云来了,安全盒子怎么办
作者 tomqq | 2017-07-27 11:35 | 类型 云计算, 网络安全, 行业动感 | 1条用户评论 »
|
云来了,安全盒子怎么办 by 何恐,一个安全人
前提和假设: 本文主要讨论“当下的”私有云安全,公有云不在此文范围内 1、云带来的安全挑战近两年,云计算发展迅猛,新建的IDC如政务云,行业云,绝大部分都是云机房。云计算是大势所趋已经毫无疑问,已开始遍地开花。 关于云环境下如何做网络安全防护,常听见一种观点:云是颠覆性的,传统硬件安全设备完全不适用云环境。 那么,云来了,安全盒子到底该怎么办? 从本质上来说,对于网络安全设备,云带来的最直接挑战有两个: 1、 主机虚拟化 2、 网络虚拟化 云主机虚拟化带来的挑战
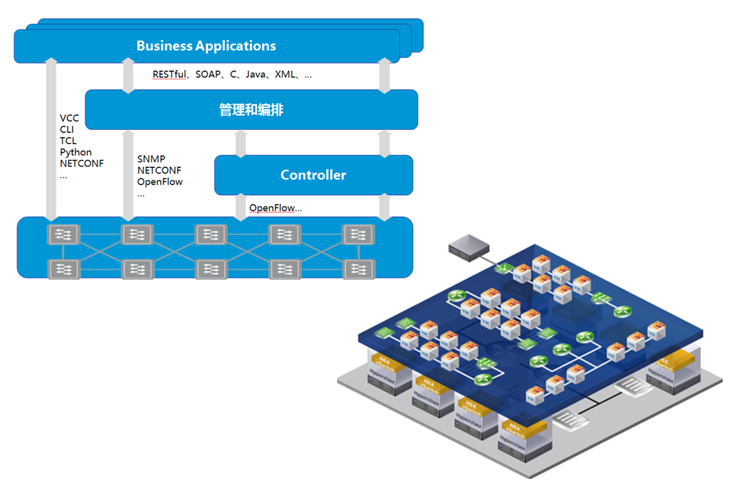
传统机房里面,每个租户的服务器是看得见摸得着的。在云环境下,租户的服务器变为了一个个运行在硬件服务器上的虚拟机,一个租户的虚拟机,可以位于不同的硬件服务器上,这是形态的变化,会引起租户的边界,从传统物理边界,变为动态、虚拟的逻辑的边界。 另外,因为一些历史原因会出现软硬件资源混合的情况。某些服务器不方便虚拟化,如历史遗留的数据库服务器,就需要和虚拟资源一起组成租户的计算资产。 最后,不同虚拟化厂家,如vmware,citrix,Hawei,H3C,各家的hipervisor系统不兼容,也会给安全厂商带来适配的工作量。安全厂家如果要以虚拟的形态运行在虚拟环境里面,需要适配不同平台的虚拟机格式。 因此,传统安全硬件要继续发挥作用,首先就要能够识别和保护虚拟的资产域,并且以动态的方式,切入到虚拟计算环境里面去。 另外,现在的运营商也不喜欢硬件盒子了。毕竟专用的盒子,利用率低,又互不兼容,运营商希望用通用的X86服务器来运行虚拟的安全设备,类似NFV,来提升经济性,可扩展性,以及适应业务快速可变的要求。
网络虚拟化带来的挑战如果按照vmware 1999年发布VMware WorkStation算起, OS虚拟化的发展时间已经不短了。但是,仅仅是服务器形态的虚拟化,还不足以支持云的发展。在云环境下,要满足云的虚拟性、动态性,还需要将网络也虚拟化。
第一个问题是传统vlan的4K问题。传统vlan因为tag字段位数限制,只能支持最多4k个vlan。但是在云环境下,租户的数量非常多,4K上限是不能满足租户数量的要求的。基于这个目的,扩展vlan tag字段位数,重新对ip报文做wrap,以便于支持更多的租户容量,采用类似vxlan这种方式来划分网络是主流方式。对传统安全盒子来说,首要问题就是能识别vxlan报文。另外vxlan带来的不仅仅是报文tag改变这一点点内容,vxlan带来的相关的网络控制方式改变,调度,如服务链、SDN等等,也都是安全盒子需要去适应的。 另外,云环境下业务动态变化非常频繁,靠传统硬件去动态开通或者销毁一个业务,显然是不行的。之前大家只知道需要把服务器虚拟化,后来随着云虚拟机数量规模的扩大,大家逐渐意识到光服务器虚拟化还不够,需要把网络部分也虚拟化,软件化,并自动化。举个例子:某租户需要开通一个业务需要一台路由器,过一段时间又不需要了,硬件路由器可以满足这样的频繁变化吗?硬件盒子,必须要也可以动态灵活的部署进去才行啊。 再加上云环境为了满足虚机动态迁移,需要在一个大二层,传统二层设备没办法支持这么巨大的mac表项,这一块也需要新的二层技术,如vxlan的支持。传统网络显然不行的。 还有,租户都有自己的vpc,IP地址范围很可能是重叠的。传统硬件设备大部分是不支持这个的,大部分不具备硬件设备虚拟为多个硬件设备的功能的。租户是逻辑的、虚拟的,是接在“逻辑交换机”上的。逻辑交换机本身就不位于任何一个固定位置,是通过计算机节点overlay的方式,分布式部署的。因此,对多租户的安全检测能力,是传统安全盒子不具备的,这显然无法适应云安全的要求。 最后,SDN控制网络,控制和转发平面分离,也使得云环境的网络和传统网络大大不一样。传统盒子如何接入如何适配新的网络架构,这个也是需要有一个重大改变的。之前安全盒子通过策略路由、桥接、分光镜像等方式接入网络做安全检测的方式,在SDN网络架构下已经不能适用了。传统安全盒子,需要按照新型网络的控制方式,来接入业务流量。否则,就完全不能发挥作用。 总结上述挑战,传统安全盒子通过交换机、路由器、分光器等物理方式接入租户网络的方式,在云环境下就失效了。要继续发挥作用,传统硬件必须要解决在云环境下的接入问题,要做到看得见、认得出、防的住,才行。 除了接入问题,安全盒子还需要适应云的弹性。硬件固定性能的盒子不容易弹性扩展,在云里面,安全也要像计算资源一样,可以动态的、弹性的扩展。 总的来说,云是利用资源的新的方式,安全本质并没有发生变化。但是,安全发挥作用的方式,需要根据云的变化而调整,才能继续有效。 2、 什么是东西向流量凡提到云防护,必然会听见“东西向防护”这个词。那么,什么是东西向流量? 下面这幅图,是传统IDC的流量走向:
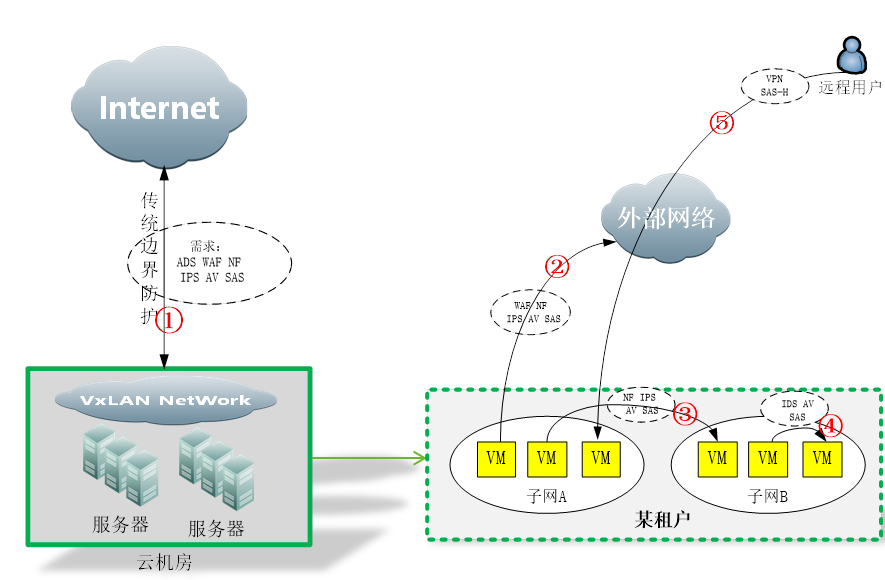
可以看到,大部分业务流量,都是从外到内为主,安全防护设备,也集中在由外到内的防护路径上,我们称之为“南北向”防护。 IDC云化以后,服务器的规模,包括虚拟机的数量,都扩大了很多。横向的虚机密度大大增加,也因此衍生出租户和各种复杂的网络虚拟设备,如下图:
传统IDC的安全问题,主要集中在①这个位置。云化以后,流量问题复杂化了,衍生出②、③、④、⑤这几个新的情况,防护也因此而有所不同。 在云网络内部,租户之间是隔离的,互相访问要通过vpn或者隧道访问。租户内部可以划分不同的子网,子网之间,子网内部虚拟机之间,虚拟到外部,外部到虚拟机,都会产生访问流量,安全问题也由此而生。 重要的是,这些流量往往产生在云内部,甚至不出服务器(如同一服务器内部虚机之间的流量)。因此这些流量,对传统硬件盒子不可见,从而也无法防护。这些流量,会成为一个真空地带,一旦发生安全问题,如虚机中木马或者病毒,将会迅速在云内部蔓延,并难以进行防护控制。这种情况是非常可怕的。根据《云等保增补方案》同等防护的原则,云内部流量也需要进行同等安全强度的防护,防护缺失是无法接受的。 综上,南北向流量,主要是指外部公网进出云计算内部的流量。东西向流量,主要是指租户内部虚拟机的访问所产生的流量。注意,东西向流量在这里是泛指租户相关的流量,并不仅仅是从外到内的流量。如果外部流量访问虚拟机,需要按照不同租户的策略来防护,此刻也称之为“东西向”。 南北向防护,传统方案都可以继续有效。而东西向防护,是云化后的机房新增加的需求。本文后面的讨论,主要集中在东西向防护方案。 3、 现有东西向防护方案凡是解决方案,出发点都是根据安全厂商自身情况优先考虑。同样的,对客户而言,“反厂商绑架”也是自然的诉求。 虚拟OS厂商的方案虚拟OS厂商,指的是虚拟系统厂家。这类厂家因为掌握了虚拟操作系统,所以自然考虑从虚拟系统本身入手来构建安全方案。通用的示意图如下:
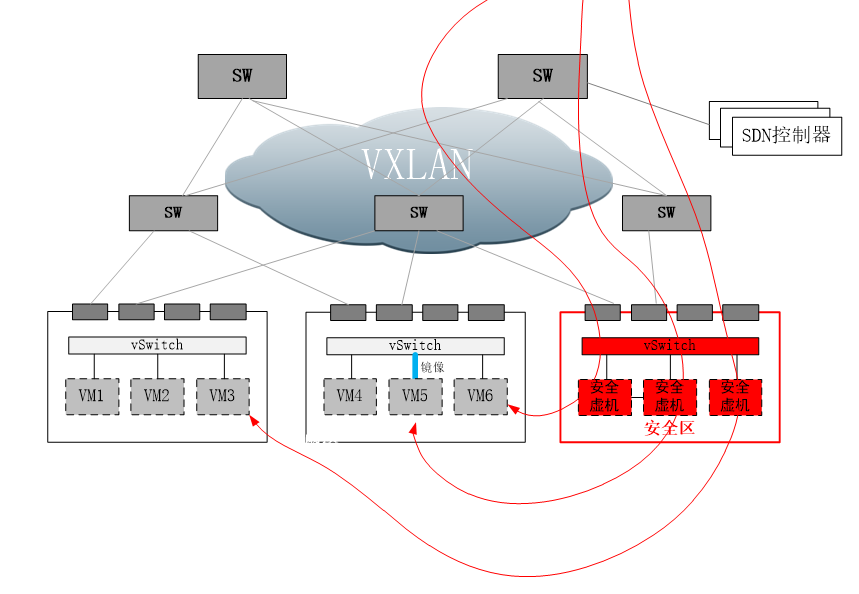
虚拟操作系统厂家,通过在虚拟系统网卡之上增加驱动过滤层,将虚拟机的流量截获,将流量导向系统内置安全模块,或第三方的安全虚拟机,进行安全防护。 从上图可以看出,对内部流量的防护,利用了计算节点本身的计算能力进行,流量在出计算节点之前,就得到了有效的防护。 这种方式有他的优缺点。优点是,在靠近虚拟机的位置进行防护,能够在最短路径上防护,同时流量不出计算节点,不会对云内部骨干网络,造成额外的流量负担。另外随着虚拟OS的部署,安全能力随之部署,在部署上也会比较便利。 缺点也很明显,首先是第三方安全厂商必须获取虚拟OS的防护API授权,才能引入自己的安全虚机,如vmware的nsx认证。对于虚拟OS厂商来说,自然不愿意第三方碰自己的蛋糕。比如vmware的NSX模块,终端用户须付费购买,第三方安全厂商须通过商业认证。只有同时满足这两个条件,用户才可以用到想要的安全厂商的安全能力。 另外一个缺点是安全模块和安全虚机运行在计算节点,会占用计算资源。对于计算资源紧缺型的用户,或许无法接受。同时安全能力和计算能力混合在一起,出现问题的时候,排查责任也会有较高的复杂度,互相依赖交叉的情况,会对虚拟OS厂商和安全厂商造成同时困扰。 最后一个缺点,是安全虚机厂商多样性也会有问题。不同厂家的安全虚机,要同时出现在同一个计算节点上,技术上会有很大的问题。从客户长远利益考虑,客户需要一个比较好的,兼容各个安全厂商的安全架构,或者说良好的生态圈。 网络厂商的方案这类厂商,以传统网络数通厂家为主。云化,不仅仅需要服务器虚拟化,也需要网络的虚拟化。流量可以在计算节点的驱动层捕获,也可以在网络层面捕获。我们知道,业务流量在哪里,安全问题就在哪里。因此对于网络安全盒子来说,在网络层面接入才是正道。
如上图所示,SDN网络,控制面和转发面分离,通过控制器来集中控制所有流量的转发。在SDN网络内部,可规划安全区。在安全区域,安全虚拟机或安全设备,可注册为服务节点。在SDN协议字段里,通常有服务字段。通过设置服务字段的值,即可控制任意的流通过指定的服务节点。 那么,安全盒子的部署,在这种情况下,也简单了。只要把安全盒子或者安全虚机,部署在服务区域,并注册为标准服务节点,即可利用SDN的服务编排能力,“指挥”任意流量,经过相应的安全节点,从而完成安全防护。 同时,SDN也有强大的网络控制力,可以实现流量镜像到服务节点,以及把服务节点的虚拟机工作口,绑定到用户VPC从而完成扫描类任务。 因为流量调度,通过网络进行了横向迁移,此刻可能大家会担心对网络带宽占用问题。为因对此问题,SDN网络内部增加了横向交换机的密度,所谓spine-leaf架构,通过增加横向带宽,来满足流量横向迁移的能力。 这种方式的优点很明显:通过设置服务节点,将流量通过网络调度的方式,进行服务编排,可以很方便的接入第三方厂商的传统盒子以及安全虚机。同时,因为通过网络控制器来进行流量牵引,可以自然兼容大部分hipervisor OS厂家——因为引流和虚拟OS没有关系。 缺点主要是增加了横向流量,会增加一部分网络建设的开销。另外在网络时延方面,不如内置在计算节点的方式。最后,采用这种方式,网络设备必须是支持服务编排的SDN网络,这对于采用传统网络方式的客户,增加了改造费用。
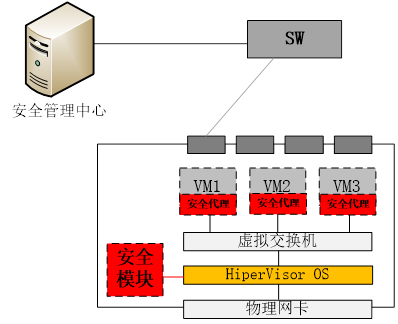
传统终端安全厂商的方案传统终端安全厂商,优势在于有安全终端,劣势在于没有网络产品,也没有虚拟操作系统产品。那么,自然会从自身优势出发,在虚拟机操作系统内想办法来构建安全能力,如下图:
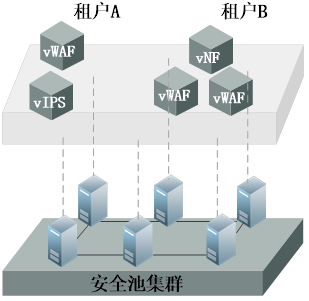
即:通过在虚拟机操作系统内,安装安全代理(通过虚拟机模板部署),以及在HiperVisor OS内安装安全模块,或称之为“无代理”方式,通过在HiperVisor系统底层以及虚拟机操作系统驱动层,捕获数据流以及文件内容,来实现安全防护。一般可实现杀毒、文件监控、网络防护等功能。 这种方式的优点在于,通过在虚拟机操作系统部署安全代理,避免了必须依赖虚拟OS以及SDN网络,而直接实现了流量捕获以及防护。另外,也可以充分利用计算节点的计算能力,无需额外增加安全硬件资源的投入,也不会引起流量的横向调度。 缺点主要有三个:一个是在客户虚拟机上安装代理,会有信任问题。如果客户数据比较敏感,可能不愿意安装第三方的程序在自己的虚拟机内;另外,如果要按照不同租户不同策略来进行防护,还是需要一个集中的管理中心和虚拟系统用户数据库进行对接,以便于识别租户以及下发相应的策略。第三个缺点是防护能力的多样化会有问题,即:很难在这样高度集成的架构内,开放的引入各家厂商的安全能力。 网络安全厂商的方案网络安全厂家,既没有SDN产品,也没有虚拟OS产品。在这种情况下,往往会选择一个中立的态度来构建云内的安全解决方案。 网络安全厂商,优势在于安全产品线很全,可以很快的将安全盒子,虚拟化为各种安全虚机,并池化。如下图:
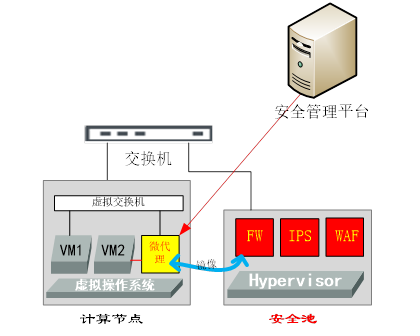
通过在标准x86服务器上,安装各类虚拟机,并形成安全池集群;然后,根据租户的需求,构建虚拟的安全能力,如虚拟WAF,虚拟IPS,以对应虚拟资源的概念。这样做可以将以前安全盒子专属硬件才能提供的能力,灵活的虚拟化到通用硬件,客无须再采购专用硬件,可就地利用虚拟服务器来作为安全池的部署环境,甚至利用现有的虚拟资源池来部署安全虚机。 那么剩下的,就是通过各种方式,将流量往安全池牵引,以实现安全防护。具体的引流方式,需要结合用户网络环境来实现。比如通过SDN API引流,通过传统路由器进行策略路由方式引流,通过虚拟/传统交换机镜像口引流,以及在计算节点内安装引流代理,通过代理方式引流。如下图:
上图的微代理,可以看作一个特殊的虚拟交换机。如果VM2需要被防护,那么只需要拆除VM2和原有虚拟交换机的连接,并将VM2的虚拟网卡,连接到微代理,微代理用TRUNK的方式再连接到虚拟交换机上,这样便不会破坏原有VM2的VLAN拓扑。然后,所有VM2的流量就会经过微代理,即使是同一个计算节点内虚机之间的互访流量,也会被微代理截获。截获后的流量,通过隧道送往安全池过安全策略,然后发回原有微代理进行正常转发。 这种方式的好处在于,通过池化安全能力,可以构建弹性、多样化且开放的安全池,方案本身符合云的特性。同时利用各种引流手段,能够灵活的实现安全防护。 缺点在于,引流方式会带来额外的带宽占用和延时。同时,需要对接不同的客户网络方案,对接成本较大。 总结:综上,可看出目前云环境下,缺乏统一的网络安全设备部署环境,目前局势还有点混乱。从另一个侧面,也看出虚拟化发展过程中,基础设施对于安全方面考虑的缺失。
4、 关于变化和发展安全能力池化传统的安全能力,都是通过固定的硬件盒子的形式提供的。在云时代,这种情况将发生变化。固化的安全能力,不能匹配云防护的要求。安全能力池化,首先是将传统的安全能力(引擎)虚拟化,其次是可弹性伸缩的安全池,最后能适应云环境的部署方式。云环境都是有租户的,那么云平台除了提供基础安全能力以外,也需要提供不同租户需求的不同安全能力套餐,并做到可运营。这样做的原因,本质是为了匹配云的特点:弹性,敏捷,虚拟化,可运营。 未来,传统硬件盒子的份额,可预见会持续下降,虚拟化安全产品的份额则会持续提高,此消彼长。传统盒子为了适应虚拟化,数通部分的模块会退化,引擎部分会持续强化。 在安全池基础上,需要有一个运营平台,对安全池进行统一管理,对安全业务进行灵活的开通、计费,并按照租户查看报表,以及云内部整体态势等功能。传统盒子的安全视角,是基于设备的。云安全池的视角,是基于运营平台的,安全盒子(虚机),只是平台下的一个基础模块。 最后,安全池是软件不是硬件,安全池泛指所有安全能力的集合,包含以安全硬件、安全虚机等组成的混合能力的“池”。 内嵌模式和外置模式互为补充内嵌模式,指的是安全池内置在计算节点内,充分利用计算节点的计算能力进行安全防御的模式,简单可认为如下图所示:
外置模式,正好相反,安全能力放在单独的通用服务器内,如下图所示:
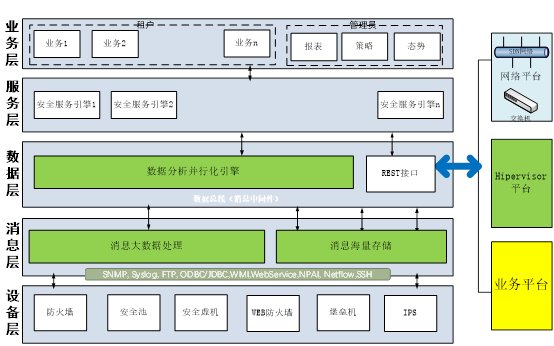
关于这两种方案的优劣势,争论很多。总的来说,内置式的最大优点,是充分利用计算节点进行就近防御。外置式最大优点,是有单独的安全能力空间,不占用计算资源。 不论安全厂商如何声称哪种方案好,从技术角度看,这两种方式实际上是互补的。外置安全池,更适合通过网络调度能力比较强的场合,以及以网络流量防护为主的场合;但是对于网络调度能力弱,需要结合local防护的场合,就适合内置方式。比如HWAF,本地杀毒,就近阻断,以及想在宿主机OS上搞点事情的场合。 外置和内置模式,都有对方干不了的事儿。从技术角度看,互补能够形成最完整的解决方案,缺一不可。无论目前坚持哪一派的厂商,最终都会走到这条路上来。从看见的客户实际需求,以及大厂的收购路线,都能印证这个趋势。 平台为王传统盒子都是以卖盒子为主要销售模式。云机房,不但需要虚拟化的安全盒子(池),还需要处理和虚拟系统的对接以获取租户信息、vxlan信息,SDN引流对接;另外从运营模式看,云平台除了提供基础防护,更重要的是提供满足租户多样化需求的可运营的平台,并满足增值收入。 传统机房只需要安全盒子接入,最多加个网管软件,即可完成销售。对云安全来说,这是不够的,需要提供平台能力,通过将虚拟化能力引入平台,并将平台和云平台的对接,从而提供云防护能力。 云安全平台的模式和盒子不一样,平台模式是平台先行,盒子和虚机随后逐步建设。从这个角度看,得平台者得天下。平台模式示意图简单如下所示:
| |
  (12个打分, 平均:4.17 / 5) (12个打分, 平均:4.17 / 5) |




从天津塘沽爆炸事故思考数据中心的灾备设计
作者 陈怀临 | 2015-08-16 10:03 | 类型 数据中心 | Comments Off
|
在云计算,大数据的今天,数据中心的灾备非常重要,例如,专业设计上的“两地三中心”的数据中心设计–同城两个数据中心实时备份;异地数据中心的异步灾备。天津是北京数据中心重要的异地灾备的选择地. 在这次爆炸事件中, 数据中心的情况如何? 据不完全的统计,天津有国家超级计算天津中心,腾讯天津数据中心 ,世纪互联,万国数据,华胜天成等等。其中, 腾讯的有20万台服务器。世纪互联方面,是国内最大的IDC,在天津有4个数据中心,其中有一个数据中心就是在滨海新区。 2012年,Pacnet的中国合资公司太平洋电信与天津市武清商务区签署了一项正式协议,在天津市武清商务区内共同打造一个全新的数据中心。这是一个可以提供2000个机柜的数据中心。 另外,中国电信天津武清IDC机房占地1800平方米,是中国电信北方区首个四星级电信级数据中心。
目前来看,万幸还没有报道上述数据中心出现宕机的报道。
伴随着互联网+,云计算,大数据的发展, 数据中心,灾备系统、灾备中心的建设成了非常重要的基础建设。社会对数据安全、应用安全有了强烈的需求。 在“两地三中心”的建设中,同城和异地的数据中心的选址都需要非常谨慎的考虑。并请专业公司设计。
亚马孙(Amazon)是世界上提供云计算的最好的公司之一。在过去的这些年里,数据中心也经常发生宕机现象。
下面是弯曲科技对AWS 2006-2014年数据中心事故的一些调查统计数据。从数据我们可以看见,电源和雷电引发的事故依然是数据中心宕机的最大原因,其次是存储系统。
从上述分析可见, 数据中心对自然灾难的抗打击能力是很脆弱的。对金融系统,政府和敏感单位数据,灾备数据中心的建设都需要非常谨慎。 | |
|
(没有打分) |
The Innovative Edge: The Rise of Cloud-Based Services
作者 陈怀临 | 2015-05-31 10:48 | 类型 云计算 | 1条用户评论 »

包云岗 。《数据中心与黑客帝国》(下)
作者 陈怀临 | 2014-09-27 19:55 | 类型 数据中心 | 5条用户评论 »
|
包云岗:中科院计算所副研究员,主要从事高效数据中心(ResourceDfficient Datacenter)体系结构与系统性能评测分析方面的工作。个人主页: http://asg.ict.ac.cn/baoyg/ ,新浪微博: @包云岗。 大概在2012年夏天,那时我还在普林斯顿大学,思考过如何从计算机底层的体系结构入手支持资源管理,消除计算机硬件层次上的“无管理的共享”。当时普林斯顿计算机系有好几位教授正在开展软件定义网络SDN方面的研究,也邀请很多大牛来做报告,比如SDN主要发起人之一、UC Berkeley的Scott Shenker教授等。平时和朋友也经常会聊起一些SDN的技术问题。网络早就面临着多业务共享与服务质量的问题,因此QoS技术(如区分服务)也相对比较成熟。而SDN则可以通过标识网络包、增加控制平面、增加可编程机制使网络管理变得更灵活方便。 当时就有一个想法——“其实计算机内部也是一个小型网络,那是不是可以将SDN技术借用到计算机内部呢?”于是写了一个5页的备忘录,题目叫《Software Defined Architecture:The Case for Hardware-EnabledVirtualization》,就搁起来了。2012年10月份回到计算所后组建了一个小团队。所里很开放,让我自己选择研究方向和内容,于是我把在普林斯顿的想法拾了起来。但那只是一个很粗略的想法,我们经过大半年的调研与摸索,不断调整目标与技术路线,在2013年中有了比较清晰的思路。我们将这个思路凝练为一种新的计算机体系结构,叫“资源按需管理可编程体系结构PARD(Programmable Architecture for Resourcing on-Demand)”。 仍然用城市交通作为例子,PARD体系结构的核心设计理念其实很直观且易于理解:(1)将车辆根据不同的用途进行涂装并安装鸣笛,救护车是白色加红十字涂装,消防车涂装等(对计算机内部流动的数据包贴上标签);(2)在一些关键路口设置红绿灯,在加油站、维修站等服务点设置管理装置(在计算机内部关键位置增加控制平面);(3)制定交通规则,红绿灯对救护车、消防车等关键车辆可以随时放行,而其他车辆则需要等待绿灯放行,而那些服务点也是优先服务那些关键车辆(根据不同标签来区分处理数据包);(4)交通规则可由管理部门根据需要进行调整,比如道路上新出现一批武警巡逻车,就为它们设立一些管理规则(管理员可以调整处理规则)。 事实上,我们日常的交通管理正是采用了这些理念。只要执行严格到位,这样的交通管理系统能在保障救护车等关键车辆顺利通行的前提下提高道路利用率。而PARD体系结构也正是希望通过相同的设计理念实现计算机内部高效灵活的资源共享与性能隔离,从而在多种应用混合的数据中心环境下,能在保障关键应用的服务质量前提下提高资源利用率。 假设PARD技术被验证是可行的(也很可能是不可行的,因为还有太多不确定的未知因素,所以还需要更深入的研究),那么将会有很多新的应用场景。比如对于云计算,可以做到做到更有效的分级服务管理,类似于航空公司的VIP服务,有的愿意多交钱,享受更稳定的服务质量,甚至是一下特殊服务,比如硬件提供的加密或压缩服务。 目前PARD第一阶段软件模拟器验证已经初步完成,还在进行第二阶段FPGA原型系统验证,有了进一步进展后希望能跟大家汇报交流。 最后,简单聊几句另一个Matrix,即《黑客帝国》。我想《黑客帝国》设想了一种场景从技术框架上是可行的,今天的云计算模式其实正是朝着这个方向发展。数据中心就像是“母体”。在《黑客帝国》中,所有人都会接入到母体中,在虚拟世界中工作生活。而如今,我们也是通过各种移动设备接入到数据中心,越来越多的时间是在数据中心上度过的。就如我们刚过去的一个多小时,就是在腾讯的数据中心上度过的。等到哪一天,我们的脑机接口有突破,人们不再需要手机这种“原始”的设备,而是可以直接通过大脑来接入数据中心,那么《黑客帝国》中的场景可能真的会成为现实。谢谢大家! | |
|
(1个打分, 平均:5.00 / 5) |
蒋清野 。《从微观经济学看云计算市场发展》
作者 陈怀临 | 2014-08-25 20:23 | 类型 云计算 | Comments Off

浅谈IaaS
作者 Roy | 2014-06-03 07:04 | 类型 云计算, 行业动感 | 3条用户评论 »
|
http://www.valleytalk.org/wp-content/uploads/2014/06/浅谈IaaS.pdf 图画得不咋地,不喜欢的可以直接看下面纯文本。 1 前言 图1. 传统IT系统结构 图2. 传统IT系统结构-应用分层 图3. 云化IT系统技术结构 图4. IaaS整体系统架构 图5. KVM虚拟化平台结构 图6. IaaS数据中心网络系统结构 图7. IaaS安全防护系统 图8. 管理平台架构 | |
|
(3个打分, 平均:5.00 / 5) |

25个值得关注的云计算, 安全和移动初创公司
作者 陈怀临 | 2014-05-29 11:22 | 类型 云计算, 移动互联网, 移动和设备, 网络安全 | Comments Off
|
Network World — There’s no scientific formula behind this list: It’s just a bunch of new-ish, mainly enterprise-focused computing and networking companies that have launched, received fresh funding of late or otherwise popped onto my radar screen. I’ll give you a brief description of the companies, then links to their respective websites or to stories about them so that you can explore further. Don’t read anything into the order in which these companies are presented either: It’s basically the order in which I came across them or their latest news. (IDG News Service and Network World staff reporting is included in this article.) *Tactus: Appearing and disappearing tactile buttons for your otherwise flatscreen tablet or smartphone. Tactus, which got $6 million in Series A funding in December of 2011, announced a mysterious Series B round in January 2014: Weirdly, no financial details disclosed. One founder led JDSU’s Optical Communications Division, and the other led development efforts for microfluidic-based programmable transdermal drug delivery systems and advanced optical sensors at Los Gatos Research. *Confide: Quickly became known as Snapchat for professionals not that Facebook has offered $3 billion for it — because like the popular photo-sharing app Confide is designed for highly secure messaging. A Confide messages, on sensitive topics like job inquiries or work conspiracies, disappear upon being read. *ClearSky Data: This Boston-based startup is enjoying calling itself a stealthy venture on its Twitter account. The Boston Globe has reported that ClearSky’s founders previously helped get tech startups CloudSwitch and EqualLogic off the ground. Highland Capital, which along with General Catalyst invested a combined $12 million in ClearSky, describes the newcomer as “working on solving an enterprise infrastructure problem for medium and large enterprises.” *Aorato: This Israeli company, which has received $10 million in funding from Accel Partners and others, calls its offering a firewall designed to protect Microsoft Active Directory shops. A pair of brothers are among the company’s founders. *Nextbit: Rock Star alert! Oh, technical rock stars, from Google, Amazon, Dropbox and Apple, according to the company’s skimpy website. The San Francisco company is focused on mobile something or other possibly some sort of mobile OS reinvention — and has received $18 million in funding from Accel and Google. *Confer: This Waltham, Mass., startup with perhaps the most boring name on this list hopes to make a name for itself nonetheless with software and services aimed at sniffing out malware and attackers targeting enterprise servers, laptops and mobile devices through its application behavior-analysis approach and its cloud-managed threat-intelligence platform.
*Bluebox: The latest in a long line of “Blue” IT companies (Blue Coat, BlueCat, Blue Jeans, Blue Prism, etc.), this startup has received more than $27 million in venture funding to back its mobile security technology. Its “data-wrapping” technology for Apple iOS and Android is designed to give IT control over enterprise apps but leave personal apps…personal. *Viddme: No sign-up video posting and sharing app, which works on mobile devices and the desktop. Simpler than YouTube. Development team is out of Los Angeles. *MemSQL: This Big Data startup formed by a couple of ex-Facebook engineers raised $45 million through January. This database company’s technology is designed to run on commodity hardware but handle high-volume apps. | |
|
(没有打分) |
作者 陈怀临 | 2014-03-24 17:57 | 类型 云计算, 行业动感 | 1条用户评论 »
谷歌高调宣布大力拓展云计算 欲与亚马逊争霸[摘要]本周二谷歌将宣布对该公司云计算服务所做出的数项调整措施。
 腾讯科技 景隼 3月25日编译 近日《连线》杂志网络刊登文章称,谷歌长期以来一直都在提供云计算服务,不过该公司多年来却将其视为可有可无的业务。近期谷歌副总裁乌尔斯•霍尔泽(Urs Hölzle)突然高调宣布准备大力拓展云计算服务,并希望借此将亚马逊赶下神坛。 以下是文章主要内容: 作为谷歌副总裁,乌尔斯•霍尔泽是谷歌网络基础架构的主要负责人。1999年,当霍尔泽还是加州大学圣塔芭芭拉分校的一名计算机科学教授时,拉里•佩奇(Larry Page)和塞吉•布林(Sergey Brin)就力邀他为支持谷歌搜索引擎的软硬件设备出谋划策。当时,谷歌搜索仅仅运行在位于北加州一个数据中心里的100多台电脑上,而15年以后,霍尔泽则把谷歌搜索的运行平台发展成了遍布全球的数据中心网络,并使谷歌成为网络服务当仁不让的王者。谷歌的网络服务也从当初的搜索拓展至Gmail、Maps和Apps等多个领域。 带着强大的自信,这位土生土长的瑞士人开始领导谷歌的技术设施(technical infrastructure)团队,该团队在谷歌内部被亲切地称为“TI”。霍尔泽将谷歌的其他团队称为他的“客户”。搜索团队是他的客户,Gmail和Maps也是客户。霍尔泽和他的TI工程师为谷歌的其他团队提供设施保障,这些团队使用由TI提供的全球计算机为数亿用户提供网络和移动服务。简单来说,多亏了霍尔泽的保驾护航,谷歌额服务才得以运行得如此高效。 然而在今年1月,霍尔泽突然在全公司范围内发表了一篇惊人的内部备忘录,他在备忘录中详细阐述了他领导的团队以及整个谷歌帝国的全新发展方向。他在备忘录中表示,在未来几个月里,他和他的团队将降低对谷歌搜索和Gmail等服务的关注度,从而将更多的精力放在为公司外部的新客户提供服务上。他们当时正在准备大力拓展谷歌的云计算服务,该服务能够让其他企业或软件开发者在谷歌的全球设施平台上运行他们各自的软件。 霍尔泽写道:“我们将把主要精力放在拓展这一新领域。每个开发者都想依托于云计算服务,而我们有责任提供这样的服务。” 谷歌的云计算历史 谷歌长期以来一直都在提供云计算服务,外部企业和开发者可以依托于谷歌的这一方面服务而建立网站和开发应用程序,与此同时他们还无需购买、安装或运行他们自己的计算机硬件设备。 谷歌曾在2008年推出了一款名为Google App Engine的云计算服务,后来又在2012年推出了另一款姐妹版服务,Google Compute Engine。然而,在这一代表着计算未来发展趋势的领域,亚马逊和杰夫•贝索斯(Jeff Bezos)却一直令谷歌望尘莫及。而且多年来,无论是谷歌还是霍尔泽都将云计算视为可有可无的业务。但现在,霍尔泽表示,谷歌有意将云计算发展成为下一个庞大的业务,一项营收甚至有可能超过在线广告的大业务。 这似乎听起来有些不可思议。毕竟,正是在线广告让谷歌发展成为全球最富有的公司之一。但霍尔泽的意思是,即使智能手机和平板电脑广告市场实现了非常快速的增长,云计算的市场潜力也要远超在线广告市场的未来发展潜力。 霍尔泽在谷歌总部接受媒体采访时表示:“公共云计算市场时未来的发展方向,这一点已经变得非常明朗。将来有一天,云计算可能会超过广告市场,当时我是指在市场潜力方面。” 霍尔泽已经对云计算市场跟踪观察了数年之久。他承认,谷歌和云计算市场的大部分企业都还有很长的路要走。但很多其他业内人士则表示,云计算注定要得到非常快速的发展,并且正在逐步蚕食年规模达到6,000亿美元的IT市场份额。市场研究机构Forrester的分析师詹姆斯•斯塔滕(James Staten)表示,截至2020年,云计算将占据全球IT市场约15%的份额,即900亿美元。而与谷歌不谋而合的是,亚马逊也认为,云计算服务可能会成为该公司规模最大的业务。 谷歌长期以来一直都在提供云计算服务,外部企业和开发者可以依托于谷歌的这一方面服务而建立网站和开发应用程序,与此同时他们还无需购买、安装或运行他们自己的计算机硬件设备。 谷歌曾在2008年推出了一款名为Google App Engine的云计算服务,后来又在2012年推出了另一款姐妹版服务,Google Compute Engine。然而,在这一代表着计算未来发展趋势的领域,亚马逊和杰夫•贝索斯(Jeff Bezos)却一直令谷歌望尘莫及。而且多年来,无论是谷歌还是霍尔泽都将云计算视为可有可无的业务。但现在,霍尔泽表示,谷歌有意将云计算发展成为下一个庞大的业务,一项营收甚至有可能超过在线广告的大业务。 这似乎听起来有些不可思议。毕竟,正是在线广告让谷歌发展成为全球最富有的公司之一。但霍尔泽的意思是,即使智能手机和平板电脑广告市场实现了非常快速的增长,云计算的市场潜力也要远超在线广告市场的未来发展潜力。 霍尔泽在谷歌总部接受媒体采访时表示:“公共云计算市场时未来的发展方向,这一点已经变得非常明朗。将来有一天,云计算可能会超过广告市场,当时我是指在市场潜力方面。” 霍尔泽已经对云计算市场跟踪观察了数年之久。他承认,谷歌和云计算市场的大部分企业都还有很长的路要走。但很多其他业内人士则表示,云计算注定要得到非常快速的发展,并且正在逐步蚕食年规模达到6,000亿美元的IT市场份额。市场研究机构Forrester的分析师詹姆斯•斯塔滕(James Staten)表示,截至2020年,云计算将占据全球IT市场约15%的份额,即900亿美元。而与谷歌不谋而合的是,亚马逊也认为,云计算服务可能会成为该公司规模最大的业务。 优势≠成功优势≠成功 亚马逊可谓是云计算市场的开拓者,该公司曾经凭借Elastic Compute Cloud和Simple Storage Service两款软件率先给云计算市场下了定义。现阶段,亚马逊仍然是全球云计算市场的主导者。而亚马逊在云计算市场的其他竞争对手还包括微软和Rackspace。但霍尔泽认为,谷歌所拥有的庞大设施群会让该公司在速度、效率、价格等方面具有天然的竞争优势。 此言不虚。为了服务于谷歌搜索、Gmail和其他自有网站产品,谷歌运营着比亚马逊或微软都要更加庞大的在线设施,而且这一庞大的计算系统拥有全球最先进的技术。在过去的15年里,随着谷歌帝国拓展至前所未有的规模,霍尔泽以及包括杰夫•迪恩(Jeff Dean)、桑杰•吉玛瓦特(Sanjay Ghemawat)和路易斯•巴罗索(Luiz Barroso)在内的工程师团队对谷歌数据中心的软硬件设施进行了全新设计,以便跟上谷歌的发展步伐。而现在,其他云计算企业正在努力模仿谷歌的这些技术。 现在的问题是:谷歌是否能够将这些优势转化为另一种成功。历史经验告诉我们,最好的技术并不是总能够赢得市场,市场营销、时机甚至是一点点运气都将发挥重要作用。云计算公司Cloudant的创始人迈克•米勒(Mike Miller)表示:“我相信,谷歌拥有最好的网络基础设施、最好的工程师以及最好的软件。但有时候拥有这些还不够。想想当年Betamax 与VHS的格式之争你就会明白了。” 打造全球最大云计算 在当地时间本周二上午,谷歌将在旧金山举行的一次活动上宣布对该公司云计算服务所做出的数项调整措施。霍尔泽将发表主题演讲,阐述他对云计算市场未来的见解。 与其他云计算巨头一样,谷歌和霍尔泽的目标也是想让人们的云计算生活变得更加轻松,无论是用户开发新网站或新移动应用,还是存储或处理大量数据,抑或只是想看看有些代码是否能够运行等等。企业和开发者此后无需拥有自己的网络设备,他们只要打开网络浏览器在谷歌的网络上运行自有软件就可以了。 很多企业和开发者已经这样做了。根据谷歌提供的数据显示,该公司的云计算服务网络上正在运行着475万个活跃的应用程序,其中就包括著名的阅后即焚社交应用SnapChat和移动新闻阅读应用Pulse。谷歌App Engine每天单独处理的在线申请就多达280亿个,是维基百科单日处理量的近十倍。 现在,如果你在谷歌App Engine上创建一家网站,该服务就会自动将这个网站推广至越来越多的电脑,从而让越来越多的用户访问这个网站。但问题是,你不可能只是简单地把软件挂靠在谷歌提供的云计算服务上。你必须按照某种方式、使用具体的编程语言、软件库和架构来创建你的网站。而谷歌的其他服务,比如Cloud Engine,恰恰能够帮助用户解决这些问题。 降低服务费用 霍尔泽还指出,云计算服务的费用有时过高。确实,很多小企业和开发者也抱怨称,有时候云计算服务的收费比他们购买和运行自己的设备还要高。包括亚马逊在内的有些云计算公司似乎对他们的服务收取了令人难以理解的高额费用,至少在某些案例中是这样的。但霍尔泽相信,由于谷歌拥有规模效应,因此该公司能够帮助解决这一问题。就像沃尔玛可以降低牙刷成本一样,谷歌也可以降低计算循环成本。 霍尔泽表示:“要想在云计算市场取得成功,你不仅需要有先进的技术,而且还必须能够在经济性方面击败其他竞争对手的产品。”这番变态似乎在暗示,谷歌将在明天举行的活动中宣布大幅下调云计算服务的费用。 Forrester的斯塔滕认为,要想主导云计算 ,谷歌还有很长的路要走。他指出:“谷歌仍在扮演着追赶者的角色。”总体上来说,斯塔滕认为,谷歌的服务并没有亚马逊和微软提供的服务那般成熟,也就是说谷歌并没有提供足够多的用于快速开发和运行软件的工具。 斯塔滕指出,霍尔泽和谷歌将会与亚马逊、微软和IBM在云计算市场展开长期竞争,因为他们都想在6,000亿美元的IT市场上分一杯羹。 | |
|
(1个打分, 平均:5.00 / 5) |
杜玉杰 。《2014年再不加入OpenStack你就真OUT了!》(下)
作者 陈怀临 | 2014-01-17 10:05 | 类型 OpenStack, 云计算 | Comments Off
2014年再不加入OpenStack你就真OUT了!(下)上篇:《一场没有硝烟的战争》文中讲到如今各家厂商已是纷争四起,主要是希望换个角度思考一下当前的OpenStack生态环境,文章发布之后未曾料到会得到这么多的关注,特别要感谢一下白小勇等几位好朋友的建议与反馈,谁让大家现在都如此的看好 OpenStack这块香饽饽了呢 :-) 下篇:《开放式创新》一文中将为大家整理一下OpenStack这三年来孕育的创新力量,以及它目前所面临的机遇与挑战。
开放式创新“开放式创新”这个词最早应该是加州大学伯克利分校的Henry Chesbrough教授的《开放式创新:新的科技创造盈利方向》一书中所提到的,由于开源企业和周围环境之间的界限变得模糊,创新可以在公司以内和公司以外进行。OpenStack通过开放的社区直接把用户引入到这个创新的过程中来,这种以用户为中心的社会化研发方式越来越有优势(如果想了解以用户为中心的民主化的创新如何发挥作用不妨参考一下上篇提到的《民主化创新》一书)。 首先正如OpenStack名字中所表达的,开放(Open)是这个项目核心的价值。这个成立之初仅有两个基础模块的OpenStack,如今已发展成为拥有9个核心子项目(Havana)一系列孵化项目的庞大开源组织。并且作为开源领域的后起之秀,它博采众长吸收了众多开源组织的优点,比如延用了 Ubuntu社区的发布模式,每六个月发布一个版本(与Ubuntu版本同步发行),借鉴了Apahce基金会和Linux基金会的运作模式,打造一个更加开放的OpenStack生态系统——OpenStack基金会,同时还为开发者提供更成熟和专业的社区管理工具,通过持续集成和基础设施项目为OpenStack开发进度和开发质量提供保障。也吸引到了众多开源领域的专家加入:如Nova项目里的Russell Bryant (Asterisk专家)、Oslo项目里的Mark McLoughlin (KVM、 GNOME、Linux kernel、Java专家)、TripleO & CI system 项目里的Monty Taylor (MySQL专家)等,还有厂商们的大力追捧:Top 3的服务器厂商(HP、DELL、IBM)、Top 3的Liunx发行版厂商(RedHat、Canonical、SUSE)、Top3的交换机厂商(Cisco、Juniper、Alcatel-Lucent)、Top3的存储厂商 (EMC、IBM、NetApp)等等,今年Orcale也刚刚加入这场变革。 社区的蓬勃发展,厂商的不断加入,成熟的社会化研发模式,精英团队的领导(但需不需要有一个灵魂人物也是大家争论的焦点之一),灵活的架构设计都使得OpenStack成为了最有活力的全球开源项目,这种开放也极大的激发了相关技术的创新。所以如果关注OpenStack只是看到大量优秀的代码和框架,不参与到这场令人兴奋的变革中去那你就损失大了,因循守旧就坐等淘汰吧! OpenStack用户在哪里?上篇也提到了中国用户对于OpenStack具有较高的认同度,并且已经纷纷开始尝试与实践。这些成功部署了OpenStack平台的企业大致可以分为两类:一类企业属于内部有较强的技术实力,对开源软件有着强烈的好感,他们下 载源码之后几乎可以通过DIY来解决自己问题的(不过这可不是下载几部电影那么简单,你真的要这样做吗?想好怎么升级了吗?谁来为你提供技术服务?);另一类企业则选择了开源服务供应商,不管是OpenStack发行版还是各种OpenStack解决方案(请结合上篇的各个山头对号入座)。下面我就结合我个人所了解的情况来介绍一下国内OpenStack的用户发展情况,当然肯定会有遗漏或还未公布出来的信息,欢迎大家补充。
DIY用户记得2011年初,我开始参与在国内推广和普及OpenStack时,国内也才刚刚开始了解OpenStack,很多企业都还在观望,包括之前我就职的一家国字头的Linux发行版厂商。既然项目不是咱们伟大的民族发起的,那咱就虚心学习呗~ 所以当时我们联合英特尔、广州电信研究院等几家单位,在上海市科委的支持下,邀请来了该项目的发起者RackSpace和Nebula(前NASA CTO创建的公司),以及Intel和Dell的海外研发团队来国内布道,共同组织了首届OpenStack上海峰会(后来由于和基金会的 OpenStack峰会在名称上容易混淆而改成用户组大会),国内也只有电信广研院和上海交大几个为数不多的机构和部门开始研究OpenStack。电信广研院后来做了一套开放云体系与OpenStack开放测试平台(OSTP:OpenStack Test Platform),上海交大的团队则对内提供了一套OpenStack运营平台,他们对于SDN网络虚拟化这块也有丰富的经验,另外还基于 OpenStack平台做过Syslog 分析方面的工作(大家有兴趣可以上网搜索一下金教授他们的发表的论文)。 付费用户2013 年开始我和我的团队开始为部分国内企业客户服务,所以接触到一些付费或有意向用户。 如IDC客户,因为随着微软Azure与AWS的进入,外资领先的云服务商可能对国内IDC企业造成毁灭的打击,IDC正在转型的关键节点,迫使他们必须从卖资源转型到卖服务。而目前国内公有云现状是:没有成本优势 ,规模无法实现盈利,不计成本很难持久,几乎没有提供相关的API,不能给用户提供按需付费的交付方式。所以说AWS模式很难在国内复制,特别是AWS采用的DevOps模式,要知道有600多人在AWS产品线,并且他们无需客服人员,用户自助、互助服务,国内没有客服你都不敢想象会是什么样子。 还有一些金融客户,他们面临大数据的机遇与挑战,正在努力寻找突破。相对来说,互联网企业投入其实并不大,几个人的团队就已经足够为云平台提供运维支撑,出了问题也是可以自己抗的。金融客户重点在于关注自身的业务,而底层的基础设施服务希望能够通过第三方服务提供商来提供保障,进而可以加快项目实施进度。政府和教育行业也同样, 他们面临定制化开发风险,面对升级维护等问题时也倾向于选择第三方服务提供商来实施自己的云平台项目。 我们正在改变世界在这过去的一年中,国内 VC们也很忙,苦苦支撑的国内云计算相关企业纷纷拿到融资。启明创投对七牛的投资,红杉资本对够快的投资, DCM和贝塔斯曼对UCloud的投资,涌金对华云的投资,光速安振对QingCloud的投资,以及一批项目的天使融资,让我们感受到了云计算市场的活跃。 国内几家专注OpenStack的初创企业也纷纷传来喜讯,先是年初UnitedStack获得红杉资本、ChinaRock、IDG的天使投资,年中中路股份投资了道里团队,11月份易云捷讯获得用友幸福投资和信中利集团的联合投资,年底的时候海运捷迅也斩获了A轮战略投资,还有最近一家新成立的 easystack也刚刚拿到了蓝驰的投资,还有stackinsider(云动科技的一个项目)等初创企业纷纷开始为国内客户提供OpenStack相关产品及服务。 IDG Connect发布的2013年度 OpenStack云发展路径的调研报告结果更是显示,绝大多数接受调研的企业IT决策者表示,OpenStack已纳入其企业云计算基础设施的未来计划当中。调查结果提到,随着企业用户可以越来越重视去解决这些问题,企业用户正在或有计划的向OpenStack私有云迁移。有60%的受访者表示,他们正处在配置OpenStack的初期阶段,有的尚未完成,或者还在实施过程当中。有84%的受访者表示OpenStack的是他们未来云计划的一部分。 说到这里忍不住想提一下TryStack.cn,早期为了推广OpenStack,解决大部分用户没有安装部署环境,另外各种组件及插件也不知该如何选择,还有版本升级更新维护等问题,所以在英特尔、山石、盛科等相关企业的支持下,提供了一个OpenStack测试体验环境,并公开了它的参考架构,从F版开始每个版本都及时更新,如今已经部署到最新的Havana版本,并在去年香港峰会上发布了面向企业的Trusted Enterprise Cloud 参考架构。 OpenStack生态系统将会重新洗牌开放并不等于免费,所以如果把自由(free)当作免费 (free)那就图样图森破了。正如Mirantis有篇博客里写到的那样“Some companies will get acquired, while some others will get acqui-hired.”,OpenStack确实给一些初创公司带来了很高的知名度以及投资机会,但基础软件开发周期长,投入大、见效慢,技术创新转化成产品需要更多时间,而现在还搞不清楚用户在哪里的初创公司已经逐渐失去往日的光辉。 开放最大的价值在于创新,并且是超越了公司界限的创新。 开放协作才会有利和促进产业繁荣发展,这也是我发起TryStack社区联盟的主要用意。虽然越来越多的朋友开始拥抱OpenStack,并开始把 OpenStack作为创业途径或新的发展方向,但教育客户和培养市场的工作任重而道远。希望国内的OpenStack生态圈也能更加开放,充满活力,才能吸引更多人才加入到这个大家庭中来,一己之力毕竟是有限的,吸引更多人参与类似的事情当中才是有意义的,也希望看到越来越多的在OpenStack线体验或测试平台上线(或许大家可以反馈给我来做个统计?)。 去年我在给北航云计算硕士班的学生们讲OpenStack这门课时,曾说过好好花半年时间学习一下年薪30W不是没有可能(也不是说一定能拿到 :-)),今年看来门槛仍在不断提高,有朋友曾回复我说没有看懂上篇里的人才之争一部分的内容,其实我想告诉他的是创业团队和巨头们之间的人才之争已经愈演愈烈,丰厚的薪水还是美好的未来,你想好了吗? | |
|
(没有打分) |

杜玉杰 。《2014年再不加入OpenStack你就真OUT了!》(上)
作者 陈怀临 | 2014-01-16 11:01 | 类型 OpenStack, 云计算, 行业动感 | Comments Off
[原文可参阅: http://duyujie.org/post/72355803255/2014-openstack-out]2013年底最后一周突然收到两封邀请函,一封是来自微软,邀请我参加2014年1月微软开放技术有限公司中国运营启动仪式,这是微软新成立的一家专注于开源技术的全资子公司;还有一封是来自华为,邀请我前去为其某产品线做一个关于社区与运营的报告(上一次去华为还是2013年6月份,在他们加入OpenStack基金会之前,受邀前去深圳总部为云计算产品线做的关于OpenStack社区的报告),看到国内外的企业都越来越关注和重视开源社区,真是2014年的头等喜事。欣喜之余我整理了一下几年来对OpenStack社区的所见所感,希望对于想要了解OpenStack的朋友能够有所帮助,关于社区运营的的话题稍后我会另外再写一篇。纯属个人观点,仅供参考,拿砖头的、丢臭鸡蛋的看准了再扔:-)。一场没有硝烟的战争去年11月份,在香港举行的OpenStack峰会是OpenStack基金会首次在美国本土之外举行的大型社区活动。在这次峰会上,作为众多开源云架构中最受宠的OpenStack享受到的不仅仅是来自全球企业和开发者的高度热捧,主办方也是想尽一起办法彰显中国元素。
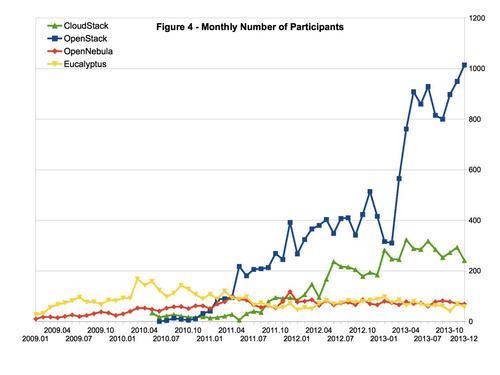
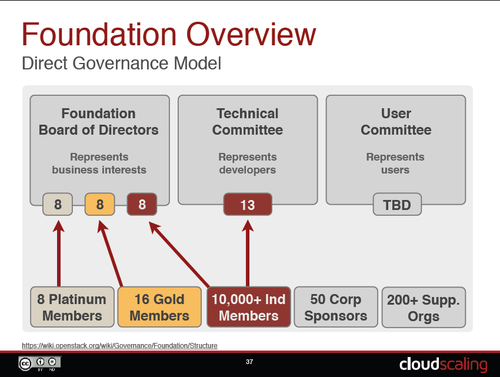
图1 -OpenStack香港峰会 无论是现场观众得知目前全球范围内拥有最多的OpenStack开发人员的城市是北京时的惊呼,还是在峰会期间,特意邀请来爱奇艺、奇虎360、携程等来自中国OpenStack用户所做的经验分享,无不显示出OpenStack基金会对中国市场的重视。 而每一场开源运动中,技术人才的争夺都是白热化的。OpenStack在开源云平台的人才大战中取得了不可思议的成绩,从2010年到香港峰会结束,三年的时间里,OpenStack社区已经遍及全球132个国家,13504人参与,其中个人开发者人数达到了近6000人,而支持厂商/组织共有298家,按级别来分共有8个白金会员、19个黄金会员、54个赞助公司、217个支持机构(截止至2013年12月31日),这样的规模对于一个开源组织来说,可谓声势浩大。 图2-开源云计算社区对比参与度对比[1] 但看似一团和气的大家庭其实私下也是暗潮涌动,感受最为深刻的就是香港峰会展区里到处摆放着的RedHat Partner的牌子,可以说大家为了抢占至高点,用尽了各种手段招数。
图3 -香港峰会展厅 如果配上旁白的话大致如下:
这不禁让我想起前段时间网上吐槽一则“雾霾对武器影响多大:侦察看不清导弹打不准”新闻时的一个段子: 美:我们有B52轰炸机。中:我们有雾霾;美:我们有精密雷达。中:我们有雾霾;美:我们有精确制导炸弹。中:我们有雾霾;美:我们能把你们的城市从地图上抹去。中:你们不能,我们能。美:你们有什么武器做到?中:我们有雾霾。 再看看这帮军阀们手中的武器都有哪些: RedHat 作为老牌Linux厂商,手握Libvirt(别告诉我你不知道这个项目意味着什么)、KVM还有Gluster,最近CloudForm也是耍的有模有样,更别说OpenShift,oVirt等宝贝了。Libvirt和KVM反正是绕不过去了,所以Canonical很早就和 Inktank抱在一起,当然是试图希望通过Ubuntu和Ceph的整合来对抗RehHat的Glusterfs。而SUSE仍是紧抱微软的大腿(其中缘由请自行谷歌),不知是不是希望通过Hyper-V绕开RedHat 的KVM。其实RedHat 也没闲着,PLUMgrid的加入让人不禁猜想是否想对VMWare NSX + vCenter构成威胁? 武器在手免不了占山为王,所以除了各自产品的较量,更重要的还有山头之争,目前都有哪些山头呢? 第一个山头自然是对上游的影响力
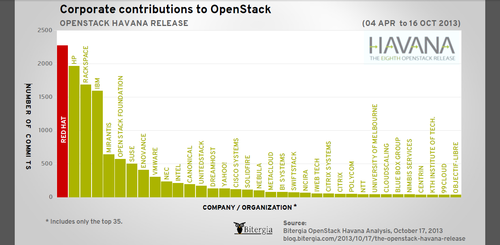
图4-OpenStack基金会 在OpenStack社区里真正有影响力的当然是技术委员会的PTL和Core开发者,主要由他们决定OpenStack的开发方向,不过来自企业的代码贡献量也能说明不少问题:
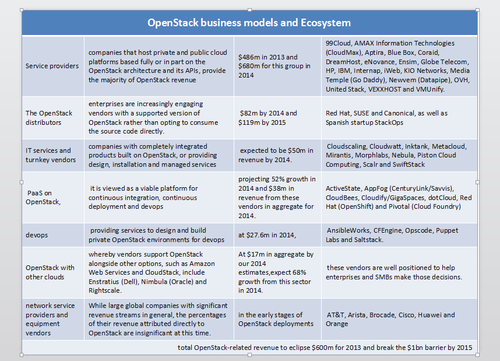
图5 -企业贡献排名 从最新统计中可以看出Rackspace已从D版和E版的第一名贡献者已经下滑到H版的第三名,并且还有下滑的趋势;Mirantis从上一版的16位飞速上升到第五;HP和IBM最近几个版本倒是一直都在前五;RedHat从F版开始就一直领跑(Canonical的老大不知咋想的?),RedHat早已牢牢地控制住了Linux主要市场,如今看来他们对OpenStack也是势在必得,想想Cloudera和Hortonworks怎么争夺Hadoop的(这两兄弟也不知有没有分出高下?)。 进化论告诉我们物竞天择,竞争的结果就是用户直接受益。目前看到无论是你想要的度量和计费(Ceilometer),或者是配置管理和编排服务(Heat)、甚至是部署服务(TripleO/Tuskar)和PaaS(Solum)服务在OpenStack中都有了各自的模块,所有你想要的一切,社区都会逐步的整合进来,所以不要再试图维护自己的专有分支或模块了,拥抱社区并参与贡献上游吧~ 第二个山头应该算是服务提供商了由于这块目前入门门槛比较低,但早期市场主要在这里,更接近早期的“领先用户”,并且提供服务的公司可以在这些客户的付费中成长,对于处于市场培养阶段的的OpenStack厂商来说自然也是必争之地。 实践证明参与产品开发与改良的用户很多,创新用户的研究表明,这些用户具有“领先用户”的特征,也就是说他们在一个重要的市场趋势中领先于用户总体的主流,而且他们为了自己所遇到的需求期望从一个解决方案中获取相对较高的收益。由于领先用户在重要的市场趋势中处于市场的前端,所以我们可以相信,许多他们自己开发使用的新产品也会吸引其他用户,即他们可以为愿意将创新产品商业化的制造商提供产品基础。 ——节选自《民主化创新》
图6 -商业模式和生态系统 这个山头占据了几乎主要的OpenStack市场份额,引得大多数OpenStack厂商都杀向了这个山头。在这个山头上在新秩序还没建立起来之前,大家都被Linux世界的大佬们划分成鲜明的两大阵营:RedHat和Ubuntu。 第三个山头就是各自的相关产品前面提到RedHat和Ubuntu作为上个时代的开源领袖,目前都开始角逐OpenStack时代的最强者。而Mirantis绝对是匹黑马,过去的一年当中连续推出了 Fuel for OpenStack deployment、Murano for Windows and Linux、 Savanna for Hadoop,Rally for testing and benchmarking等开源项目,还放出了Stackalytics统计社区的代码贡献量,硬件在线评估系统,几乎把能赚钱的工具都统统开放了出来,如今更是把它们整合成了Mirantis OpenStack 4.0,绝对值得期待!另外OpenStack的发起者RackSpace虽然放权给基金会,但并不意味着放弃整个市场,12年下半年就曾推出其私有云产品Alamo现在已经更新到最新的Havana版本的了。当时思科紧随其后也曾推出过一个OpenStack发行版本,不过随后就没什么音信了,倒是其公开的文档吸引了不少用户的关注[2]。 而CloudScaling 似乎和AWS走的很近(参见[3]: 一封致OpenStack社区的公开信),并且由于瞻博和希捷参加了Cloudscaling 2013年B轮1000万美元的融资,所以他们的OCS似乎也很值得尝试。另外Piston 和国内程辉团队的UOS比较像,可最近声音都不多,不知出了什么状况?(Piston 2013年也拿到了B轮,目前融资总额1250万美金)。 另外两匹黑马Metacloud和Morphlabs,一个是做Managed service,另一个做OpenStack Applicance,倒也是风声水起,其中Metacloud在2013年6月刚获得1000万美元的A轮融资,投资者包括canaan Ventures、Storm Ventures和Jerry Yang(former Yahoo co-founder)的AME Cloud Ventures。MorphLabs 2013年D轮之后总共融了2250万美金,我在去年的CloudConnect China大会上曾邀请他们来上海分别做过交流。 最后还有培训这块山头别小看了培训这不起眼的生意,大家都是醉翁之意不在酒,主要都是看重生态系统的建设。RedHat的Linux培训体系就是一个很好的证明,Cloudera的Hadoop培训也类似。他们一方面通过继续贡献社区提升对上游的影响力,加快代码修复速度,另一方面通过培训体系打造自己的生态系统。除了上述提到的几家厂商之外,还有swiftstack专门提供针对存储模块Swift的培训。目前国内唯一能看到的应该就是TryStack联盟成员Mirantis授权的培训课程(详细内容参见[4])。 [1]CY13-Q4 Community Analysis — OpenStack vs OpenNebula vs Eucalyptus vs CloudStack [2]思科wiki [4]OpenStack培训 | |
 (3个打分, 平均:2.67 / 5) (3个打分, 平均:2.67 / 5) |