




OSDI2010专题–确定的并行性(Deterministic Parallelism)
作者 陈怀临 | 2010-11-21 18:13 | 类型 研发动态, 行业动感 | 5条用户评论 »
|
【陈怀临注:在现代OS,特别是多核OS的情况下,并行性的研究是最重要的部分之一。工业界的应用通常都比较naive或者simple–通过最简单的利用系统,从而remove任何系统资源(CPU,Mem,Interconnect)利用的非确定性。这种usage的最大缺点是导致了基于芯片的Bare Mental环境的产生和使用,从而导致了大量的3rd party app应用的无法及时apply。。。在今年的OSDI2010上,有三篇不错的文章关于Deterministic Parallelism。其中来自Yale大学的Efficient System-Enforced Deterministic Parallism更是获得了OSDI2010的Best Paper!!!。其中第3篇,来自哥伦比亚大学的文章是来自Junfeng Yang。弯曲评论的海外学人曾经介绍过这个来自清华大学,后毕业于西海岸斯坦福大学的青年才俊。。。不错,这次的OSDI2010的高调出场,基本上是Tenure到手了。恭喜,小杨!】 Deterministic Process Groups in dOS Awarded Jay Lepreau Best Paper! Stable Deterministic Multithreading through Schedule Memoization | |
  (2个打分, 平均:4.50 / 5) (2个打分, 平均:4.50 / 5) |
OSDI2010—众核(Many Cores)环境下Linux的可扩展性研究
作者 陈怀临 | 2010-11-21 17:17 | 类型 研发动态 | 33条用户评论 »
|
【陈怀临注:我在11月4日的多核与OS Submit上主要就是把这篇OSDI2010的来自MIT的文章的结果作为论据,谈Application Aware OS是将来OS的必由之路。在经典OS的研究里,围绕着Kernel的优化必定是死胡同。换言之,芯片设计,OS设计和优化,应该与Application设计与优化作为一个整体来考虑,才是系统软件有突破的基础。例如,我提到的:为什么Cache指令必须是Priviledged?为什么Pseudo-LRU算法是default的?这都是App与OS与CPU割裂的产物。。。It’s time to make a change…】
| |
|
(2个打分, 平均:5.00 / 5) |

Hillstone山石网科SG-6000-X6150防火墙评测报告
作者 老韩 | 2010-10-14 11:38 | 类型 互联网, 弯曲推荐, 研发动态, 网络安全 | 78条用户评论 »
|
4年时间完成从0到100G的跨越,山石网科让人无话可说。再过4年,中国信息安全行业的格局是否会被改变?10月21日,山石网科将在北京正式发布这款百G级别的产品,感兴趣的话可以猛击这里查看官方专题页。 原文发布于《计算机世界》。本文尽量注意在正文中不出现带有个人感情色彩的语言;另一方面,拓展表现形式,用视频保存下测试中的经典瞬间,编辑后以更易于接受、传播的方式加以体现。(对于镜头晃动带来的眩晕感我非常抱歉,此外请忽略鼻炎导致偶发的怪腔怪调……)
Hillstone山石网科(以下简称“山石网科”)是一个令人惊叹的安全企业。自成立以来,该公司保持着稳定、高速的产品研发速度,有步骤地推出了一系列多功能安全网关产品,占据了市场先机。但所有这些产品,其形态都属于“盒子(Appliance)”的范畴,固化的业务处理单元决定了其防火墙性能无法突破20G这条水平线。而在云计算从未来时发展为现在进行时的今天,运营商、金融、教育等大型行业用户有了更高的业务需求,百G级别的防火墙在骨干网、数据中心等环境开始进入实际应用阶段。为了应对新的需求变化,山石网科又于近期推出了SG-6000-X6150(以下简称X6150)高性能防火墙,我们也在第一时间对该产品进行了测试分析。
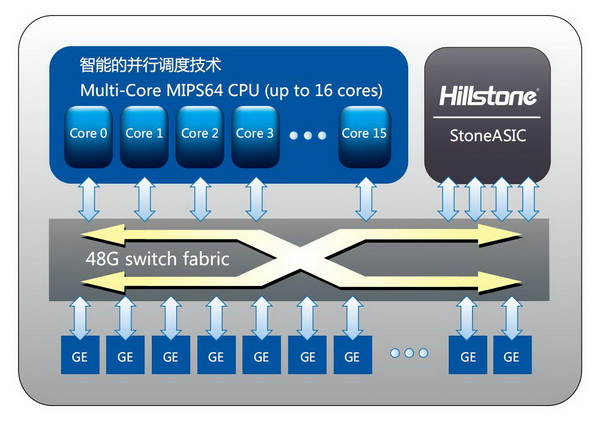
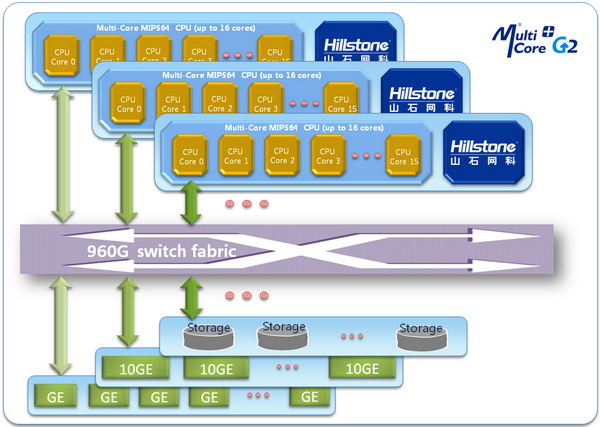
多核Plus G2的高级形态 目前,通过单独的处理器还很难达到百G级别的防火墙性能,业务的分布式处理是目前市场上百G防火墙产品的主流选择。不同厂商必然有着不同的系统实现方式,对于山石网科来说,经过多次发展演变的多核Plus G2架构则是X6150实现智能分布式处理的基础。
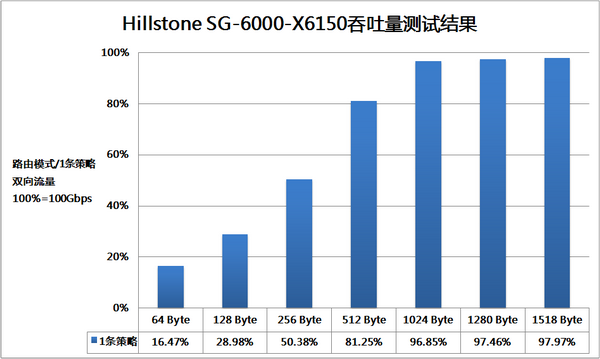
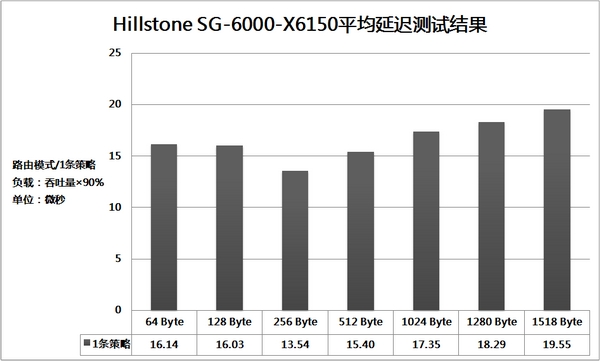
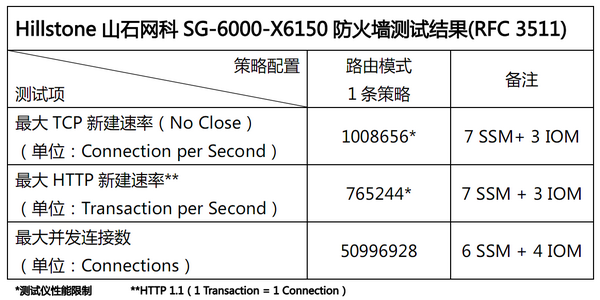
智能分布式处理也会带来一些额外的问题,由于数据流的去向存在不确定性,ALG等需要结合多条流进行处理的业务实现起来会变得比较麻烦。X6150在尽可能均衡地发送流量到不同安全服务模块的同时,也会将有业务相关性的会话分发到同一个安全服务模块进行处理,保证了数据转发的正确性。而对于QoS等更复杂的应用,该产品也继续提供独立业务模块形式的解决方案,在性能与实施成本之间找到合理的平衡。 性能:挑战极限 X6150的真实性能是所有测试工程师共同关心的话题,我们依照RFC 2544和RFC 3511规范,对开启防火墙模块时的系统性能进行了完整考察。与以往不同的是,要测试这款产品的极限性能,必须根据实际情况动态调整模块的搭配策略。例如在吞吐量与延迟测试中,64、128、256Byte帧长时的测试流量并不大,我们采用了7个安全服务模块与3个万兆接口模块的搭配;而在512、1024、1280、1518Byte帧长的测试中,带宽方面的压力比较大,所以采用5个安全服务模块与5个万兆接口模块的搭配。
更稳定 更可靠 智能分布式系统的构建虽然比较复杂,却能为产品带来更加丰富的特性。除了前文验证过的性能优势外,X6150在业务可靠性方面的表现也值得一提。由于接口模块要先对入方向的数据流进行分配,在策略允许的情况下,当安全服务模块出现增减时,数据流的分配情况也应随之发生变化。这意味着,系统在安全服务模块发生故障时将拥有一定的自我调整能力,用户也可以在在线状态下动态调整安全服务模块的配置。 【视频】 为了验证这个猜想,我们设计了一个有针对性的测试用例。首先,使用测试仪生成稳定的每秒60万的HTTP新建流量,这会在配备了7个安全服务模块的X6150上大约消耗65%左右的系统资源。当流量稳定运行一段时间后,人为在线拆除一块安全服务模块,测试仪控制台上记录的压力曲线出现一个轻微波动,随即恢复正常。从设备控制台的监控中可以看到,此时的系统资源消耗平均已超过70%,说明离线模块所对应的负载已被动态分配到其他节点进行处理。等X6150在这种状态下稳定运行一段时间后,再人为将拔出的模块推进插槽,系统马上识别出并开始进行配置。稍后再查看系统运行状态,7个安全服务模块全部正常工作,资源占用率重新回到65%左右。由此可见,只要用户在部署时为系统留出性能余量,采用智能分布式架构的X6150就能够在面临业务增长、突发安全事件或部分系统异常情况时拥有一定的自适应能力。 测试后记 在整个测试过程中,我们始终被一种兴奋的情绪所感染。回顾在市场上公开发布的各款产品,X6150应该是国内真正意义上的、纯粹的信息安全企业推出的第一款采用智能分布式架构的产品。测试结果也证明,它确实达到了百G级别的处理能力,且仅在5U规格的机箱空间内。这无论对山石网科还是整个国内信息安全行业来说,都是一个值得纪念的里程碑,必将会为行业整体水平的提高带来帮助。 毫无疑问,骨干网和数据中心将是高端防火墙的必争之地。信息安全企业必须加强对此类应用环境的理解,才能使功能更有针对性,让产品更加贴近用户。我们相信,山石网科有X6150作为基础,这一切不会太遥远。 | |
|
(9个打分, 平均:4.33 / 5) |


经典论文 – “BigTable”
作者 appleleaf | 2010-04-20 08:36 | 类型 研发动态 | 4条用户评论 »
|
从侃哥的文章中了解到一些Google的经典论文,简要的看了一下其中一篇“Bigtable: A Distributed Storage System for Structured Data”简介如下。 我的理解BigTable应该是同关系型数据库并列的概念。与微软这样的技术大鳄相比,Google的产品线略显单一,例如MS的SQL Server就是Google所没有的,为了可以以类似关系数据库的方式操纵海量的网页信息,Google在产品中抽象了这个模块。不过反过来说,SQL Server这样的通用数据库应对搜索引擎的需求,除了价格昂贵之外,可能既不能scale又不容易调优,大概不是好的选择。 1.Table
上图是BigTable中类比关系数据库的table概念,是一个三维概念。一维是Web Page的URL,对应的是某个Web页面。一维是该Page的属性,例如使用了什么编码方式,被那些网页引用。一维是时间戳,也就是同一个网页以及属性的多个时间的不同版本,例如新浪首页就常常变化。这是个稀疏存储矩阵,稀疏的含义,我的理解就是某些属性例如编码方式在所有的cache版本中只有一个值,不会变化。 其实上述概念,如果不考虑冗余,也可以用一个关系数据表来表示。这里同关系数据库table之间的差别我认为是没有强制关联关系,每个table独立存在。 2.Tablet 是BigTable的Table的一个子集,也就是table的row的一个集合,是数据层面调度、分发和负载均衡的单位。个人理解,引入的原因在于Table太大了,以至于一台设备放不下。划分为Tablet类似于操作系统的Cache概念,这样对于局部操作易于命中。这种东西在关系数据库中或有类似概念,但是被屏蔽,对于用户应该是透明的。在BigTable中用户可见。 3.API操作 其实就是增、删、改、查询等等,功能远远不及SQL语句。为了简化开发人员工作(我认为),google支持使用Sawzall语言(google内部语言)实现的脚本,对于bigtable的table进行复杂操作,实现例如过滤汇总等功能。个人感觉,类似商用数据库的存储过程。 4.底层依赖 运行在单一机器中的数据库系统,依赖OS提供的lock、FS在google的分布式应用中也有对应的概念。BigTable基于Google的GFS以及Lock service等底层应用。 大体就是这些,这篇论文在06年公布,之后据说国内有些厂家也照单实现了,不知道用的怎么样,欢迎描述一些心得体会。例如,为什么采用这种简单的模型,可否有办法improve等(相比Google没有这么好心,公布的技术应该相对落后)。 | |
 (1个打分, 平均:3.00 / 5) (1个打分, 平均:3.00 / 5) |
思科CRS-3视频
作者 陈怀临 | 2010-03-09 20:01 | 类型 研发动态, 通讯产品 | 16条用户评论 »
光子集成技术
作者 rickcart | 2010-03-01 06:46 | 类型 研发动态, 行业动感 | 2条用户评论 »
|
本文介绍了高性能低价格应用中的光子集成技术。作者为 FINISAR 和 CyOptics 公司,March09 编写。 内容包括光子集成技术的介绍,成功商业光子集成案例(包括垂直腔表面发射激光器阵列,EML,EML 阵列,可调激光器),IEEE 40 GB/S 和 100 GB/S 单模光纤标准草案(40GBASE-LR4 标准,100GBASE-LR4 和 100GBASE-ER4标准),混合 PLC 的 DML 光子集成电路(DML/DML 阵列,PLC WDM 复用器技术,耦合 DFB 激光器到 PLC,混合 PLC 案例),独石 InP EML 光子集成电路(EML 技术,复用器技术,生产技术,独石 PIC 案例)等。 Photonic Integration for High-Volume Low-Cost Application-Mar2009 现在的主流光模块公司也开始关注光子集成技术了,毕竟已经有标准认可了,降成本的效果是明显的,当前的多波可实现性也较单波强得多。看来英飞朗(Infinera)已经成为先驱了。 | |
|
(没有打分) |

又一次整合:Intel子公司风河收购Virtutech
作者 木匠 | 2010-02-28 14:21 | 类型 研发动态, 行业动感 | 9条用户评论 »
|
Virtutech的主要产品是Simics,Simics 是一种全系统虚拟机器,它能高效地在目标硬件上运行原生的产品代码。Simics最初由瑞典计算机科学研究院(SICS)开发,后于1998年派生出Virtutech公司进行商业化开发。Simics能仿真诸如Alpha、AMD64、ARM、EM64T、IA-64、MIPS(32位和64位)、MSP430、Powerpc(32位和64位)、POWER、SPARC-V8/V9、x86等多种系统,并且可以在这些仿真硬件上运行多种操作系统,包括MS-DOS、Windows、Vxworks、OSE、Solaris、FreeBSD、Linux、QNX和RTEMS等。NetBSD公司的AMD64接口在芯片公开发行之前最初是用Simics开发的。用Simics进行仿真的目的经常是使用Simics虚拟一些特定类型的嵌入式硬件平台来开发软件[1]。 2009年6月Intel以8.84刀的价钱收购WindRiver,半年后Intel再收购Virtutech并纳入WindRiver旗下,这也再次显示了Intel进军嵌入式行业的决心。来看看Virtutech的芯片合作伙伴:AMCC、Freescal、ARM、IBM、RMI;再看看看Virtutech的软件合作伙伴:ENEA、montavista、QNX、Zee2等。前者是Intel的竞争对手,后者则一直是WindRiver的死对头。这下好了,Intel先是搞定WindRiver,再是吃下Virtutech,恶意收购(算你狠!)。 | |
|
(2个打分, 平均:2.00 / 5) |

以太网联盟(EA)的40G和100G以太网技术研究报告
作者 rickcart | 2010-02-28 06:38 | 类型 研发动态, 行业动感 | Comments Off
|
以太网联盟是由100多名成员,包括系统和部件供应商,行业专家和大学和政府专业人员组成的,致力于继续取得成功和以太网技术发展的组织。该40G以太网和100G以太网技术研究报告由联盟中的3COM,FORCE10,思科专家联合编写。 主要内容包括:摘要,介绍,40G和100G以太网目标,标准时间表,40G和100G以太网架构,物理编码子层(PCS),物理媒体附加层(PMA),40G和100G以太网接口,40G媒体独立接口(XLGMII)和100G媒体独立接口(CGMII),40G附加单元接口(XLAUI)和100G附加单元接口(CAUI),并行物理接口(PPI),物理媒体独立层(PMD),BASE-CR 和 40BASE-KR4 物理层特性,BASE-SR、BASE-LR 和 BASE-ER物理层特性,总结,附件,缩略词表等。 | |
|
(1个打分, 平均:1.00 / 5) |
基于进程迁移的地址空间复用和可信进程间通信组的研究
作者 陈怀临 | 2010-02-11 20:56 | 类型 研发动态 | 2条用户评论 »

微软最新技术演示–云计算与自然用户界面
作者 陈怀临 | 2010-02-11 18:12 | 类型 新兴技术, 研发动态, 行业动感 | 4条用户评论 »