Cortana for business–now the worker’s digital assistant
作者 AbelJiang | 2015-08-25 11:02 | 类型 机器学习 | Comments Off
|
Microsoft revealed a little more about Cortana Analytics and how it is going to use machine learning to revolutionise business intelligence and productivity via its Azure cloud. Joseph Sirosh is the corporate vice president of the Information Management and Machine Learning (IMML) team in the Cloud and Enterprise group at Microsoft. He is also a maths nut and perhaps a geek. Almost all of what he said was several levels above my pay grade so I will do my best not to disappoint TWire’s erudite readers (and keep it light). “I did my PHD in 1995 in neural networks. That led to my working on fraud detection [machine learning] software for a major credit card gateway and that led to joining Microsoft where I can pursue my passion of machine learning,” he said. “Maths applies to data. Software is eating the world (apologies to Marc Andreessen for that saying) but data is drowning the world,” he said. “30 years ago data was almost all analogue, now it iP addresss attached almost all analogue, now its all digital and it has an pursue my passionm s all digital and much of it has an IP address attached. The intelligence you can derive is amazing,” he said. The problem with big data, lots of data, Petabytes, Exabytes or the stuff is that it presents an enormous challenge to store and analyse, especially in real time. Microsoft and its Azure Machine Learning and the Azure Gallery is a good place to find out more. Joseph spoke about the ‘connected dairy cow’ , a project from Fujitsu in Japan. Pedometers were attached to each cow and the bovine walking characteristics analysed via Azure to predict estrus. Not only did the data reveal the best insemination time and improved the pregnancy rate by 67% it helped predict the resultant gender of the offspring. The results were so good that Fujitsu expects this to be rolled out to 500,000 cows soon. Joseph said that with Azure cloud developers could build immensely complex systems in just a few days and introduced two plucky Adelaide undergraduates who hope to move the highly manual and inaccurate vineyard yield prediction models to the cloud using Azure. Harry Lucas, 20, Liam Ellul, 23 are part of the Seer Insights team. They described an intelligent system that assists vineyard staff, growers and wineries in improving the accuracy of their yield estimates. The key is to use Azure to find patterns and insights from both the current data and from historical data and shifting that from an analysis of what’s happened in the past to an accurate prediction of what might occur in the future. Joseph commented that what Seer had done is harness computing power, machine learning and analytics that were not available even a few years ago. Then we heard from Max Valente from Thought studio a software development company he began in Sydney in 2011 as a think tank developing technology to solve business problems and create business opportunities. Max developed the first virtual wardrobe where a person stands in front of a screen and tries on virtual clothes. The latest venture (it has two sites working as proof of concept) uses sensors and devices like Kinect to map out a shoppers experience in a store. “Kinect gives us the gender, approximate age and time someone enter and exits the store. We can marry that with things like the weather, promotional activity and more to build a profile. We then use sensors connected to Raspberry Pi to show where they go in the store, where they linger, what they try on – we collect a lot of data,” Max said. One advantage is immediately apparent – identifying shoplifters by facial and other ‘secret’ Kinect recognition. “The goal is to enhance a shopper experience, understand their journey, to lay out stores more logically, to know what’s hot and what’s not, and of course to increase sales,” said Max. “The entire system is only possible due to Microsoft’s Azure cloud, analytics, storage and tools,” Max added. So finally to Cortana Cortana is a digital assistant that can be personal (as in running on a PC or smartphone) or used for business. The former relies on getting to know you well and the latter on getting to know the company well – and keeping all secrets. Cortana analytics is too broad a subject to cover here but Joseph demonstrated a medical support practice that uses Cortana as the natural language interface between nurses/doctors and patients in a call centre environment. The result has been much better care, better analysis, easier follow up and less need to hospitalise. Joseph said that Cortana could develop perceptual intelligence to benefit any business – helping them to get closer to customers, knowing more about what they do, and what customers want etc. He finished with a haiku: The cloud turns hardware into software The cloud turns software into services The cloud turns data into intelligence The cloud turns intelligence into action I then walked outside into Sydney’s beautiful sunshine – not a [visible] cloud in sight! The cloud turns into rain, rain turns into … | |
 (没有打分) (没有打分) |
The Dawn of Artificial Intelligence
作者 AbelJiang | 2015-05-26 20:47 | 类型 Deep Learning, 机器学习 | Comments Off

Why a deep-learning genius left Google & joined Chinese tech shop Baidu (interview)
作者 AbelJiang | 2015-04-26 21:45 | 类型 机器学习 | Comments Off
|
SUNNYVALE, California — Chinese tech company Baidu has yet to make its popular search engine and other web services available in English. But consider yourself warned: Baidu could someday wind up becoming a favorite among consumers. The strength of Baidu lies not in youth-friendly marketing or an enterprise-focused sales team. It lives instead in Baidu’s data centers, where servers run complex algorithms on huge volumes of data and gradually make its applications smarter, including not just Web search but also Baidu’s tools for music, news, pictures, video, and speech recognition. Despite lacking the visibility (in the U.S., at least) of Google and Microsoft, in recent years Baidu has done a lot of work on deep learning, one of the most promising areas of artificial intelligence (AI) research in recent years. This work involves training systems called artificial neural networks on lots of information derived from audio, images, and other inputs, and then presenting the systems with new information and receiving inferences about it in response. Two months ago, Baidu hired Andrew Ng away from Google, where he started and led the so-called Google Brain project. Ng, whose move to Baidu follows Hugo Barra’s jump from Google to Chinese company Xiaomi last year, is one of the world’s handful of deep-learning rock stars. Ng has taught classes on machine learning, robotics, and other topics at Stanford University. He also co-founded massively open online course startup Coursera. He makes a strong argument for why a person like him would leave Google and join a company with a lower public profile. His argument can leave you feeling like you really ought to keep an eye on Baidu in the next few years. “I thought the best place to advance the AI mission is at Baidu,” Ng said in an interview with VentureBeat. Baidu’s search engine only runs in a few countries, including China, Brazil, Egypt, and Thailand. The Brazil service was announced just last week. Google’s search engine is far more popular than Baidu’s around the globe, although Baidu has already beaten out Yahoo and Microsoft’s Bing in global popularity, according to comScore figures. And Baidu co-founder and chief executive Robin Li, a frequent speaker on Stanford’s campus, has said he wants Baidu to become a brand name in more than half of all the world’s countries. Presumably, then, Baidu will one day become something Americans can use. Now that Ng leads Baidu’s research arm as the company’s chief scientist out of the company’s U.S. R&D Center here, it’s not hard to imagine that Baidu’s tools in English, if and when they become available, will be quite brainy — perhaps even eclipsing similar services from Apple and other tech giants. (Just think of how many people are less than happy with Siri.) A stable full of AI talent But this isn’t a story about the difference a single person will make. Baidu has a history in deep learning. A couple years ago, Baidu hired Kai Yu, a engineer skilled in artificial intelligence. Based in Beijing, he has kept busy. “I think Kai ships deep learning to an incredible number of products across Baidu,” Ng said. Yu also developed a system for providing infrastructure that enables deep learning for different kinds of applications. “That way, Kai personally didn’t have to work on every single application,” Ng said. In a sense, then, Ng joined a company that had already built momentum in deep learning. He wasn’t starting from scratch. Only a few companies could have appealed to Ng, given his desire to push artificial intelligence forward. It’s capital-intensive, as it requires lots of data and computation. Baidu, he said, can provide those things. Baidu is nimble, too. Unlike Silicon Valley’s tech giants, which measure activity in terms of monthly active users, Chinese Internet companies prefer to track usage by the day, Ng said. “It’s a symptom of cadence,” he said. “What are you doing today?” And product cycles in China are short; iteration happens very fast, Ng said. Plus, Baidu is willing to get infrastructure ready to use on the spot. “Frankly, Kai just made decisions, and it just happened without a lot of committee meetings,” Ng said. “The ability of individuals in the company to make decisions like that and move infrastructure quickly is something I really appreciate about this company.” That might sound like a kind deference to Ng’s new employer, but he was alluding to a clear advantage Baidu has over Google. “He ordered 1,000 GPUs [graphics processing units] and got them within 24 hours,” Adam Gibson, co-founder of deep-learning startup Skymind, told VentureBeat. “At Google, it would have taken him weeks or months to get that.” Not that Baidu is buying this type of hardware for the first time. Baidu was the first company to build a GPU cluster for deep learning, Ng said — a few other companies, like Netflix, have found GPUs useful for deep learning — and Baidu also maintains a fleet of servers packing ARM-based chips. Now the Silicon Valley researchers are using the GPU cluster and also looking to add to it and thereby create still bigger artificial neural networks. But the efforts have long since begun to weigh on Baidu’s books and impact products. “We deepened our investment in advanced technologies like deep learning, which is already yielding near term enhancements in user experience and customer ROI and is expected to drive transformational change over the longer term,” Li said in a statement on the company’s earnings the second quarter of 2014. What will Ng do at Baidu? The answer will not be limited to any one of the company’s services. Baidu’s neural networks can work behind the scenes for a wide variety of applications, including those that handle text, spoken words, images, and videos. Surely core functions of Baidu like Web search and advertising will benefit, too. “All of these are domains Baidu is looking at using deep learning, actually,” Ng said. Ng’s focus now might best be summed up by one word: accuracy. That makes sense from a corporate perspective. Google has the brain trust on image analysis, and Microsoft has the brain trust on speech, said Naveen Rao, co-founder and chief executive of deep-learning startup Nervana. Accuracy could potentially be the area where Ng and his colleagues will make the most substantive progress at Baidu, Rao said. Matthew Zeiler, founder and chief executive of another deep learning startup, Clarifai, was more certain. “I think you’re going to see a huge boost in accuracy,” said Zeiler, who has worked with Hinton and LeCun and spent two summers on the Google Brain project. One thing is for sure: Accuracy is on Ng’s mind. “Here’s the thing. Sometimes changes in accuracy of a system will cause changes in the way you interact with the device,” Ng said. For instance, more accurate speech recognition could translate into people relying on it much more frequently. Think “Her”-level reliance, where you just talk to your computer as a matter of course rather than using speech recognition in special cases. “Speech recognition today doesn’t really work in noisy environments,” Ng said. But that could change if Baidu’s neural networks become more accurate under Ng. Ng picked up his smartphone, opened the Baidu Translate app, and told it that he needed a taxi. A female voice said that in Mandarin and displayed Chinese characters on screen. But it wasn’t a difficult test, in some ways: This was no crowded street in Beijing. This was a quiet conference room in a quiet office. “There’s still work to do,” Ng said. Meanwhile, researchers at companies and universities have been hard at work on deep learning for decades. Google has built up a hefty reputation for applying deep learning to images from YouTube videos, data center energy use, and other areas, partly thanks to Ng’s contributions. And recently Microsoft made headlines for deep-learning advancements with its Project Adam work, although Li Deng of Microsoft Research has been working with neural networks for more than 20 years. In academia, deep learning research groups all over North America and Europe. Key figures in the past few years include Yoshua Bengio at the University of Montreal, Geoff Hinton of the University of Toronto (Google grabbed him last year through its DNNresearch acquisition), Yann LeCun from New York University (Facebook pulled him aboard late last year), and Ng. But Ng’s strong points differ from those of his contemporaries. Whereas Bengio made strides in training neural networks, LeCun developed convolutional neural networks, and Hinton popularized restricted Boltzmann machines, Ng takes the best, implements it, and makes improvements. “Andrew is neutral in that he’s just going to use what works,” Gibson said. “He’s very practical, and he’s neutral about the stamp on it.” Not that Ng intends to go it alone. To create larger and more accurate neural networks, Ng needs to look around and find like-minded engineers. “He’s going to be able to bring a lot of talent over,” Dave Sullivan, co-founder and chief executive of deep-learning startup Ersatz Labs, told VentureBeat. “This guy is not sitting down and writing mountains of code every day.” And truth be told, Ng has had no trouble building his team. “Hiring for Baidu has been easier than I’d expected,” he said. “A lot of engineers have always wanted to work on AI. … My job is providing the team with the best possible environment for them to do AI, for them to be the future heroes of deep learning.” | |
|
(没有打分) |
Facebook invents an intelligence test for machines
作者 AbelJiang | 2015-04-03 11:28 | 类型 机器学习, 行业动感 | Comments Off
|
原文转自:http://www.newscientist.com John is in the playground. Bob is in the office. Where is John? If you know the answer, you’re either a human, or software taking its first steps towards full artificial intelligence. Researchers at Facebook’s AI lab in New York say an exam of simple questions like this could help in designing machines that think like people. Computing pioneer Alan Turing famously set his own test for AI, in which a human tries to sort other humans from machines by conversing with both. However, this approach has a downside. “The Turing test requires us to teach the machine skills that are not actually useful for us,” says Matthew Richardson, an AI researcher at Microsoft. For example, to pass the test an AI must learn to lie about its true nature and pretend not to know facts a human wouldn’t. These skills are no use to Facebook, which is looking for more sophisticated ways to filter your news feed. “People have a limited amount of time to spend on Facebook, so we have to curate that somehow,” says Yann LeCun, Facebook’s director of AI research. “For that you need to understand content and you need to understand people.” In the longer term, Facebook also wants to create a digital assistant that can handle a real dialogue with humans, unlike the scripted conversations possible with the likes of Apple’s Siri. Similar goals are driving AI researchers everywhere to develop more comprehensive exams to challenge their machines. Facebook itself has created 20 tasks, which get progressively harder – the example at the top of this article is of the easiest type. The team says any potential AI must pass all of them if it is ever to develop true intelligence. Each task involves short descriptions followed by some questions, a bit like a reading comprehension quiz. Harder examples include figuring out whether one object could fit inside another, or why a person might act a certain way. “We wanted tasks that any human who can read can answer,” says Facebook’s Jason Weston, who led the research. Having a range of questions challenges the AI in different ways, meaning systems that have a single strength fall short. The Facebook team used its exam to test a number of learning algorithms, and found that none managed full marks. The best performance was by a variant of a neural network with access to an external memory, an approach that Google’s AI subsidiary DeepMind is also investigating. But even this fell down on tasks like counting objects in a question or spatial reasoning. Richardson has also developed a test of AI reading comprehension, called MCTest. But the questions in MCTest are written by hand, whereas Facebook’s are automatically generated. The details for Facebook’s tasks are plucked from a simulation of a simple world, a little like an old-school text adventure, where characters move around and pick up objects. Weston says this is key to keeping questions fresh for repeated testing and learning. But such testing has its problems, says Peter Clark of the Allen Institute for Artificial Intelligence in Seattle, because the AI doesn’t need to understand what real-world objects the words relate to. “You can substitute a dummy word like ‘foobar’ for ‘cake’ and still be able to answer the question,” he says. His own approach, Aristo, attempts to quiz AI with questions taken from school science exams. Whatever the best approach, it’s clear that tech companies like Facebook and Microsoft are betting big on human-level AI. Should we be worried? Recently the likes of Stephen Hawking, Elon Musk and even Bill Gates have warned that AI researchers must tread carefully. LeCun acknowledges people’s fears, but says that the research is still at an early stage, and is conducted in the open. “All machines are still very dumb and we are still very much in control,” he says. “It’s not like some company is going to come out with the solution to AI all of a sudden and we’re going to have super-intelligent machines running around the internet.” | |
|
(没有打分) |

【刘挺】自然语言处理与智能问答系统
作者 AbelJiang | 2015-03-04 11:07 | 类型 大数据, 机器学习, 行业动感 | 1条用户评论 »
|
节选自微博:杨静Lillian 【刘挺】哈尔滨工业大学教授,社会计算与信息检索研究中心主任,2010-2014年任哈工大计算机学院副院长。中国计算机学会理事、曾任CCF YOCSEF总部副主席;中国中文信息学会常务理事、社会媒体处理专业委员会主任。曾任“十一五”国家863 计划“中文为核心的多语言处理技术”重点项目总体组专家, 2012 年入选教育部新世纪优秀人才计划。主要研究方向为社会计算、信息检索和自然语言处理,已完成或正在承担的国家973课题、国家自然科学基金重点项目、国家863计划项目等各类国家级科研项目20余项,在国内外重要期刊和会议上发表论文80余篇,获2010年钱伟长中文信息处理科学技术一等奖,2012 年黑龙江省技术发明二等奖。
【刘挺】大家好,我是哈工大刘挺。感谢杨静群主提供的在线分享的机会。2014年11月1-2日,第三届全国社会媒体处理大会(Social Media Processing, SMP 2014)在北京召开,12个特邀报告,800多名听众,大会充分介绍了社会媒体处理领域的研究进展,与会者参与热情很高,2015年11月将在广州华南理工大学大学举办第四届全国社会媒体处理大会(SMP 2015),欢迎大家关注。 今晚我想多聊一聊与自然语言处理与智能问答系统相关的话题,因为这些话题可能和“静沙龙”人工智能的主题更相关。欢迎各位专家,各位群友一起讨论,批评指正。
IBM沃森与智能问答系统
【杨静lillian】刘挺教授在自然语言处理、数据挖掘领域颇有建树。腾讯、百度、IBM、讯飞、中兴等企业都与他有合作,他还研发了一个基于新浪微博的电影票房预测系统。 近年来,IBM等企业将战略中心转移到认知计算,沃森实际上就是一个智能问答系统。刘教授谈谈您在这方面的研发心得?
【刘挺】我们实验室是哈尔滨工业大学社会计算与信息检索研究中心,我们的技术理想是“理解语言,认知社会”。换句话说,我们的研究方向主要包括自然语言处理(Natural Languge Processing, NLP)和基于自然语言处理的社会计算,此次分享我重点谈自然语言处理。 1950年图灵发表了堪称“划时代之作”的论文《机器能思考吗?》,提出了著名的“图灵测试”,作为衡量机器是否具有人类智能的准则。2011年IBM研制的以公司创始人名字命名的“沃森”深度问答系统(DeepQA)在美国最受欢迎的知识抢答竞赛节目《危险边缘》中战胜了人类顶尖知识问答高手。 【白硕】深度,是从外部观感评价的,还是内部实现了一定的功能才算深度? 【刘挺】白老师,我认为深度是有层次的,沃森的所谓“深度问答”是和以往的关键词搜索相比而言的,也是有限的深度。IBM沃森中的问题均为简单事实型问题,而且问题的形式也相对规范,比如:“二战期间美国总统是谁。” 【白硕】要是问二战时美国总统的夫人是谁,估计就不好做了。 【刘挺】相应的,2011年苹果公司在iPhone 4s系统里面推出Siri语音对话系统,引起业内震动。百度、讯飞、搜狗先后推出类似的语音助手。但近来,语音助手的用户活跃度一般,并没有达到预期的成为移动端主流搜索形式的目标。 语音助手产品在有的互联网公司已基本处于维持状态,而不是主攻的产品方向,这背后的核心原因一方面是虽然语音技术相对成熟,但语言技术还有很多有待提高的空间,无法理解和回答用户自由的提问;另一方面,对生活类的查询用菜单触摸交互的方式,用户使用起来更便捷。 因此,但无论IBM沃森还是苹果Siri距离达到人类语言理解的水平仍有很大的距离,智能问答系统还有很长的路要走。
【胡颖之】@刘挺 这个问题我们调研过,不知国外情况如何,大部分人觉得,在外对着手机自言自语有点尴尬,且往往还需要调整识别不准的词。如果是一问一答,就直接电话好了,不需要语音。 【刘挺】IBM沃森在向医疗、法律等领域拓展,引入了更多的推理机制。认知计算成为IBM在智慧地球、服务计算等概念之后树起的一面最重要的旗帜。 【杨静lillian】深度问答系统转型成了智能医疗系统。请问我国企业怎么没有开发这种基于认知计算的智能医疗系统? 【刘挺】相信不久的将来,我国的企业就会有类似的系统出炉。百度的“小度”机器人日前参加了江苏卫视的“芝麻开门”就是一个开端。不过,当前我国的互联网公司似乎对微创新、商业模式的创新更感兴趣,而对需要多年积累的高技术密集型产品或服务的投入相对不足。IBM研制沃森历时4年,集中了一批专家和工程师,包括美国一些顶尖高校的学者,这种“多年磨一剑”的做法是值得学习的。
【杨静lillian】一个问题。百度的资料说小度机器人是基于语音识别的自然语言处理机器人,而沃森是视觉识别(扫描屏幕上的问题)。沃森到底是怎么进行问答的? 【刘挺】沃森不能接收语音信息及视频信息,因此比赛时主办方需要将题目信息输入沃森中,便于沃森理解题目。并且,Watson只利用已经存储的数据,比赛的时候不连接互联网。沃森不可以现场连接互联网,也是为了避免作弊的嫌疑。不过,如果让机器扫描印刷体的题目,以当前的文字识别技术而言,也不是难事。 【杨静lillian】原来这样,那么它会连接自己的服务器吧?可以把沃森看成一台小型的超级计算机? 【白硕】意思是服务器也部署在赛场。
【罗圣美】刘老师,IBM说的认知技术核心技术是什么? 【刘挺】罗总,IBM认知计算方面的核心技术可以参考近期IBM有关专家的报告,比如IBM中国研究院院长沈晓卫博士在2014年中国计算机大会(CNCC)上的报告。
高考机器人与类人智能系统
【刘挺】国家863计划正在推动一项类人智能答题系统的立项工作,目标是三年后参加中国高考,该系统评测时同样禁止连接互联网,答题需要的支撑技术事先存储在答题机器人的存储器中。 【杨静lillian】您说的这个就是讯飞的高考项目。哈工大与讯飞有个联合实验室,是从事相关研究么? 【刘挺】目前,863在规划的类人答题系统包含9个课题,以文科类高考为评价指标,讯飞公司胡郁副总裁担任首席科学家,我实验室秦兵教授牵头其中的语文卷答题系统,语文是最难的,阅读理解、作文等需要推理、创意等方面的能力。 【刘 挺】为什么要启动沃森、高考机器人这类的项目呢?要从搜索引擎的不足说起。海量数据搜索引擎的成功掩盖了语义方面的问题,在海量的信息检索中,有时候,数 据量的增加自然导致准确率的上升,比如问“《飘》的作者是谁”,如果被检索的文本中说“米切尔写了《飘》”,则用关键词匹配的方法是很难给出答案的,但由 于Web的数据是海量的,是冗余的,我们不断地追加文本,就可能在某个文本中找到“《飘》的作者是美国作家米切尔”这样的话,于是利用简单地字面匹配就可以找出问题和答案的关联,从而解决问题。因此,是海量的信息暂时掩盖了以往我们没有解决的一些深层问题,比如语义问题。 【白硕】飘的作者生于哪一年,也是一样,掩盖了推理和上下文连接的问题。 【杨静lillian】有没有可能,只要有足够海量的数据,那么从中总会找到想要的答案。 【白硕】不会的。 【刘挺】在搜索引擎中,海量的数据掩盖了智能推理能力的不足,但是在类似高考这样的需要细粒度的知识问答的场景里面仅靠海量数据是远远不够的,因而将把更深层次的语言理解与推理的困难暴露在研究者面前,推动技术向更深层发展。 举例而言,有用户问:“肯尼迪当总统时,英国首相是谁?”,这个问题很有可能在整个互联网上均没有答案,必须通过推理得到,而人类其实常常想问更为复杂的问题,只是受到搜索引擎只能理解关键词的限制,使自由提问回退为关键词搜索。
【胡颖之】那么微软小冰这一类的问答机器人,是属于相当初级的形态么? 【刘 挺】问答系统有两大类:一类是以知识获取或事务处理为目的的,尽快完成任务结束问答过程是系统成功的标志;另一类是以聊天及情感沟通为目的的,让对话能够 持续进行下去,让用户感到他对面的机器具有人的常识与情感,给人以情感慰藉。我们认为微软“小娜”属于前者,“小冰”属于后者。 【胡本立】词汇,语言只是脑中概念的部分表达。 【杨静lillian】提供一份背景资料。 据日本朝日新闻网报道,以在2021年前通过东京大学入学考试为目标的机器人“东Robo君”,在今年秋天参加了日本全国大学入学考试,尽管其成绩离东京大学合格的标准还相差很远,但较去年有所进步。 “东Robo君”是日本国立信息学研究所等机构于2011年开启的人工智能开发项目,目标是在2021年度之前“考取”东京大学。此次是继去年之后第2次参加模拟考试。 据主办模拟考试的机构“代代木Seminar”介绍,考试必考科目包括英语、日本语、数学、世界史、日本史、物理等7项科目,满分为900分(英语、国语满分200分,其他各科满分100分)。“东Robo君”此次获得了386分,偏差值(相对平均值的偏差数值,是日本对学生智能、学力的一项计算公式值)为47.3,超过了去年的45.1。 据介绍,如果“东Robo君”以这次的成绩报考私立大学的话,在全国581所私立大学里的472大学中合格的可能性为80%以上。研究人员认为“东Robo君”的学力水平“应该已能比肩普通高三学生”。 据称,该机器人在英语和日本语方面成绩有所提高,看来是倾向文科。在英语科目上,日本电报电话公司(NTT)参与了开发。NTT不仅灵活地运用其收纳了1千亿个单词的数据库,还加入了NTT公司开发的智能手机对话应用软件等技术。例如,在考试中的对话类填空题中,“东Robo君”会根据会话的语气或对话方的感情来进行判定,这使其成绩有所提高。但“代代木Seminar”的负责人表示,“如果目标是东大的话必须拿到9成的分数。老实说,‘东Robo君’还需更努力才行”。 但是,“东Robo君”的理科明显较弱。在数学函数的问题上,“东Robo君”无法像人一样在图表中描画图形,因为它不能进行直观性的理解。有关物体的运动问题也是同样,假设忽视物体的大小,以及假设摩擦为零之类的思考方式“东Robo君”还做不到。据称,这是因为他认为此类假设在现实中完全不可能。 除了参加7项必考科目外,“东Robo君”还参加了政治、经济的考试,它不能理解譬如“民主主义”的意思。据称,是因为教科书中没有过多解释少数服从多数,以及过半表决规则等社会常识,因此“东Robo君”对此并不熟悉,并且它也因此无法理解社会公正的概念。 该机器人项目负责人、国立信息学研究所新井纪子教授表示:“探究人工智能的极限可以说是这个项目的目的。弄清人和机器如何才能协调相处的问题,是日本经济发展的一把钥匙。”
【刘挺】杨静群主介绍的这篇新闻,我们也注意到了。日本第五代机的研制虽然失败了,但日本人仍然对机器人和人工智能充满热情,2021年让机器人考入东京大学是一个令人兴奋的目标。 【白硕】应该反过来思考,五代机的失败对今天的人工智能热有什么启示? 【刘挺】人们对人工智能的关注波浪式前进,本人认为当前对人工智能的期待偏高,本轮高潮过后将引起学者们的冷静思考。
【杨静lillian】按理说,届时我们的机器人就应该可以考入北大、清华了? 【刘挺】考入北大、清华是非常高的智能的体现,难度极大,这样的愿景能够变为现实,需要业内学者和企业界研发人员的通力合作,也有赖于未来若干年中计算环境的进一步提升。 【杨静lillian】讯飞的高考机器人是文科生,不考理科?这么说自然语言处理,反而是机器最能接近人类智能的一步? 【刘挺】文科生 【白硕】考理科想都不要想。小学的应用题要能做对已经很不容易了。 【杨静lillian】很奇怪的悖论,算力如此强大的计算机,连应用题都不能做。。。 【刘挺】我接触的一些数学家认为:只要能把应用题准确地转换为数学公式,他们就有各种办法让机器自动解题,因而即便对数学这样的理科科目而言,语言的理解仍然是关键的障碍。 【杨静lillian】看来高考机器人20年内都只能是文科生?但日本为什么2021年能让机器人上东大,也是文科? 【刘挺】日本2021年的目标也是考文科,跟中国的目标一致。 【杨静lillian】这充分说明了,为什么机器最先替代的是记者等文科生。。。
机器人为什么不能学习常识?
【胡本立】还有自然语言是不精确的,要只会精确计算的机器来不精确地表达比倒过来更难。 【白硕】应用题背后有大量的潜在常识性假设,对于人,不说也知道,对于机器,不说就不知道。 【杨静lillian】常识难道不能学习么? 【周志华】常识问题,图灵奖得主John MaCarthy后半辈子都在研究这个问题。悲观点说,在我退休以前看不到有希望。路过看到谈常识,随口说一句。 【杨静lillian】@周志华您是说20年内让机器学习常识没有希望? 【周志华】甚至是没看到能够让人感觉有希望的途径。当然,不排除有超凡入圣的人突然降生,拨云见日。 【白硕】常识获取比常识推理更难。 【刘挺】关于常识,谈谈我的观点:理论上的常识和工程实践中的知识获取或许有较大的区别。作为应用技术的研究者,我们对常识知识获取持相对乐观的态度。 群体智慧在不断地贡献大量的知识,比如维基百科、百度知道等,谷歌的知识图谱就是从这些体现群体智慧的自然语言知识描述中自动提炼知识,取得了令人瞩目的进展。 【白硕】我误导了。显性常识只需要告诉机器就行了,隐性常识往往是我们碰到了问题才知道原来这个都没告诉机器。所以,显性常识获取并不挑战智力而只挑战体力,但是隐性常识获取至今还在挑战智力。
【杨静lillian】既然机器学不会常识,为什么能给病人进行诊断呢?语言理解虽然难,但看起来依据常识进行推理就更难,几乎被认为没有可能性。 【杨静lillian】所以霍金和特斯拉CEO马斯克为什么还要“杞人忧天”呢?连常识都不可能具备的“人工智能”,到底有什么可怕的? 【刘挺】2014年6月8日,首次有电脑通过图灵测试,机器人“尤金·古斯特曼”扮演一位乌克兰13岁男孩,成功地在国际图灵测试比赛中被33%的评委判定为人类。 【刘挺】现在有学者质疑在图灵测试中,机器人总是在刻意模仿人的行为,包括心算慢,口误等,模仿乌克兰少年也是借非母语掩盖语言的不流畅,借年纪小掩盖知识的不足。 【王涛-爱奇艺】星际穿越里的方块机器人对话很有智慧和幽默。要达到这个智力水平,还需要解决哪些关键问题?语言理解,对话幽默的能力。。。 【刘挺】智能问答系统的核心问题之一是自然语言的语义分析问题。 【白硕】我曾经提出过一个明确的问题,要孙茂松教授转达给深度学习的大拿,也不知道人家怎么应的。问题如下:输入一些回文串作为正例,非回文串作为反例,用深度学习学出一个区分回文串的分类器。
情感计算与电影票房预测
【王涛-爱奇艺】语义分析这个问题深度学习是否有效?或者要依靠知识库,推理的传统技术呢? 【刘挺】深度学习近年来成为语音、图像以及自然语言处理领域的一个研究热潮,受到学术界和工业界的广泛关注。相比于深度学习在语音、图像领域上所取得的成功,其在自然语言处理领域的应用还只是初步取得成效。 作为智能问答基础的自然语言处理技术,当前的热点包括:语义分析、情感计算、文本蕴含等,其他诸如反语、隐喻、幽默、水帖识别等技术均吸引了越来越多学者的关注。 自然语言处理领域的重要国际会议EMNLP,今年被戏称为EmbeddingNLP。(注:Embedding技术是深度学习在NLP中的重要体现) 自然语言本身就是人类认知的抽象表示,和语音、图像这类底层的输入信号相比,自然语言已经具有较强的表示能力,因此目前深度学习对自然语言处理的帮助不如对语音、图像的帮助那么立竿见影,也是可以理解的。 我实验室研制的语言处理平台(LTP)历经十余年的研发,目前已开源并对外提供云服务,称为语言云。感兴趣的群友可以在语言云的演示系统中测试目前自然语言处理的句法语义分析水平:http://www.ltp-cloud.com
【杨静lillian】情感计算,这个有趣。可以把我的微信好友按照情感量化,排个序么? 【刘挺】情感分析是当前自然语言处理领域的热点,在社会媒体兴起之前,语言处理集中于对客观事实文本,如新闻语料的处理,社会媒体兴起之后,广大网民在网上充分表达自己的情绪,诸如,对社会事件、产品质量等的褒贬评论,对热点话题的喜、怒、悲、恐、惊等情绪。 目前的情感分析技术可以计算你的粉丝对你的情感归属度,对你各方面观点的支持及反对的比例。我们实验室研制了微博情绪地图:http://qx.8wss.com/,根据对大量微博文本的实时分析,观测不同地域的网民对各类事件的情绪变化。 现在在微信上输入”生日快乐“,屏幕上会有生日蛋糕飘落。未来,只要你在微信聊天中的文字带有情绪,就能够被机器识别并配动画配音乐。 机器能够理解甚至模拟人的情感,是机器向类人系统迈进的一个重要方向。
【胡本立】深刻理解自然语言的产生和理解还得等对脑科学包括脑认知过程和机制的理解,通个模拟来发现和理解难会有突破性进展。
【杨静lillian】情感归属度这个比较有趣。我认为可以对微信群做个智能筛选。保留归属度高的,删除归属度低的。公众号也是同理。刘老师,那么您认为情感计算是未来认知计算的突破方向之一? 【朱进】@杨静lillian 恕我直言,机器的智能筛选免不了是弱智的决定。只要编程这种形式存在,真正意义上的创造就很难想象。 【白硕】情感归属度,先要解决特定的情感倾向是针对谁、针对什么事儿的。反贪官不一定反皇帝,反害群之马不一定反群主。 【刘挺】呵呵,白老师说的是评价对象(比如“汽车”)识别问题,评价对象还有多个侧面(比如“汽车的外观、动力、油耗等”)。 【刘挺】刚才杨静群主提到认知计算,我们认为计算有四个高级阶段:感知计算、认知计算、决策计算和创造计算。 语 音识别、图像识别属于感知层面,语言理解、图像视频的理解、知识推理与数据挖掘属于认知计算,在人类认知世界并认清规律的基础上,需要对社会发展的未来进 行预测并辅助决策,更高的计算则是创造计算,比如我们正在研制的机器自动作文属于创造计算。情感与认知密切相关,应该属于认知计算层面。 我们开展了两年多的中国电影票房预测研究,最近百度也开展了电影票房的预测,这项研究属于决策计算范畴。 【杨静lillian】百度对《黄金时代》的预测据说遭遇了滑铁卢。《黄金时代》这个片子,最主要的原因还是文艺片当大众片推了,高估了市场的接受度。 【刘挺】对于《黄金时代》的票房,百度预测是2.3亿,我实验室“八维社会时空”(http://yc.8wss.com)的预测是8000万,实际票房是5200万而。我们正在开展股票预测研究,社会媒体上反映出的股民情绪为股票预测提供了新的数据支持。重大突发事件与股票涨跌的关联亦是股票预测的重要手段。 白老师是上海证券交易所的总工,又是计算机领域的顶级专家,对证券市场中的计算技术最有发言权,以后我们这方面的研究需要向白老师学习 【杨静lillian】照白老师的想法,量化交易应该逐渐取代散户操作,那么情绪的影响应该是越来越小了。至少权重不会像此前那么高。 【白硕】应该说是情绪都暴露在量化武器的射程之内。
【刘挺】关于票房预测,我们采用了基于自然语言语义分析的用户消费意图识别技术,在电影上映前较为准确地计算在微博上表达观影意图的人群数量,这是我实验室票房预测的一块基石。 【朱 进】假如是个制作质量极差的电影,但是谁都没看过,制作方按常规方式宣传,机器能预测出来票房会极差吗?最简单的道理,完全同样的内容,换个相近的名字作 为新电影再放,机器会对票房给出跟第一次结果一样的预测吗?如果第三次换个名字再放哪?题目很牛,所有的宣传都很牛。问题是,预测的机器难道不需要先看一 遍电影再猜吗?另外,这机器真的能看懂电影吗? 【白硕】朱老师,买票的人基本都是没看过的人。做决策,从分析没看过的人的行为入手倒是可以理解的。
【刘挺】票房预测有时会失准,主要原因包括:电影制作方的强力微博营销行为、竞争影片的冲击、主创人员不合时宜的公关表态等等。 我实验室还在开展因果分析的研究,在《大数据时代》一书中,作者舍恩伯格认为相关性非常重要,因果关系可以忽略,我们认为因果关系的挖掘将对人类的决策起到关键作用,值得深入研究。 比如,如果《黄金时代》市场不理想的原因是如杨静所言“文艺片当大众片推了”,那么如何用大数据验证该原因是真正的主要原因,以及是否还有其他隐蔽的重要原因未被发现,这将对未来电影营销提供重要的决策支持。
【杨静lillian】市场有时非理性。看看《泰囧》,还有《小时代》这类片子就知道了。不知为何,国产片总是低智商更符合大众口味,但美国大片,就《星际穿越》也可以横扫中国。口碑的分析恐怕也很重要。不仅是宣传。朋友的评价这些都影响观影决策。还有时光网与豆瓣的评分。 【王涛-爱奇艺】静主说的这个,和爱奇艺同事聊也是有这个规律。我们今年买了变4,收视一般。那个便宜的泰囧,大众很喜闻乐见。小时代是为90后设计的。致青春为80后设计的。这是他们票房火的原因。 【杨静lillian】可能是两个受众市场。需要做个交叉分析。 【白硕】火的都有共同点,但共同点和智商无关。大众不是傻子但也不都是高大上。从高大上角度看低质量的影片也不乏受大众追捧的理由。这又相对论了。
【白硕】我关心的问题是,整个预测领域都有个案定终身的趋势,什么准确率召回率一类测度都不见了,这是非常危险的苗头。 【朱进】@白硕 按 我的理解,所谓的预测是在首映之前就做出来的。第一天的票房可以跟机器的预测一致。不过看电影的人又不是傻子,第一场一过,马上电影很臭不值得看的舆论就 传播出去了。后面的人还会按照之前的预测那样挤到电影院里吗?按我的理解,票房的关键还是片子的质量。可是片子的质量再没看到之前其实是不知道的。 【刘挺】@朱进 ,短期预测易,长期预测难,因为在事件演进过程中会有多种因素干扰。预测有两种,一种是事前预测,一种是在事件推进中根据已经获悉的事态对下一步事态进行预测。 【朱进】@刘挺 我咋觉得长期更容易猜准啊,因为时间对于涨落是有平滑的。
【杨静lillian】刘教授可总结一下,认知计算未来您最看好的技术突破么?需要从您的角度给出趋势判断。
【刘挺】我是自然语言处理、社会媒体处理方面的研究者,视野有限。 自然语言处理技术趋势:1. 从句法分析向深度语义分析发展;2. 从单句分析向篇章(更大范围语境)发展;3. 引入人的因素,包括众包等手段对知识进行获取;4. 从客观事实分析到主观情感计算;5. 以深度学习为代表的机器学习技术在NLP中的应用 高考文科机器人只是一种测试智能水平推动学术发展的手段,高考机器人技术一旦突破,将像沃森一样甚至比沃森更好的在教育、医疗等各个领域推动一系列重大应用。 我的观点不仅代表我个人,也代表我实验室多位老师,包括文本挖掘与情感分析技术方面的秦兵教授、赵妍妍博士,自然语言处理方面的车万翔副教授,问答领域的张宇教授、张伟男博士,社会媒体处理领域博士生丁效、景东讲师。也期望将来各位专家对我的同事们给予指点。
| |
|
(没有打分) |
百度语音识别新突破–Deep Speech系统
作者 AbelJiang | 2014-12-24 11:33 | 类型 Deep Learning, 机器学习 | Comments Off
|
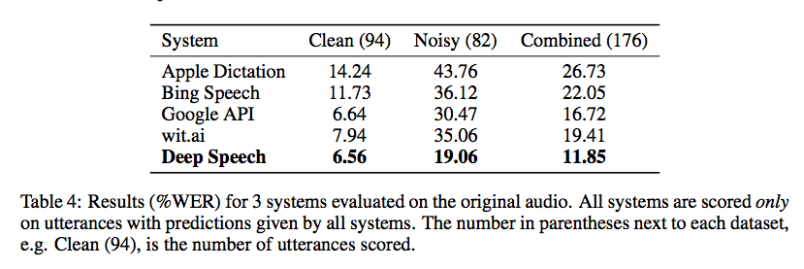
原文转载自:https://gigaom.com 相关论文:DeepSpeech: Scaling up end-to-end speech recognition Chinese search engine giant Baidu says it has developed a speech recognition system, called Deep Speech, the likes of which has never been seen, especially in noisy environments. In restaurant settings and other loud places where other commercial speech recognition systems fail, the deep learning model proved accurate nearly 81 percent of the time. That might not sound too great, but consider the alternative: commercial speech-recognition APIs against which Deep Speech was tested, including those for Microsoft Bing, Google and Wit.AI, topped out at nearly 65 percent accuracy in noisy environments. Those results probably underestimate the difference in accuracy, said Baidu Chief Scientist Andrew Ng, who worked on Deep Speech along with colleagues at the company’s artificial intelligence lab in Palo Alto, California, because his team could only compare accuracy where the other systems all returned results rather than empty strings.
Ng said that while the research is still just research for now, Baidu is definitely considering integrating it into its speech-recognition software for smartphones and connected devices such as Baidu Eye. The company is also working on an Amazon Echo-like home appliance called CoolBox, and even a smart bike. “Some of the applications we already know about would be much more awesome if speech worked in noisy environments,” Ng said. Deep Speech also outperformed, by about 9 percent, top academic speech-recognition models on a popular dataset called Hub5’00. The system is based on a type of recurrent neural network, which are often used for speech recognition and text analysis. Ng credits much of the success to Baidu’s massive GPU-based deep learning infrastructure, as well as to the novel way them team built up a training set of 100,000 hours of speech data on which to train the system on noisy situations. Baidu gathered about 7,000 hours of data on people speaking conversationally, and then synthesized a total of roughly 100,000 hours by fusing those files with files containing background noise. That was noise from a restaurant, a television, a cafeteria, and the inside of a car and a train. By contrast, the Hub5’00 dataset includes a total of 2,300 hours. “This is a vast amount of data,” said Ng. ” … Most systems wouldn’t know what to do with that much speech data.”
Another big improvement, he said, came from using an end-to-end deep learning model on that huge dataset rather than using a standard, and computationally expensive, type of acoustic model. Traditional approaches will break recognition down into multiple steps, including one called speaker adaption, Ng explained, but “we just feed our algorithm a lot of data” and rely on it to learn everything it needs to. Accuracy aside, the Baidu approach also resulted in a dramatically reduced code base, he added. You can hear Ng talk more about Baidu’s work in deep learning in this Gigaom Future of AI talk embedded below. That event also included a talk from Google speech recognition engineer Johan Schalkwyk. Deep learning will also play a prominent role at our upcoming Structure Data conference, where speakers from Facebook, Yahoo and elsewhere will discuss how they do it and how it impacts their businesses. | |
 (2个打分, 平均:1.00 / 5) (2个打分, 平均:1.00 / 5) |

【邢波】机器学习需多元探索,中国尚缺原创引领精神
作者 陈怀临 | 2014-12-17 11:49 | 类型 Deep Learning, 机器学习, 科技普及 | 1条用户评论 »
|
【邢波Eric P. Xing】清华大学物理学、生物学本科;美国新泽西州立大学分子生物学与生物化学博士;美国加州大学伯克利分校(UC,Berkeley)计算机科学博士;现任美国卡耐基梅隆大学(CMU)计算机系教授,2014年国际机器学习大会(ICML)主席。美国国防部高级研究计划局(DARPA)信息科学与技术顾问组成员。(他在中国大数据技术大会上的报告请参考阅读原文链接) Professor of Carnegie Mellon University Program Chair of ICML2014Dr. Eric Xing is a Professor of Machine Learning in the Schoolof Computer Science at Carnegie Mellon University. His principal researchinterests lie in the development of machine learning and statisticalmethodology; especially for solving problems involving automated learning,reasoning, and decision-making in high-dimensional, multimodal, and dynamicpossible worlds in social and biological systems. Professor Xing received aPh.D. in Molecular Biology from Rutgers University, and another Ph.D. inComputer Science from UC Berkeley.
【杨静lillian】这次您受邀来中国参加大数据技术大会,在您看来,中国大数据相关技术和生态发展到了什么水平?与美国的差距主要体现在哪些方面? 【邢波Eric P. Xing】中国的大数据技术与题目跟进国外趋势还做得不错。但在原创性部分有欠缺。也许由于工程性,技术性上的原创工作通常不吸引眼球且风险极大这样的特点,所以没人愿意啃硬骨头。整体不算太差,但缺少领军人物,和领先的理念。还有在导向上,倾向于显著的效益和快的结果,但对于学术本身的追求不是很强烈。如果效果不是立竿见影,愿意碰的人就少。大部分人都这样,就是趋向于平庸。整个生态系统上看,中国大数据发展水平与欧洲、日本比并不差,公众的认知也热烈。整个环境还蛮好。与中国学生有点像,群体不见得差,但缺少特别杰出的领袖,和有胆识的开拓者。
人工智能的目标没有上限,不应以人脑为模板
【杨静lillian】您说过深度学习只是实现人工智能目标的一种手段,那么在您看来,人工智能的目标到底是什么?抛开《奇点临近》的科学性,您认为机器智能总体超越人类这个目标在2050年前后有可能实现么?或者说在2050年前后,世界的控制权会不会由人工智能主导? 【邢波 Eric P. Xing】人工智能的目标其实是没有上限的。人工智能的目标并不是达到动物或人类本身的智力水平,而是在可严格测量评估的范围内能否达到我们对于具体功能上的期待。例如用多少机器、多长时间能达成多少具体任务?(这里通常不包含抽象,或非客观任务,比如情绪,感情等。)人的智力不好评价,尤其标准、功能、结果及其多元,很多不是人工智能追求的目标。科幻家的浪漫幻想和科学家的严格工作是有区分的。大部分计算机科学家完成的工作可能不那么让人惊叹,但很多任务已经改变世界。例如,飞机自动驾驶装置可能没有人的智能,但它完成飞行的任务,却比人类驾驶员好。 再比如弹钢琴,机器也可以弹钢琴,精确程度肯定超过人。但是否有必要发明机器人代替人弹钢琴来上台表演,或机器人指挥家甚至机器人乐队?从这个角度看,我个人没有动力或必要去发明机器人来弹钢琴,至少我不认为应该去比较机器和人类钢琴家。钢琴大师如霍洛维茨,鲁宾斯坦是不能被机器替代的、比较的,虽然他们也弹错音。一个武术大师,如果现在用枪来和他比武力,把他打死,有意义吗?那么标准是什么?我认为我们应该去想和做一些更有意义和价值的事情。 关于2050年的未来预测,如果非要比较的话,我认为人工智能不会达到超越人类的水平,科学狂人或科幻家也许喜欢这样预测未来,博得眼球,但科学家需要脚踏实地做有意义的工作。所谓奇点是根本不可能的。未来学家这样去臆测也许是他们的工作;政治家、企业家、实践学家向这个方向去推动则是缺乏理性、责任和常识;而科学家和技术人员去应和,鼓吹这些则是动机可疑了? 人工智能脱离人类掌控?这种可能性不能排除。但要是咬文嚼字的话,如果是计算机的超级进步涌现出智能,以至脱离人类掌控而自行其道,那还何谓“人工”?这就变成“自然智能”。我认为“世界的控制权会不会由人工智能主导”这类题目定义就不严肃,无法也无益做科学讨论,也不能被科学预见。
【Ning】能否通俗科普一下机器学习的几个大的技术方向,和它们在实践中可能的应用。 【邢波 Eric P. Xing】很难科普的讲,不使用专业术语。机器学习不过是应用数学方法体系和计算实践的一个结合,包罗万象。比如图模型(深度学习就是其中一种),核(kernel)方法,谱(spectral)方法,贝叶斯方法,非参数方法,优化、稀疏、结构等等。我在CMU的机器学习课和图模型课对此有系统全面的讲解。 机器学习在语音、图形,机器翻译、金融,商业,机器人,自动控制方面有广泛的应用。很多自然科学领域,例如进化分析,用DNA数据找生物的祖先(属于统计遗传的问题),需要建模,做一个算法去推导,数学形式和求解过程与机器学习的方法论没有区别。一个成熟的,优秀的机器学习学者是应被问题、兴趣和结果的价值去激励、推动,而不是画地为牢,被名词所约束。我本人在CMU的团队,就既可以做机器学习核心理论、算法,也做计算机视觉、自然语言处理,社会网络、计算生物学,遗传学等等应用,还做操作系统设计,因为底层的基本法则都是相通的。
【李志飞】大数据,深度学习,高性能计算带来的机器学习红利是不是差不多到头了?学术界有什么新的突破性或潜在突破性的新算法或原理可以把机器学习的实际应用性能再次大幅提升? 【邢波 Eric P. Xing】大数据、深度学习、高性能计算只是接触了机器学习的表层,远远不到收获红利的时候,还要接着往下做。算法的更新和变化还没有深挖,很多潜力,空间还很大。现在还根本没做出像样的东西。另外我要强调,机器学习的所谓红利,远远不仅靠“大数据、深度学习、高性能计算”带来。举个例子,请对比谷歌和百度的搜索质量(即使都用中文),我想即使百度自己的搜索团队也清楚要靠什么来追赶谷歌。
【Ning】世界各国在机器学习方面的研究实力如何?从科普的角度来看,人的智能和人工智能是在两个平行的世界发展么? 【邢波 Eric P. Xing】不太愿意评价同行的水平。人的智能和人工智能可以平行,也可以交互。
【杨静lillian】您既是计算机专家,还是生物学博士,在您看来,如果以未来世界整体的智能水平作为标准,是基因工程突破的可能性大,还是人工智能领域大,为什么? 【邢波 Eric P. Xing】基因工程其实突破很多。在美国和全球转基因的食品也有很多。胰岛素等药物也是通过转基因菌株来生产,而不是化学合成。诊断胎儿遗传缺陷的主要手段也基于基因工程技术。但是舆论风向在变,也不理性。例如我小时候读的《小灵通看未来》里,“大瓜子”等神奇食品现在已经通过基因技术实现。从技术上看,我们已经实现了这个需要,但公众是否接受,是个问题。科学家要对自己的责任有所界定。例如造出原子弹,科学家负责设计制造,但怎么用是社会的事。 人工智能领域也已经有很多应用型的成果,但也还有很大空间。人工智能就是要去达到功能性的目标,有很多事情可以用它去达成,但这里不见得包括感情思考。人的乐趣就是感情和思考,如果让机器代替人思考,我认为没有这个需要。 靠基因工程提升人的智能基本不可能,人的成就也未必与基因完全相关,例如冯.诺依曼,很大程度是后天环境教育形成的。基因只是必要条件,而非充分条件。作为一个生物学博士,我反对用基因工程改变人的智能的做法,认为这很邪恶。科学家应该对自然法则或上帝有所敬畏。在西方,优生学是不能提的,因为它违反了人本主义的原则和人文人权的理念。我个人认为这个题目在科学道德上越界了,是不能想象的。
【杨静lillian】您说过美国的大脑计划雷声大雨点小,请问欧盟的大脑工程您怎么看,会对人工智能发展起到促动作用么?或者说,人工智能研究是否应以人的大脑为模型? 【邢波 Eric P. Xing】欧洲大脑工程的争议很大,包括目标和经费分配。但这个目标也提升了社会和公众的对于科学的关注,工程的目的不用过于纠结。这个项目就是启发式的,培养人才,培养科学实力的种子项目。 大脑工程,无论欧洲和美国,对人工智能发展没有直接的促进作用。以仿生学来解释人工智能工程上的进步,至少在学术上不是一个精确和可执行的手段,甚至是歧路。只是用于教育公众,或者通俗解释比较艰深的科学原则。 人工智能不必也不应以人脑为模型。就像飞机和鸟的问题,两者原理手段完全不同。人工智能应该有自己的解决办法,为什么要用人脑的模型来限制学科的发展?其实有无数种路径来解决问题,为什么只用人脑这一种模板?
机器学习领域应多元探索,巨大潜力与空间待挖掘
【李志飞】更正一下我的问题: 现有的机器学习算法如深度学习在利用大数据和高性能计算所带来的红利是不是遇到瓶颈了?(至少我所在的机器翻译领域是这样) 接下来会有什么新机器学习算法或原理会把大数据和高性能计算再次充分利用以大幅提升应用的性能?我觉得如果机器学习领域想在应用领域如机器翻译产生更大的影响,需要有更多人做更多对应用领域的教育和培训,或者是自己跨界直接把理论研究跟应用实践结合起来 【邢波 Eric P. Xing】机器学习的算法有几百种,但是目前在深度学习领域基本没有被应用。尝试的空间还很大,而且无需局限在深度学习下。一方面机器学习学者需要跨出自己的圈子去接触实际,另一方面应用人士也要积极学习,掌握使用发展新理论。
【杨静lillian】您认为谷歌是全球最具领导性的人工智能公司么?您预测人工智能技术会在哪几个领域得到最广泛的应用?人工智能产业会像互联网领域一样出现垄断么? 【邢波 Eric P. Xing】谷歌是最具有领导性的IT公司。世界上没有人工智能公司,公司不能用技术手段或目标定义名称和性质。人工智能是一个目标,而不是具体的一些手段。所以有一些界定是不严肃的。关于应用领域前面已经谈过了。
【杨静lillian】您曾经比喻,中国的人工智能领域里,有皇帝和大臣,您怎么判断中国人工智能产业的发展水平和发展方向?最想提出的忠告是什么?
【邢波 Eric P. Xing】中国整个IT领域,以至科学界,应该百花齐放,有的观点占领了过多的话语权,别的观点就得不到尊重。目前业界形成一边倒的局面,媒体的极化现象比较严重。建议媒体应该平衡报道。中国目前深度学习话语权比较大,没人敢批评,或者其他研究领域的空间被压缩。这种研究空间的压缩对机器学习整个领域的发展是有害的。学界也存在有人山中装虎称王,山外实际是猫的现象。坦率的说,目前中国国内还没有世界上有卓越影响的重量级人工智能学者,和数据科学学者。中国需要更多说实话,戳皇帝新衣的小孩,而不是吹捧的大臣、百姓和裸奔的皇帝。不要等到潮水退去,才让大家看到谁在裸奔。 现在一些舆论以深度学习绑架整个机器学习和人工智能。这种对深度学习或以前以后某一种方法的盲目追捧,到处套用,甚至上升到公司、国家战略,而不是低调认真研究其原理、算法、适用性和其它方法,将很快造成这类方法再次冷却和空洞化,对这些方法本身有害。行外人物、媒体、走穴者(比如最近在太庙高谈阔论之流)对此的忽悠是很不负责的,因为他们到时可以套了钱、名,轻松转身,而研发人员投入的时间、精力和机会成本他们是不会在乎的。美国NSF、军方和非企业研究机构与神经计算保持距离是有深刻科学原因的,而国内从民到官这样的发烧,还什么弯道超车,非常令人怀疑后面的动机和推手。
【杨静lillian】确实如您所说,现在大多数中国企业或学术机构,被一个大问题困扰。就是缺乏大数据源,或者缺乏大数据分析工具,那么怎样才能搭上大数据的时代列车呢? 【邢波 Eric P. Xing】首先我没有那样说过,我的看法其实相反。即使给那些企业提供了大数据,他们真会玩么?这有点叶公好龙,作为一个严肃的研究,应该把工具造出来。得先有好的技术,别人才会把数据提供给你。有时小数据都没做好,又开始要大数据,没人会给。可以用模拟,更可以自己写爬网器(crawler)自己在网上抓。例如我们的实验室,学生就可以自己去找数据源。研究者的心态有时不正确,好像社会都需要供给他,自己戴白手套。其实人人都可以搭上“大数据”这个列车,但需要自己去勤奋积极努力。
【杨静lillian】Petuum开源技术系统会成为一种大数据处理的有效工具么?可以取代Spark? 【邢波 Eric P. Xing】希望如此。更客观地说,不是取代。是解决不同的问题,有很好的共生、互补关系。
中国学术界的原创性待提高,缺乏灯塔型领军人物
【刘成林】@杨静lillian问题提的好!期待详细报道。另外我加一个问题,请Eric给中国人工智能学术界提点建议,如何选择研究课题和如何深入下去。 【邢波 Eric P. Xing】希望中国人工智能学术界要对机器学习、统计学习的大局有所掌控,全面判断和寻找,尚未解决的难题。这需要很多人静下来,慢下来,多读,多想。而不是跟风或被热点裹挟。得有足够的耐心,屏蔽环境的影响和压力。在技术上得重视原创性,如果只把学术看成是一个短时期的比赛,价值就不大。得找有相当难度,而自己有独特资源的方向,就保证了思想的原创性和资源的独特性。要分析清楚自己的优势。 例如我们做的Petuum,很多人就不敢碰。我们开始时甚至都不懂操作系统,从头学;我们放缓了步子,两年近十人只出两篇文章。但不尝试怎么知道?得给自己空间。
【张宝峰】邢老师提到过在机器学习领域,美国可以分成几个大的分支,比如Jordan 算一个,能否再详细的阐述还有哪些其他分支和流派? 【邢波 Eric P. Xing】这算八卦。原来有几个流派,但现在流派的界限已经非常模糊了。
【刘挺-哈工大】您认为哪些方向或组织有希望出现领军人物? 【邢波 Eric P. Xing】国内的同行思路有些短板,所以研究领域比较割裂。上层不够高,下层也不够深,横向也不宽,因此扎根不够,影响有限。所以比较缺憾,体现为很多割裂的领域。 在中国的企业界和学术界哪里会出现领军人物?这个问题我认为:对什么叫“领军人物”国内的同行的定义还相当肤浅,功利。除了商业上的成功,或者学术上获奖,这些显性成就,还需要有另外的维度。例如从另外一个角度,具有个人魅力,他的思想、理论、人格被很多人追随和推崇的,有众多门生甚至超越自己的,就没有。中国的研究者不善于建立自己的体系,去打入一个未知的境界,做一个灯塔型的人物。这种人物在中国特别少,基本上没有。 在美国M.Jordan就是这样的人物,就有灯塔型的效应,被众人或学术界效法,敬佩,和追随,包括他的反对者。他也不是中国最典型的最年轻教授等成功人物,而是大器晚成,到了45岁才开始发扬光大,上新台阶。但他的做为人的魅力(会五国语言,年轻时弹琴挣钱,平时风趣博学);他的勤奋自律(到Berkeley后正教授了还和我们一起在课堂听课,从头学统计,优化,到现在还天天读文献);他的工作和生活的平衡(现在自己组乐队,和孩子玩儿);他的众多学生的成就(很多方向和他大不相同,甚至相对);他的严谨,严肃的学风;和他的洞察力。这些都是除了学术成就之外他成为领军人物的要素。我们国内知识分子接近这个境界的太少了。不要说学术上的差距,就连上餐桌品酒、懂菜,说话写作遣词造句的造诣都差不少。所以,先不要急出领军人物;先从文化上培育土壤,培育认真、一丝不苟的习惯和精神,培育热爱教学、热爱学生的责任;培育洁身自好、玉树临风的气质;注重细节、小节、修养,再由小至大、由士及贤、由贤入圣。在这个境界上,学问就变成一种乐趣了,就可以做出彩了。
【张宝峰】欢迎回国,把Pleuum变成实际产业标准。 【邢波 Eric P. Xing】不是没有可能,但也需要好的平台和环境、机缘。这次回国参会,很兴奋的是,学术界和产业界都对机器学习的技术有很大的热情,也有信念去获取成功,相当积极。我个人的观点,通过交流,收获很大。期望这种交流继续,也期待国内的学界、媒体、企业能够共同促进产业生态的发展,利益多样化。可以是金钱的成功,也可以是原创性的增长。而不是被某一个目标来一统天下。 如果回国发展,应该有更多商业上的机会。但是国内的起点低,有些规则两国不一样。现在人生的目标不是钱,而是对乐趣的满足,以及服务社会。实现自我的价值,也让家人,朋友,学生,师长,同事开心。 下个月还有机会回国,到时也期待与大家继续交流互动。非常感谢@杨静lillian 提供这个和大家交流的机会。也钦佩她专业敬业。这次结识很多朋友,后会有期! | |
|
(3个打分, 平均:5.00 / 5) |
The Wall Street Journal吴恩达专访
作者 AbelJiang | 2014-12-08 13:47 | 类型 Deep Learning, 机器学习, 行业动感 | Comments Off
|
原文转载自:http://blogs.wsj.com Six months ago, Chinese Internet-search giant Baidu signaled its ambitions to innovate by opening an artificial-intelligence center in Silicon Valley, in Google’s backyard. To drive home the point, Baidu hired Stanford researcher Andrew Ng, the founder of Google’s artificial-intelligence effort, to head it. Ng is a leading voice in “deep learning,” a branch of artificial intelligence in which scientists try to get computers to “learn” for themselves by processing massive amounts of data. He was part of a team that in 2012 famously taught a network of computers to recognize cats after being shown millions of photos. On a practical level, the field helps computers better recognize spoken words, text and shapes, providing users with better Web searches, suggested photo tags or communication with virtual assistants like Apple’s Siri. In an interview with The Wall Street Journal, Ng discussed his team’s progress, the quirks of Chinese Web-search queries, the challenges of driverless cars and what it’s like to work for Baidu. Edited excerpts follow: WSJ: In May, we wrote about Baidu’s plans to invest $300 million in this facility and hire almost 200 employees. How’s that coming along? Ng: We’re on track to close out the year with 96 people in this office, employees plus contractors. We’re still doing the 2015 planning, but I think we’ll quite likely double again in 2015. We’re creating models much faster than I have before so that’s been really nice. Our machine-learning team has been developing a few ideas, looking a lot at speech recognition, also looking a bit at computer vision. WSJ: Are there examples of the team’s work on speech recognition and computer vision? Ng: Baidu’s performance at speech recognition has already improved substantially in the past year because of deep learning. About 10% of our web search queries today come in through voice search. Large parts of China are still a developing economy. If you’re illiterate, you can’t type, so enabling users to speak to us is critical for helping them find information. In China, some users are less sophisticated, and you get queries that you just wouldn’t get in the United States. For example, we get queries like, “Hi Baidu, how are you? I ate noodles at a corner store last week and they were delicious. Do you think they’re on sale this weekend?” That’s the query. WSJ: You can process that? Ng: If they speak clearly, we can do the transcription fairly well and then I think we make a good attempt at answering. Honestly, the funniest ones are schoolchildren asking questions like: “Two trains leave at 5 o’ clock, one from …” That one we’ve made a smaller investment in, dealing with the children’s homework. In China, a lot of users’ first computational device is their smartphone, they’ve never owned a laptop, never owned a PC. It’s a challenge and an opportunity. WSJ: You have the Baidu Eye, a head-mounted device similar to Google Glass. How is that project going? Ng: Baidu Eye is not a product, it’s a research exploration. It might be more likely that we’ll find one or two verticals where it adds a lot of value and we’d recommend you wear Baidu Eye when you engage in certain activities, such as shopping or visiting museums. Building something that works for everything 24/7 – that is challenging. WSJ: What about the self-driving car project? We know Baidu has partnered with BMW on that. Ng: That’s another research exploration. Building self-driving cars is really hard. I think making it achieve high levels of safety is challenging. It’s a relatively early project. Building something that is safe enough to drive hundreds of thousands of miles, including roads that you haven’t seen before, roads that you don’t have a map of, roads where someone might have started to do construction just 10 minutes ago, that is hard. WSJ: How does working at Baidu compare to your experience at Google? Ng: Google is a great company, I don’t want to compare against Google specifically but I can speak about Baidu. Baidu is an incredibly nimble company. Stuff just moves, decisions get made incredibly quickly. There’s a willingness to try things out to see if they work. I think that’s why Baidu, as far as I can tell, has shipped more deep-learning products than any other company, including things at the heart of our business model. Our advertising today is powered by deep learning. WSJ: Who’s at the forefront of deep learning? Ng: There are a lot of deep-learning startups. Unfortunately, deep learning is so hot today that there are startups that call themselves deep learning using a somewhat generous interpretation. It’s creating tons of value for users and for companies, but there’s also a lot of hype. We tend to say deep learning is loosely a simulation of the brain. That sound bite is so easy for all of us to use that it sometimes causes people to over-extrapolate to what deep learning is. The reality is it’s really very different than the brain. We barely (even) know what the human brain does. WSJ: For all of Baidu’s achievements, it still has to operate within China’s constraints. How do you see your work and whether its potential might be limited? Ng: Obviously, before I joined Baidu this was something I thought about carefully. I think that today, Baidu has done more than any other organization to open the information horizon of the Chinese people. When Baidu operates in China, we obey Chinese law. When we operate in Brazil, which we also do, we obey Brazil’s law. When we operate in the U.S. and have an office here, we obey U.S. law. When a user searches on Baidu, it’s clear that they would like to see a full set of results. I’m comfortable with what Baidu is doing today and I’m excited to continue to improve service to users in China and worldwide. | |
|
(没有打分) |
Spark的现状与未来发展
作者 陈怀临 | 2014-12-02 10:17 | 类型 Deep Learning, 机器学习 | 1条用户评论 »
|
[转载文章] Spark的发展对于一个具有相当技术门槛与复杂度的平台,Spark从诞生到正式版本的成熟,经历的时间如此之短,让人感到惊诧。2009年,Spark诞生于伯克利大学AMPLab,最开初属于伯克利大学的研究性项目。它于2010年正式开源,并于2013年成为了Aparch基金项目,并于2014年成为Aparch基金的顶级项目,整个过程不到五年时间。
由于Spark出自伯克利大学,使其在整个发展过程中都烙上了学术研究的标记,对于一个在数据科学领域的平台而言,这也是题中应有之义,它甚至决定了Spark的发展动力。Spark的核心RDD(resilient distributed datasets),以及流处理,SQL智能分析,机器学习等功能,都脱胎于学术研究论文,如下所示:
Discretized Streams: Fault-Tolerant Streaming Computation at Scale. Matei Zaharia, Tathagata Das, Haoyuan Li, Timothy Hunter, Scott Shenker, Ion Stoica. SOSP 2013. November 2013.
Shark: SQL and Rich Analytics at Scale. Reynold Xin, Joshua Rosen, Matei Zaharia, Michael J. Franklin, Scott Shenker, Ion Stoica. SIGMOD 2013. June 2013.
Discretized Streams: An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters. Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, Ion Stoica. HotCloud 2012. June 2012.
Shark: Fast Data Analysis Using Coarse-grained Distributed Memory (demo). Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Haoyuan Li, Scott Shenker, Ion Stoica. SIGMOD 2012. May 2012. Best Demo Award.
Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker, Ion Stoica. NSDI 2012. April 2012. Best Paper Award and Honorable Mention for Community Award.
Spark: Cluster Computing with Working Sets. Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, Ion Stoica. HotCloud 2010. June 2010.
在大数据领域,只有深挖数据科学领域,走在学术前沿,才能在底层算法和模型方面走在前面,从而占据领先地位。Spark的这种学术基因,使得它从一开始就在大数据领域建立了一定优势。无论是性能,还是方案的统一性,对比传统的Hadoop,优势都非常明显。Spark提供的基于RDD的一体化解决方案,将MapReduce、Streaming、SQL、Machine Learning、Graph Processing等模型统一到一个平台下,并以一致的API公开,并提供相同的部署方案,使得Spark的工程应用领域变得更加广泛。
Spark的代码活跃度
从Spark的版本演化看,足以说明这个平台旺盛的生命力以及社区的活跃度。尤其在2013年来,Spark进入了一个高速发展期,代码库提交与社区活跃度都有显著增长。以活跃度论,Spark在所有Aparch基金会开源项目中,位列前三。相较于其他大数据平台或框架而言,Spark的代码库最为活跃,如下图所示:
从2013年6月到2014年6月,参与贡献的开发人员从原来的68位增长到255位,参与贡献的公司也从17家上升到50家。在这50家公司中,有来自中国的阿里、百度、网易、腾讯、搜狐等公司。当然,代码库的代码行也从原来的63,000行增加到175,000行。下图为截止2014年Spark代码贡献者每个月的增长曲线:
下图则显示了自从Spark将其代码部署到Github之后的提交数据,一共有8471次提交,11个分支,25次发布,326位代码贡献者。
目前的Spark版本为1.1.0。在该版本的代码贡献者列表中,出现了数十位国内程序员的身影。这些贡献者的多数工作主要集中在Bug Fix上,甚至包括Example的Bug Fix。由于1.1.0版本极大地增强了Spark SQL和MLib的功能,因此有部分贡献都集中在SQL和MLib的特性实现上。下图是Spark Master分支上最近发生的仍然处于Open状态的Pull Request:
可以看出,由于Spark仍然比较年轻,当运用到生产上时,可能发现一些小缺陷。而在代码整洁度方面,也随时在对代码进行着重构。例如,淘宝技术部在2013年就开始尝试将Spark on Yarn应用到生产环境上。他们在执行数据分析作业过程中,先后发现了DAGSchedular的内存泄露,不匹配的作业结束状态等缺陷,从而为Spark库贡献了几个比较重要的Pull Request。具体内容可以查看淘宝技术部的博客文章:《Spark on Yarn:几个关键Pull Request(http://rdc.taobao.org/?p=525)》。
| |
|
(没有打分) |
机器学习应用–Smart Autofill
作者 AbelJiang | 2014-12-02 10:13 | 类型 机器学习, 行业动感 | Comments Off
|
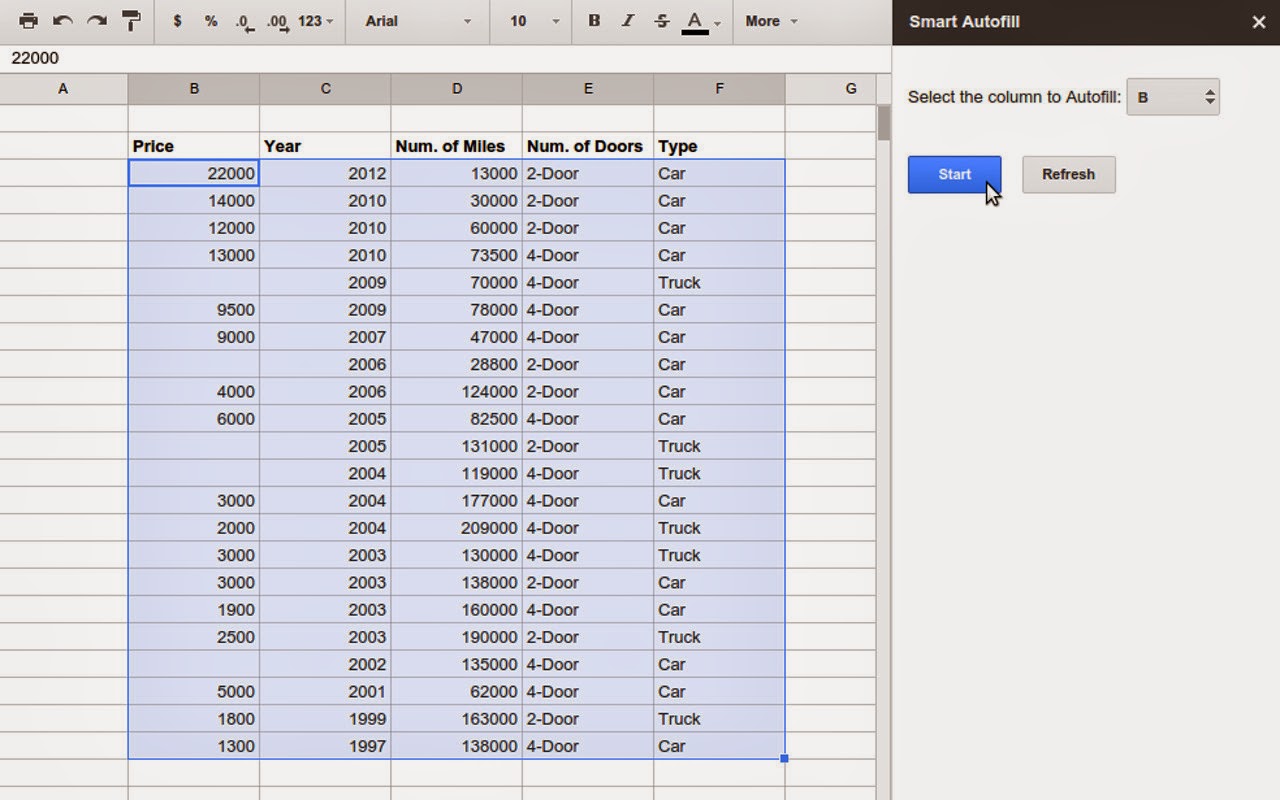
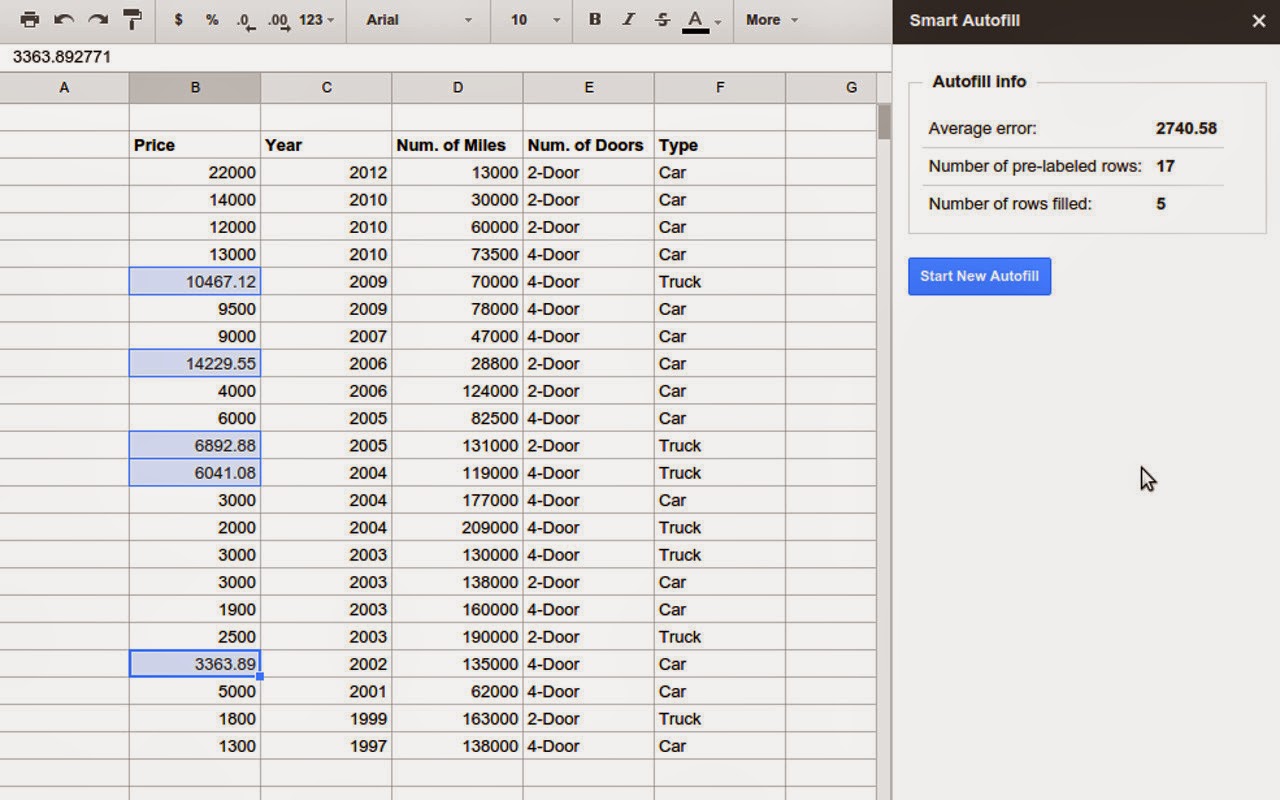
机器学习算法被广泛的应用在谷歌家的语言语音处理,翻译,以及视觉图像处理方面的应用上,看起来都是比较拒人千里的东西,但是最近,谷歌把这项技术用在了自家的Google Sheets上,貌似在我朝较难使用Google Sheets,但是感兴趣还是可以在Chrome Webstore里找到这款叫做Smart Autofill的插件试用一下。 那么Smart Autofill是干什么用的呢?顾名思义,它是用来填表的。经常用Excel的读者一定知道一个功能叫自动填充,能够填充的信息包括日历日期,星期,以及有序数字等。Smart Autofill干的是类似的事,但由于融入了机器学习,逼格又稍高,它可以根据表格中与缺失信息栏相关栏中的数据,学习其中的模式,推测出缺失信息栏中缺失的数据。 Smart Autofill使用了谷歌基于云的机器学习服务–Prediction API。这项服务可以训练多种线性或非线性,分类和回归模型。他会通过对比利用cross-validation算出的Misclassification error(针对分类问题)或RMS error(针对回归问题),自动选出最佳的模型,用于数据预测。 让我们来举个例子: 在下图的截图中,我们给出车的五个非常简单的数据,分别为使用购买年份,行驶里程,车门数量,车辆类型以及价格。因为车的价格可能和车的这些特质有关,因此可以把那些包含价格的行作为训练数据,用Smart Autofill来估测缺失的价格数据。
/*高亮所需数据,选中目标栏*/
参考: | |
|
(没有打分) |