




OpenFlow技术及应用模式发展分析
作者 老韩 | 2011-05-21 10:34 | 类型 互联网, 弯曲推荐, 新兴技术 | 88条用户评论 »
|
近来OpenFlow的话题比较多,INFOCOM上清华土著又给上了一课,就找了些资料学习了一下,顺带编写了这篇科普文章。感谢许多朋友在撰写过程中的帮助和启发,另外yeasy兄发在弯曲的系列文章也非常有价值。很喜欢LiveSec团队的开放心态,希望能帮他们的产品和理念做尽量广泛的传播。 原文发于《计算机世界》。顺带说下,最近要做NFGW的选题了,感兴趣的朋友来找我吧,Email和GTalk是hanxu0514 aT gmail dOt com。
4月10日至15日,第30届IEEE计算机通信国际大会 (INFOCOM 2011)在上海国际会议中心隆重举行。本次会议吸引了国内外1000多名计算机和通信领域的专家、学者和企业的科研人员到场,重点围绕云计算、网络安全、数据中心网络、移动互联网、物联网等一系列研究领域的前沿问题进行了深入的探讨。在倍受关注的现场展示环节中(Live Demo),来自清华大学信息技术研究院网络安全实验室的师生们展示了基于OpenFlow的网络安全管理系统LiveSec,引起了与会者的普遍关注。该系统的成功运行,是国内通信领域的研发团队对前沿技术跟踪、创新工作的完美诠释,在科研成果转化为可用产品的道路上占据了先机。 OpenFlow扬帆起航 OpenFlow技术最早由斯坦福大学提出,旨在基于现有TCP/IP技术条件,以创新的网络互联理念解决当前网络面对新业务产生的种种瓶颈,已被享有声望的《麻省理工科技评论》杂志评为十大未来技术。它的核心思想很简单,就是将原本完全由交换机/路由器控制的数据包转发过程,转化为由OpenFlow交换机(OpenFlow Switch)和控制服务器(Controller)分别完成的独立过程。转变背后进行的实际上是控制权的更迭:传统网络中数据包的流向是人为指定的,虽然交换机、路由器拥有控制权,却没有数据流的概念,只进行数据包级别的交换;而在OpenFlow网络中,统一的控制服务器取代路由,决定了所有数据包在网络中传输路径。OpenFlow交换机会在本地维护一个与转发表不同的流表(Flow Table),如果要转发的数据包在流表中有对应项,则直接进行快速转发;若流表中没有此项,数据包就会被发送到控制服务器进行传输路径的确认,再根据下发结果进行转发。 OpenFlow网络的这个处理流程,有点类似于状态检测防火墙中的快速路径与慢速路径的处理,只不过转发与控制层面在物理上完全分离。这也意味着,OpenFlow网络中的设备能够分布部署、集中管控,使网络变为软件可定义的形态。在OpenFlow网络中部署一种新的路由协议或安全算法,往往仅需要在控制服务器上撰写数百行代码。加州大学伯克利分校的Scott Shenker教授对此有着很到位的评价:“OpenFlow并不能让你做你以前在网络上不能做的一切事情,但它提供了一个可编程的接口,让你决定如何路由数据包、如何实现负载均衡或是如何进行访问控制。因此,它的这种通用性确实会促进发展。” 在得到学术界的普遍认可后,工业界也开始对这项新技术表达出浓厚的兴趣。OpenFlow已经在美国斯坦福大学、Internet2、日本的JGN2plus等多个科研机构中得到部署,网络设备生产商思科、惠普、Juniper、NEC等巨头也纷纷推出了支持OpenFlow的有线和无线交换设备,而谷歌、思杰等网络应用和业务厂商则已将OpenFlow技术用于其不同的产品中。就在半个月前,以OpenFlow为产品核心设计理念的初创企业Big Switch Networks成功完成了总额1375万美元的第一轮融资,标志着资本市场对这项新技术及其发展前景的充分认可。目前,OpenFlow的推广组织开放网络基金会(Open Networking Foundation)的成员基本涵盖了所有网络及互联网领域的巨头。 好用才是硬道理 使用新技术的代价往往十分高昂,好在OpenFlow具有足够的开放性,给在传统网络中的融合实现带来可能。清华大学信息技术研究院网络安全实验室在本届INFOCOM大会上现场展示的部署在清华大学信息楼内的LiveSec网络安全系统,就是一个非常好的范本。该系统在传统的以太网之上,通过无线接入技术和虚拟化技术引入了基于OpenFlow协议的控制层,显著降低了构建成本。
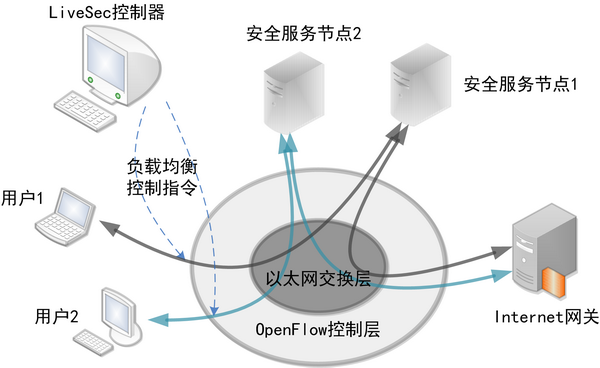
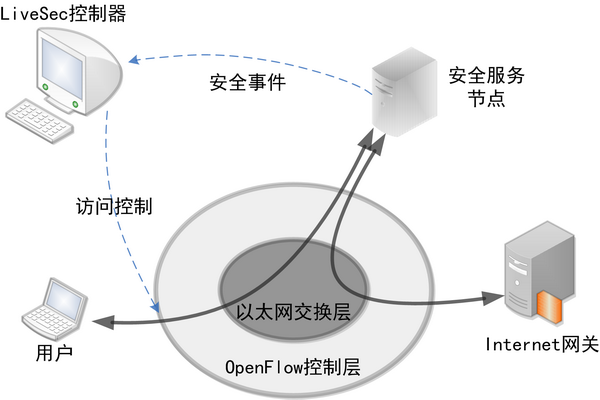
LiveSec网络安全系统包含三层架构:
基于上述架构,LiveSec相对传统的安全部署模型具有多重优势。首先,该系统解决了安全设备的可扩展问题。通过全局细粒度的负载均衡,LiveSec支持安全设备在网络的任意位置进行增量式部署。新部署的节点会按照OpenFlow协议自行入网,并自动将控制权交由LiveSec控制器。所有的用户和服务节点均可在LiveSec网络内动态迁移,包括无线接入和虚拟机的无缝迁移。记者在展示现场尝试进行了基于虚拟机的服务节点动态加入网络的实验,当具有安全检测能力的虚拟机加入网络中时,LiveSec的可视化界面会显示出该虚拟机在网络中的拓扑及其具备的业务能力(如杀毒功能,协议识别功能等)。LiveSec控制器会依据新增节点的处理能力将需要安全处理的网络流量均衡到新的节点上,从可视化界面中也可以看到新增节点引起的链路流量变化。
传统网络中,安全设备一般被部署在边缘,对进出流量进行访问控制。这种方式虽然成熟有效,对内网中的安全问题却无能为力。LiveSec创新的交互式访问控制特性则能很好地解决这一难题,由于系统提供了安全节点到控制器的信息交换通路,并针对安全事件设计了一套信息交换协议,LiveSec可以根据安全节点传来的安全事件,在用户接入层实施访问控制。这意味着,该系统做到了全网的点到点安全控制,任何攻击流量在不离开接入交换机的情况下就被扼杀在萌芽状态,内网安全的顽疾可以从根本上得到解决。
在OpenFlow网络中,控制服务器管控着所有的数据流,又能实时感知其他节点的状态,为可视化提供了足够的基础。记者在展示中看到,LiveSec结合OpenFlow协议以及应用层业务识别服务节点,将网络中所有的拓扑、流量、应用、安全变化都按照统一格式写入中央数据库,并在动态界面中实现了包括当前状态及历史事件回放在内的全网业务可视化。当使用无线设备的用户通过OpenFlow无线路由器接入后,立即会显示在系统的可视化界面中。该用户上网所涉及的应用层协议,也会实时显示在用户图标一侧。当用户访问不良网站或者进行攻击时,图标上会出现红色警示,LiveSec也会依据安全策略在用户接入端实时阻止用户的部分或所有流量。历史回放功能也相当实用,可以回放特定时间段内LiveSec的所有事件,攻击发起者包括地理位置在内的所有信息均可以通过数据库查找获取。 图4. 在清华大学信息楼部署的LiveSec系统 商业模式定成败 虽然OpenFlow网络从根本上解决了传统网络存在的很多问题,却也因标准化过程刚刚起步,缺乏大众化的、实用的落地方案,至今仍然多被用于各类实验性质的网络。在其发展的道路上,势必还要经历扩大用户规模和商业模式创新两大阶段。而纵观近年来IT行业巨头们的发展情况,缔造一个成功的商业模式,其重要性显然远远超过了技术创新。
未来的数据中心网络越来越趋向于由虚拟机和服务器群所组成,数据中心的交换架构则趋向扁平,使用高性能交换机群组或clos 网络甚至可以支持百万个节点的无阻塞互联。在这种情况下,网络服务质量及高可用性成为用户最为关心的问题。以LiveSec为代表的基于OpenFlow的网络操作系统支持网络设备的分布式部署,有效避免了单点失效问题。控制服务器的分布式部署,则可以利用分布式哈希技术同步全网拓扑和策略。当网络出现局部故障时,系统可以利用OpenFlow协议迅速构建全新的互联拓扑,甚至可以为不同的业务和应用分别构建不同的拓扑,以满足安全和服务质量的需求。这又是新的商业机会,试想一下,在OpenFlow网络的支持下,IaaS提供商可以为用户交付一个独一无二的网络,用户甚至可以自行设定数据流在本网内的路径和安全策略,而不仅仅是几个虚拟设备的控制权。 从系统实现模式的角度看,LiveSec的模式是构建网络操作系统(基于开源项目Nox),这个发展方向已经被许多业内人士所认同。不管对象是桌面还是网络,操作系统存在的根本意义都是管理设备和提供编程接口。众所周知,想发挥一块高性能显卡的处理能力,必须先安装该硬件的驱动。基于OpenFlow的网络操作系统也是如此,仍以LiveSec为例,所有OpenFlow交换设备和安全服务节点都可看作网络系统中的硬件设备,安全业务的实现则通过服务节点上的软件完成。当新的服务节点加入网络时,LiveSec控制器首先要知道这个节点能处理什么业务,以及如何与设备建立通信机制,才能让安全处理的执行者和决策者有效地互动起来。出于商业层面的考虑,这种机制的建立往往由服务提供者主动告知控制器,需要一个与电脑安装硬件驱动十分相似的过程。对网络管理者来说,这个步骤简化了部署及使用难度;而对设备制造商而言,这种方式也有利于将现有针对传统网络的产品快速移植到OpenFlow网络中。 受当前流行的运营模式影响,基于OpenFlow的网络操作系统也在加入更多的应用发行元素。当用户在控制台中添加服务如同在App Store获取应用般便捷时,OpenFlow网络的建设必然会步入高速发展阶段。实际上,这种发行模式与当前许多云安全服务的商务模式是可以无缝对接的,为云安全的落地提供了绝佳的渠道。以抗DDoS需求为例,在用户购买对象大量地由专用设备转向清洗服务的今天,供应商可以通过系统内置的发行体系为用户提供自助服务,然后按次数或处理能力收取费用;用户完全不必考虑现实中令人头疼的部署问题,只需通过“软件商店”下载安装相应服务,就能为OpenFlow网络添加抗DDoS的能力。
| |
  (8个打分, 平均:4.38 / 5) (8个打分, 平均:4.38 / 5) |




雁过留声
“OpenFlow技术及应用模式发展分析”有88个回复
我一直很好奇OpenFlow倒底有多大的生命力?还是学术界没事找事骗funding的又一个fad。
Internet设计的初衷是独立转发,以保证局部故障不会中断报文转发。OpenFlow可以说是对此设计初衷的背叛。
OpenFlow确实能降低成本,不仅仅节点的控制平面不需要fancy的功能,数据平面也简化了,比如甚至不需要支持longest match,Hash table足矣。
Flow-based forwarding也不是新概念,比如Riverstone早就有过flow-based router。当然,那是单机版的。
“学术界没事找事骗funding的又一个fad。”
你自己已经说的很清楚了。
OpenFlow在可预见的未来,看不到很大前途。
1、从业界技术看,这个idea本身正如mpc8240所说,并不新鲜,从2000年国内电信的IPTN,到2005年BT北电的PBB,以及目前还算热中的IMS如TISPAN等,都没有成功,可见如果不是open flow里出了apple jobs,openflow就不可能大乘
2、从产业链看,以思科为首的传统路由交换厂商没有任何理由支持这个技术,因为这个技术本身就是要打破传统路由交换的封闭性,把业务和平台分离,这明显是在挖传统路由交换厂商的墙角,在利益冲突面前,他们怎么可能真心支持呢?他们的态度只是为了学术面子的态度,里子根本不会支持的,拉他们过来,只是充门面,作势作态而已。
3、这个技术的两个核心,首先是open,然后是flow,flow是假,open是真,flow到路由就是IPTN,flow到MAC就是PBB,flow到N元组就是IMS TISPAN。在运营商,可以说10年内没戏,在企业网,可能性略高,但不要忘了,企业网和运营商用的路由交换设备大体是相同的,很少是单独为企业开发的,所以希望也不大。
4、openflow的硬件核心在千万级以上的流表的硬件芯片成本,要研究就研究这个技术,并且这个技术不仅用在openflow,可以用在所有基于流的设备中。
5、openflow的真正出路在安全,因为安全的软硬件基础平台在同质化,从Linux、多核到FPGA,并且已经有一些软硬件平台厂商,如软件的pabaos,硬件的从RMI、cavium到一些基于他们的硬件平台以及FPGA、SOC,openflow在于定义了流处理的标准,软硬件平台支持这个标准,应用层支持这个标准,那么二者之间就可以seamless对接,这也符合internet/TCPIP把网络和应用解耦,带来internet应用大爆发的特点。让擅长软硬件平台的专注于提供一个好的平台,让擅长处理用户应用的专注于提供各种丰富的好应用,让客户自由选择平台和应用组合,这才是openflow的真正价值,而这个价值的空间在安全,不再路由交换,不要搞错了方向。
真想玩openflow,要不搞paper,通过学术成就获利,要不就向openflow芯片和安全方向,寻找商业利益,跟这两个都不沾边的,早点干点有意义的事,不要在这里浪费感情。
老韩是个nice guy,但是你的这个文章,说实话,有些水,如果因为潜规则,不得不说点官话,那适可而止就可以了,然后把上面的东西挖掘一下,适当穿插在里面。做媒体,如果每天主要写此类文章,如果不是为生计所迫,还是不要做了好些
硬评。
http://perspectives.mvdirona.com/2011/05/20/SoftwareLoadBalancingUsingSoftwareDefinedNetworking.aspx
”
When networking equipment is purchased, it’s packaged as a single sourced, vertically integrated stack. In contrast, in the commodity server world, starting at the most basic component, CPUs are multi-sourced. We can get CPUs from AMD and Intel. Compatible servers built from either Intel or AMD CPUs are available from HP, Dell, IBM, SGI, ZT Systems, Silicon Mechanics, and many others. Any of these servers can support both proprietary and open source operating systems. The commodity server world is open and multi-sourced at every layer in the stack.
Open, multi-layer hardware and software stacks encourage innovation and rapidly drive down costs. The server world is clear evidence of what is possible when such an ecosystem emerges.”
From
http://perspectives.mvdirona.com/2011/05/20/SoftwareLoadBalancingUsingSoftwareDefinedNetworking.aspx
感谢楼上的精彩评论!
为了能引发更多的讨论,我也来补充两句。
首先,前途不在于OpenFlow,而在于Open,在于这类东西:
http://www.opennetworkingfoundation.org
Open的目的是SDN(软件定义网络),让网络开发/管理摆脱硬件和厂家的束缚。OpenFlow只是SDN的一种方法,且既然有人能鼓吹的动,大家不妨先拿这个玩玩。至于将来真正用什么,应该还是工业界说了算的。学术界能做的事情,一是抽象,即抽象出什么需要Open,什么易于Open。另一点是Demo,做些好玩的演示给工业界看,看看Open后能有什么效果。要靠OpenFlow改变Internet,不是Open的目的。
SDN不是新概念,如楼上所说,电信里很早就用上了。这里的SDN不是解决交换路由问题,而是支持变化更多的业务问题。SDN中Open Layer(e.g. OpenFlow, Open vSwitch)的引入有两方面目的:
1)对于接入设备,这一层提供虚拟化,使得接入的主机/虚拟机只看到各自的L2/L3网络,并能对其控制和管理。
2)对于传输设备,这一层提供网包映射、流汇聚等功能,使得不同架构的传输网络能够快速提供点到点的连接。
这样做之后,Host和Network之间有了弹性可控的一层。研究的问题就变为:
1)这一层部署在哪儿?
2)这一层如何对Host提供虚拟网络?
3)这一层如何满足Network的高效传输?
Cisco的UCS基本在这么做。Google在用Onix这么做。但华为的Single Cloud,不像是这么做的。
从实现层面讲,细粒度流表查找的芯片需要做,而且这个也是我一直研究的方向,但是否真的要为OpenFlow做芯片,国内是否有需求,目前还没听说。
从软件层面来讲,能够驾驭OpenFlow网络控制原语的控制平台(先不说OS这级别的,但方向是OS)需要去做。这是个巨大的工程,需要理论、抽象、应用支撑及大量实践,需要聪明的头脑及网络巨头们提供开放的合作。
看来不管是acadamic还是industry都需要概念从客户裤兜里把钱忽悠出来
我有个直觉,最后能把Open Flow的系统(System)做成的,就是我。工业界找不出第二个更适合的了。。。
我只关心一个问题,性能问题怎么解决?解决不了就扯淡⋯⋯
作为被退团的,还是相信团长的话
清华土著是明白人,老韩同学可能是难得糊涂。
无论ZZ还是科技,一个封闭多年的系统总是会被人不断努力突破,要不是老系统被phase out,要不是被新势力/技术突破,虽然要突破经典的TCP/IP路由交换体系很难,但目前看,如MZ对专制一样,尽管有各种弊端,但openflow/SDN还是最佳方向。
几年前参与过863的一个关于可重构IP系统的题目,也是要open的IP系统,当时还是首次和清华合作,在FIT楼
相信清华土著一定会有更多突破,到时一定要再请老韩来:)
其实某种意义上来说, Openflow可以算是一个针对集群化系统的一个控制平面扩充, 其实我们可以看得很清楚, 工业界的产品来说, 大家都在搞集群和分布式部署. 从最先的NP+ Switch Fabric的架构(CJAN都这么干), 然后到多机箱集群, 例如TX-Matrix/CRS. 然后控制平面需求越来越多, 都想把一些东西做的更智能化, 于是J搞了个JCS,直接用的IBM的刀片做控制平面. C也搞了些DRP. 控制和转发接口嘛基本上都是以太网了.
于是好事者出来了, 有人说, 你们这些厂家别搞了, 我搞个OpenAPI, 把你们全管了…而且这些好事者又开始游说政府和运营商, 说, 你看, 你们有了这些API可以干嘛干嘛…
实际上来说, 这东西就是个扯淡的东西… 不过每个厂家能够follow一个openapi库来开放一些API实现一些例如loadsharing / firewall / DPI / IPS一类的业务, 倒是个好事. openpipe也是个不错的东西…
而至于Openflow的系统, 还不如proximity一类的系统做一个中间代理, 然后下层继续走原来的路由交换.
首席来北京不会就是做这个吧?
我觉得可以试一试。至少是个新的idea,总比吃别人的冷饭要好很多。
看来斯坦福Nick教授的NetFPGA很大程度上都是为openflow服务的啊,还有他那野心勃勃的cleanslate计划
湾区的精彩在于评论。 有些话可能老韩自己不便说, 所以他把文章贴到这里, 让读者说。
接入方面,目前已经有运营商根据客户要求提供基于VPN的有限的命令集授权给客户用,当然目前都是简单的非opensource的,这个业务模型对路由交换虚拟化(VR/VS)有需求,对openflow是一个实际可能的机会点。另外是企业网设备提供一个API,用于增值业务处理,这些东西可以考虑被openflow做成标准接口,还是颇有一些前途的
IP CORE,一个是光传输的IP化,另一个是IP的clouding和virtualizing化,这里面openflow可以做学术研究,但商业化的机会很小
所以安全和接入部分可能是openflow目前可以重点冲击的突破口
路由传输领域,目前已经在往夕阳方向走,首席正直壮男,不,壮年,应该是在做smart terminal才和首席配
openflow的重点是open,非常重要。openflow因为有很多开源的资源,所以更可能得到快速的发展,犹如现在的linux。可以预计,openflow最先将在高校和互联网企业中得到实现和应用,这两个地方都是开源的重要应用地。目前可以预料的使用场景,一个是虚拟环境下的安全控制,另外是广域网的流量调度。
感谢理客老师的教导,对于本文我自己也不甚满意,主要是起初对OpenFlow缺乏足够了解,学习阶段看得、想得也不够深入(轻敌了,前面看文档时间太多,后面写得时间被挤得很少,在平面媒体发文章每周都有deadline)。总而言之,水平还相当有限,以后会多注意积累。
除此之外没有什么潜规则,也没有商业利益掺杂进来。我只是比较认同清华土著团队的理念,对他们开放的态度非常赞赏。另外,这个团队在我接触过的来自高校的团队里面,算是在工程化方面认识实践最深刻的(当然不能和企业比)。我个人愿意去帮这样的团队去做一些事情,报社领导也比较支持,如果弯曲上的朋友有类似的好产品、好团队,可以联系我们。
To 15:
我没想太多,贴到弯曲一来为了学习,二来为了帮这个团队、这个产品做做推广。前面理客老师说难得糊涂,其实在这个技术领域我是真糊涂:)
to 老韩:
抱歉,我有时也是口无遮拦,不多进大脑,也略有玩笑,言过之处,还请海涵。
另外,老师可担当不起,我只是个engineer,清华土著可以是
To 21:
三人行必有我师,您说话还是非常有水平的。况且现在IT媒体确实好内容有限,真希望能多点3楼那样的真知灼见。方便的话,咱建立个邮件联系(见文章首部),以便随时请教。感谢
请教不敢当,我个人邮箱是totobeing@hotmail.com,但不常看,可能需要在这里提醒我看一下
再次证明评论的价值…我继续搬小板凳…围观学习…
清华土著同学了不了解Forces,能不能分析比较一下Openflow和Forces?
基于Forces发展近十年的结果,能否预测一下Openflow的命运呢?
Open是个泛泛的概念,不能一说Open了就有价值,Open是有代价的,Open是冲击产业链的,Open是有阻力的。只有市场需要的Open才能生存。
市场需要什么样的Open?运营商希望什么样的Open?企业用户需要什么样的Open?各位大侠能不能亮亮各自的观点?
我先抛个砖,市场需要的是管道上的业务(流)处理和加工能力,也就是开放管道流处理能力。至于流表的开放,也就是开放转发,有什么企业需要呢?什么场景需要呢?有什么运营商需要呢?安全性、可靠性、性能的代价如何解决呢?貌似只是学术圈里的研究需要吧。产品中转发由设备商做到高效、高可靠就够了,是否Open貌似并不重要。
早知把上次的评论搬到这边来了。学习吧……
大家伙谁记得 论坛里面有一副通讯产品图,有各个产品的分支。比如负载均衡、应用层过滤等的一个分支图。标题是啥我记不得了。谢谢
来学习的,个人观点,open是好的,至于openflow目前的前景不好说!
个人认为openflow不会长久,如果是支持网络研究的,基于openflow难以实现各种新的协议机制。如果是面向商业应用的,ISP是难以接受的。
目前国内863在做“可重构路由器”,貌似比openflow更加激进,路由器可以将第三方的构件植入,重构网络的功能。可重构路由器不仅仅open流表,是把datapath给open了。各位大侠如何评论这项技术?
如大多数说的那样,高校确实在用,斯坦福名声很大,但openflow似乎是小儿科。NetFPGA更笑死人,1G板的TCAM是32×32,10G板跟1G一点关系都没有。10年了,现在算是忽悠到国内了。至于清华加的那东西我不了解,绝没有否定的意思,希望青出于蓝。
openflow就是一个Minix。它是一个尝试。我倒希望有Linus2让它蜕变,但switch不是OS,因此可能性很渺茫。
“可重构路由器”,多么熟悉的名字。
重构、自定义 之类的名词已经不新鲜了。
个人觉得,上面的部分评论很多是看了 老韩的一点文章就开始评论了,并没有认真的看完openflow的来源、未来,并没有看清openflow的真实意图。
1.openflow确实重在开放,开放了当然好处多,不用说了
2.要着重强调openflow的应用范围!是企业网络,什么叫做企业网,自己可以定义。这样,才不会被目前一些明显无法解决的问题而难倒。
3.openflow,最初是由集中式网络体系结构ethane而来,着重Id的真实性。openflow就是继承了这个思考,openflow没有那么大的志向,只是想在解决企业网的问题。
。。。
想请教一下openflow里的flow指的是什么?
个人认为,网络本身应该是L3的,至于在边界L2oL3的功能是Openvswitch要做的事儿…
工业界的朋友是无法站在学术界的角度来看openflow的,就像工业界垄断屏蔽了路由器的内部机制,但学术界却并不希望这样,这是个博弈的过程。
可重构路由器,是不是又是拿一个美好的前景去忽悠国家的经费?
等到路由器领域出现了Wintel,把器件和OS全统一了,也许可以任意重构。
不是100%的忽悠,但应该有50%
在当前工业界在网络通讯领域具有绝对话语权的时代, 对学术界要宽容, 尤其是国内的学术界。
不要指望他们能做什么,但愿培养出来的学生不是大“忽悠”就行了。
楼上们何必总透着工业界对学术界的优越感,在一些算法以及某些前瞻领域主要还是学术界的在推动,不管工业界还是学术界能做到吃螃蟹都是令人尊重的,成功的产品和商业模式都是在伴随质疑声的沙子中淘出来的
Heeeee。工业界,学术界都是谁? 类似于问人民是谁一样? 大家都是一个工作,一个爱好,或者一个饭碗嘛。不要分的太清楚乐:-)
1.靠什么来识别flow呢?用五元组力度不够细,对4层以上的应用需要识别的内容可能千奇百怪啊。
2.如果用HASH来实现五元组查找不能通配,配置规则会很麻烦,用tree表等转发性能得不到保障。用TCAM成本高,而且受制于TCAM的容量FLOW的条目数会有限制。
3.靠什么决定FLOW的下一跳呢?小网络还可以靠人力维护,大一点的网络还是要靠路由协议吧。
感觉OPENFLOW可能在学校的某个校区或固定在某个区域的企业内部用会好一点,呵呵。
我本來也以為OpenFlow是個幌子,但後來發現它對雲端計算是非常重要的技術!有人說它有效能上的問題,非也非也,它的設計就是為了突破效能上的瓶頸!雖然目前的Switch都各自在本身的設備上跑Protocol,聽起來要比受「遠端」Controller的控制來得快,但是L2/L3的Protocol之間的計算還需要等彼此之間的回應,你想想要多久才能達到收斂?對日後更複雜的Protocol設計,將造成最大的瓶頸。集中給Controller計算,沒有互相溝通的問題,能快速達成收斂!這就是所謂「計算」與「頻寬」分離之設計最重要的目的。只是這樣的技術,目前還只能用在雲端計算(私有網路),畢竟世界各地目前的設備都還是傳統的,尚不支援OpenFlow,因此OpenFlow目前只能應用在範圍不大的私有網路中。
1年后重读,我基本上知道理客是谁了,呵呵。
评论果然很精彩
其实Openflow最大的问题还是成本,它是高带宽的,对Search要求很高,如果没有低成本及大容量的Search Processor,Openflow就是一个概念,无法做到商业化。
第二大的问题,因为Mircosoft和Intel只有一个,而Openflow的门槛又不是太高,可以有很多个Microsoft及Intel,大家难免价格战,价格战的结果就是全部玩完,一个企业没有Margin能玩不.
第三大问题是通讯设备如何加入,没有利益,他们有什么兴趣,你不会没有发现驱动Openflow几乎全是数据中心的人,因为虚拟化,简单化,高带宽是他们想要。
我不知道Openflow的明天是怎么样的,究其本质 来讲成本才是硬道理,谁能做到低成本,大容量的Search Processor,你会发现Packet Processor已经不是问题,Openflow是想简化Packet Processor,做Flexible的Parsing,这些都不是难的。所以Intel是做大容量,低成本的Search Processor厂商,根本就不是PP。
Open Flow下来,PP就剩下接口的东西的,主体就是SP了。到时候不再说PP集成SP,反过来是SP集成PP了。
Broadcom最有望成为Intel
SPY很有见地,但不能太靠既得利益的vendor,否则是就很难玩了
呵呵,能够得到理客的称赞真是幸运,我认为Broadcom能成为Intel最主要的原因是要做这个Intel,要几个要素它都具备;
1. Switching Fabric
2. QoS
3. Packet Processor
4. Search Processor
唯一的缺陷是Search Processor在流支持时成本过高。
Swithcing Fabric + QoS + Search Processor 是大多数公司不具备的,可能也是也C了,C呢Search。我认为所有公司的瓶劲都在Search Processor上,其它的还好做。
而Openflow叫,如果将PP简化,成本在初期没有优势,但到少有一点是将极大的缩短PP的研发时间
Broadcom的PP够呛吧,C3不好用啊。OPENFLOW是准备另外定义报文格式还是沿用IP报文格式呢?估计是沿用IP,那怎么才能做到识别FLOW?如果要带掩码匹配的话用TCAM成本下不来哦。
to SPY: 虽然我们都是纸上谈兵,我还是比较同意你对SDN/OF的comments。
呵呵,C3怎么个不好用法,很早以前,Broadcom就用滑窗来做ACl,叫Conent-Aware技术,只有老江湖才知道吧,效果一直不好,我以为C3会有大改进呢
或许明天就有方案解决Flow的问题
如果没有好的芯片来支持openflow,性能价格都没办法下来。
可以用这个:
http://www.a10networks.com/products/axseries-ax3530_IPv6_Migration.php
1.硬件构架非常简单,与早期x86软件防火墙极相似
2.不同的是CPU是双8核(共16core),Sandy Bridge。当然,I/O有他们公司自己的设计,100G不是简单的几个PCIe就能搞定的。
3.软件系统是核心。所有的处理都在CPU,应用层。我这哥们现在在做的,就是把driver移到应用层
4.具他说这个硬件平台,性能还有提升的空间,还在做软件上的优化。
5.与DPDK无关。
没有那么简单!
64Bytes的小包来了,你推荐的系统就要打穿了!
switch还是由硬件来做,X86因该做L4-L7.
不用64,如果256可以线速也可以,欢迎MT踢馆
受到鼓励,斗胆地预测一下A10的性能:
1)对于小于512Bytes的包,估计要被打穿!
2)大于1024Bytes, 估计没问题!
3)平均的处理能力大概是30-50Gbps (当然是很好的了:-)
汗,用至强去的业务,这个成本,功耗呢,开发难度,也太太理想化了,Intel就是加入通讯行业,成本也降不少多少呀
这个用来做switch或router,肯定是没有优势。其优势在7层。传统的switch和router构架,对7层业务是更是想都不要想。大家各自针对不同的市场,没必要硬把ADC设备当switch,或者把router当ADC。这个设备,其主业务是ADC,但在安全业务(安全的重心已转向应用层,这个是共识了吧?)以及其它一切应用层业务,都有很大潜力。唯独不必看其4层以下的前景。
这个CPU的主频有多少?假设是3.3G,按照256字节的报文计算100G就是450MPPS,每个核大概28MPPS,要到线速的话相当于每个报文大概执行120行代码,感觉这个设备到不了100G啊。
即时按照你的“错误”数据,也应该是45MPPS。
此外你没有考虑包之间的填充字节。。。
按256B算,是1000/(256+20) = 0.37M PPS
100G就是37MPPS,算8核的至强 8X3.3 = 26.4G
26.4G/37MPPs = 713条指令处理一个包。
而一条包的处理,包括ingress/Egress,ACL,QOS,NextHop,还包括报文编辑,VLAN,Tunneliing,IP DA/SA Lookup,MAC DA/SA Lookup等等,还包括QoS调度。
业务还包括
神仙能用712条指令写出这么多东西来吧。还不包括OS切换的开销。
Fabric怎么处理的还没有说,要不要SAR等,复杂着呢。
一个8核至强能处理20G就不错了,还要简单业务,复杂业务更不可能。
而一个8核到强怎么也要4000美金吧,跑3.3G的,便宜点也要2500美金吧
上 1000/(256+20)/8 = 0.453M PPS,我算错了。 一个是453MPPS
26.4G / 45.3 M PPS = 582 条指令。
可能在20G以上内,正常人只能做出10G,要超级高手才能做出20G
同意Multithread的观点,一个完整的路由芯片流程肯定不少于5000个指令的,复杂一点要到10000条指令(注意一行代码可能是几条指令的),所以用CPU做Switch router是不可能的,100G光查找就不可能的(包括ACL的情况下)。
这样自算下来,1000Bytes还是要找究,2K以上才不被打穿
to #66
肯定不是256字节的数据。
7层设备,不太care小包性能。
另外,现代CPU都能在一个时钟周期执行多条指令,intel的xeon,ipc应该在8以上。
若是1024bytes,100G应该是没有任何问题的。
其实所谓利益也是相对的,正因为openflow是要“从头再来”,恰恰提供了一个弯道的机会,更多的二三流但有野心的厂商说不定会全力支持,就好像你拿了一手烂牌,你想不想重新洗牌?
但是,目前的openflow还确实不足够好,openflow为了做到SDN,把抽象控制的部分集中了,这反而不安全了,如果控制了controller,岂不就控制了整个网络?
超赞,我们是穷人,肯定要抢劫富人呀
其实可以划成很多个虚拟运营商,相互隔离呀
to 67:如果用CPU的流水线,肯定会卡在内存访问上了。反正用至强做交换路由不可思议,得多大的内存带宽才行
To #70
100G,DDR3 1066内存是能hold住的。
简单计算一下:
按字节算,100(Gb/s)/8 = 13(GB/s),
两条DDR3 1066内存,组成双通道后,理论上速度能到16.6(GB/s),把实际损失计算在内,应付13(GB/s)没有问题。
所以大包100G是没有问题的。
对性能问题,我们不需言必称小包。毕竟没有全小包的实际环境。而且,如果用户都不关心小包,厂家也不会主动提它。如果是做专业的交换机/路由器,小包可能必须考虑。但ADC设备,交换路由只是为适应网络环境,厂家和用户都不太关心小包数据。
如果内存卡住了,是无论如何也到不了100G的。
这样,厂家就是在官网上公开撒谎了,没有人会这么做吧?这一点点信任还是应该有的。一般没有提小包性能,就是小包达不到其所宣称的数据,不然肯定会以最醒目的方式昭告天下了。
所有厂商,无不如此。
#72, 有两点值得再思考:
1。每一个包要N次内存访问? What is N (N>1)?
2。带宽够了不代表时间上来的及处理。 这就是为什么要算cycles.
〉对性能问题,我们不需言必称小包。毕竟没有全小包的实际环境。
For the DDOS SYN attack, most of packets are 64B small packets.
晕,前面确实算错了,256字节100G应该是45Mpps。不过就这样看用通用处理器性能还是不行啊。性能要上去应该还得多核做控制NP或者FPGA做转发才行吧。
我的算法是按 8核来算的,再加8个Pipeline,每秒执行 3.3 X8 * 8 X64位宽= 13516.8G
就单指令来讲 需要 13516 /2G (DDR3最高了)/16 = 422个16位的DDR,如果CPU是32位的,就是211个16位DDR,这是典型的服务器呀。
还不算包缓存及查表的内存带宽。所以肯定不能到100G,除非是只支持简单路由,很多东西不处理勉强能够做到。
一句话,不够能做到高速的
通用处理器性能是没有问题的,但是功耗上有点大!
原来PCIe是不够的,随着PCIe 3.0时代的来临,IO应该不会是问题了。
主要问题是软件问题,One must know OS,multi-core Architecture,compiler to design a good system.
To #75: SB上有20MB的LLC!! 如果把它用好了,内存的压力陡然减小; 否则你分析的最坏情况是有可能发生的。
http://www.tilera.com/sites/default/files/productbriefs/TILExtreme-Gx-PB040-02_web.pdf
tilera新推出的高密度网络评估系统,16万兆口,最多288个处理器,1u size。 可用为SDN 网络research
那玩意贵呀,看了前面的,Openflow至少是革命,是好事,强烈要求打土豪分田地
在TILERA上,四个GX之间用PCI-e相连,它们支持CACHE的一致性吗?
to 81, 四个GX 跑四个OS,每个CPU都是独立的,一个为root,其他三个为agent
如果是这样,四个CPU之间的通讯和同步是有挑战性的。
绿盟的难点大概在此。如果问题能在一个CPU上搞定,皆大欢喜;否则通过PCIe同步起来,比较难办。
@SPY 关于高性能低成本的 search processor 可以看看这个http://www.cavium.com/processor_NEURON_NEURONMAX.html
TCAM Cell肯定不是Openflow的解决方案,成本高,功耗高,40M算什么大容量,哥,你讲笑了
无论是数据中心还是运营商需求,带宽需求都非常大,表项数目也要多。所以X86,TCAM都不行。
在现有的芯片上做,则必须牺牲openflow的功能范围,即使用openflow满足某些特定业务,比如mac+vlan转发,ip+vrfid路由等。但是这样的结果是,openflow只是变成了网管工具。
不知道bc有没有规划做这样的芯片,考虑到它有hybird模式,做这个芯片业不容易。
什么Hybrid