




拨云见日:虚拟化的最后一公里–虚拟化网卡
作者 libing | 2011-06-07 08:00 | 类型 弯曲推荐, 行业动感 | 58条用户评论 »
|
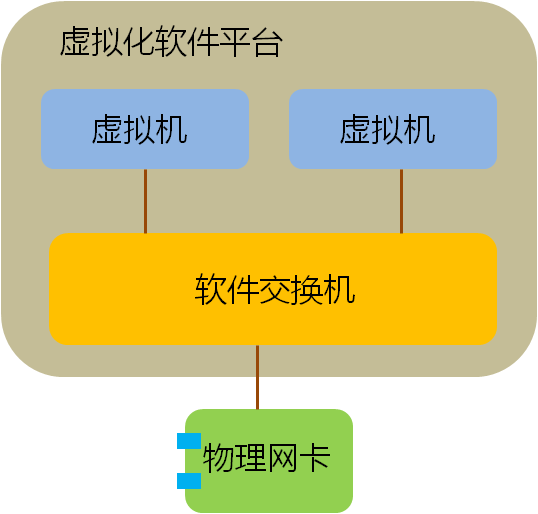
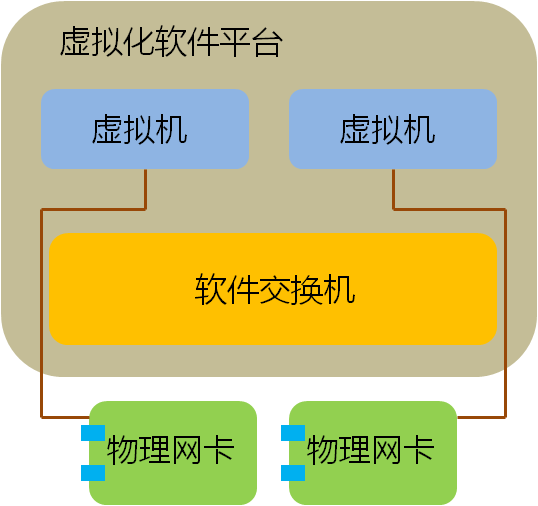
最近看到有国内厂家打出“虚拟化网卡”的概念,我认为这个提法是非常有价值的,可以让更多的人开始思考网络I/O在虚拟化发展中的重要性,但什么才是“虚拟化网卡”?“虚拟化网卡”有何作用?也许这个概念本身并不清晰,在更多的场合仅被作为一个忽悠的工具在使用。另一方面,今天的服务器网卡确确实实在发生一些重要的变化,这些变化将对整个数据中心产业今后的发展产生至关重要的影响。 我希望通过自己的理解,引来更多高手的讨论,最终对这个概念提出一个明确、清晰的认识。毕竟,技术名词是要落地的,我们需要的是“云计算”而不是“晕计算”。 关键词:虚拟化网卡 厂商:Cisco、Intel 。。。 领域:数据中心网络 模糊程度:四星 缘起:虚拟化的最后一公里 在推动虚拟化轰轰烈烈发展的众多因素中,资源的再利用是很重要的一点,当一台服务器只运行一个业务时,其CPU资源往往没有被充分利用,花大价钱购买的CPU就这样沉睡在机架上,干耗电不干活。大多数客户都希望在部署虚拟化之后,将原来服务器可怜的CPU利用率尽可能提高一些。虚拟化软件(如VMWare vsphere、XEN、KVM等)很好地解决了这个问题,在虚拟化软件中,一颗CPU能够被分配给多个虚机同时使用,部署了虚拟化软件的服务器,其CPU利用率往往能够从不到10%增长到70%左右。 这当然非常棒,可任何新技术的发展都是一个以点带面的过程,好像抗生素的发明虽然挽救了成千上万的生命,但人类至今仍在为对抗其带来的副作用而努力。虚拟化技术也不是真空中的产物,它需要同数据中心内部的主机、存储、硬件等方方面面发生关系,当操作系统的运行方式发生变化时,原先的基础架构并不一定能适应这种变化,新的挑战开始浮出水面, 首先告急的就是内存,当CPU主频在Intel和AMD的竞争中,如脱缰野马一般往前发展时,其他部件并没有以相同的速率前进。内存大小就一度制约了单台服务器上虚拟机–也就是VM(Virtual Machine)–数量的增加,由于大量OS实例同时运行在内存中,服务器的内存容量很快捉襟见肘。为了解决这个问题,各个服务器厂家开始疯狂增加DIMM槽容量,现在单台X86服务器最大内存已经可以达到令人匪夷所思的1TB! 内存警报暂时解除后,网络逐渐成为新的瓶颈。当越来越多不同性质的虚拟机跑在一台物理服务器上时,他们的进出数据都会拥挤在一个I/O通道上,这显然是不合理的。以Cisco为首的网络厂家提出了VN-Tag/VEPA等解决方案,来规范虚拟机流量的转发机制,通过在全网部署VN-Tag,不同虚拟机的流量能够被识别,并且在上联交换机上得到很好的QoS保证和安全隔离,但这只解决了一部分问题,虽然VN-TAG能够区分出来自不同虚拟机的流量,但普通服务器网卡只提供一个PCIe通道,在出口网卡上,这些流量仍然混杂在一块。 单一通道造成问题的典型例子是高性能计算环境。 虚拟软件平台也就是Hypervisor往往集成了一个软件交换机,这个软件交换机通过CPU模拟出简单的二层转发功能。传统的解决方案中,多台虚拟机通过一个Hypervisor软件交换机连接到一张物理网卡上,流量进入软件交换机不但消耗CPU资源还产生了时延,这还不要紧,在高性能计算环境中,上层业务对网络I/O的设置有非常敏感的反应,虚拟机往往要求特殊的端口队列模型,如果模型不对,性能可能大幅下降甚至不可用,而单一的物理网卡无法对上层多个操作系统提供不同的队列服务,进一步影响了性能。
既然软件交换机是问题,最直接的思路就是绕过软件交换机。因此,VMWare、Intel、AMD等提出了Hypervisor Bypass方案,也就是说虚拟机绕过软件交换机直接同网卡打交道,这样做的好处是一个虚拟机独享一个PCIe通道,想怎么玩就怎么玩,能够实现接近于访问物理PCIe设备的功能和性能。这个方案在主流平台上有不错的支持,VMWare VMDirectPath和Intel VT-d/AMD IOMMU等相关技术都有比较广泛的部署。
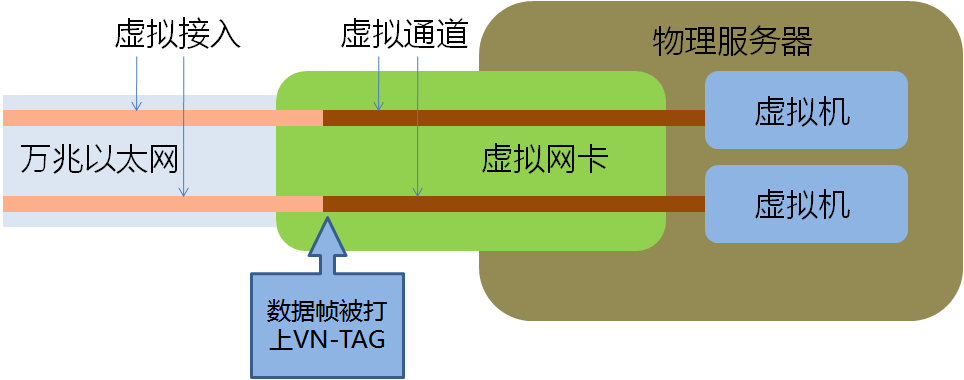
上面这种形式的Hypervisor Bypass满足了虚拟机对I/O性能的要求,但它远非一个一劳永逸的办法,基本是个半拉子工程,其思路是利用物理网卡为VM直接服务,从而暂时回避了传统I/O跟不上虚拟化发展的问题。最大的缺陷就是每个虚拟机都独占一个PCIe插槽,而插槽意味着什么呢?意味着money!在不断扩张的服务器机房内,每一个PCIe插槽都牵动着能耗、散热和空间的支出,更不用说单台服务器上PCIe插槽的数量上限了。这种以大量占用物理网卡数量为代价的方式很快就会遇到PCIe插槽数量的极限,不是一个可持续发展的方案。 也许有人会问,能不能通过优化Hypervisor的网络功能来解决这个难题呢?首先,网络不是虚拟化软件目前的开发重点;其次,软件的开销太大,普通万兆网卡在多VM的传输环境下已经占用了不少系统资源,如果还要精确、高效地模拟不同虚拟机的传输队列,将会消耗大量CPU资源;最后,软件实现的效率也不高。 随着邮件、OA等简单应用在虚拟化平台上的成功运行,越来越多的重要业务将开始向虚拟化迁移,这些业务中很大一部分都对网络I/O有着严格要求。我们搞定了CPU,搞定了存储,搞定了内存,搞定了交换机,却没来及搞定服务器上一块小小的网卡,当其他所有都不再是限制的时候,I/O这块短板开始慢慢显现,成为阻碍虚拟化发展的最后一个瓶颈,也就是接通虚拟化世界的最后一公里。 所以我们看到”虚拟化网卡”应运而生了,这个概念出现在这个时间点是一件自然而然的事,是技术进化到一个阶段的必然产物,只有跨过这个坎,虚拟化才可能开始向更高的段位发展。 那么,下一个问题就是:什么是虚拟化网卡? 什么是虚拟化网卡? 除了基本的数据转发,上层业务对网络的需求可以归纳为以下两点: 1)安全隔离; 2)服务质量保证QoS 实现这两点的前提都是对数据流量进行清晰的区分,只有区分出不同的流量,才能根据业务类型配以不同的保障等级。如果以服务器出口为界,我们可以将数据流过的路径划分为外部和内部两部分。 对于服务器外部网络:VN-TAG/VEPA可以区分出不同虚拟机的流量,并在整个数据中心内部署有针对性的隔离和QoS策略,我们称为“虚拟接入”; 对于服务器内部:虚拟化网卡要在不破坏现有业务机制的前提下,为每个虚拟机提供一个模拟真实的网络通道,这个模拟出来的虚拟通道不仅仅要对VM透明,而且要尽可能重现在非虚拟化环境中的一切网络机制,我们称为“虚拟通道”。只有在这样的环境中,上层业务在向虚拟化迁移的过程中,才不必因为网络环境的变更而做出改动,从而尽量减小迁移成本,加快迁移流程。虚拟机产生的数据通过独立通道进入网卡 ,紧接着被打上标签送往外部网络,反向亦然,对于上层业务来说,感受不到I/O的变化,所有的数据行为同运行在一台独立物理服务器上无异。 因此,我们可以定义虚拟化网卡的核心是“虚拟接入”和“虚拟通道”,只有补上这两块短板,才真正打通了服务器网卡的虚拟化瓶颈,彻底解决了服务器端的网络I/O限制。
在这里有很多针对虚拟接入的非常棒的讨论,下面介绍虚拟通道技术。
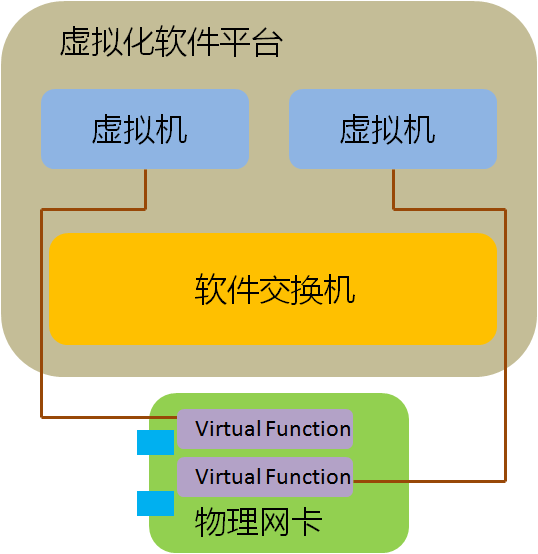
SR-IOV 虚拟通道的实现方式有很多,由于其在未来虚拟化环境中的重要性,大佬们纷纷提前卡位,其中PCI-SIG制定的SR-IOV影响力最大,其背后推手是Intel、Broadcom等巨头。 大多人认识虚拟通道都是从SR-IOV开始,SR即Single Root,IOV为I/O Virtualization,合起来就是将单个PCIe设备(Single Root)–如一个以太网卡–对上层软件虚拟化为多个独立的PCIe设备。 SR-IOV虚拟出的通道分为两个类型,PF(Physical Function)和VF(Virtual Funciton)。
每一个VF都好象物理网卡硬件资源的一个切片,对于虚拟化软件平台Hypervisor来说,这个VF同一块普通的PCIe网卡一模一样,安装相应驱动后就能够直接使用。假设一台服务器上安装了一个单端口SR-IOV网卡,这个端口生成了4个VF,则Hypervisor就得到了四个以太网连接。 SR-IOV的实现依赖硬件和软件两部分,首先,SR-IOV需要专门的网卡芯片和BIOS版本,其次上层Hypervisor还需要安装相应的驱动。这是因为,只有通过PF才能够直接管理网卡的I/O资源和生成VF,而Hypervisor要具备区PF和VF的能力,从而正确地对网卡进行配置。 在SR-IOV的基础上,通过进一步利用Intel VT-d或AMD IOMMU(Input/output memory management unit),直接在VM和VF之间做一对一的映射,在这个过程中,Hypervisor的软件交换机被完全Bypass掉了,同传统的VM DirectPath相比,这种方式即实现了VM对VF硬件资源的直接访问,又无需随着VM数量的增加而增加物理网卡的数量。
在业界厂家的大力推广下,SR-IOV已经成为虚拟化数据中心一个非常重要的演进方案,支持SR-IOV的网卡开始大量出现,其中不得不谈谈的就是Cisco名声大噪的Palo卡。 Cisco Palo Cisco这块红得发紫的网卡大名M81KR,昵称Palo。 Palo是一块SR-IOV网卡,但它又不是一块标准的SR-IOV网卡(×_×!),这句话翻译成人类的语言就是,Palo能够兼容SR-IOV的所有行为,但无需Hypervisor对SR-IOV的支持。 之所以Cisco要玩得这么特立独行,是因为PCI-SIG自推出SR-IOV后,其市场推广并不是太给力,前面说过,要实现多个虚拟通道需要在Hypervisor上安装对应的驱动,但目前为止只有XEN和KVM等开源系统比较积极地提供了对SR-IOV的支持,VMWare vsphere和Microsoft Hyper-v这类主流平台迟迟不见动静。 数据中心市场经过一轮大浪淘沙,已经逐渐明确了未来的发展方向,谁越早拿出一个切实可行的解决方案,客户就会跟谁走。Cisco在数据中心市场提前数年布局,投入不可谓不重,目前看来,思科是是唯一在各个方面有充足储备的厂家,其他人的下一代数据中心网络产品线还很模糊。尽管Nexus平台优势明显,但后面的追兵一刻也没松懈,大家都在争分夺秒地划分地盘,HP已经在给802.1qbg拼命造势,如果这个节骨眼上,客户因为SR-IOV的不成熟限制了虚拟化的部署,拖累了整个市场向虚拟化的转型,相当给了其他厂家喘息的机会,这是Cisco最不希望看到的局面。 因此,思科在Palo上又一次采取了以往屡试不爽的策略,一方面提供对公开标准的支持,一方面抢先推出自己的实现版本,以促进市场尽快成熟。同SR-IOV类似,Palo最大能够实现128个以太或存储通道,但Hypervisor无需支持SR-IOV,思科会单独推出Palo在各个平台上的驱动。能做到这点,一方面是因为思科自身迫切的需求,另一方面,其网络大佬的影响力,也推动了软件厂家的合作。 Palo作为市面上第一块真正意义上的虚拟化网卡,同时实现了基于VN-Tag/802.1qbh的虚拟接入和类似SR-IOV的虚拟通道功能,第一次将网络接入延伸到VM层面。在部署了Palo卡的刀片服务器上,VMWare vsphere上VM的流量被直接发送到一个独立的PCIe通道,这些数据在此随即被打上VN-Tag标记,然后送往上联交换机。在这个环境中,上联交换机、服务器网卡、甚至刀片机框IO模块不再是分裂的对象,而是合并为一个逻辑上统一的接入交换机,这个接入交换机能够直接看到VM的端口,对单个VM的数据流量进行安全隔离,对以太和FCoE流量实施QoS策略,而Hypervisor无需再维护一个软件交换机,原来被软件交换机占用的CPU资源能够用来运行更多的虚拟交换机。 虚拟接入和虚拟通道相辅相成,在Cisco Palo上第一次实现了同物理机类似的虚拟机接入。 后面的故事 近年来,数据中心的发展如火如荼,VN-Tag、FCoE等新技术层出不穷,新一代数据中心架构逐渐成形,虚拟化网卡是这个拼图的最后一块。Cisco Palo作为这个领域的第一个尝试,拉开了服务器网卡的升级序幕,网卡厂家将开始新一轮的技术竞争,MR-IOV、Hypervisor Bypass情况下的虚拟机动态漂移等领域将成为下一代技术热点。而随着虚拟化网卡的不断完善,数据中心的转型将开上一条真正的快车道。 五分钟Q&A 1)什么是虚拟化网卡? 虚拟化网卡要能够对不同的虚拟机提供独立接入,区分不同虚拟机的流量,以提供相应的安全和QoS策略。在实现方式上,虚拟网卡要支持”虚拟接入”和“虚拟通道”技术。 2)什么是“虚拟接入”? “虚拟接入”技术利用标签,在全网范围内区分出不同的虚拟机流量。 3)什么是“虚拟通道”? “虚拟通道”在物理网卡上对上层软件系统虚拟出多个物理通道,每个通道具备独立的I/O功能。 4)什么是SR-IOV? SR-IOV是PCI-SIG推出的一项标准,是“虚拟通道”的一个技术实现,用于将一个PCIe设备虚拟成多个PCIe设备,每个虚拟PCIe设备如同物理物理PCIe设备一样向上层软件提供服务。 5)SR-IOV在网络虚拟化方面有和用处? SR-IOV网卡能对上层操作系统虚拟出多个PCIe网卡,每个网卡可以实现独立的I/O功能。独立的通道能够实现更强的安全隔离、更完善的QoS和更高的传输效率。SR-IOV目前支持在一块PCIe网卡上虚拟出256个通道,是实现虚拟化网卡的基础之一。 6)部署SR-IOV需要什么条件? 部署SR-IOV需要支持SR-IOV的硬件网卡,和支持SR-IOV的软件操作系统。 7)SR-IOV同Hypervisor Bypass是一个玩意吗? 不是。 尽管SR-IOV常常同Intel VT-d等Hypervisor bypass技术配合使用,但两者各自独立,SR-IOV的功能是虚拟出多个PCIe设备,Hypervisor Bypass实现的是虚拟机对底层硬件的直接访问。 8)什么是Cisco Palo? Palo是Cisco推出的兼容SR-IOV的虚拟化网卡,能对上层虚拟出128个以太或存储通道,并且支持VN-TAG/802.1qbh虚拟接入技术。 10)SR-IOV是实现虚拟网卡的唯一方式吗? No 市场还有很多公司提供类似的I/O虚拟化解决方案,如Xsigo等。 | |
 (9个打分, 平均:5.00 / 5) (9个打分, 平均:5.00 / 5) |
雁过留声
“拨云见日:虚拟化的最后一公里–虚拟化网卡”有58个回复
vmware早就提供了一种叫VMDq的技术…
写的非常不错,学习了。
发现一个拼写错误。Virtulization
请假楼主一个外行的问题:虚拟机理论上是不是只需要一个I/O通道收发报文就可以了?如果是,那么用基于VLAN ID的逻辑接口+驱动虚拟化,然后绑定VM是不是就可以了,为什么要这么复杂呢?
很不错
To 虚拟化
VMDq是intel VT-c的一部分,它的作用是针对不同的虚拟机提供不同的队列服务,但是VMDq仍然共享一个PCIe通道,并且,需要软件交换机的介入。可以说SR-IOV配合VMDq能实现更好的性能
to 理客
理论上可以用VLAN区分每个虚拟机,但是VLAN在数据中心内更多被用来区分不同的服务器群组,如果用来区分虚拟机,两个功能会有冲突。
其次,VLAN的划分是要消耗地址空间的,用来区分虚拟机流量过于“奢侈”鸟,呵呵
我在拨云见日:fabricpath中也部分谈了这个问题
嗯,很久以前写过关于网卡虚拟化技术的一些简单的介绍:
IO虚拟化:虚拟设备队列VMDq技术解析
http://virtual.it168.com/a2010/0126/843/000000843481.shtml
IO虚拟化:虚拟直接连接VMDc技术解析
http://server.it168.com/a2010/0205/848/000000848949.shtml
to 0
256个physical function的限制是指16位的pcie header中的0-7用作identifier所致,剩下的8位是用来表示bus,通过支持的vmm向设备分配更多的bus号,可以让单个pcie设备使用超过256个funcitons,市面上就有不少虚拟化网卡支持1024、2048个funcitons
另外,某段说的独立的pci-e通道还是有问题的,其实还是在同一个pcie通道里面
to 1
vmdq和sr-iov是不同的
最后
文中提到的hypervisor bypass实际上有两种意思,可能会导致混淆,一种是就是direct assignment方式,virtual function直接映射虚拟机里面,通过nic内置交换机实现hypervisor bypass。一种是cisco的vn-tag实现,它实际上是hyprvisor+nic passthrough,让vm直接和物理交换机通信,bypass的更多——让vm的流量经过物理交换机而不是nic当中进行交换才是这个方式的真正主旨
to 5
vmdq实质上就是一个l2交换机,目的就是去掉hypervisor当中的软件交换机
to gaohl
多谢指正,我写东西就害怕错别字
多谢libing,QINQ有什么问题吗?或者如果L3/MPLS VPN到边缘了,VLAN只用做本地标记?
VMDq 可以完成L2的转发,部分替代二层软件交换机。目前的VMDq实现仍然需要hypervisor维持一个软件的VMM,完成原来软件交换机的I/O收发功能。
俺不是内部人士,VMDq的后期发展会如何,Intel的童鞋可以来爆一爆。
不过,我觉得更有意思的是,VMDq+SR-IOV正好对应Cisco Palo,只不过前者把数据的分发在网卡就搞定了,而后者则致力于让交换机完成这部分工作。孰优孰劣,市场还没作出最后的评断,不过个人觉得,从全网流量管理的角度来说,Palo这种集中式的思路更加make sense。
目前Intel和broadcom的大方向是一致的,而emulex和qlogic跟思科站队。
从这里也可以看出来,虚拟化不仅仅只是在服务器上装一个XEN了事,虚拟化的部署是一个牵一发动全区的工程,连网卡和交换机厂家都可能产生直接竞争,你说有意思没有:D
to 理客
QinQ这些机制如果在现网已经有部署,拿来干其他事情,有可能会打乱客户的业务流程。
三层VPN在数据中心内部部署的机会不大,一来复杂、二来贵、三来效率不高。
vmm就是hypervisor啦,现在的vmdq实现在包方面不需要软件做什么工作了,就是是数据的复制,也有vt-d的dma remmaping,说深一些的话,interrupt的处理还需要hypervisor发送到虚拟机就是了,不过这一点目前所有的虚拟化技术都一样
从本质上说,cisco palo的vn-tag和vmdq是相违背的,一个思路是所有流量交给物理交换机处理(cisco做交换机的么),一个是流量交给网卡处理,这点是它们的根本性的不同,用了后者的话,前者就没啥用了其实
一个明显的例子是,vmdq允许vm2vm流量在网卡上完成,但是vn-tag就不允许,因为它失去了它的原意
嗯,vmdq就已经是硬件交换机了,因为interrupt处理并不属于交换机的内容
再说说cisco vn-tag原意吧,其实这有点像pcie里面的acs(access control services),因为pcie允许两个endpoint通过pcie switch直接互相通信,而不通过pcie root complex,这样两个网卡(乃至上面的vm们)之间的通信就无法处于监控状态,可能会引起问题,因此acs出现就强制所有的点对点pcie传输都要上行经过root complex,从而处于ats(address translation service)的管理之下,和cisco推的这个很相似吧?从这点来看,vn-tag或类似的东西应该确实是一个趋势,大概是不可以避免了
To lucifer
acs实现的功能就好像在网卡里实现ACL,intel大概也看到了客户的需求,但是这部分工作以往都在交换机上完成,按照这个逻辑继承下来,客户更容易理解将流量往上拉到交换机的实现方式。Intel做了一个很漂亮的工作,只是思科在网络方面更强势是罢了。
不过我觉intel和cisco其实并不太在意网卡市场的share,毕竟这块太小了,谁占都无所谓,关键是尽快推进虚拟化的成熟,这样Cisco可以多多得卖Nexus,Intel可以多多地卖XEON,所以目前为止两家都蛮友好滴,哇哈哈~~
准确的说法是acs是在pcie层面里实现acl,acs是pcie 2.0的一个ecn……可选功能,现在已经是pcie 3.0的标准属性
对intel没有影响的应该是cisco不做网卡芯片,而不是网卡市场太小
写得好很通俗,有几个不情之请,可否用同样通俗的语言介绍一下下面几个技术?
1、可否布道一下share io这项技术?
3、Multi-Hop FCoE,FCoE Forwarder
另外有个看法,看回帖好像很多人都离不开以太网。其实思科野心不仅是以太网,数据中心中还有传统的存储网,包括以太和FC,以及后续可能取代FC的SAS光网。SR IOV以及虚拟PCIE设备可以从底层解决问题,如果用qinq,vmdq之类,只能解决以太网的问题,而解决不了sas和fc光网的问题。
to libing:前向兼容和存在即合理确实影响很大,其实如果真要做,支持新协议的交换机/服务器系统和一个支持MPLS VPN的L3(因为相比外部网络,DC里路由和MPLS LSP的数量远不在一个数量级),成本、复杂度和效率未必有多大差别,但是目前已经上了L2以太的船,再下来就很难了
求教一下 IBM 及 Emulex 使用的Virtual Fabric 解决方案 是昙花一现 还是..,
M81KR可以虚拟出两种卡,一种是网卡,一种是HBA卡。
搏科希望把所有的交换工作都在他们的机器上完成,估计年底就会出方案了。
VMWARE则希望能在内部交换完成,就在内部完成,毕竟出去转一圈,消耗还是比较大的。当然,VMWARE在这方面肯定不是他们的强项了。
vmware esx server 5.0支持cisco vn-tag和vmdirectpath2啦,为了无缝vmotion
虚拟化的极致是 -- 虚拟上网。。。
just kidding..
to 冬瓜头
希望有精力写这些题目,我的目的其实是把自己知道倒出来,引来大家的讨论。
Cisco目前在以太的上的态度还是很坚定的,在数据中心的接入层,FCoE将是Cisco主推的方向。至于SAS,似乎在Cisco的方面动静不大,估计目前不是其重点吧。
冬瓜能不能介绍一下SAS在业界的风向呢?
vmdirectpath gen 2号称能实现直接访问物理I/O的同时进行虚拟机迁移。这个feature要等到vsphere 5吗?这我倒不清楚
To 土人
Virtual Fabric我也不熟,不过看资料描述,应该同Cisco Nexus VDC类似,大意就是把一台物理交换机的端口划分到不同的虚拟交换机上。这玩意同vrf最大的区别就是,不同的虚拟交换机之间完全隔离,无法通过背板交换数据。
私以为,VDC和Virtual Fabric在某些场景中是很有用的东东,但这是一个设备级的功能,对整体架构的影响应该不大。这个功能以后应该变成一个common feature,就像现在的交换机支持模块化操作系统一样
昨天刚刚看见冬瓜头的书,今天居然看见冬瓜在回帖,欢迎欢迎
to libing
回去琢磨,先谢过,最近入手一台BCH 本想跟C混,无奈BNT方案的银子太诱人。。所以就从了,不知C 的味道如何。
to 冬瓜头
2 太厚了 可以杀人了 和1 重复的太多,望 3 薄一点 ,对了 新 NETAPP 32xx 如何
HP FlexNic
HP FlexHBA
Cisco CNA
这些都是网卡虚拟化的产品
结合现在的CEE交换机使用
to 冬瓜头
希望有精力写这些题目,我的目的其实是把自己知道倒出来,引来大家的讨论。
Cisco目前在以太的上的态度还是很坚定的,在数据中心的接入层,FCoE将是Cisco主推的方向。至于SAS,似乎在Cisco的方面动静不大,估计目前不是其重点吧。
冬瓜能不能介绍一下SAS在业界的风向呢?
+++++++++++++++
SAS会在存储行业会有比较大的作为,其他不好说。
我书包里一直放着打印好的VN-TAG的相关资料,想看ing。。。你的文章非常好。而且都是重点。冬瓜汤,多学习学习。。。
谢谢首席的鼓励。
我写这些文章,一方面是希望给国内的朋友提供一个入门介绍,另一方面,我坚信网络将是未来数据中心的核心组件,任何忽视网络的架构设计都将会先天不足,这不但从技术上可以证明,在实际项目中也已经开始显现。
这篇给力^_^
文章很不错。
To 理客,兄弟别太迷恋MPLS,IP的发展更验证了适者生存的道理。
不错,学习中。
microsoft 在win8 new feature中加入了对虚拟通道方面的硬件要求,虽然不是强制的,但是对于市场的普及也是一种推动力量。
MPLS已经不是青春美少女了,没那个爱好,要迷恋也是cloud和smart terminal
按libing所说,那HP的VEPA是有问题的。它就是重用了QinQ来区分virtual port,而不像Cisco VN-link那样,重新定义了“干净”的标签,来标识vport,避免和已有的业务标识冲突
很不错的一篇文章,赞一个。
一点小观点,QinQ实际上在数据中心目前基本没有人用,所以qbg使用QinQ并不能算是太大的问题,何况并不是所有情况都要用QinQ。qbg、qbh实际上要解决的问题是一致的,预计在高级阶段两者对用户的表现也是一致的。
libing请教,在虚拟网卡的情况下,每一个虚拟机都给了不同的mac吗?
我们目前正在尝试做国内第一个基于云的虚拟数据中心,发现不仅仅在服务器层面,在网络层面包括跨域互通,在机房层面,在散热层面,甚至在运维层面,都和普通的idc区别很大,基本属于全新架构,汗。。。今后还要多多请教
To zhihuayang
实际上,我也不觉得是多大的问题,但既然成为一个标准,可虑得就会周全些。
另外,VEPA最大的问题是产业化的速度落后VN-TAG太多,以现在整个行业推进的速度,HP要弥补这个缺陷,需要狠狠下工夫才行。
To 玛雅茶
您说对了,每个虚拟机都有唯一的L2/L3表示,其数据通过不同的MAC地址和IP地址在网络上被转发。
我同意您的看法,虚拟化的内涵非常大,不仅仅是操作系统的更新,基础架构跟不上,离真正成功就远得很
To Lucifer
漏看了你之前的评论,Hypervisor bypass这个概念确实很混淆视线,所以Cisco现在开始提PTS(Passthru switching)以做区分。
VN-Tag是Palo的重要组成部分,但VN-Tag的功能只是打上标签,网卡内部的通道虚拟化实际上不仅仅是VN-Tag,而是一个类似SR-IOV的机制。
Anyway,重点就是Cisco使用了VN-Tag将流量引出来,Intel的VMDq则将流量保持在网卡内部,这两条路线的竞争会是一个非常有趣的故事。不过对于Cisco来说,VN-Tag关系到其数据中心整体战略的成败,而VMDq对于Intel来说不过是锦上添花的东西。相反作为服务器网卡芯片的大头,Broadcom可能更加看重网卡内硬件交换机的实现,但是目前看起来,Broadcom和Intel还差了一个车位。
请教一下。Cisco提出的Network as a Service.
http://wiki.openstack.org/NetworkContainers
有啥特别的地方吗?
看起来似乎虚拟化网卡是最后一公里,对于端系统的虚拟化,很早就有人已经在做这些事情,但是实际如何并不能确定。
因为,这种思想从某正程度上已经改变了“端到端”的思想,把一些更加复杂的功能企图在端系统上实现,这样的更新是可能的吗?或许这种虚拟化主要用在专网中。
to 陈沙克
这个是cisco在openstack中提出的概念,本意就是提供对下一代云计算平台的接入服务,宗旨是把nexus包装进去。
这是一个拼爹的时代,openstack虽然有NASA,但产业界的代表只有rackspace,rackspace是一家美国的hosting,虽然做得不小,但同amazon神马的比还是不够响亮,cisco也是刚刚宣布对openstack的支持,因此,这个玩意要折腾起来有难度。cisco在这里做的事情估计也仅仅是占坑而已。
请教一下:文章中提到“上层业务对网络I/O的设置有非常敏感的反应,虚拟机往往要求特殊的端口队列模型,如果模型不对,性能可能大幅下降甚至不可用,而单一的物理网卡无法对上层多个操作系统提供不同的队列服务,进一步影响了性能。”
这个问题引出了整个虚拟网卡技术。
能不能举个实际例子关于,模型不对造成性能大幅下降的实例啊?
或者有相关的性能数据对比,一个PF同多个VF的性能差距吗,感觉VF仍然是逻辑的,硬件资源上没有变化啊。
to Paul
典型的例子是在palo中可以对每个虚拟NIC设置独立的MTU大小,transmit queue,receive queue大小等等,MS W2K8和RHEL5在不同的值下表现都不同。
公开的测试文档,推荐你google“sr-iov”+“performance”或“palo”+“performance”
“一个PF同多个VF的性能差距吗,感觉VF仍然是逻辑的,硬件资源上没有变化啊。”
多个VF和PF不是互相包含的关系,单个NIC只有一个PF,但可以有多个VF,SR-IOV要求网卡硬件支持,不是写个driver就能实现的,因此硬件资源同传统NIC是有区别的。
因为软件QOS基本是难以feasible的,QOS必须是硬件支持
@libing 47.. not only … Cisco start Naas research for many years ago , and recently a software will be released .
To libing
如果说每个虚拟机都有唯一的MAC和IP地址,那么虚拟机的流量就不需要使用VN-TAG来引出来了,在交换机上是可以根据MAC和IP来确定QoS规则的。直接使用IP地址来管理虚拟机及其流量,不但不需要引入全新的交换机,还可以省略全网分配和识别VN-TAG的工作。
请问为什么还如此热烈的引入VN-TAG和VEPA等新的技术呢?
To 52:
我理解是性能和互通问题:
1,性能问题:如果采用IP地址来识别VM,那么VM间的通信就需要在L3层解决了,性能必然比在L2层低得多了。
2,互通,一个物理网卡只能配置一个MAC,一个Server上的VM通过MAC是无法区分的。这样一个刀片上的多个VM,如果相互发包,按照现在的机制,是无法互通的,因为一个VM把包发给Switch后,Switch是无法再把包发回来(源MAC和目的MAC相同,Switch就不知道咋办了)。
libing能否留一下email地址或其他联系方式,有些技术希望交流一下,谢谢
L3一定比L2性能差很多,是误解
MAC不是必须和物理口绑定,它也可以是逻辑地址,按需创建
ToddHan的问题太好了!我也想问。
请思考这样一个问题:虚拟机的MAC地址是所在主机分配的,在non-live迁移到另外一台主机时,该MAC就变了。也就是说MAC地址是本地有效的。但是VN-TAG和VEPA对数据包所附加的标签是全局有效的,即使虚拟机迁移了还有效。
To 53:
第2条,关于“互通”的解释说“一个物理网卡只能配置一个MAC”是这样么?libing说的可是每个VM都有唯一的L2/L3标识,我看大家也都认可每个虚拟机都有自己的MAC/IP。你的解释成了每个网卡上的多个VM共用一个MAC了。
ToddHan,当你google思科的这篇文档“Cisco VN-Link: Virtualization-Aware Networking”,花上几分钟时间读读,一切疑问就扫除了。正如我猜测的那样:支持VM migration是提出VN-Link的动因。