Either CMT, FMT or SMT, the scheduling is all of preemption based. it is not the case that you need explicitely call something like sched_yield():-).
Yes, Intel’s HypeThreading is one of the SMT technologies. However, it really doesnot mean high performance. All about which kind of applications that you are trying to get optimized. Some people even claim that the performance got dropped when HT being enabled.
XLR应该不是。因为对于一个Network Service Processor不需要做这么复杂,SMT会使得die size,内部逻辑增加许多。我来查一下资料,确保咱们给读者一个正确的理解。非常谢谢。很好的反馈。我许多录音基本上现场直播,没有稿子,就上来就讲的,顶多写几个摘要提纲,所以如果有错误,一定要指出来,就像在学校里做seminar一样。
莲花木匠 于
2008-10-26 8:21 上午
Rara XLR是SMT。如XLR732内有8个独立的core,每个core有4个独立的硬件线程。8个core之间是smt,每个core里头的4个县城间同时支持FMT和CMT(可以是Round Robin、Fixed cycle or Priority)。
An application exhibits fine-grained parallelism if its subtasks must communicate many times per second; it exhibits coarse-grained parallelism if they do not communicate many times per second:感觉支持了FMT必然就支持了CMT?
8572 不是多线程,目前只 IBM 设计的 PowerPC 处理器才会引入多线程,如 Power5/6 (2×2),XBox 360 用的 Xeno8n (3×2) 和 Cell 中的 PPE (1×2), 且都是 SMT。
至于 UltraSPARC T1 (8×4) 的多线程,SUN 自己在其手册里是称为 CMT 的。CMT 这个名词大概也是来自于 SUN 吧。有意思的是 Wikipedia 的Simultaneous_multithreading 页面作者特地强调了 T1 不是 SMT
Eleven 于
2008-10-26 10:16 下午
按照陈博士的讲解,并查阅了些paper,也来说两句。实现hardware multithreading有两种做法: 一种是chip multiprocessing, CMP, 通过增加core的数量,multi-core per die,每个core执行不同的single thread,Cavium的Octeon就是这种方式。另外一种是multithreading per core,每个core都支持multiple hardware threads,Raza的XLR和SUN的UltraSPACR T1都支持multithreading per core,同时它们单个的core都是single-issue or scalar,并且可以switch threads every cycle,所以是fine-grained multithreading.按照他们自己的说法,是combine chip multiprocessing and fine-grained multithreading. 和CMT,FMT一样,Simultaneous Multithreading也是针对per core的概念,这个core首先应该是multi-issue or superscalar,如IBM的Power 6, SMT通常用在Server处理器上,因为实现它的hardware cost很大. 另外,SUN的CMT,is not coarse-grained multithreading, but chip multithreading,是它自己的说法而已,以示区别。






几个有用的LINKS:
×ILP
× ILP Wiki
下星期,我来谈谈 Cavim Vs. RMI.也是录音。现在不太想写字。太忙了。
SMT结构下:流水线是共享的,不同的thread不再是被动的被调度、而是主动抢占计算资源?
目前有没有采用这种结构的商用芯片,感觉比较复杂
期待下一期的内容
Either CMT, FMT or SMT, the scheduling is all of preemption based. it is not the case that you need explicitely call something like sched_yield():-).
Yes, Intel’s HypeThreading is one of the SMT technologies. However, it really doesnot mean high performance. All about which kind of applications that you are trying to get optimized. Some people even claim that the performance got dropped when HT being enabled.
Rara XLR 应该是 SMT,只是其同时支持 Fine-grained schedule 和 Coarse-grained schedule。博士,疏忽了吧?
XLR应该不是。因为对于一个Network Service Processor不需要做这么复杂,SMT会使得die size,内部逻辑增加许多。我来查一下资料,确保咱们给读者一个正确的理解。非常谢谢。很好的反馈。我许多录音基本上现场直播,没有稿子,就上来就讲的,顶多写几个摘要提纲,所以如果有错误,一定要指出来,就像在学校里做seminar一样。
Rara XLR是SMT。如XLR732内有8个独立的core,每个core有4个独立的硬件线程。8个core之间是smt,每个core里头的4个县城间同时支持FMT和CMT(可以是Round Robin、Fixed cycle or Priority)。
陈博:freescale最近发飙了,出了一个8572(双核,宣称是两个8548),基于e500的。freescale在多核上算是稍微偏后了,前期出了8641D(e600),功耗大的不行,貌似最初的设计团队都散了,而在如此短时间内能推出性能如此优越的8572(这个东东貌似现在价格很低),个人觉得中间的技术不是出自freescale。
从freescale上down了份8572的manuel,两个core之间是一个e500 coherency module的东西,似乎也是SMT。
Parallel computing:http://en.wikipedia.org/wiki/Parallel_computing#Fine-grained.2C_coarse-grained.2C_and_embarrassing_parallelism
An application exhibits fine-grained parallelism if its subtasks must communicate many times per second; it exhibits coarse-grained parallelism if they do not communicate many times per second:感觉支持了FMT必然就支持了CMT?
(陈博下周的XLR vs CAVIM能否带上freescale?^_^)
我其实对PowerPC还是很有感情的,对405,750和7447系列是一定了解。但e5000这套东西确实有点别扭。曾经与他们谈过几次。我来看一下这个8572.好久没有观察他们了。
我准备有时间讲讲bus,心目中还是想那60x或MPX来做case study。为什么?我其实对PowerPC的bus最熟悉。现在发现,那个东西你摸的最早,你的体会最深。后来的东西还都忘的快。按理说,x86的东西是在学校里就接触。但发现体会不深。我也想过为什么,原因可能是在工作中没有太被折磨过。技术的东西就是:被折腾一回,什么都学会了:-)。
SUN公司的UltraSPARC T1就支持SMT,UltraSPARC T1结合了CMP和SMT。
8572 不是多线程,目前只 IBM 设计的 PowerPC 处理器才会引入多线程,如 Power5/6 (2×2),XBox 360 用的 Xeno8n (3×2) 和 Cell 中的 PPE (1×2), 且都是 SMT。
至于 UltraSPARC T1 (8×4) 的多线程,SUN 自己在其手册里是称为 CMT 的。CMT 这个名词大概也是来自于 SUN 吧。有意思的是 Wikipedia 的Simultaneous_multithreading 页面作者特地强调了 T1 不是 SMT
按照陈博士的讲解,并查阅了些paper,也来说两句。实现hardware multithreading有两种做法: 一种是chip multiprocessing, CMP, 通过增加core的数量,multi-core per die,每个core执行不同的single thread,Cavium的Octeon就是这种方式。另外一种是multithreading per core,每个core都支持multiple hardware threads,Raza的XLR和SUN的UltraSPACR T1都支持multithreading per core,同时它们单个的core都是single-issue or scalar,并且可以switch threads every cycle,所以是fine-grained multithreading.按照他们自己的说法,是combine chip multiprocessing and fine-grained multithreading. 和CMT,FMT一样,Simultaneous Multithreading也是针对per core的概念,这个core首先应该是multi-issue or superscalar,如IBM的Power 6, SMT通常用在Server处理器上,因为实现它的hardware cost很大. 另外,SUN的CMT,is not coarse-grained multithreading, but chip multithreading,是它自己的说法而已,以示区别。
我前些天就将SUN的CMT跟B大讲的搞混了.
从概念上讲,CMT,FMT,SMT都是“硬件多线程”调度资源方式。与多核系统(CMP)无关。例如,一个CPU核的die,可以有4way Hardware Thread。这4个HT可以是C,F或S的调度控制。。。。。。
另外举一个例子更加说明TLP技术中多核与多(硬件线程)的关系。
在ILP技术中,超量(SuperScalar)与流水线技术的关系。一个CPU可以只有一个整数运算器,但可以5,10级流水线。或者,一个CPU可以有多个整数运算器,但可以(从理论上而言)不需要流水线。
T2,有8个核心,每个核心8个线程,一共64线程,但是SUN公司仍然说是CMT。
Power6,有4核心,2个线程,一共8个线程。但是IBM说自己是ESMT。
有个问题T1/T2到底是不是SUN自己设计的呢?
SUN可能要被迫出售了。Southeastern Asset Management大股东在增持普通股票,已经21.2%了。估计又要开始洗牌了。
http://ogun.stanford.edu/~kunle/
Architect of the Niagara chip(T1)
陈先生对ILP、TLP这些概念讲解的非常清晰透彻,我以前对“CMT, FMT or SMT”之间的区别搞不清楚,听了陈先生的讲课录音,对这几个名词已经有一些基本认识了。
我们的目的是“格物以至知”,下面我也斗胆格一格ILP和TLP这两种不同的技术选择。
前几年,CPU设计领域主流的技术选择是ILP,这几年,似乎TLP突然变得流行起来了,各种多核、多线程设计层出不穷。这是为什么?
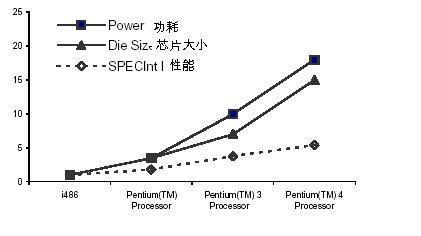
一般来说,所有新的CPU(包括NP)设计的都有一个共同的目标:追求高性价比。对CPU来说,在单位硅片面积上,单位时间内运行指令数量的多少,基本代表了它的性价比。
在同样的制造工艺(注1)下,一个芯片的成本基本是由其硅片面积决定的。硅片面积越大,一个晶圆上的能够容纳的芯片就越少。更要命的是,芯片面积越大,成品率越低。
一个CPU在一秒钟内运行的有效指令数量(或者反过来说,每个指令的时钟周期CPI),也基本基本代表了芯片的性能。这个比较容易理解,不再解释。
随着芯片制造工艺的不断提高,同样的硅片面积上,能够制造的晶体管(MOS管)数量越来越多,那么现在CPU设计者就有两种选择了:1、尽量减小CPU的硅片面积,以期降低芯片成本;2、尽量利用这些多出来晶体管来提高芯片的性能。实际上,主流的CPU厂商会选择第2种策略,提高性能,而不是降低成本。为什么呢?因为现在PC机的功能越来越多,软件越来越复杂,游戏也越来越好玩,这些都需要更高的性能。消费者需要更高性能的PC,而不是更低成本的PC。当然厂商也乐于引导消费者购买更高性能的计算机,因为这样可以维持产品的利润率。如果现在每台PC的价格是10元钱,那么估计Intel、AMD甚至包括micrisoft等,都要倒闭。
那么如何提高性能呢?也就是如何利用这些多出来的晶体管运行更多指令呢?。有两种做法,ILP、TLP。
ILP的做法就是芯片只支持一个线程(注2),让一个线程的指令运行的速度尽量的快,在1秒钟内为这个线程运行更多指令。怎么做呢?最简单的办法就是提高时钟频率,流水线的目的就是提高时钟频率(注3)。很多时候,一条指令要占用很多个时钟周期。比如cache mis的时候,当跳转的时候,要刷新流水线,当流水线里面两条指令同时要访问外部RAM的时候,当流水线里面的后一条指令依赖前一条指令的结果的时候,都必须用更多的周期来运行一条指令。解决这些问题的办法是:加长流水线、增加cache、分支预测、寄存器重命名、乱序执行等等。以及尽量用简单的指令格式(RISC)。还有一个办法,看能不能在一个周期内运行多条指令,因为在芯片里面本来就有很多不同的逻辑和运算单元,看能不能让他们同时工作起来,解决这个问题方法就是超标量(SuperScalar),国内资料一般把这个词翻译成超标量。所有这些办法,都需要更多的控制逻辑,换句话说,需要更多的晶体管。
上述那些方法中,最常用也是最有效的方法,是提高时钟速率。但是到3-4年前,提高时钟速率的办法变得越来越不可行了,为什么呢?因为提高时钟速率带来了一个极大的副作用,就是同时也提高了芯片的功耗。当时钟速率提高到2GHz以上的时候,CPU的功耗也增加到了100w以上,一般来说,芯片的正常工作温度是有一个上限的(很多芯片的最大结温在120-150之间),超过这个温度,芯片就不能正常工作了。如果温度再高,主板上的焊锡都会融化(187°C)。总之,由于功耗的原因,频率不能再增加了。为什么频率增加功耗就会增加呢?因为CMOS工艺芯片的功耗主要是由于开关状态切换造成的,静态漏电流很小,可以忽略不计。也就是说,功耗跟频率是线性关系,成正比。
既然通过提高频率的办法不可行了,那么怎么办呢?就是TLP,线程级并行。让一个芯片里面有很多个CPU(多核),或者像是有很多个CPU一样(多线程)。每个线程都可以运行一个独立的指令流,不同线程之间的指令相互无关,不需要相互等待。在同一个时刻,有很多的个线程指令同时流入芯片,虽然对每个线程来说,指令的执行速度都不高,但是多个线程加起来,芯片在1秒钟内执行的指令数量并不少。这个就是TLP的出发点。TLP有两种不同的思路,多核,多线程,我再另外一片评论里面解释了这两种方法的差别。
相对于ILP,TLP似乎更好。其实不尽然,TLP并不是对所有的应用都能够起到加速的作用,很多应用不是多线程的,是单线程的。对这类应用,那么尽管Intel的CPU里面有多个核,其处理能力也不能完全被利用到。无论你的计算任务现在多么忙,可能都只有一个核正在运行。双核的机器上,你看CPU利用率的时候,都只有50%。也就是说,TLP需要应用支持,ILP则不需要。因此设计的首选是ILP,只有当ILP山穷水尽的时候,才考虑TLP。
————–
注1:我经常听说的,0.25微米=>0.18微米=>0.13微米=>90纳米=>65纳米=>45纳米,这个就是制造工艺的进步。
注2:线程就是一个指令流的单位,简单的判断办法是,一个机器里面保存了几个PC(指令计数器)值,这个就有几个线程正在运行。一个芯片里面保存了几个PC值,这个芯片就支持几个线程。
注3:在芯片内部,基本的单位是晶体管,现在多数数字电路都采用CMOS工艺,也就是有NMOS和PMOS共同构成了一些基本逻辑单元,总的说来,基本逻辑单元可以分为两类:组合逻辑,触发器。组合逻辑是由AND、OR、NOR等基本逻辑电路构成的,可以执行算数运算和逻辑运算功能,触发器可以保存状态,也是构成寄存器的基础。一般来说,组合逻辑的运算速度是有一个上限的,为什么呢?电信号在半导体硅片上传输速度是有限的,这个速度叫做传输延迟,在一定的工艺下面,每个逻辑门的传输延迟是确定的,假设某工艺下一个逻辑门的传输延迟是1ns,那么对那些只经过一个逻辑门就可以得出结果逻辑预算,他们最大运行速度是就是1Ghz。很多算数运算(特别是浮点运算)要经过很多个逻辑门才能够得出结果,也就是延迟时间很长,这就限制了一个芯片的最高运行时钟速率。但我们希望时钟速率越高越好,怎么办呢?就用流水线来解决,在一个算数和逻辑运算部件的中间安插很多个触发器,用来保存中间结果。每个时钟周期只作一个完整逻辑和算数运算的一部分,中间结果保存在中间的触发器中,下一个时钟周期再运行一部分。时钟速率就可以提高,而且从外部来看,每个时钟周期流入这个预算部件的运算任务也是一个。用更多的晶体管提高了运算部件的时钟速率。
XLR支持三种Thread调度方式,Round Robin, Fixed Cycle, Priority,不是陈老师提到的SMT,和Intel的超线程不一样的。SMT是种高级的线程调度方式,在多流水线设计中会发挥作用,XLR是单pipeline,所以也没法做SMT。
8572怎么成了SMT,呵呵,有意思
ILP和TLP应该算比较成熟的技术了,但也是现在的热点话题,另外一个是DLP和异构多核。
对于显式MT,多线程的分类主要是根据线程间共享的资源,和线程切换机制划分成FMT,CMT和SMT三种。另外还有一大类是隐式MT。根据已经披露的资料,比较一致的看法是:P4是一种混和式的MT,流水线前端使用CMT的方式,发射、执行和存储访问阶段是SMT的方式,提交阶段采用的是FMT方式。有兴趣的可以去读相关书和论文。