




嫦娥二号今日发射–进入倒计时
作者 陈怀临 | 2010-09-30 22:19 | 类型 行业动感 | Comments Off
探索UCS(4)- UCS的核心技术之VN-Link
作者 吴朱华 | 2010-09-30 20:17 | 类型 云计算, 行业动感 | 5条用户评论 »
系列目录 探索UCS今天特别将本系列其余三篇贴到弯曲上,希望大家能喜欢:)
每当谈到思科的时候,大家第一个反映,肯定是“网络之王”,虽然它现在的战线已经涉及到服务器端和虚拟化相关的产品,但是在UCS的整体设计上还是非常重视网络的作用,希望网络在实施虚拟化的数据中心中能够居于一个非常核心的地位,其中最有代表性的技术莫过于VN-Link,而且VN-Link也是UCS的三大核心技术之一。首先,先介绍一下VN-Link技术产生的背景。
Virtual Networking的难题在VN-Link相关技术推出之前,虽然Virtual Networking技术,比如Virtual Switch极大地方便了虚拟化技术的使用,但是随着虚拟化技术在数据中心的大规模使用,打破一个主机只运行一个操作系统和系统地址是固定这两个非常重要的假设,导致很多问题的出现,而且主要出现在两个方面,其一是使网络架构更复杂,其二是管理困难。(具体细节,请查看剖析系统虚拟化(7)) 为了解决上面提到的这些难题,VMware携手Cisco发布一系列产品来提升Virtual Networking,VMware推出了Distributed Virtual Switch(简称vDS),同时Cisco则推出了VN-Link。 VN-Link是一整套能在分布式虚拟技术环境下直接运行的网络方案,并且提供了和其它思科网络产品相似和让人很熟悉的功能集和运行模型。在设计方面,核心思想就是让虚拟机在网络方面的使用和管理都尽可能地和现有的网络架构融合在一起,而不是独创一派。这样的设计理念不仅能很好让虚拟环境更好地适应当今数据中心的网络环境,而且能维护思科在网络方面的王者地位。而且VN-Link包括两个子方案。其一是基于Cisco Nexus 1000V的解决方案,这个方案可以视为是以软件为主的实现。其二是基于NIV(Network Interface Virtualization)的解决方案,这个方案可以被认为是硬件实现。
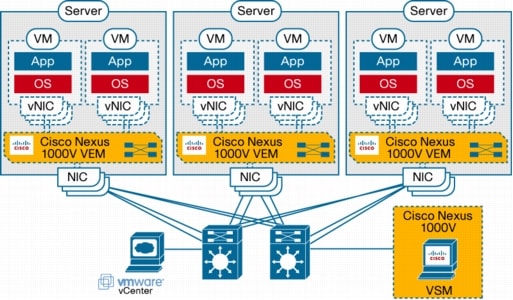
Cisco Nexus 1000V的方案首先,因为Cisco Nexus 1000v 是基于VMware vDS框架,所以其在总体的架构上也和vDS非常相近。它的做法也是分离了交换机的数据功能和控制功能,首先数据功能不是由主机上的Virtual Switch来处理,而是由安装在主机上的思科的VEM(Virtual Ethernet Module)模块来管理,而控制功能则被集中起来离至主机之外,可以是安装在一个特制的虚拟机内(Cisco Nexus 1000v使用这种做法),在Virtual Center内或者是内嵌在一个特制的物理机上(Cisco Nexus 1010)。下图为Cisco Nexus 1000V的架构。
图1 Cisco Nexus 1000V架构 接着,给大家分别介绍一下数据模块VEM和管理模块VSM。
通过VEM/VSM的组合,除了非常支持原有vDS的功能集合,而且能提供一些能更好地和现有企业网络架构融合的特性,比如其自带的企业级NX-OS系统,堪称业界事实标准的Cisco IOS CLI,Private VLAN,Encapsulated Remote SPAN和NetFlow v.9等
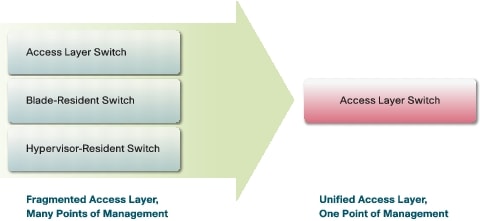
NIV的方案NIV全称为“Network Interface Virtualization”,在技术层面上,其和Cisco Nexus 1000V相差很大,它主要通过引入支持NIV技术的新设备来避免使用诸如Cisco Nexus 1000V或者Virtual Switch等软件交换技术。 首先,在普通的刀片虚拟机环境下,有可能在网络Access层出现三种交换机:其一是在Access层外置的交换机,比如:Cisco Catalyst 6500系列。其二是在Blade机箱层的刀片交换机,比如:Cisco Nexus 4000系列。其三是主机层的Virtual Switch。但是在UCS上,Cisco通过利用多种技术来简化这三种交换机至一种:
图2 整合三种交换机(参[3]) 通过整合三种交换机,能够让所有的流量都直接传送到Fabric Interconnect,这样不仅能极大地简化了网络的架构,而且能统一整个网络的管理。 接着,介绍Networking Interface Virtulization技术是如何让虚拟机直接连接物理网卡。大家都知道,一台主机上运行虚拟机的数量是远大于1的,所以虚拟机内置的虚拟网卡是远多于实际物理网卡的数量。为了解决这个不对称的问题,思科在UCS中引入了支持Networking Interface Virtulization技术网卡Cisco UCS M81KR,也称作“Palo”,因为Networking Interface Virtulization技术能够将一个物理的端口虚拟成多个虚拟的端口,所以Palo卡能虚拟多达128块虚拟网卡来对应虚拟机内置的网卡,而且加上Intel的Directed I/O技术,使得Palo卡在速度上也非常优秀。
VN-Link技术和它旗下的两个子方案,虽然还没有在各大企业数据中心中大规模铺开,但的确是对虚拟化网络环境的一次可贵的创新。
本篇结束,下篇将关注UCS的核心技术之Unified Fabric。 参考资料: | |
   (3个打分, 平均:3.33 / 5) (3个打分, 平均:3.33 / 5) |
《华尔街日报》2010科技创新奖
作者 陈怀临 | 2010-09-30 17:31 | 类型 行业动感 | Comments Off
40余富豪出席“巴比夜宴”
作者 陈怀临 | 2010-09-29 22:12 | 类型 行业动感 | 1条用户评论 »
|
【陈怀临注】富豪名单有:陈怀临,李彦宏,任正非,马云,王石,等等。其中陈怀临当场捐出其投机PAR赚到的N千美金。得到了巴比娃娃的青睐和现场其他富豪的嫉妒。。。 | |
|
(3个打分, 平均:2.67 / 5) |
走出云计算的误区(2)- 云计算和网格计算
作者 吴朱华 | 2010-09-29 21:10 | 类型 云计算, 行业动感 | 3条用户评论 »
|
本文是和IT168合作的“走出云计算误区”系列的第二篇,由于本系列的一篇云计算与环保的原文,曾经发表在弯曲上过,所以不重发,如果想看的话,请点击此。
对于IT界很多资深工程师而言,网格计算(Grid Computing)是一个耳熟能详的概念,它是把一个需要非常巨大的计算能力才能解决的问题分成许多小的部分,然后把这些部分分配给许多个计算设备来进行处理,最后把这些计算结果综合起来得到最终结果的计算模式。
在本世纪初,网格计算和现在的云计算一样是一个非常火热的概念,但是由于网格计算在商业模式,技术和安全性这三方面的不足,使得其并没有在工程界和商业界取得预期的成功,但在学术界,还是有一定的应用,比如,用于寻找外星人的“SETI”计划等。 在2007年底云计算这个概念刚诞生的时候,由于其在概念上和网格计算比较类似,也希望能让IT资源像水电这类公用事业那样按需使用和随需应变,所以有部分业界的从业者认为云计算相对网格计算而言只是“新瓶装旧酒”而已,对于这点,我不是很认同,接下来我从下面几个方面来分析两者之间的区别。 概念方面 在概念上,两者的各有侧重,网格计算主要强调的将一个巨大的问题分成许多个子问题,并通过许多个子节点分别对这些子问题进行计算,而云计算则强调通过后端的大型云计算中心来同时为多个用户服务。 领域和需求方面 网格计算这个概念是诞生在学术界,主要是为了解决处理大型的计算难题,比如,寻找并发现对抗艾滋病毒更为有效的药物或查找那个地方会存有石油等。而云计算则诞生在工程界,也就是Google的数据中心,主要是为了满足用户海量的搜索请求等。大家都应该知道,不同的领域和需求会引发出不同的产品,对于IT模式而言,也同样如此。 架构方面 在架构方面,网格计算和云计算都可分为后端和前端这两部分,但在网格计算中计算工作主要由前端来完成,后端主要用于调度任务,而在云计算中计算工作则主要由后端的大型云计算中心完成,其前端是用来接受后端的计算成果并显示,还有,在网格计算中参与计算的设备经常是异构的,比如,运行Windows的笔记本和运行Unix的小型机等,而在云计算中参与计算的设备往往是同构的,比如运行Linux的X86服务器,这样的做法不仅能简化管理,而且能提升运行效率。
虽然这两种模式之间有一定的区别,但是不可否认,云计算的诞生是离不开网格计算之前的试水。 | |
|
(1个打分, 平均:5.00 / 5) |

华为C8600体验报告
作者 老韩 | 2010-09-29 21:08 | 类型 互联网, 移动和设备 | 15条用户评论 »
|
华为终端近来势头很猛,在国内外接连发布多款基于Andriod系统的智能手机,出货量方面也有不小的增长。相传,华为终端部门的领导层十分看好Android及其衍生系统的发展,组建了国内最大的Android系统研究与产品开发团队。也许是看到了苹果在与联通合作中的强势表现,一贯走运营商定制路线的华为终端据称将以新的姿态出现在零售领域,IDEOS的全球发布就是序曲。而对于消费者而言,华为终端的发展壮大绝对是件好事,物美价廉的终端才是推进移动互联网发展的催化剂。 原文发于《计算机世界》
但华为C8600相对于U8220来说,还是做了一些改进。最大的进步当属内存容量,该产品配备了256MB RAM/512MB ROM,即便不做APP2SD,系统也可以运行得相当流畅,可以很好地满足一般商务应用。基带芯片也有所不同,华为C8600是一款支持CDMA2000 1X/EVDO Rev.A规格的产品,可以在中国电信的天翼网络中使用。所以在待机时,可以同时看到两张网络的信号。FM收音功能的加入也颇为实用,这也是许多消费者在选购时的考察重点。 华为C8600采用了经过修改的Android 2.1系统,在系统开放性方面拥有一定优势。因为是定制机的关系,该产品去掉了谷歌提供的所有服务,改为内置中国电信及第三方的工具和应用程序。这些软件与用户捆绑得比较紧密,如果使用CTWAP模式接入数据网络,诸如189邮箱、掌上营业厅、号码百事通等运营商提供的应用都可以直接识别用户手机号码,减少复杂的身份认证流程。而对于通讯录这一手机中最宝贵的个人数据,中国电信还提供了有针对性的同步服务,可以随时将联系人信息更新到云端,彻底解决了用户的后顾之忧。 第三方应用程序方面,除了传统的阅读、办公类软件,华为C8600也紧跟移动互联网发展的脚步,内置了开心网、新浪微薄等流行的社会化应用。如果用户想增加新的应用程序,可以通过手机内置的“华为空间”(新版更名为“智汇云”)下载安装,或使用其他第三方市场类软件。 支持电信天翼网络的Android终端数量本身就比较有限,其中摩托罗拉、HTC和三星都有惊艳的旗舰机型,中低端却罕有相应的产品;华为则继续沿袭“农村包围城市”的战略,用高性价比的C8600疯狂抢占着中低端市场,掀起一拨又一拨的“人民战争”。它的市场表现令人信服:在淘宝网的手机分类中,以“Android系统”和“电信天翼网络”为条件进行筛选,可以发现华为C8600在销量排名前五的商品中占据了三把交椅。其不俗的硬件配置、1500元左右的平均价格和正规行货可享受的服务,都是吸引消费者的重要因素。 | |
|
(2个打分, 平均:1.00 / 5) |

来自SlideShare的教训 – 使用云计算的惨剧和怎么避免其发生
作者 吴朱华 | 2010-09-29 07:45 | 类型 云计算 | 1条用户评论 »
|
本文翻译自一篇GIGAOM的文章,原帖地址,作者为Jonathan Boutelle,他是著名站点SlideShare的CTO和创始人之一。
对初创公司而言,云计算可谓是利器,因为只要通过鼠标点击就能一下子拥有几乎无限的计算能力,而且通过这些计算能力能够很好地开创新的机遇。通过鼠标点击就能一下子启动或者关闭上千台服务器是一个非常强大的能力,但就好象漫画书所教我们的那样“great power comes great responsibility(能力越大,责任越大)”。 我公司Slideshare在我们几乎所有的事情中都使用到了云计算,这也导致,我们在使用云计算方面也出现一些大错,下面是两个最明显的例子:
在没有试用之前就浪费了五千美元几个月前,我们开始非常着迷于Hadoop,我们甚至在办公室中组织了一个Hadoop黑客日(Hackday),并非常迅速地编写一些Hadoop原型代码来对SlideShare用户的数据进行分析, Hadoop分析本身是一个极为适合云计算的任务。虽然你需要一大堆电脑,但却仅需一天就能把所有的数据都给处理了。但当我们开始使用越来越多和越来越真实数据集来测试我们的原型代码时,它开始花费越来越多的时间来完成一个任务。 在那个时刻,我决定将机器的数目翻四倍(从20台升至75台)。这个决定是非常有意义的,如果一个任务需要100个计算时才能完成,那么100台机器就只需1个小时就能将这个任务快速地完成。 在我做这个决定的几小时后,一次大型站点事故引起所有工程团队人员的注意,为了解决处理这个事故和其它相关的事故,我们连续工作一个晚上和一个整天,最终直到周五的下午才全部搞定。在我们心安理得享受了一个周末之后,周一上班的时候我们发现在事故之前运行的Hadoop分析任务还在继续运行着。我们包含Bug的代码以一种我们没有预想到的方式失败了,以至于在这个问题上就算加入再多的硬件也解决不了这个问题,同时,我们收到了一张来自Amazon Web Service的五千美元的账单。 我们的教训是:如果你真正想使用云计算的力量,那么你需要不停地观测支出,并且确保它没有出现乱来的情况或者超出预算,特别当你快速地伸展和缩小使用云计算的规模时。不巧的是,Amazon Web Service并没有提供任何提醒或者图表工具来帮助用户简单地跟踪支出,虽然跟踪支出是一个牵涉到下载CSV文件,将它们导入Excel并进行分析的繁琐流程,但它却是不可或缺的。
使用云存储的麻烦我们最近发现我们在存储(S3)方面的开支急剧地增大,经过多天的调查,发现我们在使用存储方面没有明确的原则,比如,一些可以被删去的文件还保留着;不同类型的文件被放置在同一个目录;还有些文件我们根本不知道它们的来源和它们还是否需要。 Amazon S3,和其它类似的云存储,都可以被认为是一个大型的文件系统,它们不会对数据的位置进行任何控制,它由使用者来确保这个存储是否被有条理的使用。如果一个人写代码,这是很简单,但是让一个团队来写多个依赖云存储的程序时,是很容易忘记删除某些文件的。你需要确保你们没有浪费存储,唯一的方法是需要非常明确地定义那些数据存放在那些地方。一个最佳实践是将不同类型的资源放置在不同的”bucket(桶,S3的最高层的目录)“,这也是唯一地能让你得到每种类型数据的占有空间的方法。
蜘蛛侠的原则在上面两个例子中,我们知道了我们并没有很严格地使用云计算的力量,如果让我们之前借用硬件的话,我们也会触及硬件的限制(比如,磁盘空间用完),这是一件麻烦的事情,但去逼迫我们总结一下过去的行为,来更合理地支出。拥有强大的云计算力量是一件好事,但是如果你要使用它,就要有一定的责任心。 | |
|
(3个打分, 平均:4.67 / 5) |

新岸线:发布全新低耗高能计算机芯片
作者 陈怀临 | 2010-09-27 20:16 | 类型 芯片技术, 行业动感 | 11条用户评论 »
|
【陈怀临注:位于大宋深圳新岸线公司和ARM公司最近共同宣布推出新岸线首个计算机系统芯片NuSmart 2816,该芯片是基于40纳米工艺的SoC。新岸线推出的NuSmart 2816芯片将瞄准超薄笔记本和全内置台式机市场,以及上网本和平板电脑市场。】 下图所示为新岸线的老大周文: 下面是从相关新闻报道摘录的信息: 新岸线计算机系统芯片公司总经理周文表示:“封闭的计算市场在经历了30年单向发展之后,现在已经进入一个全新的时代。这一转变的推动力来自片上系统技术以及虚拟IDM行业模式,这二者在开放的、具有高功耗效率以及多样化用户体验的移动市场中都得到了很好的发展。创新的NuSmart 2816计算机系统芯片是全球首个以具有竞争优势的价格整合了具有传统PC市场的高性能处理能力以及移动市场的高效率的芯片。我们相信这个解决方案将为客户带来焕然一新的用户体验,并将重塑主流计算市场。” ARM公司市场营销执行副总裁Ian Drew表示:“ARM Cortex-A9 MPCore 处理器和Mali-400 MP图形处理器的结合,为业界提供了领先的可扩展解决方案,能够解决通用计算对于高性能的需求。在低功耗的情况下,这项产品同时带来了出众的2D和3D图形加速、尖端的ARM实体IP以及非常高的处理性能。” 下面是新岸线这次发布的芯片: NuSmart 2816集成了2GHz双核ARM Cortex-A9处理器、多核2D/3D图形处理器、64位DDR2/3-1066存储控制器、1080p多格式视频引擎、SATA2控制器、USB2.0、Ethernet和通用I/O控制器的芯片。通过利用多层混合互联技术、多级精细能源管理技术以及先进的40纳米制造工艺,NuSmart 2816芯片拥有不错的功耗性能,运行在2GHz时只消耗不到2瓦的能耗。 相关的英文描述: NuSmartTM 2816 is the world’s first chip to integrate a 2GHz dual-core ARM Cortex-A9 processor, multi-core 2D/3D graphics processor, 64bit DDR2/3-1066 memory controller, 1080p multi-format video engine, SATA2 controller, USB2, Ethernet, together with general I/O controllers. By leveraging the multi-layer hybrid interconnection technology, multi-level fine grain power management technology and advanced 40nm manufacture process, NuSmartTM 2816 is very energy efficient consuming less than two watts when running at 1.6GHz. | |
|
(1个打分, 平均:1.00 / 5) |


再谈Intel CPU微结构–过去,现在和将来
作者 陈怀临 | 2010-09-26 14:35 | 类型 芯片技术, 行业动感 | 25条用户评论 »
|
【陈怀临注:时光如梭。上次写这篇文章是2008年10月。转眼2年过去。这次做一些修订和校注。】 Intel CPU的产品称呼比较混乱。这一点对于在Intel工作的员工也是如此。下面是笔者在这方面的一些经验。希望对读者同学们有所帮助。 首先,对非专业人士而言,接触的名称通常为CPU的产品品牌(Brand Name),而不是微结构(Micro-Architecture)名称。什么是微结构?就是你看不见的那些东西。例如流水线(Pipeline)的设计,局部总线(Local Bus),缓存(Cache)的设计,存储总线(Memory Bus)等。到目前为止,一般而言,Intel CPU微结构的系列为:i386, i486, P5, P6, Netburst, Pentium-M,Core(Merom 65nm和 Penryn 45nm)。Core微结构的65nm流片有:Merom,Concore,Allendale等;45nm的流片Penryn,Workfiled,Yorkfield等。Penryn是Merom的直系后代。Nehalem是基于Penryn 45纳米流程的直系后代。从Penryn 45nm工艺流程的基础上,Nehalem微结构横空出世。在Nehalem与Core微结构的继承性上,目前英文的wiki上是不精确的。Nehalem最大的特点就是FSB和(或)北桥的消失,QPI的引入和把在Core微结构抛弃(或曰暂停的)HyperThreading从新引入。 Nehalem之后的事情比较清爽:Nehalem, Westmere(Nehalem在32nm工艺下的Tick ),Sandy Bridge,Ivy Bridge(Sandy Bridge在28nm 工艺下的Tick)和Haswell。通常,我们也可以说Nehalem和Westmere都属于Nehalem微结构。Sandy Bridge和Ivy Bridge都属于广义的Sandy Bridge微结构。这种关系就是Intel现在非常重要的Tick Tock的流程。如下图所示,为Intel的TT模型。
Tick其实就是Introduce一个新的工艺和各种PROCESS。Tock就是Introduce一个新的微结构。 工艺与结构的拆分对于Intel这些年来的成功是根本的。这里面的原因其实也很简单:如果一个芯片建立在一个新的工艺 AND又是一个新的微结构上。一旦出了问题,基本上整个公司就歇了一半了。CEO就要买豆腐撞死。没有Baseline的事情,最好不要去做。所以TT模式可以你确保,在一个已经酒精考验的PROCESS下,Tock一下,如果芯片有问题,那就基本上是新的结构出了问题。如果一个基于考验过的微结构在一个新的工艺下(Tick一下),如果芯片有问题,显然是工艺方面有bug。。。。总而言之,这样一个拿着billion美金烧出来的芯片,就可控了。。。 另外,TT模型的另外一个好处就是把工程师队伍有效的运作起来。例如,Core的Merom和Pennyn都是Intel以色列团队主导做的;然后Nehalem和Westmere是美国Oregon团队做的;然后Sandy Bridge和Ivy Bridge又是犹太人主导;再下面再是美国团队做。TT下去,循环往复。。 Intel在这个方面是从血的教训里学来的。当年的最新的NetBurst redesign Prescott在90nm就是Tick(90nm 所以,Intel的微结构变化可以简单概括为: 同一个名称的CPU可以是来自不同的微结构。如Celeron CPU有P6微结构的,Netburst微结构的,Pentium-M微结构的和Core微结构的。如果不懂的话,您购买了一个Netburst微结构的Celeron,在性能价格比上就不好了。在同年代中,您当然应该选择Pentium-M的款式。对Intel的Xeon名称的CPU也一样,读者可以发现,Xeon可以来自不同的微结构技术。 因此,CPU的产品名称基本上没有用。一定要知道其来自哪个微结构。换言之,CPU名称与微结构的映射关系是M:N。 这些微结构名词与我们日常看到的广告上的“Inside Intel”的名称的关系如下: (本文不讨论IA64体系结构。笔者认为IA64除了在科学计算方面,基本上没有任何意义了。) <微结构名称>: {CPU品牌(Brand)}+ i386: 80386DX, 80386SX, 80376, 80386SL, 80386EX i486: 80486DX, 80486SX, 80486DX2, 80486SL, 80486DX4 P5: Pentium, Pentium with MMX P6: Pentium Pro, Pentium II, Celeron (Pentium II-based), Pentium III, Pentium II and III Xeon, Celeron (Pentium III Coppermine-based), Celeron (Pentium III Tualatin-based) Netburst:(32位)Pentium 4, Xeon, Mobile Pentium 4-M, Pentium 4 EE, Pentium 4E, Pentium 4F,(64位)Pentium D, Pentium Extreme Edition, Xeon Pentium-M:Pentium M, Celeron M, Intel Core, Dual-Core Xeon LV, Intel Pentium Dual-Core Core:(64位)Xeon, Intel Core 2, Pentium Dual Core, Celeron M Nehalem:Xeon, Core i7,Core i7 Extreme,Core i5。 Westmere:Xeon, Core i7,Core i7 Extreme,Core i5, Core i3,Pentium,Celeron 在基于Nehalem微结构下45nm工艺下流片的CPU有: 桌面(Desktop) 服务器(Server) 下图是Nehalem-EX和Nehalem-EP的结构比较图: Westmere-EX (还没有出来。应该10个核,20个线程) 下图所示为Westmere的Clarkdale的芯片图。一个Package,二个Die。CPU Die是32nm;Graphic芯片是45nm。换言之,就是混在一起完事交差。读者想想马上要出来的无缝的Sandy Bridge的GPU集成,就知道其中之区别了。
下图所示为Sand Bridge的Die图。与Westmere + GPU的双芯片(Die)解决方案,我们可以看见,GPU Seamlessly进来了。。。
| |
|
(8个打分, 平均:4.50 / 5) |







未来的书
作者 陈怀临 | 2010-09-25 21:49 | 类型 行业动感 | 1条用户评论 »