




网络设备中的多核OS的讨论–Case Study Hillstone StoneOS
作者 deltali | 2010-12-23 07:30 | 类型 行业动感 | 74条用户评论 »
|
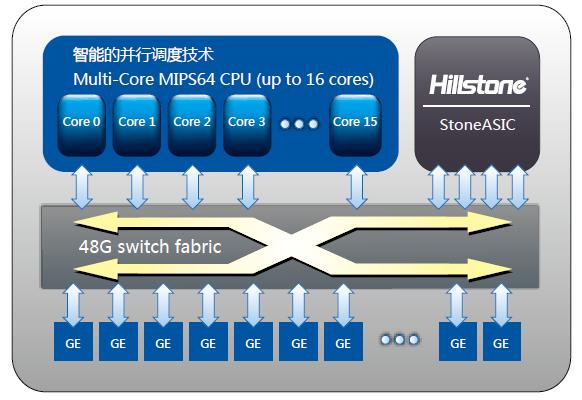
引子: 10月中旬的时候,首席发了个北京上地的pre-ipo的网络通信公司招聘帖子。里面的股票,重金一下子刺激了我的眼球。凭借着对linux kernel和虚拟化技术的热爱,我毅然投了简历。结果如泥牛入海,杳无音讯。但在此期间内,我为了方便面试提前做了些调查功课。在目标上根据北京,上地,海龟,通信安全公司,我的第一反应和大家一样,认为是山石,但是随后我又锁定了另一家公司—a10 networks。Google了下2家公司,发现它们的产品都是基于多核平台,特别的它们都开发了基于多核的OS。于是多核,智能化调度,64位并行OS 一下子取代了股票和重金对我的眼球开始了新一轮的冲击。作为一名内核开发的爱好者自然想了解下这些OS是如何实现的。因此特地以山石的StoneOS写了这篇文章,希望和弯曲的高人能一起探讨一下。 资料来源: 并没有Google出太多的相关资料,还好有相关的白皮书,于是我就以白皮书为参考资料来写这篇文章。如果有什么理解错误,希望大家能及时指出。 http://www.hillstonenet.com.cn/cms/down/pdf/FullyParallelArchitecture-WhitePaper.pdf http://www.hillstonenet.com.cn/cms/down/WhitePaper/SafetyRoof-WhitePaper-0424.pdf 山石使用的是Cavium公司的octeon系列的产品,具体型号我不知道。但是并不影响我们的讨论。 产品架构: 从山石的白皮书和他们的产品宣传看: 1. 硬件平台架构:
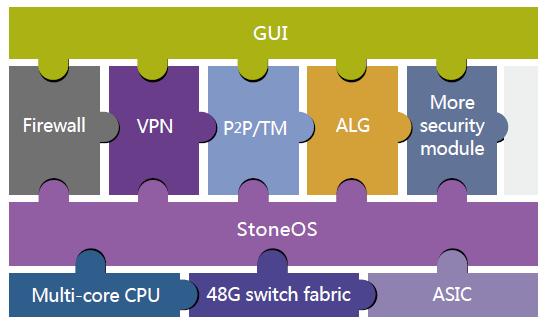
2. StoneOS软件架构
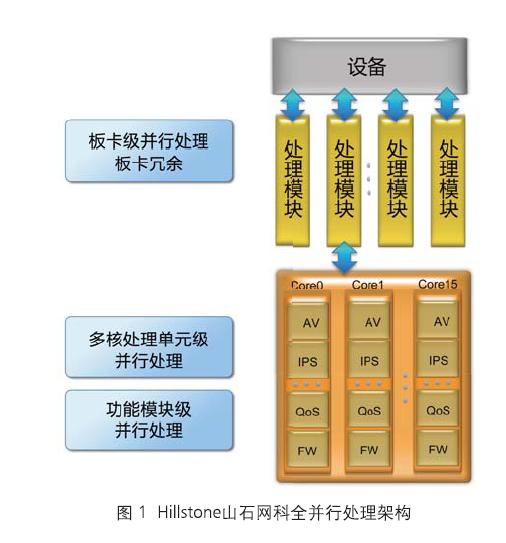
Hillstone的网络级安全是由ASIC来实现,而耗费cpu的应用层的安全加速则由多核cpu来实现。 3. 全并行架构
Hillstone点出了当前并行的技术难点,他们是通过实现3个并行来解决:板卡,cpu和核内多功能。 1. 板卡间的并行应该是IOM硬件来将负荷智能分发数据到各板卡 2. 各个板卡上的cpu的功能应该是对等的,除非是某个数据包必须要在某个cpu上处理,否者数据包可以在任意一个cpu上被处理 3. 每个cpu core上跑的软件也是相同的,这样就能实现全并行数据处理 1是硬件来处理,2最终是由3来决定的。 从白皮书来分析的话,最让我不明白的是3的实现: 我原本的理解是各个cpu之间是smp的关系,每个cpu的处理功能都是一样,但是cpu里的多个core是amp的,它们根据要处理的功能的多少和先后关系,把当前的cpu内的核划分成不同的group来实现流水线并行。 但是根据白皮书的上图和山石的宣传看,每个core上都集成了所有的功能能让一个数据包在该core上做完所有的处理, AV, IPS,…, Qos, FW等。 这样的话,问题就来了: 多个功能共享单个core时,一个数据包是只能串行的走完各种功能的扫描。如何实现功能并行处理呢?当然如果说把这些功能弄成流水线,core每次读入一批数据包,然后依次切换到对应的功能处理模块线程。即便是在cpu性能高的时候这行 但是随着业务的发展要处理的功能增多时,各种功能模块切换的开销也会递增,cpu利用率也会变低。另外一个问题就是某个流水线阶段处理较慢的话,除了动态加大它在该core上的处理时间外,没有其它的加速方法了。 不知道山石的真实设计究竟是咋样的。 我猜想的设计可能是: 1. 每个core都是硬件多thread,但是山石使用的是octeon 芯片,octeon芯片好像没有实现硬件多线程 2. 虽然每个core上的功能一样,但是每个core只全速跑设定的某个功能,除非有命令让它执行另外一个功能。这样的好处是将cpu里的core划分成不同的组来执行功能处理流水线,当某个组在处理某个功能流水阶段(比如:IPS)很吃力时,可以把其它的负荷较小的组里的core划分过来来增强处理,因为每个core的代码是相同的,这种划分是很容易的,通过设置某个标记就能让core改变要执行的功能。整个网络负荷小的时候还可以减少各个group里的core数量。这样每个core都是全速的跑应用而且没有任何的线程切换开销。 希望山石的大牛能出来给我指点一番哈。 综上: StoneOS大概由控制平面+数据平面多核的资源管理+数据平面上每个核的代码 组成 1. 控制平面的话:处理各种命令,显示数据平面的处理结果,进行各种配置和管理 2. 数据平面多核的资源管理:在IOM分流的基础上,监控各个cpu的状态,能根据实际负荷进一步的对数据包做智能调度。同时对各cpu内的各核状态也进行必要的调整 3. 数据平面上的代码:主要是针对应用层的处理,按照实现安排好的顺序走完功能流水线 4. 因为需要使用共享资源,所以如果没有硬件提供同步与互斥的话,stoneos需要提供能同步和互斥访问共享资源的软件手段。 最后: 在资料查找过程中会发现,各厂家的多核基础架构都大同小异。都有自己对应的OS,比如: A10 networks的ACOS http://www.a10networks.com/products/axseries-acos-architecture2.php http://www.a10networks.com/resources/files/WP-ACOS.pdf http://www.a10networks.com/resources/files/SB-ACOS.pdf anchiva的AnchivaOS http://www.anchiva.com/download/AnchivaOS_V1.0.pdf 还有国内的SecOS, TOS,几乎各个安全厂家的多核产品都有自己的OS,通过对应的白皮书可以看到去除各自的业务需求,在OS这层的功能实现应该是大同小异。大家要有兴趣也可以继续分析。 谢谢能有人看到这里,说实话这种文章不好写,没见过相关的产品,也没用过网络多核处理器,好多东西只能凭着对白皮书的理解来写。写了一半的时候曾想放弃了,但是想了下多核是将来的一个趋势,肯定有很多跟我一样想深入了解下多核操作系统的应用的人。网络无疑是多核应用的最多的领域,然而很多东西只有弄过了才能真正的了解,但是这种机会太少了。有时候行内人或者牛人的一句评论比很多人花费几天时间研究出的东西还有价值,希望这篇文章能有这种效果 | |
 (没有打分) (没有打分) |
雁过留声
“网络设备中的多核OS的讨论–Case Study Hillstone StoneOS”有74个回复
DeltaLi,你是自己在乱投的,还是把简历给了我?最好的办法是读者们把简历都在我这里存一个copy。。。。。。
另外,透露一哈。山石的N个创办人没事也在这里溜达,潜水。所以,你这个文章一出来,后果会很严重。。。。。。山石的同学们,回答人家的技术问题呀。。。裸奔一下嘛。。。。。。
我来谈一下:
前端的Classifier是一个关键。
另外,PCI-E的ASIC还是不错。是NetScreen的方案体系结构的一种继承。
总之,多核+ASIC确实不错。表扬一哈。
坊间传闻,ASIC不存在。
一般的产品如何设计定位,是决定于如何平衡客户需要、竞争对手和自身资源这个三角关系,不同的公司,这个三角关系是不一样的。
比如华赛:客户方面和运营商好、竞争对手C/J为主、自身资源可以利用路由器平台,那么它的安全产品必然要和山石不同。华赛有硬件平台好、共享硬件成本低,利用HW的运营商关系等好处,但劣势是缺乏企业网的经验
比如山石:客户方面主要是企业用户、竞争对手是诸多企业级安全厂商、自身资源有NS的ASIC功夫
在此三角关系上,再考虑业界趋势判断,一起来确定产品的功能性能、主打客户、生命周期、成本控制、核心器件选型等等。这里一个是要有牛人掌舵,另外一个就是要有系统的分析管理而不是关键时刻总是拍脑袋。
to 理客:非常好的点评…对于绝大多数产品经理来说…真应该看一下你这段话…尽管未提及山石设计本身…但是跳出“设计”的框框来统观产品的“定位”这一点尤为关键…大多数网络/安全公司都缺乏这样的产品经理…人云亦云亦步亦趋的反而更多一些…
图2是P2P/IM吧?
如果真有ASIC,小包怎么才3G?
用商用芯片的后果就是产品同质化,每家的xxOS都差不多,最后做出来的产品规格也差不多
谢谢首席帮忙把名字排版了一下。
其实没啥,真正的核心还是在设计细节和对业务的理解。大面的东西估计各大厂家都差不多。只不多是对我们这些局外人来说还比较神秘。
强大的ASIC设计能力,对业务精准的划分,才是这些OS的存在基石。
另外:
首席,我没法瞎投的,你那个帖子好像只留了你的邮件。不过这只是写文章时开的小玩笑,我都工作多年了,被工作据过也据过工作,心理能力ganggang的。
其实说实话股票和高薪啥的都是一时的刺激,真正我还是想去个能耐心踏踏实实做事的公司,不要忽悠。真正搞技术的人最大的成就就是有天能指着某个产品说,嘿,这是我搞出来的。当然必须是很骄傲的说。
你把resume给我一个。刚才有人越洋电话来要人了。。。整的现在像我失职的样子。。。
没仔细看,随便说说。
如果只是协议和状态处理这些(ip包解码),
多核就能做的很好,似乎用不着asic,
如果是ips和av,那么多核的网络处理器
性能很差,
所以要么就一个多核处理器,包打天下,
性能差点,好在便宜。
要么加处理器(各家五花八门,asci,fpga,协处理器都有)做内容检测。
说良心话,我基本上没有真正的琢磨石头OS。据说医生不给亲人看病;首席不给朋友把脉:-)。
有时瞄一瞄结构图。总觉得这个48G的Fabric是个大问题。估计一灌multicast traffic,就歇了?有没有测试数据?
请教首席,谁家的七层设备灌multicast不歇?他的架构是如何设计的?
咔咔卡。我的意思是,我感觉StoneOS就是灌正常的through traffic都歇。当然要求过分了。反正石头一定是通过switch接在router后面的。不能拿routing的要求去要求stoneos。。。
A10的系统构架主要是为了解决L4-L7的并行处理问题。
文中引用的资料太老了,基于此讨论价值不大
我刚才与石头的CEO打了个电话。他吞吞吐吐的告诉我:似乎没有ASIC了。。。情何以堪!
是,如果有ASIC,FPGA,还是很花银子的。。。
to 老韩:
如果你有新资料,而且方便公布的话,也可以发出来让大家分析下。
其实这个东西就像大家分析魔术一样,观众来分析就是好个明白,但是魔术师是不会告诉你答案的,尽管他们知道大多数人即使知道答案也不会去表演魔术一样,毕竟行规如此。
当然了如果能有人点拨一两下,那就是这篇文章的最大收获。没有也没啥,就当是我的一个阅读笔记。
to 首席:
哈哈,这么晚还在奋斗啊。
其实当时在写文章的时候还在想,对于没有实力研发ASCI的小厂家来说。通过并行把网络功能和应用功能做到多核上,不就能冲击下低端市场了吗?
哈哈哈。果然是没有asic的。。
其实如果用acic或者别的协助处理,
就要下决心把ips做到G以上(av木有办法滴),
但是ips又涉及实时响应和分析队伍,
这个比较难搞。。。
新资料,Release的我原来写文章都引用过了,可翻查。
现在硬件平台也同质化了。如果这里有做平台的或平台的客户,应该知道我说的是谁。
基于平台的硬件开发也是个方向,好处坏处各半吧。
做一颗ASIC在设备里面,真的需要很大的投入和很多的积累。也只有思科和有专业芯片体系支撑才能真正去做。
刚看的第一个帖子是说FPGA+A9,用来做板卡或设备未必不是个新选择。
传说asic不适合以后应用方向的发展,不只是在多核的能力下体现不出多高的性能,而且还影响软件架构。
每个core上都集成了所有的功能能让一个数据包在该core上做完所有的处理, AV, IPS,…, Qos, FW等。
//真跑起来了,FW的只是更新下seq,AV算下哈希,IPS走走prefilter,QoS则只是根据一次性的policy查找进某个queue,这时候不并行也快。真跑不起来了,AV文件重组,IPS正则表达式匹配,这时候再并行也还是慢。
多个功能共享单个core时,一个数据包是只能串行的走完各种功能的扫描。如何实现功能并行处理呢?当然如果说把这些功能弄成流水线,core每次读入一批数据包,然后依次切换到对应的功能处理模块线程。
//Core一次从POW读一个包出来,由硬件完成保序;费劲的处理可以resubmit到其他pow group,交由片上(crypto/dfa engine)和片外(asic)协处理器处理,之后再回来,实现流水作业。
//ps:谁能搞清hillstone中对cache的管理和对packet data而非work的存储和优化?Full DPI玩的是包,不是meta了。
首席还需要和石头的CEO确认一下有没有ASIC,他们的项目没有请你先review?
不过好像有的安全公司经常把FPGA说成是ASIC。
突然发现蹦出来这样一个公司,www.diputech.com,什么背景?首席分析一下?
这样的话,问题就来了:
多个功能共享单个core时,一个数据包是只能串行的走完各种功能的扫描。如何实现功能并行处理呢?当然…
胡乱猜想一下:数据面不需要并行处理吧,一个连接一个控制块,来一个包查一次HASH表,这样收一个包处理一个包的速度应该很快的。可能需要将LINUX内核的中断处理去掉,CPU直接暂询网卡及周边设备的寄存器状态。这样,整个系统一个锁都不需要。不过可能需要解决数据面会话与CPU的会话保持问题
http://www.diputech.com是H3C出来的人搞的安全公司吧,目的是进入政府,军队行业的项目,貌似老大的是王冰?高人指点一下看看。
在杭州。。。感觉还真是H3C出来的弟兄:-)。。。
哪天我来写个初创公司,推荐一哈。
安全市场的市场pie很小,但为啥能容纳这么多小公司。我反正也是想不明白。Switch,Routing市场大,但其实反而没有许多小公司。。。为什么? Barrier 高?
“安全市场的市场pie很小,但为啥能容纳这么多小公司。我反正也是想不明白。”
因为需要无数的”墙”
“Switch,Routing市场大,但其实反而没有许多小公司。”
因为业务同质化
问下小象,墙是啥意思?
使用asic,硬件功能扩展比较难了。
控制面流量不大,不需要并行处理的。我感觉是弄一个core专门处理控制面,没有什么并行。其他核用来并行处理数据流
http://www.diputech.com,听说还有大鱼!
感谢弯曲评论,搭建了一个与高端人士沟通的平台,能了解到很多前言的技术。
同时感谢给我发邮件的精英分子,因出差耽误了邮件处理,导致延迟产生,但是没有丢包,都回复了。
本公司规模小,但是里面的人都是精通安全编程、安全攻防,现在想把产品移植到多核,或者大家有什么更好的平台架构给我推荐,再次感谢大家。
我的邮件地址:asdf8360@126.com
期待着大家的建议,同时也招聘兼职或者专职!
回答29楼的中兴小象:其实安全防护不等同于防火墙。构建安全保障体系需要多种技术手段共同创建,才能保证用户的安全,降低用户的风险。但是遗憾的是并不是大安全厂商都能通吃一切,相反有些小安全公司正是精通某个领域的小的安全技术,因此就存活了,如我们公司很小,但是生存下来了。
邀请对WEB攻防有研究的人士加盟,最近正在做WEB防火墙产品开发规划,恳请大家拍砖提意见。请发asdf8360@126.com
看完了~哈哈, 个人感觉
1. 多核并发的关键在于数据平面最底层的分发策略.
比如: 按连接发起者地址分发(源地址), 如此一来, 同一个用户的连接只会在一个core上面处理, 需要跨core共享的数据就基本上可以忽略了. 流跟踪, 用户跟踪,等数据结构
都不需要并发保护机制.
2. 数据平面上, 每个core需要完全负责处理被分发到该core上的流. 如: 流跟踪, DPI, 当前流统计, 甚至是QOS. 这样, core都在干活, 而且大家互相之间基本上没有需要共享
的数据, 都在个忙各的. 数据平面提供API供管理平面获取 流信息, DPI处理结果, 以及流统计信息.
3. 管理平台除了提供UI和配置程序, 还需要调用数据平面的API, 以此搜集所有流的识别和统计信息, 分析并进行ACL策略匹配, 然后转成对数据平面的控制指令.
4. 类似Qos功能, 需要进行跨core统计的工作也可由第三方负责, 这个第三方可以是数据平面的某个core, 也可以有管理平面负责, 具体看对统计信息实时性的需求而定.
即: 每个core都在自己的PerCPU变量上进行统计, 第三方来读取, 然后更新到全局统计变量, 而core在做Qos的判断时, 读取全局的统计变量, 而不要去更新它.
另外, 对于没有能力进行ASIC的小厂商来说, Tilera是个不错的选择,
据说某公司已将其开发成一块高度可定制的”网卡”.
除去成本方面的考量, 其性能匹敌10Gb的82599, 而灵活性和数据流的4-7层处理能力却是后者所望尘莫及的.
这方面高人不少啊,呵呵。
to 加菲猫:
2. 数据平面上, 每个core需要完全负责处理被分发到该core上的流. 如: 流跟踪, DPI, 当前流统计, 甚至是QOS. 这样, core都在干活, 而且大家互相之间基本上没有需要共享的数据, 都在个忙各的. 数据平面提供API供管理平面获取 流信息, DPI处理结果, 以及流统计信息.
//我现在的疑问就是单个core负责处理分发给它的流的所有工作,如何能更好的实现并行呢?不过从清华土著的回答来看,这似乎又不是个 问题了,呵呵。
to 清华土著:
Core一次从POW读一个包出来,由硬件完成保序;费劲的处理可以resubmit到其他pow group,交由片上(crypto/dfa engine)和片外(asic)协处理器处理,之后再回来,实现流水作业
//这个有点不解,这个费劲的处理是包流水处理功能中的某个功能还是全部?
能否更详细的说下如何实现流水作业呢?谢谢!
to 加菲猫:
1. 多核并发的关键在于数据平面最底层的分发策略.
比如: 按连接发起者地址分发(源地址), 如此一来, 同一个用户的连接只会在一个core上面处理, 需要跨core共享的数据就基本上可以忽略了. 流跟踪, 用户跟踪,等数据结构都不需要并发保护机制.
如果收到这个连接的反向报文,如果按照源地址HASH,很可能分配到另外一个core,如何解决?
to:酱油男, 连接发起者的地址(流的源地址) — 这个地址对于反向报文来说, 就是目的地址啊~ – 连接是具有方向性的.
to:deltali, 微观上看, 每条流需要处理的复杂度的差别很大, 但宏观上看, 因为是按照源IP分发, 所以流的分发具有一定随机性, 每个core分得的流中, 复杂流和简单流 所构成的比例是大致相当的.
很多号称ASIC+MCore的厂商, ASIC其实是交换机芯片提供的, 其灵活性可想而知, 比如上面, 需要按照连接方向控制分发的策略, 交换机芯片如何搞?
1、目前安全领域是一个适合高度细分的市场,未来解决方案会逐步统一,包括硬件/软件解决方案都会统一,谁不同质谁淘汰;
2、多核是个资源池,动态分配,耗CPU的功能就多分资源,这样才合理。
to 加菲猫:
那就是说你要查连接表了,不就是需要锁保护了。
三天都在忙,上来好文一大堆啊。没和大家一起探讨真是损失很大。
首先,无论是山石还是别家公司,那个架构图都不是真实情况,都是用来忽悠客户的,为的是便于用户理解。我曾经也为了更好的忽悠懂些技术,又不是真明白的用户而画过一些花里胡哨的流程图或者原理图。
其次,个人感觉因为安全毕竟是小众产品,就如同上面很多人所说,已经到了定制化,按用户需求出产品的阶段了。因此专门为了提升某个功能做ASIC意义不大。毕竟成本太高了,研发周期也长。这也就是为啥多核受追捧,但除了防火墙,别的性能提不上去的原因。
顺便,迪普就是H3C的国内牌子。这一套国内厂商都搞,地球人都知道。
to:酱油男, 单纯获取连接的方向, 一般来说是不必查连接表的. 因为安全设备的物理部署方式比较特别, 不像路由器~
to 首席:
做路由器、交换机的厂家少,是因为能做出来的厂家不多。网络设备的任何一个功能单拆出来都不难,整合在一起就要命了。成本竞争,尤其是低端产品的成本竞争压力也非常大。没一定的实力的公司还真搞不定。
做安全相对其实简单多了,搞明白了iptables和snort,再加点想象力,可以搞定很多种类型的产品,性能要求也不是很高,门槛反倒相对低的多。
To: deltali
这个有点不解,这个费劲的处理是包流水处理功能中的某个功能还是全部?能否更详细的说下如何实现流水作业呢?谢谢!
//费劲的处理在各大厂商中都要避免的,比如文件重组(不重组无法解压,不解压无法识别混合打包的流量),比如重组后真正的基于DFA的regular expression(hash,hash,可爱的hash,只支持字符串的hash,只支持长字符串的hash)matching等。没有tricky的重组和硬件参与的matching,很难将这些full functional的东西做到wire speed,这些不是流水能解决的范畴。当然,再强调一次,厂商们可以布龙布龙的滤掉,嘻哈嘻哈的匹配,streaming streaming的抛开重组,于是最终,就能靠total frequency解决问题了。若有偏颇,请高手指正。
to 加菲猫:
2. 数据平面上, 每个core需要完全负责处理被分发到该core上的流. 如: 流跟踪, DPI, 当前流统计, 甚至是QOS. 这样, core都在干活, 而且大家互相之间基本上没有需要共享的数据, 都在个忙各的. 数据平面提供API供管理平面获取 流信息, DPI处理结果, 以及流统计信息.
如果一个core来做这些事情的话,那这个core岂不是一直在做事情?那这个负责分发的core会不会轮转?
分发core专职负责收包分发, 以类似死循环的方式监测数据帧的到来, 解析数据帧, 按策略分发到对应的业务core, 并通知业务core: “有事要做…”
这种多核分流处理的架构早有了吧。比如国内骨干网的内容还原监控,单台双cpu 8核 x86架构,就能处理20Gbps流量。用Cavium主要解决转发包效率问题,用在流控合适,单纯对7层协议深层分析还是x86 cpu运算效率高。
就x86架构而言,现在处理瓶颈是输入接口(pcie
总线),内存带宽。cpu的运算能力应该可以到40Gps。
to multi-core,贵公司大名是什么,让大家景仰一下
实在不好意思,这几天非常忙,今天上来发现这么多的好帖子,学习了!感谢感谢!顺便祝大家在新的一年了收获多多,祝首席的论坛人气大增。
to george我们现在还没有公司,我们是一个软件工作室,给国内一安全厂商开发安全产品,公司注册正在进行,LOGO设计也在进行,2011年3月份正式以公司的名义与外界交流。
祝multi-core成功,给搞技术的兄弟们趟个路,做个榜样。
感谢george 的祝福,我会尽力不负众望!
谈及cavium和RMI,甚至Tilera的比较多, 好像很少有提起IXP系的后代啊? 不知道如今怎么样了.
用asic成本太高的话为啥不用fpga呢。。啥都没有打广告还标着asic,太忽悠人了:)
提高IXP就郁闷,当时2800做完,芯片就被卖了。。没后续了。mmd。
提到IXP就郁闷,当时2800做完,芯片就被卖了。。没后续了。mmd。
qingjiegong是leadsec的还是topsec的?呵呵。
IXP?貌似授权给Netronome了。目前的推的是NFP3200系列,算是2800的延续吧。半年前来推过,考虑到其处理性能及货期问题,pass掉了。貌似现在也拿不到样片吧
46 & 47楼,82599之类的网卡已经可以直接硬件把packet分发到不同的core上了吧?
to 加菲猫:
数据面分发的策略里,如果把所有的功能都部署在一个核上完成,确实可以避免很多数据共享保护带来的开销。这个时候我感觉分发策略本身确实如你所说会变得非常重要,而按照源地址进行分发,能否做到核之间的负载均衡呢?
我有个想法,用ASIC芯片来做数据流的分流处理,根据分流结果,依次转发给各个核进行处理。这样至少在业务分配上,感觉核之间的负载是均衡的。
另外,感觉加菲猫你在数据面并行处理方面比较专业,想请教个问题,能否详细说明下业务流水线模型与数据流分发模型之间各自的利弊。我自己有点认知,但可能不够全面
=================
1. 多核并发的关键在于数据平面最底层的分发策略.
比如: 按连接发起者地址分发(源地址), 如此一来, 同一个用户的连接只会在一个core上面处理, 需要跨core共享的数据就基本上可以忽略了. 流跟踪, 用户跟踪,等数据结构
都不需要并发保护机制.
2. 数据平面上, 每个core需要完全负责处理被分发到该core上的流. 如: 流跟踪, DPI, 当前流统计, 甚至是QOS. 这样, core都在干活, 而且大家互相之间基本上没有需要共享
的数据, 都在个忙各的. 数据平面提供API供管理平面获取 流信息, DPI处理结果, 以及流统计信息.
@ 59,硬件支持,但是还是要软件来搭配啊
NAT 情况下如何保证发起包和回应包都由同一个core处理呢?
1: 看看 CAVIUM的octeon的SDK就知道了。其中提供一个很重要的功能就是包分类器classer以及一个把队列处理的WORK机制(名字记不起来了).相当在网卡读包的时候就给包打一个标签,方便到CPU的分类;
2:可以按照包分类,也可以根据流。因为各个数据流之间相关性不大,所以根据源IP或者端口把不同的流分配到不同的核上。只要能均衡分配即可。
3:在每个核上,处理完所有的工作。例如路由、NAT、ACL等。
4:如果之间有关联,则需要单独的处理,把相关流重新分配到同一个核上。
软件的基础架构都是依据分类器这个功能。按照流分配时最简单的方式。应该没有采用流水线的方式。只要看CAVIUM的SDK就可以。从技术白皮书上书难于猜测到的。我相信山石也不能脱离CAIUM的SDK开发。只可能针对自己业务做了个性化处理。因为多核编程一定是在熟悉处理流程的基础上才能得到高效的处理能力。客观地说山石的性能还是包吞吐率还是很高的。尤其小包吞吐率。
至于硬件架构。山石好像是自己设计的板卡,但是基于CAVIUM的芯片设计的板卡不是很难。无非是把交换芯片等增加进去。
至于是否有ASCI,则不清楚了,只有知道这个ASCI是干什么的,就能猜测出是否存在。
我觉得以上大概不离其中。
看着分析, 差一点儿崩溃, 真有点皇帝新装的意思. 这不童总经常临幸弯曲, 布个道也能让大家都学习学习(歇息歇息)?
to 11 天外有天
为什么说“如果是ips和av,那么多核的网络处理器
性能很差”?
“可以按照包分类,也可以根据流。因为各个数据流之间相关性不大,所以根据源IP或者端口把不同的流分配到不同的核上。只要能均衡分配即可”
典型一个做路由器的。防火墙需要有流的概念,而且数据流之间的关联性可以很大。
to regardlan :是ASIC
to 阿土仔 , 笔误 ,是ASIC。
流水线的方式很大的缺点就是要求多个核之间的运算时间要相等,否则有些要等待。这对防火墙这种设备几乎不可能。所以每个核上跑所有任务就比较合理。
但是要把流量均衡分配到不同核上,才能发挥多核的作用。所以这里对包分类就很关键。可以按照包分配,也可按照流分配。但是按照包分配显然是不合理的。因为同一流的包分配到不同核之上。需要处理包之间的关联性。所以按照流分配就比较合理了。把同属于同一流的包分配到同一核上。
一般情况下,流之间关联度不大,所以分配到不同核上比较合理。独立性强。但是也有之间有关联的,最简单的就是FTP的控制连接和数据连接。所以还需要处理流之间的关联性。
还有ASIC?不是上了multicore,一下子就把ASIC打败了吗?不知HS挖来的ASIC牛人现在做什么。
前面看人说道“客观地说山石的性能还是包吞吐率还是很高的。尤其小包吞吐率。”如果有印象的话,可以看看弯曲转过的计算机世界对HS的x6150测试报告。100G大包的设备,小包只能到17G左右。而且还是堆到了7块处理板。反正那个测试报告里,处理板的数量在5、6、7之间变换,到底性能咋样只有老韩明白了。
其实防火墙的性能有用的是看混合包。比如JUNIPER,指标中明确指出混合包的性能,很负责。混合比好像是6:3:1。
当然了,这儿主要讨论的是多核。我只想问问,小包吞吐量不高,到底是多核的问题还是优化的问题?我不是研发,随便一说
to 69,按照你的说法,如果一个流的速度很快的话,极端情况下这个流有几个G的bandwidth多核仍然等同于单核啊,实际应用中不会出现这种情况?
“各个板卡上的cpu的功能应该是对等的,除非是某个数据包必须要在某个cpu上处理,否者数据包可以在任意一个cpu上被处理”
数据包至少要按连接分发。
特别是他们这种需要审计用户行为的产品
regardlan 正解读