




WLRU专利的非专业解析
作者 kevint | 2011-02-12 21:45 | 类型 弯曲推荐, 芯片技术, 行业动感 | 68条用户评论 »
WLRU专利非专业解析
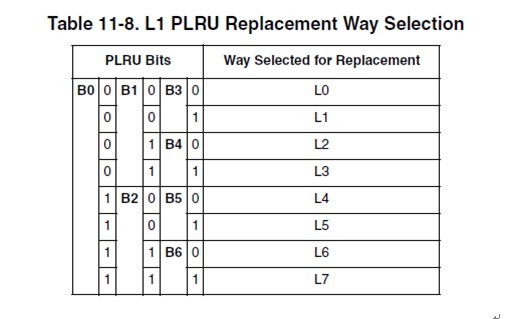
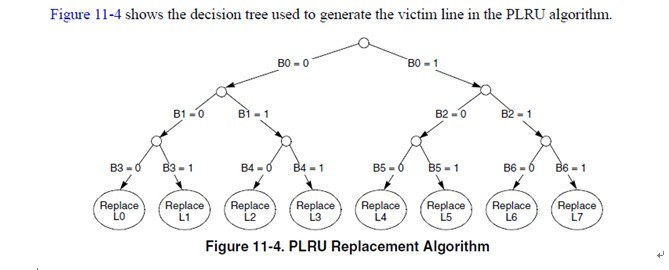
11.6.2.1 PLRU Replacement Block replacement is performed using a binary decision tree, PLRU algorithm. There is an identifying bit for each cache way, L[0–7]. There are seven PLRU bits, B[0–6] for each set in the cache to determine the line to be cast out (replacement victim). The PLRU bits are updated when a new line is allocated or replaced and when there is a hit in the set. This algorithm prioritizes the replacement of invalid entries over valid ones (starting with way 0). Otherwise, if all ways are valid, one is selected for replacement according to the PLRU bit encodings shown in Table 11-8.
注意,红色的字体是与王大师的WLRU关键的不同点。在e500的cache中,选择victim是在set select中。每一个set,有7个bit用来做cacheline的weight。
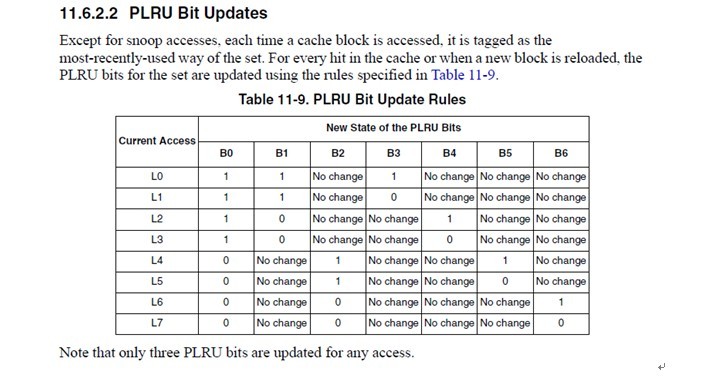
这个真值表简单明了,我就不多解释了。 所以当某个line hit的时候,或者当某个line refill到达的时候(其实line refill到达的时候也相当于hit after miss),cache logic根据这个表,更新cache set的这几个bit。 cachemiss的时候,再根据b[0:6]找出一个line换出去就完事了。 一般CPU的PLRU就是这么做了。当然,也可以像某些MIPS那样,random选一个完事。 7.王大师的WLRU是怎么做的
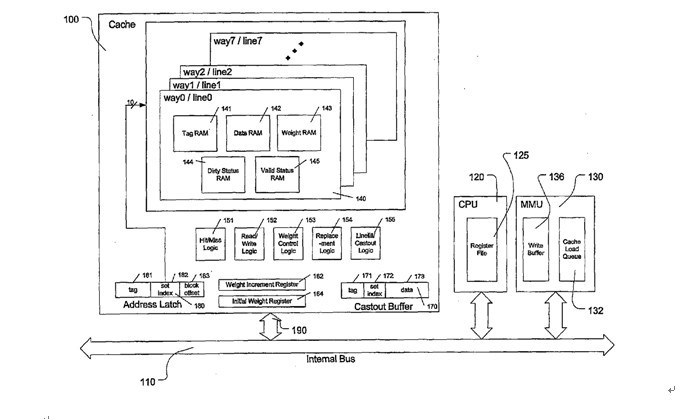
这是王大师专利中的系统框图。 注意一点,就是一个set中,每个cacheline都有一个weight ram。这点与e500不同。e500的victim select是在set select选中后,根据PLRU[0:6]选中一个line。如果WLRU 的weight ram存在每一个line中,那么每一个line都要参与weight的比较,才能算出最终的victim line。这样无疑会增加cache lookup的延迟。 王大师是这么描述的
WLRU的配置 WLRU用“i-r-b”作为weight的算法的参数 i,increment,cache hit后weight的步进。 r,upper limit,weight的上限 b,初始weight。 如i64r128b2。cache hit一次,weight增长64,最大增长到128. cacheline初始weight 为2. 每当cachemiss一次,weight减一。
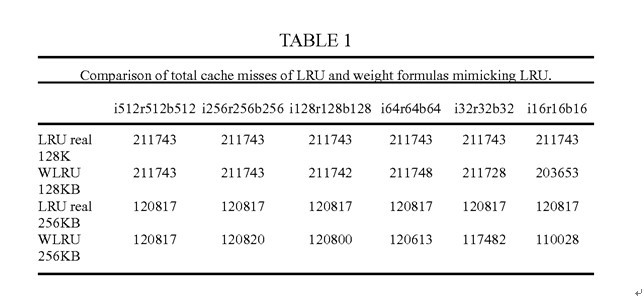
这是王大师在专利中给出的数据。与真LRU比较,证明自己的算法在r比较大的时候,是可以接近真LRU的效果。 这里王大师又搅了一次混水。证明自己的算法在某种情况下可以达到美好的理论值,但是没有详细做横向比较,比如其他LRU算法,跑同样的测试,能达到什么效果。
也没说跑的什么测试例,最后扔下这么一句话,横向比较算做完了。 更尴尬的一点,抛开这个“more than 30% fewer”句型,cache miss rate低30%以上,让人如何理解。比如原先PLRU的miss rate是1%。你低30%。那你就是0.7%。假如PLRU hitrate是99%,WLRU的hitrate就是99.3%。群众关心的综合的performance boost是多少。没说。 回到现实,看看王大师的weight ram实现的成本如何。拿专利中r256为例吧 如果upper limit 是256,那么每个line 要8个bit做weight ram。按照1valid+1dirty+19tag+256data=277bit。增加8个bit,大概增加8/277=2.8%的面积。这个数据,可能就是王大师所说的“WLRU相比于Pseudo-LRU(目前广泛使用的LRU的低代价实现变种)只多2%的晶体管,电路成本的增加微不足道。”的来源。 虽然费料不多,但是这里费时才是关键的。 每一个set要多一个8in 8bit的比较器做weight比较。这个就比较要命了。 另外,当某一个line hit的时候,需要increase它的weight。需要读出weight increment register,再从ram读出当前weight,加起来,比较是否超过了upper limit,如果没超过,再写回weight ram去。cache miss的时候,还要decrease所有line的weight。8条cacheline啊,这些都是要r-m-w的。这cache access的latency。我敲这些字都觉得罗嗦。 所以,这个WLRU做L1 CACHE是没戏了。这点也跟王大师的宣传类似,从哪搞个core,外面挂个WLRU的L2,大力丸子场就算搭起来了。 总之,理论基础铺垫完了。结论也只说能降低“miss rate”. 至于performance boost rate,没提。 8.回到现实—CWLRU 王大师也应该知道,r256,r128的模型只能在论文里做,现实是做不出来的。拿什么救场了。CompactWLRU横空出世啦。 CWLRU使用2bit做weight,并且在每一个cache set增加了一个reference counter。当line hit的时候,weight加1。miss的时候,先decrease reference counter,当reference counter到达某一个threshold的时候,再decrease 所有cacheline 的weight。 weight ram正常情况只有+1和-1的操作,所以可以用counter ram做。不用再读那个weight increment register了。 decrease 1的操作也用reference counter做了聚合。 所以,这个CWLRU,是对上面那一系列繁琐的操作做了一个简化。reference counter越大,weight采样的偏差就越大。 正常人应该看出来,这个CWLRU是非常狗屎的一个近似。。
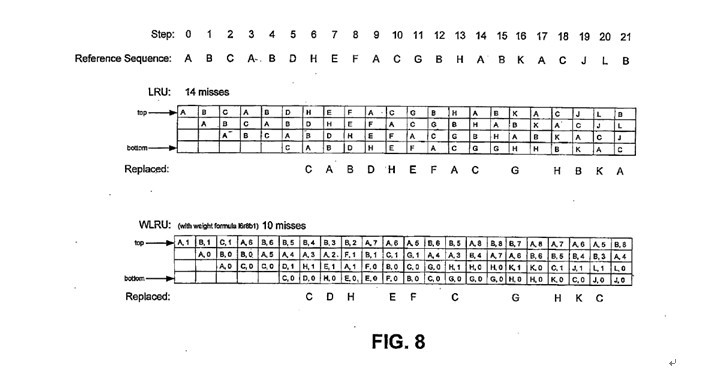
无奈王大师再次扔了一个丸子出来。。。一句话,把这个狗屎的近似算法扶正了。仍旧没有数据支持。 不管是WLRU还是CWLRU,最最要命的一点,就是有几个软件配置的寄存器。这样一来cache对系统不在透明,至少kernel developer在cpu init的时候需要配这个玩意。配多少?难道真的要application aware? 9.专利是需要证明有实际价值才能通过的。WLRU如何证明自己专利是有价值的呢? 一切答案尽在FIGURE8.
我对王大师在弯曲的第一次回复就说过,如果知道cache的组织结构,随便写个程序,让cache hitrate提高/降低10倍,都不是什么难事。 注意step0到step9. 真LRU的情况下,在step3-step7这5个step中,A没有被reference,所以被置换出去了。 而在WLRU中,因为 恰好step0中A被reference了,在step7时所以A的weight更高,没有被置换出去。 王大师在这里客串了一把刘谦,通过自己精心准备的道具(reference sequence)。证明了在WLRU在4way cache上面,miss rate是真LRU的70%。 这里算手下留情了。构造个狠一点的序列,估计真LRU还要惨。 说到这里,各位看官应该大致明白是怎么回事了吧。 王大师说这几年一直在忙着准备测试数据,估计也还是在享受通过构造各种序列降低cache missrate的快感中把。 10.捅破那层窗户纸—WLRU的本质 写这篇文章的时候,我也在思考。WLRU的价值在哪里。个人观点: 其实,这东西就是想是让那些 使用次数少的数据尽量少占用cache。这也是众多PLRU算法的初衷。标准PLRU算法在开销和预测方面选择了折中。而WLRU加入weight ram就让cache有了更大的记忆,weight ram越大,记忆的时间越长,理论预测的就越准确。当然开销也越大。 所以,这个WLRU并没有什么神秘,如首席所说,Jonh Hannessy还没老年痴呆。 前面说了,就算最简单的CWLRU,仍旧过于复杂。不可能做L1 CACHE。 CWLRU能否应用在L2 CACHE上?我想理论上不是没有可能的。不过我不是做IC的,不知道如何实现。另外,专利中的系统框图与ppc,intel的系统框图比起来基本就是小学生的家庭作业。从他的图看,cache是直接physical index, physical tag的。一般也是L2 cache才这么干。 同时,这个东西编译器应该也可以做一些工作,虽然肯定没有运行时预测的准确。但是,应该也是可以做一些工作的。什么时候编译器能够加上cacheline_size, way_number等参数?是不是也是首席说的cache aware application的一种实现呢。 不管怎么样,cache只是整个CPU系统中的一个子系统,CPU又是整个计算系统中的一个子系统,cache的优化,对于系统的加速比是多少?是否有王大师大力丸子场中描述的那般神奇可以“干掉intel”呢? 11.结语 我与公司一个做cache controller的engineer聊了一下,大致对话如下 我:对cache replacement algorithm有没有研究。 他:一般都用PLRU啊。 我:网上有个人说发明了一种cache replacement algorithm,号称miss rate降低了30%-50。能灭掉intel。 他:你给我一个100%hit的cache我也灭不掉intel。哈哈(此人以前做某主流高性能CPU) 我:他就是这么说的。现在正招商引资呢 他:回国忽悠吧。这边估计是没戏了 我:恩,已经回去了。 | |
  (14个打分, 平均:4.00 / 5) (14个打分, 平均:4.00 / 5) |



雁过留声
“WLRU专利的非专业解析”有68个回复
真给力呀!有弟兄的感觉真好!另外,贤弟,你这1,2年的进步让我非常shock。太好了,静下心来,N年下来,你必定是一个江湖上的高手。。。
BTW,鉴于WLRU的tutu前几天的折腾,为了公平起见,我要把我贤弟的这篇文章置顶N天。。。:-)
感谢首席鼓励
因为WLRU推广文章中商业味太重,盖住了里面技术的东西。我只是把这些东西扒出来,抛个砖让大家回到正确轨道上讨论。免的大家在谩骂中给大力丸子场增人气。呵呵
很好,希望这些精彩的文章能够多一些
这才是好文章!
简明按要,直击核心!
专业,否则是没有耐心把专利看完的,看专利是非常累人的一个活,太细了。
好文章,专业是靠细节表现的,而不是靠无限制的自吹。
因为我不是搞IC的,所以只能是非专业分析。跟同事聊天,才知CPU的水很深。软件看见的只是浅浅的一层。呵呵
强大
回到学校就看到如此文章,弯曲的价值淋漓尽致的发挥出来了
赞Kevin兄。作为基本不懂CPU的草根,只能从土大师狗皮膏药式的语言风格下判语为大力丸,建议大家散场不要被烘托了,还是Kevin兄的真材实料给力
国内的专家们要是这样严肃认真就好了。
赞之,确实有理有据,逻辑思维缜密,套用流行语“很给力”。
这个文章赞的,我这样的“外行”都看得懂,希望tutu可以来反驳,如果能反驳的话,呵呵。
“不管怎么样,cache只是整个CPU系统中的一个子系统,CPU又是整个计算系统中的一个子系统,cache的优化,对于系统的加速比是多少?”
这是亮点,有结论没?
谢谢Mine关心。说实话,kenvin比我专业多了。这篇分析看得我脑门直冒汗。
理客 于 2011-02-13 12:59 上午
赞Kevin兄。作为基本不懂CPU的草根,只能从土大师狗皮膏药式的语言风格下判语为大力丸,建议大家散场不要被烘托了,还是Kevin兄的真材实料给力
—————————————
两个亮点:
1 不懂CPU。
2 只能从语言风格上看内容是否有价值。
被骗的都不是不懂的,是懂半瓶子的。什么都精通才能下判断的人,不是人,要么是god,要么是devil
kevin 你把专利当学术论文看是不合适的,以我的经验,这个专利写的不错.专利只需要解释清楚claim就可以了
当然,Mr Wang把他的论文藏起来,这是他的问题
他的专利是用于L2 Cache,这个好像tutu提过
不过你还是没看明白他的专利,据我的分析,他的专利里真正有价值的,是WLRU-msb,而不是你提到的几种算法,我对WLRU-msb的评价相当不错
其实王大师真正argue的是,对网络,媒体类程序,大部分L2 Cache里的cacheline只会被使用1次,采用LRU实际上在cache里保存的是垃圾,他的WLRU-msb可以把这种cacheline很快踢出cache,而对保留下来的仍然是LRU;
至于他讲的对不对,只能看simulation结果,没做simulation其实是没有资格发表意见的,所以我从来都只是讲要看一下simulation结果
我和Mr Wang没什么关系,我专门查了他在海龟网的所有帖子,我对他的评价还不错,还真是个人物
暂且不说专利,王大师有一个大前提是错误的:
通信系统的代码和数据使用是收敛的,而不是一批没事只访问一次的。基本上收敛在fast path逻辑上。
我调系统时最头痛的是大cache时数据结构分布不均匀。
看到此贴才是弯曲啊,土大师那个系列看得呕吐不止,忽悠半天没点实料,好不容易中间陈首席把王大师论文扒出来了,结果土大师立马联系首席撤掉,说是他的浅显易懂,结果看到最后也没啥实质。终于有能人找了其专利来分析,这下终于看到点东西了
to calio
没钱去买他这个论文。呵呵
你说的对,把专利当论文看是不合适的。等论文放出来,也可以说,把论文当design spec看是不合适的。所以我们就不纠结一些细节的东西了。
这个是用在L2 cache上,因为不可能用在L1上。
你又来了一记钩拳,把WLRU和CWLRU绕过去了,蹦到这个WLRU-MSB。因为他专利里面没有数据,所以我就没有分析。“没做simulation其实是没有资格发表意见的”,你是怎么知道这个不错的呢。
当然,对于“大部分数据只访问一次”的软件模型,这是一种思路。判断逻辑依旧复杂,hit latency仍旧很大。而且这几个bit就不能用ram做了。
按照你的逻辑,如果他这辈子不放simulation结果,我们也只能在大力丸子场充当广大不明真相的群众,强力围观下去了。
我的初衷还是把主题引到技术面上面来讨论,如果王大师/tutu能反驳我的观点,那更加皆大欢喜。当然写的时候也还是带一点情绪的,因为那几篇软文确实有一点恶心到我了。
这才是做实际工作的态度。
如果这种项目都能到ZF拿资金做,想想那都是纳税人的钱呀,心疼!
谢谢各位的关心,我确实不知道各位喜欢嚼菜干不喜欢喝菜汤。广东人是喜欢喝汤的,并认为精华都在汤里面,汤是比汤渣软,可是营养都在汤里面啊。看来弯曲的围观者基本上没有广东人。实际上我把所有的问题都讲过了,概念提出来了,教科书错在哪里也指出来了,我们超越教科书的重大成就自豪地发布了,超越多核和多线程设计思想的单核心设计思想也隆重宣布了,分析方法也荣誉出品了,算法和weight也解答过了,比较三种算法的模拟结果bar chart也贴出来了,为什么我们自以为能超越Intel的论据也长篇累牍解释了,市场在哪里也说明了。大家不是想看枯燥的论文综述、数据分析和论据引述说明这些渣滓吧?好像弯曲以前都没有贴这样的文章的。
可以在饭前饭后喝点汤,你一直把汤当饭给大家喂,群众就有意见了。
看了许久了,今日终于看到正面的批评,孰料tutu还是在搅混水。
“大家不是想看枯燥的论文综述、数据分析和论据引述说明这些渣滓吧?“ — 这些怎么会是渣滓,我们就想看渣滓,拿出来看看啊??
”好像弯曲以前都没有贴这样的文章的。” — 你要是肯拿出来,还怕弯曲不给你开个先河?
“算法和weight也解答过了,比较三种算法的模拟结果bar chart也贴出来了,为什么我们自以为能超越Intel的论据也长篇累牍解释了” — 那现在的这些质疑你倒是一一回答啊??
to kevin
老火靓汤是我最拿手,大家都是有身份有文化有饭碗的人,不至于向我讨饭吃吧?
to queeten
请详细研读前面我帖子下的回复,天地良心,我是把汤料的精华都摊出来了。论文答辩太折磨人,从大学毕业设计到拿个烂校的博士,我经历过好几次了,不堪折磨啊,您老就不要勉为其难了。
“我们发现的内存访问规律和一系列原创的分析方法,澄清了许多概念,彻底改写了教科书。我们的发现和发明是CPU缓存最基本理论的突破”
“内存墙的存在阻挡了Intel的CPU性能的大幅提高,而且目前还看不到任何彻底解决的希望”
“因为内存墙,Intel的竞争对手都陆续赶上了她,Wintel陷入了困境。”
“CPU缓存一直是工业界和学术界研究的重点,但是因为CPU缓存的最基本理论基础有很多似是而非的错误假设。这些错误的理论被长期推崇,误导了许多人。”
“衡量CPU的高端程度,只看CPU缓存的大小,CPU核心的差别对性能的影响微乎其微。 ”
“在缓存领域,特别是CPU的缓存,有许多似是而非的概念,这些概念表面上无懈可击,以致蒙蔽了人们很多年。我们在CPU缓存有许多新的发现,提出了许多原创的分析手段和方法,更正了许多错误”
“多核和多线程于事无补”
“时间局域性原理。CPU缓存理论基础的错误”
“可以说,国外CPU设计思路已经“黔驴技穷””
“无法突破“内存墙”瓶颈,这是LRU算法的根本缺陷造成的。30年来,国外学术界始终没有怀疑过CPU缓存设计的理论基础Principle of Localities和LRU算法”
“大缓存与多核这两种截然相反的CPU设计思路都行不通,就因为“内存墙”是性能的根本瓶颈。不突破“内存墙”一切都是空谈,所以说我们的发现和发明是性能瓶颈的根本突破。”
“不是我们能够打败Intel,而是Intel自己走到了穷途,是“内存墙”这个“物理定律”阻挡了Intel。”
我帮你把你汤里的精华摘取出来了。
我们都是不明真相的群众,被误导了好多年。
我这人耐心不好,不多废话了。以后非技术话题彼此还是省点口水吧。预祝你的公司一帆风顺
本来懒得理你,有好心哥们给你免费建议了还在这里忽悠,不喷两句实在不舒服!
大言不惭说3C模型是个粪坑,WLRU连做大便的资格都不够。
还怪读者不跑simulation,你TMD先写篇专业文章出来-怎么跑的,什么负载,用的什么模型。不知道你装糊涂还是真糊涂,你那个结论图有意义吗,我一分钟都能画个加速比比你高的出来。
看看Intel的方案“QoS Policy and Architecture for Cache/Memory in CMP Platforms”,人家是hw/sw一起上,顺便也学学别人怎么忽悠。都年纪一把了,换个行业-比如做做脑黑金啥的,技术圈不适合你。
图图,要有则改之,无则加勉呀。。。。。。但图图的好脾气还是赞一个的说。是个混江湖的料:-)。
你们真有时间,不用干活吗?
我居然都看完了,真是。。。
下了班总得有点爱好
根据混江湖经验,大凡只谈结论,不给论据的都是忽悠。
码农先生,你觉得我说的中医算法那段对不对?
支持王大师流片实测!烧点钱尝试又如何?
提速20倍!美光宣布混合存储立方体技术
http://news.mydrivers.com/1/186/186180.htm
那XXX的龙XXX芯才是天大的笑话。哈哈!快十年了吧?
Mr. Wang让我想到了黄小宁。
关于这个混合存储立方体技术,CPU用立体封装的DRAM这种构思不是个好主意。
这样做延迟并不多,DRAM芯片本身最少有65纳秒的延迟。缩短连线,节约不了多少。立体封装的DRAM容量很小。
36楼说的是龙芯吧。 龙芯发展慢了一点,不过10年来一直在发展。
龙芯一开始走 desktop 的路子我认为不太合适,导致直到今天还没有能到爆发期。
龙芯垄断中国市场是迟早的事情。现在英特尔已经没什么发展了,一定有人要超越他,我看好龙芯。
lz kevint很有功底,说是非专业我不信。不过就算那个阿土大忽悠,也比这里一堆愤青强百倍。都是读过书的人,怎么那么容易生气?人家就是一个小发现,得意一下,你们却什么纳税人、脑白金、脑黑金、中医、黄小宁都联想上了,你以为你们是联想公司吗?
支持龙芯:)
to tutu
我没看你中医算法的东西,中医就两个算法,好的算法-有效果,坏的算法-没效果。
to 游戏机
你还是回家洗洗睡吧,又一个没常识的。
阿农你都有些神马常识啊?常识常常很不靠谱的,尊重常识是那些人云亦云的没有思想的庸人的借口。
支持龙芯 != 放卫星
龙芯还有很长的路要走
to 中医码农
西医拥趸诟病中医的一个论点就是:同样的算法,得出的结果千差万别。
当然,真正西医医生才懒得讨论这些无聊的话题。
支持40,41。
看来8年前,我离开芯片开发是对了,如今已经做了8年房地产开发。想想至今这国人IT界还是这样混乱,好像都是一群乌合之众啊。
确实是乌合之众。看看这几天的评论,话都不会好好说。
To 房地产商,赶上了中国经济的大船的航向赚了一笔就算了,你敢和我赌下一个十年吗?
TO Tech
下一个十年怎么了?现在国家正在经济结构转型,各公司也积极多元化创新转型,我旗下VC公司正在积极备战,你打算赌什么?
将近20年内的计算机体系结构的论文全部烧掉,人类没有任何损失,只需要安装前人的论文做就好了,处理器设计唯一要做的就是根据应用领域和工艺的情况,将前人的手段组合,折中,平衡好硬件代价,性能,功耗三角就完了
这种替换算法只要一复杂,消耗了芯片面积过大,就不如把CACHE加大就可以了,方便简洁,便于验证,软件的优化是非常重要的,RISC的核心思想之一就是软件的事情软件办
发展cache模拟,反标分析后优化的编译工具倒是非常有用的
TO房地产商:
投网络安全吧,现在网络安全为啥在国内发展不起来?主要是:
1:大家认识不到安全重要性,房地产商最会忽悠这个,都能把你老丈母娘忽悠出来让你认识到房子的重要性。
2:缺少黑客的攻击,所以企业懒得去搞网络安全,这个房地产商也擅长,找演员排队。
3:ZF扶植力度不够,房地产商也会这招,只需要和ZF共同捞钱,ZF肯定帮你解决问题。
所以大家就等房地产商进安全圈了,大家就有钱赚了,哈哈。
玩笑话,勿当真。
>>”我旗下VC公司”
这,这,这不是笔误吧。希望不是敲错键盘了。房地产商,你不觉得你,你,你应该给我发个E。共谋大业?
TO Will Chie:
你没必要如此痛恨房地产业,房地产是一个国家经济发展必经阶段,每个阶段都需要有一个主导产业。
我相信以后IT行业会成为主导产业,但现在没到这个水平。
TO 首席:
风投,现在很多公司都有兴趣在做,这不是什么高端行业,这方面专业人才很多。
房地产商对国产IC还是比较有贡献的,嘿嘿
可能房地产商容易理解ic,一个是论平方米卖,一个是论平方毫米卖,都是沙子变黄金的买卖,而且整个成本结构也都很容易对应起来。
我感觉房地产商是在合适的时间做合适的事情,做过地产对整个经济的理解会更深刻,因此再转型做it,也会比普通的it公司更有发展前途
最近十年搞房地产的都是识时务的枭雄。li的电力和zhu的金融都是国有垄断行业,没有国家政府高官背景没法进去,wen的地产还是给广大有胆识有能力的民间枭雄带来了无穷无尽的机会。房地产的空间还大着呢,现在一线城市抓得紧了,二三四线的房产才开始热闹呢
春节回家,发现3线城市的房价和我之前的想法完全不一样,我们那小县城,好点的房子奔5000了,看架势,还没到头呢
Kevin:
你不做模拟实验,看两眼就推翻一个博士论文,是不可能的!
三哥的空军司令,只看一下照片,就断定J20是模仿。
to brutics:
的确有许多采用非常复杂的智能算法的缓存替换算法。这些智能算法基本无法在CPU中实现。
WLRU替换算法非常简单,比真的LRU都简单,只比PLRU多1%的晶体管。因为替换算法不在关键路径上,WLRU不会增加缓存的时延。
忍者神归“胡汉三”又回来了(此处鼓掌):)
真是忍者神归。。。
你先说说你玩的是WLRU,CWLRU还是WLRU-msb,省得咱们讨论讨论着你又打勾拳。
替换(cache miss)是不在关键路径上,问题是把weight ram做在cacheline上面,cache hit的latency也变大了。
晾晾你的hit to data是几个cycle就行了吗。
还是zf的钱好挣啊
奔三L2缓存512KB 于 2011-02-22 6:28 上午 to brutics:
的确有许多采用非常复杂的智能算法的缓存替换算法。这些智能算法基本无法在CPU中实现。
WLRU替换算法非常简单,比真的LRU都简单,只比PLRU多1%的晶体管。因为替换算法不在关键路径上,WLRU不会增加缓存的时延。—–拿出实际数据来。天天放空炮
xxx大学。。。教授。。。我觉得我还是比较幸运的。。。有些话还是不说了,容易伤到很多人。。。
闲逛的时候看到的
王老师还是忽悠到补贴了
序号 单位名称 申报人 “所在园区
补贴租金时限” 实际租用面积(m²) 补贴面积(m²) “补贴标准
(元/m²/月)” 补贴金额(元) 首次申请时间
1 珠海市泰格科技有限公司 黄桂鹏 “清华科技园
2014.1-12″ 180 180 20 43200 2012
2 珠海凯芯半导体科技有限公司 王去非 “新经济资源开发港
2014.01-12″ 106.8 106.8 20 25632 2012
珠海凯芯半导体科技有限公司
王去非
突破缓存速度瓶颈的单核高清视频CPU芯片
10万 前期费用补贴