




霍夫曼编码(Huffman Encoding)
作者 帅云霓 | 2010-01-25 06:23 | 类型 行业动感 | 28条用户评论 »
|
虽然年纪不大,但吃程序这碗饭已经有年头了。今天和同事一起给人面试,同事问candidate的一个问题,让另一个“面试官”——我,也被雷到了: “咱们聊聊霍夫曼编码。” 本来平时贫嘴话痨的我立刻闭嘴以避免出丑,魂游天外地做完了剩下的面试,回到座位上问谷歌老师。谷歌老师带我去找维基老师。 维基老师说: “In computer science and information theory, Huffman coding is an entropy encoding algorithm used for lossless data compression. The term refers to the use of a variable-length code table for encoding a source symbol (such as a character in a file) where the variable-length code table has been derived in a particular way based on the estimated probability of occurrence for each possible value of the source symbol. …… Huffman coding uses a specific method for choosing the representation for each symbol, resulting in a prefix code (sometimes called “prefix-free codes”) (that is, the bit string representing some particular symbol is never a prefix of the bit string representing any other symbol) that expresses the most common characters using shorter strings of bits than are used for less common source symbols. Huffman was able to design the most efficient compression method of this type: no other mapping of individual source symbols to unique strings of bits will produce a smaller average output size when the actual symbol frequencies agree with those used to create the code. A method was later found to do this in linear time if input probabilities (also known as weights) are sorted.……Blah blah……” 看到这一大堆洋文,我又被雷了一下。这些东西是什么意思呢?幸好,有图有真相:
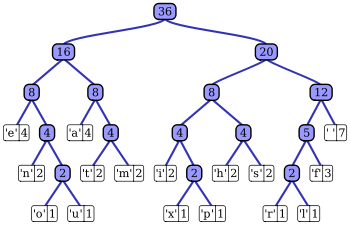
原来,它是这么做的:譬如,有个36字节长的句子:“this is an example of a huffman tree”。它由16种字符构成。我们发现,e, n, o, u, a, t, m这几个字符占了16个字节,另外i, x, p, h, s, r, l, f和space占了20个字节,这样分开它们,两半比较平衡。于是,构建一个二叉树,左边是e, n, o, u, a, t, m,权重为16,右边是i, x, p, h, s, r, l, f和space,权重为20。对于二叉树的每个节点,再用同样的方法尽量均衡地二分,以左节点为例: 左边的e, n, o, u占8个字节,右边的a, t, m也占8个字节。因此,在该节点下建立两个子节点,左边为e, n, o, u, 权重为8, 右边为a, t, m,权重也为8。 如此递归,不断拆分每个节点,直至每个节点仅包含一个字符,最后生成如图所示的一棵二叉树。 每个字符的编码这样确定,如h: 从根节点找到h需要经历:右-左-右-左,右对于1,左对应0,这样,它的编码为1010。其他依次类推。 从几何上看,如果一个字符离树的根越近,其编码长度越短。其数学意义,是出现得越多的字符,编码长度越短。 所有字母的编码为: space 111 那么,为什么这样做呢?我们知道,从信息论的角度看,一件事情概率越大,信息量越小。如果,把一个随机事件包含的信息量用bit计数的话,那么bit数n = log2 (1/p) (P为事件发生的概率)。比如,必然事件的信息量为0,(譬如,“今天,CCTV又放新闻联播了”,这句话不是废话嘛!)1/2概率事件的信息量为1bit。这就是霍夫曼编码的数学原理基础。一个字符或者别的符号,出现的概率越大,包含的信息量越小,因此编码需要的bit数也越少。如果一个符号出现概率为50%或更多,那么只需要1bit编码;出现概率为25%到50%则需要2bit编码…… 看来,霍夫曼编码初听觉得可怕,看懂了觉得很简单,但dig into it,深入想想,还能发现更深入的东西。推而广之,学习的道路上,什么事情不是这样呢? PS:今儿心情好,才敢在各位大侠面前班门弄斧。切莫piss off我…… | |
  (2个打分, 平均:4.50 / 5) (2个打分, 平均:4.50 / 5) |
雁过留声
“霍夫曼编码(Huffman Encoding)”有28个回复
那个图片没显示出来啊。维基百科的页面在这里:
http://en.wikipedia.org/wiki/Huffman_encoding
奇怪,在公司能看到,家里电脑看不到。难道被GFW了?
先来顶一下,呵呵,以前研究生的时候学过这个编码,一般好像用在数据压缩里。
帅帅这文章是我6点多的早晨,通过iPhone批发的。谢谢Steve Jobs同学。
实时数据库的无损压缩似乎喜欢用这个霍夫曼编码。
中国计算机专业的数据结构中有讲霍夫曼和霍夫曼编码。通信专业使用的曼彻斯特编码,差分曼彻斯特编码则属于调试和解调方向。
(来自麦道飞机上的水)帅帅显然是EE出身。
Huffman也是EE出身的,这是他在上信息论的course project搞出来…听说是试了很久才试出来的:)
多谢首席。在美国的高校,EE和Automation应该是不分的,在国内都是分家的。我学的就是Automation,因此数据结构、离散数学一律统统地没正规学过。(所谓没正规学过,也就是搬板凳蹭过课听,但以国内大学的体制,学分和考试可没法蹭)
幸好自己生在网络技术发达的今天,不懂可以问Google老师,Google老师不懂的还可以在弯曲评论上讨教。
有点意思
国外貌似没有automation这个专业,要么归到EE,要么归到Mechanical,虽然控制的根本-反馈现象是普适性的,并且在人类产生之前就存在。不过形成一门专门的学科应该是维纳写的cybernetics出来之后吧,而维纳本身也是数学出身,搞信号处理的。后来钱老写了工程控制论,在国内才出来自动化的学科,将传统的PID控制,Nyquist,Bode等人的理论融合成当前的自动控制理论。等到现代控制理论,又基本上是矩阵论的应用了,主要都是应用在石油炼钢等大型过程控制或者机床或机器人这样的运动控制系统中。不过自动化出来的学生们去传统控制工业的人应该很少,大部分都来跟CS或EE的人抢饭碗了,就像我跟帅同学:)
CS or EE是什么?
CS: Computer Science or Counter Strike
EE: Electronics Engineering or Electrical Engineering
谢谢,刚刚以为CS是cisco,EE是ericsson
还好您没以为CS是Counter-Strike, EE是Electical Entainment.
简单好用:Huffman coding。Source Coding的一种,需要预知信源的概率分布,因此不适于连续或者不是各态遍历的信源。
雷吗?不雷吧。 虽然我也很菜,但我偶尔也会问这个,或者泰勒级数,FFT这些,我觉得这是在考察基本素养。
我当时学的计算机专业,数据结构有讲,微机原理讲指令编码的时候有讲,还有哪些课有讲忘了,当时耳朵都听起茧了:)。 有一个映像,当年我觉得书上讲的方法编码出来都不是最优的,后来还编了个小程序来整了个“最优”。
之所以说雷,是因为自己见识短浅都没听说过这玩意……
人类基因是什么编码规则,上帝造人有没有考虑过?
木有造过人的同学飘过……楼下保持队形……BS某些娃已经会跑了的人,跟我这样的未婚纯洁青年美男探讨造人问题……
这是你么?
http://www.qiushibaike.com/users/41845
确实蛮帅的!:-)
别瞎说。我发现老妈有时候也会上来看……
闭嘴,闭嘴……
[等到现代控制理论,又基本上是矩阵论的应用了,主要都是应用在石油炼钢等大型过程控制或者机床或机器人这样的运动控制系统中]
现代控制理论里面的状态空间理论,最初是阿波罗登月工程应用的,解决多输入多输出的系统解耦控制问题。现在在导航、飞控上也用得很多。譬如,直升机的力学模型,就是一个很头大的8阶矩阵……残念ing
导航跟航天这块的自动控制现在很多高校都有专门的专业了。
解那些高阶矩阵很郁闷的,matlab几行语句就搞定了,手算算到吐血…
帅同学被人肉了,呵呵
今儿刚发了些邪恶内容的留言,正偷偷得意坏笑,老妈在MSN上跟我说:儿子,弯曲评论上的xxx文章是你写的?不错嘛……我当时冷汗就把衬衫湿透了。
老妈是某高校计算机系的老师……没准是哪天查资料翻到了这里……
这个。。。本科生data structure的必修课吧。。。这个。。。
帅帅,真的假的?我大姐也来弯曲评论?是,帅帅长大了。我其实都想好了。你这个ATOM好好写,我给你出个PDF专辑。ATOM与ARM的比较topic很大。慢慢写,有个计划。
首席是帅帅他长辈?