




通信顺序进程( Communication Sequential Process ) [序言,第一,第二章]
作者 陈怀临 | 2017-11-26 11:14 | 类型 专题分析, 科技普及 | Comments Off
|
文件下载:通信顺序进程(Communication Sequential Process)(一,二)
| |
 (2个打分, 平均:5.00 / 5) (2个打分, 平均:5.00 / 5) |



云来了,安全盒子怎么办
作者 tomqq | 2017-07-27 11:35 | 类型 云计算, 网络安全, 行业动感 | 1条用户评论 »
|
云来了,安全盒子怎么办 by 何恐,一个安全人
前提和假设: 本文主要讨论“当下的”私有云安全,公有云不在此文范围内 1、云带来的安全挑战近两年,云计算发展迅猛,新建的IDC如政务云,行业云,绝大部分都是云机房。云计算是大势所趋已经毫无疑问,已开始遍地开花。 关于云环境下如何做网络安全防护,常听见一种观点:云是颠覆性的,传统硬件安全设备完全不适用云环境。 那么,云来了,安全盒子到底该怎么办? 从本质上来说,对于网络安全设备,云带来的最直接挑战有两个: 1、 主机虚拟化 2、 网络虚拟化 云主机虚拟化带来的挑战
传统机房里面,每个租户的服务器是看得见摸得着的。在云环境下,租户的服务器变为了一个个运行在硬件服务器上的虚拟机,一个租户的虚拟机,可以位于不同的硬件服务器上,这是形态的变化,会引起租户的边界,从传统物理边界,变为动态、虚拟的逻辑的边界。 另外,因为一些历史原因会出现软硬件资源混合的情况。某些服务器不方便虚拟化,如历史遗留的数据库服务器,就需要和虚拟资源一起组成租户的计算资产。 最后,不同虚拟化厂家,如vmware,citrix,Hawei,H3C,各家的hipervisor系统不兼容,也会给安全厂商带来适配的工作量。安全厂家如果要以虚拟的形态运行在虚拟环境里面,需要适配不同平台的虚拟机格式。 因此,传统安全硬件要继续发挥作用,首先就要能够识别和保护虚拟的资产域,并且以动态的方式,切入到虚拟计算环境里面去。 另外,现在的运营商也不喜欢硬件盒子了。毕竟专用的盒子,利用率低,又互不兼容,运营商希望用通用的X86服务器来运行虚拟的安全设备,类似NFV,来提升经济性,可扩展性,以及适应业务快速可变的要求。
网络虚拟化带来的挑战如果按照vmware 1999年发布VMware WorkStation算起, OS虚拟化的发展时间已经不短了。但是,仅仅是服务器形态的虚拟化,还不足以支持云的发展。在云环境下,要满足云的虚拟性、动态性,还需要将网络也虚拟化。
第一个问题是传统vlan的4K问题。传统vlan因为tag字段位数限制,只能支持最多4k个vlan。但是在云环境下,租户的数量非常多,4K上限是不能满足租户数量的要求的。基于这个目的,扩展vlan tag字段位数,重新对ip报文做wrap,以便于支持更多的租户容量,采用类似vxlan这种方式来划分网络是主流方式。对传统安全盒子来说,首要问题就是能识别vxlan报文。另外vxlan带来的不仅仅是报文tag改变这一点点内容,vxlan带来的相关的网络控制方式改变,调度,如服务链、SDN等等,也都是安全盒子需要去适应的。 另外,云环境下业务动态变化非常频繁,靠传统硬件去动态开通或者销毁一个业务,显然是不行的。之前大家只知道需要把服务器虚拟化,后来随着云虚拟机数量规模的扩大,大家逐渐意识到光服务器虚拟化还不够,需要把网络部分也虚拟化,软件化,并自动化。举个例子:某租户需要开通一个业务需要一台路由器,过一段时间又不需要了,硬件路由器可以满足这样的频繁变化吗?硬件盒子,必须要也可以动态灵活的部署进去才行啊。 再加上云环境为了满足虚机动态迁移,需要在一个大二层,传统二层设备没办法支持这么巨大的mac表项,这一块也需要新的二层技术,如vxlan的支持。传统网络显然不行的。 还有,租户都有自己的vpc,IP地址范围很可能是重叠的。传统硬件设备大部分是不支持这个的,大部分不具备硬件设备虚拟为多个硬件设备的功能的。租户是逻辑的、虚拟的,是接在“逻辑交换机”上的。逻辑交换机本身就不位于任何一个固定位置,是通过计算机节点overlay的方式,分布式部署的。因此,对多租户的安全检测能力,是传统安全盒子不具备的,这显然无法适应云安全的要求。 最后,SDN控制网络,控制和转发平面分离,也使得云环境的网络和传统网络大大不一样。传统盒子如何接入如何适配新的网络架构,这个也是需要有一个重大改变的。之前安全盒子通过策略路由、桥接、分光镜像等方式接入网络做安全检测的方式,在SDN网络架构下已经不能适用了。传统安全盒子,需要按照新型网络的控制方式,来接入业务流量。否则,就完全不能发挥作用。 总结上述挑战,传统安全盒子通过交换机、路由器、分光器等物理方式接入租户网络的方式,在云环境下就失效了。要继续发挥作用,传统硬件必须要解决在云环境下的接入问题,要做到看得见、认得出、防的住,才行。 除了接入问题,安全盒子还需要适应云的弹性。硬件固定性能的盒子不容易弹性扩展,在云里面,安全也要像计算资源一样,可以动态的、弹性的扩展。 总的来说,云是利用资源的新的方式,安全本质并没有发生变化。但是,安全发挥作用的方式,需要根据云的变化而调整,才能继续有效。 2、 什么是东西向流量凡提到云防护,必然会听见“东西向防护”这个词。那么,什么是东西向流量? 下面这幅图,是传统IDC的流量走向:
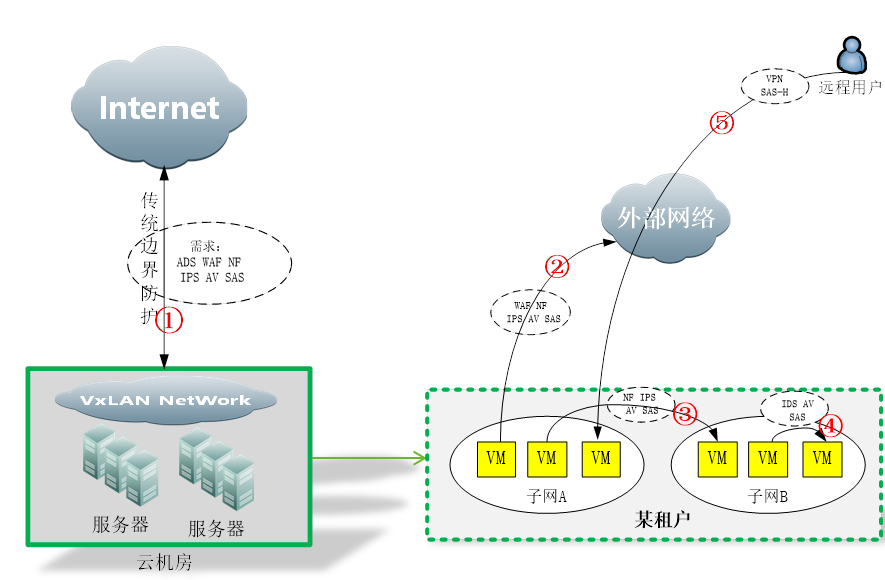
可以看到,大部分业务流量,都是从外到内为主,安全防护设备,也集中在由外到内的防护路径上,我们称之为“南北向”防护。 IDC云化以后,服务器的规模,包括虚拟机的数量,都扩大了很多。横向的虚机密度大大增加,也因此衍生出租户和各种复杂的网络虚拟设备,如下图:
传统IDC的安全问题,主要集中在①这个位置。云化以后,流量问题复杂化了,衍生出②、③、④、⑤这几个新的情况,防护也因此而有所不同。 在云网络内部,租户之间是隔离的,互相访问要通过vpn或者隧道访问。租户内部可以划分不同的子网,子网之间,子网内部虚拟机之间,虚拟到外部,外部到虚拟机,都会产生访问流量,安全问题也由此而生。 重要的是,这些流量往往产生在云内部,甚至不出服务器(如同一服务器内部虚机之间的流量)。因此这些流量,对传统硬件盒子不可见,从而也无法防护。这些流量,会成为一个真空地带,一旦发生安全问题,如虚机中木马或者病毒,将会迅速在云内部蔓延,并难以进行防护控制。这种情况是非常可怕的。根据《云等保增补方案》同等防护的原则,云内部流量也需要进行同等安全强度的防护,防护缺失是无法接受的。 综上,南北向流量,主要是指外部公网进出云计算内部的流量。东西向流量,主要是指租户内部虚拟机的访问所产生的流量。注意,东西向流量在这里是泛指租户相关的流量,并不仅仅是从外到内的流量。如果外部流量访问虚拟机,需要按照不同租户的策略来防护,此刻也称之为“东西向”。 南北向防护,传统方案都可以继续有效。而东西向防护,是云化后的机房新增加的需求。本文后面的讨论,主要集中在东西向防护方案。 3、 现有东西向防护方案凡是解决方案,出发点都是根据安全厂商自身情况优先考虑。同样的,对客户而言,“反厂商绑架”也是自然的诉求。 虚拟OS厂商的方案虚拟OS厂商,指的是虚拟系统厂家。这类厂家因为掌握了虚拟操作系统,所以自然考虑从虚拟系统本身入手来构建安全方案。通用的示意图如下:
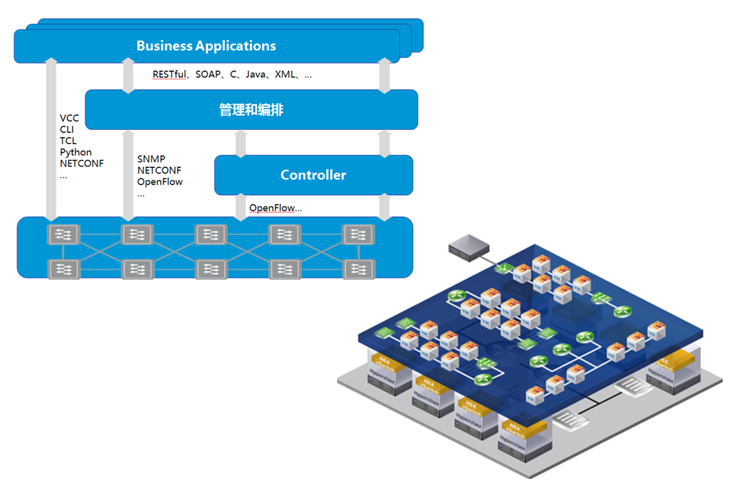
虚拟操作系统厂家,通过在虚拟系统网卡之上增加驱动过滤层,将虚拟机的流量截获,将流量导向系统内置安全模块,或第三方的安全虚拟机,进行安全防护。 从上图可以看出,对内部流量的防护,利用了计算节点本身的计算能力进行,流量在出计算节点之前,就得到了有效的防护。 这种方式有他的优缺点。优点是,在靠近虚拟机的位置进行防护,能够在最短路径上防护,同时流量不出计算节点,不会对云内部骨干网络,造成额外的流量负担。另外随着虚拟OS的部署,安全能力随之部署,在部署上也会比较便利。 缺点也很明显,首先是第三方安全厂商必须获取虚拟OS的防护API授权,才能引入自己的安全虚机,如vmware的nsx认证。对于虚拟OS厂商来说,自然不愿意第三方碰自己的蛋糕。比如vmware的NSX模块,终端用户须付费购买,第三方安全厂商须通过商业认证。只有同时满足这两个条件,用户才可以用到想要的安全厂商的安全能力。 另外一个缺点是安全模块和安全虚机运行在计算节点,会占用计算资源。对于计算资源紧缺型的用户,或许无法接受。同时安全能力和计算能力混合在一起,出现问题的时候,排查责任也会有较高的复杂度,互相依赖交叉的情况,会对虚拟OS厂商和安全厂商造成同时困扰。 最后一个缺点,是安全虚机厂商多样性也会有问题。不同厂家的安全虚机,要同时出现在同一个计算节点上,技术上会有很大的问题。从客户长远利益考虑,客户需要一个比较好的,兼容各个安全厂商的安全架构,或者说良好的生态圈。 网络厂商的方案这类厂商,以传统网络数通厂家为主。云化,不仅仅需要服务器虚拟化,也需要网络的虚拟化。流量可以在计算节点的驱动层捕获,也可以在网络层面捕获。我们知道,业务流量在哪里,安全问题就在哪里。因此对于网络安全盒子来说,在网络层面接入才是正道。
如上图所示,SDN网络,控制面和转发面分离,通过控制器来集中控制所有流量的转发。在SDN网络内部,可规划安全区。在安全区域,安全虚拟机或安全设备,可注册为服务节点。在SDN协议字段里,通常有服务字段。通过设置服务字段的值,即可控制任意的流通过指定的服务节点。 那么,安全盒子的部署,在这种情况下,也简单了。只要把安全盒子或者安全虚机,部署在服务区域,并注册为标准服务节点,即可利用SDN的服务编排能力,“指挥”任意流量,经过相应的安全节点,从而完成安全防护。 同时,SDN也有强大的网络控制力,可以实现流量镜像到服务节点,以及把服务节点的虚拟机工作口,绑定到用户VPC从而完成扫描类任务。 因为流量调度,通过网络进行了横向迁移,此刻可能大家会担心对网络带宽占用问题。为因对此问题,SDN网络内部增加了横向交换机的密度,所谓spine-leaf架构,通过增加横向带宽,来满足流量横向迁移的能力。 这种方式的优点很明显:通过设置服务节点,将流量通过网络调度的方式,进行服务编排,可以很方便的接入第三方厂商的传统盒子以及安全虚机。同时,因为通过网络控制器来进行流量牵引,可以自然兼容大部分hipervisor OS厂家——因为引流和虚拟OS没有关系。 缺点主要是增加了横向流量,会增加一部分网络建设的开销。另外在网络时延方面,不如内置在计算节点的方式。最后,采用这种方式,网络设备必须是支持服务编排的SDN网络,这对于采用传统网络方式的客户,增加了改造费用。
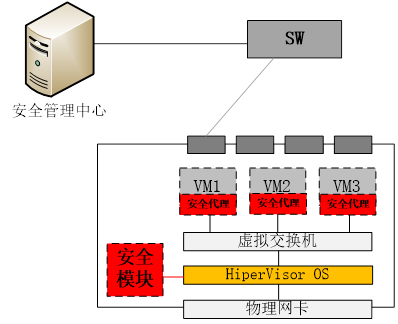
传统终端安全厂商的方案传统终端安全厂商,优势在于有安全终端,劣势在于没有网络产品,也没有虚拟操作系统产品。那么,自然会从自身优势出发,在虚拟机操作系统内想办法来构建安全能力,如下图:
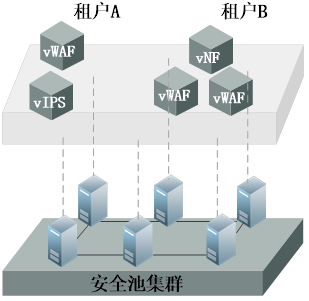
即:通过在虚拟机操作系统内,安装安全代理(通过虚拟机模板部署),以及在HiperVisor OS内安装安全模块,或称之为“无代理”方式,通过在HiperVisor系统底层以及虚拟机操作系统驱动层,捕获数据流以及文件内容,来实现安全防护。一般可实现杀毒、文件监控、网络防护等功能。 这种方式的优点在于,通过在虚拟机操作系统部署安全代理,避免了必须依赖虚拟OS以及SDN网络,而直接实现了流量捕获以及防护。另外,也可以充分利用计算节点的计算能力,无需额外增加安全硬件资源的投入,也不会引起流量的横向调度。 缺点主要有三个:一个是在客户虚拟机上安装代理,会有信任问题。如果客户数据比较敏感,可能不愿意安装第三方的程序在自己的虚拟机内;另外,如果要按照不同租户不同策略来进行防护,还是需要一个集中的管理中心和虚拟系统用户数据库进行对接,以便于识别租户以及下发相应的策略。第三个缺点是防护能力的多样化会有问题,即:很难在这样高度集成的架构内,开放的引入各家厂商的安全能力。 网络安全厂商的方案网络安全厂家,既没有SDN产品,也没有虚拟OS产品。在这种情况下,往往会选择一个中立的态度来构建云内的安全解决方案。 网络安全厂商,优势在于安全产品线很全,可以很快的将安全盒子,虚拟化为各种安全虚机,并池化。如下图:
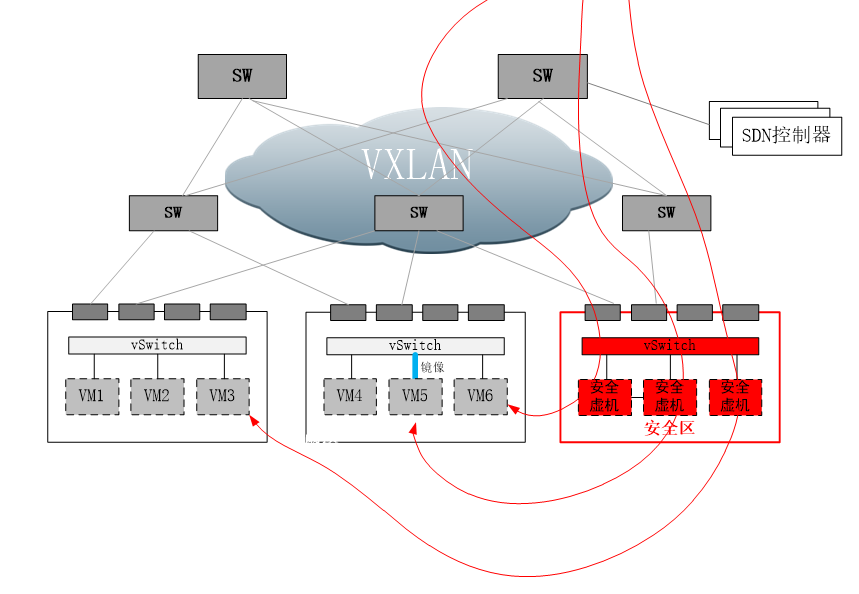
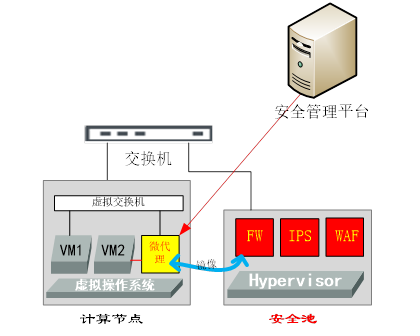
通过在标准x86服务器上,安装各类虚拟机,并形成安全池集群;然后,根据租户的需求,构建虚拟的安全能力,如虚拟WAF,虚拟IPS,以对应虚拟资源的概念。这样做可以将以前安全盒子专属硬件才能提供的能力,灵活的虚拟化到通用硬件,客无须再采购专用硬件,可就地利用虚拟服务器来作为安全池的部署环境,甚至利用现有的虚拟资源池来部署安全虚机。 那么剩下的,就是通过各种方式,将流量往安全池牵引,以实现安全防护。具体的引流方式,需要结合用户网络环境来实现。比如通过SDN API引流,通过传统路由器进行策略路由方式引流,通过虚拟/传统交换机镜像口引流,以及在计算节点内安装引流代理,通过代理方式引流。如下图:
上图的微代理,可以看作一个特殊的虚拟交换机。如果VM2需要被防护,那么只需要拆除VM2和原有虚拟交换机的连接,并将VM2的虚拟网卡,连接到微代理,微代理用TRUNK的方式再连接到虚拟交换机上,这样便不会破坏原有VM2的VLAN拓扑。然后,所有VM2的流量就会经过微代理,即使是同一个计算节点内虚机之间的互访流量,也会被微代理截获。截获后的流量,通过隧道送往安全池过安全策略,然后发回原有微代理进行正常转发。 这种方式的好处在于,通过池化安全能力,可以构建弹性、多样化且开放的安全池,方案本身符合云的特性。同时利用各种引流手段,能够灵活的实现安全防护。 缺点在于,引流方式会带来额外的带宽占用和延时。同时,需要对接不同的客户网络方案,对接成本较大。 总结:综上,可看出目前云环境下,缺乏统一的网络安全设备部署环境,目前局势还有点混乱。从另一个侧面,也看出虚拟化发展过程中,基础设施对于安全方面考虑的缺失。
4、 关于变化和发展安全能力池化传统的安全能力,都是通过固定的硬件盒子的形式提供的。在云时代,这种情况将发生变化。固化的安全能力,不能匹配云防护的要求。安全能力池化,首先是将传统的安全能力(引擎)虚拟化,其次是可弹性伸缩的安全池,最后能适应云环境的部署方式。云环境都是有租户的,那么云平台除了提供基础安全能力以外,也需要提供不同租户需求的不同安全能力套餐,并做到可运营。这样做的原因,本质是为了匹配云的特点:弹性,敏捷,虚拟化,可运营。 未来,传统硬件盒子的份额,可预见会持续下降,虚拟化安全产品的份额则会持续提高,此消彼长。传统盒子为了适应虚拟化,数通部分的模块会退化,引擎部分会持续强化。 在安全池基础上,需要有一个运营平台,对安全池进行统一管理,对安全业务进行灵活的开通、计费,并按照租户查看报表,以及云内部整体态势等功能。传统盒子的安全视角,是基于设备的。云安全池的视角,是基于运营平台的,安全盒子(虚机),只是平台下的一个基础模块。 最后,安全池是软件不是硬件,安全池泛指所有安全能力的集合,包含以安全硬件、安全虚机等组成的混合能力的“池”。 内嵌模式和外置模式互为补充内嵌模式,指的是安全池内置在计算节点内,充分利用计算节点的计算能力进行安全防御的模式,简单可认为如下图所示:
外置模式,正好相反,安全能力放在单独的通用服务器内,如下图所示:
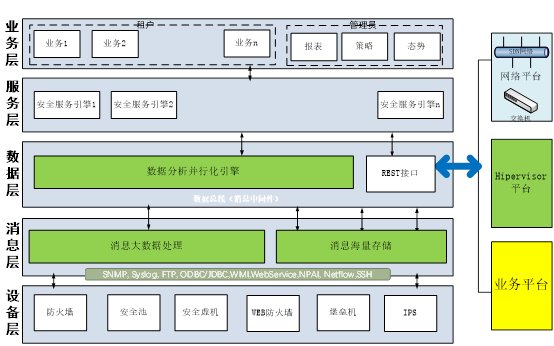
关于这两种方案的优劣势,争论很多。总的来说,内置式的最大优点,是充分利用计算节点进行就近防御。外置式最大优点,是有单独的安全能力空间,不占用计算资源。 不论安全厂商如何声称哪种方案好,从技术角度看,这两种方式实际上是互补的。外置安全池,更适合通过网络调度能力比较强的场合,以及以网络流量防护为主的场合;但是对于网络调度能力弱,需要结合local防护的场合,就适合内置方式。比如HWAF,本地杀毒,就近阻断,以及想在宿主机OS上搞点事情的场合。 外置和内置模式,都有对方干不了的事儿。从技术角度看,互补能够形成最完整的解决方案,缺一不可。无论目前坚持哪一派的厂商,最终都会走到这条路上来。从看见的客户实际需求,以及大厂的收购路线,都能印证这个趋势。 平台为王传统盒子都是以卖盒子为主要销售模式。云机房,不但需要虚拟化的安全盒子(池),还需要处理和虚拟系统的对接以获取租户信息、vxlan信息,SDN引流对接;另外从运营模式看,云平台除了提供基础防护,更重要的是提供满足租户多样化需求的可运营的平台,并满足增值收入。 传统机房只需要安全盒子接入,最多加个网管软件,即可完成销售。对云安全来说,这是不够的,需要提供平台能力,通过将虚拟化能力引入平台,并将平台和云平台的对接,从而提供云防护能力。 云安全平台的模式和盒子不一样,平台模式是平台先行,盒子和虚机随后逐步建设。从这个角度看,得平台者得天下。平台模式示意图简单如下所示:
| |
 (12个打分, 平均:4.17 / 5) (12个打分, 平均:4.17 / 5) |




《关于新一代操作系统的思考》
作者 陈怀临 | 2016-10-02 20:12 | 类型 中国系统软件 | 3条用户评论 »


山石网科下一代防火墙荣获NSSLabs推荐级
作者 陈怀临 | 2016-03-07 12:45 | 类型 网络安全 | Comments Off

关于下一代防火墙的几个思考
作者 tomqq | 2015-11-19 09:47 | 类型 网络安全 | 3条用户评论 »
|
作者:Tomqq,何恐,一个安全人 ,于2015年11月 NGFW(下一代防火墙)出来有些日子了,这3年多来众多主流厂家也都推出了各自的下一代墙。然而热闹之后,下一代墙并没有像厂家盼望的那样,对传统墙形成替代的燎原之势。与此同时,UTM也开始演进,逐渐和NGFW越来越没有区别。此外,虚拟化的兴起,对防火墙也提出了新的要求,不管是传统墙还是下一代墙,在虚拟化面前,不但摆放的位置需要重新定义,甚至对于东西向流量如何去适应也成了需要重新思考的问题。最后,态势感知、安全大数据在今年成为了国内安全届的热门,下一代防火墙应该在新的体系下充当什么角色,等等这些,都需要逐一重新思考,并判断出新的定位。
1、 下一代和防火墙vs传统防火墙/UTM:核心区别在于识别能力 下一代防火墙,按照公安部起草的标准,统一叫做第二代防火墙(GA/T1177-2014《信息安全技术 第二代防火墙安全技术要求》),并将国际通用说法“下一代防火墙”正式更名为“第二代防火墙”。 综观国内外各个不同机构的定义,总的来说认为二代墙和传统防火墙的最大区别是 可视化和高性能这几块,另外是有ips,av,url之类的但是我认为不是本质。比如PaloAlto就说 app Id、user Id + 高性能就是他们的核心技术,其实说的就是用户可视、应用可视,高性能。
另外,说到下一代防火墙和UTM的差别,一般是诟病UTM性能这块。具体到技术上,一般会说UTM是上一代技术,采用包一次通过每一个引擎处理,采用的是串糖葫芦方式,开启安全功能后性能会急剧下降;下一代防火墙是采用分离式引擎,一次性并行扫描处理所以性能会很高云云。实际上这是个伪命题,难道UTM不发展了吗?技术层面的问题都是可以解决的。
所以,在选择的时候人会晕。那么到底区别在哪里呢? 其实Palo是对的,从安全专业角度有句话,叫做“每个层面的安全问题,需要在那个层面来解决”。通俗的来说,先要看见贼,才抓的住贼,可视化这一块在传统火墙的粒度是较粗的,无法在3层来解决如今的7层应用安全问题,因为“看不见”。而性能这个,随着硬件的提升,其实也不存在什么解决不了的问题。至于在NGFW里面加入IPS,waf,行为管理,av,url…理论上厂商可以加入任何他认为有用的模块进去,这些我认为不构成本质区别。
另外,“可视”这个事儿解决好了,相关的Qos,策略执行,病毒扫描等等,都可以用较为精准的细粒度方式,基于“应用/用户”进行。也就是说,“可视”为精细化精准管理奠定了一个基础,这个是传统防火墙基于五元组这种粗放式的管理所做不到的。
最后,性能这块,现在确实比以前有很大提高,但主要还是基于硬件的提升,这个不构成本质区别。所谓的“快”,我认为还是应该有前提的,如果是你裸奔,我满载,你我比快有何用?
2、 下一代和防火墙市场份额:没有想象的大 实事求是的讲,NGFW没有对传统防火墙和UTM形成摧枯拉朽式的颠覆。实际情况是,大部分客户的需求传统防火墙基本能够满足,特别是渠道等中小客户。而且,这个因素把下一代墙的价格拉的也比较低。UTM继续在他的势力范围内销售,并且也越来越接近下一代防火墙。当然,下一代墙也有了自己一定的市场份额,毕竟有下一代墙的厂家,基本会主推这个来替代传统防火墙的销售。防火墙/下一代防火墙的市场边界已模糊,基本还是在原有市场份额里面混战。池子,并没有刨得很大。
下一代防火墙的特点是相对比较融合性的一个产品,比如具有传统火墙的NAT、PPPOE、VLAN、IPSEC/SSL VPN、ACL、Qos等功能,同时也有行为管理、入侵检测、WAF、反病毒、审计/行为管理、URL过滤等各种应用安全的功能。这个特点也容易让他四处树敌,比如摇身一变,可以变身为VPN;再一变,可以变为审计产品;再摇身一变,又可以变身为防毒墙、网页防火墙……事实上,各个厂家研发的下一代墙功能,也正是把自己的优势产品往里面去集成。下一代防火墙出来好几年了,很多客户还是搞不清楚下代墙的区别是啥。这让下一代墙的定位有些尴尬,既是万金油,同时也失去了自己的特点。比如,既然下一代防火墙里面有了IPS,客户为社么还要买单独的IPS? 防火墙里面有了vpn,客户为什么还要买专业的vpn?这都需要厂商好好自问一下类似的问题。
3、 新的挑战:下一代墙还需发展、突破 云技术这两年发展很快,已经不限于论文研究,全国各地陆续开始有越来越多云的建设项目。在云计算场景下,防火墙需要重新考虑他的位置和作用。
比如,在网络虚拟化的场景下,流量的进、出,不再采用传统硬件基于port、vlan等方式,而采用类似vSwitch的软路由方式导入;在私有云的场景,流量会分成虚拟机内部和外部流量情况,即“南北向”、“东西向”流量。这两种流量,需要防护的需求是不一样的,需要区别对待。南北向流量,主要是来自外部的流量,原有下一代墙的需求,本身就可以很好的进行防护;而东西向流量,主要是虚拟机之间的流量。虚拟机之间的隔离,本身就可以用虚拟交换机的策略来进行限制,那么需要防护的,主要是虚拟机之间的流量,比如审计、识别、数据库防护等,是它的主要需求。已有厂家对此进行了研究,比如山石,就很好的把这两种流量的防护,用“云界”、“云格”两个产品来区分,名字也很贴切。而传统硬件防火墙,只考虑了外部攻击的防护,对虚拟机内部,子虚拟机之间的流量还没办法直接防护。
另外,虚拟化形态(虚拟机)的防火墙也开始有了需求。公有云的提供者目前已经开始尝试,将传统硬件防护设备,统统变成平台上的虚拟机形态,通过平台商店,以产品和服务的形式销售。
最后,安全大数据在今年兴起,如利用安全大数据进行 安全态势感知、安全事件关联分析、安全预警等,也对防火墙提出了新的要求,要求防火墙能够具有流量监控和上报数据的能力,并能根据安全中心下发的规则,使得安全问题闭环。
综上,虽然下一代墙出来时间没多久,但是市场的变化,已经要求下一代墙尽快跟上新的变化了。将来不论是下一代墙的硬件形态、部署位置,还是下一代墙的防护内容,都尚需要不断发展,甚至突破。
4、 下一代墙的发展预测
随着云计算、虚拟化的发展,下一代防火墙的形态将逐渐趋软件化,变得软硬不分,硬件只是软件形态的防火墙的宿主而已。 下一代墙可以灵活的部署在任何地方,比如物理网络边界、虚拟机内部、云的内部/外部,或者作为传感器插放在任何需要流量检测的位置。
内外兼修是基本功——从传统防火墙的部署位置看,位于内外网的边界,一边是外,一边是内。因此,边界防御依然还是永恒的话题。对于外部,主要的需求来自于安全防御,因此ips,waf,抗D等等依然会有很强的需求;对内,主要的需求是管控,特别是对于流量、言论内容的管控。因此,对外防御,对内管控,这是一个内外兼修的下一代墙,需要做到的基本功。
万金油2.0—— 传统的ips、waf、审计、行为管理、vpn,以及新的功能,会继续不断地增加进来。当然,范围还是会围绕“流量处理”这一特点来叠加。随着功能的叠加,下一代墙会采用新的灵活的插件机制,通过授权的方式,灵活的增加功能模块,用户按照授权数付费;基本防火墙的功能,将会以一个很低的基础价格销售,大头还是付费模块,这样也很好的解决了和传统墙的价格纠缠不清的问题。
识别能力的持续加强——上面说到,下一代墙最本质区别就是识别能力,即:对应用的识别,对安全问题的识别,对用户的识别,对业务的识别。要防护应用问题,必须要抛弃传统x元组的粗放式防护,必须要持续的强化识别能力,强化dpi/dfi,并尽可能的利用数学建模、大数据、机器智能等方式,来解决靠人手工去识别协议的原始方式。看不见贼就抓不到贼,这是应用爆炸带来的内在需求动力。
软件化、瘦化——除了强化的识别能力,下一代墙其他的能力会弱化,而更多的向传感器、瘦盒子方向演化。比如,L3、L2功能,在云环境下,可以不需要,仅需要保留对流的识别和控制这个核心功能。不管是什么方式部署,流进来,处理,再决定下一跳的转发,这个基本的模式不会变。随着安全大数据化,不论硬件形式还是软件形式的墙,数量会越来越多,而核心功能收缩为数据识别和处理+日志上报。云端通过成熟的数据处理能力,对各种信息进行加工分析,进行态势感知、关联分析挖掘等功能运算,并将运算形成的结论,以ACL的方式下发给防火墙,形成闭环。在数据搜集方面,墙是最有利的一个位置,因为它量大。
另外,随着移动办公的发展,防火墙的物理边界也有着虚拟延伸的需要。因此,BYOD会持续发展,依靠下一代墙数据链路的加密能力,并配合终端数据加密,形成全程数据不落地的安全解决方案。
结束语 现实的生活中总是充满了机遇和困惑,做产品也一样会面对这些问题。面对不断变化的市场需求,唯有坚持围绕价值,拥抱变化,把产品最主要几个层面做好,才有生存下来的可能。 | |
|
(没有打分) |
FireEye 2015 Q3的季度营收报告
作者 陈怀临 | 2015-11-13 11:02 | 类型 网络安全 | Comments Off

M-Thrends 2015--A View From The Front Lines
作者 陈怀临 | 2015-10-26 22:13 | 类型 网络安全 | Comments Off

FireEye . 《The Advanced Cyber Attack Landscape“
作者 陈怀临 | 2015-10-25 21:31 | 类型 网络安全 | Comments Off

15秒对任何大型网络系统的Endpoint安全监控分析
作者 陈怀临 | 2015-10-19 14:30 | 类型 网络安全 | Comments Off

CrowdStrike 2014 Global Threat Report
作者 陈怀临 | 2015-09-09 12:17 | 类型 网络安全 | Comments Off
