OMAP15 A15 Dual Cores vs Tegra3 Quard Cores
作者 陈怀临 | 2012-02-25 10:01 | 类型 芯片技术 | 11条用户评论 »
王齐 。 《后科技时代--处理器的思考》
作者 陈怀临 | 2012-02-07 14:47 | 类型 弯曲推荐, 芯片技术 | 40条用户评论 »
|
在距离今天不到六十年的时间里,出现了几个与当今电子信息领域有着重大影响的公司和个人。最重要的公司当然是Fairchild半导体,另一些是Fairchild半导体派生出的公司。最有影响力的人选有诸多争议,有人说是Robert Noyce,也有人说是Jack Kilby,我以为只能是William Shockley。我每阅读着与Shockley有关的史料事迹,总有莫名的酸楚。他是硅谷的事实缔造者,也是硅谷第一弃徒。整个硅谷,整个IT史册,再无一人如Shockley般谤满天下。 1947年12月16日,John Bardeen,Walter Brattain和William Shockley发明了人类历史上第一颗固态放大器,之前的放大器采用的是至今或许已被遗忘的真空电子管。他们意识到这个放大器的本质是阻抗的变化,将他们的发明称为Trans-resistor,简称为Transistor。多年以后,钱学森将其正式命名为晶体管。正是这一天的发明,人类进步的历史轨迹被再次更改。一个令所有人为之振奋的电子信息时代即将到来。 1956年的诺贝尔物理奖没有丝毫争议地赋予了这三人。在此前的一年Shockley只身来到加州,来到Santa Clara,成立了Shockley半导体实验室。在这片美国最晚迎来阳光的大地,因为Shockley的到来,将升起第一面迎接电子信息时代的旗帜。 Shockley选人的眼光,与他的科技才能严格成正比。IT史册记载了先后加入Shockley半导体实验室的八位科学家,他们分别是Julius Blank,Victor Grinich,Jean Hoerni,Eugene Kleiner,Jay Last,Gordon Moore,Sheldon Roberts和Robert Noyce。这八个人即将被Shockley称为Traitorous Eight。 Shockley的用人方式,与他的科技才能成反比,在获得诺贝尔物理奖后,也许他认为在科技领域已经没有什么值得他去挑战,他选择挑战财富。他的目标是生产5美分一支的晶体管,借此挑战在加州已经声名赫赫的Hewlett和Packard。Shockley的这个目标直到上世纪八十年代才得以实现。Shockley的想法总是令人难于琢磨。在Shockley半导体实验室存在的岁月里,起初怀抱着无限崇拜与幻想的,Shockley天才的门徒们始终忍受着煎熬。从加入这个到离开这里,他们没有创造出任何一项可以另他们为之自豪的产品。 在Shockley否决了他们准备研究集成电路的一项提议之后,他们被最后一根稻草压垮。这八个人已经不再对Shockley存有任何幻想,集体向Shockley提出辞职。震惊的Shockley,愤怒的Shockley,狂躁的Shockley将这八个人统称为Traitorous Eight。发明了晶体管的Shockley,注定不能制造出晶体管。面对着即将到来的电子信息时代,Shockley黯然离去。他最终加入了斯坦福大学,成为一名教授。 也许是因为Shockley过于孤独,也许是因为Shockley过于希望被人再次关注,他发表了一篇可以让他在耻辱架上停留相当长一段时间的论文,黑人的智商低于白种人。这是Shockley的最后绝唱。1989年,Shockley在孤独中离开这个世界,他的孩子也只是在报纸中得知他的死讯。他启动了一个时代,却只是一个匆匆过客。 离开Shockley之后的Traitorous Eight得到新生,共同创建了仙童半导体公司。这个公司书写了一段至今仍令整个硅谷炫彩夺目的传奇。但是仙童半导体公司并没有看到硅谷最强盛的一刻。业已故去的Jobs,将仙童半导体公司比喻为一颗成熟的蒲公英,你一吹它,这种创业精神的种子就随风四处飘扬了。陪伴着这些种子同时离去的是人才。这些陆续离去的人才击垮了这家伟大的公司,也创造了硅谷持续的辉煌。 从这时起,叛逆精神在硅谷生根发芽;从这时起,更多的年轻人意识到从车库里诞生的创意完全可以击垮貌似不可战胜的巨人;从这时起,在这片土地上可以诞生任何奇迹。来自全世界各个角落的资金疯狂涌入这片长不足32公里的大地。Intel,Apple,Oracle,Sun Microsystem,AMD,Yahoo等一系列公司先后诞生在这里,组成了上世纪下半叶一道最为炫丽的风景线。集成电路屹立在这道风景线之上。 1958年,Jack Kilby与Robert Noyce先后发明集成电路,Jack Kilby因此获得了2000年的Nobel物理奖。Robert Noyce于1990年故去,没有等到颁奖的这一天,但是他仅凭创建了Intel这一件事情,在半导体工业界的地位就几乎无人可敌。 在集成电路出现之后,更大规模集成电路的到来,通用处理器的横空出世只是时间问题。1965年Gordon Moore提出在一个集成电路上可容纳的晶体管数目,大约每隔24个月(1975年摩尔将24个月更改为18个月)增加一倍,性能提升一倍。摩尔定律指引并激励着一代又一代的工程师奋勇向前。 1971年,第一个微处理器4004在Intel诞生,随后是8008,8086,80286。很快微处理器席卷了整个天下。在上世纪八十年代中后期,Motorola 68K,MIPS,x86,SUN SPARC,Zilog Z80,联手上演了一场至今仍令人难以忘怀的微处理器大战。 在上世纪九十年代初,x86处理器在微处理器大战中胜出,中小型机逐步退出历史舞台,Intel却迎来了一场更大的危机。DEC(Digital Equipment Corporation)的Alpha处理器,AIM(Apple IBM Motorola)的PowerPC处理器,MIPS处理器和SUN UltraSPARC处理器组成了有史以来最强大的微处理器联盟,RISC联盟。Intel将要迎接来自这个联盟的挑战。当时的Intel在面对这个联盟时没有任何可以与之对抗的技术优势。事实上,RISC联盟的任何一只力量在处理器上的技术也领先于Intel。 面对这一切,昔日最坚定的盟友Microsoft开始动摇,公开宣称支持这个RISC联盟。Intel并没有动摇,至少Andy Grove没有动摇。对于Intel,退路只有万丈深渊。我喜欢那时那样的Intel。Andy Grove时代的Intel是一个连说“老子不会”都无比自信的Intel,是“老子除了技术不行,其他都行”的Intel。那时的Intel,乐子之无知,乐子之无思,乐子之独行。 几乎控制了Server市场全部份额的RISC联盟很快面对了一个几乎无解Chicken and Egg Question。Wintel联盟在不断前行的历程中,有如黑洞,疯狂般席卷着天下的应用。在整个PC世界中,几乎所有应用都已经基于x86这个并不完美的指令集。没有应用,RISC联盟无法进入PC世界去击败Intel,RISC联盟无法进入PC世界也就没有应用。面对这个难题,即便是Wintel联盟中一支的Microsoft亦无法化解。这是一种天然的力量。 RISC联盟只能在Server市场中苟存,看着Intel在不断地发展壮大,进入Server,然后战胜整个RISC联盟。面对这个由Chicken and Egg Question形成的天然力量,SUN没有办法,AIM也没有。处理器界的一代传奇DEC第一个倒下。当时的DEC在技术层面是如此强大。在DEC轰然倒塌后并不太长几年的时间内,投靠AMD的工程师先后开发出了K7和K8处理器。这两颗处理器依然可以给Intel带来灭顶之灾。 当一切成为往事,这段历史依然回味无穷。在PC领域,究竟是先有“Chicken”,还是先有“Egg”,Intel无法回答,Microsoft也无法。几乎所有Chicken and Egg Question都是如此简单,都可以用寥寥数语清晰地描述。我不太担心去解决那些需要三四天才能说清楚的问题,我总能在这些貌似复杂的过程中,找到最薄弱或者次薄弱环节,剩余部分将迎刃而解。世上最难解决的问题恰是用几句话就能够说明白,有如哥德巴赫猜想,有如费马大定律。 Chicken和Egg本是一对孪生兄弟,是在同一个时刻内降临于天地之间。初期并没有清晰的Chicken也没有清晰的Egg。Chicken和Egg是在无数次生物化学反应中水乳交融,多次反复后,在某个瞬间自然分解而成。 在Chicken和Egg的不断进化过程中,历经数不清的磨合和相互间的取长补短。Chicken和Egg最终成型后,几乎无法化解,或者说需要化解的力量要如此之大没有人愿意去化解。获胜方将逍遥于Chicken和Egg之间,挑战者将去面对着Chicken and Egg Dilemma。 Intel凭借来自PC领域的资金和Chicken and Egg的保护伞,学会了当年“老子不会”的所有知识,屹立于集成电路的浪潮之巅,执着捍卫着摩尔定律的正确,芯片制作工艺从65nm,45nm,32nm,22nm,14nm直到10nm。至今,天下半导体公司的合力在处理器制作技术上也无法与其抗衡。Intel更加明了制作工艺比拼的是金钱。金钱可以带来世上的绝大多数,却带不来真正的创新,并不为工艺上的领先欢欣鼓舞。在战胜RISC联盟之后长达十年的时间里,Intel所感受到更多的是来自浪潮之巅的寒意。曾经弱小到不能再弱小的ARM正在给Intel这个巨人制造一道或许难解的Chicken and Egg Question。 以ARM处理器为中心的半导体联盟完全控制了移动终端。在这个比PC领域更加宽广的舞台中,如今的Intel没有任何份额。Intel始终在反击。x86具有足够的性能优势,也有显而易见的劣势。事实上只要x86处理器还继续背着向前兼容(backward-compatibility)的包袱,无论使用什么样的工艺,与ARM都不会在同一个起跑线上竞争。 在2012年的CES,Intel展示了基于Atom SoC的Medfield手机,可以预期Intel在陆续的几年时间内,将推出几款功耗更低,性能更高的处理器。这并不意味着x86可以很容易地进入手持式市场。如果处理器技术可以决定一切,当年的Intel不可能战胜RISC联盟。在处理器领域之外,Intel一直在寻找新的盟友。Wintel联盟已是同床异梦。Windows 8将支持ARM平台,x86也选择了Android。或许ARM处理器进入PC领域只是时间问题,x86处理器进入手持式领域依然有许多问题需要解决。 Android与ARM的组合渐入佳境,几乎所有Android的应用都在某种程度上与ARM处理器有着千丝万缕的联系。运行在x86处理器之上的Android系统,几乎没有什么可以直接使用的应用程序。使用Binary Translation将基于ARM的应用程序移植到x86也许是一个不错的想法。这个想法并不新,RISC联盟当年用过这个方法。另外一条路艰辛许多,Intel可以将Android上使用频率较高的应用程序一个一个地移植到x86平台,只是这件事情究竟该如何做,由谁去做。Intel可以投资80亿美金去建设22nm工厂,却没有足够的能力和足够的财力完成这些移植。 应用匮乏将使x86-Based的手持式设备举步维艰;没有更多的厂商拥护x86-Based的手持式设备将使应用进一步匮乏。Intel在CES 2012上发布的手持式终端仅是投石问路,没有人可以预料最终结局。值得庆幸的是,或许Intel正在面对着的问题,并不是Chicken and Egg Question,这与RISC联盟曾经面对过的Chicken and Egg Question并不相同。 在手持互联领域,在这个年代或许依然存在着Chicken and Egg的故事,却不在传统的处理器和操作系统之中。也许与很多人估计的并不不同,Intel的实质对手并不是ARM,Intel即便战胜了ARM也很难破解在移动终端上所需要解决问题。 以应用为王为大前提的手持互联领域中,Intel甚至还没有起步,占据了移动处理器全部市场份额的ARM也并不算是Winner。在一个ARM SoC中,处理器微架构并没有占据统治地位。在手持式互联领域,ARM只能算作幕后英雄,真正的弄潮儿是Apple,Google和一些掌控着应用的公司。 ARM更似处理器的掘墓人。因为ARM的存在,处理器设计的门槛再不断降低。以前没有处理器设计经验的Qualcomm和Apple之类的公司可以顺利进军这个领域。在中国的珠海,一些制作ARM SoC厂商的制作能力与设计速度令人叹为观止,这已经使得欧美一些单纯制作ARM SoC的传统处理器厂商几乎寸步难行。 2012年这个世界将产出大约80亿个ARM SoC,远超过x86处理器的销售量。只有两千左右员工的ARM向Intel清晰地传达了一个事实,单纯的处理器设计并不需要动用十万员工。这并不是Intel真正需要面对的难题。Intel所需要战胜的并不是ARM。从某种意义上说,Intel与ARM非但不是对手,而是盟友。他们有着相同的称呼,处理器厂商。在不远的将来,他们将共同面对即将到来的,针对处理器的挑战。 这个挑战首先来自操作系统。操作系统已经完成三次大的革新。最初的处理器并没有操作系统,只有一些简单的批处理和任务排队功能。在中小型机中,UNIX和VMS操作系统的出现奠定了现代操作系统大的基调。PC的兴起极大促进了操作系统的发展,先后出现了CP/M和DOS以磁盘管理为中心的操作系统。这些操作系统的主要工作是管理基本的硬件信息,并为用户提供基础的字符界面。这些操作系统属于第一代操作系统。 第二代操作系统引入了图形界面,鼠标的发明极大降低了人机交互的难度。Apple和Microsoft的努力使得图形界面的深入人心。这是一个属于PC的辉煌时代。在这个时代,Intel和Microsoft在各自的领域并不是技术上的领跑者,却和而凝结出一种令所有对手望而生畏的气势。峰之所至,无坚不摧。 前两代操作系统以管理处理器硬件资源为核心。我们正在经历着第三代操作系统。iOS和Android的兴盛,促进了移动互联网的发展,以应用为中心的厂商依靠着这一代操作系统日益强大。这一代操作系统引入了Touch和Gesture等一系列辅助功能,但这不是这代操作系统最重要的特征。与前两代操作系统不同,第三代操作系统的重心不再是管理处理器系统提供的基础硬件;这一代操作系统不再是处理器微架构的衍生品;这一代操作系统是进一步服务于应用,硬件资源管理不再作为中心。 第三代操作系统也可以被称为应用操作系统,主体是服务于应用,不再是硬件资源的管理者。运行在这一代操作系统中的应用程序也在参与着硬件资源的管理,使用者已经不需要了解过多的处理器知识,不需要了解磁盘目录文件这些细节。七八岁的孩童,七八十岁的老人都可以熟练地操作着这些应用。 这些应用的出现,使得操作系统与处理器之间的紧耦合已经被打破。这个年代将很难出现,Wintel联盟因为x86与Windows水乳交融所形成的Chicken and Egg Question,也极大降低了ARM处理器进入PC领域,x86处理器进入手持互联领域的难度。这一代操作系统的出现使得通用处理器与传统操作系统已渐别这个时代的浪潮之巅。 处理器面临的第二个挑战源于自身发展的后继乏力。通用处理器的诞生是电子信息时代得以爆发式发展的基础,摩尔定律的持续正确为处理器的进一步发展插上翅膀。但是摩尔定律并不是摩尔真理,总有失效的一天。至今,这一天不再是离我们很近,而是已经到来。在Intel的Tick-Tock计划中,Tock已经越来越难引起更多人的关注,重要的是Tick。Tick的持续发展维护着摩尔定律的最后领地,却已很难改变摩尔定律的最终结局。 在处理器微架构中,流水线的设计已成往事。我很难相信x86指令流水线的执行效率能够明显超越ARM或者是MIPS,反之亦然。指令流水线性能的提高只剩下工程师在1/2,1/4个节拍中的精益求精,不存在质得飞跃。这使得本世纪初兴起了一场多处理器革命,使用更多的处理器提高整个处理器系统的执行速度。这场革命尚未步入高潮,就已经遭遇瓶颈。 很多人意识到同构多处理器系统很难提高并行度,从而转向异构多处理器系统,也进一步加大了处理器间总线互联的压力。在这样的系统中,互联总线的效率也决定了应用程序的执行效率。在多处理器系统中,需要首先解决的问题依然是进一步提高存储系统的带宽,并尽可能降低存储系统的延时。返璞归真,我们需要解决的问题依然在存储器子系统中。 在Intel每一次的Tock中,重大的技术革新集中于存储器子系统,引入了结构更加复杂,容量更加庞大的Cache Memory。Cache Memory系统不能提高运算类指令的执行效率,只是在以存储器为中心的处理器体系结构中,Cache Memory的效率决定了一个程序最终的执行效率。从体系结构层面上看,Cache Memory的设计方法已经趋于稳定,在整个科技界,即便在理论界,我也看不到哪怕是所谓的革新。 Intel在Cache Memory的领先源于工艺。制作工艺的领先使Intel可以在Cache Memory系统上花费更多资源。只要Intel的竞争对手没有在制作工艺上迎头赶上,就没有可能在Cache Memory子系统领域中更胜一筹,就没有可能在存储器子系统的设计中超过Intel。依靠着在Cache Memory中的优势,Intel屹立处理器领域之巅,所有竞争对手望尘莫及。在存储器子系统中大获全胜的Intel,赢得了Server,并没有赢得天下。 在比Server领域更加宽广的手持式领域中,所比拼的并不是存储器子系统,芸芸众生使用电子设备的主要目的不是用来算题或是为他人提供服务。即便仅考虑Server领域,Intel也正在面临着更多的挑战。存储器的瓶颈与功耗严重阻碍了处理器系统的进一步发展。存储器瓶颈的愈发严重,使得Server处理器需要更加庞大,更加复杂的Cache Memory系统与之匹配。使用这样的Cache Memory将使处理器系统的功耗持续上升。 存储器瓶颈与功耗已经成为Server处理器进一步发展的障碍。因为存储器瓶颈而增强存储器子系统,因为存储器子系统的增强,而进一步提高了功耗。从这种因果关系可以发现,似乎只要解决了存储器瓶颈问题其余问题便迎刃而解。 这个问题却很难解决,甚至可以说在以存储器为中心的冯诺依曼体系(Von Neumann Architecture)中,这个问题几乎无解。我们在试图解决这个问题,并在试图取得在某种意义上突破性的进展之前,需要重新讨论这个问题源自何方。 1945年6月30日,John von Neumann正式发表“First Draft of a Report on the EDVAC”,简称为First Draft,这个设计草稿令整个科学界欢欣鼓舞,第二年John von Neumann,Arthur Walter Burks与Herman Heine Goldstine一道进一步完善了First Draft,发表了另一篇题为“Preliminary discussion of the logical design of an electronic computing instrument”的论文。这两篇文章所阐述的内容被后人称为冯诺依曼体系。 在此之前,世上并没有处理器,只有一些可以执行固定任务的计算器,有进行简单加减乘除的计算器,求解微积分的计算器,求解倒数的计算器。在这个前冯诺依曼体系年代,科学家们为了进行新的科学计算,需要设计一款新型的定制计算器,需要重新搭建电子设备。冯诺依曼体系改变了这一切,建立了计算机体系结构中最重要的组成原理,影响至今。冯诺依曼体系第一次引入了Store-Program计算理论,确定了一个计算机的五大组成部分,包括Arithmetic Logic Unit,Processor Registers,Control Unit(包括IR和PC),用于存储指令和数据的Memory和输入输出设备。 在这种体系中,计算机将按照程序规定的顺序,将指令从存储器中取出并逐条执行。在程序和数据中使用二进制表示方法,当一个计算课题发生变化后,只需要更改Memory中的程序,而不需要重新设计一款新的计算器。 冯诺依曼体系极大化解了此前在计算器设计中的冗余,可以将世上的绝大多数应用规约于一个统一模型,奠定了现代计算机体系结构的基础。计算机的历史揭开了新的一页。这套体系诞生至今,在计算机体系结构中始终占据着主导地位。在计算机体系结构持续发展的几十年时间以来,没有任何理论能将其颠覆,更多的只是在冯诺依曼体系之上的修修补补。 大规模集成电路的出现为冯诺依曼体系插上翅膀。基于这个体系的通用处理器最终成为可能。Intel与其他处理器厂商一道上演了通用处理器的传奇。摩尔定律的持续正确使得处理器迅猛发展,处理器变得愈发强大,愈发廉价。通用处理器席卷了天下应用。通用处理器的大规模推广与普及也奠定了当今电子信息领域的基础。 Von Neumann Architecture并不完美,在这种以存储器为中心的体系结构中,存储器必然成为瓶颈,这一瓶颈也被称为Von Neumann瓶颈。这一瓶颈伴随着冯诺依曼体系的出现而出现,目前尚无有效的方法消除。Cache Memory的出现极大缓解了Von Neumann瓶颈,随后出现的Modified Harvard Architecture,Branch Predictor和NUMA体系结构进一步缓解了这个瓶颈。但是这种量的积累并没有引发质变。冯诺依曼体系并没有因此升华,直到今日存储器瓶颈依然存在,而且愈演愈烈。 在今天的Server领域,几乎所有应用都有一个相同的运行轨迹。I/O设备首先将数据发送到存储器子系统,处理器对数据进行处理后再交还于存储器子系统,I/O设备再从存储器子系统中获取数据,之后再做进一步的处理。在这种模型中,每进行一次运算,需要多次访问存储器子系统。存储器子系统必然成为瓶颈,使用再多的处理器也不能解决这些问题。 首先是作为数学家与物理学家的John von Neumann,从事计算机科学的出发点,是进行科学计算,他没有预料到二十一世纪的今天,有这样不学无术的一群人在这样地使用计算机。在我们所处的这个时代,通用处理器的主要功能早已不是在进行风花雪月的数学计算。 通用处理器在一路前行的道路上,席卷天下,应用边界在不断的扩张。我们可以使用处理器进行文字数据,数据挖掘,上网聊天,打游戏。在今天使用处理器的人群中,用其进行科学运算的屈指可数。为了专门算题买台PC或者Server的人,我一个也没有见过。 今天的处理器如此科技,如此廉价,已被视作电子信息领域高科技的象征。这导致天下人对通用处理器的盲从,导致了通用处理器能够更加顺利地席卷着天下应用。众多应用的叠加,使得处理器遭遇了前所未有的存储器瓶颈问题。可以预见,只要通用处理器继续吸纳着更多的应用,存储器瓶颈只能更加严重,功耗将持续上升。 问题是我们为什么要用通用处理器解决所有问题。通用处理器可以解决很多问题,但在这个世界上,许多问题的解决根本不需要使用通用处理器。冯诺依曼体系的提出是针对当时电子设备高度定制化所产生的浪费,至今已时过境迁。在冯诺依曼体系之下,即便是即便是验证i加j确实等于2的问题,也需要将程序与数据输入到处理器,需要各种算术逻辑,数据传送单元的共同参与,经过了诸多操作后,获得最终结果。 如果仅是为了验证i加j确实等于2的问题,倘若使用定制逻辑,只需要使用一个加法器和一个比较器,并不需要通用处理器。但是在摩尔定律持续正确的年代,处理器持续着廉价。在多数应用场景中,使用通用处理器依然最为有效。即便是一些扭曲身形去迎合通用处理器的应用,也因为通用处理器的飞速进展,获得了事实上的最优。在摩尔定律持续正确的年代,绝大多数采用定制逻辑而违背冯诺依曼体系的处理机制没有获得成功。 顺势而为是取得一定程度的成功的保障。在许多情况之下,即便你明知99%以上的人选择了一条弯路,依然需要这种顺势而为。因为这99%的合力就算是在走一条事实上的弯路,也远快过独自一人走真正的捷径,也更容易到达终点。 时过境迁,种种迹象表明摩尔定律不再正确。这意味着在面积大小一定的Die中将无法容纳更多的晶体管。使用通用处理器,无论是同构或者异构模型,在解决某类应用时,已经不再是最优方案,甚至不是次优方案。 通用处理器在一路前行的道路,是与存储器瓶颈不断斗争的历史。从冯诺依曼体系诞生至今,通用处理器所面临的主要问题依然是存储器的延时与带宽。在一个通用处理器中,存储器子系统占据了绝大多数资源。在一个通用处理器中,如果去除L1,L2等诸多层次的Cache子系统,去除指令流水线中为了减轻存储器瓶颈的各种预测机制和MMU后,所剩无几。如今的通用处理器更是将主要的资源放在道路建设上,并没有专注于应用问题的解决。 这种并不专注同时也意味着巨大的浪费,与John von Neumann的初衷不再吻合。John von Neumann所设计的体系是基于当时的认知,为了避免定制逻辑所造成的浪费。至今通用处理器本身已经成为最大的定制逻辑,在这个定制逻辑中,所关注的主要问题是如何修路,很多情况下是为了修路而修路,以容纳更多的应用,即便有很多应用根本不需要这条路,也不需要依照冯诺依曼体系的要求去执行。 在这种趋势下,存储器瓶颈将持续存在,持续恶化。我们正在经历着一个以应用为中心的时代。不同的应用对处理器系统有着不同的需求。这使得定制化与差异化重回议程。在一个通用处理器中,正在容纳更多的定制逻辑,正在容纳更多的加速模块。这些变化使得所谓的通用处理器并不再是绝对意义上的通用。 ARM这个比Intel弱小得多的企业,依靠着并不领先的技术取得如今的成就,我认为最主要的原因是ARM为其他厂商的差异化与定制化提供了便利条件。电子信息领域经历了Mainframe Era,PC Era,Internet Era,而至Mobile Era时代。在这个名为Mobile的Era中, ARM身后隐藏的定制化与差异化已经成为Mobile的时代主题。 作为公司的ARM距离Intel还有相当长的一段距离,但是作为一个行业的ARM已经取得事实上的领先。从这个角度上说,不是ARM在手持互联领域中暂时领先与Intel,而是在Mobile Era的时代,定制化与差异化在与通用化的较量中获得了先机。 对定制化与差异化的最大挑战是IC设计领域中客观需要的规模效应。定制化与差异化的思路与此背道而驰。Intel使用单一产品覆盖绝大多数的应用,产生了规模效应,实现了利润最大化,Gross Margin超过60%。采用ARM的定制化与差异化方案的任何公司都无法获得这样的Gross Margin。在Mobile Era中,手持处理器厂商呈百花齐放格局;在Mobile Era中,各式应用的不同要求使得相关的处理器进一步差异化。 单个厂商获得60%以上的Gross Margin正在成为过去。Intel维持高额的Gross Margin主要依靠的是Mobile Era的Server领域。Intel的Mainframe处理器首先是针对Server的一种定制化,之后将这种设计简化到PC领域,以获得最大的规模化效应。Intel从Nehalem开始的Tock过程,事实上是一个针对Server的定制过程。今天的Intel已经不是凭借着PC的占有率去攻占Server,而是凭借着Mobile Era对Server的需求,维护着在PC领域中的地位。 在手持式领域,Intel的Medfield仅是一次尝试,并不会给ARM的Cortex系列处理器带来质的挑战。整个业界窒息般等待着的是Intel在Atom处理器中的Tock-Tick,Silvermont和Airmont。Tick-Tock计划在Atom处理器中的引入转达着Intel对在手持式领域中,所遭受的一个接着一个失败的愤怒。认真起来的Intel在处理器领域依然无敌,从纯技术的角度上看,如果Intel的竞争对手在芯片的制作工艺上没有出现大的突破,那么Intel出现功耗性能比超越世上任何一个ARM SoC处理器只是时间问题。ARM阵营将对此没有任何办法。 只是决定一个手持式处理器最终成败的并非是处理器微架构的性能功耗比,购买手持式产品的最终用户有几人能够理解处理器微架构。处理器微架构之外的音视频效果,互联网体验,设备提供商是否足够的Fashionable更能够吸引他们的眼球。 在手持互联领域中,处理器进一步的定制化已经成为事实。在手持式处理器中,已经含有各类音视频加速引擎。在一些基于Web的应用中,正在使用一些专用加速引擎去解析HTML,去解析Javascript。在这个领域中,通用处理器正在为定制化预留空间,在未来的几年内,将会出现更多的加速引擎,进一步减轻处理器的负担。 如果Intel将芯片制作工艺上的优势仅仅转化为处理器的性能功耗比,依然以处理器微架构为中心,所取得的成就将十分有限。我更期待在未来的几年内,Intel能够将工艺领先而获得的额外资源用于定制与差异化逻辑,淡化处理器微架构在系统中的位置,进而为定制化和差异化提供空间。若仅在技术层面考虑,这将是其他处理器厂商的噩梦。 问题是如何为手持式领域进行定制化与差异化。在手持互联领域中存在两类公司,一类是Apple与Samsung,另一类是山寨。我不得不承认,这些生产手持设备的厂商合在一起也不如Intel更懂硅芯片的制造,但是几乎任何一家都比Intel更加理解芸芸众生为什么要买一个手持产品,也更加理解如何针对这些产品进行深度的定制化与差异化。 定制化与差异化也同时决定着,即便Intel能够在技术层面上完全领先也无法取得其在PC领域中的地位,也因此无法获得足够高的Gross Margin。这些现状将会使Intel这个具有十万员工的公司,在没有一个Andy Grove般强势有力的领袖时,很难在内部形成有效的合力。Intel在手持互联处理器中的艰难在很大程度上是颛臾之忧。 在技术层面之外,第一类手持设备厂商Apple与Samsung在为最终用户提供各类产品的同时,还生产用于手持式设备的处理器。在这个手持处理器这个领域,Intel要与这些既是运动员又是裁判员的第一类厂商竞争,并不公平。这些内外之扰,决定了Intel即便在三年后制作出在技术层面超过Qualcomm的处理器,也并没有丝毫办法把握能够主导这个市场。 在手持式领域中,也许依然存在着Chicken或者Egg,但是单纯的处理器或者操作系统将不再是Chicken也不再是Egg。在Server,或者是其他Embedded领域,大量出现的定制与差异化逻辑已经使得处理器微架构在一个系统中逐步偏离设计中心。 这些定制化与差异化的大规模出现,是因为许多人已经意识到有些应用并不适合处理器去解决,摩尔定律的事实结束使得通用处理器的效率无法继续获得线性加速比。很多人意识到我们似乎重新回到前冯诺依曼体系时代,那个只有差异与定制的时代。 这些变化并不意味着处理器会消亡,只是处理器不会在继续通用化的道路上顺利向前,并不会作为绝对的中心。将有更多的应用将按照自己的特点使用定制逻辑,不再是交由处理器。这将进一步化解存储器的瓶颈,进一步的降低功耗。这些变化将使我们迎来一个新的时代,一个属于定制化与差异化的时代。 从技术的角度上看,定制化与差异化是消减存储器瓶颈的有效手段。在Server或者是其他领域,如果一个应用的90%以上工作可以交予定制逻辑,剩余的10%再交予处理器,以目前的半导体技术,存储器将不再是瓶颈,处理器系统的功耗也将随之降低。 但我认为这并不是定制化的主要方向,定制化逻辑并不一定要隶属于处理器。在未来,定制逻辑之间,带有智能功能的外部设备间可以直接交互信息而不必通过处理器。在这些智能设备中可以含有冯诺依曼体系的处理器,也可以没有。 在数据中心的应用中,如果智能网卡可以通过与智能盘卡之间的直接交互,而不是全部通过通用处理器,我们将可以不再使用机器人去维护这样的系统,也不需要使用专门的电力通路。这种设备的运行有如人体,肢体器官间存在着更多的下意识行为和更加自然的操作,不必全部由大脑指挥。 我没有理论与数据验证这一结论,只是自觉告诉我这种智能设备将很快出现,将有更多的应用远离通用处理器系统。在可以预见的将来,各类定制化与差异化应用将继续着劈波斩浪。这是一个年轻人可以持续着向广袤神秘的未知领域挑战,是一个可以持续着带来新希望的大应用时代。在摩尔定律即将且正在结束的时代,定制化与差异化的时代窗口将再次开启。只是这一次,我们不知道何时还能再有冯诺依曼。 | |
  (37个打分, 平均:4.73 / 5) (37个打分, 平均:4.73 / 5) |
单芯片的云计算:Intel . 众核 . KnightCorner . 50+ Core . 22nm
作者 陈怀临 | 2011-12-05 21:00 | 类型 专题分析, 芯片技术, 行业动感 | 9条用户评论 »
|
单芯片, 50+ x86+SIMD extension的核,22nm工艺;计算能力为1 Teraflop。不知Tilera的同学们如何想。当然,KnightCorner的市场方向主要还是SuperComputing或者HPC。单芯片的高性能计算。太可怕了。。。 关于Intel这方面项目的背景可以参阅:Intel MIC(Intel Many Integrated Core Architecture)。
| |
|
(1个打分, 平均:5.00 / 5) |


NVIDIA . Tegra3(Kal-El) . 4+1 Cores .vSMP
作者 陈怀临 | 2011-12-04 13:47 | 类型 专题分析, 芯片技术, 行业动感 | 8条用户评论 »
|
ARM的Big-Little Computing的意思是大流氓(Cortex-A15)带着小跟班(Cortex-A7)一起玩为了省电的非对称作战。NVIDIA方面在其Tegra3上也整了个4+1的“非对称的SMP计算”[Variable Symmetric Multiprocessing (vSMP)](还整了个专利。可见专利或者文章有多恶心)。但与ARM的Big-Little最大区别是:大家都是一样的流氓-Cortex-A9。Tegra3啥意思呢: 5个都是40nm的Cortex-A9。其中一个(叫做援交芯片[companion core]是通过40nm的Lower-Power工艺做的silicon[500MHz then]。其他4个Cortex-A9是40nm的标准工艺,可以是1.4GHz/1.3GHz. 换言之,5个哥们,其中4个可以高负荷的工作,生命的燃烧当然比较厉害;比较耗电。其中一个比较enjoy life一点;工作频率慢一倍。。。 在与ARM的Big-Little Computing的体系结构比较的时候,要注意: Cortex-A7可以运行在1GHz下。还是很快滴 Tegra 3 (Kal-El) series
The Tegra 3 is functionally a quad-core processor, but includes a fifth “companion” core. All cores are Cortex-A9s, but the companion core is manufactured with a special low power silicon process. This means it uses less power at low clock rates, but more at higher rates; hence it is limited to 500 MHz. There is also special logic to allow running state to be quickly transferred between the companion core and one of the normal cores. The goal is for a mobile phone or tablet to be able to power down all the normal cores and run on only the companion core, using comparatively little power, during standby mode or when otherwise using little CPU. According to Nvidia, this includes playing music or even video content. 下面是NVIDIA的两个非常好的White Paper。对其vSMP结构有比较完整的描述。 | |
 (没有打分) (没有打分) |



ARM的三大家族阶级成分和相应的富(穷)N代 分类。
作者 陈怀临 | 2011-12-03 13:07 | 类型 专题分析, 芯片技术, 行业动感 | 4条用户评论 »


big.LITTLE Computing 。 Cortex A7 。Cortex A15
作者 陈怀临 | 2011-12-03 11:52 | 类型 专题分析, 芯片技术, 行业动感, 通讯产品 | 11条用户评论 »




Cache一致性协议与MESI(2)
作者 muxiqingyang009 | 2011-07-11 16:58 | 类型 科技普及, 芯片技术 | 11条用户评论 »
|
Write invalidate提供了实现Cache一致性的简单思想,处理器上会有一套完整的协议,来保证Cache一致性。比较经典的Cache一致性协议当属MESI协议,奔腾处理器有使用它,很多其他的处理器都是使用它的变种。 单核处理器Cache中每个Cache line有2个标志:dirty和valid标志,它们很好的描述了Cache和Memory(内存)之间的数据关系(数据是否有效,数据是否被修改),而在多核处理器中,多个核会共享一些数据,MESI协议就包含了描述共享的状态。 在MESI协议中,每个Cache line有4个状态,可用2个bit表示,它们分别是:
MESI状态 M(Modified)和E(Exclusive)状态的Cache line,数据是独有的,不同点在于M状态的数据是dirty的(和内存的不一致),E状态的数据是clean的(和内存的一致)。 S(Shared)状态的Cache line,数据和其他的Cache共享。只有clean的数据才能被多个Cache共享。 I(Invalid)表示这个Cache line无效。 E状态示例如下:
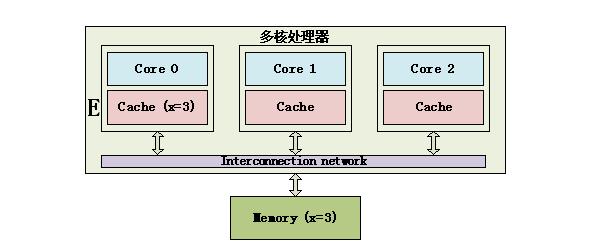
E状态 只有Core 0访问变量x,它的Cache line状态为E(Exclusive)。 S状态示例如下:
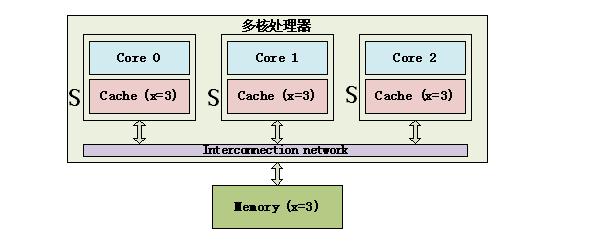
S状态 3个Core都访问变量x,它们对应的Cache line为S(Shared)状态。 M状态和I状态示例如下:
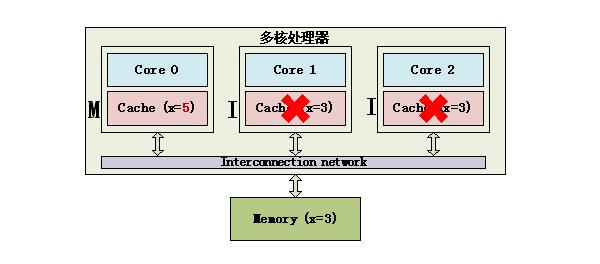
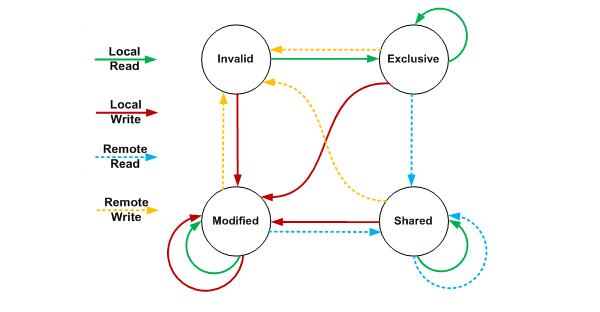
M状态和I状态 Core 0修改了x的值之后,这个Cache line变成了M(Modified)状态,其他Core对应的Cache line变成了I(Invalid)状态。 MESI协议状态迁移图如下:
MESI协议状态迁移图 在上图中,Local Read表示本内核读本Cache中的值,Local Write表示本内核写本Cache中的值,Remote Read表示其它内核读其它Cache中的值,Remote Write表示其它内核写其它Cache中的值,箭头表示本Cache line状态的迁移,环形箭头表示状态不变。 MESI状态之间的迁移过程如下:
MESI状态迁移 AMD的Opteron处理器使用从MESI中演化出的MOSEI协议,O(Owned)是MESI中S和M的一个合体,表示本Cache line被修改,和内存中的数据不一致,不过其它的核可以有这份数据的拷贝,状态为S。 Intel的core i7处理器使用从MESI中演化出的MSEIF协议,F(Forward)从Share中演化而来,一个Cache line如果是Forward状态,它可以把数据直接传给其它内核的Cache,而Share则不能。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
(3个打分, 平均:5.00 / 5) |
Cache一致性与2种基本写策略(1)
作者 muxiqingyang009 | 2011-07-07 21:26 | 类型 科技普及, 芯片技术 | 12条用户评论 »
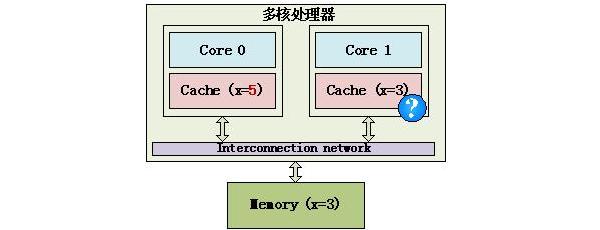
[陈怀临注:很高兴这位同学写这方面的文章。而且还自己标注“弯曲推荐”,which被我拿掉了。老天,你也太自信了:-)。弯曲评论上藏龙卧虎,您老上来就把科普文章整成弯曲推荐。。。:-)。鼓励一下。Cache的东西要写好,不容易,不要到时收不了笔呦。。。透露一下,王齐大侠在写一个传世佳品。很快会出台。。。](1) 一致性问题的产生——信息不对称导致的问题现实生活中常常会出现因为沟通不畅而导致的扯皮,一方改了某些东西,又没有及时通知到另一方,导致两方掌握的信息不一致,这就是一致性问题。 多核处理器也有这样的问题,在下面这个简单的多核处理器示例中,内存中有一个数据x,它的值为3,它被缓存到Core 0和Core 1中,不过Core 0将x改为5,如果Core 1不知道x已经被修改了,还在使用旧的值,就会导致程序出错,这就是Cache的不一致。
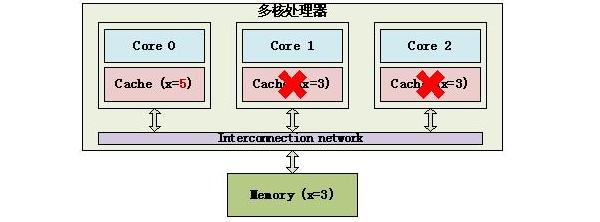
Cache的不一致示例 (2) Cache一致性的底层操纵为了保证Cache的一致性,处理器提供了2个保证Cache一致性的底层操作:Write invalidate和Write update。 Write invalidate(置无效):当一个内核修改了一份数据,其他内核上如果有这份数据的拷贝,就置成无效(invalid)。 下面这个例子中,3个Core都使用了内存中的变量x,Core 0将它修改为5,其他Core就将自己对应的Cache line置成无效(invalid)。
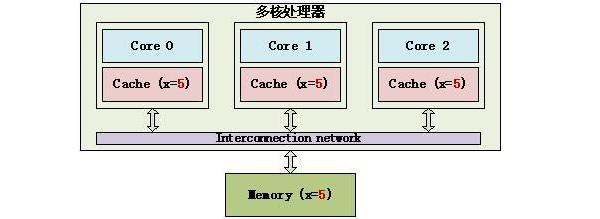
Write invalidate示例 Write update(写更新):当一个内核修改了一份数据,其他地方如果有这份数据的拷贝,就都更新到最新值。Write update示例如下:
Write update示例 Write invalidate和Write update比较:Write invalidate是一种很简单的方式,不需要更新数据,如果Core 1和Core 2以后不再使用变量x,这时候采用Write invalidate就非常有效。不过由于一个valid标志对应一个Cache line,将valid标志置成invalid后,这个Cache line中其他的本来有效的数据也不能被使用了。Write update策略会产生大量的数据更新操作,不过只用更新修改的数据,如果Core 1和Core 2会使用变量x,那么Write update就比较有效。由于Write invalidate简单,大多数处理器都使用Write invalidate策略。 | |
|
(2个打分, 平均:5.00 / 5) |
浅谈高端CPU Cache Page-Coloring(全)
作者 陈怀临 | 2011-06-20 18:49 | 类型 科技普及, 芯片技术 | 34条用户评论 »

内存控制器与内存通道问题
作者 kunzhang3510 | 2011-06-02 20:51 | 类型 专题分析, 科技普及, 芯片技术 | 9条用户评论 »
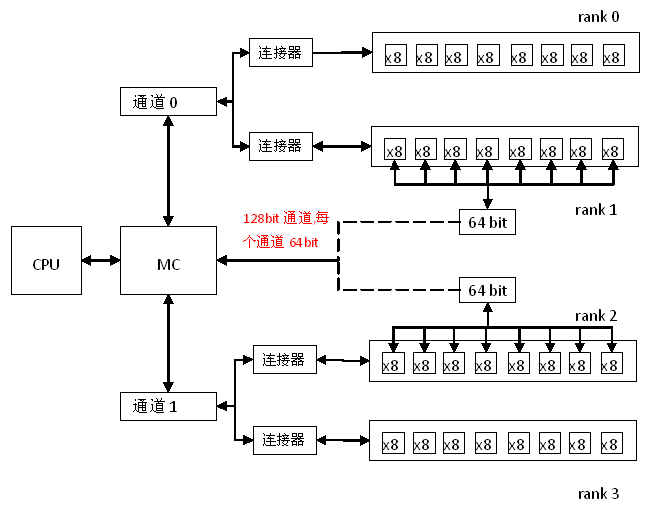
内存通道问题
内存系统结构图
通道,rank和内存地址
| |
|
(6个打分, 平均:3.83 / 5) |