华赛USG9110已经相当成熟,至少在硬件设计与系统结构上达到国际水准。期待下一代产品的问世,也希望国内安全厂商迅速跟进,提升行业的整体水平。
原文发布于《计算机世界》
 信息时代,运营商网络带宽不断增加,需要面对更多、更复杂的安全威胁。同时,行业用户及大型企业开始建设更具规模的数据中心,对安全产品的性能需求也与日俱增。但由于自身的业务复杂性限制,防火墙性能的提升速度总是逊于同时代的数据通信产品,成为新一代高速网络中的瓶颈。 信息时代,运营商网络带宽不断增加,需要面对更多、更复杂的安全威胁。同时,行业用户及大型企业开始建设更具规模的数据中心,对安全产品的性能需求也与日俱增。但由于自身的业务复杂性限制,防火墙性能的提升速度总是逊于同时代的数据通信产品,成为新一代高速网络中的瓶颈。
针对这一现状,国内外安全行业领导厂商也推出了一些高端解决方案,它们无一例外地采用了分布式处理的思路,以增加业务处理节点的方式实现高性能。交换机加载防火墙模块是出现较早的一类成熟方案,它利用交换机的高速交换能力,将需要进行访问控制的流量通过背板导入防火墙模块,经处理后再进行转发。如果遇到性能瓶颈,可以多配置几个防火墙模块,线性提升系统的整体处理能力。但从实际应用的角度看,这种方案还存在一些问题。首先,如果想充分发挥性能,管理员必须非常了解自己的业务模型,人为地进行流量分配,才能使各业务节点达到较高的利用率。其次,当业务流量模型发生变化时,很难迅速找到合理的配置修改方案。对于业务灵活性要求不亚于性能的运营商和数据中心用户来说,这类产品显然不是最佳选择。
为采用分布式处理思路的高端防火墙增加智能负载均衡特性,使其可以自行为各业务节点合理分配流量,已成为业界公认比较先进的一类产品解决方案。由于该方案对厂商的研发实力有着非常高的要求,目前市场上可见的产品并不多,且多由国外厂商所推出。作为国内规模最大的信息安全解决方案提供商之一,华为赛门铁克亦成功推出了采用智能分布式处理方案的Secospace USG9100/USG9300(以下简称USG9100/USG9300)系列产品。近日,计算机世界实验室对USG9100系列中的低端型号USG9110进行了细致深入的评估测试,在此与读者朋友们分享。
ATCA架构下的智能分布式处理
USG9110是第一款来到计算机世界实验室的基于ATCA架构设计的安全产品,满足PICMG 3.0规范的要求,在交换容量、可靠性、兼容性及功耗等方面有所保证。5U规格的机框显得十分紧凑,前后面板都留满扩展槽位,主要用于扩充业务卡与接口卡。机框两侧是支持热插拔的风扇框,USG9110可以根据内部温度传感器提供的信息动态调节风扇转速,在保证自身健康运行的同时减小功耗、降低噪音。顶部留有机框管理卡(SMM)插槽,该卡负责机框及所有扩展卡物理层面上的统一控管,属于必配部件之一。USG9110工作在主备模式的供电子系统支持多种规格的动力电输入,可以满足不同环境下的部署需求。
为了实现业务的分布式处理,USG9110采用了以交换为核心、控制平面与业务平面相分离的设计思路。机框面板的最下侧两个扩展槽位属于主控交换卡(MSU),该卡运行着系统软件,负责完成路由协议的维护、系统配置及各层面功能特性的管理等工作,是USG9110业务层面的控管核心。卡上集成的交换模块为USG9110提供了120Gbps的数据交换能力,并且当插入两块主控交换卡时,各卡上的交换模块将共同工作,使设备的交换容量达到240Gbps,同时提供相应的冗余特性。为了提升这部分带宽的应用效率,配置下发、信息统计和各部件/接口状态信息的收集将从另一个独立的交换网络上进行。这种设计符合ATCA标准定义,是保证分布式系统稳定性的必然之选。
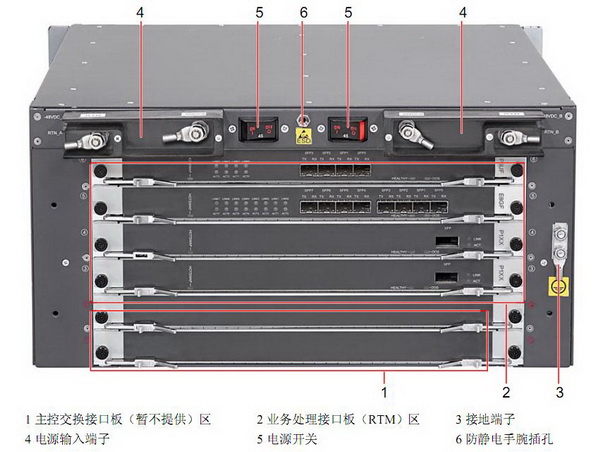 机框前面板的另外4个槽位属于业务卡(SPUA),它与交换背板相连接,负责绝大多数安全业务的处理和数据转发,是USG9110的业务处理核心。这块业务卡的设计十分惊艳,其思路和做法在安全产品范畴内实属罕见:华为赛门铁克的工程师在一块业务卡上集成了两颗运行在950MHz的NetLogic XLR732多核多线程处理器,提供了强大的计算与转发性能;而针对快速转发前访问控制对性能造成的微弱影响,更是不惜成本地采用了通常出现在高端路由器上的TCAM来进行硬件加速。除此之外,作为智能分布式处理的关键因素,数据流的调度分配由业务卡上自行研发的FPGA逻辑实现。它可以根据多种算法,实现不同的负载均衡模式,将流量下发到单块或多块业务卡上的处理器进行处理,是当之无愧的交通枢纽。单从硬件规格上看,这块业务卡已经体现了华为赛门铁克优秀的硬件研发实力,其水平在国内外均处于领先行列。 机框前面板的另外4个槽位属于业务卡(SPUA),它与交换背板相连接,负责绝大多数安全业务的处理和数据转发,是USG9110的业务处理核心。这块业务卡的设计十分惊艳,其思路和做法在安全产品范畴内实属罕见:华为赛门铁克的工程师在一块业务卡上集成了两颗运行在950MHz的NetLogic XLR732多核多线程处理器,提供了强大的计算与转发性能;而针对快速转发前访问控制对性能造成的微弱影响,更是不惜成本地采用了通常出现在高端路由器上的TCAM来进行硬件加速。除此之外,作为智能分布式处理的关键因素,数据流的调度分配由业务卡上自行研发的FPGA逻辑实现。它可以根据多种算法,实现不同的负载均衡模式,将流量下发到单块或多块业务卡上的处理器进行处理,是当之无愧的交通枢纽。单从硬件规格上看,这块业务卡已经体现了华为赛门铁克优秀的硬件研发实力,其水平在国内外均处于领先行列。
 USG9110的接口卡(RTM)被设计为插在机身背面的小卡形式,与前置的业务卡一一对应。规格方面,华为赛门铁克提供了多款集成不同种类、不同接口密度的型号,用户可根据自身情况灵活选择。接口卡的规格还在随着需求变化推陈出新,我们这次测试的产品就配备了两块新发布的高密度接口卡,单卡提供16个千兆接口和两个万兆接口。 USG9110的接口卡(RTM)被设计为插在机身背面的小卡形式,与前置的业务卡一一对应。规格方面,华为赛门铁克提供了多款集成不同种类、不同接口密度的型号,用户可根据自身情况灵活选择。接口卡的规格还在随着需求变化推陈出新,我们这次测试的产品就配备了两块新发布的高密度接口卡,单卡提供16个千兆接口和两个万兆接口。
USG9110定位于高端应用环境,各方面特性都与常见的中低端产品有明显不同,我们用了很长时间来熟悉这款产品。各类模块的全冗余设计是最引人注目的一点,也是运营商及大型行业用户最关注的指标。在测试中,我们曾对主控交换卡、业务卡和接口卡都进行过热插拔操作,系统一直保持稳定运行。由于USG9110具有智能负载均衡的能力,当一块业务卡被拔出时,该卡承担的所有任务会被自动分发到其他业务卡进行处理,最大化地减小了上层业务中断的可能性。
通常,高端产品也意味着高功耗、高发热,但USG9110并不在此列。这款遵循ATCA标准设计的产品对整机与各模块的功耗、散热控制得十分严格,官方给出的整机最大功耗仅为800W。而经过实测,采用双路供电、配备两块机框管理卡、两块主控交换卡、单块业务卡和单块高密度接口卡的USG9110在满载运行时的功耗为每路174W,双业务卡、双接口卡时的每路功耗为264W,在同级别产品中优势明显。
性能:随业务卡数量线性增长
有了强大的硬件平台做基础,USG9110的性能可谓十分强悍。每秒25万HTTP新建、400万并发连接、10Gbps的吞吐量……这仅仅是产品规格表中给出的USG9110单块业务处理卡的性能,却已经为测试带来不小的难度。2009年9月,华为赛门铁克联合实验室合作伙伴思博伦通信对该系列产品进行了测试,其中某些项目竟然动用了20台当时最先进的应用层性能测试仪Avalanche2900方可完成。本次测试中,虽然思博伦通信为我们提供了最新的Avalanche3100测试仪,却仍然无法测出USG9110的某些性能值,我们会在统计图表中特别注明。受整体测试环境的限制,所有项目中都使用测试仪直接连接USG9110的两个10Gbps端口进行测试。
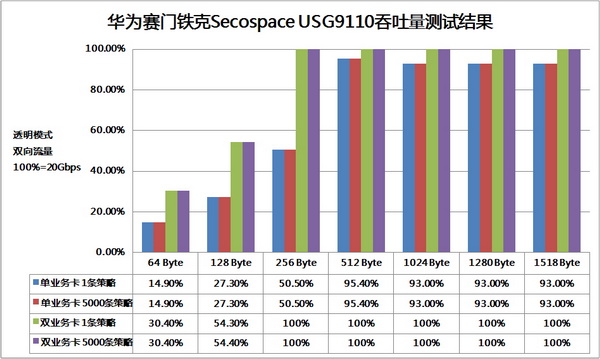 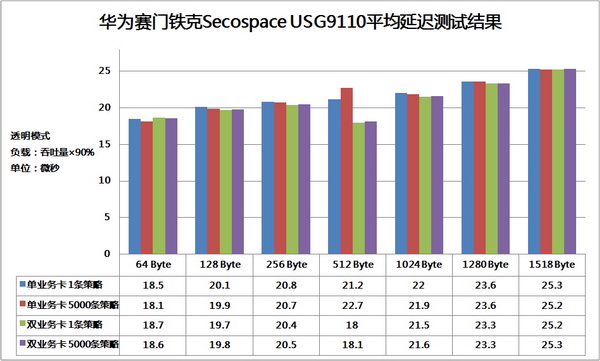 吞吐量与延迟是防火墙产品永恒的性能指标。我们按照RFC2544规范的要求,使用思博伦SmartBits网络层性能测试仪对透明模式下的两个10Gbps链路进行了测试。USG9110在配备单块业务卡的情况下,64Byte帧长时的双向吞吐量接近15%,256Byte以上帧长时超过90%。而在配备两块业务卡的情况下,只要带宽不成为瓶颈,吞吐量就都可以翻番,达到了智能分布式处理最理想的效果。平均延迟方面,单/双业务卡下的测试结果几乎没有区别,显示出分布式处理并未给业务流程带来额外的开销。TCAM的引入理论上可以大幅增加访问控制的实现效率,我们在USG9110上加载5000条策略后重复进行了测试,结果未发生丝毫变化。 吞吐量与延迟是防火墙产品永恒的性能指标。我们按照RFC2544规范的要求,使用思博伦SmartBits网络层性能测试仪对透明模式下的两个10Gbps链路进行了测试。USG9110在配备单块业务卡的情况下,64Byte帧长时的双向吞吐量接近15%,256Byte以上帧长时超过90%。而在配备两块业务卡的情况下,只要带宽不成为瓶颈,吞吐量就都可以翻番,达到了智能分布式处理最理想的效果。平均延迟方面,单/双业务卡下的测试结果几乎没有区别,显示出分布式处理并未给业务流程带来额外的开销。TCAM的引入理论上可以大幅增加访问控制的实现效率,我们在USG9110上加载5000条策略后重复进行了测试,结果未发生丝毫变化。
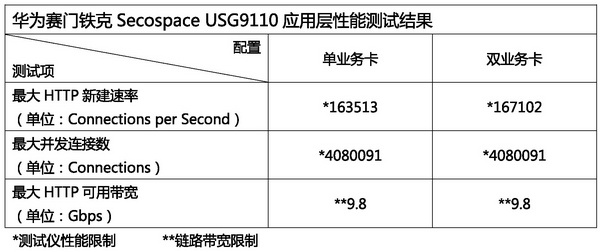 随着互联网应用技术的变化,防火墙的连接处理能力已逐渐超越包转发性能,成为用户选型时最关键的评估指标。而USG9110在这部分测试中表现出来的性能,令人相信华为赛门铁克的工程师们深谙这一点。我们按照RFC3511规范的要求,使用Avalanche3100应用层性能测试仪考察了USG9110在透明模式、加载5000条访问控制策略情况下的性能。遗憾的是,在对HTTP新建速率和最大并发连接数进行测试时,即便只配备单业务卡,测试仪还是先于USG9110到达性能极限。虽然我们无法验证官方给出的性能数据,但从测试仪达到满载时USG9110的CPU资源占用情况推断,该产品“单卡25万HTTP新建/400万并发连接、双卡性能增加一倍”的指标合情合理。而在最大HTTP可用带宽的测试中,9.8Gbps的实测结果也只是10Gbps链路能够达到的最大性能,USG9110处理起来显得游刃有余。 随着互联网应用技术的变化,防火墙的连接处理能力已逐渐超越包转发性能,成为用户选型时最关键的评估指标。而USG9110在这部分测试中表现出来的性能,令人相信华为赛门铁克的工程师们深谙这一点。我们按照RFC3511规范的要求,使用Avalanche3100应用层性能测试仪考察了USG9110在透明模式、加载5000条访问控制策略情况下的性能。遗憾的是,在对HTTP新建速率和最大并发连接数进行测试时,即便只配备单业务卡,测试仪还是先于USG9110到达性能极限。虽然我们无法验证官方给出的性能数据,但从测试仪达到满载时USG9110的CPU资源占用情况推断,该产品“单卡25万HTTP新建/400万并发连接、双卡性能增加一倍”的指标合情合理。而在最大HTTP可用带宽的测试中,9.8Gbps的实测结果也只是10Gbps链路能够达到的最大性能,USG9110处理起来显得游刃有余。
 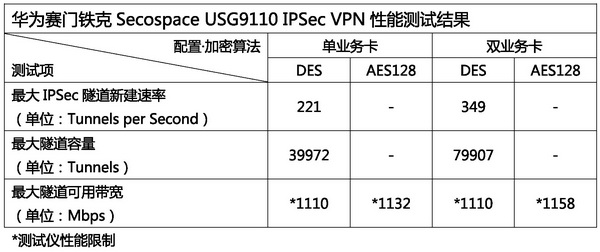 防火墙集成IPSec VPN接入已经是业界的事实标准,许多用户为了业务的安全,也在进行愈发复杂的VPN部署。借助高性能硬件平台,USG9110也提供了相当强悍的IPSec隧道处理能力,并且同样可以借助更多的业务卡实现性能的进一步提升。测试结果也证明了这一点,在野蛮+快速/DES+MD5的参数配置下,该产品配备单业务卡时的隧道新建速率达到每秒221条(峰值速度,平均稳定在170左右),最大隧道容量接近4万;双业务卡时,两个指标都有了将近一倍的增幅。需要说明的是,我们并没有对新加入的业务卡进行任何设置,USG9110可以自动进行VPN隧道协商的分布式处理,效果也令人满意。在隧道的可用带宽测试中,测试仪的性能又很不幸地成为瓶颈,实测得到的结果只有官方标称值(单业务卡8Gbps)的零头。有了如此强大的性能和分布式处理机制做基础,相信在网络带宽没有发生量级变化前,USG9110可以胜任任何规模的VPN部署。 防火墙集成IPSec VPN接入已经是业界的事实标准,许多用户为了业务的安全,也在进行愈发复杂的VPN部署。借助高性能硬件平台,USG9110也提供了相当强悍的IPSec隧道处理能力,并且同样可以借助更多的业务卡实现性能的进一步提升。测试结果也证明了这一点,在野蛮+快速/DES+MD5的参数配置下,该产品配备单业务卡时的隧道新建速率达到每秒221条(峰值速度,平均稳定在170左右),最大隧道容量接近4万;双业务卡时,两个指标都有了将近一倍的增幅。需要说明的是,我们并没有对新加入的业务卡进行任何设置,USG9110可以自动进行VPN隧道协商的分布式处理,效果也令人满意。在隧道的可用带宽测试中,测试仪的性能又很不幸地成为瓶颈,实测得到的结果只有官方标称值(单业务卡8Gbps)的零头。有了如此强大的性能和分布式处理机制做基础,相信在网络带宽没有发生量级变化前,USG9110可以胜任任何规模的VPN部署。
测试后记
这是一次艰难而顺利的测试。为了搭建与USG9110相匹配的环境,我们在测试仪的协调方面颇费周折;而在性能测试过程中,该产品表现稳定,业务的分布式处理效果也颇为出色,使实测数据与预测值大多吻合,又节省了许多时间。我们认为,在软、硬件系统方面有着深厚积累的华为赛门铁克,对USG9110这种采用智能分布式处理机制的安全产品已有充分的驾驭能力。深入了解用户的安全需求,扩展USG9110的功能特性,也许应该是产品团队下一步的工作重点。
| 

 (6个打分, 平均:4.17 / 5)
(6个打分, 平均:4.17 / 5)



这软文写得,挺牛的。有没有应用层的测试?
“USG9110在配备单块业务卡的情况下,64Byte帧长时的双向吞吐量接近15%”
—>我眼花了吗?这个值ms很低啊,怎么就拿出来吓人了。。。
IMHO,我对这篇文章的文笔保留个人disagree的意见。产品评测,要的是朴实无华。好坏让人去说。
下面这些话略微有点露出胳膊,然后鲁迅就想到了其他部位。。。
“这块业务卡的设计十分惊艳,其思路和做法在安全产品范畴内实属罕见:华为赛门铁克的工程师在一块业务卡上集成了两颗运行在950MHz的NetLogic XLR732多核多线程处理器,提供了强大的计算与转发性能;而针对快速转发前访问控制对性能造成的微弱影响,更是不惜成本地采用了通常出现在高端路由器上的TCAM来进行硬件加速。除此之外,作为智能分布式处理的关键因素,数据流的调度分配由业务卡上自行研发的FPGA逻辑实现。它可以根据多种算法,实现不同的负载均衡模式,将流量下发到单块或多块业务卡上的处理器进行处理,是当之无愧的交通枢纽。单从硬件规格上看,这块业务卡已经体现了华为赛门铁克优秀的硬件研发实力,其水平在国内外均处于领先行列。”
FPGA估计就是打Seq ID的,否则无法报序。
两片732,还挂了TCAM。是不是贵的跟什么似的?
试着算了如下一笔帐:
假设400Hz的MIPS没有TCAM这些高档玩意儿的情况下,check 1000条策略性能200Kpps(多说一句:在一定的策略数范围以内性能差不多)。
以这个200Kpps为基准,计算USG9110的性能水平:
一个vCPU: 950/400*200Kpps = 475Kpps
一个Core: 475*4 = 1900Kpps(RMI逢人就说IPS(instrctions per second)有多么地高,所以就直接给他乘上4)
七个Core: 1900*7 = 13300Kpps(留4个vCPU给Control plane)
换算成bps: 13300/1500 = 8.87Gbps
就算IPS打个对折,8.87/2 = 4.43Gbps
USG9110两片732还挂了TCAM。20Gbps*0.15 = 3Gbps
请各位在此基础上展开广泛讨论。:-)
嗯,的确。RMI似乎对他们新货里的4issue很鼓吹。。
1)由于USG9110具有智能负载均衡的能力,当一块业务卡被拔出时,该卡承担的所有任务会被自动分发到其他业务卡进行处理,最大化地减小了上层业务中断的可能性。
>>这个能介绍得详细点吗?个人认为这个东西是个难点。
2)用TCAM查policy,是不是有点浪费。还有就是容量够不够?
“华为赛门铁克的工程师在一块业务卡上集成了两颗运行在950MHz的NetLogic XLR732多核多线程处理器,提供了强大的计算与转发性能;而针对快速转发前访问控制对性能造成的微弱影响,更是不惜成本地采用了通常出现在高端路由器上的TCAM来进行硬件加速”
————————————
这个是RMI XLR732做数据面的标准配置,例如:
CCPU的ATCA_XE50(RMI XLR732)
Radisys的ATCA_7220(cavium5860)
Emerson的ATCA_9305(cavium5860)
————————————–
(1)64byte的小包效果好象也不是太好!
(2)系统满负荷运转测试和使用部分代宽还是有差别的!
to 陈怀临
我想贴图,怎么样?谢谢!
现在搞了UTMS+,貌似蛮牛的
透明模式双向15%,如果接口同时支持路由的话,貌似软件还是不错的,一般软件实现的透明模式性能都要比路由模式差
一看这面板就知道是国产山寨货,
啥时候我们也能多关注一下这些细节。
透明应该比路由效率高啊,怎么反过来了?把流程列出来,好好琢磨琢磨。
是,整个中国和人就是山寨,可惜现在还大不过美寨
架构已经比SRX5000先进了,至少不像SRX业务板上需要一个CP做控制
这文档写得太华为了,除了这里头没有我司。都这么久了,怎么还没点进步呢。。。
这不是发表在公开媒体上的吗?怎么像个内部的技术评测报告?貌似写得很内行,架构啊什么的谈了一大堆,数据也有,实际没有大局观。
如果用学术论文评价的那几句话来说,这文章没说清楚,做这个产品的市场背景是什么,为什么做这个产品,这个产品在和类似的产品竞争的时候主要优势是什么;
感觉只是在说自己解决得了防火墙比路由器慢的问题,然后给了一堆术语,和评测数据;完全对读者不负责任,学术会议的大牛报告肯定是深入浅出的。
哪位老大能说说这产品,比起其他的防火墙产品强在哪里啊,还有这个市场的现状和背景?我咋看了半天也没看出来。。。
不明白,不用CP先进到什么地方了?很感兴趣。
其实敢将实测性能贴出来,本身就是一种勇气,试问多少声称性能很牛的设备,能达到这种程度呢?我佩服这种做法,顶!
1. 没有将IO卡的结构讲一下,用的是EZ?。例如没有CP,first packet是如何处理的?
2. 每个业务卡处理和管理局部session。可以。但ALG如何处理?
3. FPGA不是个亮点。。。
http://www.nsfocus.com/ 2U 的盒子,一样的性能
想不到一天没来就这么多评论,感动。有朋友说我软文写得不错,先行谢过,没想到我也有去厂商Marketing或者公关公司的潜质。我想我不排斥这个工作,有意者可以邮件联系:)还有朋友说我忘了写“我司”,这纯属杯具。我曾经想过去华为,可是华为不要我……所以我只能写写媒体评测报告,写不了内部的技术评测报告,也干不了产品经理的差事。
但是站在媒体实验室角度,我是不会把评测报告写成软文的。在弯曲评论也发过不少篇产品评测内容了,基本上应该说是以测试数据为本,再辅以客观的评价。而这次陈老师在3楼用黑体标注的不太客观的文字,完全是我自己的想法,是思考后得到的结论,否则我也不会写。华赛的这块业务板,确实是我见过的国内安全厂商推出产品中(军品、工控机不算)集成度最高、设计最复杂的一块办卡。而国内安全厂商又有几个能自己设计硬件,这掰着指头也数得过来。so,眼见为实,我觉得这个结论下得有根据。最后说硬件研发实力在国内外均处于领先行列,这话留了伏笔,没说是最好,但是确实不错了。至于为啥一个卡上俩732,还有TCAM,我只能说华赛设计产品时就有自己的考虑。我也觉得成本挺高,可能对于华赛的量来说就不算啥了。再说,硬件选型时肯定不全为了性能考虑,听说思科新的5585还用x86,很大程度上就是因为软件架构决定的。
再上升一层,陈老师说产品评测要朴实无华,我部分认同这个观点。如果是官方背景的第三方评测机构或者用户自己的标前测试,那必须客观中立,按流程画表、填数、盖章;但是作为媒体评测来说,我认为“评”的重要性大于“测”。“评”应该是“测”的升华,体现了个人对产品的观点、看法乃至倾向性,这就是比表格+数据更有价值的地方。厂商实际上也希望媒体评测报告中有这些因素,否则还费哪门子事去做什么测试,以广告插页的形式附赠产品的Datasheet不就得了?所以,我在文中清楚地表达了自己的看法:我觉得USG9110是款不错的产品,在国内安全厂商推出的产品中属于技术领先范畴。对于有人提到和SRX架构先进性的对比,我是这样看:Juniper的SRX5000系列在设计理念(甚至是对安全的理解)上都和华赛USG系列有很大不同,CP的存在使得SRX的HA能力达到一个其他产品无法比拟的高度,同时也在一定程度上成为性能瓶颈。
多说几句,DUT的技术实现是测试前必做的功课。只有充分了解产品,才能制定合理的测试方案,以及推测出测试中可能出现的问题。防止被蒙当枪也是目的之一,比如一台用了一个XLR732的IPS号称20Gbps的吞吐量,又不告诉是怎么实现的,那我不给你测,也不给你写。当然,有些涉及到客户机密的东西在写的时候肯定会做一些处理,我总不能签了NDA又哗哗地往出翻。所以评论中提到的各类技术细节问题,我没法回答,只能说报告中体现的内容已经是用户或读者主要关心的问题了。其实我觉得华赛以及华为现在的心态好多了,挺开放的,也通情达理,连处理器型号都能在报告中出现了,更别提产品手册了,都写的很清楚。就这么不起眼的一个细节,有多少厂商能做到?
客观地说,我的能力还不能完全驾驭这个级别的产品。虽然测试过程中学到不少东西,但也有很多细节还有待研究。水平有限,文中诸多不妥之处,还请各位指点。感谢。
说一句,我以为这东西是华为内部的人写的,用来介绍自己产品,打市场用的,所以打了个负评价;如果是媒体实验的测试报告,还是挺好的。没看全标题,对不住作者。
如果是媒体实验室当然不了解华赛推出这产品背后的想法,和动机。
如果接口只是纯透明模式是会比路由性能好,但基本上用户实际使用都要求同时支持路由,即混合模式,这种情况下就会比纯路由差。年初有个网界网的测试UTM报告,启明多核UTM的透明模式性能基本只是路由模式的一半。
以前听说华赛用RMI不是CPU直接接收数据包,而是有个接口卡收包后再分配到各CPU去处理,从而容易实现负载均衡的,这个接口卡就是那个FPGA吧,CPU上应该还是跑RMIOS实现防火墙功能吧。有知道细节的dx说说
如果在IOC上做load balance,而且还能cover大部分case,那就是挺牛逼的。还能支持热插拔,这个设计不容易。顶一下。
这个一定会大卖的。
我不是华为的,我们公司2年前就开始做类似的东西,一年前已经在wa测试过了。我们现在方案是包处理板+nehalem刀片+200g交换板+无瞬断光保护,足以应付安全的各种应用了。支持2u2槽、5u6槽、13u14槽atca机箱。pos板有双np3,支持2×10g pos,2×10g以太网(lan、wan),8×2.5g、8×622m、8×155m pos、8xge接口,rtm后板后扩20ge。但是。。。。。。。。。。。。。。。。。。。。。。
哎,东西是好东西,但是技术决定不了什么的。
9系列产品应该是华赛的一位朋友领导做的,他们确实是钢铁一样的队伍。我很佩服。
国内其他安全厂商的研发就一个字,扯。
如果不提醒,读者一定会认为贴错图了:你小样为啥把NE5000 Core Router的图贴出来了。是的,这就是华赛的9300. 感觉是拿NE5000的Chasis做的系统。。。这确实有点Over Kill和不理解。。。
http://www.huaweisymantec.com/en/Product___Solution/Products/Security/Firewall_VPN/USG/Secospace_USG9300/
在华赛的网站上,如下数据。很奇怪,不理解。
http://www.huaweisymantec.com/en/Product___Solution/Products/Security/UTM_Firewall/USG/Secospace_USG9100/Product_Date_List/Specifications/
Model USG9110 USG9120
Number of slots 4 pairs for service boards and interface boards. 12 pairs for service boards and interface boards.
Throughput 10 G x 4 10 G x12
Number of concurrent connections 4M x 4 4M x 12
Number of new connections per second 250K x 4 250K x 12
Number of virtual firewalls 1024 1024
Product USG9310 USG9320
Number of slots Eight slots, in which service boards and interface boards can be inserted. Sixteen slots, in which service boards and interface boards can be inserted.
Throughput 10 G × 4 10 G × 8 (9300的throughpu不比9100好????)
Number of concurrent connections 4,000,000 × 4 4,000,000 × 8
Number of connections established per second 250,000 × 4 250,000 × 8
VPN performance 4 G × 4 4 G × 8
Quantity of VPN tunnels 40,000 × 4 40,000 × 8
Virtual firewall 1024 1024
从数据上来看,9100已经beat了Juniper SRX 5800的相关数据:
http://www.juniper.net/us/en/products-services/security/srx-series/srx5800/#specs
Firewall performance (max)
120 Gbps //大宋9120 120G?
Maximum concurrent sessions
10 Million //全部输给华赛。
New sessions/second (sustained, TCP, 3-way)
350,000 //USG 9K系统全部压倒。显然是无CP导致。
似乎是东风已经压到了西方。中国人民在网络安全领域,像其他高科技领域一样,终于站起来了。
答案通常是:当毛润之忽悠我们父辈所谓帝国主义从来就是纸老虎的时候,他自己在中南海学英文,而非学俄文。。。
无奖问答:USG的9K系列的7寸在哪里?
去华为不要,估计因为体格不行。现在已经是华赛了,大家还在说华为,华为的惯性太强了
回26楼
国内做安全的大都都有华为中兴的案底,呵呵
队伍都是一样的
呵呵,这文章,评的水准很低。更像一个枪手。
比较感兴趣的是在多个业务卡的情况下,单个session的信息是如何共享的呢?
这个性能是先测单板的性能,然后就是线性增加。在测试中如何做到这一点。这涉及到接口板和业务板流量的映射,也就是说,真正的最大值是如何测出来的?
从Juniper或者Cisco的技术报告,通常能看出许多东西来。而且也没有整的一个什么怀春少女(或者红墙少妇),羞羞答答,欲罢还休的样子。
华为也好,华赛也好。简直是。。。
有个弟兄说过:华为信息保密,目的是不让敌人知道我们有多差,而非Otherwise。
开放的华为才是新华为。否则,没意思。。。
NetLogic XLR732这种平台的,我们公司现在就用这个平台哈,而且还加了一个2008做DPI,给安全厂商推,基本上没有几个用,成本太高太高了,一般烧不起。
关于并发连接的评价是有问题的,首先要确定每块业务卡上的状态表是全局的还是局部的,如果是全局的,那么一块卡的最大并发连接数就是整机的最大并发连接数,多块卡不能增加这个数据,因为每块卡上的状态表其实是一致。如果是局部呢,那么就要问问怎么解决非对称路径问题,NAT ALG问题,以及状态表的维护和老化等。如果说不清楚,那么基本就是在瞎掰!
HW E8000E=HS USG9300,分别主打运营商和企业网市场。其实就是在NE80E上增加防火墙处理卡。
USG9100是HS自己开发的防火墙。
SRX5000和USG9300/9100相比架构非常不同:
1、作为防火墙,SRX5000有全局统一的状态表(在CP上),整机是一个系统;USG9300/9100可以看作是将多个防火墙插进同一个路由器机箱,每个防火墙的状态表相互独立,没有全局的状态表,整机是多个防火墙系统;
2、SRX5800在硬件(多核CPU)、软件(JOS 9以上)方面均支持IPS等DPI业务,USG9300/9100目前还不支持DPI业务;
3、SRX5800的SPC和IOC数量可以灵搭配,USG9300/9100的接口板和处理板必须成对使用;
to 楼上:
如果是多防火墙系统,那么也就意味着其性能并不具有扩展性,每块卡就是一个独立的防火墙,那个机框也就和一个机柜本身没有什么区别。也就是说,买一个配置4块防火墙卡的USG9100,和买4个小包3G处理能力的防火墙没有区别。那我干嘛还需要这个东东呢?这是所谓的分布式转发吗?
分布式转发仅仅是L3转发,而不是业务分布式处理。
USG所有性能参数均为单板性能 x 业务板数量:
http://www.huaweisymantec.com/en/Product%5F%5F%5FSolution/Products/Security/UTM%5FFirewall/USG/Secospace%5FUSG9100/Product%5FDate%5FList/Specifications/
to zeroflag:
USG9K的架构,从业务处理角度看,与多台防火墙放在一个机架里没有区别。从设备角度看,将板卡之间的物理连线变为背板走线,同时设备的可靠性也有所提高。
这种做法现在很流行,天融信的100G防火墙是中兴89交换机+自己的防火墙卡,H3C也在交换机插多块防火墙插卡冒充100G防火墙。运营商似乎比较认可机箱+处理卡的方式。
to os9600
我说的问题是这种结构本身并不具有扩展能力,因为每块板卡都是独立的。就算每块卡有10G的性能,10块卡也凑不出100G的性能。这不能叫分布式转发,也不能用“单卡×卡数”来计算整机性能。所以,USG也好,擎天也好,在这个方面都属于偷换概念,说重一点就是虚假宣传。
而J的SRX和H3的F5000的结构才能算是分布式转发,用“单卡×卡数”来计算整机性能才是有意义的。
至于说运营商接受机箱+插卡的方式也是它们不得以,否则连招投标所必须的三家品牌都凑不齐的。
同意楼上。
真正的分布式防火墙应该是L2/L3分布式转发+防火墙分布式处理,无论是转发还是业务处理都应该有基于全局的整机控制点,如SRX的SCB和CP。
目前业界的防火墙,好像只有SRX5800是这种架构,Forti的5000和3950也是机箱+多防火墙的架构。
H3的F5K有个问题:交换/主控板没有冗余
问题大概清晰了:
USG其实是多个独立防火墙的有机(或者无机)叠加。一个防火墙i的traffic似乎不能出墙,带着红杏包去另外一个防火墙j的业务卡。。。
如果是这样,就没劲了–就是婚姻终生制(一个IO卡与一个业务卡是pair的)。
不是一个IO对应一个业务卡的,再怎么,华赛也不是这么出来混的
一天又是20层楼啊,看得有点晕,有些明白有些不明白,再想想。
貌似是对名词的定义理解有偏差,比如,什么叫做分布式防火墙?这是一个学术定义还是一个市场包装的定义?反正我是当做后者看待的。分布式防火墙一定要有基于全局的整机控制点么?那我觉得这个定义下得太J了,一时想不起其他产品有类似设计。
我觉得,既然叫防火墙,就专品专用。把状态检测、ALG、NAT、路由、L2/L3抗攻击等等等等做好了,就无愧于防火墙的称号。哦忘记了IPSec VPN,这应该也算是防火墙的事实标准了吧。只要这些业务和转发做到分布式处理,并且这个分布式不用人为干预(例如交换机+FW模块),我认为就应该算是分布式防火墙。
华赛的USG9110就是这么做的,状态的处理和数据转发由所有业务卡上的所有处理器完成,纯并行化。它没有类似CP这样的设定,所以确实没有整体控制的概念。但文档显示业务卡可以做1+1热备,可惜我没实测。
我理解USG9110的处理流程,应该是首包从一个口进来,先到对应主控板的FPGA上,根据策略分配到不同处理器进行处理。建完状态如果permit,则甩到相应出口。包到FPGA的时候,可以原路返回,如果需要也可以上背板去别的业务卡上的FPGA,再到对应接口卡出去。
因为业务卡是连到交换背板上的,所以数据包也可以被分配到其他业务卡的处理器上,这一点测试结果可以证实(包括IPSec VPN处理也是,我们一直就用同一块接口卡上的2个10Gb的口进行测试)。
USG9110的业务卡和接口卡是必要不充分的对应关系,接口卡数量不能超过业务卡。这应该是ATCA架构决定的吧,大小卡,小卡从大卡上取电,数据通路也到大卡。小卡根本不连背板,所以卡上貌似没有上EZ的必要。流的去向都由FPGA负责,所以我才觉得FPGA是USG9100系列的核心。
但是业务卡数量可以超过接口卡,比如4个业务卡为1个接口卡服务,这就不是婚姻终生制了吧?从这个角度说,用单业务卡性能做乘法得到整体性能也是有根据的。USG9300应该是业务卡和接口卡都连接到交换背板的,和SRX类似,接口卡上应该有NP做分流,NP维护一个大表。但是貌似也没有CP,有机会测测看。不过,USG9100和USG9300的软件系统应该在逻辑上是一样的,在我看来都算是分布式防火墙。
至于H3C的F5K,貌似既不是分布式防火墙也不是交换机+FW模块,倒是有点像NetScreen老的SSG,只不过主控的Intel换成了RMI,接口卡上的MAC+PHY换成了FPGA+PHY吧。就像上面有朋友说技术不能决定什么,没错,存在就是合理的。我觉得这产品非常成功,很对国内用户的胃口,卖得好是应该的。
SRX上CP的存在到底是为了什么?体现在什么特性上?中国的用户是否需要这个/些特性?还请各位多指教。感觉CP在SPU或者SPC不正常的时候可以省却一次策略匹配,但是后面应该一样还得做会话同步。换做USG9100,应该也就是重新做一次首包流程吧,好像也不费什么资源。
to楼上:
打流量时是一条流还是多条流?只打一条流时也能在多业务板间负载均衡么?
业务卡数量大于接口卡数量才有意义,因为接口卡L2/L3转发能力远大于处理卡L4~L7处理能力。如SRX5000和USG9300都有40G线速的接口卡,但没有40G线速的防火墙处理卡。
根据J官方网站资料,SRX5800的典型配置是4块40G的IOC+8块SPC,接口卡:处理卡=1:2,接口卡也可以只配1块,其它槽位都插业务卡。
HS网站资料显示,插槽数量为4对(9110)和12对(9120);
一条流打到多个业务卡,这个不可能,太难了。
莫非9100上还把数通的TM芯片(FPGA)也整进来了???
To 48:多条流。测试过的能做流分配的设备都如此。一条流负载均衡的情况有可能做到,要看FPGA或者NP里的逻辑,不过现实中应该不会有这样的应用环境吧。
维护全局最大的作用就是多卡做分担,还有就是处理特殊情况。比如网路中有对称路径的情况下,一条流的数据包是有可能在A卡回来,也有可能在B卡回来。最典型的就是叉形连接备份时,上端两台路由器出现了倒换的情况。如果维护了全局状态表,那么就不会有任何问题,但是如果没有全局状态表,那么就需要做板间的备份,但是只能双板备份,不能多板备份,这就是为什么说USG9100实际上是一堆的盒式防火墙叉到一个箱子里面的原因。
另外考虑前面提到,业务卡和接口卡分离以后,多业务卡为一块接口卡服务的情况。没有全局状态表,一条流的状态建立起来以后,就固定到一块业务卡上了。多块卡是要靠一定的规则进行负载分担的,目前的实现都是基于ACL的,也就是说两个IP之间的通讯是固定死在某一个业务卡上的,即使是这个卡的负载已经很高了,也不可能转移到其他卡上去。那么为什么不能做动态负载呢?因为没有全局状态表。后续的转发不知道应该通过那个卡来进行。
那么加一个类似于负载均衡的功能行不行呢?可以,但是一样需要全局的状态表才行。
以上就是为什么分布式防火墙需要全局状态表的原因。
维护全局状态表的缺点是,单板的并发连接数就是实际的整机并发连接数,但是只有这样多板才能作为一个整体工作。
H3的F5000本质上是一个有全局状态表的分布式防火墙,但是没有做业务卡和接口卡分离的设计。因此也不会有多块业务卡为一个接口卡提供服务的情况。另外就像上面有人提到的,没有主控冗余设计。
接口卡也业务卡不分离,接口容量上不去啊。还有这个卡的成本如何?
如果老韩确认在只用两个10G接口打流量,加多块SPUA比一块SPUA的情况下性能有显著提升则我认为USG9110确实是分布式处理
to53:
受教了,我现在理解CP存在的意义,除了可靠性外,很大程度上是让负载分摊的更均匀,更智能。其他基于多FPGA或者多NP的负载分摊,也只能因为没有全局状态而不能达到非常合理的效果,不知道这么理解对不对。
那SRX5000的CP应该也不会只是一个732吧,那瓶颈太明显了。但如果是多个CP,那又存在同步、可靠性等方面的问题了吧?
这里有没有华赛的人,站出来解释一下,或者发布一下91的转发白皮书。省得大家在这里猜测
to 老韩:
一般说来,CP做的事情是做状态表的新建、老化和同步这一块的事情,瓶颈还不是很大。最多影响整机每秒新建的速率。并且CP上可以不只一块CPU的,多几块CPU也行,只要通用内存就可以了。SRX的引擎上面貌似是两个732的CPU。另外两个CP做互备,其难度不会高于两台防火墙做热备,不是什么太大的问题。
状态表的一般性维护和数据包的转发可以放在业务板的FPGA上做。如果有全局状态表,一个接口板收到非新建连接的数据包以后,可以随便丢到任何一个相对空闲的业务板上去处理,不需要查任何表,也不需要走CP。
说点题外话,有状态表好处之一是对于非新建连接的数据包不需要再查路由表来决定转发路径。所以我觉得有了状态表可以省掉FIB表甚至CAM表。不过无论是juniper、cisco还是华为都不可能这么做,因为她们的NOS还要工作在路由器和交换机上,把FIB表、CAM表省略了,那些东西就工作不起来了。这方面只有纯安全厂商可以这么做。
To droplet:
那块卡的接口密度是做不上去呀,也就2万兆的水平。至于成本就不晓得了。不过从几次运营商集采时候的报价来看,成本应该不会非常的高。
另外,个人觉得H3的F5000是一个实验性的,或者说做了一半的产品。倒不是说产品稳定性上有什么问题,而是没有做接口卡和业务卡分离这块说明,H3在做F5000的时候还没有能够完全处理好新建和状态表维护之间的关系,尤其是存在多条路径的时候,应该还没有特别大的信心。估计H3的下一代高端防火墙可能就会彻底采用业务卡和接口卡分离的做法了。
不过也仅仅是猜测,H3也可能是处于成本,产品定位或者使用环境等多方面的考虑,觉得现阶段做在一起就可以,以后有必要的时候在分离。这就只有H3自己的人才清楚是怎么回事了。
CP只处理1%的流量就是好的设计,所以说不会成为瓶颈的。CP需要简单,只一个基于session的load balance就够。zeroflag说的没错,CP对CPS有影响,但是对throughput,latency之类的测试没有多大影响。
其实如果有一个ccNUMA芯片。整一个Virtual CP。就什么都解决了。例如QPI一拉。。。N路互联。
我评价一下吧:恭喜苏总,李总,杨总和弓首席。希望迅速的把Hillstone,PAN,J都灭了。倒时我请客:-)
感觉Routing方面的Feature和QoS方面弱了一点,或者在网站上没有看到。
如此热闹,我去搬小板凳….各位继续….
To zeroflag:
58楼我不是很赞同,CP应该只是负责负载分配工作,以及全局状态表的维护。流建起来后,CP不参与业务处理,但接口卡上的NP和SPU之间应该是有对应关系的,不是随便扔给哪个SPU都行吧。不过,只要后面的SPUs足够强劲,CPS方面的瓶颈应该还是CP带来的。
59楼我倒是赞同后面那部分,华三应该是觉得没必要把F5K做成业务、接口分离的结构,这个平衡找得不错。我对F5K业务接口卡上的FPGA比较感兴趣,哪位老师能给讲解下?不胜感激
FPGA可能是做ordering,也有可能是MAC到XLR的一个adaptor,但不会是做load balance或者QoS,这些活对FPGA太复杂了。连swtich fabric需要用FPGA做adaptor吗?
多个chip互联,做一个强大的virtual CPU,这个不错。但是内存怎么办。需要64bits才能搞定,不知道os对NUMA的支持现在到了能实用的阶段了没,我指的是在嵌入式里面的应用。
to zeroflag:
接口卡、处理卡分离不是分布式处理的必要条件。在F5K的架构中,主控板集成了croossbar,从任意一个板卡进入的流量都可以无阻塞交换到其它板卡,因此可以实现同一条流在不同板卡的负载分担。关键是F5K的主控板嫩否实现流量的调度。
对F5K不采用接口卡、处理卡分离的个人看法:
F5K单板处理能力不超过10G,整机性能不超过40G,每个板卡配置2个10G接口绰绰有余。采用接口处理一体化的板卡可以简化设计、节省体积。
想了下,觉得SRX上CP的意义应该不只维护全局状态那么简单。如果开启IPS,还能像防火墙这样为各SPU精准均衡负载么?
66楼说得强大啊,颠覆了我对F5K的一切认识和推断……
这个平台离J的SRX还有一定的差距。在可扩展性,以及未来的升级,都是个麻烦。比如端口数量,比如处理性能的增强等等。
F5K的“从任意一个板卡进入的流量都可以无阻塞交换到其它板卡”只是个传说
帅:
我就知道这贴子能把你这条鱼给炸出来,对于F5K和SRX你都应该很了解,在不惹麻烦的前提下,说点真实情况吧!
to 70楼:
F5K是否是crossbar并不关键,即使是总线架构,处理80G的流量对H3来说也不困难。
问题的关键是,F5K的主板板能否把同一条流分担到不同接口板。如果不能,F5K就没必要实现接口板之间的转发了
把一条流分担到不同的接口板,目的何在?有何意义?order如何做?
TO老韩
对于老韩提到的分布式架构有不同看法。按照“只要这些业务和转发做到分布式处理,并且这个分布式不用人为干预(例如交换机+FW模块),我认为就应该算是分布式防火墙。”那么如果把众多的盒式防火墙旁挂到交换机上,通过策略路由进行负载分担,也不需要人为干预啊(即使是模块也需要配置各种引流策略)。但这能算分布式防火墙吗??
再看看9100的架构,所有的业务板卡负载分担只能针对一个接口板实现,正如前面各位大拿讲的,还不是基于状态表的分担,说白了就是多种基于五源组的HASH算法。因此,9100只能算是在“板卡+交换机”和”纯分布式”中间中到了一个平衡点,比“板卡+交换机”多了统一管理、更多的分流算法而已。
还有一个问题一直没有明白,9100的各个业务单板能实现统一地址的全局NAT吗?如果按照各位大拿的分析,业务板就是一个完整的FW,既然没有全局统一状态表,如何实现全局NAT?
业务板与接口板之间的流量是基于什么转发的,各自与背板之间的接口是怎么样?这都决定了9100是否是真正的分布式FW!!!
我来写一个USG9110黑盒子分析调查报告如何?我不要华赛小样(:-))任何资料,从PUBLIC数据和资料来讨论,类似与我整CRS和ASR。。。华赛的弟兄们,想从网站上撤下来的东西,请抓紧时间。马上是大宋的国庆了:-)。
TO os9600 :
上次与Forti的哥们聊天,Forti的5000系列也是ATCA的架构,多个FW板卡无法统一管理、无法智能调度。但是其新推出3900系列貌与似H3C F5000的架构类似。
SRX的3000与5000都是采用类似的架构,都有CP、NPU、SPU的概念,只不过5000的转发引擎SBC与路由引擎RE分离。此外,每个业务办事都是2个多核芯片,可以通过协商完成CP的选举。一般一个CP负责调度3块业务板,这就是为什么在网站上SRX的典型配置是7个SPC实现30G吞吐量,每块5G性能,6块达到30G,还有1块做调度。
但是SRX有一点问题,他也不能做到全局的状态表备份,CP只是一个简易全局表,一旦一块板卡故障,流量就转发。
如果需要全局备份,那这个工作量、算法、内存等一系列问题都出来了,难度不小
个人拙见!!!
F5K肯定做不到板间的负载分担。讨论负载分担一定要建立在业务板和接口板分离的前提下,否则是没有意义的。
因为业务板与接口板合一以后,一条流的进接口和出接口就直接决定了了一条流在哪个板上处理,其他板不可能参与到其中去。但是这个过程确实不需要主控板的参与。因此可以算是分布式转发。这其实和交换机和路由器分布式转发的情况类似,交换机、路由器也不可能做到多块板之间的负载分担。
也许是我文章里没写清楚,好像大家对USG9100的架构理解都不太一致。9100上每块业务板上都有FPGA,负责后面接口卡过来流量的分流,每个FPGA和每个XLR732应是全连接的关系,逻辑上可以认为是接口子系统、业务子系统分离,只不过受ATCA架构限制前后同一槽位的两块卡共享一条去交换板的链路。
F5K应该不是这样,我推测F5K的业务接口卡是紧密耦合的,主控板过来的链路直接进快转的FPGA,然后出来MAC和PHY,不同业务接口卡之间应该没有数据交互。因为没研究过真机,所以不知道ALG之类是怎么处理的。不过根据华三的技术实力,解决ALG、非对称路由之类的应该不成问题。再说,F5K的产品设计思路也很明确,就是性价比、投入产出比最高的FW,实际上我觉得他们做到了,用户的接受度也是证明。
我还是那句话,国内运供应商之类的用户,貌似对性能的需求还是远远高于其他细节,合适的就是好的。
要做到全局的负载分担,最好的实现是把报文接收(接口卡)、报文处理(转发板)、首包或者首流分析建表(业务板)、报文查找引擎和表项存贮(查找引擎板),独立出来,进行负荷分担的组织和调度,但这种架构在实际实现中是的技术可行性和市场可行性,不好说
在开始写USG9100的分析。不对呀。USG9100只能支持一个10G的线卡,while SRX可以支持4×10G。USG9300也是只支持一个10G port。
这意味着,USG系列或者只用了一个EZChip,或者是用了自己的一个10G的Forwarding Chip。
something wrong呀。按目击者老韩的报告,每个业务卡是两个RMI的话。应该是两个SPI 4.2接入的20G呀。
但现在Chaisis后面4个10G的Interface IO卡。前面面挂4×20G=80G的Throughput。
这不对呀。。。
去年年底测试过USG9300,看起来9300/9100是类似的架构,单块业务板确实只能处理10G的Throughput,不知道是软件上没有启用;还是硬件上没有连线;
如果是这样的话,USG系列基本上是无法与SRX较量。SRX 5800,如果配4个IOC。可以配到4×40G(理论上)。剩下的8个卡位可以配SPC卡。每个20G。从而可以支持160G的Throughput。。。
奇怪呀奇怪,为什么USG只配一个10G port。。。其中必有大猫猫。。。lets find it out.
kakakaa. 又看了一遍小韩的文章。大概快清楚了。
USG的每个业务卡其实就是10G(或者20G)。如何讲。就是那个FPGA!!!是FPGA接在Switch Fabric上的,而非两个10G的SPI 4.2!
换言之,两个RMI其实是相公。是坐在FPGA后面的!!! 华赛可真有钱呀。。。
从小韩说自己拿到了最新的华赛IOC卡。是两个万G的。从而可以得出,这个FPGA是20G的。。。
邪门呀!!!我接着分析。。。
(早晨起来)接着写:一个FPGA,要有2个SPI 4.2的10G Interface来连接2个RMI。这似乎不错。。。换言之,这个FPGA的Ingress Interface是一个什么20G的?如果USG9100的Fabric chipset是用Dune的,这个FPGA前面应该还有一个Dune的芯片才对。但从小韩的描述,似乎是FPGA直接就连到了Fabric backplane上。
to:Beat “beat HS”
Forti 3950资料比较少,但从网站看,并没有宣称实现整机统一的状态表,只是说内置240G的Fabric,其实5000的Fabric得更好。
3950的亮点是小包20G线速,Forti其它产品性能都是以512K字节计算。
SRX5000状态表备份确实比较复杂,做双机HA时,每个SPC(包括CP所在的SPC)似乎都要互联,调度应该很复杂。不知有没有人了解SRX5000 HA的实际应用情况。
情绪为啥那么激动?
每个SPC都要互联,做双机备份,那是SPC备份,还是整机备份?做整机备份简单一点,每个SPC备份,不知道有没有人敢这样想。
本来想说几句的^_^,但是洗衣机里面的衣服好了。感觉大家对分布式的FW很感兴趣,哪天开个篇大家一起聊聊,J的SRX架构方面和我司的产品却有不同都是各有优劣,没有完胜的。功能颗粒度方面应该远胜我们的USG9300。但是人口红利给中国带来的东西远超想象^_^。只不过我们是不是能在环境和经济上做到完美的统一的问题。
得,工号都直接上来了。欢迎吴总。
欢迎爆料,技术先进是一方面,市场的选择是另一方面。从用户角度来说,哪个更方便,更稳定,更容易扩展,是最终决定产品的命运。
H3C的F5000还这么多人关注,732+PCIE Switch+(N*FPGA+N*(10GE/GE Port))。硬件架构上分布式的样子,集中式的本质,N:X8 Gen1 PCIE。还有什么要问的?
732和PCIe Switch之间是用什么连接呢?SPI4.2怎么转过去的?
F5000:集中式转发+分布式处理+防火墙统一管理。
USG9000:分布式转发+分布式处理+防火墙独立管理。
SRX是分布式转发+分布式处理+防火墙统一管理。
对防火墙而言,统一管理最重要,否则Cisco、Junier、H3C的交换机插上10多个防火墙模块就变成了高端防火墙?
统一管理是什么概念?我记得USG9100是统一管理的啊,一切配置都在主控交换卡上进行,系统自行下发。这和SRX的RE应该一样吧?
集中式转发又是什么概念?貌似F5K的732除了做新建和抗攻击的一部分工作,剩下应该纯粹在FPGA上做快转,这显然是分布式啊?就算从PCIe到其他板出去,也没732什么事。对于连接来说,貌似反倒是集中式处理吧。
不太明白,纯请教
F5K的XLR732处理首包,然后通过XLR732的HT端口向下刷Session,FPGA接到这个Session的时候,再转发的事儿就交给FPGA了。
刷到FPGA,FPGA做转发,这个和路由/交换有什么区别。安全怎么做,应用层的检测也是在FPGA?
FPGA从HT接到Session?不是PCIe Switch么?
不是的,是用了一个HT转PCIe的桥,然后分发到每个子卡上,子卡上是PCIe到PCI的桥,通过PCI连接到FPGA上,用这条路径去刷Session。这是以前的思路,不知道现在是否可以通过PCIe Switch的VC1通道去刷了。
这就是这个系统的问题所在,FPGA就是转发用,最多做到UDP层,至于再往上的application层应用,只能交给CPU去做,呵呵。FPGA做转发性能还是挺不错的,哈哈,当时最开始据说小包转发能达到6.4Gbps。
噢,太好了,楼上提供的信息很实用。这么转来转去的还真折腾,一定得找机会确认一下。
顺便把100楼占了吧!
FPGA做转发不好,不如用ASIC Switch:
1.FPGA贵,发热量大
2.FPGA对包处理比较简单,表项小
3.FPGA带宽小,才6.4Gbps,对普通的GE switch来说不值得一提.
基本上FPGA资源有限,速度瓶颈大,综合后跑个200MHz算不错的了。
FPGA功耗方面不是问题,Xilinx的LXT系列,功耗要小很多了。FPGA对包的处理很简单,提取五元组,然后根据上层下刷的Session进行转发,除此之外还有逐包攻击、ACL、黑名单过滤等。外挂DRAM或者SRAM,表项应该可以扩充得比较大。带宽问题,其实是这样的,总共F5K背板PCIe采用8lane,2.5Gbps。而且我提供的6.4Gbps也就是初期,现在不知道达到多少带宽了,呵呵。
有点意思。打酱油的路过
资源相对有限的FPGA对包只能做相对简单的处理,一般Switch内置的TCAM的功能和性能做ACL把FPGA秒杀了,如果FPGA外挂TCAM和RAM等,成本上去不少了。更别说QoS,L2 MAC,L3 LPM等更复杂的功能.
还有华赛那个好像是Mini ATCA,Fabric平面应该是XAUI接口的? FPGA很难处理不了那么10G口的转发,带宽不够,
估计只支持简单的处理下1G每槽位的流量。
多核CPU+ASIC Switch是做这类产品的极佳选择.多核CPU做Security,DPI,VPN…
交换芯片可以做Local Switching,L2,L3;
Eric做过FPGA吗
to 楼上.哈哈,你有本事就列出FPGA的优点和ASIC pk吧.
我做了N年的FPGA.
F5K,第一步的产品,现在没有人做下一代了吧。下一代是别的Logo了吧?
嘿嘿,据说现在fpga的发展趋势改为那种半订制的ASIC,可以提供一堆的ARM或者MIPS的core供你生成,在顶层调用,然后保证一下时序,最后写个testbench仿真一下下就okay了。fpga最大的优点还是灵活,定制化,越高端的fpga用量少,价格自然就很高。就目前来说,只能做个接口转换,通过外置辅助的一些东东,比如RAM、TCAM来辅助它做一些更高层面上的的东东。它最基本的功能,在网络里面还是转发。
F5K,是H3C的高端产品,内部消息,这个平台会持续5年左右,后续暂时不会开发新的平台。呵呵。
5年?不会吧,我觉得不太可能。不是说新的40G级别的产品已经ok了么,从防火墙到IPS
内部消息是这样的,嘿嘿,这个平台架构在5年内是不会变的。而且有G和Ten G,没必要再去开发别的了。呵呵。
怎么还在用PCIe的交换架构?这个东西又贵又单调。如果改用switch ASIC还可以做些别的事情, 比如Qos,load balancing,L2, L3 or more, ACL。现在流行用Fulcrum的交换芯片。单片搞定24K ACL, 8个负载均衡算法,64K flow Qos,可编程。有兴趣研究的同学请联系QQ,136005387
10G环境,F5K一个732处理连接比较困难吧
华赛这个架构做的不好,不应该用FPGA的,这东西资源有限包处理特性少,还有各个槽位之间做Local switching的话带宽上不去,不能线速,转发能力有限。N个slots,1G,2.5G,10G,等等,FPGA搞不定线速转发.
用什么器件肯定是根据需求评估的,没有放之四海皆准的东西。
Fulcrum的交换芯片-不知道什么时候公司就被某个大公司收购了。
to Andy。
fpga才可以达到线速转发呢。
小心友商拿Switch和你的FPGA拼线速不掉包啊,哈哈
和它拼小包,嘿嘿
Switch是转发很快,但是没有安全特性啊,又不是测试交换机。
Switch那些PCL TCAM就可以用来做安全特性啊,当然做安全的还是需要多核CPU了。Switch的优势是可以做各个槽位之间的线速转发,带宽可以做到很高.
FPGA拼小包?哈哈,带宽上去就歇菜了
多少算够啊,举例,1G的设备放个200G的交换芯片有意义吗?
带宽上到多少FPGA就歇菜了?
呵呵,几个美金的低端交换芯片就能完成这个1G的设备的功能了,性价比和功耗都秒杀FPGA啦
to Andy
几美金的低端交换芯片做2G左右的线速转发是没有问题的,但是你怎么处理安全特性,最简单的,你能实现2G的NAT吗?状态表怎么处理?
中移动的防火墙性能测试都是带NAT和访问策略的,转发性能,并发连接等数据是这个环境下一次测出来的。你几美金的芯片在这种环境下能测出个什么性能?
To zeroflag,
你没有看上面的comments吗?switch是用来做转发的啊。安全特性当然由Cavium,RMI multi-core cpu做啦。
还有,几美金的低端交换芯片出6个GE口,做6G的线速转发都没问题.
NAT和转发是在一起的
FPGA做NAT??不是用CPU做?开玩笑啊,FPGA做简单的影射倒是可以
谁说FPGA做NAT了?
to Andy:
如果你还是需要多核来做安全特性的话,那么你的交换芯片的意义在哪里呢?你的瓶颈依然卡在多核上,仅仅为了做快速转发时性能好看?
回头说说中移动那种测试,带NAT和ACL的功能性能一起测的环境下,加了交换芯片能够提高性能表现吗?
to Eric:
个人理解,安全设备上FPGA都是给CPU打杂的,CPU处理新建连接,之后的转发都交给FPGA来做,NAT应该也是这么处理的。不是单纯的用FPGA来做。
Switch可以做Local switching啊,各个板卡之间都可以线速转发,不单是到多核上。
FPGA那点简单的功能,用switch都能做…
请参考看思科的ISR,可以混插多个交换板卡和安全卡,计算卡等等,各个板卡之间可以做到线速转发,不光是到多核的主卡上.
to Eric:
华为低端路由器有两个系列,一个是AR系列,是OEM H3C的。另外一个是新推出的SRG系列,这个系列就是把USG改过来用的。
至于证据嘛,你可以比较一下SRG和USG的规格就能了解个大概,比如SRG3260和USG5220。另外,你不觉得SRG作为一款路由器,其支持的接口类型有点过少吗?
以下订购信息摘自华为官方网站http://www.huawei.com/cn/products/datacomm/detailitem/view.do?id=4504&rid=4945
型号、订购信息、备注
SRGM00326000、SRG3260 主机-含HS通用安全平台软件、交流/直流
不好意思,上两条发错地方了。
to Eric:
FPGA的功能好坏取决于开发者是怎么设计开发的,龙芯的第一个实现也是在FPGA上,你怎么能说FPGA的功能简单到交换芯片就能替代呢?不同厂家用同一个FPGA,做出来的东西可能完全不同,简单的说FPGA性能好功能弱其实并不负责任。
Eric似乎和FPGA有仇,要不就是卖交换芯片的
不吵了,说下去就是ASIC和FPGA之争辩啦.哈哈
FPGA就是ASIC呀,只不过是自己做的,不过FPGA,不用不知道,保你用了,愁白了头,绝对不是小公司能玩的,投入太大,而且FPGA买个大厂和小厂的差价可能有10倍,HUAWEI可能用,小厂商用了就不合算。