




Aresta Networks 。数据中心 。云计算
作者 陈怀临 | 2009-10-24 13:37 | 类型 初创公司, 行业动感, 通讯产品 | 75条用户评论 »
|
Aresta Networks是一家为数据中心提供云计算基础设备的初创公司。他们的产品目前是10GBps的Datacenter Ethernet switches。也就是说,是一个为数据中心而设计的以太网交换机。显然,事情的重点不是端口,一切的精华在于他们的软件–EOS。当然EOS不是一个简单的东西,似乎是一个把数据中心内部虚拟化等等呢个东西都考虑进去的一个东东。 至于为什么说Aresta的交换机和EOS软件系统就更适合于数据中心。读者自己去判断。但是如果看了其创办人和目前的管理团队,确实会觉得Aresta is something。 Aresta的创办人谦逊的个人简历如下: Andy Bechtolsheim:公司目前的CTO。他曾经创办过一家公司叫做Sun MicroSystems。前些日子这家公司被Oracle收购。希望读者们除了巨大中华,也碰巧听说过Sun这家公司。Andy其他的业绩似乎还很多。但似乎都没有必要说了。 David Cheriton:公司目前的首席科学家。斯坦福电子工程系教授。这似乎就够了。他曾经与Adny在一起忽悠了一个公司叫做Granite Systems并在1996年卖给了思科。卖了2亿多美金。从此思科在Switch方面才成了老大。 David自己还身体力行,做思科Catalyst 4×00产品线的首席芯片设计师。 David目前还是Google, Vmware, Tibco, Cisco 和 Sun等等公司的顾问。 Ken Duda:公司目前的软件研发副总裁。当年Granite的第一个工程师。MIT毕业后,投靠斯坦福。显然是David的博士。现在与老师又在一起混。 读到这里,感觉如何?是否比你身边的人要狠一些? 再来看看谁是CEO?答案是:一个印度美女! Aresta的创办人都是斯坦福,MIT等精英人才。大家看了除了郁闷也没有其他办法。您说你非要于前Sun Micro的创办人闹别扭,比优秀,您一定是心理有问题不是?但Jayshree确实是一个英雄不问出身的又一典型。基本上可以与思科目前的CTO也有一拼。另外,大家知道印度人确实比中国人更能混了吧? Jayshree从旧金山州立大学获得本科文凭,从位于硅谷的Santa Clara University获得了她的硕士文凭。 下面是Aresta目前的产品一览:
| |
 (5个打分, 平均:5.00 / 5) (5个打分, 平均:5.00 / 5) |
 如果您在Cisco,Juniper,Ericcsion等上班,除了IP Header的格式比较熟悉之外,Google,Facebook和twitter的那套东西,例如php编程,mySQL都不会,今天想换一个工作,而且想去startup,为了老婆孩子和房子,拼一把,陈首席推荐一个公司–
如果您在Cisco,Juniper,Ericcsion等上班,除了IP Header的格式比较熟悉之外,Google,Facebook和twitter的那套东西,例如php编程,mySQL都不会,今天想换一个工作,而且想去startup,为了老婆孩子和房子,拼一把,陈首席推荐一个公司–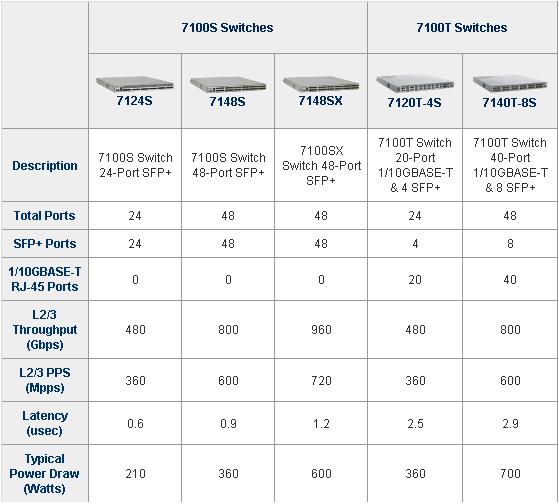
雁过留声
“Aresta Networks 。数据中心 。云计算”有75个回复
谢谢首席
Ken Duda开玩笑说Arista不需要VC因为几个founder的钱可以撑100年以上
金融市场是他们另一个主攻方向,所以也特别强调低延迟,对于做HFT的比较重要
这个公司够狠。。。基于Linux的EOS号称是一个Staeful的Switch 系统。我感觉所以的Story就在这个Stateful上。似乎是能够建立session,从而可以track云里面的VM Server,例如vmware等等的迁移和做SLB(Server Load Balancing)的时的State变换。。。
可惜在成都没有分公司哈,可惜可惜。
对Arista比较关注。founder牛是不用说了。不过他们的产品有多牛目前还没有概念。
Cisco不太可能买他们,switch上Cisco不缺技术。
要攻金融市场,光有low latency是不够的。并且Arista的latency据说是indeterministic的,depending on packet size。另外金融市场及其看中support,Arista现在人口还太少了。当然人多的话局外人也就没机会了。。
管理团队牛并不一定公司就能成功,甚至并不一定增加公司成功的机会,比如,Google/Yahoo的创业团队当初绝对是默默无闻,但是公司很成功,前Cisco的CTO Michael Volpi离职后搞得一个在线视频的公司,至少目前还是很不成功的,并且看上去已经没有机会了。企业终归是市场动物,不是舞台动物。所以,从财务和市场竞争性角度来分析一个企业能够成功可能更靠谱。
是这样的呀,大人物不保证成功,但如果统计一下,那么大人物可以增加成功的几率应该是可以的
对缺钱,缺知名度,不缺实力的startup来说,闻人和VC的作用更大一些。
“这个公司够狠。。。基于Linux的EOS号称是一个Staeful的Switch 系统。我感觉所以的Story就在这个Stateful上。似乎是能够建立session,从而可以track云里面的VM Server,例如vmware等等的迁移和做SLB(Server Load Balancing)的时的State变换。。。”
“要攻金融市场,光有low latency是不够的。并且Arista的latency据说是indeterministic的,depending on packet size。另外金融市场及其看中support,Arista现在人口还太少了。当然人多的话局外人也就没机会了。。”
请问这个基于linux的EOS处在哪个path上?,latency靠软件加算法能保证吗,精度能到多少?
还是靠单独的芯片保证? 为什么跟packet size又扯上关系了呢?
文章前面所说的,能在Cisco/Juniper/Ericsson工作的,干嘛要去startup?C/J/E这样的大公司多少人想去还去不了呢。
首席能否预测一下,未来5~8年有前途,处于上升期,多半startup公司会进入角逐的产品方向在哪里?
应用,应用,应用。
移动,移动,移动
回复11
移动互联网…大有可为!
首席抢的太快了.
大家会不会对〈生化危机〉电影版里面的那个绑的手腕上的设备还有一些印象?我想在未来2,3年内这个终端会面向市场。
iphone的3.7寸屏幕在没有出来之前,有多少人会想到?LG又推出了4寸的巧克力手机,都在印正这一点。
想像一下那个终端是什么样的,我想它是一个有着4.3寸屏幕的本本,它具有传统键盘,屏幕是可正反旋转的。具有多种无线接入方式(wi-fi, 3g, 4g),gps定位功能.
大公司是个增值的地方,但是要较快速的发大财,除了创业,碰到一个有潜力的startup公司是最佳选择。
H进入欧洲后,第一个死的是诺西。
H进入北美,第一个死的是谁?Juniper。H必然会挑起价格血战,在只有C的时候,J因为政治和技术的原因,还可以老老实实的享受20%的市场,但H一旦进入,在C和H的夹缝中,J几乎没有生存之地,纵使J的技术确有过人之处,再市场大战中亦无济于事,犹如当今毛蒋时代,其他英雄如何?最近的例子是在华为和港湾死磕的时候,有他们参加的项目,思科根本就不会报价,H开始进军北美之时,就是J准备后事之日,所以当初C阻止H进军北美,从公司存活角度,J也是一个更大的收益者,否则就没有今天的J了
谢谢理客。我对H在北美数据通信是如此个人看法的。5年之后起步。10年之后扮演significant role。华为目前似乎是芯片问题,其实是有了芯片之后,突然的一天,会反省过来,其实真正的问题还是软件问题。。。
我觉得北美企业可以学习Walmart的经验。例如,Cisco在中国全力投入研发力量。5年之内,在上海,深圳等地招聘员工1-2万。通过这个极力抬高PK华为等研发成本和中国内地人才已经短缺的现象。以此同时,极大的提高其产品的Margin。导致基本上这个市场没有更多的利润空间。
如果这样,华为如何处理?
现在思科由于印度人当权,极力在印度扩展。这是非常不对的。现在印度招聘一个工程师的人力成本已经4,5万美金。另外,印度本身通信系统就薄弱。
焦点应该是在中国。
1,2人的招聘。这将极大的对华为研发队伍的冲击。毕竟,对于绝大多数工程师而言,华为就是一个商业公司,一份工作而已。
如果为思科工作,能多那10万人民币一年,还不需要长期加班,。。。
所以,华为其实要居安思危。Telcom行业其实就是夕阳产业。不远的将来,就是货架上的商品。毛利没几个。
看看Google。美国的研发创新能力确实非常惊人。
我国输的绝不是1,2,3,4.。。年。
如果再要看BioTech,制药,材料。。。。
因为不知道当时H/C官司和解的内幕,所以无从知道美国法院对H的禁售令的截止期限,如果明天到期,以H的文化风格,今晚就会准备发起总攻.
软硬在具体功能上可以做一定的协调,但在大方向上是无法替换,硬件如果无法勃起,软件是干着急使不上力,所以硬件是第一障碍,但软件是决不能等硬件ready才开始准备的,应该是同步设计的,一旦硬件OK后,并且和竞争对手在一个层次上后,后面能否杀敌,就看软件的了。软件的难度和硬件不好说谁问题大,看个人屁股坐在哪里,对于数据通讯的软件,从基本OS到路由协议系统,从主控板到线路板,从主控系统到转发系统,从单核CPU到多核CPU/NP/ASIC/DSP,从业务系统到管理系统,这个大架构的架构师,不知道业界有哪些大牛?
这是当年思科起诉华为的法律文件原文。
http://newsroom.cisco.com/dlls/filing.pdf
我曾经打印出来仔细读过一篇。
佩服陈首做事情的认真态度
好像是禁售令今年开始已经过了,因为后来算和解,也许H/C之间内部还有些什么约定,或者H学精了,悄悄的进村,打枪的不要
你的idea很高,印度人虽然也有能人,但整体上缺乏中国人做事业的拼命精神和灵活手段,细节上曾经有公司用过外包给他们做的核心一点的模块,实在是没法用,最后还是给重写了。当然也许这只是个案,甚或是我们自己没有管理好外包。
你的idea如果真的做了,中国企业只好使用民族主义来开战了,当然这也是美国精英很担心的事。但是基于美国整体目前对中国高科技的态度,什么时候哪个大鳄把核心技术的1/4拿到中国研发,似乎还看不到可以预期的时间,美国的精英很精呀,命根子看的比谁都紧:资源和高技术。美国人最愿意输出的是民主、军火、美元国债、媒体、快餐
电信正在逐渐成为汽车制造、钢铁等基础行业,但这个时间应该还有一段,并且即使成了基础行业,中国人一样要牢牢把握,像德国人把持高端机电制造一样。
从Google和Obama来看,要美国没落还有些年头。
Google就是比Microsoft还Microsoft的另一种类型的生命力更强大的Microsoft,从政治和民族崛起的角度,全面打击Google,扶植百度等民族企业势在必行,只是中国人不是日本人,而日本又不是中国
不是因为Obama很牛或者可能成为林肯式的伟大总统,而是美国人转变和接受的能力,说明其国内民主政治体制的活力,伟大的企业和国家最可怕的不仅仅是其现在的强大做正确决策的能力,而是其与时俱进,能及时改错,自我反省的能力,一个强势力量,如果具备这种能力,那么很难预期其真正衰落的时间,所以从这点看,我们能否抓紧有限的机会窗,接近美国的核心实力,革命还远未成功,同志尚需苦苦努力,一万年太久,只争朝夕。有识之士,都知道这一点,只是国家宣传机器,会根据需要来宣传,一般主流不这么宣传,但对精英不是这样。媒体控制是个很复杂的事情,不完全是民主和媒体要努力100%真实的问题,相反,有些时候不能真实,老百姓是大傻瓜呀,比如你告诉他真实情况,中国不行了,完了,大多数老百姓会怎么样?大多数会等死。比如腐败问题,比如全部中国媒体开放,如实曝光,结果90%的官员都腐败,那么老百姓会怎样,这个政府还如何运作,动乱后谁得利?好的媒体要揭露黑暗,但同时必须要考虑如何引导群众,不是把一筐臭鸡蛋打碎了,然后站在旁边,看各色人马人仰马翻,从而得到更多的爆炸材料。一个媒体老板,以揭露黑暗,还原本质,深刻分析,合理引导为目标,才是一个真正有社会负责的媒体
离题太远了,停
http://www.fulcrummicro.com/
To 9 杰克:
Latency当然是靠ASIC保证。软件保证的latency,是没有商用价值的。
Arista用的是off-the-shelf的Chip,这可以说是致命的一点。当然我指的致命并不是陈首席提到的Chip Vendor被C/J买下来。
思科是绝对不可能在中国投入大量研发的。现在的投入估计也是政治因素多,trying to please Chinese government that China is part of Cisco blahblah.
原因很简单,思科总部朝中没有中国人。这一点就够了。
说实话,我认为美国各大公司软件质量持续下降的重要原因是印度人太多。不是stereotying老印,而是老印玩政治比中国人至少高一个数量级。公司里雷锋少了,做事自然是事倍功半。这个说来话长了。不过老美估计是意识不到的;或者意识到了,但networking gear正向白菜化发展,outsourcing也是不得已之举。
To mpc8240:
那和packet size的关系能否提示一下呢?
首席说说中国的人力成本是多少,美国的人力成本是多少?据我所知,c公司核算出中国的人力支出是美国的1/3,包括薪酬,工作场所租金,之类。
23楼的分析,严重同意,阿三们在C的势力实在是太大。
如果说老印的政客高于中国,我相信,要说政治家,我倒是觉得老印很幼稚,经常顾头不顾腚,毫无大国素质,这得从其根源非暴力不合作这种其引以自豪的用自虐来自慰式的政治传统说起,被人类稍有头脑的人在家里捧腹大笑,而在外面却说尊称甘地圣雄,树立为发展中国家民主自由的模范好孩子,捧得印度人至今还爽在里面,不知道是被抬上去后有苦说不出还是真的很爽,一直都不明白印度人何以推崇这种自宫式的独立方式,要在其他国家,一定会被骂为真是丢你先人的脸
Tilera Announces the World’s First 100-Core Processor With the New TILE-Gx Family
Tilera Leads the “Many-Core” Era, Opening up New Possibilities in Networking, Multimedia, Wireless and Cloud Computing
Highlighted Links
http://www.tilera.com
http://www.tilera.com/products
SAN JOSE, CA–(Marketwire – October 26, 2009) – Tilera® Corporation, developer of the breakthrough TILE™ family of high-performance multicore processors, today announced its new TILE-Gx™ family — four new processors from Tilera including the world’s first 100-core processor: the TILE-Gx100™. The TILE-Gx100 offers the highest performance of any microprocessor yet announced by a factor of four. Moreover, the entire TILE-Gx family raises the bar for performance-per-watt to new levels, with ten times better compute efficiency compared to Intel’s next generation Westmere processors. And Tilera has simplified many-core programming with its breakthrough Multicore Development Environment™ (MDE), together with a growing ecosystem of operating system and software partners to enable rapid product deployment.
The TILE-Gx family — available with 16, 36, 64 and 100 cores — employs Tilera’s unique architecture that scales well beyond the core count of traditional microprocessors. Tilera’s two-dimensional iMesh™ interconnect eliminates the need for an on-chip bus and its Dynamic Distributed Cache (DDC™) system allows each core’s local cache to be shared coherently across the entire chip. These two key technologies enable the TILE Architecture™ performance to scale linearly with the number of cores on the chip — a feat that is currently unmatched.
“The launch of the TILE-Gx family, including the world’s first 100-core microprocessor, ushers in a new era of many-core processing. We believe this next generation of high-core count, ultra high-performance chips will open completely new computing possibilities,” said Omid Tahernia, Tilera’s CEO. “Customers will be able to replace an entire board presently using a dozen or more chips with just one of our TILE-Gx processors, greatly simplifying the system architecture and resulting in reduced cost, power consumption, and PC board area. This is truly a remarkable technology achievement.”
Leading the Evolution to Many-Core
Tilera’s breakthroughs in scalable multicore computing are changing the model of computing. Many-core processors enable a wide range of new opportunities including:
– Consolidation of functions: A single many-core processor can absorb
functions that previously required multiple processors, thus lowering
system cost and providing a single software tool chain and programming
model for developers.
– Granularity of compute: Processing resources can be allocated to
functions in precise increments, optimizing performance and saving power.
– Deterministic compute: Enables processor cores to be dedicated to
specific tasks, including cache-coherent islands of compute, for highly
predictable performance.
“At various points in microprocessor history there have been breakthroughs that have enabled significant advances in computing, such as when the barrier of single-core clock speed was overcome by the introduction of multicore,” said Sergis Mushell, principal research analyst, Gartner. “Cloud computing and virtualization have ushered in a new era of processing power optimization and utilization, which has accelerated the roadmaps for multicore architectures and changed the paradigm from a clock frequency discussion of the past to a new discussion about number of cores and core optimization.”
About the TILE-Gx Processor Family
The TILE-Gx family, fabricated in TSMC’s 40 nanometer process, operates at up to 1.5 GHz with power consumption ranging from 10 to 55 watts. Like the TILE and TILEPro™ processors, the TILE-Gx family incorporates many cores on a single chip together with integrated memory controllers and a rich set of I/O. However, the TILE-Gx device also brings together a number of new features to maximize application performance while offering the best performance-per-watt in the industry. Some of the technology highlights include:
– Next-generation 64-bit core: New three-issue 64-bit core with full
virtual memory system. Each core includes 32KB L1 I-cache, 32KB L1 D-cache
and 256KB L2 cache, with up to 26MB total L3 coherent cache across the
device.
– Enhanced SIMD instruction extensions: Improved signal processing
performance with a 4 MAC/cycle multiplier unit delivering up to 600 billion
MACs per second, more than 12x the fastest commercial DSP.
– Integrated high-performance DDR3 memory controllers: Two or four 72-
bit controllers running up to 2133 MHz speeds with ECC support. Up to 1TB
total capacity and powerful memory striping modes for maximum utilization.
– Hardware acceleration engines: On-chip MiCA™ (Multistream iMesh
Crypto Accelerator) system delivers up to 40Gbps encryption and 20Gbps full
duplex compression processing, tightly coupled to the iMesh for extremely
low latency and wire-speed small packet throughput. In addition, a high-
performance true random number generator (RNG) and public key accelerator
enable up to 50,000 RSA handshakes per second.
– Packet processing accelerator: mPIPE™ (multicore Programmable
Intelligent Packet Engine) system provides wire-speed packet
classification, load balancing and buffer management. This flexible, C-
programmable engine delivers 80 Gbps and 120 million packets-per-second of
throughput for packets with multiple layers of encapsulation.
Target Markets and Availability
The TILE-Gx processor family is ideal for a wide range of markets including enterprise networking, cloud computing, multimedia and wireless infrastructure, with the TILE-Gx16™ targeting more cost-sensitive applications and the TILE-Gx100 targeting performance applications.
The TILE-Gx36 processor will be sampling in Q4 of 2010 with the other processors rolling out in the following two quarters.
Tilera Sponsors EE Times Many-Core Virtual Conference
Join Tilera for the EE Times Many-Core virtual conference on Oct. 28, 2009 from 11 a.m. to 5 p.m. Eastern to hear panelists from Tilera and other companies speak about the impending shift to many-core. Tilera will be hosting a premier booth where it will provide further details on the TILE-Gx family and answer any questions you may have. Register at: http://www.eetimes.com/manycore/
About Tilera
Tilera® Corporation is the industry leader in highly scalable general purpose multicore processors for networking, wireless, and multimedia infrastructure applications. Tilera’s processors are based on its breakthrough iMesh™ architecture that scales to hundreds of RISC-based cores on a single chip. The distributed nature, of Tilera’s revolutionary architecture, and the standards-based tools, including ANSI C/C++ compiler, GNU tools and Eclipse IDE, deliver an unprecedented combination of performance, power efficiency and programming flexibility. Tilera was founded in October 2004, and is currently shipping two product families: TILE64™ processors and TILEPro™ and will ship its 3rd generation TILE-Gx processors in 2010. The company is headquartered in San Jose, Calif., with locations in Westborough, Mass., Shanghai, and Beijing.
没空仔细看是不是当年比较早做swich cluster或者说虚拟交换机的那个啊。就是把多个交换机的l2表都给统一了,省得跑生成树那个?
首席和理客能够评价一下这个Tilera? 以及网络、安全盒子的前景? http://tilera.com/solutions/network_security_appliances.php
我看他们网站上列出来Toplayer的IPS。这种10G/20G
的吞吐能力实际效果如何?先谢过
小包小latency,大包大latency。
做广告的时候当然用的是小包的latency数字。But for data center apps,实际上是大包多。
>小包小latency,大包大latency?
没说反吧?? 64byte的UDP vs 1500的TCP Packet。
Richard,从直觉上而言,这是个很好的芯片。但是作为一个total solution,例如,你是一个公司的PLM,你如果要考虑一个产品线的产品家族(而非一个产品),TILE芯片需要与其他芯片配合。例如fabric芯片(Dune)和线卡上的NP(EZChip)等等。
For a given packet size:
Higher data rate –> higher latency
For a give data rate:
Larger packet size –> higher latency, especially regarding how to handle jumbo frames.
陈首席,推荐你个网址,http://wave.google.com/help/wave/about.html#video, 希望你们的网站能用上这个新的功能,这样子大家回帖看贴就不用这么累了,这可以将来的趋势哦。
那个Sun的Andy很厉害,千兆的交换机他做的,当年google刚起步时,他大笔一挥给了100K,后来估计变成100M了
H不厉害,H搞研发的说到底才40K人,这算啥,也就一个军的实力吧,再过5-10年,中国领头公司中出一个5个军的研发军团也未可知,中国人的资源太丰富了,老毛当年利用了这点扭转乾坤。
最近cisco 2.9B 收购了一个什么Starent Networks,其软件的核心还是linux,要说陈首席你算是搞linux的第一代人吧,到现在几年,10-15年,再过10-15年,有个3-4代人,国内的软件业不愁不起飞,不愁不发展,关键是有没有像当年老毛一样的有心人去实现之,然后还要借助外援,就像当年老毛身边有多少个出国勤工俭学的帮助他。
我也扯远了,止而思
35, 你是对的。我其实就是在说throughput。
36,Heeeee。我看看google wave。另外,陈首席想回国折腾,胡不才同学有没有合适的机会和人引荐一哈?陈首席在H基本上不灵。讨厌我的人巨多。不过我也不care:-)
For a given packet size:
Higher data rate –> higher latency
For a give data rate:
Larger packet size –> higher latency, especially regarding how to handle jumbo frames.
如果用软件实现,解释的通,
如果用硬件实现,不太make sense吧,除非他的硬件处理能力达不到那个速率。
我觉得除非修改协议,否则以太网的latency肯定是有一定硬伤的。解决得方法有那么几方面。一方面提高芯片处理能力,一方面就是提高调制的速度。
但是我觉得以太网现在面临的延迟问题,与其说是延迟不如说是抖动的问题。延迟的范围基本不可控制。
另外,不要站在一个盒子来看延迟和抖动的问题,而是要站在全网的角度来看。全网的角度问题很多,比如你要几跳实现端到端,冗余链路如何走,如何收敛。我觉得如果说可扩展性越好,特别是管理和维护的可扩展性越好越简单,解决延迟问题越难。你做个infiniband和fc的网络能够有多大?你如果做一个IP或者以太的网络会有多大规模?者首先就是一个不可以比拟的命题,然后再讨论,基本上就等于无法讨论。
陈首席想回国创业?如果真有好项目,我倒是有一些开发区资金和政策支持的渠道…
40,其他的读者弟兄就知道忽悠我。你是真帮助我。能否给我huailin@tektalk.cn来个E?或者huailin@gmail.com。我的gtalk ID是:huailin
To Richard:这个不需劳驾我,请陈首处理:)
陈首一个小时就搞定,我得一天以上,这不,陈首的文章都已经出来了,我还在思考中。很惭愧,被点名回答却不会。
一直在欣赏弯曲的文章和评论,却没有贡献,等我不知道有时间清闲下来,一定写一个豆腐块,给大家。
从机械到软件, 是不是要早点想想软件后面是什么, 首席说得对, 一门心思在电信过于局限了, 现在看来紧接着的bio,mat,还是挺能搞的
请问陈首席现在的国籍是?
大陆这边还买不到吧,呵呵。
44,我生活中喜欢开玩笑。另外许多读者其实我都在现实生活中都是朋友。所以我说话有时不注意。你不要在意我大宋,大清的。看我做的事,不要看我说的话。
拿中国护照的不一定爱中国;拿美国护照的不一定就是汉奸。
共勉。
PS:我是中国人:-)
大陆可以买到,这个公司用了amd的cpu ,在那么小的盒子里,所以导致了很多无谓的烦恼,散热,稳定性等等,创想是伟大的,但是困惑也是现实的。 就是可以用api操作的switch/router,这也是所有router的趋势和方向之一,管理自动化,变更智能化,比如F5的icontrol
关于C/H/E/J….,我想说的是,成败其实既复杂又简单,说复杂是因为肯定是各种合力的结果 说简单其实往往有一个或者很少的最重要的因素在主导.但无论从简单说还是从复杂说 技术肯定不是最重要的主导因素.从小了说,一个或几个芯片 甚至庞大的软件系统,从大了说,整个技术实力 研发体系也不会是一个公司成功的最主导因素(当然可能是公司失败的最主要因素),这样的例子太多了 (就不用举了).任老板最常说的一句话就是,“技术的先进代替不了商业的成功”,技术的成功也不一定造就商业的成功。
其实,很多时候,大家都是局外人,不是站在外边看里边,就是站在里边看外边。对于H公司,我可以这么说,老任独特的管理风格和人格魅力,98年开始从IBM引入的IPD管理流程以及以后的坚定执行和持续改进,等等,都比技术层面的影响要大很多。这些都是局外人 很难看清楚的。别的不说 公司的办公系统和版本管理系统 BUG管理系统以及其他多个数据库系统,应该都是IBM帮着建的,绝对是非常先进和方便的。
在技术方面,H虽然不能一下子做出很好的芯片来,但是我敢说,H的硬件实力是非常非常强的,这个强不是说设计出先进的逻辑来,或者芯片来就一定强,我指的是,人家的大到大柜子 中到盒子 小到板子 敢拿出来卖的 问题很少 硬件BUG基本没有 这一点 很多很好的公司也是做不到的….
支持楼上的,我相信5年以内,IT业就会发送比较大的变化,特别是中国的公司将拥有越来越多的份额。
技术总是被管理管,似乎是很明显的。但如果大到人类发展的角度,就很难说,比如人类会制造工具从而带来的具体社会变化,比如说达尔文进化论对西方社会的影响,所以技术和管理之间的关系是纠缠在一起,很难讲清楚的,比如Google,到底是技术创造了goole还是管理创造了Google,技术在人类社会发展中的作用到底是根本性的还是局部性的,没有长远的基础研究成果积累,那么国家是否超过美国,但是这些远期技术研究是否需要有一个优秀的管理才肯能做到?
35. For a give data rate:
Larger packet size –> higher latency, especially regarding how to handle jumbo frames.
不好意思,51敲错了。
要看芯片怎么做了。
如果只parser前几百Byte的话,现在ASIC对jumbo frames的处理可以做到很好,不受影响,在这种情况下,packet size 越大latency越理想。如果要对whole packet deep parse,或通过微指令parse,searching…packet size 越大latency越不理想了。
我做包引擎的,不知道我对latency的理解是不是合理:
1 对于cut-through类型的包引擎,其实latency和包大小是没有关系的,这种类型的转发引擎很多是用于data centec那种对feature要求比较低,但是对延迟极其敏感的地方
2 对于存储-转发式包引擎,包延迟取决于两大因素,a 包大小(大包需要更多的clock放入packet buffer中,存包和取包都要更多clock), b 调度优先级(如果有拥塞,那么低优先级的包会有更大的delay)
3 如果是复杂的feature,那么也可能会导致大一点的delay,但对于pipeline的转发引擎而言,问题不大
包转发设备,基本都是cut-through,不会把整个报文放到转发引擎中,只是把需要的部分放进来,一般是报文开始的部分,其他的缓存在片外内存中。
同样是cut-through,在具体处理上可能会有不同的模式,比如我是等报文从线路上全面接受完毕再开始报文处理,还是当只接收了报文头的时候就开始处理,这个对时延的影响是比较大的,所以也有人把后者叫更严格意义上的cut-through,这个时延对低速链路的业务影响相对大一些,对于高速链路,其实影响不大,高速链路下这种时延的影响主要不在业务,而在一些特别时延抖动敏感的应用,比如时钟同步,尤其是2G/3G/4G里面的时钟同步,固定语音一般问题不大
53, 恩,跟feature关系很大:查表次数,查表地址(内部、外部cam、ram),queueing priority,每一级pipeline的fifo depth够深否。不过一般转发引擎及chipset设计时考虑的跟多是的在各种wrost case下能否达到wire-speed,throughput有多少,latency倒是可以够长,呵呵。PC芯片的chipset设计时就对latency要求很高了,因为这直接影响到用户体验了。
to 54, 不知道是不是我看错了,现在大部分包引擎是store-forwarding吧, take a example, bcm 56520, 5690, 56620, and marvel‘s mx,ex seriers, 还有我参与过的, cisco 和 juniper 的我不是很清楚,could you plz tell which company use cut-through,except fulcrum and bcm 56880
TO BBB:存贮转发是包交换的基本特征,这里cut-through定义为转发引擎只存贮和处理包头,外部内存来缓存实际的包体(还可能有其他不同的定义),这也是基于存贮转发的,和存贮转发不矛盾,交换芯片具体规格不是很了解,但如果需要外挂大量内存的话,应该也是这种模式,如果不需要,那么其交换芯片内部内存很难做的很大,如果是这样,那对QOS设计是个问题,也许这是交换机的QOS比路由器弱的原因之一
Packet Switching 都是Store Forwarding。
客客说的是:对payload不折腾,只折腾packet header(descriptor)。例如,packet payload上来就被DMA放入DRAM里 until被forwarding engine通过fabric送到outgoing interface线卡上。。。。
有个朋友周游世界之后去了这家公司。
当时说的时候我就有印象,今天闲来无事看看,果然陈首席评价很高啊!
54楼说的实际上是理解有误。
58楼说的是正解,很多store Forwarding都是不对pay load折腾了,如果折腾就不是switch了。
有的storeforwarding是放到一段内存里,然后记得这个packet在哪一块,在决定了向哪里转发之后,对应的端口会来复制。
这是近10年前看到的一些文档。
但是我觉得随着这个市场的成熟,有意思的尝试太少了。
还有人记得当年的enterasys公司的Matrix系列交换机吗?真的好有意思,完全没有通常意义的switch Fabric,而是靠line card之间的bus进行互联,想想真的超有意思。但是类似得设计估计以后没有了。
其实就像看一些讲老爷车的电影,很多有意思的设计虽然有很多bug,但是能够体会到当时工程师的创新精神,而随着产业成熟,这种异想天开的创新太少了,更多的设计师是跟随。我觉得我们国内产业缺乏这种悲情的创新,更多是对相对稳妥道路的跟随。这样会成功吧,但是总觉得少了些噱头,少了谈资,少了点味道,太平淡了。你看到的东西无非就是在比自己的端口密度,线速等等,其他还有啥吗?真的让人觉得无聊。
不同意楼上的观点。这是个系统工程,跟你所谓的创新没关系。
客户需要什么,更低的成本,更大的端口容量。公司做产品不是大学生设计大赛。
搞些异想天开的东西,看客爽了,失败了,下面的人谁给发工资。
好比汽车,这年头就比些马力啊扭矩啊,无聊死了。但是动嘴的永远理解不了动手的在达到这个速度时候所做的外部不可见的创新工作。从外面看不就是四个轮子的汽车么,无非跑的快了点。
aresta据说最近在腾讯百度等企业测试想卖进去,但由于功能不太稳定而没有成功
请首席把拼写错误改下吧: Arista
思科内部印度人的势力太强大了,中国只是做做样子的。这次思科调整,印度研发是得益最大的。人数不减反增。并且有一个完整的BU都放在了印度(硬件,软件,测试,市场,所有产品,老大全在)。中国这边就是帮忙打杂。
Arista前段时间是在Tencent做测试,花费了不少时间过Tencent准备的Case。
我几乎看完所有的评论,实在是精辟入微!
个人认为Latency的大小决定于是否做丢包处理,因为如果有丢包功能,就得存储整个包,包越大就在buffer里面呆得越久直到包尾到来,校验完毕。
另一个latency的因素是查找forwarding decision,这个省不掉,包包在不知道该往哪里去的时侯,只好等着。这个和包大小没关系。
to switch兄,阿三已经强大到可以排挤老美了,其他人就不需说了
不过阿三也有该学习的地方,他们工作很认真,加班也不再话下,关键是,他们敢忽悠。听说C内部有个提交idea申请专利的地方,阿三们什么破烂都敢提交,以至于后来公司得专门给他们培训告诉他们:C真的不需要破烂
latency 是亮点
to Lucien兄,排挤老美,刚开始我是不信的。后来我信了,原来发生了这样一件事:美国一个team作的产品都快bringup,结果老大一声令下,transfer给印度人,给出的理由是美国需要他们做更核心的东西,到了8月,这个team从director到engineer全reorg掉了。
11 -》09 穿越了
丢包处理一定是有的,严格来讲,时延测试的是没有丢的包。
按照之前经验,至少在印度的印度人是做不出核心东西的,不排除现在他们真的长进了,也未无不可
丢包这个feature影响了所有包的latency。按照上面说得,最小的latency是0.6us,那估计是最小的包的latency了。
如果是1536Byte,在10G速率下,仅仅把包从头到尾全部存下来,就需要0.1536*8us = 1.2us
所以,我觉得,在没有congestion下,还是2us比较靠谱
年初Arista专门在深圳招了个工程师来做腾讯的项目。
2012,Arista怎么样了?
首席眼光很独到