




《给力吧,x86》专题连载九:英特尔Sandy Bridge平台网络通信性能测试分析
作者 老韩 | 2011-12-14 11:07 | 类型 研发动态, 科技普及, 网络安全, 行业动感, 通讯产品 | 57条用户评论 »
|
本篇是《给力吧,x86》专题的第9篇连载内容,也是截至目前最后一篇。其中性能评估从Atom N270到Sandy Bridge,涵盖了目前主流嵌入式平台(尚缺3420)。后面如果时间、精力、环境允许,会补充针对NIC的独立测试。再次感谢同事与厂商朋友们付出的努力,也感谢弯曲站务组和读者朋友们的支持。 本专题内容原文刊登于《计算机世界》。水平有限,文中定有偏颇之处,希望弯曲网友不吝赐教。 ============================================================== 上一期连载内容中(见本报今年35期第36、37版),我们记录了上海交通大学网络信息中心的老师们通过严谨的测试,选择基于英特尔5520平台的x86服务器打造校园网流量分析与优化系统的全过程。那么,万众瞩目的英特尔新一代Sandy Bridge平台在网络通信应用中又会有怎样的表现?它是否可以将效能推进到一个新的高度?就让测试数据去证明一切吧。
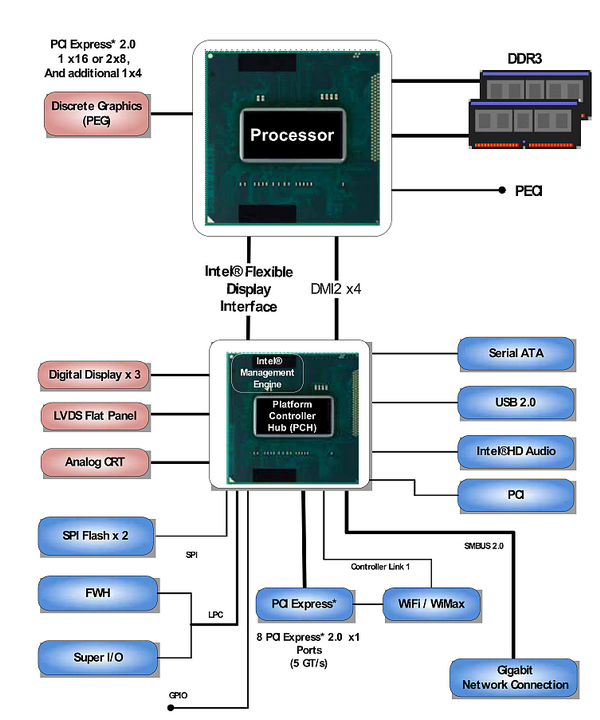
规格放大 体积缩小 FW-8865的核心是英特尔Cougar Point C200芯片组中最高端的型号C206,支持LGA1155接口的Sandy Bridge处理器,包括企业级的Xeon E3和桌面级的Core i3/i5/i7。理论上,LGA1155平台的Sandy Bridge处理器和芯片组可以混合搭配,但前提是使用正确的、高质量的BIOS,因此并不是所有的主板都能良好地兼容两种处理器。FW-8865在这方面显然不存在问题,因为测试中使用的就是一颗四核心、32nm工艺制造的Core i7 2600K。该处理器具有256KB L2缓存(每核)和共8MB容量的通过环形总线和CPU核心连结的共享L3缓存,主频为3.4GHz,最大Turbo Boost频率可以达到3.8GHz。不过从稳定性的角度考虑,该特性在测试中没有被启用。同样的道理,Core i7 2600也支持超线程技术,可以提供8个硬件线程,但在测试中也被关闭。 针对处理器内置PCIe 2.0 Lane数量的差异,FW-8865的主板也分为支持Core i系列的MB-8865A和支持Xeon E3系列的MB-8865B。对于后者来说,Xeon E3系列处理器额外的4个PCIe Lane也连接到左起第三个扩展接口模块,与C206提供的另外4个PCIe Lane共同工作,使接口带宽加倍;另外两个接口扩展模块的规格则没有区别,使用的都是处理器上16个PCIe Lane配成的两个x8接口。内存方面,MB-8865A/B都提供了4个ECC DIMM插槽,最大支持32GB的Unbuffered ECC/Non-ECC DDR-1333内存。而我们测试的这台设备配备了两条2GB容量的DDR3-1333内存,工作在双通道模式。FW-8865的标准配置还包括一个Mini-PCI插槽、一个x4的PCIe Riser(与OPMA远程控制模块复用)、一个CF卡插槽和4个SATA端口,并使用一颗Realtek出品的RTL8110SC千兆网络控制器作为管理配置接口。 作为最新一代的网络通信硬件平台,FW-8865提供了多种高速以太网接口扩展模块(甚至包括万兆电口的型号),可供用户灵活选配。对于这个目前最强大的x86平台来说,千兆级别的负载显然不能充分挖掘其性能,所以本次测试都在搭配双万兆接口扩展模块的FW-8865上进行(使用与处理器直连的槽位)。该模块基于英特尔82599ES打造,它是常见的82599EB的串行版本,主要区别是针对高密度/刀片应用增加了对串行背板总线的支持,功能、性能都极其强大。在T540尚未推出前,它们是英特尔万兆网络控制器产品线中最顶级的型号。82599ES/82599EB使用了5GT/s的PCIe 2.0 x8接口,支持32个PCIe并发请求和512字节的PCIe有效载荷,以及MSI和MSI-X(Extended Message Signaled Interrupt,扩展消息告知中断)特性。单芯片提供双万兆以太网接口是82599ES/82599EB的标准规格,每个接口可以支持128个TX/RX队列,并可根据需要最多划分为64个RSS(Receive Side Scaling,接收方扩展)队列。此外,它们还支持RSC(Receive Side Coalescing,接收方聚合)、低延迟中断等技术,以及包括基于L2 Ethertype、5元组、SYN标识以及英特尔Ethernet Flow Director在内的多种分类/过滤特性。 也许是因为英特尔在芯片层面就开始整合,基于Sandy Bridge平台的FW-8865在设计上显得并不复杂,2U规格的机箱内留有大量空间,对系统散热十分有利。而从最大300W的冗余电源的配置来看,该机的整体功耗也相对较低。有了这样的优势,立华科技也推出了接口数量略低的1U规格产品,在机架空间愈发宝贵的今天相信会有更强的竞争力。 40G:理想照进现实 我们依旧采用了NCPBench 0.8评估软件,依照RFC 2544标准对多达4个万兆接口进行了纯转发模式下的测试(NCPBench的功能介绍和使用方法见本报今年第16/17期51版)。起初我们曾怀疑这个发布已有一段时间的版本不能充分发挥最新硬件平台的性能,但事实证明这种担心是多余的。FW-8865在测试中的表现,足以用震撼二字来形容:当我们将一个扩展模块上的两个万兆接口配置为网桥进行测试时,64Byte帧的整体转发速率达到22.3Mpps,吞吐量达到14.98Gbps;换用128Byte帧时,吞吐量上升为19.37Gbps,已接近线速。有了这样的铺垫,FW-8865在使用256Byte-1518Byte帧的测试中做到线速转发就丝毫不令人惊讶了,这台基于Sandy Bridge架构的网络通信硬件平台就这样轻松刷新了x86平台的性能记录。
表1 FW-8865吞吐量测试结果(1组桥,1组双向流量,同模块) 一直关心本专题的读者朋友们可能记得,在上一篇关于英特尔5520平台的测试记录中,由上一代顶级至强处理器X5690搭配82599万兆网络控制器的系统在同样的测试条件下只达到整机10.24Mpps的64Byte帧转发能力。仅仅更新系统平台就能让性能翻倍,Sandy Bridge的火力未免也太过强劲。为了寻找系统瓶颈,我们开始人为地制造一些障碍。在以往的测试中,我们曾经遇到过一些产品,其跨模块测试时的性能要远低于同模块内测得的性能。为验证这种现象在FW-8865是否存在,我们将隶属不同模块的两个万兆口配置为网桥,重新进行了一次测试,结果不降反升:系统自128Byte帧起就已线速转发,64Byte帧时的整机转发速率更是达到了惊人的28Mpps,吞吐量接近19Gbps。我们猜测之前单模块时的接口资源有限,如PCIe接口的并发请求数量和重传缓冲都可能受到限制;跨模块测试时,可以调用的资源翻倍,从而提升了平台的整体性能。而两个万兆接口模块直接连接到CPU,其间没有了可能成为性能瓶颈的桥片,也许是性能提升的另一个因素。
表2 FW-8865吞吐量测试结果(1组桥,1组双向流量,跨模块) 看来20G已经无法阻止彪悍的Sandy Bridge平台了,感谢立华科技为我们提供了两个万兆接口扩展模块,能让压力测试继续上升到x86从未染指过的40G级别。在巨大的压力下,当同一模块上的两个万兆口分别配置为网桥进行测试时,整机64Byte帧的转发速率为23.3Mpps,较同模块1组桥时略有上升,但大大低于跨模块1组桥时的性能。但在使用128Byte帧的测试中,FW-8865的整机转发速率基本没有下降,吞吐量达到27.54Gbps。并且从256Byte开始,做到40G流量的线速转发。我们随后也在跨模块两组桥的配置下重复了测试,结果没有发生任何变化。老实说,有了之前的测试结果打底,本次测得的多个40G线速转发的结果并没太令人惊讶。照这种情况推断,只要接口带宽不成为瓶颈,Sandy Bridge平台的大包转发能力即便测到60G也不足为奇。相反,64Byte帧时的性能下降是个很意外的情况,在以往测试中很少出现,推断其瓶颈应出现在I/O层面。
表3 FW-8865吞吐量测试结果(两组桥,两组双向流量,同模块)
表4 FW-8865吞吐量测试结果(两组桥,两组双向流量,跨模块) 为了弄清造成这种情况的原因,我们又构造了一个新的测试用例。在刚才的环境中,我们去掉了1组桥中某个方向上的所有数据流,对FW-8865施加共30Gbps的测试流量(1组双向流量+1组单向流量)。这次的结果又高得令人感到意外,该平台在使用128Byte帧测试时吞吐量就基本接近线速;64Byte帧时的整机转发速率更是大幅增加至32.5Mpps,吞吐量达到21.86Gbps。并且无论将同模块还是不同模块中的两个接口配置为网桥,性能都保持一致。虽然这一结果依然无规律可寻,但我们确实是第一次在x86平台上见到64Byte帧转发能力超过20Gbps,就请记住这个由Sandy Bridge创造的里程碑吧。
表5 FW-8865吞吐量测试结果(两组桥,1组双向流量+1组单向流量,同模块)
表6 FW-8865吞吐量测试结果(两组桥,1组双向流量+1组单向流量,跨模块) 需要说明的是,以上所有测试结果都是在NCPBench中设定一个vcpu(即一个物理核)做管理、两个vcpu做I/O时得到的。我们也尝试着使用除了管理核外的其它所有3个vcpu做I/O,但测得的性能并没有像预期那样线性增长,反而会略有下降。但当NCPBench运行在“转发+简单业务”模式时,两个vcpu情况下的性能会有超过20%的下降,3个vcpu时的性能则不受影响。这至少说明在第二种情况下,处理器的负荷仍未达到100%,理论上可以在保证速度的前提下进行更加复杂的业务处理。
测试后记:x86,真的开始给力了 自从2月28日刊登第一篇内容开始,本专题已陆续进行了9期连载。我们与读者朋友们一起,回顾了x86平台在网络通信领域的应用历程,也分析了曾经活跃在市场上的一些产品解决方案。此后,我们开始了网络通信硬件平台的实际测试工作,对几款目前主流的x86解决方案进行了分析,亲眼见证了其规格与性能不断提高的过程。虽然它们与同级别的专用产品解决方案相比仍不占优,但差距已明显缩小,表现出一定的市场竞争力。而英特尔最新的Sandy Bridge平台在测试中表现出的超群实力,完全扭转了之前的被动局面,达到业界领先水平。在用户业务逐步由网络层转向应用层的今天,x86平台凭借I/O与计算能力方面的综合优势,也有机会去赢得更多的市场。如果说以前英特尔在网络通信领域处于追随者的位置,那么Sandy Bridge平台的横空出世,则意味着这个通用领域的巨擘已经站在了该领域的最前沿,抢占了云时代的先机。 链接:“企业级”价值何在? 今年4月,英特尔面向四路及四路以上服务器市场发布了代号为Westmere-EX的Xeon E7系列处理器。一同发布的还有Xeon E3,一类面向单路服务器/工作站市场的产品。实际上,Xeon E3就是1月份发布的Sandy Bridge-DT处理器的Xeon版本,它们非常相似,例如一样都是LGA 1155封装,使用的芯片组也同属Cougar Point PCH系列。甚至在价格上,英特尔官方给出的两类同级别产品的指导价也只有很小的差异。
不过,面向企业市场的产品和面向桌面市场的终究还有一些不同。目前,大部分英特尔平台已经走向单芯片组方案,很多功能融合进CPU,因此差异也更多地体现在CPU上。与桌面版本一样,Xeon E3也集成了传统的北桥,提供PCI Express 2.0接口,但它提供了20个Lane,比桌面版本多出4个,较为明显地增强了其综合I/O能力。例如对工作站用户来说,可能需要使用一个x16接口或者两个x8接口连接单显卡/双显卡,同时还需要通过阵列卡连接磁盘系统,并使用高速网卡连接到局域网。这时,桌面级处理器的16个Lane就显得捉襟见肘,虽然设备也可连接到PCH上,但其带宽和延迟均无法与CPU直连的模式相提并论。而对于网络通信应用来说,PCIe Lane的数量直接决定了最大接口数量,自然是多多益善。 第二个差别体现在内存支持上,几乎所有的桌面级处理器都不支持ECC内存。而企业级应用通常都会长期持续运行,它们需要7×24的可靠性,因此所有的Xeon处理器都支持ECC技术。常见的可以检查多位错误并纠正单位错误的ECC内存会自动检测并纠正约99.99%的内存错误,可以消除约1/3的由数据破坏引发的系统出错事件,提升了系统长期运行时的稳定性。 Xeon E3还提供了无内置显卡的版本,这也是一个比较明显但不是所有情形下都能从中获益的区别。笔者在Sandy Bridge测试分析系列连载的第5篇(见本报今年11期第48版)中曾经介绍过,目前所有的桌面版Sandy Bridge处理器中均集成了显卡,它将会与CPU共享L3缓存。如果确定不使用内置显卡,可以通过屏蔽的方式提升CPU可以使用的L3缓存容量,从而提高性能。 Cougar Point PCH的桌面版本是为人所熟知的P67、H67、Z68等芯片组,而其服务器版本则称为C200系列,目前有C206、C204、C202三个型号。它们的区别主要体现在扩展性方面,例如最低端的C202仅能支持CPU提供的16个PCIe Lane,不支持CPU内置显卡,也不支持SATA 6Gb/s端口及Intel AMT 7.0特性。除此之外,C200系列芯片组能够支持更多的TACH/PWM风扇控制信号、PECI(Platform Environmental Control Interface)界面和SST(Simple Serial Transport)总线,C204还可以实现英特尔特有的Node Manager特性,可以监控管理每个节点的能耗。以上多种企业级特性,对提升网络通信产品的可靠性来说有着非常积极的意义。(文/计算机世界实验室 盘骏) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
  (3个打分, 平均:4.67 / 5) (3个打分, 平均:4.67 / 5) |


雁过留声
“《给力吧,x86》专题连载九:英特尔Sandy Bridge平台网络通信性能测试分析”有57个回复
难道是用了DPDK?标准LINUX不可能达到20Gbps的小包吧
一直在关注你们对X86用于通信所作的努力,感谢老韩!
这个测试也印证了我最近对SNB线速64B/20G可行性的猜想。对于文章结尾提到的E系列服务器平台,我推荐关注1620(尚未上市)和1220L。
E5-1620价位比2600稍低不到300刀,却支持ECC,LLC也到了10M,缺省主频也提高到了3.6,然后最重要的还是支持四通道DDR和PCIE3(这两个东西简直是做通信杀人放火的必备武器啊,非常期待40G测试又能给我们树立怎样新的标杆)!!!不过缺点是主板socket不兼容1155,是2011的,而且功耗有些高,不过由于是单路方案尚可忍受
至于E3-1220L,作为低功耗(20w)、低成本($189)方案,由于直接兼容2600一样的1155槽位,也很希望能立刻看到只有两核的它在20G/40G下的表现,也再次印证CPU的瓶颈在什么位置
是否方便透露一下,在测试过程中,两个vCPU和三个vCPU场景下,NCPBench是怎么配置82599的吗?——比如设置几个TX/RX/RSS队列,如何设置cpu affinity的,等等
Linux原始的报文流程+协议栈,即使把RSS\中断负载均衡都用上,和上面的测试结果也有较大差距
to 4,要大幅提升性能,这些小打小闹是不行的。Panabit的做法也不算独创,但是确实比较深入。要多思考,我导师跟我说的。
其实没有什么诀窍,一切诀窍均在于细节和专注!耐下心来,就那么几千行程序,1天50行,也就几个月的事情。
Panabit说得没错,需要像艺术品那样精雕细琢。大公司很难做出这样的事情,大家以完成KPI了事,代码堆砌而已。
从测试结果看,NCPBench简单转发模式应该用了零拷贝。否则,双通道1333只有20GB带宽,而40Gb则需要两进两出40*4/8=20GB,已经是内存的理论带宽了,没损耗是不可能的。
如果做业务,意味着要对包头进行分析,CPU必须要读进去内容,不知道这时是否要对82599做一些hacking,并利用Intel IOAT,比如设置header split,对header做DCA操作,硬件辅助一些stateless操作如checksum检测计算等。
请问header split对性能的收益主要体现在什么方面?如果要做7层内容检测(不仅仅看header)的话,split还有没有优势?
split会把报文分解为不连续的内存区域,在一定程度上加大了编程的复杂度(当然也不是不能处理)
对7层业务,不是每种业务的每一个包的payload都需要处理。那样的话,就没有所谓fastpath和slowpath了。在一个应用流的前面部分被识别后,后面的报文可以走fastpath,这时候header split就会体现出价值
多谢指教!
sandybridge的io能力不错,但我认为还可提高,还有未调好的地方
cache,cache是性能的关键
回11楼:的确是这样,还有优化的余地。
To #7-#10:
Intel已宣布不建议在82599上使用header split,它会触发一个hw的BUG.
给一个Sun/Arista的Andy关于10Gbe的文章,文中提到了Intel收购了Fulcrum Microsystems,10年(2001-2011)来,Intel的CPU性能提高了100倍但大多数的网卡还是1G。一个Arista单chip的switch和思科6509的比较,同样的吞吐量,Arista用1U的空间和125W而思科用了15U和5000W。
http://www.aristanetworks.com/en/blogs/?p=551
我没有权限,但从现象看,Arista的EOS应该是基于X86的:http://eos.aristanetworks.com/2011/11/running-eos-in-a-vm/
confirmed, it is x86 http://eos.aristanetworks.com/wiki/index.php/What_is_the_EOS_naming_convention%3F
NCPBench的结果肯定不是X86的最好性能结果,相信还有提高的地方。NCPBench只是给大家抛砖引玉,向大家说明,X86目前至少是能达到这样的性能的。另外,目前国内有好几个团队具备这样的性能能力,只是它们“可能”还没有形成自己的体系,还是依赖于操作系统内核。
@14
can you show the link of the bug?
目前正在接触一些国内团队,商讨本专题后续内容的合作可能性。也欢迎与我交流,邮件是hanxu0514 艾特 gmail。com
对在X86上用户空间转发性能做到足够高,可以看看这个成熟的开源实现: http://info.iet.unipi.it/~luigi/netmap/
1.2G的CPU中的一个单核可以做到14.88Mpps的线速报文生成,并且可以做到10.66Mpps的简单转发;换言之,如果有三个流,被网卡RSS分配到3个core上,完全是可以达到31Mpps的转发能力的。
呵呵
至Panabit,麻烦问题一下,NCPBench 0.8是内部测试工具嘛,可以提供下载嘛,期待中~
@20
1. 1.3G CPU是报文生成。不是报文转发。
2.你的换言之是不成立的。
一个core能达到10.6mpps是因为这哥们占用了所有LLC及membw。多core竞争的情况性能下降是很明显的。
@23
Intel CPU在多核调度时cache的实际表现如何没有深入研究过,但Cavium这样的CPU里面,packet i/o 直接进cache,如果不查大的外部表,memory带宽对数据流没有任何影响;而对于报文而言,貌似每单个报文对cache的消耗可以忽略不计吧。即使在有外部表的情况下,prefetch机制也可以把对memory带宽的消耗减到最小,所以其性能scale up的能力很强,至少在8-10个核以内,实际程序中看到的资源竞争,一是来源于软件临界区的锁等待,二是来源于报文保序(对于单流而言,硬件保序此时成为了瓶颈,要是多流反而不存在问题),而看不到太大的非软件实现类的瓶颈(即你说的带宽瓶颈)。
intel没有花心思去做报文的硬件保序调度,所以发明了个RSS来解决同一流调度到同一核的东东来实现伪scalability,至于这种伪scalability对LLC/memory利用效率的实际效果如何,我的确不应该拿C家上的效果往Intel上生搬硬套。当然,要是其实际效果有问题的话,倒可以从另一个侧面证明,X86做高性能网络处理,还是有致命缺陷的。
恩。scalability的前提是大伙不竞争share的东西。如你所说,CVM和RMI在做芯片的时候已经替你操心过这些问题了。
intel最大的好处和最大的坏处就是不用程序员操心cache。这哥们生为desktop/server,只是拿来做网络处理罢了
dotslash能详细解释一下为什么每单个报文对cache的消耗可以忽略不计及prefetch机制怎么把对memory带宽的消耗减到最小吗?最小是多小?谢谢
“prefetch机制也可以把对memory带宽的消耗减到最小”,这句话做和解释?我也想知道
各位大佬,小弟对Cavium一无所知,请问硬件“报文保序”的确切含义是什么?
A. 是纯2层的概念,跟任何flow无关
整个系统呈现FIFO行为,先进入系统的报文一定先发出去
比如报文按a/b/c/d顺序到达,一定按a/b/c/d的顺序进行转发,不关心a/b/c/d是否属于相同的flow(以及4层的序列号)
B. 比A弱一些,多核情况下仅保证单核是FIFO行为,多核之间可以出现乱序
比如报文按a/b/c/d的顺序到达,a/c分给core#0,b/d分给core#1,b/d可以在a/c之前离开系统
C. 仅保证单个flow的满足FIFO模型,不关心flow之间的顺序
比如报文按a1/a2/b2/b1的顺序到达,a1/a2属于flow#1,b2/b1属于flow#2,b2/b1可以在a1/a2之前离开,注意没有调整b2/b1的顺序
D. 系统保证单个flow按照4层的序列号离开系统(非FIFO模型)
这个是最常见的tcp流重组模型,不关心flow之间的顺序——但是对于udp而言,这个有意义吗?
C和D的区别在于,对于单个flow,如果输入是乱序的,C保持乱序,D要纠正乱序
C
#24,
1. RSS is a Microsoft invention not Intel one. Please check it up.
2. Since no prefetch can guess 100% right, I doubt one can ignore the cache miss rate when processing a packet.
在82599做Intel的DCA时,配合header split有个麻烦:不支持程序配置任意长度的”header”。最好的always方式,也要先自以为是判断一下它理解的所谓“header”,如果它判断出来了,就结束了,判断不出才会读取一定长度的认为是包头。这对于任意复杂封装的包头(比如各种隧道格式)不太合适,DCA能力发挥不好。
当然,这不是IOAT架构问题,只是NIC实现问题。如果下一代NIC能做到程序定义什么是“header”,至少我可以自定义比如头128个byte是header,那就会好很多
to 根本不相干,
你要的DCA,首先要能够识别报文。”任意复杂封装的包头(比如各种隧道格式)”,如果只是ASIC方式的配置寄存器来识别提取,比较困难(特别是私有封装)。
然后才能根据报文识别,控制每一个报文需要缓存报文头长度。
这个玩意,XLP可以做到。它的前端微引擎(就是16个mips ucore,c代码编程),然后可以对每一个报文就行单独控制缓存报文头长度
http://info.iet.unipi.it/~luigi/netmap/
I read their INFOCOMM’12 paper but find out the forwarding/switching rates are around 3-4Mpps, far from 14.88MPPS.
It seems thet did NOT run any IPv4 routing algorithm. The real performance should be less than what they reported
Last but not the least important they use only one core to do experiments, avoiding the hard issue of how to make good use of multi-cores???
to Matrix
不是,不需要识别报文,它只需要把我配置好的给定字节数(比如128B)当成“header”送上去就行了。剩下的工作,交给软件。
to 阿土仔:
关于28/29楼,“仅保证单个flow的满足FIFO模型”,从实现的角度而言,是不是每个flow所有的报文去的一个固定的core?这样才能保序。
这样的话,在进入选择进入哪一个核之前,应该有一个器件:从packet里识别出一个流(譬如五元组),给报文tag一个flow id,然后再去不同的core进行处理。
不知道我理解的对不对。
多谢
“仅保证单个flow的满足FIFO模型”仅是必要条件,如果保证进入CPU的报文和出去的报文都是保序的,其实也满足了这个条件。因此一条流是否进同一个core,是不需要的。但是能够直接分发到不同的core是比较好的,这样core之间的影响会小。
832是64K虚拟流,就是你说的给报文tag一个flow id,但没有实际流那么多条
to 36楼,一个流进入不同的core,还能做到保序,这个需要软件干预,还是纯粹硬件的功能?
一个流进入不同的cores是一个被证明的不好的选择,在实际中没有人会采取这种做法。
to 38:这个依赖于所用芯片的硬件保序设计,比如732没有硬件保序功能,那只能软件做
to 39,40楼,谢谢。不同core之间对同一个流保序,如果是软件保序,能否提供一个伪代码片段描述?如果是硬件保序,能否提供一篇文章,描写电路如何实现?
关于X86做TM:
其实,目前的网卡已经具备一些简单的辅助功能,比如82599支持128个queue,和8个优先级的packet buffers,可以完成一些基本的TM/shaping
Descriptor Plane Arbiters and Schedulers:
• Transmit Rate-Scheduler — Once a frame has been fetched out from a transmit rate-limited
queue, the next time another frame could be fetched from that queue is regulated by the transmit
rate-scheduler. In the meantime, the queue is considered as if it was empty (such as switched-off)
for the subsequent arbitration layers.
• VM Weighted Round Robin Arbiter — Descriptors are fetched out from queues attached to the
same TC in a frame-by-frame weighted round-robin manner, while taking into account any rate
limitation as previously described. Weights or credits allocated to each queue are configured via the
RTTDT1C register. Bandwidth unused by one queue is reallocated to the other queues within the TC,
proportionally to their relative bandwidth shares. TC bandwidth limitation is distributed across all
the queues attached to the TC, proportionally to their relative bandwidth shares. Details on
weighted round-robin arbiter between the queues can be found in Section 7.7.2.3. It is assumed
traffic is dispatched across the queues attached to a same TC in a straightforward manner,
according to the VF to which it belongs.
• TC Weighted Strict Priority Arbiter — Descriptors are fetched out from queues attached to
different TCs in a frame-by-frame weighted strict-priority manner. Bandwidth unused by one TC is
reallocated to the others, proportionally to their relative bandwidth shares. Link bandwidth
limitation is distributed across all the TCs, proportionally to their relative bandwidth shares. Details
on weighted strict-priority arbiter between the TCs can be found at Section 7.7.2.3. It is assumed
(each) driver dispatches traffic across the TCs according to the 802.1p User Priority field inserted by
the operating system and according to a user priority-to-TC Tx mapping table.
Packet Plane Arbiters:
• TC Weighted Strict Priority Arbiter — Packets are fetched out from the different packet buffers
in a frame-by-frame weighted strict-priority manner. Weights or credits allocated to each TC (such
as to each packet buffer) are configured via RTTPT2C registers, with the same allocation done at
the descriptor plane. Bandwidth unused by one TC and link bandwidth limitation is distributed over
the TCs as in the descriptor plane. Details on weighted strict-priority arbiter between the TCs can
be found in Section 7.7.2.3.
• Priority Flow Control packets are inserted with strict priority over any other packets.
• Manageability packets are inserted with strict priority over data packets from the same TC, with
respect to the bandwidth allocated to the concerned TC. TCs that belong to manageability packets
are controlled by MNGTXMAP.MAP.
楼上的,你说的这些特性,我估计Intel自己都没用过
这8个TC是为DCB做的,应该还是有一定应用空间的
不过Intel没用过很正常。我记得当初做产品开发时,测试人员比开发人员对设备熟多了,N多花样开发人员自己都不知道还可以这么玩:)
http://tech.sina.com.cn/it/2011-12-30/08396585208.shtml
英特尔承认上网本销量下滑 寄望于新兴市场
intel 不会停了现在的ATOM把
ATOM不可能停的,ATOM应该是Intel未来一段时间在嵌入式领域的主打产品,昨天刚有新闻稿说又交付了一批新型号开卖。
老的型号,新的型号好像都要SOC了,更加适合平板,手机,是否可以提供大量PCIE或者网络能力呢? 不知道INTEL是否会把面向手机,平板的芯片做的能够非常适合网络用。 如果新的ATOM出来了,老型号量就会大量被取代,不停产,估计价格也不会再这样好了把。
英特尔在第二季度彻底停产前,将减速生产酷睿i5-661/660、酷睿i3-530、奔腾E5700和赛扬E3500处理器。
此外英特尔应该也会在2012年第二季度停止生产酷睿i7-960/950/930/870/880S/870S、酷睿Core i5-2300/680/670、酷睿E7500/E7600、奔腾G960、E6600/E550以及赛扬E3300处理器。而酷睿i7-875K/860S、酷睿i5-760/750S/655K和赛扬450/430处理器在第一季度就会停产。
Intel和6wind有一个测试数据,含L3转发(但没给出路由表数,估计不大最多几万条,至少应该都能命中LLC,否则感觉不太可能)
怎么贴PDF文件?想贴出来供大家参考一下
基本数据是:
E5600每个核14-18M pps,单路3个核达到饱和42M pps(估计受限于内存和IOH),
E5600双路6个核达到饱和84M pps(应该是内存和IOH翻倍了);
sandy bridge E5每核心转发性能差不多,单路6个核达到饱和86M pps(果然SNB的内存四通道和IO能力远超前辈)
貌似做NPC没人用4通道,4通道只有高端发烧友用得上。对于带上安全业务的软件系统来说,4通道的意义也不大。
4通道已经出现在很多200-400美元的CPU上,本身价格已经不是问题。
但是,8核心CPU是否适合做NPC,确实需要探讨。8核心主频上不去,价格也贵。
目前的工艺来看,4核心是性价比不错的主流选择,而此时对应的2通道或3通道应该也能满足要求。
看了好了,大家都在讨论软件方面的问题,不敢发言,一直在做X86平台的网络安全的主板的硬件方面,看着x86系统性能的逐步提升,从当年的815系列,到后来的845 865 945 7520 965 G41 一直到现在的Q67(Sandy Bridge)系列,与之搭配的网卡性能也逐步提高,到现在能在64k的小包下能达到线速,感觉intel在这方面还是不错的,大家都在谈论软件的,是否可以讨论一下硬件方面的东西,比如说系统的搭配,哪种硬件的扩展方式更适合客户使用,平台搭配何种的网卡能更好的发挥性能,请大家不吝赐教
how about this:
Intel’s next-generation communications platform, Crystal Forest, is expected to deliver up to 160 million packets per second performance for Layer 3 packet forwarding, making it possible to send thousands of high-definition videos across each network node. Previously, only ASIC or specialized processors were capable of sending more than 100 million packets per second. The Intel (R) Data Plane Development Kit, a set of software libraries and algorithms, improves the performance and throughput of packets on Intel architecture platforms to yield more than five times the performance over previous generations of Intel platforms.
http://newsroom.intel.com/community/intel_newsroom/blog/2012/02/14/intels-next-generation-communications-platform-key-to-accelerated-network-services
使用风河Wind River提供的Crystal Forest平台的模拟模型加快下一代通讯平台的软件开发、测试和集成
英特尔已经披露了代号为“Crystal Forest”的下一代通讯平台的一些重要功能。这个通讯平台是建立在英特尔在通讯基础设施领域的强大的基础之上的,将更有效率和更安全地管理整个网络的数据处理,同时,满足处理云连接和内容处理的特殊需求。
英特尔称,一天中的每一分钟整个网络将上载30个小时的视频。到2015年,每一秒钟向IP网络上载的视频大约需要5年时间才能看完。随着这个数字的继续增长,这个负担将落在设备厂商和服务提供商的身上。他们要提供一个解决方案以节省成本的方式管理日益增长的通讯量,同时不影响性能和安全性。
采用英特尔的“Crystal Forest”通讯平台,设备厂商将能够把三个通讯工作量(应用、控制和数据包处理)整合到多核英特尔架构处理器以提供更好的性能和加快产品推向市场的时间。厂商还可以根据多个英特尔处理器的选择开发一种具有伸缩能力的产品,为将来提高性能做好规划。
英特尔下一代通讯平台Crystal Forest能够为3层数据包发送提供每秒最多1.6亿个数据包的性能。,使它能够在每个网络节点发送数千个高清视频。以前,只有ASIC(专用集成电路)或者专用处理器能够每秒钟发送1亿个以上的数据包。英特尔数据平台开发套件(Data Plane Development Kit)是一套软件库和算法,改善了英特尔架构平台上的数据包的性能和吞吐量,比上一代英特尔平台性能提高了五倍。
英特尔Crystal Forest平台将让设备厂商设计出更灵活的平台,包括从小型和中型企业防火墙到高端路由器等多种设备。
开发者能够使用英特尔全资子公司风河(Wind River)提供的Crystal Forest平台的模拟模型加快软件的开发、测试和集成。
http://news.mydrivers.com/1/217/217805.htm
最新猎头职位:京深:攻防研究(渗透 漏洞挖掘)/架构(产品线 通用网络平台)/系统工程师/测试/LinuxC/java工程师/大客户销售(金融)、深圳:市场技术总监/产品运营经理/金融售前产品经理/区域销售总监(广州、深圳、福建、海南、江苏、西北)、成都:VPN研发 联系qq:2594873804
看完了x86平台的所有测试专题,有个疑问就是在各种测试场景下的CPU占用率是怎么样的?好像一篇都没有提到这一点,是否所有的测试条件下CPU的计算能力都不是瓶颈?