




GFT你这么diao,你的伪粉丝们造吗(3)
作者 彩筆 | 2014-05-21 01:37 | 类型 大数据, 行业动感 | 1条用户评论 »
|
GFT 3.0: updated (2013) 副标题:旁观一个技术主管的verbal reasoning ability
注:本文“内容”若非特别注明,均来自“Copeland P, et al. Google Disease Trends: an Update. International Society for Neglected Tropical Diseases. 2013. available at: http://patrickcopeland.org/papers/isntd.pdf”一文。
GFT 2.0针对GFT 1.0对非季节性流感的Underestimate做出改进(在建模过程中增加了09年H1N1爆发期间的检索数据)。GFT 3.0是针对在2012年流感季节,GFT 2.0对实际数据的overestimate作出的改动。 第一次更新时,GFT 1.0 underestimate的原因被归结为季节性流感和非季节性流感期间用户的health-seeking behavior不同,但并未明确指出究竟为何不同。 在构建GFT 3.0时,GFT团队将导致GFT 2.0 overestimate的原因归结为媒体的放大效应。表现为:大众媒体对流感疫情的报道,使更多的未患病个体也进行flu-related检索,导致检索词出现次数与ILI病例比例之间原有的数字关系不再“有效”。
作者尝试在文章中给出以下问题的答案。 1. 为什么12-13年度的流感季节中,GFT的预测过高?Why were this season’s predictions so high? 2. GFT模型是否过于简单粗暴?Is our model too simple? 3. GFT 2.0中是否仍有未考虑到的影响因素?Were there unforeseen side effects from the 2009 update? 4. GFT是否能表现出CDC的ILI数据之外的现象?Does this reveal a phenomenon not captured in incidence data provided by the US Centers for Disease Control and Prevention (CDC)?
旁白:都是好问题,从实际问题出发(overestimation),既有对GFT本身的反思(too simple),也对有关GFT的舆论做出回应。层层递进,有理有据。
1. 怎么就overestimate了 GFT 1.0刚上线时,计划对它每年更新一次。然而在GFT 2.0和GFT 3.0之间,未有annually update。原因是,每个流感过后对GFT模型评估,GFT 2.0的表现so far so good。团队的观点是:不断添加新数据确实能够提高估计的准确性,但对于truly anomalous years的情况无改善。 GFT 2.0一直doing well,直到2012-2013 flu season,模型输出的预测结果明显偏离了真实数据源,(However, in the 2012-13 season, the overestimation peaked at 6.04 percentage points, an estimate more than twice the CDC-reported incidence (week starting Jan. 13: CDC data 4.52%, GFT estimate 10.56%).),drastically overestimated peak flu levels [1]。
2. 简单粗暴,不失有效 GFT团队承认,他们的算法容易受到短期内检索词数量不规则变化的影响,而这些“数量的不规则变化”可能是concerned people对流感相关的媒体报道做出反应的结果。(所以,GFT的直接目的是预测CDC ILI data,但它所能描述的远不止于CDC ILI data。) GFT团队在承认他们的算法sensitive to sudden changes in query volume的同时,也巧妙地表达了不能公开组成模型的检索词的必要性。作者回忆在2008年发布GFT 1.0时,New York Times的一篇报道碰巧包含一个模型中的检索词。他们马上就看到了这条检索词流量的增加。笔者不禁想到,Lazer [2]在他的文章中一边要求Google公开GFT的内部细节,一边也担心所谓的red team issues(用户有预谋地操纵“数据生成过程”),是赤裸裸的自相矛盾啊。
3. Unforeseen side effects肯定是有的了 基于上述推理,GFT团队进一步修正了模型,以摆脱媒体报道的影响。 (1)为降低算法的sensitivity,GFT团队用“spike detectors”监测数据中inorganic检索词流量,并将其从模型中剔除。做法:The system receive time series data of the flu-related queries as input and validates whether the latest counts are within expectation, based on statistical variations from what we have seen in the past. 从2008年以来的数据得知:大多数由新闻报道引发的关注所导致的query spikes大约持续3-7天。这种情况导致,上述处理过程只能solve for short-term spikes,对在整个流感期间延续的high query volume无能为力。 (2)除此之外,作为对于外界普遍吐槽的GFT模型简单的回应,GFT 3.0也尝试了几个高大上的优化算法。
LARS是更适合高维数据(比如:变量数多,案例数少)的一种回归算法。在对多个自变量回归分析,得到1个因变量的预测的分析过程中,LARS算法可以确定哪些自变量参与回归,并得到这些自变量的系数。
LASSO和Elastic Net均是对回归模型进行规范化(regularization)的方法。LASSO(Least Absolute Shrinkage and Selection Operator)的penalty function为
。Penalty function为包含λ1(线性)和λ2(二次)的部分。 写这些并不是为了让每个读者都看懂甚至理解,而是为了给大家营造一种身临其境的感觉:GFT不再是那个国内本科学生毕业设计的非专业水平了。各个优化版本模型的预测效果可见下图。
从图中可以明显看出Current Model对CDC data的overestimate,但究竟哪个优化的模型效果最好却不显而易见。特此为每个模型的预测输出计算RMSE,Elastic Net的RMSE最小(1.22),即其效果最好。
写在最后的话 纵使笔者心中仍有千万次的问,作者的文章到此便戛然而止了。笔者很忧伤,却也毫无办法,只能开始总结。 从逻辑上讲,GFT的一切行为都是合理的。对于在每一处关键点上的选择,不排除其他alternatives的存在,但是不存在比GFT的选择明显更优的处理方式。 纵观整个GFT模型更新的过程,第一次更新向仅有季节性流感数据的旧模型添加非季节性流感的数据,自此,GFT双腿健全,可以稳健地丈量CDC数据。 CBS热播剧《BONES》中的starring actress有一句频繁出现的台词:I believe in patterns。还没想清楚的人不妨认真考虑一下了:GFT并不是literally“神来之笔”,它的诞生机制和工作原理决定了它的输出结果(对CDC数据的预测值)是依赖统计学习习得的“规律”,将现有值与未来某时间的“可能值”建立联系,而已。期待它给出一个确定的真实值这个愿望是不切实际的。 私以为,pattern比truth更加客观。每个人都可以把自己坚持的称作“真理”,并拒不接受说教。Pattern却不然。A出现10次中,有8次B也同时出现(贝叶斯[崇拜样]),这就是一个pattern。下次A出现时,笔者愿意投入成本做好B伴随出现的准备。也许有人会问,会不会A出现的10次中B也出现10次?To这样可爱的同学:当然会啦。只是这样的情况,如何确定B不是A的天然组成部分)?哈利波特偷偷去霍格莫德村,穿着隐形衣帮忙打架,不小心将头露了出来,马尔福少爷回学校打小报告时的推理过程是这样的:你的头出现在了那里,那么你的身体也一定在那里。See the beauty of uncertainty。换句话说,当pattern变成了“注定”的(definite),也便失了趣味性。【写这一段的目的是想传达:GFT是应用统计学习方法做出来的一个产品,各界都需要调整好对GFT的期望值。同时,也从逻辑上引出下一段。】 所以说GFT团队的vision也是极其精辟的。对GFT的第二次更新并没有纠结那些学者们不肯放手的检索词问题,可重复性问题——这些都不重要。GFT的核心矛盾必须是对统计学习方法的无上限的完善过程好么。按照大数据的处理思维,从原始数据中直接捞出来的(may not be perfect),但一定是best | available了。文章[3]点到为止地总结了入选模型的几个检索词的主题,以及数量和体量(占比)等,只不过是可视化不可见“模型”的一种手段而已。一些矫情的人类个体给点儿阳光就灿烂,嫌弃“描述性”的内容太少,各种,已经不单是避重就轻的迟钝,甚至是买椟还珠的愚蠢。 GFT的第二次更新考虑了多种优化模型的算法,反映了统计领域的state of art,不管从战略还是战术上看,都妙极,妙极。
关于副标题:都说是“旁观”了,顺便看一下得了。总的来说,原文是一篇虎头蛇尾的文章。前面铺垫的絮絮叨叨,像极了革命战士喜欢的千层底儿的鞋,结尾却只有戛然而止,断没有余音绕梁,徒留笔者独自在电脑前神伤好嘛。
相关文献: [1] Butler D. When Google got flu wrong[J]. Nature, 2013, 494(7436): 155. [2] Lazer D, Kennedy R, King G, et al. The Parable of Google Flu: Traps in Big Data Analysis[J]. Science, 2014, 343(6176): 1203-1205. [3] Ginsberg J, Mohebbi M H, Patel R S, et al. Detecting influenza epidemics using search engine query data[J]. Nature, 2009, 457(7232): 1012-1014. | |
 (1个打分, 平均:5.00 / 5) (1个打分, 平均:5.00 / 5) |

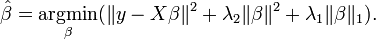{kind=link}
雁过留声
“GFT你这么diao,你的伪粉丝们造吗(3)”有1个回复
应该不知道