




GFT你这么diao,你的伪粉丝们造吗(4)
作者 彩筆 | 2014-05-26 21:44 | 类型 大数据, 行业动感 | 2条用户评论 »
|
GFT诞生背景与应用基础 副标题:愿科技进步惠及每一个人
这是一个给GFT舔脚的系列。前面三篇文章从方法论的角度解剖GFT,本文作为这个系列的终结,为达到“划上圆满句号”的华丽特效,将从(伪)“形而上”的高度俯视GFT,品味一个高科技产品的人文情怀。
作为一个自由主义者,笔者拥护“个人自治权”,认为理想的社会组织应能够确保每个个体的行为不受限制,正当的“灵魂”运行模式应是由内而外的感受“什么是我想做的”,而非由外而内的将“什么是需要我做的”强加到个体身上。 在这样的指导思想下,本文首先用明确的语言表述GFT团队想做的事,其次证明这样一件事是被“需要”的(上纲上线[狂汗],笔者很无奈),再后是这件事的“可行性”,最后有关GFT的实现过程前面三篇文章已介绍过。这个逻辑顺序自然是笔者主观臆测。笔者只是按照自己的情感倾向,在孤立的环节间建立关联。然而作为一个理想主义者,笔者愿意为营造这样美好的未来而奔走。 言归正传。
1. What is it? 心理学上有名的five stages of grief中蕴含着一个很有趣的现象。五个阶段分别是[2]: 1) “否认”:“不会吧,不可能会是这样。我感觉没什么事啊。” 2) “愤怒”:“干嘛啊,这不公平!这怎么可能让人接受!” 3) “讨价还价”:“让我活着看到我的儿子毕业就好。求你了,再给我几年时间。我什么都愿意做。” 4) “抑郁”:“唉,干嘛还要管这些事啊?反正我都要死了。也没什么意义了。” 5) “接受”:“我没问题的。既然我已经没法改变这件事了,我就好好准备吧。” 心理学家用这五个阶段描述人们经历哀伤或失去的过程。“有趣”的地方在于,“接受”是最后一个环节。在前面四个阶段,人们拒绝正确地认识现实,对“客观”也抱持着偏激的态度。我们可以从中学到的是,在到达“正确”之前,必然会受到“干扰项”的蛊惑。为避免弯路和不脚踏实地的态度,“明确定义”是第一步。而将模棱两可的想法实实在在的写下来的过程最有助于厘清思路。 简单粗暴地说,GFT analyze large numbers of Google search queries to track influenza-like illness in a population [1].如果将GFT比作奶牛,它吃进去的草是Google服务器日志中记录的用户提交的检索词,它挤出来的奶是人口中的流感患病情况。 单看效用(理想情况下),它可以向地球人提供每个区域的人口中流感(后来又增加了登革热)患病比例。为追求更高的准确率,需满足的前提是(区域)人口中包含足够数量的Google用户(这其中又隐含了互联网基础设施建设、公民教育普及、人权实现率等,这些都是后话)。
2. Why is it? 运用大数据技术(吐槽:这个说法太模糊了)可以做很多改变世界、造福人类的事,比如运用贝叶斯概率模型结合random walk theory预测股市波动(准确率还蛮高,隐约记得高于80%——但这个概率在实际应用中对应的具体损失有待具体分析),可观的利润自然是池中之物,探囊可取。为什么选择预测流感发病情况呢?GFT团队是这样理解的: (1)流感是人类个体遭受的苦难,减少社会累积财富。Seasonal influenza epidemics are a major public health concern, causing tens of millions of respiratory illnesses and 250,000 to 500,000 deaths worldwide each year. In addition to seasonal influenza, a new strain of influenza virus against which no previous immunity exists and that demonstrates human-to-human transmission could results in a pandemic with millions of fatalities. (2)提前判断疫情有利于降低损失。Early detection of disease activity, when followed by a rapid response, can reduce the impact of both seasonal and pandemic influenza. 在前面的文章中提到过,在这几句类似宣言的外国文字的字里行间,笔者清晰地看见了三个代表中“代表最广大人民群众的根本利益”(笔者政治觉悟不高,如果理解的偏差太大,还请看官们多多包涵),也有与美国英雄们“拯救人类”的行为等同的崇高感。 整个思维过程既脚踏实地、接地气(“流感面前人人平等”),也充斥着人间大爱。GFT向人类世界输出每个区域的疫情严重情况,接下来各个层次的决策者就可以考虑资源分配问题了。
写这一部分的目的就是想传递出:GFT并不是一群人无所事事,以圈钱为最终目的和唯一考虑。它的人文主义情怀(对世界的责任感)下文还有提及。
3. How it’s done? 改善公共卫生状况的途径有很多。GFT拥有大量存储在服务器日志中的检索词(与flu或有关或无关),从Google Search queries到CDC ILI data,是否有可能?GFT团队可能是这样下定决心的: (1)皮尤研究中心2006年发布的一项关于互联网的调查显示,每年有9千万美国成年人在互联网上检索与疾病或用药有关的信息。 (2)在文章[1]的补充资料部分,Google提供了一个其他主题的例子,证明特定检索词的数量变化与现实生活中某些“事件”的发生有关联。如下图所示,曲线表示有关日食的检索词的数量随时间的变化(按周汇总数据),黑点对应日食发生时间。清晰可见,每次日食出现的日期附近,检索词“solar eclipse”的提交数量都明显高出日常水平。也就是说,倘若我们无从得知日食何时会出现,监控Google用户检索“solar eclipse”的次数可以给我们提供很准确的预测。
文献来源:参考文献[1]的supplementary 上述事实不仅能够证明,特定检索词的数量变化与客观世界中的一些事件是“相关的”(大数据所强调的相关关系哦),也暗示了特征检索词数量变化能够反映流感患病的门诊数量(在总人口中的比例)的潜在可能性。准备工作进行到这里,只剩下谨遵Michael Jordan的教诲:JUST DO IT。
总结: 伟大的工作其实一直都有人在做,对公共卫生基础水平的关注并非GFT之始。比如我们熟悉的这个星球上最大的慈善基金会Bill & Melinda Gates Foundation。其下设专门的division Global Health关注和推动有关传染病、疫苗等的科学和技术项目。相比于这些“传统”的做法,GFT的优势是:快。在参考文献[1]中我们知道,GFT比CDC的统计提前2周,即实时。而它若是结合时序分析的技术,实现“提前”预警也不足为奇。这对于资源准备和分配、提前疏散(隔离)等决策的指导意义不言自明。这也难怪很多public health officials都是GFT的用户。(参考文献[3]:In addition to the general public, an important target audience for GFT has been public health officials, who can benefit from reliable daily estimates and often make far-reaching decisions based on predicted flu incidence (such as how to stock and distribute vaccine, and the content of public health messaging). God is a bitch,祂能力有限或心怀不轨,坐视整个人类社会千疮百孔。GFT的内生性不完美略表如下: 1. GFT整个技术体系是大数据,预测的目的却是传统的统计数据。预测的“不准”是因为GFT的结果与“现实”不一致,还是因为CDC根本就代表不了“客观的显示”?(这对于强迫症、完美主义来说,简直闹心死了。) 2. 上一篇文章大言不惭地说,GFT的核心矛盾是无上限的优化统计学习过程的需要。不假。但也还有其他。“联系”的观点,GFT并非独立存在,GFT的问题也并不单一。伴随着Google的推广普及,甚至人类社会的进步(更多的互联网基础设施,更普及的基础教育,基本人权的基本保障等等,GFT会越来越完美,也或许到那个时候,GFT也便不再被需要。
相关文献: [1] Ginsberg J, Mohebbi M H, Patel R S, et al. Detecting influenza epidemics using search engine query data[J]. Nature, 2009, 457(7232): 1012-1014. [2] http://zh.wikipedia.org/wiki/%E5%BA%93%E4%BC%AF%E5%8B%92-%E7%BD%97%E4%B8%9D%E6%A8%A1%E5%9E%8B [3] Copeland P, et al. Google Disease Trends: an Update. International Society for Neglected Tropical Diseases. 2013. available at: http://patrickcopeland.org/papers/isntd.pdf | |
 (没有打分) (没有打分) |

GFT你这么diao,你的伪粉丝们造吗(3)
作者 彩筆 | 2014-05-21 01:37 | 类型 大数据, 行业动感 | 1条用户评论 »
|
GFT 3.0: updated (2013) 副标题:旁观一个技术主管的verbal reasoning ability
注:本文“内容”若非特别注明,均来自“Copeland P, et al. Google Disease Trends: an Update. International Society for Neglected Tropical Diseases. 2013. available at: http://patrickcopeland.org/papers/isntd.pdf”一文。
GFT 2.0针对GFT 1.0对非季节性流感的Underestimate做出改进(在建模过程中增加了09年H1N1爆发期间的检索数据)。GFT 3.0是针对在2012年流感季节,GFT 2.0对实际数据的overestimate作出的改动。 第一次更新时,GFT 1.0 underestimate的原因被归结为季节性流感和非季节性流感期间用户的health-seeking behavior不同,但并未明确指出究竟为何不同。 在构建GFT 3.0时,GFT团队将导致GFT 2.0 overestimate的原因归结为媒体的放大效应。表现为:大众媒体对流感疫情的报道,使更多的未患病个体也进行flu-related检索,导致检索词出现次数与ILI病例比例之间原有的数字关系不再“有效”。
作者尝试在文章中给出以下问题的答案。 1. 为什么12-13年度的流感季节中,GFT的预测过高?Why were this season’s predictions so high? 2. GFT模型是否过于简单粗暴?Is our model too simple? 3. GFT 2.0中是否仍有未考虑到的影响因素?Were there unforeseen side effects from the 2009 update? 4. GFT是否能表现出CDC的ILI数据之外的现象?Does this reveal a phenomenon not captured in incidence data provided by the US Centers for Disease Control and Prevention (CDC)?
旁白:都是好问题,从实际问题出发(overestimation),既有对GFT本身的反思(too simple),也对有关GFT的舆论做出回应。层层递进,有理有据。
1. 怎么就overestimate了 GFT 1.0刚上线时,计划对它每年更新一次。然而在GFT 2.0和GFT 3.0之间,未有annually update。原因是,每个流感过后对GFT模型评估,GFT 2.0的表现so far so good。团队的观点是:不断添加新数据确实能够提高估计的准确性,但对于truly anomalous years的情况无改善。 GFT 2.0一直doing well,直到2012-2013 flu season,模型输出的预测结果明显偏离了真实数据源,(However, in the 2012-13 season, the overestimation peaked at 6.04 percentage points, an estimate more than twice the CDC-reported incidence (week starting Jan. 13: CDC data 4.52%, GFT estimate 10.56%).),drastically overestimated peak flu levels [1]。
2. 简单粗暴,不失有效 GFT团队承认,他们的算法容易受到短期内检索词数量不规则变化的影响,而这些“数量的不规则变化”可能是concerned people对流感相关的媒体报道做出反应的结果。(所以,GFT的直接目的是预测CDC ILI data,但它所能描述的远不止于CDC ILI data。) GFT团队在承认他们的算法sensitive to sudden changes in query volume的同时,也巧妙地表达了不能公开组成模型的检索词的必要性。作者回忆在2008年发布GFT 1.0时,New York Times的一篇报道碰巧包含一个模型中的检索词。他们马上就看到了这条检索词流量的增加。笔者不禁想到,Lazer [2]在他的文章中一边要求Google公开GFT的内部细节,一边也担心所谓的red team issues(用户有预谋地操纵“数据生成过程”),是赤裸裸的自相矛盾啊。
3. Unforeseen side effects肯定是有的了 基于上述推理,GFT团队进一步修正了模型,以摆脱媒体报道的影响。 (1)为降低算法的sensitivity,GFT团队用“spike detectors”监测数据中inorganic检索词流量,并将其从模型中剔除。做法:The system receive time series data of the flu-related queries as input and validates whether the latest counts are within expectation, based on statistical variations from what we have seen in the past. 从2008年以来的数据得知:大多数由新闻报道引发的关注所导致的query spikes大约持续3-7天。这种情况导致,上述处理过程只能solve for short-term spikes,对在整个流感期间延续的high query volume无能为力。 (2)除此之外,作为对于外界普遍吐槽的GFT模型简单的回应,GFT 3.0也尝试了几个高大上的优化算法。
LARS是更适合高维数据(比如:变量数多,案例数少)的一种回归算法。在对多个自变量回归分析,得到1个因变量的预测的分析过程中,LARS算法可以确定哪些自变量参与回归,并得到这些自变量的系数。
LASSO和Elastic Net均是对回归模型进行规范化(regularization)的方法。LASSO(Least Absolute Shrinkage and Selection Operator)的penalty function为
。Penalty function为包含λ1(线性)和λ2(二次)的部分。 写这些并不是为了让每个读者都看懂甚至理解,而是为了给大家营造一种身临其境的感觉:GFT不再是那个国内本科学生毕业设计的非专业水平了。各个优化版本模型的预测效果可见下图。
从图中可以明显看出Current Model对CDC data的overestimate,但究竟哪个优化的模型效果最好却不显而易见。特此为每个模型的预测输出计算RMSE,Elastic Net的RMSE最小(1.22),即其效果最好。
写在最后的话 纵使笔者心中仍有千万次的问,作者的文章到此便戛然而止了。笔者很忧伤,却也毫无办法,只能开始总结。 从逻辑上讲,GFT的一切行为都是合理的。对于在每一处关键点上的选择,不排除其他alternatives的存在,但是不存在比GFT的选择明显更优的处理方式。 纵观整个GFT模型更新的过程,第一次更新向仅有季节性流感数据的旧模型添加非季节性流感的数据,自此,GFT双腿健全,可以稳健地丈量CDC数据。 CBS热播剧《BONES》中的starring actress有一句频繁出现的台词:I believe in patterns。还没想清楚的人不妨认真考虑一下了:GFT并不是literally“神来之笔”,它的诞生机制和工作原理决定了它的输出结果(对CDC数据的预测值)是依赖统计学习习得的“规律”,将现有值与未来某时间的“可能值”建立联系,而已。期待它给出一个确定的真实值这个愿望是不切实际的。 私以为,pattern比truth更加客观。每个人都可以把自己坚持的称作“真理”,并拒不接受说教。Pattern却不然。A出现10次中,有8次B也同时出现(贝叶斯[崇拜样]),这就是一个pattern。下次A出现时,笔者愿意投入成本做好B伴随出现的准备。也许有人会问,会不会A出现的10次中B也出现10次?To这样可爱的同学:当然会啦。只是这样的情况,如何确定B不是A的天然组成部分)?哈利波特偷偷去霍格莫德村,穿着隐形衣帮忙打架,不小心将头露了出来,马尔福少爷回学校打小报告时的推理过程是这样的:你的头出现在了那里,那么你的身体也一定在那里。See the beauty of uncertainty。换句话说,当pattern变成了“注定”的(definite),也便失了趣味性。【写这一段的目的是想传达:GFT是应用统计学习方法做出来的一个产品,各界都需要调整好对GFT的期望值。同时,也从逻辑上引出下一段。】 所以说GFT团队的vision也是极其精辟的。对GFT的第二次更新并没有纠结那些学者们不肯放手的检索词问题,可重复性问题——这些都不重要。GFT的核心矛盾必须是对统计学习方法的无上限的完善过程好么。按照大数据的处理思维,从原始数据中直接捞出来的(may not be perfect),但一定是best | available了。文章[3]点到为止地总结了入选模型的几个检索词的主题,以及数量和体量(占比)等,只不过是可视化不可见“模型”的一种手段而已。一些矫情的人类个体给点儿阳光就灿烂,嫌弃“描述性”的内容太少,各种,已经不单是避重就轻的迟钝,甚至是买椟还珠的愚蠢。 GFT的第二次更新考虑了多种优化模型的算法,反映了统计领域的state of art,不管从战略还是战术上看,都妙极,妙极。
关于副标题:都说是“旁观”了,顺便看一下得了。总的来说,原文是一篇虎头蛇尾的文章。前面铺垫的絮絮叨叨,像极了革命战士喜欢的千层底儿的鞋,结尾却只有戛然而止,断没有余音绕梁,徒留笔者独自在电脑前神伤好嘛。
相关文献: [1] Butler D. When Google got flu wrong[J]. Nature, 2013, 494(7436): 155. [2] Lazer D, Kennedy R, King G, et al. The Parable of Google Flu: Traps in Big Data Analysis[J]. Science, 2014, 343(6176): 1203-1205. [3] Ginsberg J, Mohebbi M H, Patel R S, et al. Detecting influenza epidemics using search engine query data[J]. Nature, 2009, 457(7232): 1012-1014. | |
 (1个打分, 平均:5.00 / 5) (1个打分, 平均:5.00 / 5) |

GFT你这么diao,你的伪粉丝们造吗(2)
作者 彩筆 | 2014-05-10 08:55 | 类型 大数据, 行业动感 | Comments Off
|
GFT 2.0: updated (2009) Add unseasonal influenza to seasonal influenza
前一篇文章完整地记录了GFT诞生的全过程。
GFT 1.0发布于2008年11月,建模参考的CDC数据为2003-2008年3月(全部为季节性流感的统计数据),预测2008-2009年的疫情。GFT 1.0在线期间,有评论表示担心,GFT 1.0之所以能够准确的预测流感疫情(以CDC发布的ILI统计数据为准),很可能是由于用户在网上检索医疗信息的“群体行为”在时间上的一致(may be limited by the consistency of inline health-seeking behavior)。如果是这样,那么,在季节性流感和非季节性流感爆发期间的不同情境下,用户的检索行为是否仍能保持一致?是否会有不同的terminology规律?等。 Thus, an open question was whether GFT could provide accurate estimates of NON-SEASONAL FLU.
2009年爆发的H1N1为GFT提供了预测非季节性流感疫情的训练数据(The 2009 influenza virus A (H1N1) pandemic [pH1N1] provided the first opportunity to evaluate GFT during a non-seasonal influenza outbreak.)。 GFT 2.0发布于2009年9月24日,预测了2009年9月-12月的疫情。
2.0与1.0的methodology是相同的。本文依据参考文献[1],从模型所包含检索词的数量(number)和体量(volume)、模型对历史数据的拟合效果两个方面对比1.0与2.0两个版本的GFT。检视GFT 2.0的准确率,并从检索词的数量和体量(volume)变化窥探用户检索行为和terminology的变化。
一、构成两个模型的检索词的特点 (1)采纳的检索词数量和体量 l GFT 2.0包括160个与流感活动有关的检索词,而1.0的版本中只有40个。 l 尽管2.0的版本使用的检索词数量将近是1.0版本的4倍,但是,GFT 2.0的检索词体量只有GFT 1.0的1/4。因为GFT 2.0使用了更多不常见的检索词(due to the inclusion of less common queries than in the original model)。 l 两个模型有11个重合的检索词,占GFT 2.0体量的50%,却只有GFT 1.0的11%。 (2)内容 l GFT 2.0包含的检索词直接与influenza有关,而非是与流感有关的病症(比如:influenza infection, such as “pnumonia”,拼写错误是故意为之,保持与检索词的原始形态一致): a) (流感引发的疾病)主题是influenza complication和symptoms of an influenza complication的检索词占GFT 1.0体量的48%,但是在GFT 1.0中只有17%; b) 主题是general influenza symptoms和specific influenza symptoms(即与流感直接相关)在GFT 2.0中占69%,但在GFT 1.0中只有8%; c) 在GFT 2.0中,包含flu的检索词有72%(个数38%),在GFT 1.0中只有14%(个数2%)。
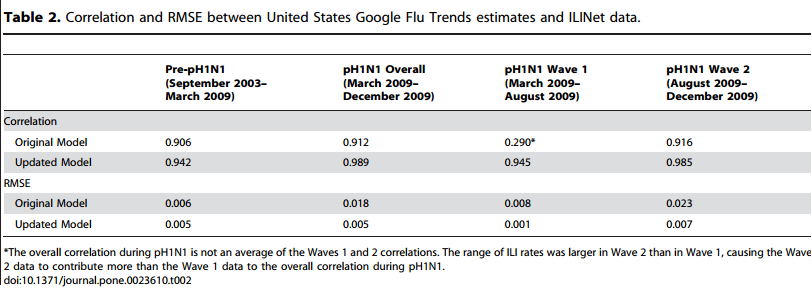
将检索词按照主题汇总,比较每个主题的大小如截图Table 1。 文献来源:参考文献[1]
二、两个模型的预测效果对比 首先,将整个研究区间划分为4个时间段: (1)阶段1:pre-H1N1 (2003年9月-2009年3月) (2)阶段2:H1N1 overall (2009年3月-2009年12月) (3)阶段3:Summer H1N1 (2009年3月-2009年8月) (4)阶段4:and Winter H1N1 (2009年8月-2009年12月)
接着,对比两个模型的预测效果的参考指标,结果如截图Table 2: (1)相关性 Pearson Correlation (2)误差 RMSE
结论: 1. 在4个阶段中,模型的估计值与ILI数据的相关性 在阶段1和阶段2,两个模型都与ILI数据高度相关; 在阶段3(H1N1流行期间前半段),GFT 1.0与ILI数据无关(0.290),而GFT 2.0与之非常相关(r = 0.945); 在阶段4(H1N1流行期间后半段),两个模型均与ILI数据高度相关,相关系数分别为(r = 0.916 and r = 0.985)。
2. 两个模型对ILI数据的描述程度 粗略地讲,在统计学中,用R2表示所建立模型对变量之间关系的描述了多少,取值在0-1之间,RMSE = 1- R2。 所以,根据Table 2中的数据可知,GFT 1.0对ILI数据的描述能力比GFT 2.0差,在阶段2最差(GFT 2.0的RMSE是GFT 1.0的3倍多)。
3. 总体趋势 虽然,两个模型的估计值与ILI的数据均强相关,从Figure 1的2个图(尤其是A图)中还是可以明显看出拟合效果的差异。 两个模型都能够对2009年早期季节性流感期间的疫情做出准确的估计。在整个pre-pH1N1期间,2.0与ILI数据的相关性比1.0稍好(1.0: r = 0.906, RMSE = 0.006; 2.0: r = 0.942, RMSE = 0.005)。并且,2.0的预测值与4个ILI峰值一致(共出现6个峰值);而1.0只与3个峰值一致。 文献来源:参考文献[1]
三、H1N1期间的检索行为 通过前文的对比,可以得出,在整个时间段,两个模型的估计值与ILI数据均强相关,但GFT 2.0的效果略好于GFT 1.0。然而,在阶段3,也就是H1N1爆发期间的前半段,GFT 1.0的估计值与ILI数据不相关,而GFT 2.0强相关。也就是说,改进后的模型不仅能够拟合原有的ILI数据(季节性流感爆发的数据),也能够拟合新产生的数据(非季节性流感爆发期间的数据)。 同时,旧模型完全不能够拟合新产生的非季节性流感的数据,也说明,在季节性流感和非季节性流感两个阶段,数据中确实发生了变化。
如本文开头提到,主流的观点是认为是用户的信息检索行为发生了变化。 参考文献[1]对用户行为的探索是通过对构成模型的检索词的数量前后变化的比较进行的。 作者们观察到,在整个H1N1期间,GFT 1.0中检索词的数量比期望的要低(考虑之前得到的检索词数量与ILI数据之间的数量关系),导致其对ILI数据预测值偏低。为了检测这种变化对模型的影响,用每个主题的检索词数量和ILI数据建立模型。结果,这些模型几乎都低估了在H1N1期间的ILI数据。原文给出了2个例子,如Figure 2。
同样,在用地区数据进行的类似分析中,也表现出,GFT 1.0对实际值的预测偏低(与使用全国范围的数据得到的结果一致)。
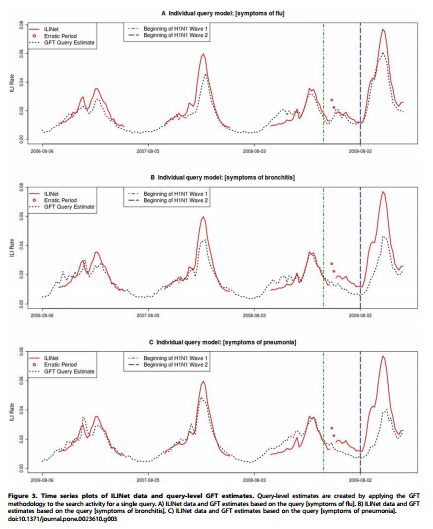
Figure 3展示的是ILI数据和单个检索词构建的模型预测值,“symptoms of flu”, “symptoms of bronchitis”, and “symptoms of pneumonia”。在H1N1之前,这三个检索词能够很好的拟合ILI数据。在H1N1期间,“symptoms of flu”仍能很接近的拟合ILI数据,但是“symptoms of bronchitis”和“symptoms of pneumonia做出的估计已经明显的低于实际值,尤其是在H1N1爆发期间的后期。 文献来源:参考文献[1]
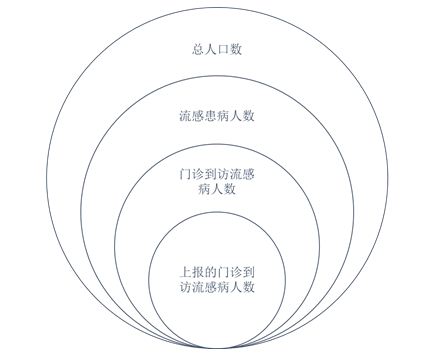
讨论: 从上面的过程中,我们可以得出,在季节性流感和非季节性流感爆发季节,用户检索医疗卫生信息所使用的检索词确实发生了变化(用户行为变化)。 然而,要准确地指出导致这种行为变化的原因是很困难的。作者列出了几个可能原因,解释GFT 1.0低估H1N1活跃度的原因。 1. 用户减少了使用与influenza complications such as bronchitis and pneumonia有关的检索词。这个主题的检索词在GFT 1.0中占据很大比例。 2. H1N1病毒出现于春夏的月份,与秋冬月份(季节性流感高发时期)不同。人们极有可能在冬天和夏天使用不同的检索词。 3. GFT建模使用的ILI数据,来自各地各类医疗卫生机构向CDC的报告,因此,CDC统计的数据可能跟ILI的真实情况有差。另外,ILI的数据估计的是因流感而到访门诊的病人在总人口中的比例,这个数据既有赖于实际的流感发病情况,也依赖患病者中实际去门诊的比例。后者的变化能显著影响ILI的数据以及GFT模型的估计值。(三个数据的转化关系见下图) CDC实际统计到的ILI数据为:(上报的)门诊到访流感病人/总人口数,然而,它将“上报的门诊到访流感病例数”作为对“门诊到访流感病人数”估计。而GFT的社会使命是估计流感患病人数/总人口数。由此也可以看出,模型“与生俱来”的假设才是导致“预测不准”的根源。只是这种根源,有点宿命的不可改变的韵味。(即便GFT能够“准确”地预测出CDC统计的ILI数据,ILI数据又代表了什么?)
写在最后: 请牢记,除了每年更新一次GFT建模数据之外,GFT的Methodology到目前为止只更新过2次。本文记录了第一次,接下来会有一篇文章介绍第二次更新。 作为第一次更新,GFT补充了在非季节性流感爆发时的数据。从GFT 2.0与ILI数据的相关系数和RMSE来看,模型2.0对现实数据的拟合情况是很好的。So,until now,GFT已经prepared for everything。能想到GFT第二次更新了什么吗?敬请期待。
参考文献: 1. Cook S, Conrad C, Fowlkes A L, et al. Assessing Google flu trends performance in the United States during the 2009 influenza virus A (H1N1) pandemic[J]. PloS one, 2011, 6(8): e23610.
小吐槽:这篇文章在内容上的组织结构并不好(就更别说“巧妙”了),不知道是不是因为不是正式出版物所以标准降低。 | |
|
(没有打分) |
Google Flu Trends: Algorithm Dynamics
作者 彩筆 | 2014-04-28 10:47 | 类型 大数据, 行业动感 | Comments Off
|
正文中的指代: 文章A:Lazer D, Kennedy R, King G, et al. The Parable of Google Flu: Traps in Big Data Analysis[J]. Science, 2014, 343(6176): 1203-1205. 文章B:Butler D. When Google got flu wrong[J]. Nature, 2013, 494(7436): 155. 文章C:Copeland P, et al. Google Disease Trends: an Update. International Society for Neglected Tropical Diseases. 2013. available at: http://patrickcopeland.org/papers/isntd.pdf
本文继续讨论文章A作者认为导致GFT出错的因素(two issues that contributed to GFT’s mistakes)之二:Algorithm Dynamics。 在系列(一)中简单提过,作者(在所有可能产生混淆的情况下,下文出现的“作者”均指文章A的作者,没有例外)所说的Algorithm Dynamics包括2个意思:1. Google的工程师为改善服务对算法做出改动;2. 用户使用行为的改变。作者认为,这两个因素致使GFT对流感趋势的反映不稳定。(At a minimum, it is quite likely that GFT was unstable reflection of the prevalence of the flu because of algorithm.)
在文章A发表之前,对GFT预测有偏最常见的解释是:在(前一个)流感期间,媒体的宣传报道引起更多本身没有生病的人进行与流感有关的检索,(The most common explanation for GFT’s error is a media-stoked panic last flu season.)导致对今年流感样病例的较高估计。 比如,在2013年初,GFT的预测值是实际值的2倍,文章B中写过,一些专家认为the problems may be due to widespread media coverage of this year’s severe US flu season, including the declaration of a public-health emergency by New York state last month. The press reports may have triggered many flu-related searches by people who were not ill. 文章C(第一作者Patrick Copeland,目前职位:Senior Engineering Director – Google)记录了针对GFT(以及Google Dengue Trends)在2012年表现出来的overestimating influenza-like illness (ILI)所做的改进。其作者在文章中提到:We have concluded that our algorithm for Flu and Dengue were susceptible to heightened media coverage.
然而文章A的作者认为:媒体报道导致用户群体行为模式的改变是可能的影响因素,却无法解释为什么GFT曾经在连续108个星期中有100个星期的预测值偏高。(Although this may have been a factor, it cannot explain why GFT has been missing high by wide margins for more than 2 years.)(GFT has missed high for 100 out of 108 weeks starting with August 2011.)如下图,参考线右侧为包括100个overestimate数据点的108个星期的数据。 他们认为可能性更大的原因是Google搜索算法的变动。(A more likely culprit is changes made by Google’s search algorithm itself.)并用blue team和red team来比喻来自两个方面的作用力。 注:”blue team”和”red team”在英语中义项较多,在此不做过多解释。
文献来源:文章A
1. “blue team” dynamics – where the algorithm producing the data (and thus user utilization) has been modified by the service provider in accordance with their business model 也就是前面提到的Google主动修改算法。在文章A随附的supplementary materials中,从第10页开始图文并茂的展示了多个作者认为会导致GFT结果不准的Google对算法的改动。这里拣选作者在正文提及的供大家管窥。 案例1 2011年6月,也就在GFT开始持续高估ILI的前几个星期,Google新增了相关检索这一功能。比如,检索“flu”会返回流感诊断和治疗的推荐。作者认为,这导致了流感诊断和治疗检索次数的虚高,并进一步使得GFT的预测不准。(是的,没有提供“事实”,只有“推测”。案例2也是这样。) 案例2 2012年2月,Google推出Health Search Box服务:当用户检索某种症状时,会返回症状可能的诊断。作者尝试检索“runny nose and fever”,返回的结果中“flu”和“common cold”分别排在第一、二位(见下图)。作者由此推断,Health Search Box可能导致了2012-2013年间流感高发季节,GFT统计的 “cold vs flu”和“cold or flu”的搜索数量激增。(As the reader can see, the top two results are for the flu and the common cold. This seems a likely reason why searches like “cold vs flu” and “cold or flu” seem to spike up in the 2012-2013 flu season.)
文献来源:文章A的supplementary materials 或许作者也意识到,单纯罗列假设很难make a case,于是在另外的切入点提供了一个用户行为确实被改变的事实论据。 案例3 Google发布Health Search Box时,提供了一个演示案例,如下图。作者认为,这种情况相对罕见。 注:“这种情况”是指用户一次性输入检索词“abdominal pain on my right side” exactly。因为Google在为GFT建模时,统计的是一次完整的用户输入为基本单位,不对其做其内容任何处理。
文献来源:Improving health searches, because your health matters, Google; http://insidesearch.blogspot.com/2012/02/improving-health-searches-because-your.html,转引自文章A supplementary materials 而实际上,在Google发布公告前后,“abdominal pain on my right side”的检索次数(模式)真的有明显不同,见下图。
文献来源:Google Trends, www.google.com/trends/,转引自文献A supplementary materials,downloaded data available in replication materials.
结合三个案例来看,作者说的不无道理。(作者意欲证明,Google对检索服务的改进会影响用户检索模式,并进一步导致GFT模型失效。)但也未到言之凿凿的程度。 写过GRE Analytical Writing的同学应该很容易在上述推理中找到不止一个unstated assumptions,笔者出于写作方便随机总结若干如下: 1. 在案例3中确实能够看到“用户群体行为”的“突发性”变化,但并不意味着这种突发性也存在于案例1和案例2的过程中(待证明); 2. 在案例3中肉眼可见的“突发情况”的极端情况,无非是对“abdominal pain on my right side”的检索由0次增加至约100次。这种变动幅度,在以“某检索词被检索次数占同时期所有检索次数比例”为建模依据的GFT中,对最终结果会产生影响吗(同样待证明);
此外,Blue team issues并非Google独有。类似Twitter和Facebook都会频繁被重新设计。作者十分担忧blue team issues对科学实验的可重复性的影响(虽然他们这样担忧的依据也并不充分)。
2. “red team” dynamics – occur when research subjects (in this case Web searchers) attempt to manipulate the data-generating process to meet their own goals, such as economic or political gain 也就是用户利用系统逻辑来达成自己的目的(在过程中可能会扭曲系统逻辑本来的目的)。作者认为这GFT暂时不存在这类问题,但需引起科研人员的注意。
小结: 原文:Search patterns are the result of thousands of decisions made by the company’s programmers in various subunits and by millions of consumers worldwide.这一点无需否认。但笔者始终认为,作者将search patterns的变化与GFT预测结果联系起来的推理证据不足。
反思: 写到这里,文章A的主体内容介绍完了。围绕文章A展开讨论GFT的系列文章亦到此为止,特此告知。 笔者很消沉。原来,把“一本书”读厚再读薄之后,并没有满溢的成就感,反而是铺天盖地的空虚。 GFT的模型是不完美的,然而这个世界上存在“完美”吗?(据说在英语文化中,perfect一词连比较级的派生含义都没有。)出于对大数据应用的热爱,对GFT自然是爱屋及乌。最初看到这样一篇发表在Science上,为GFT提供改善建议的文章,笔者兴奋坏了。果壳网的简单报道(http://www.guokr.com/article/438117/)对(不读论文原文的)中文读者远远不够,Time.com(http://time.com/23782/google-flu-trends-big-data-problems/)上的内容太通俗,只简单改写了论文内容,以便于更一般的读者接受。然而笔者这一个系列的文章写下来,像是激情过后(It doesn’t have to be sexual.-_-|||。如果是sex过程,涉及到的激素就远不止肾上腺素啦:P),肾上腺素恢复正常水平,空落落——连被子都抱不紧。作者的points都是老生常谈(大言不惭地说,所有的统计分析都需要纠结这些问题)。退一步讲,即便是旧瓶装新酒,作者也没有给出solid evidence,证明GFT存在这些常见统计分析问题,并且,就是这些统计分析过程降低了GFT预测的准确程度。
另外,文章A的supplementary materials还给出了一些实证研究的结果,证明结合使用“大数据”与“小数据”,对ILI的预测准确程度高于仅使用单一类型数据所做的预测结果。对此,笔者的看法是这样的。 笔者(还是那个“大数据婊”)在系列(二)中提到过,GFT的伟大之处在于“即时”,甚至“超前”。GFT比CDC提前发布预测结果的2个星期时间,人类有机会去挽救,死亡或痛苦。笔者认为,在“实时”甚至“超前”面前,准确率必须退居次要位置。更何况GFT到目前为止的预测结果在变化方向上无差错。作者纠结的只是数值大小。 正因大数据的这个特性是传统数据所不具备的,所以将两者综合使用会损失掉大数据的这一优势。也正因如此,笔者同意GFT需不断完善其算法,提高准确率,但“提前性”不容compromise。 “I’m in charge of flu surveillance in the United States and I look at Google Flu Trends and Flu Near You all the time, in addition to looking at US-supported surveillance systems,” says Finelli. “I want to see what’s happening and if there is something that we are missing, or whether there is a signal represented somewhat differently in one of these other systems that I could learn from.”(from文章2) ——笔者看来,对于非大数据应用研发人员,这种心态就很健康。 | |
|
(没有打分) |

The Mathematics of Romance (1):Preliminary
作者 彩筆 | 2014-04-28 10:45 | 类型 互联网, 大数据, 行业动感 | Comments Off
|
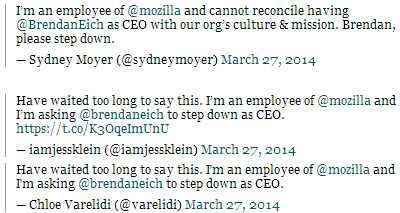
几天前的Mozilla CEO一事沸沸扬扬。自2013年4月,经过近1年的苦苦寻找,Mozilla终于在3月25日公布了新CEO人选——JavaScript创建者、Mozilla当前CTO——Brendan Eich [1]。然而,10天之后(4月4日),新上任的CEO即因曾经(2008年)支持加州反同性恋婚姻提案、捐款1000美元,以及公开发表过歧视同性恋的言论,被迫离职[2]。 关于前文所列原因的真实性,作为怀疑论者的笔者始终存疑。不过,一些媒体截取了部分Twitter上的“民意”,展示出Eich的不受欢迎(可参考下图[3])。
不管怎样,另一个角度的报道更吸引笔者:“The Hypocrisy of Sam Yagan & OKCupid”(笔者试译:“假惺惺的SY和OKC”)[4]。 So, who is Sam Yagan? & what is OKCupid? 简单的说,Sam Yagan是OkCupid的联合创始人。OKCupid是一个很有名气的相亲网站。 Sam Yagan is an American Internet entrepreneur best known as the co-founder of OkCupid. In 2013, he was named to Time Magazine’s 100 Most Influential People in the World’s list. He is currently the CEO of the world’s largest e-dating site, Match.com.[5] 注:2011年2月2日报道,Match.com以50 million美金收购OkCupid。[6] 他们做了什么? 3月31日,用Mozilla登录OKCupid的用户会看到以下内容: “Mozilla’s new CEO, Brendan Eich, is an opponent of equal rights for gay couples. We would therefore prefer that our users not use Mozilla software to access OkCupid.”[7] 他们在联合OKCupid用户抵制使用Mozilla,以表达对新任(2014年3月上任)CEO在2008年曾经给加州反同性恋婚姻提案捐款1000美金这一(系列)行为及其所代表立场的否定。 “假惺惺”一文认为:OkCupid played a major role in the successful effort to bring down Mozilla CEO Brendan Eich.(OKC在扳倒Brendan Eich中起到了决定性作用。)并质疑OKC此举的动机:PR,nothing but PR。(具体内容请参考原链接,作者用一个事实论据巧妙地佐证自己的观点。因与本系列文章主旨无关,不在此详述。) By the way, OKC在4月2日撤销了上述行为。 笔者在此补充一项数据(除“说明”数据本身之外不做任何解读,读者可自行用于证明各自的立场)。下图是在Google Trends(googel.com/trends)检索“OKCupid”的结果。图中由A-I标注的点表示OKCupid(以下简称OKC)出现在某媒体头条。在A右侧的区域最小值对应2014年3月热度89,而4月份不完整数据已累积为100(曲线最右端上扬的最高点)。
笔者认为,数据分析从业人员的基本修养(之一),立场并非“必需品”,对“结论诞生过程”的“批判性审视”才是。在这种“朴素推理”产生的结果面前,最有效率的处理方式是保持沉默。(我)既不能提供“硬”数据以支持或反驳,也不能通过比嗓门的方式强迫别人接受(我的)观点。对事情的关注可以简单看看“投票结果”就可以了,即便“结果”也不足以说明“问题”(“少数服从多数”还是“真理往往掌握在少数人手中”?)。关于数据分析结果在其中扮演的角色(社会功能)是另外一个任重而道远的过程,还是让其他“更有话说”的人去说吧。 最后引用张有待(新浪微博@有待)老师在2013-2014深圳迷笛音乐节领奖(中国摇滚贡献奖)时讲的一句话:Time will tell。(他是个寡言的人。)
言归正传。这次的the Mathematics of Romance系列将会从OKC出发。
之前提到过一些,OKC is a free friendship, dating and social networking website,在07年被列为Time magazine十大相亲网站之一[8]。 OKC现在是IAC/InterActiveCorp旗下的网站之一(下面列出IAC所有的网站,为读者建立IAC逼格的baseline)。其创始人(Chris Coyne, Christian Rudder, Sam Yagan, and Max Krohn)在鼓捣出TheSpark(OKC的最初版本)的时候还是哈佛大学的学生。 文献来源:[9] OKC除了提供一般的instant messages和emails等服务外,最有特色的是他们计算匹配度的方法。数据源有2个:users’ activities on the site and their answers to questions。通过回答问题,用户不仅给出了自己的答案,也暗示了他/她能够接受的选项范围,以及不同选项对他/她来说的重要程度。对于得分较高的用户,会收到一封邮件告知:他们是OKC最有吸引力的用户,可以在他们的匹配列表中看到更多的attractive people。最后,OKC还会写一句”And, no, we didn’t just send this email to everyone on OkCupid. Go ask an ugly friend and see”. 是不是逼格特别高[笔者很欢乐]。 2009年7月,OKTrends(Dating Research from OKCupid)上线。OKC网站自2004年发布累积了大量数据。OKTrends团队成员分析OKC用户产生的交互数据,在OKTrends(以下简称OKT)的博客上跟大家分享things they’ve learned about people,并且他们只发布那些他们认为有趣的内容。不幸的是,OKT的博客在2011年停止更新。 然而,有了这些博客,笔者得以研究和整理他们的做法(Please keep in mind that这些research是在2009-2011年进行的,与GFT在同一时期诞生)。了解他们是如何利用既有的数据(读者将会在后续文章中发现,同样是“大数据”,GFT与OKC的处理方式并不相同,后续文章将结合实例探讨细节上的差异)、如何根据特定的需求设计数据生成过程、如何在具体的应用情境下解读数据,等等。 我已经迫不及待的要向大家介绍: 1. 你的哪些特质影响你的吸引力(在社交网站上让其他人主动联系你)? 2. 人们在选择感兴趣对象时的博弈心理是怎样的? 3. 第一次向(感兴趣的)陌生人打招呼应该说些什么? 4. 第一次见面时可以聊哪些话题? 5. 以及OKT团队是如何得到这些结论的。 如果不与整个系列的文章冲突,笔者还将介绍另外一个数学博士利用OKC的数据给自己找对象的案例。让我们一起期待吧。
补充说明: 同GFT一样,OKT同样十分注重用户隐私,他们声明: All data is anonymized and aggregated; no member of our blog staff sees an individual user’s personal information.
最后,以下是OkCupid’s Blog Team的成员名单,是笔者要由衷感谢的人(都是一些经历丰富、十分有趣的人,希望笔者有机会在后续文章中介绍他们): Sam Yagan—CEO Christian Rudder—editorial director / data analyst Max Shron—data scientist Chris Coyne—creative director
参考链接: [1] Mozilla任命JavaScript发明人Brendan Eich为新任CEO. 张勇. 2014-03-25. CSDN. http://www.csdn.net/article/2014-03-25/2818955 [2] 唏嘘不已!Brendan Eich上任Mozilla CEO仅十天即因歧视同性恋被迫辞职. 钱曙光. 2014-04-04. CSDN. http://www.csdn.net/article/2014-04-04/2819159-mozilla-ceo-brendan-eich-resigns [3] 同[2] [4] THE HYPOCRISY OF SAM YAGAN & OKCUPID. 2014-04-06. http://uncrunched.com/2014/04/06/the-hypocrisy-of-sam-yagan-okcupid/ [5] Sam Yagan. Wikipedia. http://en.wikipedia.org/wiki/Sam_Yagan [6] Christian Rudder. Wikepedia. http://en.wikipedia.org/wiki/Christian_Rudder [7] OKCupid asks users to Boycott Firefox because of CEO’s gay rights stance, Russell Brandom, 2014-03-31, http://www.theverge.com/2014/3/31/5568136/okcupid-asks-users-to-boycott-firefox-because-of-ceos-gay-rights [8] OkCupid. Wikipedia. http://en.wikipedia.org/wiki/OkCupid. Accessed at 2014-04-26. [9] IAC/InterActiveCorp. Wikipedia. http://en.wikipedia.org/wiki/IAC/InterActiveCorp. Accessed at 2014-04-26 | |
|
(没有打分) |

Netflix推荐算法
作者 AbelJiang | 2014-04-28 10:31 | 类型 大数据, 机器学习 | Comments Off
|
前一阵子听闻阿里巴巴搞了一个推荐算法大赛,顿时想起Netflix搞过的Nexflix Prize. 大赛始于06年,Netflix希望通过比赛来找到合适的算法,以提高其推荐系统Cinematch的准确率,并承诺给使其准确率(以RMSE作为评测标准)提高10%的个人或团队一百万刀的奖励。最终,融合了多个参赛队伍的混血团队BellKor’s Pragmatic Chaos因为提交时间原因险胜The Ensemble团队,成功提高了10.06%的准确率,在09年拿下该大奖。由于用户及FTC等机构对于隐私问题的忧虑,第二届大赛还没开始就被取消了。在中国,估计应该不会因为这个原因停赛吧?下面就贴出当时获奖团队发表的论文。 Yehuda Koren,The BellKor Solution to the Netflix Grand Prize A. Töscher, M. Jahrer, R. Bell,The BigChaos Solution to the Net ix Grand Prize M. Piotte, M. Chabbert,The Pragmatic Theory solution to the Netflix Grand Prize | |
|
(没有打分) |
GFT你这么diao,你的伪粉丝们造吗(1)
作者 彩筆 | 2014-04-28 10:31 | 类型 大数据, 行业动感 | Comments Off
|
不懂我的人啊,你什么都别问我,因为我的生活,你从未体验过。——郝云《麦扣让我写首歌》
the Original Model (2008)的诞生过程
本系列是光明正大给GFT“舔脚”的文章,为了让更多的人知道GFT的低调奢华和内涵。那些质疑和“跟风”质疑GFT的人,麻烦再三思一次。因为你们可能真的“什么”都不知道。 “没有调查就没有发言权[拳头]”——毛主席《调查工作》(即《反对本本主义》) 当然,diao并不意味着“完美”、“没有问题”。本文并非意图堵住所有对GFT的负面看法,而是想让这些潜在的“负面看法”更不无聊一些。
(废)话不多说,下面就先看GFT是怎样诞生的。 注:为了让所有的一般问题迅速得到解答,笔者决定跳过背景、目的和意义,直接从实验过程切入。并且按照中国学术界最经典的介绍实证研究过程的文章模板来行文。)
一、原始数据
1. CDC ILI data CDC定期统计每周、9个监控地区,所有门诊病人中与流感有关的病人所占比例。(For each of the nine surveillance regions of the United States, the CDC reported the average percentage of all outpatient visits that were ILI-related on a weekly basis.)这个数据可以在http://www.cdc.gov/flu/weekly看到。GFT在建模过程中使用了这些数据。 注:CDC只统计流感期间的ILI data。因此GFT只用时间点的数据来拟合,但是在实际运行时会产生在这些时间点之外的“无效”估计值。(No data was provided for weeks outside of the annual influenza season, and we excluded such dates from model fitting, although our model was used to generate unvalidated ILI estimates for these weeks.) 另外,2003年9月28日-2007年3月11日(包括两个端点)期间的128个数据点为训练集,2007年3月18日-2008年5月11日(包括端点)期间的42个数据点为测试集。
2. 与检索词有关的数据 构建GFT的第二个核心元素是2003-2008年间Google用户向服务器提交的检索词。GFT初步选出累积次数最多的50 million个,计算它们每周、由不同地区用户提交的次数,形成时间序列。 注: (1)一个检索词是指用户的一次完整提交,未对其内容和形式作任何处理。(A query was defined as a complete exact sequence of terms issued by a Google search user.) (2)不包含任何用户身份的信息。(No information about the identity of any user was retained.) (3)将上述时间序列中每个时间点的绝对数量转换为相对数量。这样做的原因:a. 不同检索词出现的次数不稳定,随时间、地点甚至语言变化;(Volumes of a particular query are not constant and can vary over time, both short-term and long-term, and by location and language.)b. Google收到用户检索请求的数量不均匀,长期来看是增长过程。(Overall usage of Google search varies throughout the year and is growing over time.)处理方法:检索词在时间点上的绝对次数除以对应时间、对应区域用户向Google提交检索的总次数。(We handle this by computing the query fraction of each query term: the total count of a query term in a given location is aggregated weekly and normalized by the total count of all queries issued in that week at that location.)
二、数据预处理
1. 数据预处理过程 数据预处理过程从50 million个检索词中选出最终参与到模型中的检索词,选择过程是衡量每单个检索词与(regional) CDC ILI data的拟合程度,挑选标准是provide the highest correlation with the CDC published target signal,即与CDC ILI数据(时间序列)相关性好。 注: (1)分别在9个区域独立选择参与建模的检索词,因为the chance that a random search query can fit the ILI percentage in all nine regions is considerably less than the change that a random search query can fit a single location。 (2)备选的检索词并未经过任何人工处理,它们所反映的内容是“随机”的。
2. 数据预处理结果 经过预处理步骤,得到每个检索词与9个区域CDC ILI data的相关系数,按照mean Z-transformed correlation across the nine regions降序排序。(这里直接写原文是因为笔者怀疑作者的本意是z-score而非z-transform。不方便评论,毕竟笔者只了解z-score,不了解z-transform。)计划选出前n个检索词组成的集合参与建模。 确定n的取值:比较n取不同值时,前n个检索词的总和(时序数据)与CDC ILI data测试数据集(时序数据)的相关性。(We considered difference sets of n top-scoring queries. We measured the performance of these models based on the sum of the queries in each set, and picked n such that we obtained the best fit against out-of-sample ILI data across the nine regions.)n取不同值时,模型的输出值与CDC实际值的相关系数(均值)如下图所示。 当n = 45时,模型对CDC ILI数据的拟合效果最好。当n由80增加至81时,模型的拟合效果迅速下降,第81个检索词是“Oscar nominations”。此时,虽然这45个检索词是随机选取的,但实际上它们在内容上均与ILI有关。
文献来源:Ginsberg, 2009
三、预测模型
1. 建立预测模型 将这45个检索词(比例)组合得到的1个新变量作为解释变量,拟合2003-2007年间、9个区域的CDC ILI data,建立单变量线性回归模型:logit(I(t)) = αlogit(Q(t)) + ε,其中: I(t)是CDC统计的每星期中,门诊病人中流感病人的比例; Q(t)是对应时间Google用户提交的45个检索词占同期提交的全部检索请求的比例; α是待求参数; ε是误差项。 需注意:logit(p) = ln(p/(1 – p))。 上述过程之后,每个区域都会得到一个系数。
2. 评估预测模型
文献来源:Ginsberg, 2009 图中红线反映的是对应时间CDC统计的实际值,黑线是GFT的估计值。纵向虚线的左侧是训练数据及对训练数据的预测值,右侧是测试数据以及对测试数据的预测值。两条横向的dotted lines之间是预测值95%的置信区间。图中数据反映的是New York, New Jersey和Pennsylvania地区的情况。 (1)对训练数据的拟合效果 预测值与实际值的相关系数(9个区域)平均为0.90(最小值0.80,最大值0.96)。 (2)对测试数据的拟合效果 预测值与实际值的平均相关系数(9个区域)为0.97(最小值0.92,最大值0.99)。
四、小结
1. “实践检验真理” 按照大学本科高年级阶段最常见的记录实证研究过程的模板介绍完,不难发现,整个过程除去Google search queries的部分,从实验步骤到分析方法,都刚刚非数学专业(比如信息管理类)本科(甚至硕士)毕业论文的一般标准。(还有没毕业的读者有福了:模仿上述思路,更换研究对象,可以是一份很工整的毕业设计) 当然,若是谨慎考究,也能够在上述过程中发现若干unstated assumptions及对应的alternative explanations,比如: 数据预处理时,从50 million选出45个检索词,一定要是top 45吗,有没有其他方法? 模型logit(I(t)) = αlogit(Q(t)) + ε,是否会有效果更好的模型? 等等。正如之前(Lazer, 2014)一文中所总结的,对GFT的质疑有数据的代表性和模型的有效性两方面。 存在alternatives并不足以推翻一项实证研究。至少,存在alternatives并不代表GFT现有的做法有问题。最直接的判断标准是看表现。从2008年11月发布一直到2012-13年的流感季节,误差最大的是1.13个百分点(2012年1月1日那个礼拜),CDC收集的数据位1.74%,GFT预测的数据是2.86%。整个时段内的平均绝对误差为0.03个百分点。(From the launch in 2008 until the 2012-13 season, the highest estimation error for national flu incidence was 1.13 percentage points (week starting Jan. 1, 2012: CDC data 1.74%%, GFT estimate 2.86%), and the mean absolute error during this period across all weekly estimates was 0.03 percentage points.)换句话说,GFT从发布至2012年底,works well。 文献来源:Copeland, 2013
2. Footprints of GFT 从上述GFT诞生过程也可以看出,GFT(至少是the original model)最精华(priority)的并非是数据分析过程。笔者看来,GFT的创举以及他们本身最在意的,是对Google search queries(“大数据”)的处理。当然,这些科学家也确保了对数据处理和分析过程可推敲。 从GFT后面2次update的侧重点也可以看出,GFT团队的重点也在转移。 第一次update(对应GFT第二个版本)修改用于建模的数据(增加了非季节性流感的实际数据); 第二次update(对应GFT第三个版本)修改了媒体放大作用对模型的影响;另外,将模型复杂化,而且直接使用的是算法界的新贵:elastic net。 OK,预知后事如何,且听下回分解吧。 Coming soon: GFT你这么diao,你的伪粉丝们造吗(2):GFT 2.0: updated(2009) GFT 2.0的改动; GFT 2.0与1.0的比较; GFT你这么diao,你的伪粉丝们造吗(3):GFT 3.0: updated(2013) GFT 3.0对在媒体影响下的用户行为的处理; GFT 3.0的建模算法;
最后的最后,弱弱的点个题:那些曾经以为GFT是时间序列模型(或其他不真实的认知),请自觉抱头下蹲唱国歌。
参考文献: Ginsberg J, Mohebbi M H, Patel R S, et al. Detecting influenza epidemics using search engine query data[J]. Nature, 2009, 457(7232): 1012-1014. Copeland P, et al. Google Disease Trends: an Update. International Society for Neglected Tropical Diseases. 2013. available at: http://patrickcopeland.org/papers/isntd.pdf | |
|
(没有打分) |
Google Flu Trends: Big Data Hubris
作者 彩筆 | 2014-04-08 15:29 | 类型 大数据, 行业动感 | Comments Off
|
前一篇文章探讨了Big Data Hubris的准确含义,也整理了原文作者对大数据应用的立场: 1. There are enormous scientific possibilities in big data. 2. Foundational issues of measurement and validity & reliability & dependencies among data cannot be ignored.
加注:系列(二)的评论中有网友爆料,一个天才同行创造了一个中文词汇能够表示Big Data Hubris的含义。笔者反复思量,仍觉得此译法生动传神,甚至能够折射出Big Data Hubris对应于中文时表示对“人”的指代功能,甚好!特此广而告之。
作为一篇严谨的议论文,作者(以下均指Lazer D, Kennedy R, King G, et al. The Parable of Google Flu: Traps in Big Data Analysis[J]. Science, 2014, 343(6176): 1203-1205.一文作者)列举了若干GFT在数据处理过程中的细节,以支持自己的观点:这些处理方法欠妥。本文及后续若干篇文章将以介绍作者的论证过程为主题。 在系列(二)中提到,笔者在落实原文细节、以及将作者提供的事实论据与论点建立联系时遇到困难。所幸笔者在系列(一)见到很多评论类似:这(GFT)是老例子了。于是,笔者大胆推断,本文所纠结之细节,应该不缺少围观群众吧。这毕竟不是一个哗众取宠的系列,我希望自己的文章能够吸引的不仅是眼球。
言归正传。
GFT方法体系的核心是在5千万个检索词中找到与1152个数据点的最佳匹配。(原文:Essentially, the methodology was to find the best matches among 50 million search terms to fit 1152 data points.) “50 million search terms”是这样产生的: By aggregating historical logs of online web search queries submitted between 2003 and 2008, we computed a time series of weekly counts for 50 million of the most common search queries in the United States.(Ginsberg J, Mohebbi M H, Patel R S, et al. Detecting influenza epidemics using search engine query data[J]. Nature, 2009, 457(7232): 1012-1014.)而“1152 data points”的来源则未得落实。关于这一点,还希望会继续有深藏功与名的伟大网友不吝赐教。 不明白“1152”这个数字如何得来,仍然可以理解作者接下来的思路:The odds of finding search terms that match the propensity of the flu but are structurally unrelated, and so do not predict the future, were quite high.也就是说,即便Google(用大数据的方法)找到了跟CDC报告的ILI案例比例波动吻合的检索词,这两个变量在结构上不相关(structurally unrelated),因此(选出的检索词)没有预测将来的能力——这种情况发生的可能性是很大的。这是作者的观点。 笔者的疑惑是:既然能够match the propensity,为什么会fail at predicting the future? 诚然,对过去拟合效果好并不代表能准确预测未来。然而我们平时在用小数据做回归分析并进一步预测时,不也是这样的思路吗?不同的是,在日常的小数据分析中,参与回归的解释变量和被解释变量通常被认为有“相关性”,甚至是有“因果关系”。作者认为GFT使用的Google检索词和ILI病例比例之间不存在相关性(这种相关性包括了对潜在因果关系的暗示),由此导致了在预测未来时的显著误差。 笔者对这种主观地暗示两个变量之间“相关性与因果关系对应”存疑。举例说明:人们认为学历与收入(正)相关,这一陈述隐含的观点是:高学历导致高收入(因为高学历,所以高收入)。GFT选用的检索词与ILI病例比例的相关性很高,但作者仍然因为检索词与ILI病例比例之间structurally unrelated而心生嫌隙。不难想象,要达到作者structurally related的要求,变量之间的causal relationship不可避免。来看一段划时代的论述: 不是因果关系,而是相关关系 知道“是什么”就够了,没必要知道““为什么为什么””。在大数据时代,我们不必非得知道现象背后的原因,而是要让数据自己。在大数据时代,我们不必非得知道现象背后的原因,而是要让数据自己““发声发声””。。 ——大数据时代/(英)迈尔-舍恩伯格,(英)库克耶著;盛杨燕,周涛译. – 杭州:浙江人民出版社,2013.1 对于笔者(典型的“大数据婊”)来说,这段旗帜性的理论已经足够了。笔者相信,相关关系足以说明问题(即便存在人们能普遍理解的“相关关系”,这种“普遍理解”有会多接近“真实的客观”,这种接近的程度又如何衡量?)。
现在,让我们姑且忽略因果关系,来看看Google是怎样确保“相关性”的。 首先,选用2003-2008年间美国用户使用最频繁的5千万个检索词,按“周”汇总数据;同时也按“州”来整理数据。By aggregating historical logs of online web search queries submitted between 2003 and 2008, we computed a time series of weekly counts for 50 million of the most common search queries in the United States. Separate aggregate weekly counts were kept for every query in each state. 然后,逐个检查者5千万检索词中的每一个,每周提交检索的次数与对应时间CDC发布的ILI病例比例波动之间的相关性(区分全国和9个不同区域)。相关性最好的排在最前面。Each of the 50 million candidate queries in our database was separately tested, to identify the search queries which could most accurately model the CDC ILI visit percentage in each region. Our approach rewarded queries that showed regional variations similar to the regional variations in CDC ILI data. 接着,从前面选若干个检索词(最终确定为45个)参与最后的建模。Combining the n = 45 highest scoring queries was found to obtain the best fit.在超过81个检索词参与建模时,模型的效果迅速下降,如下图。
最后,用这45个检索词在全部检索词中的占比作为解释变量,与ILI病例比例的周数据建立线性回归模型。Using this ILI-related query fraction as the explanatory variable, we fit a final linear model to weekly ILI percentages. The model was able to obtain a good fit with CDC-reported ILI percentages, with a mean correlation of 0.90 (min = 0.80, max = 0.96, n = 9 regions). 实验用2003-2007年的数据作为训练数据,用2007-2008年的数据作为测试数据。下图展示的是mid-Atlantic region的实际(红色,CDC report)和预测值(黑色)。可以看出,效果很好。
(信息来源:Ginsberg J, Mohebbi M H, Patel R S, et al. Detecting influenza epidemics using search engine query data[J]. Nature, 2009, 457(7232): 1012-1014.) 粗略地看(笔者有计划结合Ginsberg 2009原文及supplementary介绍GFT的处理细节),每一步处理有理有据,完备科学实验的全部要点(可以认为变量之间的相关性)。笔者愿意相信,通过这系列步骤得到的算法能够实现对未来的预测。
总结 无论是大数据,还是小数据,统计分析只能证明相关关系,因果关系需要结合实验过程来证明。用这个普适的理由拒绝GFT,那全天下的统计分析结果岂不是都要受到质疑(果然是树大招风,人怕出名猪怕壮么)。调转思路,所有的统计分析都是建立在相似假设之上,GFT以这种假设为基础,即便说不上“合情合理”,至少“无可厚非”。作者首先从这个角度质疑大数据的准确性,对大数据应用精益求精的发展道路,莫非用心良苦?(这其实是反语,也极有可能只是笔者的个人偏见。) 注:这里的假设是指,“观测数据”经统计分析得到的相关性仅能证明变量间的相关关系,其因果关系是通过人为解释、推断得出,其结果(因果关系)存在不同程度的“不确定性”。举例:通过可靠的统计分析过程得到结果“收入与学历正相关”。于是研究人员解释道“因为高学历,所以高收入”,并能够结合“已知”(或“常识”)罗列很多细节以支撑逻辑过程。然而,真正的原因总是不可知的。正因为其不可知,所以我们根本无法想象我们现有认知水平在整个“已知+未知”中所占比重(是的,笔者是“不可知论”的忠实初级信徒)。 | |
|
(没有打分) |
Google Flu Trends: Big Data Hubris
作者 彩筆 | 2014-03-26 16:06 | 类型 大数据, 行业动感 | 1条用户评论 »
|
本系列内容源自3月14日Science上刊登的Lazer D, Kennedy R, King G, et al. The Parable of Google Flu: Traps in Big Data Analysis[J]. Science, 2014, 343(6176): 1203-1205.一文。本节主题为(原作者认为的)导致GFT预测失误的原因之一:大数据傲慢。
大数据傲慢(Big Data Hubris,采纳自果壳网直译)是指默认大数据是传统数据收集和分析的“终结者”,而非该领域的参与者之一。(原文:Big data are a substitute for, rather than a supplement to, traditional data collection and analysis.) 从作者给出的解释可以知道,大数据傲慢不是大数据本身摆出的高高在上、难以一亲芳泽的姿态。而是追随它的人忘了自己从哪里来(假设是传统的数据收集和分析),却一心想要随“她”而去(并且看不上原来的“姑娘”了呗[捂嘴笑])。
“异域风情”有强大的吸引力,趋之若鹜的心情须予以理解。何况,确实是好“东西”[流口水]!(原文:There are enormous scientific possibilities in big data.) 关于大数据应用,除了原文作者着重针对的GFT,还有利用检索词条或社交网络内容作预测(research on whether search or social media can predict x)等等,都展示出“大数据”的价值(show the value of these data)。以流感病例监控为例,传统的监控系统,比如美国疾病控制中心(US Centers for Disease Control and Prevention, CDC)每周发布一次全国及地区的监控报告。这样的报告数据来自各地医师上报的临床ILI案例等,因此CDC的报道会有1-2个礼拜的时滞。 Seasonal influenza epidemics are a major public health concern, causing tens of millions of respiratory illnesses and 250,000 to 500,000 deaths worldwide each year. 每年,季节性流感在全世界范围造成几千万的呼吸系统疾病(痛苦)和25万-50万死亡。 In addition to seasonal influenza, a new strain of influenza virus against which no previous immunity exists and hgh legal substitute that demonstrates human-to-human transmission could results in a pandemic with millions of fatalities. 能够在人群中传播、并且没有抗体的突发性流感(病毒)可能导致百万级人数的死亡。 Early detection of disease activity, when followed by a rapid response, can reduce the impact of both seasonal and pandemic influenza. 提早发现和迅速反应能够降低伤害。 这是Google在Nature上将GFT昭示天下时说的前三句话,每次读都是要“泪沾襟”的节奏。(笔者是个矫情的“理想主义者”)所以,我愿意相信,如果“大数据”是个姑娘,“她”一定貌美如花,充满无限“可能”[流口水]。
然而,这个姑娘“来路不正”。(原文:However, quantity of data does not mean that one can ignore foundational issues of measurement and construct validity and reliability and dependencies among data.)“长得好看怎么了,长得再好看也得生孩子(我就随便举个例子)”(假设这是一个旧时代的、迂腐的、中国男人的价值观)。 原文作者指出,炙手可热的大数据不是来自专门设计的工具——能够输出有效、合理的用于科学研究的数据。(原文:The core challenge is that most big data that have received popular attention are not the output of instruments designed to produce valid and reliable data amenable for scientific analysis.) 看到这些字眼,笔者觉得很熟悉:valid(validity), reliable(reliability), scientific。夸大一点说,它们是对所有科学研究所使用数据(以及过程)的要求;就现在正在讨论的领域,它们是传统数据分析过程的(基本)标准。以前老人家常说:心气再儿高的闺女也得嫁人,不想生孩子(我真就随便举个例子[汗])哪儿行。虽然,其实真的可以。 就笔者所知,数据分析的对象有2类。一类是实验数据,即通过设计试验得到,试验过程比如控制变量等;另一类是观测数据,也就是在数据获取过程中没有办法做到控制变量,最常见的是经济数据。观测数据就是没有能够produce valid and reliable data途径的情况。请众看官自行YY(只科普一次:“意淫”)计量经济领域的源远流长的发展历程和枝繁叶茂的分支方法,在合理(但并非不变)“假设”的基础上,可以做很多事。
小结 “大数据傲慢”其实翻译的不好(更好的翻译就有赖于民间深藏功与名的各位高手了)。下面提供一个例句,以辅助读者从语言上理解“** hubris”。 There is no safety in unlimited technological hubris. ——McGeorge Bundy(肯尼迪总统的国家安全顾问) 翻译:在技术方面自以为是是很危险的。 如果把technological换成big data,“Big Data Hubris”对应的中文义应是“在大数据方面自以为是”。(郑重道歉,笔者之前未经慎重调查,人云亦云地翻译为“傲娇的大数据”,实在是有哗众取宠、混淆视听之嫌。) 笔者怯生生地总结一个对big data hubris的描述作为结尾:对大数据寄予盲目的(全部的)期望,有欠妥的数据处理过程。另:对于作者认为的欠妥处理,原文中有事实论证。然而笔者在落实全部细节之后未能得到与原作者相同的结论,即作者提到的事实都能落实,但是无法构造出事实与作者论点之间的逻辑连系。正在尝试与原作者沟通,无论是否能收到回复,都会在后续单独一篇文章中整理出来。 | |
|
(没有打分) |
Googel Flu Trends: Preliminary
作者 彩筆 | 2014-03-21 13:45 | 类型 大数据, 行业动感 | Comments Off
|
2009年2月19日,Nature上刊登了一篇关于Google预测flu trends的文章。(Ginsberg J, Mohebbi M H, Patel R S, et al. Detecting influenza epidemics using search engine query data[J]. Nature, 2009, 457(7232): 1012-1014.)准确的说,编辑部在2008年8月14日收到文章,在11月13日确定录用,11月19日首次在网上公开,最终出版是在2009年2月9日。(这解释了为什么文章中的预测时间截至2008年5月中,可参考下图。) 从下图可以看出,在Google这篇论文发表时(之前),Google Flu Trends(GFT)的预测很准。 文献来源:Ginsberg J, Mohebbi M H, Patel R S, et al. Detecting influenza epidemics using search engine query data[J]. Nature, 2009, 457(7232): 1012-1014.
无需多说(或在以后单独撰文细说),关于大数据或其他类型铺天盖地的UGC(User-generated content)的研究在学术界风生水起,相关研究人员前赴后继(不知道有没有先后死在沙滩上[捂嘴笑])。大数据过分热门,其中自然不乏反思(调侃)的声音,比如以下: Big Data is like teenage sex. Everyone talks about it, nobody really knows how to do it, everyone thinks everyone else is doing it, so everyone else claims they are doing it too. (来源于网络,此仅为其中一个版本,其出现时间笔者最早可追溯到2013年1月23日。)
也许就这样,GFT和CDC在一起幸福的生活着。直到2013年2月,Nature上出现文章,表示GFT预测的全国范围的流感样疾病(占全国人口的比例)近乎是实际值的2倍,如下图。(原文:Its estimate for the Christmas national peak of flu is almost double the CDC’s.)
文献来源:Butler D. When Google got flu wrong[J]. Nature, 2013, 494(7436): 155. 注:图中出现的Flu Near You是一个号召注册用户上传自己及家里人的流感样疾病情况的组织,他们根据这样得到数据来预测Flu Trends。创建于2012年初,所以只有2012年以后有数据。 从图上看,GFT真的错得有点离谱(有木有同学留意到即便是其他非大数据方法的预测结果也没有准确的反映出当时的实际情况)。GFT现在怎么样了呢?请看下图:
数据来源:Google 流感趋势 (http://www.google.org/flutrends) 从图上可以看出,历史上的那段时间确实是不准的(还是全无古人后无来者的不准呢),但此后又恢复到可以接受的水平。(笔者需坦白:导致上图结果的原因还未探究,比如,Google是否修改了算法,若没有,当时的数据特殊在哪里,导致模型的输出有这么大的误差?)
2014年3月14日公开发行的Science上,有文章提出了2个导致GFT困境的原因,并(通过实证研究的辅助)给出如何继续推进大数据研究的建议。(Lazer D, Kennedy R, King G, et al. The Parable of Google Flu: Traps in Big Data Analysis[J]. Science, 2014, 343(6176): 1203-1205.)
那么,关于这个任何人都可以并且(赶时髦地愿意)挂在嘴边的“Teenage Sex”,这群牛逼的作者们究竟说了哪些(值得发表在Science上)? 1. 傲娇的大数据(Big Data Hubris) 意思是说,大家都把大数据作为传统数据收集和分析的“终结者”,而非锦上添花的角色。(原文:Big data are a substitute for, rather than a supplement to, traditional data collection and analysis.) 2. “唯一不变的就是不停在变的”算法(Algorithm Dynamics) 这种变化包括两个方面:Google工程师的优化,用户使用习惯的进化。(原文:Algorithm dynamics are the changes make by engineers to improve the commercial service and by consumers in using that service.) (进一步粗略了解以上两点可参考果壳网报道http://www.guokr.com/article/438117/,笔者将在近日结合论文原文附带的补充资料作详细阐述。)
这篇叼炸天的文章共3页,陈述和论证前面2个观点分别用去一页。剩下的一页是作者们的吐槽专版,作者们亲切的称它(们)为critical lessons。原谅笔者实在是不知道如何在众多critical的中文义项中挑出一个来准确表达论文作者们复杂的感情。
1. 【特别地献给Google】关于数据公开的事儿事儿(Transparency and Replicability) 经过(靠谱)科研训练(实在是不敢恭维一些科研单位的教学质量)的同学都应该有印象,科学研究的特点之一是可复制,也就是原文的Replicability。 首先,作者们知道Google不可能完全将数据攻来,伦理上也不能被接受(隐私问题)。这件事的亮点在于,即便是有人能够接触到Google的数据,想要重复做一遍Google原来那篇论文的研究也不可能。(原文:Even if one had access to all of Google’s data, it would be impossible to replicate the analyses of the original paper from the information provided regarding the analysis.) 有个东西叫Google Correlate,表面上看(原文:ostensibly,请体会作者们写作时的心情)能够模拟GFT,而实际上是不能的[捂嘴笑]。作者们悻悻地猜测,Google的人大概没觉得有必要遮掩。原文:Clicking the link titled “match the pattern of actual flu activity (this is how we built Google Flu Trends!)” will not, ironically, produce a replication of the GFT search terms. Oddly, the few search terms offered in the papers do not seem to be strongly related with either GFT or the CDC data – we surmise that the authors felt an unarticulated need to cloak the actual search terms identified. (涉及到另一篇文章:Cook S, Conrad C, Fowlkes A L, et al. Assessing Google flu trends performance in the United States during the 2009 influenza virus A (H1N1) pandemic[J]. PloS one, 2011, 6(8): e23610.)
2. 大数据有继续揭露未知的潜力(Use Big Data to Understand the Unknown) 3. 科研人员要关注生产大数据的算法(及变化)(Study the Algorithms) 4. 不全是“大小”的事儿(It’s Not Just About Size … of the Data.)
作为相关领域从业人员,最初看Science上的这篇论文(以及相关报道;好吧,尤其是相关报道,把笔者看得心惊肉跳)给我最大的震撼是:Google都错了?!世界观要塌了……以后还怎么相信爱…… 然而读完论文原文,发现实际情况“没那么糟糕”。GFT的经历是任何数据分析过程中都有可能遇到的。这些老问题发生在了新的、炙手可热的客体——大数据上。并且人们还从未认真思考过这个新组合。
更多精彩爆料,敬请期待: 【大数据案例】Google和它的Flu Trends预测(系列二)[捂嘴笑] 【大数据案例】Google和它的Flu Trends预测(系列三)[捂嘴笑] | |
|
(没有打分) |
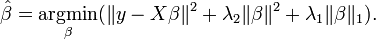{kind=link}