




现代 CPU 中的 Cache 结构
作者 comcat | 2011-04-14 20:07 | 类型 专题分析 | 26条用户评论 »
|
0.缘起 受首席启发,补充点 cache 背景。再乱弹一下 Page Coloring
1. 概述 Cache 是用来对内存数据的缓存。CPU 要访问的数据在Cache中有缓存,称为“命中” (Hit),反之则称为“缺失” (Miss) CPU 访问它的速度介于寄存器与内存之间(数量级的差别)。实现 Cache 的花费介于寄存器与内存之间。 现在 CPU 的 Cache 又被细分了几层,常见的有 L1 Cache, L2 Cache, L3 Cache,其读写延迟依次增加,实现的成 现代系统采用从 Register —> L1 Cache —> L2 Cache —> L3 Cache —> Memory —> Mass storage 引入 Cache 的理论基础是程序局部性原理,包括时间局部性和空间局部性。即最近被CPU访问的数据,短期内 CPU
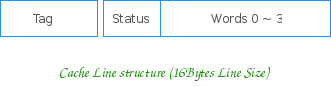
2. 结构 2.1 Cache 行 Cache 以行大小(Line size)为单位分成若干个行。行 (Line) 是 Cache 的数据存储和管理单元。一个典型的 Cache 行
其由 Tag 域、Status 域和数据域组成, Tag 域存放该行数据对应地址的高位。CPU 在索引后,用相应地址与组内所有行的 Tag 相比较,以之区分具体的行。 数据域能容纳的字节数是为行大小 (Line Size),其为 Cache 与内存之间数据交换的单位。 Status 域则为一些控制位信息(如Valid, Lock 以及Parity check 位等等),不同的Cache 类型,不同的 Cache 实
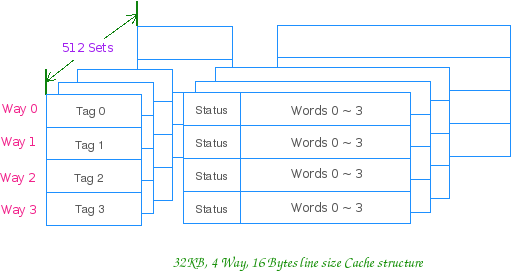
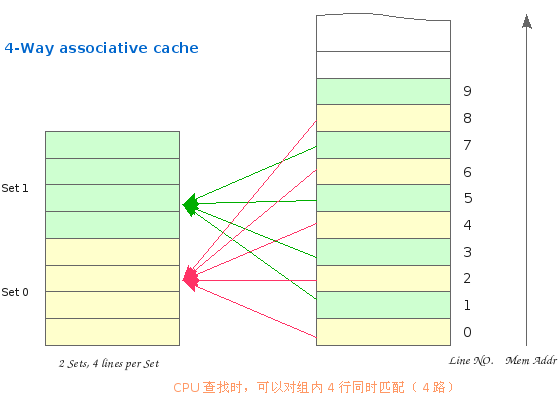
2.2 相联方式 2.2.1 组相联 通俗地讲就是 Cache 行的分组,比如 4 路组相联,就是 4 行一组,4 行一组。。。。。。 比如 32KB 的 4 路组相联 Cache,行大小为 16Bytes 的话,他就有 32*1024/(16 * 4)= 512 组 CPU 访问组相联 Cache 时,就先用地址索引到组,然后组内同时匹配 Tag,进行路选。一个典型的组相联 Cache
内存逻辑上也按 Cache 行大小分块,按地址由低向高,依次编号。因此 Cache 与内存就会有个映射问题,如:第四 组相联的 Cache 是先索引组,其规则为: Cache 组号 = 内存行号 % Cache 总组数
对于上图这个只有 2 个组的 Cache,假设其行大小为 16Bytes,这个组索引的过程,实际上就是用地址的第 5 位 尔后,内存行可以映射到该组内的任意行上。缓存数据时,有空占空,如组内所有行被占用,则使用替换算法(LRU,
2.2.2 直接相联 略. 或可参阅 The MIPS Cache Architecture 的相关部分
2.2.3 全相联 略. 或可参阅 The MIPS Cache Architecture 的相关部分
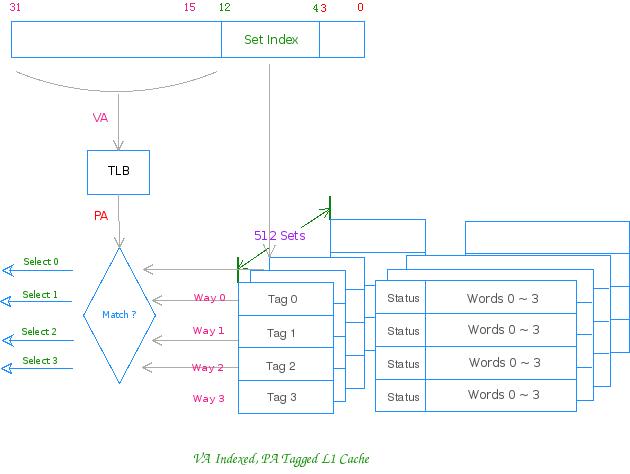
3. 组相联工作方式 K 路组相联 Cache 的通常工作方式是:先用物理地址或虚拟地址索引组,然后用物理地址 (PA) 或虚拟地址 (VA) 同 以上述 32KB ,4 路组相联,行大小为 16Bytes 的 Cache 为例,正常工作时其对地址的划分如下所示:
Addr[12:4] 用来索引组,9 bit 可索引 512 组 VA 索引,PA 匹配 Cache 之工作方式图:
4. 乱弹 在 OS 层面上,我们还有分页的概念,物理内存被分为若干个 Page Frame,其大小以 4KB 始。对 4KB 页大小的系 若系统采用 4KB 的 PAGE_SIZE,则第一个 Page Frame 总是会被索引到 cache 的前 256 组,第二个 Page Frame 通俗地说,就是让 OS 在分配页面的时候,让红色的页和黑色的页一样多。这个应该就是 Page Coloring,不知道对不 用颜色位更形式化地说: 作为一个理解的便利,请各位看官看看地址的组索引位和行内索引位所表示的空间大小是多少? 2^13 = 8KB,这个 因此拿到一个 Cache 在判断系统的 Color 位时,可以借助一个 Way Array 的概念,一路 Cache 的大小就是地址用 当 Way_Size > PAGE_SIZE 时,即 log2(Way_Size) > log2(PAGE_SIZE), 则用于索引一路 Cache 的地址低位较 若 log2(Way_Size) <= log2(PAGE_SIZE),则数据可以很均衡地进入 Cache 没有谈论的必要的,但可以作为另外一
5. 摘要 Way_Size = Cache_Size / Ways 当 log2(Way_Size) > log2(PAGE_SIZE) 时,系统具有“颜色位”,其影响为: 1. 用 VA 索引,PA 匹配的 Cache,会存在 Cache alias 问题 个人觉得在可能的前提下,提高 PAGE SIZE 比较靠谱,大页的影响,除了在 Cache 上外,在 RISC 的 CPU 上,还
| |
 (12个打分, 平均:5.00 / 5) (12个打分, 平均:5.00 / 5) |

雁过留声
“现代 CPU 中的 Cache 结构”有26个回复
几个小问题需要注意:
1. Page Coloring的前提是要Physicall Indexed。否则,OS的allocate_page就失去了影响cache的基础。 brk或者vm_alloc(kmalloc或者vmalloc)在虚拟地址上,一定要是连续的。例如stack或者heap,是不能出现hole的。
2. 你的图用了一个VA indexed。
3. 意思都谈到了。很不错的文章。把SET/WAY都谈清楚了, 就好办了。下个星期我来用大白话解释coloring。我觉得如果让弟兄们看不明白,就说明我的功力不够。
Color对数据结构的设计要求很高,应用程序需要管理自己的数据结构,单靠malloc/free是不行的,要有自己的内存管理。
1.除了MIPS坚持用virtual index physical tag,别人家好像都是PIPT。加上那个delay slot。一坚持就是20多年,真是老顽固。估计好些东西被john写进教科书以后自己也不好意思再拿掉了。
2.除了L1,其他必然是PIPT
3.cache color的是L2及后面东东,屁大点的L1 color一下软件也不要活了。
AMD, virtual index phy tag L1 cache
to 2
我感觉你说的那个是我们经常做的“人肉color”
OS做的还是希望对application透明的机器color
不然你软件写出来,从INTEL的CPU换到AMD上,估计就有一群人要跳楼了
及时雨
昨天我正好在找CACHE的基础知识
期待首席深入浅出的Page Coloring
请问一个问题。CPU在什么时候会去访问CACHE.是访问memory的所有地址都会吗?
cache attribute is controlled in MMU
这都是虚的,翘首首席的 Page Coloring
坚持用virtual index 多少有些性能上的考虑,毕竟索引时不用先走一下 TLB
在MIPS教科书里5级流水线的情况,类似VIPT, delay slot等概念普遍容易被接受
我了解的情况VIPT用的很少,delay slot除了mips要顽固的支持legacy code,其他处理器早把这玩意扔垃圾堆了
arm11 vipt,應該還有不少arm11在用,不過是L1的了
還有,首席,virtual index也有page coloring…
mips cache alias也是个很绕的东东。
以74kc 32KB L1 Cache为例:
Cache Line:32B (bit[4:0])
Associativity: 4-way
Sets: 256 (bit[12:5])
way_size = Line-32B * 256-Sets = 8KB
假设tlb page size:4KB,并有下面两个地址映射关系:
va0 0x0000_0020 -> pa 0x0000_0020,
va1 0x0000_1020 -> pa 0x0000_0020
由于是VIPT:
va0 0x0000_0020 index到set_num:1
va1 0x0000_1020 index到set_num:129
再假设初始化cache全部无效,
a) 访问va0 0x0000_0020, cache miss pa 0x0000_0020(对应的cache line)被加载到set_num 1
b) 访问va1 0x0000_1020, cache miss pa 0x0000_0020(对应的cache line)被加载到set_num 129
c) 结果pa 0x0000_0020的数据同时存在在set_num 1和set_num 129中,并为两个不同虚拟地址va0/va1访问。
实际上访问va1 0x0000_1020的时候,它对应的pa 0x0000_0020的内容已经在set_num 1中了。
但由于是virtual index,va1 0x0000_1020去匹配set_num 129,结果却是cache miss。
它没法知道它的pa data已经在set_num 1中,因为它不等tlb结果出来就先干上了。
悲剧就这样静悄悄的发生了。
VIPT为了缩短Cache访问时间,却引入了cache alias问题。
如果将MIPS比作汽车,车厂已经告诉你:等红绿灯的时候、这车会偷步,请小心驾驶。
书中写到:
Many MIPS CPUs do not have hardware to detect or avoid these cache aliases and leave them as
a problem to be worked around by the OS’s memory manager。
还有书中写到:
Cache aliases crept into the MIPS world by accident.
从硬件角度来看这能不能算VIPT设计的一个bug呢,哈。
期待首席的page coloring x篇出炉!
看的我好累。。。
to 13:
Many MIPS CPUs do not have hardware to detect or avoid these cache aliases, at least 10 years ago
有个弱智的困惑问首席和kevin。VA index实际上是使用了VA-PA中不改变的部分。。。那这样的话,VI和PI在表现上没有区别啊。。
甚至可以认为VIPT是PIPT的一个优化实现。
请释惑。。@_@
In general,
L1: VIPT
L2,L3: PIPT
Why?
VIPT is fast. Cache Controller don’t have to WAIT for MMU, say, TLB look up, and can directly look up the cache SET. The MMU/TLB look up circle is doing in parallel.
However, VIPT’s cost is to handle the Cache Aliasing, and need logic. So, VIPT is NOT suitable to large cache, say, L2, L3…
For PIPT, before the cache logic can look up an index/set, it has to wait for the results coming back from MMU. Ohterwise, you don’t have the PHYSICAL Indexed’s value yet.
嗯。这个明白。但是楼主画的这个case里面,index是在末尾12位内。如果4K页面大小以上的情况,VIPT和PIPT在最终结果上没有区别,甚至可以不需要别名检测了吧。
因为offset从来不会在映射过程中改变。
与专门做这个东东的家伙聊过,CPU的pipeline是一个整体,用VIPT还是PIPT是pipeline的架构决定的。
用VIPT,省掉的仅仅是查index的那一个cycle,在MMU给出物理地址之前,数据仍旧是出不来的。所以这是个伪并行。然而MMU非常可能因为TLB miss等原因导致PA过很久才能出来,这样会导致cache的数据延时不确定。让cache subsystem和pipeline变得更加复杂。
IBM的PPC和sun的usparc都是PIPT,性能跟MIPS比就不用多说了。
首席帖个VHDL或Verilog源码吧,看易行难,理论跟实践差别很大。
嗯。看来我没有理解错。话说速度上,VIPT和PIPT那一丁点时间的差异已经不是决定性因素。TLB数量和cache数量等造成missing rate的才是关键。
类似于freescale的powerpc软MMU的,跑上大程序就神马都是浮云了。
当 cache 的路数达到8路以上,os这种coloring的存在性就不重要了,而现在的cache路数已经有16或者更多。
一级的都有8路了,刚才说16路指的是三级cache
to chandler:
请问这个怎么理解:
>>但由于是virtual index,va1 0×0000_1020去匹配set_num 129,结果却是cache miss。
是不是说在pt中,pa 0x0000_0020只可能在cache set中出现一次?即不可能set_num 1 和 set_num 129都是0x0000_0020?
如果是,那set_num 129里面是什么呢?空的?
匹配cache miss后又会怎么样呢?
>>它没法知道它的pa data已经在set_num 1中,因为它不等tlb结果出来就先干上了。
这句话完全不理解。。。。
我的邮箱,linux.swang@gmail.com
哪位好心人给解释一下。。。
看了个各位的帖子,受益匪浅。我想请问一下?对于VIVT/VIPT/PIPT/PIVT,都有哪些CPU呢?
比如mips用的是VIPT?X86呢?
关于陈首席解说的coloring,在这两种平台上,意义大吗?
还有就是同一款CPU,其L1/L2/L3 cache,match模式是一致的吗?比如都是VIPT或 PIPT的