




北斗第三颗星成功定点,以及坊间流传的后续发射计划
作者 高飞 | 2010-01-25 15:11 | 类型 专题分析, 行业动感 | 6条用户评论 »
系列目录 全球卫星定位系统
首先是来自www.beidou.gov.cn的正式报道:1月22日1时47分,北斗卫星导航系统第三颗组网卫星自2010年1月17日0时发射后,经四次变轨,成功定点于东经160度、轨道倾角1.8度的赤道上空。随后,卫星有效载荷开通,目前卫星工作正常。 其次是坊间流传的北斗二代2010发射计划。来源不可靠,笔者不负责。发射计划当然会根据具体情况变化,咱们祝福具体情况一切正常。2010年前,已经有北斗二代COMPASS-M1和COMPASS-G2。 1、年初1月,西昌,长三丙,北斗二代同步轨道1号星(COMPASS-G1); 北斗今年还要发7颗,到年底总数将达到10颗。欧洲的伽利略呢?维基百科告诉我们,2010年1月7日,欧洲宣布建造首批14颗卫星的合同已经包出,14颗卫星的造价总共是5.66亿欧元(8.11亿美元)。前两颗预计在2012年10月就绪。欧洲航天局估计的总发射费用是3.97亿欧元(5.69亿美元)。 嗯,让欧洲人追去吧。 | |
 (1个打分, 平均:5.00 / 5) (1个打分, 平均:5.00 / 5) |
UTStarcom的更懂中国
作者 陈怀临 | 2010-01-25 08:07 | 类型 行业动感 | 8条用户评论 »
霍夫曼编码(Huffman Encoding)
作者 帅云霓 | 2010-01-25 06:23 | 类型 行业动感 | 28条用户评论 »
|
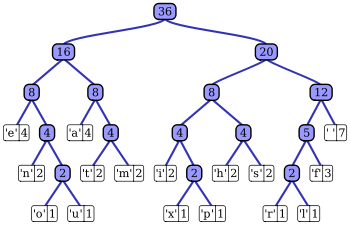
虽然年纪不大,但吃程序这碗饭已经有年头了。今天和同事一起给人面试,同事问candidate的一个问题,让另一个“面试官”——我,也被雷到了: “咱们聊聊霍夫曼编码。” 本来平时贫嘴话痨的我立刻闭嘴以避免出丑,魂游天外地做完了剩下的面试,回到座位上问谷歌老师。谷歌老师带我去找维基老师。 维基老师说: “In computer science and information theory, Huffman coding is an entropy encoding algorithm used for lossless data compression. The term refers to the use of a variable-length code table for encoding a source symbol (such as a character in a file) where the variable-length code table has been derived in a particular way based on the estimated probability of occurrence for each possible value of the source symbol. …… Huffman coding uses a specific method for choosing the representation for each symbol, resulting in a prefix code (sometimes called “prefix-free codes”) (that is, the bit string representing some particular symbol is never a prefix of the bit string representing any other symbol) that expresses the most common characters using shorter strings of bits than are used for less common source symbols. Huffman was able to design the most efficient compression method of this type: no other mapping of individual source symbols to unique strings of bits will produce a smaller average output size when the actual symbol frequencies agree with those used to create the code. A method was later found to do this in linear time if input probabilities (also known as weights) are sorted.……Blah blah……” 看到这一大堆洋文,我又被雷了一下。这些东西是什么意思呢?幸好,有图有真相:
原来,它是这么做的:譬如,有个36字节长的句子:“this is an example of a huffman tree”。它由16种字符构成。我们发现,e, n, o, u, a, t, m这几个字符占了16个字节,另外i, x, p, h, s, r, l, f和space占了20个字节,这样分开它们,两半比较平衡。于是,构建一个二叉树,左边是e, n, o, u, a, t, m,权重为16,右边是i, x, p, h, s, r, l, f和space,权重为20。对于二叉树的每个节点,再用同样的方法尽量均衡地二分,以左节点为例: 左边的e, n, o, u占8个字节,右边的a, t, m也占8个字节。因此,在该节点下建立两个子节点,左边为e, n, o, u, 权重为8, 右边为a, t, m,权重也为8。 如此递归,不断拆分每个节点,直至每个节点仅包含一个字符,最后生成如图所示的一棵二叉树。 每个字符的编码这样确定,如h: 从根节点找到h需要经历:右-左-右-左,右对于1,左对应0,这样,它的编码为1010。其他依次类推。 从几何上看,如果一个字符离树的根越近,其编码长度越短。其数学意义,是出现得越多的字符,编码长度越短。 所有字母的编码为: space 111 那么,为什么这样做呢?我们知道,从信息论的角度看,一件事情概率越大,信息量越小。如果,把一个随机事件包含的信息量用bit计数的话,那么bit数n = log2 (1/p) (P为事件发生的概率)。比如,必然事件的信息量为0,(譬如,“今天,CCTV又放新闻联播了”,这句话不是废话嘛!)1/2概率事件的信息量为1bit。这就是霍夫曼编码的数学原理基础。一个字符或者别的符号,出现的概率越大,包含的信息量越小,因此编码需要的bit数也越少。如果一个符号出现概率为50%或更多,那么只需要1bit编码;出现概率为25%到50%则需要2bit编码…… 看来,霍夫曼编码初听觉得可怕,看懂了觉得很简单,但dig into it,深入想想,还能发现更深入的东西。推而广之,学习的道路上,什么事情不是这样呢? PS:今儿心情好,才敢在各位大侠面前班门弄斧。切莫piss off我…… | |
 (2个打分, 平均:4.50 / 5) (2个打分, 平均:4.50 / 5) |
我看”App Firewall”
作者 appleleaf | 2010-01-25 02:13 | 类型 网络安全, 行业动感 | 10条用户评论 »
|
安全概念到了app上面概念有些混乱,不象白垩纪那么清晰,也没有什么人和有权威组织的标准定义,例如App FW。下图是笔者自身对于AppFW模块(注意不是产品)的概念的认识。
下图从不同层次的SAP概念(SAP不是ERP系统,而是网络访问点的缩写)出发进行说明解释
| |
|
(1个打分, 平均:5.00 / 5) |


美宇航员首次太空实时更新微博客(Twitter)
作者 陈怀临 | 2010-01-24 17:04 | 类型 行业动感 | 5条用户评论 »
|
【编者注:美国NASA宇航员T.J. Creamer在国际空间站上玩twitter。并完成了来自太空的人类的首次(直接)灌水:“”Hello Twitterverse! We r now LIVE tweeting from the International Space Station — the 1st live tweet from Space! | |
 (没有打分) (没有打分) |
FPGA系统设计的主要思路和方法初探
作者 陈怀临 | 2010-01-24 13:03 | 类型 学术园地, 科技普及 | 31条用户评论 »
系统设计的一些前沿问题(Frontiers in Systems Research)
作者 陈怀临 | 2010-01-24 12:08 | 类型 研发动态, 行业动感 | 5条用户评论 »
|
【编者注:演讲者Brad Chen是谷歌Native Client项目的负责人。加入谷歌之前,是哈佛大学的教授,教授操作系统,体系结构和分布式系统等。他从斯坦福大学获得其学士和硕士学位,从CMU获得其博士学位。2010年的OSDI会议,这个哥们将担任 Program Chair。】 | |
|
(1个打分, 平均:3.00 / 5) |
云计算–谷歌Faculty Speech
作者 陈怀临 | 2010-01-24 10:05 | 类型 研发动态, 行业动感 | Comments Off
|
【编者注:谷歌的SVP Alan Eustace谈云计算。】 【Alan Eustace简介:】 Alan Eustace is one of Google’s senior vice presidents of engineering. He joined Google in the summer of 2002. Prior to Google, Alan spent 15 years at Digital/Compaq/HP’s Western Research Laboratory where he worked on a variety of chip design and architecture projects, including the MicroTitan Floating Point unit, BIPS – the fastest microprocessor of its era. Alan also worked with Amitabh Srivastava on ATOM, a binary code instrumentation system that forms the basis for a wide variety of program analysis and computer architecture analysis tools. These tools had a profound influence on the design of the EV5, EV6 and EV7 chip designs. Alan was promoted to director of the Western Research Laboratory in 1999. WRL had active projects in pocket computing, chip multi-processors, power and energy management, internet performance, and frequency and voltage scaling. In addition to directing Google’s engineering efforts, Alan is actively involved in a number of Google’s community-related activities such as The Second Harvest Food Bank and the Anita Borg Scholarship Fund. Alan is an author of 9 publications and holds 10 patents. He earned a Ph.D. in computer science from the University of Central Florida. | |
|
(没有打分) |
多核时代的并行计算研究(视频)
作者 陈怀临 | 2010-01-23 16:53 | 类型 学术园地, 研发动态 | 9条用户评论 »
多核时代的并行计算研究
作者 陈怀临 | 2010-01-23 16:34 | 类型 学术园地, 研发动态 | 13条用户评论 »
|
【编者注:据说钱和美女,从来不嫌多。不知道皇上是什么感觉。但在并行计算方面,多多益善是不一定正确的。在并行计算方面,有个重要的Amdahl公式。其意思其实很简单。用大白话说,就是对于一个问题,你总有不能并行做,要顺序化的。那个地方就是你系统的瓶颈。即使你的多核处理器有无限个,从而可并行化的那部分所需的时间都接近0了。但也没有用。系统的最大加速被那个瓶颈决定了。举一个具体的类比来解释什么是高深的Amdahl’s Law。假如一个导演要选女一号。自己干累死了。整了许多副导演去各个省份帮助海选整候选人。这个海选的候选人,最后要汇总到总导演这里,总导演亲自把关,把候选人都整一遍。为了节约开销,加快拍摄进度,投资方说了,多整点副导演,并行的去整候选人。没问题,以前计划3个月的事情,由于多了许多副导演,结果一个星期就搞定了。如果副导演再多,可以一天就搞定。投资方是个脑残,不懂Amdahl’s Law。傻乎乎的问总导演,咱们多整些副导演,那我们一天就可以选出女一号了。总导演说:不行,No Way。我不管候选人选的多快,我这里必须把关,挨个的面试,上镜头和其他的。。。。(省略250个字)。这必须要2个星期。而这件事副导演不能插手,别人不能帮忙,没法并行化。投资方明白了:哦,这件事最快最快也要2个星期。所以,知道不要脑残的雇太多的副导演去整女候选人了。 白浪费钱。】 | |
|
(4个打分, 平均:3.75 / 5) |
