计算与存储重新合体?三统理论?真正的统一存储?
作者 冬瓜头 | 2011-01-01 16:20 | 类型 云计算, 新兴技术, 研发动态, 行业动感 | 21条用户评论 »
|
存储和计算结合之后,是什么样的产品形态啊?计算,存储,都很牛叉的机器? | |
 (1个打分, 平均:5.00 / 5) (1个打分, 平均:5.00 / 5) |


Open vSwitch – 开放虚拟交换标准
作者 yeasy | 2010-12-20 19:34 | 类型 互联网, 新兴技术 | 12条用户评论 »
系列目录 Future Internet Technology
从虚拟机到虚拟交换 提到虚拟化,大家第一印象往往是虚拟机(Virtual Machine),VMware、Virtualbox,这些大名鼎鼎的虚拟机软件不少人都耳熟能详。对企业用户来说,虚拟技术最直接的好处是通过灵活配置资源、程序来高资源的利用率,从而降低应用成本。近些年,随着虚拟化技术、交换技术以及云计算服务的发展,虚拟交换(Virtual Switch)已经越来越多的引起人们的关注。 顾名思义,虚拟交换就是利用虚拟平台,通过软件的方式形成交换机部件。跟传统的物理交换机相比,虚拟交换机同样具备众多优点,一是配置更加灵活。一台普通的服务器可以配置出数十台甚至上百台虚拟交换机,且端口数目可以灵活选择。例如,VMware的ESX一台服务器可以仿真出248台虚拟交换机,且每台交换机预设虚拟端口即可达56个;二是成本更加低廉,通过虚拟交换往往可以获得昂贵的普通交换机才能达到的性能,例如微软的Hyper-V平台,虚拟机与虚拟交换机之间的联机速度轻易可达10Gbps。 虚拟交换与Open vSwitch 2008年底,思科发布了针对VMWare的Nexus 1000V虚拟交换机,一时之间在业界掀起不小的风头,并被评为当年虚拟世界大会的最佳新产品。或许思科已经习惯了“群星捧月”,此后很长一段时间里并没有见到正式的虚拟交换标准形成。除了惠普一年多以后提出了VEPA(虚拟以太网端口聚合器),其他厂家关注的多,做事的少。随着云计算跟虚拟技术的紧密融合,以及云安全的角度考虑,技术市场曲线已经到了拐点,业界已经迫切需要一套开放的VS标准,众多门派蠢蠢欲动。 烽烟即燃之际,Open vSwitch横空出世,以开源技术作为基础(遵循Apache2.0许可),由Nicira Networks开发,主要实现代码为可移植的C代码。它的诞生从一开始就得到了虚拟界大佬——Citrix System的关注。可能有读者对Citrix不熟,但说到Xen恐怕就是妇孺皆知了,没错,Citrix正是Xen的东家。OVS在2010年5月才发布1.0版本。而早在1月初Citrix就在其最新版本的开放云平台(ref[2])中宣布将Open vSwitch作为其默认组件,并在XenServer5.6 FP1中集成,作为其商用的Xen管理器(hypervisor)。除了Xen、Xen Cloud Platform、XenServer之外,支持的其他虚拟平台包括 KVM、VirtualBox等。 OVS官方的定位是要做一个产品级质量的多层虚拟交换机,通过支持可编程扩展来实现大规模的网络自动化。设计目标是方便管理和配置虚拟机网络,检测多物理主机在动态虚拟环境中的流量情况。针对这一目标,OVS具备很强的灵活性。可以在管理程序中作为软件switch运行,也可以直接部署到硬件设备上作为控制层。同时在Linux上支持内核态(性能高)、用户态(灵活)。此外OVS还支持多种标准的管理接口,如Netlow、sFlow、RSPAN,、ERSPAN, 、CLI。对于其他的虚拟交换机设备如VMware的vNetwork分布式交换机跟思科Nexus 1000V虚拟交换机等它也提供了较好的支持。 目前OVS的官方版本为1.1.0pre2,主要特性包括
OVS获取 由于是开源项目,代码获取十分简单,最新代码可以利用git从官方网站下载。此外官方网站还提供了比较清晰的文档资料和应用例程,其部署十分轻松。当前最新代码包主要包括以下模块和特性:
此外,OVS也提供了支持OpenFlow的特性实现,包括
结语 IT领域可以称得上是人类历史上最开放创新,也是最容易垄断的行业。PC行业,wintel帝国曾塑造了不朽的神话,证明谁控制了cpu跟os,谁就控制了话语权,只要PC的软硬件模式不发生革命性变化,wintel帝国的地位将是无人能撼的。后起之秀ARM借助重视能耗的东风,再加上智能终端技术的大发展才展露头角。而在互联网界,思科更是首先把握住了最核心的交换市场,早早登上至尊之位,即使是步后尘的juniper、huawei也只能是虎口夺食,各凭绝技分天下。现在虚拟交换技术的提出将给这一领域带来新的契机,究竟鹿死谁手,更待后人评说。 参考: <1> http://openvswitch.org/ <2> http://xen.org/products/cloudxen.html | |
 (5个打分, 平均:4.20 / 5) (5个打分, 平均:4.20 / 5) |
Google图算法引擎Pregel介绍
作者 Huiwei | 2010-12-03 18:33 | 类型 云计算, 学术园地, 新兴技术 | 2条用户评论 »
|
【前言:有一种说法[1]是Google的程序里面80%用的是MapReduce,20%用的是Pregel。今天就来介绍一下这个Pregel。想要深入研究的同志们,可以参考最新的SIGMOD 2010 ppt[2]。】 简介 Pregel是一个用于分布式图计算的计算框架,主要用于图遍历(BFS)、最短路径(SSSP)、PageRank计算等等。共享内存的运行库有很多,但是对于google来说,一台机器早已经放不下需要计算的数据了,所以需要分布式的这样一个计算环境。没有Pregel之前,你可以选择用MapReduce来做,但是效率很低;你也可以用已有的并行图算法库Parallel BGL或者CGMgraph来做,但是这两者又没有容错。所以google就自己开发了这个新的计算框架。 (八卦一下:Pregel的名字来历很有意思。是为了纪念欧拉的七桥问题[7],七座桥就位于Pregel这条河上。) 核心概念 从高层次看,Pregel是BSP[8]模型,就是“计算”-“通信”-“同步”的模式,参看图1。
 图1: BSP Model 在Pregel中,以节点为中心计算。Step 0时每节点都活动着,每个节点主动“给停止投票”进入不活动状态。如果接收到消息,则激活。没有活动节点和消息时,整个算法结束。 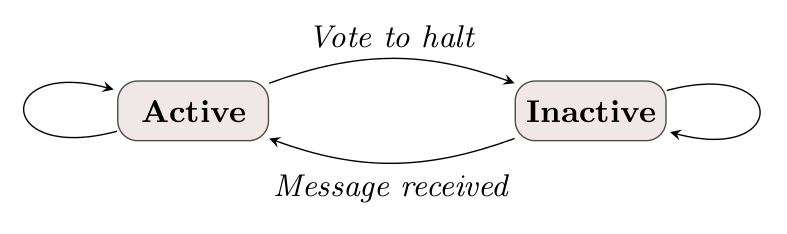 图2: Vetex State Machine(参考2) 容错是通过检查点来做的。在每个超步开始的时候,对主从节点分别备份。 核心的概念就是这些,其他还有一些消息聚集(combiner)等优化。有兴趣可以看看Lixiang的阅读笔记[6]和Pregel Slides[2]。 类似开源实现 人人都喜欢免费。跟Pregel最像的是Hama[5],也是基于BSP,但是,开源的Hama还未成气候。笔者原来打算拿它来做些实验,结果还不能运行。 国内似乎还没有类似Pregel的计算引擎,不知道百度和淘宝这些公司有没有需求。淘宝最近9月份开源了他们的文件系统TFS[3][4],很敬仰。不知道上面的运行环境是不是在开发中。大宋的开源软件也要有自己的创新,不能老是拿老外的改改就用了。 参考资料 1. Pregel: Google’s other data-processing infrastructure, http://www.royans.net/arch/pregel-googles-other-data-processing-infrastructure/ 2. Pregel: A System for Large-Scale Graph Processing, SIGMOD 2010的ppt, http://www.slideshare.net/shatteredNirvana/pregel-a-system-for-largescale-graph-processing 3. 淘宝文件系统TFS开源代码,http://code.taobao.org/project/view/366/ 4. 淘宝文件系统TFS介绍,http://rdc.taobao.com/blog/cs/?p=128 5. Hama homepage, http://incubator.apache.org/hama/ 6. 论文阅读笔记:Google的图模型分布式计算框架Pregel 7. Seven Bridges of Königsberg, http://en.wikipedia.org/wiki/Seven_Bridges_of_K%C3%B6nigsberg | |
|
(1个打分, 平均:5.00 / 5) |
OpenFlow – 打造弹性化的可控互联网
作者 yeasy | 2010-11-07 15:28 | 类型 互联网, 新兴技术 | 25条用户评论 »
系列目录 Future Internet Technology
OpenFlow – 打造弹性化的可控互联网 2012的故事 2012年的某天,你跟往常一样起床,打开电脑,却发现无法登录到邮箱、无法连接到公司的VPN网络、无法订购任何东西……,你会发现一切都简直跟世界末日一样,离开了网络,现代社会根本无法正常运行。这并不是可笑的无根据的幻想,如果世界末日真的来临,摧毁互联网无疑是最直接有效的办法,而现代互联网并没有我们想象的那样鲁棒。 从上个世纪70年代初,互联网在短短不到40年时间里已经发展成为这个星球上不可或缺的基础设施。然而由于一开始的设计并没有考虑到后来互联网的规模会如此庞大、承载的应用会如此复杂、地位会变得如此重要,现代的互联网在过重的压力下已经凸显出太多亟待解决的问题。互联网太危险,恶意攻击、病毒、木马每年造成上千亿刀的损失;互联网太脆弱,无标度(Scale-free)的特性让整个网络可以在精心设计的少数攻击下即告崩溃;互联网太随意,p2p等应用的出现一度造成各大ISP网络堵塞,严重影响传统正常的访问;互联网太迟钝,现代臃肿的路由机制不能支持快速的更新,即便发现问题也无法快速反应;互联网太局促,IPv4的分配地址已经捉襟见肘…… 这一切的问题都隐隐的指向了互联网这个庞然大物最关键的软肋——可控性。缺乏有效的控制措施让互联网这个为服务人类而设计的机器,正在逐渐演变成一头臃肿而暴躁的凶兽,挣扎着要摆脱人类所施加的脆弱枷锁。 下一代互联网和GENI 为了解决当前互联网的问题,不少国家都纷纷提出了下一代互联网计划,代表性计划有美国的FIND(Future Internet Network Design,未来互联网网络设计)和GENI (Global Environment for Network Innovations,全球网络创新环境),欧洲的FIRE (Future Internet Research and Experimentation,未来互联网研究和实验),中国的CNGI-CERNET(China Next Generation Internet)。所有这些计划参与者大都是各个国家产、学、研顶尖的机构。 这三大计划中,CNGI-CERNET主要是研究在IPv6体系下的新一代网络;而NSF支持的FIND计划计划在不受当前互联网的制约下提出未来互联网的需求,从2006年到2014年分三个阶段主要致力于五个问题:是否继续采用分组交换、是否要改变端对端原理、是否要分开路由和包转发、拥塞控制跟资源管理、身份认证和路由问题。FIND计划最主要的成果之一就是GENI——一套网络研究的基础平台,同时FIRE计划跟GENI项目合作也非常密切。GENI计划的两大任务是为最前沿的网络科学工程领域革命性研究开路;刺激和促进重大社会经济影响的奠基性创新的出现;围绕这两大任务,GENI致力于打造下一代互联网的虚拟实验室,为研究者提供验证创新的架构、协议的灵活、可扩展、可配置的实验平台,并促进学术界和业界的相互合作。长期以来,缺乏合适的实验平台让各界的专家学者们伤透了脑筋,PlanetLab的种种局限已经不能满足广大researcher越来越令人fz的需求了。 毫无疑问,GENI的目标将让每个网络研究者为之着迷和激动,一套完全可控、可定制、大规模的网络试验床,对学术界将意味着大批的顶级paper,对业界意味着大量的新标准、新协议。 OpenFlow的前世今生 GENI的好处虽多,但要部署这个平台无疑是一件太过昂贵的事情,于是一个自然的事情就是在目前现有的网络下,能否省时省力的干好这个事情? 很自然的想法,如果我能控制整个Internet就好了,而网络中最关键的节点就是交换设备。控制了交换设备就如同控制了城市交通系统中的红绿灯一样,所有的流量就可以乖乖听话,为我所用。然而现代的交换设备被几家巨头垄断,开放的接口十分有限,能做的事情也十分有限。如果能有一套开放接口、支持控制的交换标准该多好?OpenFlow应运而生。 最初的想法其实十分简单,无论是交换机还是路由器,最核心的信息都存放在所谓的flow table里面,用来实现各种各样的功能,诸如转发、统计、过滤等。flow table结构的设计很大程度上体现了各个厂家的独特风格。OpenFlow就是试图提出这样一个通用的flow table设计,能够满足大家不同的需求,同时这个flow table支持远程的访问和控制,从而达到控制流量的目的。具体来说,OpenFlow的flow table中每一个entry支持3个部分:规则,操作跟状态。规则无非是用来定义flow,OpenFlow里flow定义十分宽泛,支持10个域(除了传统的7元组之外增加了交换端口、 以太网类型、Vlan ID);操作就是转发、丢弃等行为,状态部分则是主要用来做流量的统计。在此基础上最关键的特性就是支持远端的控制,试想,如果我要改变entry就必须跑到交换机前重新编程写入得多麻烦,而且如果我想获知网络的实时状态咋办,有了统一的控制机制,我们的网络才变得真正智能可控起来。OpenFlow的控制机制也十分灵活,感兴趣的同仁可以参考NOX。 好了,有了这个标准,只要大家以后生产的交换设备都支持,那么学术界以后能做的事情就太多了,以前YY无数次的梦想终于开始变成了现实。比如我们可以在正常运行的网络中自己在定义一些特殊的规则,让符合规则的流量按照我们的需求走任意的路径,就仿佛将一张物理网络切成了若干不同的虚拟网络一样,同时运行而又各不干扰,我们可以轻而易举的测试各种新的协议;以前要做什么处理,需要考虑到具体的拓扑结构,考虑到box的先后顺序,现在好了,通过定义不同的flow entry就可以任意改变流量的运行策略,这也很好的为解决移动性问题提供了便利(一个著名的demo是笔记本在不同交换机之间切换,虚拟机在两地之间切换,运行的游戏不受影响)。从这个意义上说,OpenFlow将传统的物理固定的硬件定义互联网改造成为了动态可变的软件定义互联网(software defined networking)。而一个软件定义的可控的互联网,除了更加灵活以外,毫无疑问,通过恰当的控制算法,将大大提高网络自身的鲁棒性、运行效率以及安全性。 目前学术界OpenFlow主要是stanford、berkeley、MIT等牵头的研究组在推动,而业界据说包括Google在内的几大巨头已经纷纷参与其中,最新的版本1.0协议已经发布。牵头人Nick Mckeown曾在Sigcomm08上做过专题的demo,后续这几年仍有不少的相关工作在高水平的会议上发表。国内据说清华大学已经有研究机构参与进去。 Nick Mckeown这个人十分有意思(主页在http://yuba.stanford.edu/~nickm),现任standford的AP,从他本人提供的简历就可以看出,Nick同学跟业界关系十分紧密,phd毕业两年就创办了公司,还参与了Cisco的项目,后来新公司卖给Cisco(Cisco这种模式很不错,有兴趣的同仁可以搜索过往案例)。笔者有幸在某次国际会议上碰到真人,给人感觉是十分的humorous且energetic的。Nick同学在推OpenFlow的时候明显十分重视跟业界结合,基本上是一边做,一边拉生产商的支持,很重视做demo,很早就在stanford的校园网中部署了OpenFlow,做的差不多了再提标准,再做宣传就事半功倍了。他的这种发展模式也十分为笔者所推崇。 最后的战役 OpenFlow的出现无疑给现有的交换市场带来了新的巨大的商机。网络行业发展到今天,垄断已经十分的严重,许多年来,交换机制造商已经麻木于每天忙碌提高性能的目标,偶尔做点小工作,支持下出现的新的需求。而OpenFlow创造了一块前所未有的大蛋糕,能否抓住这一机遇,不夸张的说是重新瓜分市场的生死之战。目前Cisco、HP、Juniper、NEC等巨头已经纷纷推出了支持OpenFlow的交换设备,不仅有固网的,移动互联网领域也相关产品开始试水。从另外一个角度看,市场的重新瓜分,新需求的出现,也会给小规模的生产商带来一线生机,对于新出现的厂家来说,这也许是能争得一席之地最后的战役。 相关资料 官方网站见http://www.openflowswitch.org,目前有软件版本、netfpga版本可供使用,支持的交换设备相信很快就可以能够买到。 | |
|
(4个打分, 平均:5.00 / 5) |
FastSoft E50 在青岛某企业跨洋测试效果
作者 xubuyu | 2010-10-15 07:30 | 类型 初创公司, 新兴技术, 行业动感 | 28条用户评论 »
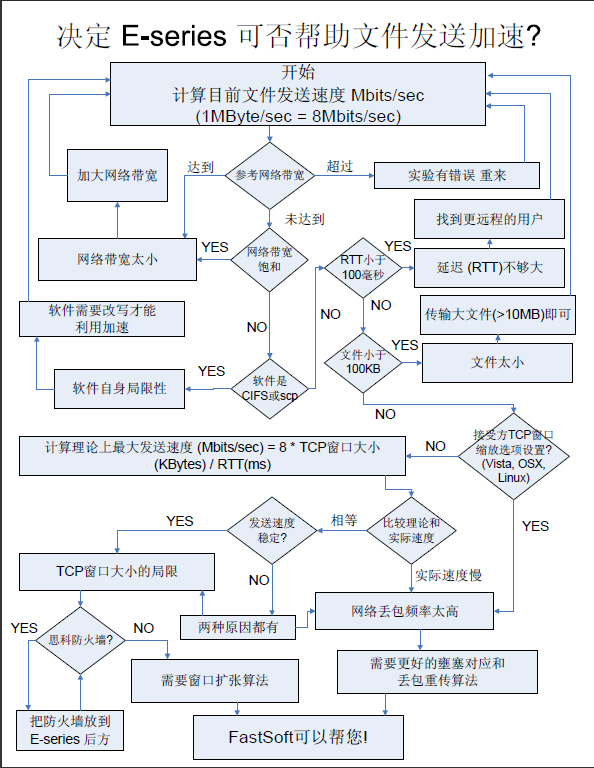
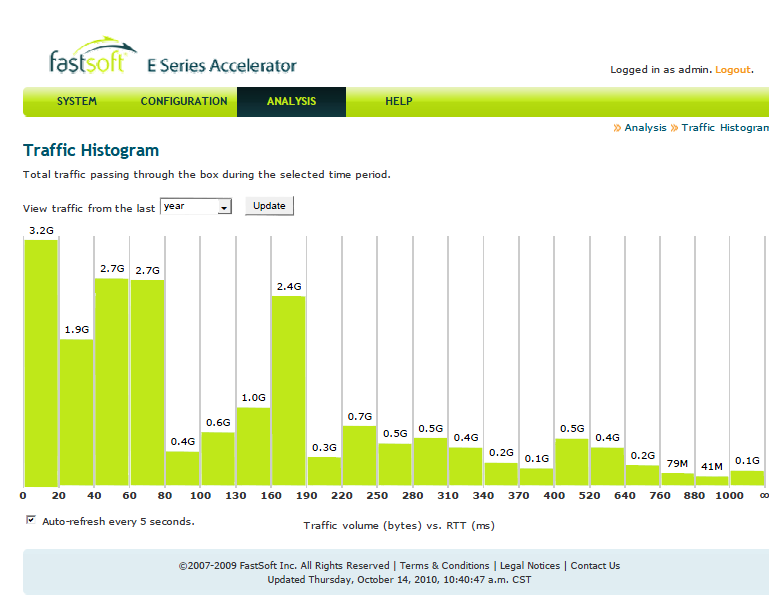 Traffic-Histogram 9月份流量图表 首先感谢青岛某外资企业IT的袁经理,提供给我们宝贵的测试机会。就如他所说,他们的网络架构是一个标准的跨洋、VPN数据链路,100M网通共享带宽,我在之前提到过,测试结果发现国内共享链路的传输效率依然很糟糕,下载速度尚能接受,往外发送速度是一个瓶颈。(上述图表选择范围是1年,其实就是9月份的测试结果,这是因为9月之前的数据因修改时间bug而丢失,从美国得到的消息是demo机的版本低,但完全不影响使用和展示) 在这样的情况下,我们依然得出FastSoft能够在数据传输量不大的情况下,加速比还是很可观,见下图。  Speedup Histogram 9月份加速比图表 我们在向加拿大传输100M的文件,加速和没有加速的实际效果是:大概是20分钟对2个小时左右。况且这是走VPN到加拿大,对端是3M ADSL+7M的Fiber。 青岛的WAN节点是一台WatchGuard X550E,通过建立VPN,走国产的100M共享(工业区内)连到加拿大。 另外,青岛的应用是条码扫描产品,实时传输扫描内容到加拿大的数据库,还有小部分的RDP应用-加拿大连到青岛服务器,或者青岛连到加拿大服务器等等,其他一部分的高峰流量显示是员工传输视频等:),还有员工上网流量。 总结:工厂处于投资人计划增长期间,没有标准的机房(网络和服务器等设备堆放在房间桌子上),车间实际生产的数据日产量很少,但是却需要实时传输到加拿大服务器,这在将来潍坊总厂的数据也汇入到青岛机房,对FastSoft来说是一个好机会。但是目前已存在瓶颈的状态下,我们还是建议客户尝试更改国内链路供应商(如电信,MPLS,或干脆用专线),并且让IT架构更加上一个层面,这样,相信FastSoft会比其他加速方案要更加适用。 有兴趣的朋友可以来信咨询,或者由我们提供中文资料,或者由我们为您和您的客户提供免费试用,测试服务。 Michael Xu. Best Regards. ——————————————— 2010/12/5 by xubuyu update. FS如何判断能帮到您的网络?请看下图:
| |
|
(1个打分, 平均:5.00 / 5) |
精彩科技视频:逼真的物理模拟动画
作者 陈怀临 | 2010-07-24 18:04 | 类型 新兴技术, 科技普及 | 14条用户评论 »
2009的最佳发明 。时代杂志
作者 陈怀临 | 2010-04-16 06:28 | 类型 新兴技术 | 2条用户评论 »
剖析系统虚拟化(1)- 简介
作者 吴朱华 | 2010-04-11 16:24 | 类型 云计算, 新兴技术 | 23条用户评论 »
系列目录 漫谈虚拟化技术因为在写探索UCS系列的时候,我发现弯曲的受众群主要以从事网络和通信为主,对系统虚拟化这方面不是特别熟悉,从而导致大家有可能无法很好地吸收UCS的一些技术,所以我特地准备写一个关于系统虚拟化的系列,来帮助大家加深对虚拟化技术的了解,希望大家能喜欢。
简单而言,虚拟化(Virtulization)是表示计算机资源的抽象方法。通过虚拟化可以对包括基础设施,系统和软件等计算机资源的表示,访问和管理进行简化,并为这些资源提供标准的接口来接受输入和提供输出。 虚拟化技术有很多种,比如,网络虚拟化,内存的虚拟化,桌面虚拟化,应用虚拟化和虚拟内存等等。因为篇幅的原因,本系列将重点关注系统虚拟化,特别是X86平台。今后此系列当中提到的虚拟化皆指系统虚拟化。 系统虚拟化的目的通过使用虚拟化管理器(Virtual Machine Monitor,简称VMM)是在一台物理机上虚拟和运行一台或多台虚拟机(Virtual Machine,简称VM)。VMM主要有两种形式:
系统虚拟机的分类由于采用技术的不同,可以将系统虚拟化分为五大类:
硬件仿真(Emulation)简介:属于Hosted模式,在物理机的操作系统上创建一个模拟硬件的程序(Hardware VM)来仿真所想要的硬件,并在此程序上跑虚拟机,而且虚拟机内部的客户操作系统(Guest OS)无需修改。知名的产品有Bochs,QEMU和微软的Virtual PC(它还使用少量的全虚拟化技术)。
图1. 硬件仿真架构图 优点:Guest OS无需修改,而且非常适合用于操作系统开发,也利于进行固件和硬件的协作开发。固件开发人员可以使用目标硬件 VM 在仿真环境中对自己的实际代码进行验证,而不需要等到硬件实际可用的时候。 缺点:速度非常慢,有时速度比物理情况慢100倍以上。 未来:因为速度的问题,渐趋颓势,但是还应该有一席之地。 全虚拟化(Full Virtulization)简介:主要是在客户操作系统和硬件之间捕捉和处理那些对虚拟化敏感的特权指令,使客户操作系统无需修改就能运行,速度会根据不同的实现而不同,但大致能满足用户的需求。这种方式是业界现今最成熟和最常见的,而且属于 Hosted 模式和 Hypervisor 模式的都有,知名的产品有IBM CP/CMS,VirtualBox,KVM,VMware Workstation和VMware ESX(它在其4.0版,被改名为VMware vSphere)。
图2. 全虚拟化架构图 优点:Guest OS无需修改,速度和功能都非常不错,更重要的是使用非常简单,不论是 VMware 的产品,还是Sun(Oracle?)的 VirtualBox。 缺点:基于Hosted模式的全虚拟产品性能方面不是特别优异,特别是I/O方面。 未来:因为使用这种模式,不仅Guest OS免于修改,而且将通过引入硬件辅助虚拟化技术来提高其性能,我个人判断,在未来全虚拟化还是主流。 半虚拟化(Parairtulization)简介:它与完全虚拟化有一些类似,它也利用Hypervisor来实现对底层硬件的共享访问,但是由于在Hypervisor 上面运行的Guest OS已经集成与半虚拟化有关的代码,使得Guest OS能够非常好地配合Hyperivosr来实现虚拟化。通过这种方法将无需重新编译或捕获特权指令,使其性能非常接近物理机,其最经典的产品就是Xen,而且因为微软的Hyper-V所采用技术和Xen类似,所以也可以把Hyper-V归属于半虚拟化。
图3. 半虚拟化架构图 优点:这种模式和全虚拟化相比,架构更精简,而且在整体速度上有一定的优势。 缺点:需要对Guest OS进行修改,所以在用户体验方面比较麻烦。 未来:我觉得其将来应该和现在的情况比较类似,在公有云(比如Amazon EC2)平台上应该继续占有一席之地,但是很难在其他方面和类似VMware vSphere这样的全虚拟化产品竞争,同时它也将会利用硬件辅助虚拟化技术来提高速度,并简化架构。 硬件辅助虚拟化(Hardware Assisted Virtualization)简介:Intel/AMD等硬件厂商通过对部分全虚拟化和半虚拟化使用到的软件技术进行硬件化(具体将在下文详述)来提高性能。硬件辅助虚拟化技术常用于优化全虚拟化和半虚拟化产品,而不是独创一派,最出名的例子莫过于VMware Workstation,它虽然属于全虚拟化,但是在它的6.0版本中引入了硬件辅助虚拟化技术,比如Intel的VT-x和AMD的AMD-V。现在市面上的主流全虚拟化和半虚拟化产品都支持硬件辅助虚拟化,包括VirtualBox,KVM,VMware ESX和Xen。 优点:通过引入硬件技术,将使虚拟化技术更接近物理机的速度。 缺点:现有的硬件实现不够优化,还有进一步提高的空间。 未来:因为通过使用硬件技术不仅能提高速度,而且能简化虚拟化技术的架构,所以预见硬件技术将会被大多数虚拟化产品所采用。 操作系统级虚拟化(Operating System Level Virtualization)简介:这种技术通过对服务器操作系统进行简单地隔离来实现虚拟化,主要用于VPS。主要的技术有Parallels Virtuozzo Containers,Unix-like系统上的chroot和Solaris上的Zone等。
图4. 操作系统级架构图 优点:因为它是对操作系统进行直接的修改,所以实现成本低而且性能不错。 缺点:在资源隔离方面表现不佳,而且对Guest OS的型号和版本有限定。 未来:不明朗,我觉得除非有革命性技术诞生,否则还应该属于小众,比如VPS。 五大类之间比较根据个人的经验,我在性能,用户体验和使用场景这三方面对这五大类进行了比较,具体请看下图:
表1. 系统虚拟化五大类之间的比较 因为这表只是我笼统的经验之谈,仅供参考,特别在操作系统级虚拟化这块。 系统虚拟化的用处主要有那些用处呢?
本篇结束,下篇将关注X86虚拟化技术的发展。 参考资料: | ||||||||||||||||||||||||
|
(6个打分, 平均:5.00 / 5) |




IPV6演进
作者 wjunjmt | 2010-03-30 18:36 | 类型 互联网, 新兴技术 | 30条用户评论 »
|
IPV6的商用还需要一个长期的过程来演进,在很长一段时间需要IPV4/IPV6共存。城域网全网使用IPV6是未来一段时间的目标,预计要到2020年左右才能实现全网IPV6。升级到IPV6需要从核心层、业务控制层面、接入层面和业务应用均要全面支持IPV6,从现网IPV6城域网升级至IPV6城域网至少需要下述几个阶段: 1、 IPV4城域网(现网) 2、 IPV4/IPV6共存 3、 IPV6城域网 其中IPV4与IPV6共存阶段是一个较为长期并需要大量设备升级和割接扩容的阶段,是以后城域网一个重要的阶段。对于该阶段我们建议关注以下内容: 1、 地址规划 2、 核心和业务层面升级至IPV6 3、 接入层面升级至IPV6 4、 IPV4组播业务升级至IPV6 IPV6地址管理一直是所有运营商最关心的问题,合理的地址分配方式和地址标识易于推进IPV6运营和管理。核心和业务层面的现网大部分设备可支持IPV6,因此在过渡阶段对于核心层面与业务层面建议部署dual stack,核心层面和业务层面设备同时提供IPV4与IPV6网络环境。而接入层面由于现网设备种类繁多,功能支持不一,需要进行大量的设备扩容、升级或替换后才能支持IPV6,因此接入层面的升级将是城域网升级至IPV6的关键的一部分,接入网演进至IPV6阶段需要两个方向:1、BRAS连接支持IPV6的接入网为用户提供直接的IPV6服务;2、BRAS(dual-Stack)通过隧道或6RD为接入网用户提供服务,接入网不能完全支持IPV6,用户使用dual stack,在过渡阶段将接入网慢慢升级至IPV6。另外一个IPV6问题是组播业务的升级,需要将原有IPV4组播升级至IPV6,该方式只能在接入网过渡阶段采用两个方向的情况下才能进行IPV4组播业务至IPV6升级。 图示:
城域网IPV6演进思路: 1、核心层面: 1.1、在整个城域网中启动IPV6,实现部署IPV4/IPV6 Dual Stack,城域网中IPV4与IPV6网络共存; 1.2、当IPV6业务发展到一定阶段,用户大面积采用IPV6后可以考虑取消IPV4承载。 1.3、核心层面需要支持6PE/6VPE;支持Carrier Grade NAT(CGN)或者是叫Large Scale NAT(LSN) 2、业务控制层面: 2.1、业务层面BRAS大多数已经支持IPV6,建议支持IPV6 BRAS部署dual stack,提供IPV4和IPV6网络服务; 2.2、BRAS不支持IPV6可采用L2TP连接至IPV6业务路由器提供IPV6服务。 3、接入层面: 3.1、现网不支持IPV6接入网可采用6RD方式为用户提供IPV6服务,通过6RD中继边界设备访问IPV6应用;逐步进行升级支持IPV6;也可通过BRAS作为LAC通过L2TP方式连接至dual stack的LNS提供ipv6服务; 3.2、根据用户区域逐步新建支持IPV6接入网提供用户IPV6服务,包括IPV6组播视频业务。 4、IPV6/IPV4互访 4.1、核心层面部署CGN实现城域网内ipv4和ipv6用户访问互联网服务(包括ipv4和ipv6服务); 4.2、城域网内ipv4用户使用6RD方式通过6RD中继设备访问ipv6服务; 4.3、当城域网骨干完全升级至IPV6,IPV4用户可通过DS-Lite访问IPV4互联网服务;IPV6用户可通过NAT64访问IPV4互联网服务。 5、组播演进 5.1、在只支持ipv4的接入网中,复制点将终止在BRAS上。 5.2、由于接入网只支持ipv4时候无法有效实现ipv6组播至终端,建议IPV6组播业务提供在新建IPV6接入网中。 5、移动分组核心网 6.1、需要对PDSN进行改造以支持dual stack,并且需支持dual-stack-ip-flow over ppp,可选支持6over4隧道; 6.2、移动分组核心网使用dual stack,部署dual-stack proxy mobile ipv6进行演进,LMA/MAG均需要具有ipv6地址,信令格式基于PMIPv6。 | |
 (4个打分, 平均:4.25 / 5) (4个打分, 平均:4.25 / 5) |

IRIS
作者 wjunjmt | 2010-03-17 02:13 | 类型 新兴技术, 网络安全, 行业动感 | 3条用户评论 »
|
不知道大伙有没有看过韩国一部《IRIS》电视剧,IRIS(国际反动个人集团International Reaction Individuall System)是一部非常精彩的国家间谍电视剧,值得为大家推荐!这里要说的是Cisco 的IRIS,IRIS—>Internet Routing in Space. Cisco在今年一月份通过intelsat’s IS-14卫星部署IRIS使用IOS实现与地面互通。IRIS计划是美国国防部联合能力技术验证(Joint Capability Technology Demonstration)项目的一部分,主要由思科和Intelsat公司负责实施,第一台IRIS太空路由器与Intelsat IS-14商用卫星一起,在2009年11月23日发射升空。 IRIS是一台针对卫星和航天飞船的耐辐射IP路由器,可以支持语音、视频和数据通信,主要依赖IP协议与地面进行通信,下面是Cisco IRIS的CSR(Cisco Space Router)的样子:
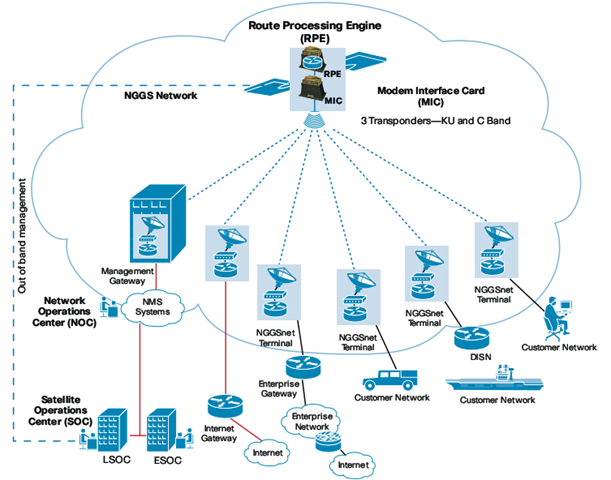
CSR通过Cisco IOS软件提供IP数据通信,增强通信利用率、吞吐量和延时,可以配置RF MIC(Modem Interface Card)、小型的卫星天线,支持配置动态ip路由协议,通过Zero-Touch部署(ZTD) 实现地面部署,当然还有一些Cisco IOS所提供的管理、安全、策略的功能,包括IPV4和IPV6。:) Cisco Space Router主要的特征:
Cisco Space Router是Cisco NGGS的重要组成部分,NGGS称为Next Generation Global Services,主要为卫星网络提供IP访问服务。下面是NGGS的体系结构:
| |
|
(1个打分, 平均:3.00 / 5) |