提供相应的接入解决方案,它的饼会越来越小,活得非常难受。
VN-Tag就是Cisco试图一统下一个十年数据中心的努力,HP虽然同思科正面开战时间不长,但从VEPA来看,其手法相当老辣。由于VEPA没有对以太网数据结构提出任何修改,实现成本非常低,以往被思科扫到大门之外的厂商,一下子见到了曙光,前仆后继地投靠过来,Juniper、IBM、Qlogic、Brocade等等都毫不掩饰对VEPA的期待,Extreme甚至表示,已近着手修改OS以保证对VEPA的支持。待各方站队结束,大家发现Cisco虽然有强大的盟友VMWare,但另外一边几乎集结了当今网络界的所有主流厂商,舆论也逐渐重视VEPA的优点,甚至Cisco自己也不得不松嘴说会考虑对802.1Qbg的支持。
戏演到这里,很多人幸灾乐祸地等着看Cisco怎么低头。但有一个问题,VEPA这么完美,为啥Cisco之前没有采用类似的思路?仅仅为构建一个封闭的体系架构吗?我认为不是。
回答这个问题前,我们首先要弄清楚另一个问题。以VMWare ESX/ESXi为例,由于ESX/ESXi自带的vswitch只是模拟了一台二层交换机,当一台物理服务器上两个处于不同VLAN的虚拟机之间需要交换数据时,vswitch是无能为力的。只能将数据送到上联物理交换机上,由物理交换机完成VLAN间的三层转发。听起来是不是很熟悉?这和之前提到的VN-Tag与VEPA的机制很相似,如果现有的虚拟化环境已经能够将数据交换的行为转移到上联交换机,为啥还要大费周折地提出一个新标准呢?
这是因为,当下的这种方案是利用VLAN来隔离不同虚拟机,通过TRUNK将对应多个虚拟机的VLAN送到物理交换机上。这种方式打破了数据中心内对VLAN的使用惯例,比如,网管人员通常会把负责同一业务的多台服务器放在一个VLAN内,如果VLAN标签都被用来隔离虚拟机了,则没法按照传统方式来区分不同业务,解决了一个问题,带来另外的问题,这是绝对行不通的。
现在,我们可以回答之前的问题了,新一代的虚拟接入方案是要在不影响802.1Q等原有网络行为的前提下,完成对虚拟机的接入、区分和管理。有人会说,用PVLAN不可以吗?但我们怎么保证PVLAN没有其他的用处呢?出于这样的思路,Cisco没有利用现有的任何技术,提出了一个全新的实现方案,正因为VN-Tag从出生起就“干干净净”,同谁都没有瓜葛,因此VN-Tag携带的信息就能够在整个数据中心内自由的传递,从而快速为用户搭建起一个清晰、完整的虚拟接入平台,所谓“磨刀不误砍柴工”。
HP充分利用了现有条件,VEPA的整个架构看上去简洁、高效,但是对生成树协议改动和利用Q-in-Q无疑会影响到现网的行为。生成树协议的效率和问题一直是个老大难,但无数聪明绝顶的高手琢磨了这么多年,协议的变动仍然不大,说明对这种基本协议的修改不是一蹴而就的,往往迁一发而动全局,现有的模式是各方协调、妥协的结果。VEPA要在短时间内拿出一个完美的方案,所需花费的精力也许并不比重新提一套方案少。
除了协议本身之外,摆在HP和VEPA面前还有两个难题,首当其冲就是VMWare的支持。VEPA虽然对交换机硬件改动不大,但要真正跑起来,还需要虚拟化平台软件的支持,虚拟网卡和虚拟交换机得主动把所有数据帧扔到上联交换机上,后面的故事才能续上。可是VMWare还是Cisco在VN-Tag上最大的盟友,虽然Cisco已经表示会支持802.1Qbg,但会有多及时就难说了。
时间也就是VEPA的第二个困难。目前,思科的UCS服务器已经能够提供端到端的VN-Tag部署。而HP的Virtual Connect解决方案仅实现了Q-in-Q的多链路,对“发夹弯”的支持并不好,也没有VMWare的支持,说白了,VEPA还只是图纸上的设计,没有实际产品支撑。此外,虚拟接入只是下一代数据中心组成之一,FCoE、THRILL等都非常重要,针对这些技术,HP仍拿不出成型的产品,相反,Cisco在所有领域几乎都布局完毕,留给HP的时间不多了。
这场针对数据中心接入的争夺,在2011年必将愈演愈烈,Cisco携全线产品势在必得,而HP的VEPA评价聪明的设计,得到业界广泛支持,故事结局如何,还待静观其变。
| 







深入浅出,说得很清楚,佩服佩服
写的不错,有理有据的。要是能把写这篇文章的参考资料也给出链接就更好了
想请教一下楼主,Multihop FCoE,FCoE forwarder,Fabric Extender,这些词我前阵子搜索过,一直没有找到细节的东西,不知道楼主是否了解,请指教!
非常好的观点,非常清晰的思路
好文,学习。
新平台/新标准的搭建不论对谁都是事关生死 的大事,就看业界怎么演绎了,呵呵。
写的非常好,学习了
按道理,虚拟机之间的流量在vSphere内部应该更快点,为什么要跑到外面的交换机上转一圈再回来?如果把vswitch做成一个full feature的switch,会不会更好一点?
physical switch vswitch–virtual machine.
不懂网络内核方面,猜测如果做入那些full feature,esx上的cpu恐怕吃不消了吧。
to kernelchina:
看这篇文章的意思,就是要把虚拟机当真实的机器用,让它们之间的流量也暴露在整个网络中,就像2台物理主机共用一根网线一样。
这篇文章意义重大。。。。。。
http://bradhedlund.com/2010/09/15/vmware-10ge-qos-designs-cisco-ucs-nexus/
这人是思科的,他的博客偷了不少这方面的料。
这个文章好,拜读了!
这都是过分渲染“云”计算,虚拟化的结果。
VN-tag和VEPA是虚拟接入的两个标准草案,其本质从用户的角度来看,不过是虚拟机识别和管理的技术实现手段而已。
思科推行VN-tag的市场目的就是搞垄断,就像当年的EIGRP一样;其他厂商推行VEPA就是不想这块细分市场被思科所垄断,就行OSPF一样。 这种从网络设备到服务器/网卡的端到端垄断是思科所追求的,也正是其他厂商不希望看到的。
功力啊功力,清晰易懂,好文。
和FCoE一样。还好有个iSCSI顶着。。
以前看cisco的nexus 1000v和vn-link没搞明白是什么意思,现在有点明白了。把虚拟机当真实的机器用,需要各方面加倍,然后再分割,否则性能没法保证。
好文!
PS:冬瓜头同学也写一个吧
To cong:
呵呵,感谢这位的 鞭策,此文甚好,学习中,后续文章会努力提高质量!谢谢!
to 冬瓜头
FCoE forword和fiber channel forward一般指的都是服务器上联的交换机,FCoE的链路目前只能实现一跳,存在于服务器网卡和forward之间,FCoE的帧在forward上被拆开,并通过FC链路送到SAN上。
而要将FCoE链路延长到更远的交换机,就是Multihop FCoE,即FCoE的多跳。Multihop FCoE在FC-BB-5中已经有了对应标准,实现方式也不止一种。
Fabric Extender一般指Cisco的Nexus 2000扩展设备,相当于把机架式交换机的板卡取出来,作为一个独立设备。这样的好处是可以以ToR的方式不限,以EoR的管理。
deltali的意见很好,我找了一个FEX的说明:
http://www.networkworld.com/community/node/39236
to kernelchina
基本上,虚拟接入解决的不是性能问题,而是管理问题,将网络的行为重新还给网络设备。
当然,解决一个问题的方式有很多中,这只是其中一种
不知道CISCO针对TRILL是什么解决方案
好文,必须要顶
猜测一下结果,VEPA将会赢得胜利,一个封闭的系统没有前途,就如EIGRP一样。。。。。。
to 旁观者清
实际上你说的OSPF是Cisco除了BGP外贡献最大的标准协议之一。从对RFC的贡献看,Cisco从来不想做一个“垄断的协议”(这和当年IBM、DEC和HP有多么大的不同啊),Cisco只是想抢先推出一些标准,并试图放到IEEE和IETF上公开,不过想在这些领域抢得先机而已。若说垄断,凭着现在全球市场占有率,直接出私有协议不就完了,象水果公司的OS那样。
to libing
Palo绕过Hypervisor实现VM直接驱动的I/O,这可是大大的性能问题,想想现在那些I/O密级型的应用
to libing
Palo绕过Hypervisor实现VM直接驱动的I/O,这可是大大的性能改善(Hypervisor Bypass),想想现在那些I/O密级型的应用
to tom
现在很难说,和EIGRP最大的不同是,Cisco当年不同意公布EIGRP协议,而802.1Qbh从一开始就是开放的。而且Cisco进可攻、退可守:进,可以推行干干净净的虚拟化接入方案802.1Qbh,不增加用户部署的管理负担(Spanning Tree快在数据中心死了);退,可以非常容易支持Qbg,和大家一样不就完了
to Cius,
关于绕过虚拟Hypervisor,直接读取I/O的技术意义,对VN-LINK等技术有重要的间接推动作用. 毕竟, “Palo卡的vNIC技术,配合VN-Link以及VMWare的Hypervisor Bypass技术,可以让网卡流量不经过CPU和Hypervisor,完全交由Palo网卡直接硬件处理。这样能带来带宽吞吐30%的性能提升”。
http://www.cisco.com/en/US/solutions/collateral/ns340/ns517/ns224/ns944/white_paper_c11-593280_ps10279_Products_White_Paper.html
但是,从实际看,包括同虚拟化厂商的沟通,坦率说,现在还没有killer级应用,必须用direct I/O;就客户而言,国内也极少有实际部署direct I/O案例。我了解只有个别类似于涉及视频编辑的应用,可能会考虑。
因此,如果你这边有关于Direct I/O在实际中的应用情况,可否分享一下~
采用Direct I/O的话,首先会对live migration造成影响。这个是绝对不能接受的,不知道现在这方面的问题解决的如何了?
其次跟嵌入式设备不同,在服务器虚拟化这边,还是要尽量避免让虚拟机直接控制硬件。
To xie:
TRILL就是Cisco在推的,与之对应的是IEEE在推的802.1aq(SPB)。这两个方案都是为了解决STP带来的问题而提出的。感觉TRILL更正统一些,因为是Perlman大妈主导的,当年也是她搞的STP。但目前TRILL的标准里边都没有OAM相关的内容。而SPB由于完全继承QinQ和PBB,分成SPBV和SPBM两种模式,也顺理成章的继承了以太网的OAM那一套东西。但是这里又把PBB/PBT这个边缘化了的东西给弄回来了,好不热闹。现在TRILL和SPB都还是draft。
至于后边怎么发展就拭目以待啦。
写得很好,但我有疑问,VN-tag如何表示虚拟机的Mac地址,从文中描述看,传到上联交换机的IP包为网卡Mac+vif_id,网卡Mac表示物理网口,vif_id表示绑定在该物理网口的虚拟网口,如果虚拟机被迁移至另一台物理机上运行,路由如何修改?IP协议修改了,虚拟机如何跟外网通信?
To Fear
VNTag本身是不携带MAC信息的,对现有的vMotion流程也不产生影响,VNTag解决的网络侧对虚拟机的识别和管理问题。
就我的知识范围,虚拟机迁移后,还是需要通过ARP更新来实现正确寻址。
To Cius:
Cisco在协议标准化方面对行业的贡献非常之大,这是有目共睹的。但是,既然是商业公司,毕竟不是研究机构或者慈善机构,必定有其特定的商业目的,不会做亏本的买卖。Cisco投入大量的人力物力在标准化方面,或者说是抢得先机,目的其实再简单不过了,就是要早一步抢占这块细分市场,形成对后来者的技术垄断,如果没有反垄断法的制约,天知道会是什么样的情况,呵呵。效果很明显,Cisco也是领导行业标准化的最大贡献者,同时也是最大的受益者。
举个在中国最简单的例子,想当年中国的整个金融行业就一种路由协议,EIGRP,放眼望去,都是Cisco的设备。华为搞一个EIGRP,被Cisco给告了最后不了了之,一些其他厂商(我就不点名了),现在还私底下维护EIGRP的代码和功能,为了能在某个网点可以和Cisco的EIGRP互通。近些年,在其他厂商的集体抗议和抗争下,OSPF才得以进入到中国的金融行业网络中…
To Xie
TRILL是Layer 2 multi-path的“标准化”实现版本,如Da Vinci所言,是Cisco主推的基于二层网络的基于Mac地址进行“路由”的协议,用了ISIS的协议扩展。Cisco私有的实现叫FabricPath,其实和TRILL几乎完全一样。
目前处于Draft状态,想法很好,感谢Cisco的不断创新,不过,至于实际可用性还有待未来市场的考验。
To deltali & Tanglin
Palo除了能配合ESX实现direct I/O,还有一种hypervisor pass thru模式,这种模式也能一定程度地降低CPU负载,增加I/O吞吐,同时保持vMotion等高级功能
passthru模式其实是direct i/o的延伸,本质上是vt-d和sr-iov的配合,网卡本身提供多个logical function(就是多个小的虚拟网卡),然后通过vt-d映射到虚拟机里面。esx本身通过一个驱动模型来解决vmotion迁移到不支持这些技术的机器上的问题
虚拟机里分配virtual function ,加载对应 virtual function driver, 与 vmm 中的 physical function driver 通信
关注下技术新动态
嗯,是virtual function
虚拟机的virtual function driver不需要和physical function driver通信,是直接和virtual function通信
请问类似altor,针对虚拟机安全的目前有哪几家?
libing是哪位,是我除了kenealchina、冬瓜头以外又想拜见的一位大师。好文!
09年的时候思科中国的朋友想让我写篇关于nexus的软文,给了我一堆ppt,还有一个上海的tme给我讲了一通,就觉得当时做datacenter,想搞虚拟存储融合,思科看得真的远。nexus强不在性能上,而是在内涵上。Juniper的产品更像是美国跑车,快,不会拐弯,没内涵。
当时对n1000的v和n5k的几个产品是颇有想法,想仔细研究研究,无奈犯懒,就没写。也失去了稿费啊。
早知道当时写了,即使没稿费,也能在弯曲得个头彩,再树树我在网络圈的威。
此次本文,我是服了。好文!
但是,其实我一直有个想法,我们是沿着虚拟化这么看得,复杂之复杂化。
会不会有一个简单不需要复杂的东西呢?
这样搞下去,用户使用成本更高。
1、很奇怪IEEE的trill在05年就提出来,为啥推动得这么慢,现在draft还只是个high-level的状态,几个核心问题oam机制,isis扩展,分发树计算方案都还只是个概念,根据draft还不能做出该功能,特别是控制平面,如DRB选举之类的东西。
相反SPB这个“弃婴”反倒找到了数据中心这个应用场景,内容更新得较快。(虽然我个人很不看好SPB的对于trill的竞争)
2、关于vm迁移中的不中断业务(在线迁移)的方案(IP,mac不变,业务不断),难道只能是arp的方式来解决,是否有更好的方法,也许两个管理团队(网络管理与服务器管理)的配合能更好的解决这个问题,至少不是等网络去被动的发现迁移,不过要这两方配合太不容易:)
3、关于VEPA的实现,我更多的是担心多播或者广播的问题,看各位大虾有比现有draft更好的解决方案
altor 已经被JUNIPER收购,而且J也不仅仅是快而没内涵啊?
to bigrong:
“09年的时候思科中国的朋友想让我写篇关于nexus的软文,给了我一堆ppt,还有一个上海的tme给我讲了一通,就觉得当时做datacenter,想搞虚拟存储融合,思科看得真的远。nexus强不在性能上,而是在内涵上。Juniper的产品更像是美国跑车,快,不会拐弯,没内涵。”
原来是专业人士,而且和思科的渊源很深哦,呵呵,佩服佩服,也怪不得没有稿费还在这里帮Cisco免费打广告呢,对于您这种敬业的精神很有感触。。。
顺便请教一个小问题,您了解Nexus的历史吗,能深入解释一下为什么Nexus的内涵如此之深吗? 我们这些局外人没有渠道,对此又非常感兴趣,希望不吝指教。。。
to bigrong:
高抬了,大师都藏着,我的原意是抛砖引玉。
我觉得你说得很棒,很多时候,我们需要把复杂的实现机制隐藏在简单的使用界面后面,提供给用户,用户用个机器不需要磨练成专家。如果用户觉得太复杂,那就不是好的解决方案,这个方面,国内很多厂商做的非常好。
To Tom:
类似的产品其实非常多,特别是针对VM的性能和安全监控,数不胜数,但能做得好并跳出来的不多。思科有一个类似的产品VSG,可以看两眼
http://www.cisco.com/en/US/products/ps11208/index.html
多谢libing,此文章受益匪浅
回旁观者清的所有帖子
你说的都是事实,但是流于短视,对于任何公司来说,技术垄断都是利润,但是任何垄断都是短线的利润,创新才是长期的,对于EIGRP来说更多的是销售团队的策略,并不是cisco创建这个协议的本意,至少不全是为了垄断,多给用户一个选择,也不是坏事啊,开个玩笑,您对阴谋论估计研究多了,呵呵
另外给所有关注这个话题的人另外一种观点,就是抛开云计算来看,高速网络的发展,已经吧server内部io和网络io拉得非常近了,如果吧网络和计算看成是整体,那么每个部分都是组件,长久来看可以简化服务器的维护,提升网络的贡献度,让用户像使用交换机那样使用服务器,从这个角度来看,cisco的vision是要胜过HP的,而且很关键一点,无论上FC-BB5还是Fabric path,cisco都不是封闭体系,因此在垄断的同时也体现了创新
我觉得huawei对cisco的理解还是很到位的,huawei说的“像用自来水一样使用云计算”可以说是更宏伟的vision
顺便说一句,国内用户的绝大多数问题是自身造成的,试问诸位在哪个项目里面没有under the table的东西
非常非常不错的文章,拜读了好几遍!
针对7楼的问题我做下解释,如果虚拟服务器都在vswith上跑,那么虚拟服务器上无法流量监控、无法实施安全策略,管理边界不清晰,vswitch的问题到底是服务器的问题还是网络设备的问题。所以必须将vswith上的交换回归到交换机。
我也已经读了3遍,并且到处推荐了。VN-Tag的事情的战略意义太巨大。。。。。。
我要好好从这个地方开始切入networking的虚拟化。。。
为什么每次首席的发言都是只说半句话,然后留下一串省略号
让看得人真的很。。。
VN-tag是全局有效,还是虚拟机与交换机之间有效的?vif是多长字节,图看不太清楚。Q-in-Q就是为了解决vlan tag不足的问题,vif应该要考虑一下这个问题。
VN-Tag到了Physical Switch,上行的时候就没了。
所以,Cisco是要大卖VN-Tag Aware的switch。相对而言,VEPA不需要新设备。
……如果这样,VEPA胜算略大。。
客户需要考虑的很多,产业链是否配套,是否有成熟的技术人员能够管理,总拥有成本等等。
真是一篇好文章!!
VN-Tag这个是Cisco的私有协议吧,开放给别的厂家如H不?H这些厂家的在VN-TAG和VEPA的取舍态度是如何的呢?
看了下j的5800在dc云的应用,支持VEPA,Qfabric实现了3-2-1中的1,端对端,5800做访问控制就,加上j收购的altor,可以管理到虚拟机之间的流量,j的方案还是比较完整的,但个疑问,5800的fw性能据朋友说实际测试达到了150G,但如何扩展?多个5800之间如何进行高速交换?
To Netcache
创新的目的是什么,是搞研究成果申请专利?是为了提出并发布标准?是为了做技术的泰斗把创新的想法和技术普及推广而得到大家的崇拜?还是是为了人类社会的进化无私的奉献?
研究机构可能是这样的,但是商业公司绝对不会是这样的。商业公司创新的最原始目就是创造利润,不断的扩大利润。创新和技术都是商业公司创造利润的工具。
思科技术牛,如果不垄断的话,可以在创新新技术的时候应该邀请华为、邀请Juniper、邀请行业内主流的同领域其他厂商一起交流,共同推进新技术和新标准的发展啊,Cisco的fabricpath里面也放上几台华为的交换机,岂不美哉?
如果从Vision的角度,做的最好的还是IBM,要实现智慧的地球,造福全人类。思科也好,华为也罢,还是太短视了,哈哈。
To owen
VN-TAG不是私有协议,是基于802.1Qbh的一个实现
这篇文章和fabricpath那篇文章通读,还是可以看到思科布局DC市场久矣。
其它厂家看来要加油才行了。
期待LZ的下一篇作品。
To Libing: 你是sprient的吗?如果不是,告知个事情,Sprient将这篇文章到处发给end users.
To AC
谢谢告知,你是说思博伦吗,我还真不知道这事
对的,思博伦
好文,学习了
既然是开发的,那么其他厂商为什么都去支持VEPA?
从hp收购的案例来看,但hp最擅长还是打印机,呵呵,所以脚步慢很正常
恩,看后觉得十分不错,但是究竟鹿死谁手还是市场占有率说了算
[...] 内存警报暂时解除后,网络逐渐成为新的瓶颈。当越来越多不同性质的虚拟机跑在一台物理服务器上时,他们的进出数据都会拥挤在一个I/O通道上,这显然是不合理的。以Cisco为首的网络厂家提出了VN-Tag/VEPA等解决方案,来规范虚拟机流量的转发机制,通过在全网部署VN-Tag,不同虚拟机的流量能够被识别,并且在上联交换机上得到很好的QoS保证和安全隔离,但这只解决了一部分问题,虽然VN-TAG能够区分出来自不同虚拟机的流量,但普通服务器网卡只提供一个PCIe通道,在出口网卡上,这些流量仍然混杂在一块。 [...]
用VN-Tag后,在交换机侧配置里看到的是什么,子接口?
To Libing:我是报社的编辑,目前正在关注这两个标准的进展,采访了两个厂商的一些技术专家,我很想您站在客观局外高手的角度对这两种技术做一个评述,发表在我们的杂志上,并支付稿费。
您如果看到这条留言请联系我,非常希望得到您的答复。
多谢!
我的邮箱是:li_xiayan@cnw.com.cn
夏艳MM也来了……这可是真正的美眉啊,CNW就是不缺美女
做媒体的,以及市场的,尤其在基层的,和技术的表面区别首先是得牌儿靓养眼,土了做技术可以,媒体和市场不行
QinQ不能本地交换,可以考虑用三层交换机,终结vlan tag;
TO老韩:被你发现了,呵呵。
TO理客:我是做技术的媒体,你就当我是做技术的吧……
皓矾乃巾帼呀,中国巾帼可以从花木兰有机会替父从军始,如果中国男人能敞开胸怀给女子更多的机会,妇女真的能顶半边天,应该不让北欧。
历史上中国男人从大宋开始一代不如一代,宋代男人吟诗做赋的骚人多,顶天立地的男人少,而女人如李清照梁红玉者强,到南明,男人连妓女都不如了。可见曹雪芹为女子立世传而撰红楼还是有些历史依据的,叹男人无能,恨不是女人
如饥似渴的读完了,受益非浅
好文章,
读完后感觉VN-TAG就是为了管理虚拟机而增加的链路开销,而且还不能在整个网络内使用,有些浪费。如果在整个网络内都能使用VN-TAG来管理虚拟机的流量,可能是一个可能方向
不错,虚拟化的确是数据中心发展的方向,网卡的虚拟化还是第一次听说—
上次和一个牛人聊起来VN-TAG和VEPA之间的区别,他说在经过了几次修改之后,两个标准的差别已经不大,从外面来看,比较明显的差别是VN-TAG在路径选择的时候做了优化会在一条路径发包,而VEPA是每个路径都发包。
不知道各位知道啥新的进展不?
to 皓矾
能说出这么关键点的人还真不多,推荐您和那位专家 好好聊聊天,很多真正了解标准差异的人都太忙了,没时间去争论细节,VN-TAG和VEPA在后期几乎没区别,VEPA的标准在当前时间点没有任何产品可以销售,所以 纯粹是概念,另外我可以告诉大家一点儿,insight view,HP在下一代产品中会选择vn-tag而不是vepa,也就是说HP已经承认vn-tag更具有可实施性
那我通过UCS将palo卡虚拟出多个vNIC,并为每个vNIC建立QoS策略,那么在ESX的vmotion下,我的策略可以迁移吗?这里我没有使用nexus1000v,在ESX上是不是不需要做任何配置?
从现在最新小道消息看,HP离放弃VEPA不远了:
1、HP将卖思科Nexus4k
2、思科802.1Qbh已经提升为802.1br
3、HP考虑卖掉PC等终端业务,准备走IBM高附加值路线
to 皓矾& netcache
比较明显的差别是VN-TAG在路径选择的时候做了优化会在一条路径发包,而VEPA是每个路径都发包。
菜鸟没太看明白这个区别,能不能详细说明一下啊,呵呵。
1.VEPA是每个路径都发包。这里的每个路径是指往每个虚拟机都发包吗?按照个人理解假设虚拟机有自己的MAC地址,那么直接按MAC就可以转发到真正的虚拟机上去了啊,并没有往每个路径都发包啊。
2.VN-TAG在路径选择的时候做了优化会在一条路径发包,这个也没看懂,呵呵。
原来看VMWare和思科的一些做法,都没能贯通理解,看到本文才明白其深刻含义。谢谢作者分享了这么一篇深入浅出的好文。
to 皓矾
牛人说反了吧
拜读!
最近正好讨论HP的刀片,看到那个VC,感觉似乎残缺不全,拜读牛文后,总是有头绪了。
让我了解了最新的技术。感谢。
很不错,受教了
楼上都是搞网络的,我这个搞系统的学习了。
非常感谢作者和大家的讨论。
从操作系统的角度来看,Linux下一直以来使用的虚拟网络设备都是bridge,性能很好,但是特性不够,但是最新的kernel 3.3已经正式加入了Open vSwitch,这可能就是VDS和N1000V的对手。
it is designed to support distribution across multiple physical servers similar to VMware’s vNetwork distributed vswitch or Cisco’s Nexus 1000V
Features
The current stablerelease of Open vSwitch (version 1.4.0) supports the following features:
Visibility into inter-VM communication via NetFlow, sFlow(R), SPAN, RSPAN, and GRE-tunneled mirrors
LACP (IEEE 802.1AX-2008)
Standard 802.1Q VLAN model with trunking
A subset of 802.1ag CCM link monitoring
STP (IEEE 802.1D-1998)
Fine-grained min/max rate QoS
Support for HFSC qdisc
Per VM interface traffic policing
NIC bonding with source-MAC load balancing, active backup, and L4 hashing
OpenFlow protocol support (including many extensions for virtualization)
IPv6 support
Multiple tunneling protocols (Ethernet over GRE, CAPWAP, IPsec, GRE over IPsec)
Remote configuration protocol with local python bindings
Compatibility layer for the Linux bridging code
Kernel and user-space forwarding engine options
Multi-table forwarding pipeline with flow-caching engine
Forwarding layer abstraction to ease porting to new software and hardware platforms
从系统的角度来看,未来的CPU core越来越多,处理能力越来越强,未来需要虚拟化是肯定的,但是虚拟网络的管理并不一定会全交给网络管理员去管,更多的可能需要网络管理员多了解系统的知识,系统管理员多了解网络知识,需要多面人才。
如果在一台物理机上虚拟出一堆虚拟机,虚拟机之间内部的通信有什么理由非要通过物理线路到硬件交换机上绕一圈,不增加物理链路的拥堵,自己内部搞定应该更好吧?而且宿主机上的memory cp可比拥塞的物理链路快多了。
另外Linux下比较重要一个虚拟化LXC目前只支持vepa,没有VN-tag.
to 曹世军,
单从包处理看,mem cpy似乎性能高一些,但从整体解决方案来看这样不可取。个人认为,如果都要服务器内部搞定,要求配置管理是针对服务器的(旁挂网管中心)、vswitch要求是full feature的、虚拟机与OS kernel要是紧耦合的,无论多核之间通信是IPI方式还是消息队列方式,完成一个包交换都要通过多次中断(系统调用),这样看来性能不见得比外部交换高多少,系统吞吐量损失在先,并且增加系统的复杂性和可维护性。
91楼,虚拟机间通信通过硬件交换机的方式做,最大的好处是可以做到物理位置无关性。虚拟机是可能在不同的物理服务器上迁移的,也就是说无法保证两个虚拟机一直是在同一物理服务器上的,这种情况下基于服务器内部消息的通信机制就不可取了
能写得如此清晰,真了不起
好文,学习。。。
4月30日,Broadcom推出BCM56545,支持802.1BR,802.1Qbg时日不多
openflow + open vSwitch 能否解决类似迁移的问题呢;openflow可以动态定制网络。
虚拟化是大忽悠,因为按照目前这么搞下去,必然增加用户的学习成本,迫使用户都当专家。
思科那东西,本质就是给数据包打另一种vlan标签,在服务器和交换机之间跑另一种trunk。只不过这标签是在交换机和虚拟服务器之间,而非交换机和交换机之间。
以我的经验,让服务器管理员正确理解vlan-tag已经很困难了,何况再来一个vn-tag?
一堆虚拟机意味着一堆虚拟mac和一堆虚拟IP,它们跑在一条物理线路上,不是难到无可救药的事情。
我的解决方案很简单:虚拟服务器配一堆物理端口,把每台虚拟机的IP出口绑定到一个物理端口上。这种简单的映射用图形界面即可完成,基本不增加服务器管理员的学习成本。
多几根网线并不增加数据中心的能耗*,占用的空间也可忽略。QOS的问题也迎刃而解了。
至于VLAN的事情,确实没办法,让同一个vlan的服务器虚拟到同一台虚拟服务器上吧。数据中心要是连这么点数量效应都没有,也不要搞服务器虚拟化了。
虚拟化打出的旗号是压缩不必要的资源开销,包括能源、场地等等。
数据中心资源消耗的主要矛盾是服务器能耗和配套的散热,网络设备的能耗和散热从来不是主要矛盾。
虚拟化的边界就到服务器为止,出了服务器,网络是没有必要跟着虚拟化的。
数据处理能力就是要“像水管一样”地使用。客户买一份处理能力,就接一根水管,这样事情最简单。
如果大家的水挤在一根管子里,谁都不放心,害怕自己的水流被别人挤细了,这是把简单的事情做复杂了。
这时服务商如果想让每一个人都满意,就要弄很粗的水管,而很粗的水管是很贵的,包括水管的接口模块和处理设备。
——
*好吧,还是会增加一点,就是物理端口微不足道的耗电量。
kanghu也来这里找答案,惊了一下。
先回答你的问题:不能。1 因为到底什么是OF说法不一。2 动态定制网络就跟飞天一样。技术不能被口号和名字沦陷了。
abel很有见地,不过如果只需要几个以太口,比如10个以下,还是可以考虑的,但如果比较多,可能就不太合适了
我怎么觉得最终还是要把交换机芯片放到服务器内部才是最终解决方案,报文上到交换机再回来只是初步的兼容性坚决方案,最终还会走到这里。之后每个实体机都自带交换芯片,最终通过openflow和外界的交换机,server通信并下发各种规则~
多播,VEPA比VNTAG失败的关键在于多播~~
to abel:
服务器增加的端口成本不低,另外,如果每个服务器都是10个虚拟机,每个都有物理网卡,那么接入层交换机所需要的数目从目前看恐怕要翻个好几倍~ 成本增加是其次,布线和机柜摆放等这些都比较复杂需要全盘考虑
思科的兄弟更新一个此文档吧。EVB标准也发生了不少变化,802.1QBG是dead了还是只是换个名字?anyway 现在是802.1BR
网络虚拟化的说法也很多,VR也不能不说人家是网络虚拟化。
802.1Qbg也还是有应用场景的。也不能全说成大忽悠吧。
@kpang,应该是802.Qbh死掉了,Cisco改头换面另外立了802.1BR,现在EVB就是802.1Qbg,IBM也开始支持了,服务器里部署5000v,ToR交换机有Blade系列都支持802.1Qbg,还有HP/3Com的5900
回 100楼理客和103楼瀚云:
两位都提到了端口数过多的问题.答案是用多模光纤.
1\接入密度及布线
我用过Dell的刀片,机框10U高,16blade,一个机柜也就最多放4台.再多的话没有物理空间,而且散热\电力\承重都是问题.
按照这个密度计算,每机柜64个千兆口,布线当然是挑战,铜线不可取,解决方案只能是光纤.
2\接入层交换机数量及选型
至于接入层交换机的问题,我们按照每机柜64千兆口等于64G来计算.如果每列8个机柜配一个列头柜,那么每列满负载是512G,这种接入能力,什么样的接入交换机能搞定?
以思科为例,用48口的3750G?抱歉,3750最多只能堆叠9台,估计应付512G的流量是个问题.另外,我似乎没查到思科有48千兆光口的3750G.
直接上45或者65这个级别的吧.
服务器一旦虚拟化,这个时候接入层交换机的瓶颈在于转发能力\背板带宽.不管是VN-tag还是什么其他技术,都无法改变这一事实.
3\服务器配交换板卡的成本
服务器的交换板卡,Dell的刀片能做到,已经有产品,只不过板子上电口多光口少.我想技术和成本都不是问题,而是机房布线的现实环境导致的商业需求:目前机房布线,在服务器附近,还是铜缆多.
继续抛砖,欢迎批评指教.
最后再次强调:
服务器一旦虚拟化,这个时候接入层交换机的瓶颈在于转发能力\背板带宽.不管是VN-tag还是什么其他技术,都无法改变这一事实.
如瀚云所言,综合成本应该不低,比如一个刀片,本来一个10GE口就够了,但如果基于物理端口做VM的话,比如做20个VM,需要20个GE或者10GE,并且对端交换机也需要这么多的端口对应,对整个DC,意味整体增加了20倍的端口,简单算,这意味着可能要10几倍的成本,这是不可行的。而实际上这么多的端口,流量是及其不饱和的,只是为了简化VM的管理,这个VM简化管理降低的TCO可能远比不上十几倍增加的网络成本。
多模光纤和端口密度没有直接关系
回107楼理客:不是十几倍增加的网络成本,我估算只有5%。
1、多模光纤只解决布线密度的问题,确实与端口密度无关。每机柜64条铜线还是很恐怖的,但是光纤布线就完全没有压力。
2、我想还是要估算一下流量:不妨按你的数据计算,一个机框一个10GE口,一个柜4个框,一列8个柜,共320G,我看不到有什么接入层交换机能担此重任,除非每个机柜顶上放一台。
我想我强调的那段可能叙述角度有问题,好吧,我从另一个角度说一遍:
服务器虚拟化,本质是服务器密度增加,必然对应接入层网络流量增加。能够应付320G流量的接入层交换机,已经不是传统意义上的接入层交换机了。
试问哪种接入交换机的下联端口是10GE?上联又要多少G呢?这种交换机又要花多少钱?
3、也许虚拟化后,接入层交换机所承受的流量并没有320G,只要32G就够了(每机柜4G的流量,每排/每列8个机柜)。
没错,是有这种可能。我们不需要很贵的接入层交换机,只需要32G背板带宽的接入层交换机搭配8个10GE的下联端口。
我怎么看都觉得这种搭配有点搞笑,真的。我说不出为什么,直觉上想笑。难道是传说中的C3750T?
4、反过来驳您的“网络成本十几倍”论点。
端口的成本其实并不高,因为10个GE口的成本并非1个10GE口的10倍。所以您说的10几倍的端口成本我并不敢苟同,可能有5、6倍,但是10几倍不可能。没见过10GE口和GE口一个价的。
端口成本5、6倍不意味着网络成本要增加十几倍。不论是按照320G还是32G算,都不可能。
6、跳出井底。
数据中心虚拟化意味着高密度的数据处理。
6.1网络如果不跟着虚拟化,其布线密度和端口密度必然提高。不过这一块的成本并不高,整个数据中心,网络设备的价格最便宜;网络设备中,接入交换机最便宜的。就算我那个方案要贵个5、6倍,实际上并不多花多少钱,我估算数据中心的网络设备总成本增加5%而已。
6.2网络如果跟着虚拟化,问题:
第一,服务器端要与网络接入端(交换机)配合。思科并没有两头儿都占全,这事儿牵扯到利益,还很难说能否搞得成。
第二,即便搞得成,经济效益怎么算?除非思科把C3750T(笑)卖得跟C3750G一个价钱,否则客户宁可用现有的接入交换机搭配一堆千兆电口和铜缆[每列32G流量]。
6.3总之,用户会算大帐,一旦上了思科的贼船,到时候被套牢不能招标是很痛苦的。如果思科不玩,这个游戏没戏;而如果思科要玩,别的网络厂商基本没戏。思科不是傻子,费了半天劲让友商摘果子。
为了这5%,咱定向采购不招标了?
我觉得折中的办法才是出路:
网络不变,服务器虚拟化。中间的结合靠PNAT。
轻载的话,一台服务器虚拟10几个服务器,但是IP和物理线路只有一个。重载可以多几个。
关键是用PNAT把实际IP和PORT映射到不同的虚拟机的虚拟IP和提供服务的PORT上去。
反正服务器为了提供服务而开放的端口是有限的,静态的PNAT是个好办法。强调:静态的PNAT。
只是业务部署上要麻烦一些。
……
想了想还是不妥,搞服务器的要变成NAT专家,常用端口不知道要映射到哪里,很不爽。
我们公司目前就在做48*10G的接入,4*40G的上联数据中心接入交换机了.采用5684X的方案,我们还是只能算国内的小厂,其余大厂早就有类似的交换机面世了吧。
回瀚云:
感谢提示,仔细找了找,发现思科有Nexus 5000,华为有CloudEngine 6800.思科的上联端口没查到,下联10G.华为的规格跟贵公司一样.
之前是我坐井观天了哈…
万兆接入比以前的千兆接入交换机不知道贵多少,IT厂商确实能忽悠,一个”数据中心虚拟化”的旗号,产品售价马上就上来了.再次感叹…
疑问:
思科的万兆接入是vn-link技术,不知道是不是就是vn-tag?是否公有标准?
华为有个TRILL标准.这个应该是公有的,但是应该是二层多路径技术,与虚拟化没有关系吧.华为说自己的虚拟化方案是nCenter,通过高速radius部署什么的,没看明白.
求各路牛人详解vn-link与nCenter.
附:我找到的资料
思科http://www.cisco.com/web/CN/products/products_netsol/switches/products/cn1000v/cisco_nexus_1000v_overview_1.html
华为http://enterprise.huawei.com/cn/products/network/switch/data-center-switch/hw-132126.htm
瀚云什么公司的?有产品链接吗?学习一下
求各路牛人详解vn-link与nCenter.
其实,简单问题复杂化一向是网络工程师喜欢干的事情
对小规模网络,原来怎么用vlan,现在还怎么用
,只不过原先是在access switch的
untag端口加,现在是vswitch加。然后host和switch之间运行普通的trunk协议即可,该怎么玩还怎么玩。vlan数不够?对大多数中小企业这句话是个笑话。顺便补充下,目前主流网卡都支持tag/untag卸载
大规模网络,包括IDC在内,二层是行不通的,802.1AQ/Trill大二层已经证明是个笑话,不然Vmware不会再和cisco搞vxlan,微软也凑热闹弄个nvgre,再加上OVS支持的那几个tunnel方式,核心思想无非一点:L2 over physical L3仿真实现flat L2,而不是大的physical L2,这样把复杂性全部推给了end point。
下面讨论性能、管理等问题
91楼提到了一些,可惜没有说透,基本上反驳你观点的,也是cisco为代表的网络厂商常规宣传手段。其实,这里面有很大的认识误区和故意误导。
1)先看性能:毫无疑问,软switch对CPU有性能损耗,比如sriov通出去硬交换回来。但问题是,损耗到底有多少?如果少到一定程度,比如不到10%,那么综合性价比完全值得了。我看所有的评测数据,都是那vswitch和真正的switch比,然后给vswitch加个10G的64B,然后看CPU消耗。请问,您是拿它在做路由器吗?真实的app环境,大部分报文不是转发的,而是链路和app之间的IO,以及app和app之间。但你的app占用cpu到90%时,网络还不一定能发出几个G的流量,我们看到的所有网卡占用率高的场景全是大包,pps非常小,这时候vswitch所需消耗非常之低。综合意思是,除非你那它做路由器,否则一般意义的app根本无法带给vswitch任何流量冲击压力,因为它自己就发不出来这个流量,应用处理1G流量的资源远远超过网络收发的资源
回 根本不相干: 你是说,按照目前的技术水平,即便服务器虚拟化,服务器本身处理能力仍然有瓶颈,不会产生高密度的网络流量,所以网络系统尚不需要能应付高流量密度的接入层…?
to abel
是的,但准确一点是这样说:
case1: 服务器没法发出高流量(如交互消息类/事务交易类应用)
case2: 服务器虽能发出高流量(比如storage/media), 但都是大包, pps反而更少
vswitch真正怕的是高流量小包, 但该场景主要出现在流量测试仪测路由器性能:)
vswitch的性能, 是伪命题
下回有时间详细谈谈管理的伪命题: 统一网管
Cisco的最新玩法CSR-1000v
http://www.cisco.com/en/US/products/ps12559/index.html
回 根本不想干: 期待好文.
继续求各路牛人详解vn-link与nCenter.
现在看来数据中心虚拟化的网络接入层还是混战期.
对数据中心这块不是很了解,但我猜测,VEPA是不是很类似MEF26之类的东西,尤其是那个hairpin。总体看,需求和城域以太网惊人的相似啊。VN-Tag我觉得没啥必要,QinQ就很好了,这不就有点类似TR101的架构下面,每个CPE都有一个C VLAN?甚至,MPLS技术是不是也能很好的解决这一问题?当然用MPLS的话,会有不少的改造
楼上,QinQ是用在三层的,MPLS也是3层的,数据中心都搞2层,搞不定的
楼上,谁说QinQ和MPLS都是在三层的?那不过是一种应用而已
其一样可以用到二层,说到QinQ,MEF就是这么用的,至于MPLS,中移动的PTN也是这么用的
不了解是如何做的,介绍下?
静态配置管道+L2VPN
QinQ的用法也类似,一个以太网业务分配一个SVLAN,内部是VSI转发
想问下你们用的是谁家的交换机
楼上的,我们没有数据中心,也不做这块
相反,我们是做传输的,有点类比罢了
1.增强vswitch的功能,这样会在家物理服务器的负担,不光是内存和CPU,并且如果在高负载的情况下延迟可能比通过物理switch转发还要高
2.其实QinQ确实是能解决VN-TAG的问题,但是我觉得思科提出VN-TAG的目的是为了解决虚拟机的标示问题,而不单单仅是为了转发,毕竟VN-TAG是唯一的。
3.QinQ和VN-TAG都增加报文长度,这在高速交换的数据中心网络是否能接受,会不会造成更多的分片传输?
4.VN-TAG结合openflow 会不会有市场,一个用户标示flow,一个用于console
小弟不才各位大哥勿喷
intel,以后是否会把vswitch功能集成在cpu里?
to 127楼
感觉无论什么方法,增加报文长度是无法避免的
根本不相干 于 2012-06-29 8:11 上午
其实,简单问题复杂化一向是网络工程师喜欢干的事情
对小规模网络,原来怎么用vlan,现在还怎么用
,只不过原先是在access switch的
untag端口加,现在是vswitch加。然后host和switch之间运行普通的trunk协议即可,该怎么玩还怎么玩。vlan数不够?对大多数中小企业这句话是个笑话。顺便补充下,目前主流网卡都支持tag/untag卸载
大规模网络,包括IDC在内,二层是行不通的,802.1AQ/Trill大二层已经证明是个笑话,不然Vmware不会再和cisco搞vxlan,微软也凑热闹弄个nvgre,再加上OVS支持的那几个tunnel方式,核心思想无非一点:L2 over physical L3仿真实现flat L2,而不是大的physical L2,这样把复杂性全部推给了end point。
下面讨论性能、管理等问题
大二层变成笑话?
好文章,我有问题,期待作者给我分析下:Access Layer虚拟化是为了解决物理交换机无法区分虚拟机的问题。Overlay是为了decouple VM IP address from physcial IP。个人觉得两种并不是冲突的技术,但却无法理解在IaaS环境下是如何共存的。我觉得overlay应该是在VN-TAG打完之后再次封装(比如NVGRE),如此一来看来,边缘交换机如何check VN-TAG?VN-TAG已经被NVGRE封装起来了。
请赐教!
CISCO的一套nexus看出来了CISCO的能力了,整体架构能力国内的厂商还是很难触及啊。