内容简介:IPv6 address长度是128bit,Ipv4 address长度的32bit。就地址长度而言,扩大4倍。就容量而言,扩大了2^96倍。IPv6 Address Lookup对路由器设备的挑战有多大,是比IPv4难4倍还是难40倍?当前路由设备对IPv6 FIB查表的支持程度竟究如何?本文从三层转发最长匹配(LPM)原理出发,对比分析IPv6对路由器设备的带来的挑战难度。同时,根据LPM的实现原理,提出对现有设备IPv6 Address lookup及IPv6 FIB支持情况的测试用例的设计三原则:IPv6地址离散性、不同掩码长度,IPv6 Prefix有嵌套和分叉。同时,根据这三个原则对国内运营商选型测试中常用的两例IPv6测试进行分析,指出其优点改进方向。最后,提出一个满足上述四个原则的测试用例脚本。
1.迎接IPv6时代—Are the Boxes Ready?
全球的IPv4地址即将用完,尤其是中国的地址最为紧缺。另一方面,物联网概念的提出,对IP地址的需求成N倍增长。因此,IPv6地址即将走上舞台。中国政府已经将Ipv6的推进提到国家战略的高度。中国的各大运营商也对应Ipv6网络演进纷纷采取大动作,例如中国电信宣布成为全球首家认证通过的IPv6宽带接入运营商。
近年来,国内外各设备运营商纷纷对路由器设备展开IPv6 Address Lookup能力的测试,以期望这些设备能在未来的IPv6商用网络中发挥正常作用。测试的内容,主要考核点:IPv6 FIB容量、IPv6路由刷新性能、IPv6转发性能。
由于全世界IPv6并未大规模商用,IPv6路由分布和地址分配方案都存在较大变数。另一方面,IPv6地址容量大得足以给地球上每一粒沙子分配一个地址;而当前设备能处理的IPv6地址和前缀容量很有限,相对IPv6整个容量而言只能算沧海中的一小粟。因此,如何设计一个具备代表性的测试用例,以客观地评价设备对未来商用网络的支持情况,就变成一个非常重要的工作。
IPv6 address长度是128bit,Ipv4 address长度的32bit。就地址长度而言,扩大4倍。就容量而言,扩大了2^96倍。IPv6 Address Lookup对路由器设备的挑战有多大,是比IPv4难4倍还是难40倍?当前路由设备对IPv6 Address Lookup支持程度究竟如何?当前这方面的分析很少。
众所周知,三层转发查找远远比二层转发要难。难度差别来源于三层转发的一个本质特殊:最长匹配LPM。
2 路由查找LPM算法及实现
2.1 什么是最长匹配LPM?
最长匹配(Longest Prefix Match)是指如果一个IPv4地址与FIB表中的多个路由前缀(prefix)匹配,则以掩码长度最长的前缀为最终匹配结果。例如,一个路由器中有4条路由:
1) 1.*.*.*/8
2) 1.2.*.*/16
3) 1.2.3.*/24
4) 1.2.3.4/32
一个IPv4地址1.2.3.5在上述路由表中查找时,会与前3项前缀匹配上,与第4项匹配不上。匹配上的3个前缀中,1.2.3.*/24的掩码最长,所以它就是最长匹配结果。
为什么需求最长匹配?这是因为prefix有嵌套。为什么Prefix有嵌套?是因为IP地址的分配方式引起。其中一个例子是:一个Tier 1运营商申请到一个A类地址,它将其中划分一小块批发给Tier 2运营商; Tier 2运营又会继续再划出一小块,分配给Tier 3运营商。这样,就发生了“路由前缀嵌套”现象。
理论上,IPv4地址最多会嵌套24层(从8bit A类地址开始计算);这就是说,在路由转发查表时,一个IPv4地址最多可能同时与24个前缀匹配上,此时设备要从24个前缀中选择一个最佳前缀(掩码最长为最佳)。
2.2 LPM最长匹配实现算法
二层MAC转发查表可以使用Hash算法(请见小师的Hash表介绍),三层IP转发查表要使用最长匹配LPM算法。前者是精确匹配,一个地址只会与转发表中一个表项比对上;后者却是,一个IP地址与转发表中的多个表项同时匹配命中,并在匹配命中的多个表项中选择一个最佳表项。正是这个多项匹配,造成LPM算法的实现难度远远大于Hash算法,这是常说三层转发难度高于二层转发的主要原因之一。例如,一个Broadcom的以太网单芯片,可以轻松支持64K MAC地址表,但IPv4转发表只有8K量级。
LPM算法的基本实现原理是用Tree-based search。即
1) 将众多路由前缀构造成一棵树(Tree);
2) 当查找IP地址时,从树的根开始往下查找,每到一个分支点,就可以判断是否已经匹配上。如果已经匹配上,就先记录下来;
3) 继续往下走,直到没有进一步的匹配,或者已经到达树的顶端(即叶子);
4) 在多个匹配中的节点中,选择掩码最长的。一般而言,越往下的节点,其掩码越长。
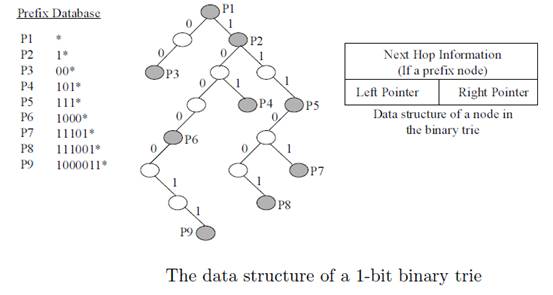
下图是一个1-bit binary trie树算法的原理图。大家看看,是否长得象一棵Orange Tree(倒过来)?
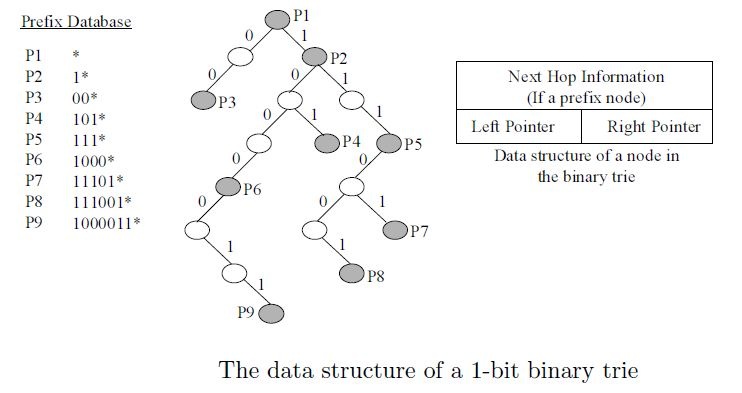
如果输入IP地址1111110000,则在该Tree中走法是:首先从根开始,命中P1;第1bit为1,往右走,命中P2;第2bit为1,再往右走; 第3bit为1,往右走,命中P5,第4bit为1,该往右走,但发现右边没有路了,故查找结束。此过程中,P5/P2/P1都命中,但P5掩码最长,故匹配结果为P5。
实际上,从P2到P5只需要一步就可以完成,而不是2步。这是因为路径上没有分叉,走向是唯一的,这叫SKIP。
在上述1-bit binary trie搜索树的原理基础上,可优化发展出Multi-bit trie,Treebimap等算法。这些算法在当前路由设备中比较常见。
2.3 用1bit Trie搜索树实现IPv6查表的难度分析
IPv4有32bit,故用它构造成一棵1-bit Trie树时,最高有32层。IPv6地址有128bit,故用它构造一棵1-bit Trie树时,最高有128层。
从Trie搜索树的形状可以看出,如果树的分支层数越多,则搜索难度越大。如果每次查1bit,32层高的IPv4搜索树,需要查找32次;128层高的IPv6搜索树,需要查找128次。
当前房地产是最热门话题,在此借用一下。IPv4查表之难度,就如修建一个32层的住宅楼;IPv6查表之难度,就如修建一座128层的摩天大楼。后者工作量和难度是前者的多少倍?应该不止4倍。
2.4 Multi-bit Trie算法
用1bit trie实现IPv6查表时,最坏情况下需要访问128次RAM。显然这在硬件实现上不太现实,故在NP的Data path中,一般采用其变种形式: Multi-bit trie算法。
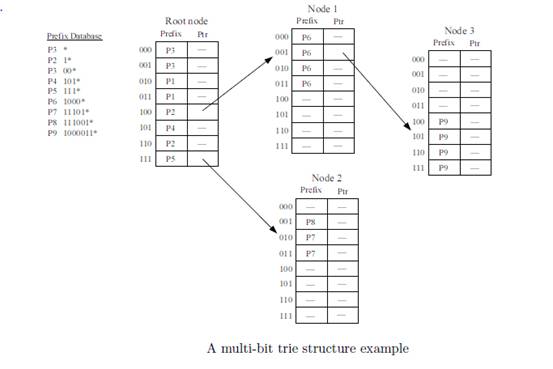
Multi-bit Tree搜索树的原理,是在1bit trie的基础上,由每一步搜索1bit改为每一步搜索8bit(也可以是其它数字如4、或16)。这样,IPv4地址就分成8-8-8-8共4个8bit段,需要访问4次DDR2 SDRAM或RLDRAM。IPv6地址分成8-8-8…8-8共16个8bit段,需要访问16次DDR2 SDRAM或RLDRAM。Multi-bit Tri的算法示意图如下:
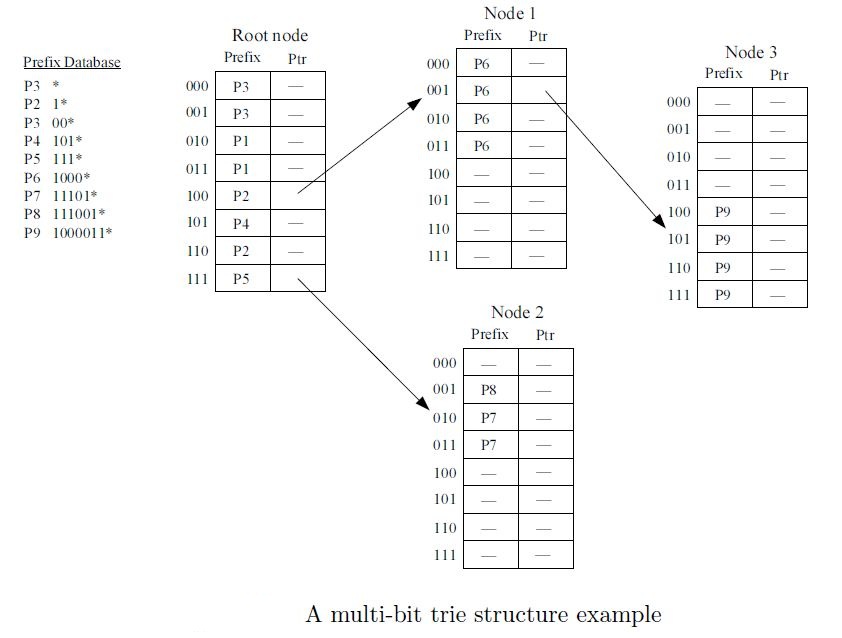
在上述基础上,如果树的某个搜索路径上没有分支(即路由没有重叠嵌套),则可用采用SKIP方法直接跳过,这样可以减少搜索次数。以IPv6为例,最好情况是所有路由都没有嵌套,访问2次-3次DRAM就能找到最终找到最终结果;最坏情况是路由有很多级嵌套发生,需要查找16次DRAM才能找到最终结果。
Multi-bit Trie算法的另一个特点是采用段页式管理DRAM,将片外DRAM划分成一个个Page,每个Page可以正好存放256条连续的路由(2^8=256)。如果路由不连续,则最坏情况一个Page只能放一条路由,此时容量大大减小。
2.5 Multi-bit Trie算法的特点
Multi-bit Tire算法(以及其派生算法如Tree bitmap, LC-trie)具备下述两个特点:
1) 路由容量不恒定。对+1、+2的连续路由容量最大,对随机产生的路由则容量严重变小;
2) 性能不恒定。对没有嵌套路由性能最好,对嵌套层数多的路由性能严重变差。这里的性能包括数据平面转发性能和控制平面刷新性能,因为路由插入时也需要软件查FIB表。
如果是让设备商推荐测试方法,则它一定会聪明地选择下述路由来测试设备:使用+1递增路由以使容量最大;使用不嵌套路由以使转发和刷新性能最好。
3. IPv6 Address Lookup测试用例设计原则
3.1 三个测试原则
由于IPv6 Address Lookup的难度比IPv4高4倍以上,那么使用什么的用例才能充分检验Router设备的查表性能、路由刷新性能、
根据Trie搜索树的原理,可以归纳出下述测试用例设计:
1) IPv6地址离散性
IPv6地址容量巨大有如浩瀚之海洋,故IPv6前缀的选择尽量离散,以求有更大的代表性;
2) 不同掩码长度
同IPv4的一样,IPv6地址也采用了层次化的分配方式,而且未来的层次化是否会出现CIDR这样的更细粒度的层次化还未可知。这导致需要不同的IPv6前缀长度。所以,在测试中尽量多采用各种前缀长度来测试,以应付未来可能出现的IPv6地址分配需求。
3) IPv6 Prefix有嵌套和分叉
这其实是层次化地址分配方式造成的必然结果。从LPM算法的实现原理看,Prefix嵌套层次越多,则构造出的树层高越高,搜索难度也就越大。所以,在测试用例中一定要考虑充分的路由嵌套。
如果站在搜索树的角度,上述原则可保证由IPv6 prefix构造成一棵枝盛叶茂的参天大树;
如果站在个房子的视角,上述原则可保证由IPv6 prefix构造成一座摩天大楼;
3.2 两则IPv6 FIB测试用例分析
根据上述三原则,下面选择国内大运营商用过的二个测试用例进行分析:
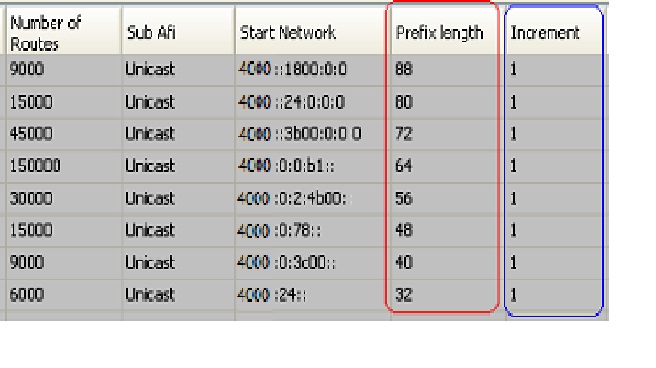
1) 用例A:几种IPv6前缀长度,+1递增路由
a) 不同的前缀长度的路由数量按照一定的比例设置;
b) 同一个前缀长度内的路由+1递增
c) 共50万IPv6路由
d) 路由分布如下所示:
2)用例B:随机前缀,前缀长度可配
在测试仪中,使用随机函数产生IPv6路由前缀。路由前缀的长度可配置
上述两个测试用例的共同最大不足点,就是路由prefix没有嵌套,在查找中始终只会匹配一个表项,而不会同时命中多个表项,失去了LPM最长匹配查表的本质特征。按三原则进行具体分析如下:
| |
原则一IPv6离散性 |
原则二不同掩码长度 |
原则三Prefix嵌套和分支 |
Search Tree视角 |
建楼房视角 |
点评 |
| 用例A+1递增路由 |
不满足 |
满足 |
不满足 |
多果椰子树 |
联排 |
性能和容量测试不准确 |
| 用例B随机路由 |
满足 |
满足 |
不满足 |
单果椰子树 |
别墅 |
容量较好,性能测试不准确 |
。
如果将A的前缀分布构建成一棵树,其形状比奇特,树干上没有分支,树梢上挂了很多果实。很象一株椰子树,是吧?这种树的搜索很简单,以Multi-bit trie为例,只需要访2-3次外部RLDRAM:第一次,从几棵树中选中一棵,并直接到达树梢(因为树干没有任何分叉);第二步,从树梢的成千上万个果实中摘取一个。第二步是比较简单的,接近于线性查表,这是因为路由前缀全部是+1递增,很紧凑地放在一起,且没有多项同时匹配的问题。
显然,测试用例A路由没有很好地考察路由设备的数据平面的查表性能; 不能很好地测试路由设备控制平面的刷新性能,因为在插入新路由时控制平面也需要查RIB/FIB表。IPv6查表理论上需要访问16次片外RLDRAM(用8-bit Multi-bit Trie),而上述路由分布只需要约3次RLDRAM访问。
测试用例A的另一个问题是:它不能客观检测设备的FIB极限容量,它测试的是设备的best case下的能力,而不是worst case下的能力。这是因为设备在实现Search Tree算法时,为了实现方便,需要采用“段页式方法”将片外的DDR2 SDRAM或RLDRAM划分成很多Page,每个Page可放下256条连续的路由。如果路由是离散的,则最坏情况下一个Page只能放1条路由。
测试用例B相对于用例A而言,有很大的改进,这是因为它的路由分布更离散,检测的FIB容量比较接近于Worst case。
4. IPv6 FIB lookup测试用例脚本参考
我们希望测试用例的Prefix构造出一棵参天的Orange Tree,有很多树叉与分支,而不是树干象光棍一样的椰子树;我们希望测试用例的Prefix构造出一座摩天大楼,而不是只有一层楼高的联排或别墅。这样,才能测试设备在Worst Case情况下的FIB容量、路由刷新性能、数据平面查表转发性能。
根据测试用例三原则,一个测试脚本用例如下:
#define MaxMaskLen = 64 //需要测试的最大路由掩码长度,取值24-128
#define Step = 8 //掩码变化步进值
do{
P = rand(128bit IPv6单播Address) //产生一个随机地址(原则一:离散性)
if ( P/24 在FIB中不存在) //去掉重复路由
{
for( j=24; j<=MaxMaskLen; j++=Step) //(原则二:多种掩码长度)
{
INSERT FIB(P/j); //表示插入值为P前缀长度为j的路由(原则三:散成嵌套)
Q = P + 1<<(128-j);
INSERT FIB(Q/j ); //表示插入值为Q前缀长度为j的路由(原则三:散成分支)
}
}
}while (FIBv6容量未满)
上述算法只是个参考例子,实际使用时还可以进一步优化。
| 

{kind=link}
{kind=link}
{kind=link}
{kind=link}




楼主辛苦了,如果能对Linux以及BSD等开源系统的IPv6转发数据结构描述一篇更好。
【图中Prefix Database首个P3应为P1】
第二个图
不错,有几个问题:
1、是否TCAM可以用于LPM,如何用?
2、实际业务部署上,IP地址的分配和聚合是考虑网络性能的,所以并不是最坏情况,所以是否能针对实际IP地址部署的情况和原则设计一些合适的测试模型,也就是首席关于理论上最优解其实商用可能就无解,所以商用方案次优解最好,也够了。当然,如果有人抓小辫子来攻击路由器,那么就需要路由协议好好考虑安全问题了,此前appleleaf做过一些文章
3、因为CIDR,理论上IPV4嵌套的可能是30
同问,为什么不是使用tcam 做ipv6的lpm,貌似很多芯片都是这样做的。
对于海量的IPv6地址查找,用tcam的话成本和功耗都非常大
关于理客说的次优解,很多时候你是无法估计某一时段网络情况的,假设一天当中只有几分钟你的次优解的弱点会被显现出来,网络延迟很大,要看运营商能不能扛下这个后果了
我是做芯片出身的,所以总是感觉如果使用tie-tree或者类似的算法实现lpm时,查表次数不是固定的,所以performance无法得到保障(恶劣情况会导致大量丢包),不知道这个对需要海量路由表的高端路由器来说,是不是可以接受?
对于这个问题,坛子上有没有作np的牛人来clarify一下?
还有,对于高端货,功耗还是这么重要?对于tcam的价格还是那样敏感?
答复:
1)TCAM是可以用于LPM查找,性能和容量都是恒定的。但有两个缺点:功耗太高;容量太小。当前TCAM最大的为40Mbit,一片可以放下256K IPv6表项,如果是2M IPv6则需要8片TCAM。 显然在高商路由器中用TCAM实现IPv6不现实。 倒是象Broadcom的L3芯片可以用TCAM,因为它只需要很小的IPv6 FIB。
查表又不是只查个前缀, 还有一些general的packet classfication 也需要, 那么TCAM位宽现在大多是288bit 或者 320bit. 当然不够给IPv6用. 640bit的tcam chip也刚出来而已.
海量路由应该用的是专用查表器,有了解的湾友可以解密一下
好像Darktom同学提交这篇文章时,分类中有一个‘弯曲推荐’,审批时被我去掉了:-)。加入‘弯曲推荐’的权利由弯网编辑部保留。根据读者的feedbacks,我现在把它加到‘弯曲推荐’。
For NPU based IPv6 forwarding algorithm, please refer to:
“High-performance IPv6 forwarding algorithm for multi-core and multithreaded network processor”,
http://portal.acm.org/citation.cfm?doid=1122971.1122998
我也共享一篇CRS-1采用,William Eatherton的大作:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.12.6583&rep=rep1&type=pdf
Broadcom的L3 TCAM支持的是32bit的key,用来实现128bit的IPv6地址的TCAM查找怎样实现呢?
应该是比较复杂吧
今天加班,来分析一把:
1 为什么lpm, 因为cidr
2 为什么cidr,因为ipv4地址不够,需要重新分配ip,并保持原有的ip分配不变
3 ipv6为什么要lpm?因为管理不当?
4 为什么ipv6要有million的路由? ipv4路由多的原因可能也是因为cidr的原因? ipv6地址那么多,我想在数十年内还是可以做很好的路由规划和路由汇聚吧?
5 对于9楼,为什么查ipv6路由的时候要同时classification?在一个合理的设计中,fib和classification rule是分离的。
6
aaa有道理
离散测试针对普通Multi-bit trie有用,针对Tree bitmap一类优化后的Trie树算法不一定有用。因为限定容量的可能是最后一级,也就是result array。
嵌套测试对于用了leaf push的算法可能有用,如果不push,不影响更新性能。但是嵌套测试能够测试出查找的性能,因为针对IPv6,很多Trie算法都采取了Skip的优化,就是跳过没有分支的键值,来减小内存读取次数。嵌套多了就不线速了。
路由离散对于tree bitmap的影响分析:
一个步长8bit的Trie Node, 需要256bit child bitmap,256bit prefix bitmap和Pointer,共64字节。
最好情况一个bitmap可以装下256条路由。最坏情况一个bitmap只有装下1-2条路由,二者相差100倍。很难说64Byte的Trie Node数量不是容量瓶颈。
aaa提得很有道理,如果严格按IPv6地址分配标准,则IPv6路由表很小,而且网络路由全部是64bit以下。但实际上,运营商并没有此信心。这从大运营商的两点测试行为可以看出:
1)测试掩码64-128bit的前缀,如文中提到的72、80,88等;
2)要求至少512K IPv6 FIB,甚至测试1M-2M FIB。
可见运营商是准备应付未来出现的各种地址分配可能性。
————————————-
3 ipv6为什么要lpm?因为管理不当?
4 为什么ipv6要有million的路由? ipv4路由多的原因可能也是因为cidr的原因? ipv6地址那么多,我想在数十年内还是可以做很好的路由规划和路由汇聚吧?
没人发现么,用例A,是错的,路由数加起来不是50万
现在,真实世界, 我是说运营商什么的, 真的启用IPv6了么? IPv6的网络有多少用户?
我知道, IPv6 是一个必备功能,但是光看支持,没见有用的啊
相对于功耗,我认为TCAM的成本更可怕。具体的价格就不讲了,反正和DRAM比起来,天上和地下。
目前,那些老的路由器多数是256K个entry for unitcast。大规模部署IPV6,让这些老马车情何以堪。像思科这些设备商倒是非常乐意,运营商可不这么想啊。
我认为,IPV6是否能大规模实现,取决于像LISP这样的协议们–这个真的可以有。到那个时候,现有的老马车不需要扔掉,新上的大table,多entry豪华马车用在edge上(配合MPLS)。五年后,绝对有可能
因为V6本身对运营商基本上没有什么revenue,但一定是cost,运营商更多是V4地址不够所被逼而上V6,更prefer低TCO的方案。除非另外一个Jobs再生,搞一个popular的必须用V6的app?
嗯,内核就是这么实现的
有个疑问,IPv6地址海量,还需要掩128位,对CIDR来讲,网络规划需要到128层吗?
作者只是从理论上讲,实际网络规划也会按理论思路。
对IPv6来讲,掩码是不是需要一位位来掩,这都是问题,在IPv6没有应用的今天,如果按128位一位位掩,在Edge Router上2M的IPv6是不够用的,所以,IPv6的网络怎么来部署,去掉地址数量的限制,BRAS,NAT,PPPoE是否还有意义,是不是采用态地址及Aging机制,请位大虾阐述下
对IPv6对运营商没有Revenue的说法,窃以为是错误的,物联网这种新兴事物是很需要IP地址的,同时,IP的地址的很少,动态分配机制也导致了网络带宽的浪费,有Router经验的人可以思考一下,在AS与AS间,往往有多路选择的问题,走到头才发现网段路由找到了地方并没有此主机路由,这都是BRAS过高导致的
当然我有些书写错误啦,事实上作者是用IPv4的网络规划来阐述IPv6的网络规划,感觉有些不对,其实我懂得也不多。
抛砖引玉,希望有真的大虾来阐述下,是不是就真的要规划很多层
人类社会组织结构有多少层,网络组织结构就需要多少层.就这么简单.
abel太高深了,有点不懂
请教下,我存细看了对IPv6的测试用例的描述,好像掩码的STEP是8,全局只有8种长度的掩码,是不是?
这样说来,IPv6的掩码复杂度其实是跟IPv4差不多的,对不对?
不好意思,看错了,是8bit 步长是采用8的原因是因为分成了8Bit段。
按作者的意思,IPv6最长掩码是64,这个根据是什么,这样的话,最大可以划64层,是不是?
还有个问题,是不是所有层的Rouer均是这样一个测试用例
好文。
LMP及SKIP那一段对于理解Linux kernel L3的radix tree很有帮助。从原理上把radix tree给阐述清楚了。
TO SPY:测试用例的设计只是提供一个构造嵌套层数的范本,将设备的真实能力给找出来,并不代表实际网络就有64层。因为被测设备是黑盒子,我们并不知道它是使用TCAM还是使用算法实现IPv6查表。
1)TCAM天然不怕IPv6路由嵌套,但缺点是容量小,功耗高。
2)算法。 以Trie算法为例,容量和性能对路由商散性和嵌套很敏感。
64位prefix只是一种推荐的部署方案,况且 目前主流的OS的stateless方案也只支持小于等于64位prefix长度,大了获取不了地址。如果你用stateful也就是DHCPv6获取地址,那prefix随便你多少位都可以。
怎么还在讨论这个老掉牙的问题。
没难度,没技术。
IPv4 Residual Deployment on IPv6 Infrastructure
http://www.ipinfusion.com/sites/default/files/document/IPv4%20Residual%20Deployment%20White%20Paper.pdf
我倒觉得 这个讨论很有含金量