作者:徐鹤军 单位:上海泛腾电子有限公司
当多数计算机工程师还在为如何充分发挥当前多核CPU的实际运行效果而绞尽脑汁时,Tilera公司内含64颗物理计算核的众核CPU已经开始的商业应用。这是一款专门为了高性能并行运算而诞生的具有革命性技术革新的CPU,采用当今最先进的两维iMesh构架,完全摒弃了传统多核CPU总线互联的结构,完全解决了传统多核CPU并行运算时常有的效率瓶颈,也为今后集成更多物理内核做好的基础构架。
单颗TileraPro64 CPU集成了64颗866Mhz的计算内核,4个DDR2内存控制器,计算内核与内存之间的数据读写从此顺畅无比。尤其还集成了2个万兆网络控制器,摒弃了传统构架中的PCI-E总线的数据传输瓶颈。从此对于网络数据包能够真正达到了万兆级的处理能力。每颗物理计算核都配有交换单元与多条总线连接,是内核之间的连接不再有瓶颈,数据交换更加通畅和实时。
多CPU的编程一直是困扰软件开发人员的技术瓶颈,当前的编程模式难以应对多CPU并行运算的效率,往往是随着的更多CPU加入运算队列,性能提升不明显甚至不升反降,多CPU反而成为累赘。
这时一门叫Erlang冷门编程语言开始引起大家的关注,20年前由Joe Armstrong 教授为爱立信通信公司的电话交换机系统开发的Erlang编程语言,以不同当前编程模式的设计模式,支持超大量级的并发线程。
Erlang社区的名人Ulf Wiger 采用Erlang语言在TileraPro64 众核CPU上实现了运算性能的线性提升,请看下图标:
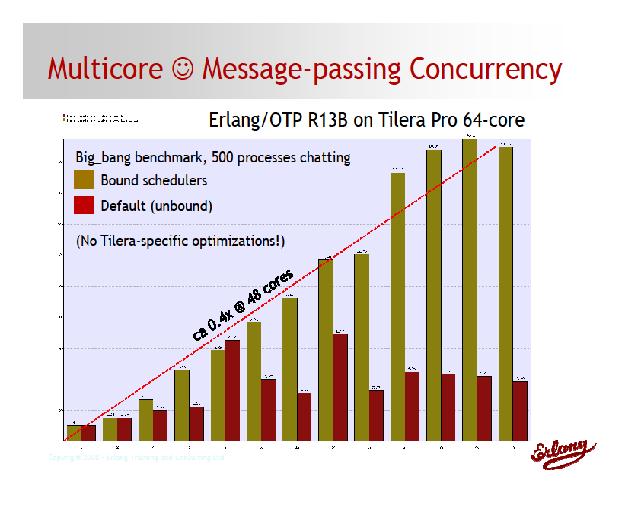
基于Tilera提供的良好软件开发环境,国内Erlang语言的先锋任职阿里巴巴淘宝网的余峰先生也在有上海泛腾电子科技有限公司提供的测试机上轻松实现了Erlang语言的编译和运行。
下面是由余峰先生提供的编译过程:
# wget http://www.erlang.org/download/otp_src_R13B03.tar.g z %
%R13B04后otp_build变了好像有点问题,编译不过去。
# tar xzf otp_src_R13B03.tar.gz
# cd otp_src_R13B03
%%由于R13B03有个小小的bug会导致segment fault,我们需要对erl_misc_utils.c打个patch,以下是要打patch的地方:
# diff -Nau
otp_src_R13B04/erts/lib_src/common/erl_misc_utils.c{~,}
— otp_src_R13B04/erts/lib_src/common/erl_misc_utils.c~
2009-11-20 14:32:23.000000000 +0100
+++ otp_src_R13B04/erts/lib_src/common/erl_misc_utils.c 2010-03-29
15:53:28.000000000 +0200
@@ -373,8 +373,8 @@
return
0;
memcpy((void *)
topology,
(void *) cpuinfo-
>topology,
- cpuinfo->configured*sizeof(erts_cpu_topology_t));
- return cpuinfo->configured;
+ cpuinfo->topology_size*sizeof(erts_cpu_topology_t));
+ return cpuinfo->topology_size;
}
%%源码算是准备完毕了
%%开始编译前的环境准备
# export ERL_TOP=`pwd`
# eval `./otp_build env_cross $ERL_TOP/xcomp/erl-xcomp-
TileraMDE2.0-tilepro.conf`
# export TILERA_ROOT=/root/TileraMDE-2.1.2.112814/tilepro/ %%这个
最好用2.x版本的
# export PATH=$TILERA_ROOT/bin:$PATH
# tile-monitor –pci — uname -a %%验证板卡确实可用
Linux localhost 2.6.26.7-MDE-2.1.2.112814 #1 SMP Wed Sep 1
00:05:06 EDT 2010 tile GNU/Linux
%%开始交叉编译
# ./otp_build configure
# touch lib/crypto/SKIP && touch lib/ssl/SKIP && touch
lib/ssh/SKIP %%这几个模块用到了openssl, 编译不过去,忽略掉
# ./otp_build boot -a
# ./otp_build release -a /tmp/otp %%安装到/tmp/otp目录去
%%如果一切顺利,到这时候就编译完毕了。
%%我们开始收获成果。
# cd /tmp/otp
# ./Install `pwd`
# tile-monitor –pci –here — bin/erl %%没出错的话,就说明我们成功了。
%%当然我们可以把otp系统上载到板卡去,方便日后使用
# $TILERA_ROOT/bin/tile-monitor –pci –upload /tmp/otp /tmp/otp
–quit %% 放在板卡的/tmp/otp目录下
%%我们还可以定义个命令别名,方便我们执行命令
# tile_erl=”$TILERA_ROOT/bin/tile-monitor –pci –resume –tunnel
2023 23 –env HOME=/tmp –tiles – all ^0 – — /tmp/otp/bin/erl”
# $tile_erl +sct L10-18,1-9,19-55,57,58,61c1-55,57,58,61 +sbt db
-noshell +S 58 -s init stop
好吧到此为止,我们在目标机器上/tmp/otp目录下有个完整的erlang系统。
我们开个console连接到板载的linux系统去:
[root@client otp_src_R13B03]# /root/TileraMDE-
2.1.2.112814/tilepro/bin/tile-console
tile-console: Assuming ‘–pci’.
Connecting to /dev/ttyS0, speed 115200
Escape character: Ctrl-\ (ASCII 28, FS):
enabled
Type the escape character followed by C to get back,
or followed by ? to see other options.
—————————————————-
# uname -a
Linux localhost 2.6.26.7-MDE-2.1.2.112814 #1 SMP Wed Sep 1
00:05:06 EDT 2010 tile GNU/Linux
# cd /tmp/otp
%%我们跑个erlang程序<em>64核心并行</em>进行数学计算
%% 代码在这里下载 http://shootout.alioth.debian.org/u32/program.php?
test=spectralnorm&lang=hipe&id=2
#cat > spectralnorm.erl
% The Computer Language Benchmarks Game
% http://shootout.alioth.debian.org/
% contributed by Fredrik Svahn
-module(spectralnorm).
-export([main/1]).
-compile( [ inline, { inline_size, 1000 } ] ).
main([Arg]) ->
register(server,
self()),
N =
list_to_integer(Arg),
{U, V} = power_method(N, 10, erlang:make_tuple(N,
1), []),
io:format(“~.9f\n”, [ eigen(N, U, V, 0,
0) ]),
erlang:halt(0
).
% eigenvalue of V
eigen(0, _, _, VBV, VV) when VV /= 0 -> math:sqrt(VBV / VV);
eigen(I, U, V, VBV, VV) when I /= 0 ->
VI = element(I,
V),
eigen(I-1, U, V, VBV + element(I, U)*VI, VV
+ VI*VI).
% 2I steps of the power method
power_method(_, 0, A, B) -> {A, B};
power_method(N, I, A, _B) ->
V = atav(N,
A),
U = atav(N,
V),
power_method(N, I-1, U,
V).
% return element i,j of infinite matrix A
a(II,JJ) -> 1/((II+JJ-2)*(II-1+JJ)/2+II).
% multiply vector v by matrix A
av(N, V) -> pmap(N, fun(Begin, End) -> av(N, Begin, End, V) end).
av(N, Begin, End, V) -> server ! { self(), [ avloop(N, I, V, 0.0)
|| I <- lists:seq(Begin, End) ]}.
avloop(0, _, _, X) -> X;
avloop(J, I, V, X) -> avloop(J-1, I, V, X + a(I, J)*element(J, V) ).
% multiply vector v by matrix A transposed
atv(N, V) -> pmap(N, fun(Begin, End)-> atv(N, Begin, End, V) end).
atv(N, Begin, End, V) -> server ! { self(), [ atvloop(N, I, V, 0.0) || I <- lists:seq(Begin, End) ]}.
atvloop(0, _, _, X) -> X;
atvloop(J, I, V, X) -> atvloop(J-1, I, V, X + a(J, I)*element(J, V) ).
% multiply vector v by matrix A and then by matrix A transposed
atav(N, V) -> atv(N, av(N, V)).
%Helper function for multicore
pmap(N, F) ->
Chunks = chunks(0, erlang:system_info(logical_processors), N, []),
Pids = [spawn(fun()-> F(Begin, End) end) || {Begin, End} <- Chunks],
Res = [ receive {Pid, X} -> X end || Pid <- Pids],
list_to_tuple(lists:flatten(Res)).
chunks(I, P, N, A) when I == P-1 -> lists:reverse([{I*(N div P)+1, N} | A ]);
chunks(I, P, N, A) -> chunks(I+1, P, N, [{ I*(N div P)+1, (I+1)*(N div P)} | A ]).
CTRL+D
# bin/erlc spectralnorm.erl
# time bin/erl -noshell -run spectralnorm main 500 -s init stop
1.274224116
real 0m 16.90s
user 1m 16.07s
sys 0m 0.79s
# bin/erl +sct L10-18,1-9,19-55,57,58,61c1-55,57,58,61 +sbt db -noshell +S 58 -eval 'io:format("schedulers: ~p~n"[erlang:system_info(schedulers)])' -s init stop
schedulers: 58
Bingo! 我们顺利的跑了数学计算,同时绑定调度器到CPU core上去了。接下来就可以按照平常那样进行Erlang并发编程了。

|








有成功的应用案例么?
另外,没有看到CPU的微架构,CPU和内存之间的IO是怎样的?支持哪些其他IO总线?架构和带宽咋样?有没有协处理器?都有哪些协处理器?
软文软的太厉害了。
建议对比Cavium或者RMI对比讲解。
另外,有没有转发类的网络设备的成功案例?
64个核,使用4个内存控制器,CPU和内存控制器如何相连?什么总线?个人觉得对于转发类的网络设备来说,内存这块是极大的瓶颈,性能根本上不去。
个人觉得由于内存IO瓶颈,性能不见得会比两路的Nehalem性能高。
哪位大哥给讲一下erlang的现状和前景?
本文的行文水平类似国内的电视购物广告。
“各位看官,我们Tilera集成了4个DDR2内存控制器,请看好呦,不是DDR,而是DDR2,而且是4个!天啊!竟然集成了4个内存控制器。计算内核与内存之间的数据读写从此顺畅无比。从此顺畅无比!!!还在等什么,请拨打屏幕下方的订购热线。前100位打进来的朋友还将获得价值9.99元的首席签名照一张哦”
老印做的东西神是很神的,但是仍需要大范围的应用和市场检验方有出头之日;否则也难逃最后被收购整合的命运;不知南京那边的兄弟现在tilera上的应用做的如何了?上来8一下吧。
鹤军同学,知道在弯曲裸奔是需要实力的了吧。。。:-)
至少深信服的何老大也没有明确表态认为T就一定ok,仍持观望态度,东西好不好,市场说了算;Panabit想必也认为发挥x86平台的潜力是大有可为的吧。
如果有可能,想听听看对T的缺点的讨论。
2.6 支持Tilera是一个大突破。但T的应用场景确实要慎重。对系统软件和工程师是个大考验。。。没有强有力的研发队伍的公司,要慎重。否则有可能成为T的试验床。我个人觉得,我能把握的住T。但也还没有摸过。我其实反而觉得我可能把握不好Power7这样的系统。。。
我知道有人用Erlang实现了AV gateway的全套proxy,徐sir可以联系他们,跑起来看看那5,6个应用协议栈的裸奔速度.
菜鸟乱评一下:
前半部分绝对软文,而且正如上面说的,软的太厉害了。。。有点雷文了。。且看:
“单颗TileraPro64 CPU集成了64颗866Mhz的计算内核,4个DDR2内存控制器,计算内核与内存之间的数据读写从此顺畅无比。”
》》》》集成了4个控制器所以导致“从此顺畅无比”?起码给点有技术含量的干货啊。。
“采用当今最先进的两维iMesh构架,完全摒弃了传统多核CPU总线互联的结构,完全解决了传统多核CPU并行运算时常有的效率瓶颈”
》》》》两个“完全”,绝对够分量!世界大同了,所有难题“完全”被解决!
尤其还集成了2个万兆网络控制器,摒弃了传统构架中的PCI-E总线的数据传输瓶颈
》》》》摒弃了瓶颈,语法错误,起码也是消除了瓶颈。而且摒弃了pcie,那么这两个万兆与cpu核心之间具体怎么连接的,起码给点干货吧。。
每颗物理计算核都配有交换单元与多条总线连接,是内核之间的连接不再有瓶颈,数据交换更加通畅和实时。
》》》》上面不是说摒弃了“总线”么,这里怎么又出现总线了,而且还不再有瓶颈。。。
总之我感觉前半部分真的很雷,希望楼主能够给点干货出来,详细分析Tilera的众核CPU!!
别无他意,也是学习欲望强烈却没看到干货啊,楼主见谅!
不知道楼上各位看过t的资料没有,曾经有幸看过一些SDK中的文档,且不论这个文章是否枪文,我觉得就T的架构和思想来说其实是非常先进的,T的开发者已经充分意识到对于对于多核平台来说,软件才是软肋,所以T的公司在软件方面下了非常大的力气,他的的平台就是基于linux的,他的的开发平台尽量的向标准的linux系统靠拢,没有像rmi的rmos或者cavium的SE那样的单独的库,这样就非常有利于将现有的基于linux的软件架构移植到多核平台上。而且他的众多核系统在低功耗方面有非常大的优势,64个核,随便拿几个核出来就可以解决很多以往多核系统中碰到的问题,经典的用处就是他可以直接拿几个核出来管理一片或者几片内存,你根本不用担心内存的同步问题。所以我觉得楼上各位不要一棒子打死,毕竟cavium这样的大公司也是从这样的小公司过来的,我个人比较看好T公司产品的前途,当然被不被收购另当别论。顺便说下,鄙人不是什么枪手,只是在做过几年多核的研究而已,从最早的C-5,ixp1200/2400,rmi的532,一直到oct5650,都用过,个人觉得对多核还是有比较深刻的认识。对于T的产品,我们拭目以待,如果他们公司上市的话,能买,我一定会去买他们的股票
To 11楼:
是不是误会了,打死的不是T,而是这篇软文里的一些句子,仅此而已。不是说T不行,东西好,没人了解不行啊,让人了解就得给干货,我对cpu不懂,所以希望牛人给科普一下,用通俗的话把技术讲清楚,但是看软文的话,说实话,很浪费时间。
嗨,我们公司已经为此衍生出一款产品了。。。正在评测中。。。。。
用过Tilera,同意11楼的看法。软件部分(sdk,tilera叫MDE, Multicore Development Environment)做得相当好,比intel的scc舒服。大多数普通应用可以直接交叉编译过去,源代码修改一点或者根本不修改。
sdk里文档非常细致,不过他的sdk和里边的文档都签了NDA才给,可能这也是没什么人出来讲细节的原因吧。
直到目前,在弯曲里裸奔,没有人能够随随便便成功。除了技术实力,还需要求是的态度。
如果为了广告效应,我觉得这里混的多数都是“厂商”,很少有客户,就别费那力了。
还有啊,楼主文章里引的余锋用的那个erlang的测试程序,其实跑起来性能是非常差的。那个程序在计算矩阵的谱范数,而我们能拿到的Tilera机器是不带FPU的(好像是不允许卖给中国),算这种东西性能之差可想而知。
TO 11、14楼,两个回复依然很软,还是没有听出太多技术的东东。
多个CPU同时访问一块内存的时候,不需要考虑同步问题,怎么做到的?跟spin_lock有没有本质区别?这个是erlang的优势还是t家CPU的优势?
尽量像linux标准靠?这个到底做了哪些事情?Cavium和RMI很多的SDK都是用来直接操作硬件的API,因为他提供了很多协处理器,例如保序的、加解密的。如果T家的没有这些,那似乎也只能说明它并没有这些协处理器,并不很偏向于专业的NP处理器?我胡说的,不知道是不是这样,但有点可以肯定,我们没有歧视T家处理器,实际上这么关注,也是希望尽早的了解它,对于工程师,只有我们所说的那些才能真正吸引我们,软文只能吸引不干活只讲话的老板。
TO 17楼,怂恿你们那个不干活只讲话的老板要台Tilera的样机不就什么都清楚了。它那么一大堆文档,几句话实在概括不过来。
不管是多少核,多少性能,多少功耗,我觉得大家总是会忽略一些方面的根本物理局限。一颗芯片的功耗=静态功耗+动态功耗,静态功耗基本上就是取决于你使用的制程(制程越先进,单位面积静态功耗越大)、die size;动态功耗基本上就是取决于 die size、主频和核电压。所以在一个给定的制程上面,基本上 die size 决定功耗的大小,大家再想一想,在一个给定的 die size 上,能多少个晶体管这个是玩不了假的?然后再看看对于给定的应用,你到底做了特性,譬如superscaler,out-of-order,multithreading,FPU 有,各种提高性能的特性都是要占面积了,最后,我要说一句,there is no magic!!!
感觉T的多核似乎更适合做存储或者云计算? 在通信行业的能力还有待验证,期待更详细的分析资料!
同意19楼的观点,除非有技术上的绝对领先,否则就是取舍问题。
这个东东我实战过,I/O能力高于x86,毕竟集成了MAC,并且不通过中断方式传送报文到操作系统(与NP类似),在数据平面(转发)应该可用。但复杂计算的场景下,据我的评测一颗866MHz的TileraPro64大概相当于2.13G Xeon L5408的1/3的能力
TO:首席
敢于裸奔的信心不是自己的技术实力,而是Tilera这条粗腿的实力。
对2011年,RMI的情况我不知道,Cavium是肯定歇菜了,各位不要对Cavium能在今年出更高性能的的芯片抱幻想了。
我的另一篇文章是“2011年Tilera独领风骚”。
TO 18楼,我们领导是既说话又干活的领导,呵呵。不过我会试着“怂恿”一下地。
Tilera的产品敢于给任何人做评测。
Erlang也搞过一段时间,在语言层面的并发概念不错,状态机实现的也很有特色。不过用它真正做产品还是不太现实,底层的东西它还是要依赖C语言,否则Ericsson也不会放它出来了。
大家可以去查查SGI的新闻,SGI采用Tilera的产品做整数计算加速
To:xStorm
国内早就有人用Erlang开发出拥有电信管理的系统了,而且卖的很好,过的很滋润。
To xStorm:
不考虑I/O只论计算能力,比如七层重组和解码,Intel如果说是二,那没人敢说自己是个大,这个我们看法一致。不过你说Erlang做产品不太现实,这个我只能说实践已经证明你错了,这个咱俩不一致。
To 徐sir:
提醒下哦,宣讲会的时候不要判cavium死刑,不然V的观音姐姐会找人肖你,哈哈,报首席的名字或许可能免打。
正经说,你给一个和RMI/Cavium的纯技术的Comp Table更有说服力,这地和我一样认理不认人的主比较多。腿比T粗的厂商多了,在这被练过的不在少数。
很是热闹呀;
tilera的CPU和MDE做得确实不错;基于ZOL的开发环境和NETIO库,做包处理方面的应用很方便自己动手做过测试,其包转发能力非常强,基于ZOL单个核做三层转发可以做到120W+;
to 17楼,帮你解释下那个内存问题,在T的架构里面其实多核并发访问内存并不是不存在同步,只要是并发访问就有同步,只不过在T的软件体系里面可以专门分出一个或者多个核来管理内存,同步问题直接交给管理内存的核来做了,使用内存的核可以不用考虑这个问题。他可以用核实现cavium里面的类似于内存pool一样的功能,而且可以不受内存对其的限制,要灵活的多。至于那个linux的问题14楼已经说了。技术细节太复杂,一句半句说不清楚。欢迎各位和我一起讨论,顺便说下,我目前做的是cavium,和公司建议过可以调研下T的处理器,但是出于楼上某些人说的原因被拒了。但是我依然很看好T的处理器,Cavium的处理器已经到底了,除非进行真正架构上的改动,不过貌似从他的XLP上看的话,觉得可能性不大,XLP更像是一个仓促推出来的为了适应市场的东西。
晕了,搞错了rmi的是XLP,oct的是6XXX系列的,特此更正!!!!!!!!!
Heeeee. 一失足成千古恨呀。。。犯下技术大错。。。很难解释你是typo了还是不懂:--)
搞混了搞混了!!!!关键是前阵子关注了下XLP
我觉得T公司的人报答我一下,我和几个朋友都推荐过他们的平台!唉。。。可惜一直没有机会真正搞点东西出来
国内一些网安公司之所以对Tilera犹豫不决,主要是他们以前一直代码都是围绕Kernel在做优化,担心迁移的难度。用过Cavium的人应该知道从Intel迁到Cavium的难度。国外的公司基本已经将代码从kernel迁到用户层了。迁移的成本大大减小。国内公司的观念落后了一大截。
对于网安厂商,进行选型的时候要更加冷静一些,不是一定是 Embedded Multicore 就是时髦的东西,我认为从一个产品经理和一个产品规划架构师的角度来考虑,你要看看你的软硬件规格以及你相应准备作出来的研发投入,还有你的团队背景如何,更重要要清楚自己的核心价值在哪里,不然最后即使你用了 Cavium, Netlogic or Tilera,你依然做不出自己的特色出来。。。其实对于网络安全厂商来说,可能更好的更快的架构应该是 X86 + Offload 而不是选择全平台彻底移植
安全产品硬件架构从X86到多核的过度,这是市场催生这一变化产生的。我们现在就在多核上做产品迁移,大家支持我吧。
我司的是在用户态的,可前段时间兄弟部门的测试结论:不太适合做网络设备,更适合做图像处理。
去徐次席的网站上溜了一圈。网站上的产品介绍与本文行文水平类似。非常爱用形容词。
看东西还是比较有料的,但是这marketing做的实在是太。。。
我觉得瓶颈在内存上,64bit@800MHz*4。总共内存带宽才200Gb,打完折估计150G算乐观了。要喂64core@866Mhz数据和指令。除非cache命中率很高,不然IPC绝对很低。想想intel quad core也要上DDR3的原因。我想这也是22楼测试出来复杂处理性能低的原因之一。
复杂的包处理,loopback一下,绝对歇。呵呵。
谁知道他内部interconnect的bandwidth。不知道用pipeline给不给力
我刚拿到SDK,但是没板子。
总觉得泛腾科技的人在忽悠我……….
to 40楼的,你忽略了他的mash网络,通过mash网络它可以直接core之间进行通讯而不通过内存,还有通过这个网络还可以将多个core组成一个cache。T的多核并不是传统意义上的总线式的多核。
to 39楼,感觉你们测试的兄弟有点没下功夫啊
core和core之间进行通讯,不经过内存,是说数据和指令都在CPU里,不需要访问内存?数据包不需要copy到内存?
个人觉得mash网络无非就是一个多个核共享一个内存控制器用的东东,最后无论是对数据的访问,还是对指令的访问,都会到内存控制器那排队(实际是等待抢占IO总线)。
intel就是因为这个瓶颈,才搞的超线程,就是为了在等待IO的时候切换到另一个线程进行运算。
多个core使用一个cache这个intel和amd也是有的,这个并不是什么可以证明独特的东东。
谁能给解释一下:
在T的架构里面其实多核并发访问内存并不是不存在同步,只要是并发访问就有同步,只不过在T的软件体系里面可以专门分出一个或者多个核来管理内存,同步问题直接交给管理内存的核来做了,使用内存的核可以不用考虑这个问题。
by boblee
我不是很懂,没深入的接触过这块,这个可以做到么?
我一直认为,一个技术牛人是绝对可以将技术给人讲明白的,前提是他真的理解了,如果讲不出来,就证明他至少没有理解到骨子里。
To 41楼
基于我们产品的网安产品早就开卖了。
是否忽悠你,还是请你仔细看看文档吧。
很多人还停留在总线式的多核结构里。
在Tilera里根本没有总线的感念,
这是个矩阵的高速交换机。
也是将来多核技术的发展方向。
Cavium所以歇菜,也就是死在总线构架上。
是否可以理解为每个CORE有一路连接到SWITCH,switch在把所有core做full mesh连接,如果是这样的话,在N:1的CORE之间通讯的时候,如何处理拥塞?还是这个架构,不允许出现N:1 CORE通讯的情况?
37楼说得非常好
能有高手说说 RMI、Cavium、Tilera、Netlogic、Intel等多核芯片技术否?
现在比较多网络厂商利用这些芯片技术来处理应用层的识别及控制,特别在安全应用方面。
这个里面说得多的都是以做安全产品的思路来做分析了,安全产品不等同于网络产品。
说Cavium已死,用Tilera做个台式交换机的主控cpu给我看一看,各有各的特色,把自己做好了再吹吧,
Tilera 64核就是一个忽悠,一个大忽悠,2008年就开始了,拿到可一张测试卡,实际能够用的玩意到2011年年底才能够发布,中间的都是残废,害死人。
想把T做好也不是那么容易的,毕竟是小众,找个熟悉来讨论都不容易。现在的pro 64用来做转发性能上还行,但interface太少了。现在就对gx系列还是抱很大信心的,就是别再拖了
唉。。。不管是mesh,ring,xbar还是bus,都是一种interconnect topology。各有所长。
所以没有必要说什么死在总线架构上面这种话,把带宽拿出来晒一晒。就行了。搞R&D的吗,严谨点。
同意54楼的。
Processor
Each core is a complete computer
3-way VLIW CPU
Designed for low power – 200mW per core
SIMD instructions: 32, 16, and 8-bit ops
Instructions for video (e.g., SAD) and networking
Protection and interrupts
Single core performance roughly the same as a
modern MIPS or ARM core
Memory
L1 cache: 8KB I, 8KB D, 1 cycle latency
L2 cache: 64KB unified, 7 cycle latency
32-bit virtual address space per process
64-bit physical address space
Instruction and data TLBs
Cache integrated 2D DMA engine
Switch in each tile
Runs SMP Linux
Runs off-the-shelf open-source C/C++ programs
Distributed resources
2D Mesh peer-to-peer tile networks
5 independent networks
Each with 32-bit channels, full duplex
Tile-to-memory, tile-to-tile, and tile-to-IO data transfer
Packet switched, wormhole routed, point-to-point
Near-neighbour flow control, dimension-ordered routing
Performance and energy efficiency
ASIC-like one cycle hop latency
2 Tbps bisection bandwidth
32 Tbps interconnect bandwidth
Low power
6 independent networks
One static, four dynamic
IDN – System and I/O
MDN – Cache misses, DMA, other memory
TDN, VDN – Tile to tile memory access and coherence
UDN, STN – User-level streaming and scalar transfer
2 Tbps bisection bandwidth
5个channel,每channel 400G。单向200G。
32bit?频率6.25G?
总共32T又是怎么算出来的?对于mesh,把带宽加起来算个32T有意义吗?再加上外面那撑死200G的mem ctlr?
Near neighbour flow control。
刚去查了下资料,感觉这玩意做pipeline还不错。还是太复杂了。做硬件的头痛完了就该做软件的头痛了
大家就别为难他了,他是来错了地方了。我觉得我们得不到更多的信息了。
To: Will Chie
如果你有兴趣可以像Kevin那样去查查资料。
能放出来的资料都可以从g/b 上找到。
想知道不能放出来的货色,就来签NDA。
别老想别人喂你。
1: 弯曲不是个大广告的地方,就是技术交流的地方。
2: 我不觉得你是不是想“喂”的问题,而是有没有能力“喂”的问题。
3: 就这一个“喂”字就反映了RP。
不在继续和RP有问题的人继续交流。
1: 我的文章是不是广告不是阁下就能裁定的。
首席之所以同意将我的文章发出来,已经有了判断。
2:关于新产品新技术的技术细节如何发布,这个行业中的是有规矩的。
3:不愿意自己稍微做些调查研究,只知道一味的瞎子摸象般的瞎问。这种所谓技术人员的素质可想而知。
4:交流与否是你的权利,我尊重你的选择。
和FAE交流的时候的时候首先要丢个开门的问题试试水,水浅就钓小鱼,水深就钓大鱼,这和搞面试的时候一样,不然彼此会弄得比较尴尬。
俺不是搞R&D的,曾经是,呵呵,有些年不做了,所以长期在弯曲潜水,不敢冒泡,今天看到这个帖子,开始眼睛为之一亮,因为偶们公司主要就是基于Tilera平台开发应用解决方案的,也是Tilera在国内最早的代理商,习惯性会对Tilera选择性敏感:),不过看完徐兄的文章,禁不住也小汗了一把,徐兄的确是发错地方了,这种软文应该发在IT168之类的网站,弯曲的确不合适。
关于Tilera芯片,偶不是专家,这里简单说说偶对Tilera的一些肤浅认识:
1. Tilera在处理器上的最大革新应该是Mesh二维总线结构,很好地解决了处理器核数增加以后的总线瓶颈问题,无法想象,如果64个核都挂在一个总线或者一个令牌环下面,总线效率会怎样
2. Tilera的另一个优势是低功耗,64核25w以内的典型功耗,如果按同等处理性能相比(同意22楼的说法,Tilera单核的性能大约相当于Intel 2.13G Xeon L5408的1/3,当然,这是大家都跑整型运算的前提下),Tilera的功耗还是非常有优势,这点应该是Google最喜欢的
3. Tilera片内集成了网络接口,目前64核版本提供2个GE、2个10G XAUI和2个PCIE 4lane接口,加上PHY就可以直接出GE和10GE
4. Tilera没有浮点单元,毕竟它不是定位在通用处理器,目前它的主要应用领域还是网络(L4-L7层的处理)和多媒体(音视频编解码、视频分析等),其次在云计算领域也越来越体现出应用的优势
5. Tilera是分布式内存,设计不好,互斥问题就会导致内存效率大打折扣,这也是为什么经常碰到有的客户用Tilera用得很好,有得却直摇头,认为还不如CAVIUM的****芯片,这里面可能有芯片本身的差异(客观讲,每个芯片都是自己最适合的应用领域),也有客户的使用问题。另外Tilera目前还只是DDR2,在内存访问带宽上不能算很Power,还好在今年即将发布的下一代Gx芯片上已经支持DDR3了
暂时就这些,想到什么写什么,都不是什么有技术含量的话,呵呵,有兄弟想更进一步了解技术细节,可以给我发mail,我转给我们公司的技术专家
meganovo总算出来了,不枉我喊了两声,呵呵,欢迎参与讨论。
正如首席所说,弯曲不是bbs。有啥牛逼见解就直接在评论中拿出来,如果还觉得不过瘾就再单开个主题,专么写篇文章。
搞到后来都走e-mail去了,那还看个啥评论阿。
to 老徐:
弯曲上搞技术的人居多,大家都想看点有干货的东西。没人想故意刁难谁,如果你不是打广告而是抱着交流的态度来到这里,就耐心点。对大家的问题,在不涉及到机密时,能答就答,不能答就直言。当然能搬个tilera的牛人来就更好了。既然敢发帖子就应该有接受大家提问并解答的义务。不用说的 喂 这么难听。难道一个朋友跟你说了个有趣的东西,你还非要回家查了资料才能再问他问题吗?
9494,实在看不下去了,不懂吧,还出来装懂,说的话没句贴边的不说还不严谨,出来挺他的呢,也是一样,居然能说出神品一样的东东,不像搞技术的,像sales讲技术。
这“不屈不挠”的精神,让我说点啥好呢?
再加上上面有位兄弟说了,被tilera忽悠了好几年,被实验了,再看这作者这RP,我是不敢和他们公司打交道的,我怕我遇到问题打电话给他们公司被告知:“SDK有bug你不会自己解么?”;甚至:“我们的SDK是不可能会有bug的,肯定是你们使用的问题”。
另外我们公司的确有人测过了,得出的结论的确就是:不信,搞图像处理还行(应该是说适合大规模运算,不适合做通信类产品)。
刚看了一下meganovo果然是搞多媒体的,看来我同事还真没搞错。
Tilera的特点就是二维Mesh网络,因此可以很方便地连接很多的核心,缺点就是这些核心的同步以及访存比较成问题,不如xbar或者ring那样简单,加大开发难度……
刚看一个帖子:
A:就是维京人,现在的俄罗斯人就是他们的后代,我说的是现实。
B:维京人是北欧那边的吧,确切的说是 丹麦 挪威 瑞典 那一代的。怎么能扯到俄罗斯呢。
A:自己去查历史。
这种人还真多。
T在CPU多核架构上是最理想的,H公司就在与之合作,联合开发基于H公司需求的通用CPU……
H公司这么多人逛弯曲呢,有知道的不?“基于H公司需求”的定制,是不是就是解决内存IO瓶颈呢?
我都怀疑是不是首席在这里钓鱼呢,故意放个有争议的文章出来吸引人气。似乎很有成效,回帖空前的热闹。
不过这样的文章只能一不能再,严重影响湾区评论的品质。
大家未尝不可以一起钓一起吃,众乐乐,独乐乐,熟了?
不是。我不至于这么猥琐。关于Tilera的讨论太少。我也没有时间写。是希望大家能多讨论。
我不认为弯曲评论会和能够整成一个nurd的园地,或者什么通信研发精英的集散地。
弯曲评论的精华是评论,而非文章本身。
当然,文章确实不能太软。
说心里话,我写的文章后面的众位读者的评论的水平远远大于我个人的水平。我的文章其实就是一个抛砖引玉。。。。。。
高手都隐藏于民间。弯曲评论的目的就是通过一种精神使得民间高手能入世。。。
咳。。。。过了两天又是这么多帖子,建议各位网上可以搜下T公司产品的一些资料,我说的都是我通过他公司资料的个人理解,我前面说过,我没有实际做过T的开发,XLR或者oct我可以扯很多。其实T公司的多核,从早期的版本到后面的pro版本,以及未来的Gx版本,改动还是非常大的,早期版本是不太利于网络应用,但是到后面的版本,T的公司,汲取了不同产品的优点,并且在不断的改正自己的缺点,他的前途我依然看好。
同意楼上的说法,客观讲,不能说Tilera不适合做网络,只是目前的版本没有类似C家的针对网络应用的一些“硬核”,如packet parsing & classification,load balance,crypto,compress & decompress,所有的网络处理全靠CPU软处理,不过这点在Gx版本中都已经改进了,Gx有了专门的网络处理Engine。
Gx的确是一款值得期待的下一代众核处理器,产品系列更丰富,从16核到100核,主频提到了1.5Ghz,位宽变为64位,内存支持DDR3,增加了许多针对网络处理和多媒体处理的指令,以视频编解码为例,单核的处理能力将能达到现在的3倍,以此测算,一颗64核处理器可完成至少30路的1080p@30fps高清视频的H.264解码。
77楼所言甚是, 设备厂商真正关心的正是这些!
感谢大家的捧场。这两天在北京走访客户,为客户做技术讲座,没能及时回复大家。
1)正如首席点出的弯曲的精华就是回帖中的内容。
如果提问前能花点时间看看已有的回帖就会大大提高效率。如果能花些时间去查查资料,效果能更好。这个行业的规矩就是要看细节签NDA。这在回帖中的很多朋友都已经说了。把执着的劲头花在研究上比花在回帖上更能提高自己的能力。我想这也是首席所希望的主贴是抛砖引玉的功能。
2)说Tilera产品不适合做网络要分清楚是做交换机还是网络安全产品。做交换机,Tilera的确不行,因为Tilera是个全功能CPU,而不是只做L1-2 的网络处理器。我在回帖中一直说的是网安产品,而且点出可以搜索出目前已经采用Tilera做网安产品的公司。偏偏有人不仔细看,又不喜欢去动手查资料。实在是无语。好在弯曲上相Kavin这样愿意去查查资料的人还是多数。
再次声明:评测才是硬道理。老韩已经联系我了,争取早日到老韩的实验室去评测。
1. “目前没有类似Cavium家的针对网络应用的一些硬核“,个人觉得,T家处理器设计之初根本没有为网络设备考虑,只是后来发现网络设备是一个市场,就往这方面转,前几年可以看出,T家处理器主要用于多媒体,而也有公司提到”被试验了“,直至今天都没有真正针对网络设备的处理器,也就是说:还是得等。而且等出来的结果不可预料。
2.之前T家处理器以能耗比高作为一个卖点(实际情况我并不知晓),但看他们的GX:
40 – 80 Gbps Snort® processing
40 – 80 Gbps nProbe
H.264 HD video encode: dozens of streams of 1080p (baseline profile)
64+ channels of OFDM baseband receiver processing (wireless)
这样的处理器能耗比还能高么?
3.现在网络设备的性能瓶颈在哪里?是在核数么?100个核,和16个核用一样的IO带宽,并且单核能力偏低,架构如何设计才能提高网络设备的性能?
我并不看好改来的处理器,架构设计之初就不是为网络设备做的,所以才会出现这些问题。后来只能打补丁,增加了协处理器就是NP了?没错,可以成为NP,但和架构为网络设备订制的NP比呢?
尤其是基于T家处理器的软件架构这块,国内也就华为有钱往上砸着试试,大家当初吃intel的NP的亏还不够么?还没被intel的微码折磨够么?
说起intel来非常搞笑,当初我们的人被intel的微码折磨的够呛,总算被折磨出来了(当时不只是技术问题,intel本身,板卡本身都有很多问题),后来intel的工程师(售前?what ever)过来给我们讲,以后不会再提供微码的方式了,他们和北大(还是清华?不记得了)一个实验室合作,把原来以微码提供的功能已API的方式封装提供,当场的人全部被雷到。
完全被试验了,公司在这块损失惨重(比起华为算小公司)。惨痛的教训啊。
另外还有一个现实问题,相信真正搞过多核的人都清楚,对网络设备而言,相同软件架构下,当IO成为瓶颈时,核数的增加会使性能不升反降的,而且核数越多,性能下降的越厉害。举个例子,一个两路的x86 NUMA架构,两个双核处理器可能比两个四核处理器性能高很多。
说法可能不严谨,但相信做过的人都懂得的。
真是非常感动,我是TILERA的peter, 感谢大家回帖,也非常希望和大家交流,向大家学习,我的邮件是pliang@tilera.com。 大家可以发邮件给我,我可以提供相应文档,软件,评估系统,面对面交流,TILERA不是完美的,但是我们非常想进步,广大用户的反馈,指导和需求是我们进步的直接动力。
我们最近还在招人,各位高手,如果有兴趣加入,一起面对客户,一起来成功,也非常欢迎。
首席,我三月去湾区出差,热烈的邀请你到我公司参观,交流,如果方便,我可以邀请Anant和我公司的技术人员在和你交流交流,可以把大家的疑问来切磋切磋,也好让首席给大家一些应用建议。 当然我也有私心,可以借此机会首席见面。
还有,我所在的就是网络安全设备公司。做交换机的用多核?没做过,不知道。
非常有趣的是,在去年某人写的博客已经提出相同的质疑:
http://blog.ednchina.com/coyoo/201587/message.aspx
摘要如下:
Mesh架构解决了多个内核之间互连互通的问题,但是处理器毕竟要同外部进行交换数据。从上图可以看到,一颗Tile64处理器上有4个DDR2内存控制器,算每个控制器支持双通道DDRII 800,那么理论上内存带宽为51.2GB/s。(文章中这么说其内置的内存控制器可以在芯片内实现高达200GB的内存带宽--芯片内这个词值得推敲)
要知道,现在的Intel Bensley平台(双路双核共四核,或者双路四核共八核)采用4通道FBD内存,内存带宽为25.6GB/s,但是这样的系统并不平衡,可想而知,Tile64处理器要充分发挥效能,面临的问题也很大。
所以同意文章中的这个观点“可见,未来芯片的基本限制将不再是内核性能,而是I/O性能。 ”但是不是未来,很久以来一直是I/O性能。
可见,真正懂得的人,都是应该非常明白这个道理的,无需我多说。
至于绿盟采用这个的问题,我一直都不觉得绿盟的优势是架构。
1)Will Chie 终于用搜索了,可喜。
2)Will Chie 提到的网络设备到底是指网络交换机还是网络安全设备?争论了半天不把目标前提确定下来,牛唇不对马嘴。从我看Will Chie 提到的内容来看Will Chie 提到网络设备应该是指网络安全设备。但愿我没有理解错。
3)本人曾亲耳听Kernel团队中的负责加密算法部分的Herbert Xu说,当初就有制作网卡芯片的公司曾游说他,希望他在相应的模块中添加支持网卡硬件加密的代码,但是Herbert分析说当前CPU的运算能力远远没有被充分利用,利用已有的计算能力完全可以替代硬件加密的性能。同样Sun的ZFS也是用软件RAID功能来替代硬件RAID。所以Tilera的设计思路思路也是利用足够多的核的优势来取代硬件加速,这在性能上的损失微乎其微,但带来的好处是软件代码维护成本的大大降低,和开发的灵活性。今天从客户反馈回的信息是用C硬件开发一款网安产品的周期是一年,而我们自己客户的反馈是用Tilera开发产品的周期是2个月。用C硬件的朋友应该是用体会的。用过NP的客户就更有切肤之感了吧。我们刚刚招降了一家用过NP的客户,用户体验过我们产品后的高下立刻清楚了。
4)正如Will Chie 所说不能相信Intel这样的大公司,对于Tilera来说,C也是个大公司。Will Chief倒是力挺的吗?
5)我们Tilera的产品在2011年就是来砸Intel和C的场子的。通过2010的摸索,我们现在又足够的信心。
6)我们客户在我们平台上开发的产品64字节的处理能力是9.3Gbps,数据转发延时是38us.
7) Will Chie 要挺C,是您的权利。大家到招标会上去比比就行了。奉劝Will Chie 等到了2011年春季不要惊讶,忽如一夜春风来,满城尽是Tilera。
对于Will Chie 同胞的搜索能力十分钦佩。
挖出一段符合自己胃口的内容就到处招摇。
http://blog.ednchina.com/coyoo/201585/message.aspx
这是Will Chie引用内容的同一作者的上一篇blog.其实这位博主也是应用媒体宣传稿上的内容。
“ 值得一提的是,Tilera的魅力不仅仅是能够装入更多的内核。该芯片上有一对万兆以太网端口以实现高速网络接入功能,还包括片上I/O和外设控制器。其内置的内存控制器可以在芯片内实现高达200GB的内存带宽。这也是为什么TILE64特别受到Top Layer青睐的原因所在,Top Layer是一家专业的网络安全和入侵检测设备制作商。据该公司首席策略官(Chief Strategy Officer)Mike Paquette表示,虽然Top Layer拥有自己的处理器,但现在已计划转向Tilera的芯片。“我们的软件是针对多核进行设计的,在Tilera中能够在内核与软件进程之间实现几乎1对1对应的功能。Tilera的网络功能要比X86处理器强得多。我们预计其性能会超出采用其他任何一种芯片的方案”。
作为一名技术研发人员这种以偏盖全的研究方式是RP问题了。所以我用喂字不是我的RP问题。
Will Chie,你露底了,haha
改天再去拜会。
引用首席原话:
2.6 支持Tilera是一个大突破。但T的应用场景确实要慎重。对系统软件和工程师是个大考验。。。没有强有力的研发队伍的公司,要慎重。否则有可能成为T的试验床。我个人觉得,我能把握的住T。但也还没有摸过。我其实反而觉得我可能把握不好Power7这样的系统。。。
国内除了华为谁有首席级别的人才?
我一直也质疑的就是如何用如此的IO能力解决众核的问题,其实也就是首席所说的对软件架构的把握问题,我们的软件架构和Panabit的如出一辙,国内有其他更好的解决方案么?
至于销售的言辞,呵呵,大家都买过东西,都清楚:”突破“、”超越“、”划时代“、”终结者“……
至于说到挺,前面我也很少讲Cavium和RMI家的技术(又没人给我好处),其实现在我更期待的是NUMA架构的Nehalem的NUMA架构(QPI互联)+PCIE3+各种专业芯片。
首席在另外一篇文章的评论中讲到一个轮回问题,就是单核->多核->单核……,这个在IT业界还是很常见的,单核到多核是第一次发生,还没有经历多核到单核的事情发生,但回头看一下硬盘的数据线:串行->并行->串行……,就是当遇到了干扰瓶颈时,通过单线的传输能力解决,遇到单线传输能力瓶颈时,通过加强抗干扰用多线解决问题,核数也是一样的,现在是单核频率上不去才用多核解决问题,而多核的问题会是核数上不去了么?其实不是,其实问题就在于多核架构问题,因为这个问题才会回到单核去。T家的处理器可能很适合多媒体这种情况,我对多媒体业务并不了解,但最起码它一开始就是做的多媒体市场而且看起来还不错,但是不是能解决其他问题呢?
T家处理器有个自相矛盾的问题,就是自家下代可作为网络处理器的GX系列引入了各种协处理器,而自家的销售人员/市场人员却出来说用处理器解决协处理器该解决的问题?
我提醒一下做通信类产品的架构师们,不说别的,保序问题,没错可以软件解决保序问题,但仔细想一下你们的保序方案在多核下和在众核下的区别。
Mr Xu,很不巧我恰好在你去北京的时候到上海了,再找机会碰。我是一直对T的东西比较感兴趣,有机会当然想看看。
不过我喜欢你这句话:“我们Tilera的产品在2011年就是来砸Intel和C的场子的。通过2010的摸索,我们现在又足够的信心。”
酒后之言,勿怪。
何必吵来吵去呢,尤其是网络安全行业,我们做一些很粗浅的分析:
1.中国的安全行业,不过是总共10-20万多台设备的容量,包含了所有的防火墙、VPN、IDS/IPS、UTM、隔离网闸、行为管理、甚至防水墙(;-)),从桌面型到最高端的(经验数据,从与平台厂商沟通,IDC排名,中国领袖厂商的销售额和ASP等判断);
2.中国的网络安全设备厂商(除了少数从通信设备厂商挖人过来)基本上都是软件公司,不是嵌入式系统公司,基本上连Intel IXP425,Cavium CN50XX,RMI XLS208,单核 PowerPC,Marvell Kirkwood这种低端的,100%完全架构在 Linux 之上的系统都难搞定(对于上面多核处理器厂商,高端系统也是可以架构在Linux之上的,不是只能架构在Cavium Simple Executive、Netlogic NetOS/RMIOS, Freescale executive 甚至 Windriver executive),主要是因为大小端、体系结构移植、嵌入式文件系统的架构等;
3.中国的安全设备厂商,大概是最低端使用atom的机器,整机平台成本在人民币1500-2500之间,中档可能是用酷睿这样的,高端用Xeon,Tilera对比的是哪个市场空间(应该是瞄准XEON而不是ATOM吧)?根据最低端、中端、高端9:3:1(没有查找具体的统计数据,根据一般的行业经验粗略估计),高端安全设备在中国市场总的量是7-15K台,这个量,对于板卡厂商是一个不错的生意,估计基于C, N, T的最高端设备,报价一万美金左右,最后成交3-5万之间,取决于客户的量,最后这个是几亿人民币的一个市场,对于芯片公司,7-15ku的量,如果成了变成了某个CPU公司聚焦的领域,只能说杯具了;
4.Intel现在性能越来越好,功耗也开始被Intel重视,安全厂商何必跟风要上自己根本不熟悉的嵌入式系统呢?你们的核心价值是安全软件、安全评估、攻防积累、安全架构等;如果性能实在上不去(据说Intel平台现在转发性能很好),需要做VPN加速的,你可以使用VPN加速器,需要做DPI的,DPI加速器市场上也有几家,甚至您还可以使用Intel+嵌入式多核,把少部分业务offload到嵌入式多核上;
5.其实DSP并不是小市场,看起来dsp市场竞争反而比CPU市场好,而且DSP上的软件也没有CPU上的复杂,也不需要那么大的ecosystem来支撑,这个可能是一个方向,wireless和multimedia都是巨大的市场;
6.每个公司要认清楚自己的优势和劣势,要有自己的方向,最强大的人不停的挑战自己,每一家公司go-to-market的策略都不一样,不能照搬,譬如C是安全起家,当然以安全作为切入,而N(应该说R)第一把就是做嵌入式多核CPU,所以他们进入的策略是直接杀进网络设备领域,那我们想想T到底应该如何杀入市场呢?那块才是自己真正的优势呢?我们做产品,不管是芯片厂商、平台厂商还是设备厂商,我们总要仔细思考几个问题:1、我的客户的pain是什么?2、我如何解决客户painful的事情?3、我的核心价值和differentiation是什么?
前面讨论中一些具体的技术问题,不一一讨论了。
最后产品选型和定义,不是一个简单的性能、功耗的事情,在设备厂商角度从产品经理的角度、从架构师的角度、从开发者角度和从采购角度看的问题都不一样。
祝愿Tilera早日找到自己的杀手应用领域,杀开一条血路,市场需要竞争,竞争又利于创新,竞争最后可以给客户和消费者带来最佳的方案!
btw,哪位指教下上海漕河泾的思科大楼里有没有做安全的人?具体是哪个部门?多谢
@99楼 Will Chie
至于说到挺,前面我也很少讲Cavium和RMI家的技术(又没人给我好处),其实现在我更期待的是NUMA架构的Nehalem的NUMA架构(QPI互联)+PCIE3+各种专业芯片。
我赞同 Will Chie 关于 Intel+Offload 架构作为安全产品的方向
老韩专门盯安全应用的啊?
上面可能没说清楚,就是保序方案,因为保序方案同时带来的问题一个flow或者一个packet的并发问题,带来的不仅是锁的问题,还有cache的问题。
虽然Gustafson定律不像阿姆尔达定律那么悲观,但是你们有信心把串行化的比例作的那么小么?尤其是像销售人员/市场人员说的那样仅用两个月的研发周期。
还是像首席所说,对于软件研发人员来说是一大考验。
@95,勉强算是吧,关心的东西以八卦为主……
同意92楼的观点,视角放的足够高,像俺等这般编码的,看问题还是太技术化。
不懂软件,不过就前1,2段落而言,有自吹自擂嫌疑,无实质内容!很吹牛!
1.目前哪位在国内看到了大众客户的“商业应用”?
2.“网络数据包的万兆处理能力”—怎么个处理法?简单应用貌似对各家都是easy的事情,复杂应用必定跑死T,呵呵,什么年代了,还拿万兆这个字眼来吹牛!
强烈建议首席收广告费!
想做好广告也需要有创意的,拿marketing吹牛不要命的东西来这儿,貌似走错地方了,对不对首席?
Intel已经在存储领域霸占了几乎所有市场。Intel+offload已经在存储应用了多年。
这里争论的很是激烈,都说弯曲是牛人出没的地方,诚不欺我呀!我是Meganovo的Eric,小弟做市场的,技术方面是菜鸟,每天潜水在弯曲学习各位牛人的文章,以便到客户那显摆。甚是赞同弯曲之前关于多核的一篇文章(应该是首席写的),“应用系统决定CPU”,所以没有好坏之分,只有是否适合之处。也甚是赞同萧秋水的观点,“我们做产品,不管是芯片厂商、平台厂商还是设备厂商,我们总要仔细思考几个问题:1、我的客户的pain是什么?2、我如何解决客户painful的事情?3、我的核心价值和differentiation是什么?
”,作为我们代理商和方案提供商,应该从萧秋水兄角度考虑问题。小弟没有其他能力,如果大家对Tilera感兴趣,小弟可以提供基于TilePro处理器的ATCA线卡、1U服务器、多媒体平台供大家评测(大家可以发邮件给我eric@meganovo.com,暗号:弯曲兄弟)。
To:徐鹤军同学,作为一个销售,我佩服你再弯曲和大家争论的勇气,但请注意你作为销售在这个行业的职业道德,不知道客户信息是商业秘密吗,你没有和客户签署过双向的NDA吗?私底下说说就算了,还在像弯曲这样有影响力的网站上讲,你老板zc怎么教你的!这样的职业道德以后还有那个客户敢跟你交流!
萧秋水兄的评论甚合我意,赞一个!!!
推销自己的平台,应该能说清楚自己的优势在哪里,和其他厂商的比较。单一个CPU是不行的,还有板卡,外设等。加入这个不是问题,软件平台是什么样的。能不能快速开发自己的服务,让客户关注自己的服务,而不是在操作系统,工具,以及与SDK的bug做斗争。从这一点来看,能进入linux mail trunk就是一件很重要的特色,至少说明能用,而且有不断更新,升级的可能。如何把产品快速推向市场才是最重要的,特别是对初创公司。
还有就是建议做广告的公司给弯曲一点赞助费,把网速,服务器升级一下,这个建议不过分吧。
102楼言重了。
严重同意104楼的建议,支持弯曲,人人有责。
不知道这个有没有参考意义
Top Layer Releases 10GbE Intrusion Prevention Solution for High-Performance, Scalable Protection against Network-borne Cyber Threats in 2011
Powered by Tilera Multicore Technology, New IPS 5500 Model 2000ES Delivers Low-Power Stackable ProtectionCluster™ Support for Unmatched 10GbE IPS Solution
HUDSON, Mass.–(BUSINESS WIRE)–Top Layer Security, a leading global provider of Network Intrusion Prevention Systems (IPS), announced today the availability of its new IPS 5500 solution for 10GbE networks. Leveraging Top Layer’s 4th-generation IPS architecture, and powered by Tilera’s most powerful multicore processor, the new solution delivers proven protection against network security threats in an innovative high-performance, low-power, scalable 10GbE IPS solution. The Model 2000ES is the 8th new IPS 5500 model that Top Layer has introduced in the past 12 months.
“2010 Update: What Organizations are Spending on IT Security”
.“Top Layer was my IPS decision three years ago because they provided the specific solutions I needed to protect my network,” Jeff Hinkle, President, Global Net Access, LLC. “Now that I am ready to expand my network to 10Gig Ethernet, Top Layer’s IPS 5500 Model 2000ES makes it a smooth transition that allows me to continue my network protection without interruption. Top Layer continues to deliver product innovations that we need to deal with growing network security demands.”
According to Gartner, “More than 40% of organizations name IPS, patch management, DLP, antivirus and identity management among the top five security priorities for 2010. Almost half of organizations include intrusion prevention systems (IPSs) in their project portfolios.”1 Top Layer was also recently recognized as a visionary in Gartner’s 2010 Intrusion Prevention Magic Quadrant.2
“Top Layer’s new 10GbE IPS 5500 solution combines flexible deployment options with powerful, scalable network security protection and reliability that customers need,” said Peter Rendall, President and Chief Executive Officer, Top Layer Security. “Built on the high-performance Tilera platform, Top Layer’s 4th-generation IPS technology is a testament to our commitment to understanding future needs of customers as they navigate a mature IPS technology market while providing them with capabilities to protect their companies’ critical online assets against a constant barrage of network-borne cyber threats, new and old.”
The new 10GbE IPS solution provides protection against current and future network-borne cyber threats by combining Top Layer’s TopResponse™ threat protection update service, high-performance, purpose-built IPS platforms, and real-time management and reporting capabilities. Top Layer’s new Model 2000ES solution offers significant advantages:
昨天休息一天,今天继续灌水。。。。其实个人觉得楼上诸位所说的IO瓶颈的问题,目前在所有多核厂商的产品中都存在,是共性的问题。其实我倒是觉得我们没必要关心这些问题,因为大多数厂商目前多核产品的瓶颈还没有转移到关心IO这一步来。就现阶段来说,其实多核产品的主要问题依然是软件架构的问题;也就是如果能够在现有的linux架构下发挥最大的性能。有的厂商寄希望于选用性能更强的CPU来解决这个问题,有的厂商将自己的应用移植到多核厂商提供的类似于SE这样第三方库的环境中运行。不管采用哪种方式,软件架构问题永远是一个不能回避的问题,所以就目前来说我觉得“解决软件问题者,得天下”
没错,相信翻腾的人已经自己很清楚了,那就是他们已经吃了N次闭门羹了,业内的几个兄弟都说他们已经去过他们的公司了,这些公司(包括我所在的公司)得出了一致的结论,我不说泛腾的人也清楚。
为什么需要通过更复杂的软件架构才能充分的利用T家处理器的资源?因为并不是为网络设备订制。
还有就是我上面提到的问题,谁能做到像Gustafson定律那样的大规模并且很小的并发比率?如果解决不了,超过16/32个核都是多余的。
再说IO问题,假设I家4个核的性能相当于T家16个核的运算能力,而I家和T家拥有同样的IO带宽,你说谁的性能高(在网络设备应用场景下)?
还有就是一个专门的核用于同步缓存和内存,所以不需要软件关心同步问题,这个,我真的弄不明白怎么回事,Meganovo有搞技术的跟大家分享一下么?
我猜T家的策略是这样的:
1.真正搞的懂多核的,已经有其他多核方案了,事实也证明了,这些厂商并不是没有考虑T家处理器,而是很快就否定了这种技术方案。
2.但国内还有很多技术实力很薄弱,根本还没搞多核甚至跟本没有实力搞多核(其实国内这样的小厂商不在少数),他们最不懂多核,且没有研发实力,是最好被忽悠的,所以这部分厂商就成了T家市场策略的重点目标。
3.问题是,他们没有能力做多核,怎么办呢?于是T家找了几家做平台的,原来可能都是做多媒体之类的,搞出一套通信解决方案,然后卖给这些小厂商。
TILERA RAISES $45 MILLION INCLUDING INVESTMENTS FROM ARTIS CAPITAL, WESTSUMMIT, CISCO, SAMSUNG
看来cisco,samsung都加入了翻腾。
Will Chie, 你好,我是TILERA的peter, 非常希望和你当面交流,请教,你的指导我将非常荣幸,当然也希望能够多个朋友。 技术只是技术,条条大路通罗马。
TILERA有自己的强项,也有自己的弱项,没有客户的敲打,不可能提高,只有各位高手多指导,多敲打,TILERA才可能走的更远,更成功。希望各位大侠指导,如果需要,文档,软件,评估系统,找我联系。好的建议我们一定接受。
Chie兄,可以和peter liang联系下要一些详细的技术资料了解下。。不要一棒子就把别人打死,任何大公司都是从小公司一步步的做起来的。
谷歌还投资太阳能公司呢,
思科对T的投资就说明T进入通信行业一线了么?
楼主的软文固然要予以“揭露”,但Will兄的观点似乎也略微偏激了一点吧,听您那口气通信和网安就代表了全部?
另外,好像没有人说T是通信行业一线吧。
TO: 115,
看清楚点再发言,我承认T在多媒体领域的成功,否认T家处理器在通信行业的适用性,我甚至都没有否认他家将来的处理器是否适合通信行业,何来偏激?何来“通信和网安就代表了全部”?
Will兄,可能是我理解错了吧,不过坛子里好几个兄弟好像都有”你好像一棒子要把T打死“的感觉啊,呵呵。
其实个人感觉T走的是通用处理器的路子,更接近x86而不是C或R,除了网络和视频应用外,服务器可能是他家更重要的方向。
对于C和R等专用处理器而言,随着通用处理器性能的逐年提升,总的来说生存空间会越来越狭窄,大家看看NP的市场就知道了。
不同意117的观点。如果T走通用处理器的路去跟IA,POWER抢服务器市场,一定成先烈
T现在在manycore的interconnect上领先了一步,一定得走农村(嵌入式,网络,媒体)包围城市(SERVER)的路线。看看ARM就知道了。
回117楼:你理解错是你的事情,别人理解错是别人理解错的事情,理解错了还让我做解释的话,我这辈子活得得多累啊。
个人觉得正是他家搞大杂烩,会使得他家优势尽失。
另外,顶T家的人有个共同的特征,完全没有搞过研发的,说的技术的话也全都是市场上的技术话语。
不知道什么时候C和R成了专用处理器,而T和ARM成了通用处理器?不知道您是怎么定义通用和专用的?如果真要说通用,MIPS阵营的Ecosystem要比T的架构的健全多了;
有一句话,大家自己琢磨一下:当一个CPU号称自己做啥都擅长的时候,实际上是在每个领域都不擅长。
BTW:我前几天还看到联想网御的一个PR里面说,现在处理器有两种架构:一个是以Intel为代表的x86架构,一个是以Freescale、C、N、ARM为代表的MIPS架构。
看到大家这么多评论,真的很感动,我们一定努力工作,不让大家失望。
120楼想反驳什么?“MIPS阵营的Ecosystem要比T的架构的健全多了”?什么意思。现在T也是MIPS阵营里的吧
至于C和R是专用处理器这个没什么好争论的吧。。。通用?好歹装个FPU进去吧兄弟。。。
不知道你想反驳什么。。。
To 120:联想网御写那篇稿子的人早就离开了,不能把所有责任都归给PR
To Will, 希望大家都理性的讨论,不要陷入口舌之争。
To 120,通用处理器和专用处理器本身就不是学术名词,根本也没有什么严格的定义,具备视频、网络、通信以及DSP功能的T相对于C和R来说称为通用并不为过吧。
至于你说的通用性必然会损失性能的问题,我非常同意。但有一点请注意,由于市场范围广,最多2年通用处理器就可以发展一代,哪个专用处理器有这样的发展速度?这个是核心问题。
TO 124:讨论问题不应该:“理性不理性的问题”,应该是“准确不准确”“正确不正确”的问题,我不觉得我不理性,反而你这么说,显得不是很理性吧,你哪看出来的啊?
另外,你完全没有技术能力啊,尽讲些市场术语能分析出东西来么?能得出正确的结论来么?
阿姆达定理和Gustafson在实践中的应用你知道怎么回事么?你知道加锁对于并行的影响有多大么?你知道哪些情况引发cache的miss match从而导致cache刷新么?知道这些开销又多大?你知道基于packet的并发和基于flow的并发问题么?你知道保序的设计和上面两个并发问题的关联么?有没有做过相同的处理器不同的总线带宽的性能测试?有没有做过不同串行化程度的性能测试?
To 125,牛!您的问题我看都看不懂,更别说回答了,就此别过,我还是继续潜水吧。
我告诉你我在这辩驳这个问题的意义:
别让厂商因为利益问题把弯曲污染了,弯曲和ZOL不一样,来这的人不应该受到广告的影响(你看首席打过广告么?),而是真正的分享其他的研究人员技术人员的成果,首席可以发出一片市场文章来供大家讨论,技术人员应该从这些评论中得出某一种技术到底是不是好的,而不是文章本身,我相信这是首席本意(首席一再强调弯曲评论的意义)。因此厂商的水军们不应该采用一些人身攻击方式及一些辩论技巧问题、还有什么心理学技巧、影响力技巧、五毛党攻势来误导群众。
我再说说我对非技术人员的看法:我同意首席的观点,弯曲不会也不应该成为nerd的园地,但这里绝大多数抱着纯正目的的非技术人员都很有意义,老韩的评测,萧兄上面从产品经理角度看问题的高度,等等,都非常有意义。
但有些人因为有利益问题,所以就有不择手段的嫌疑,国内其他网站论坛的水军还少么?为什么大家来弯曲?
要说在弯曲做纯粹的宣传谁有资格?Panabit,首先人家是首席大弟子,在弯曲做宣传跟新浪宣传新浪微博没啥大区别。
而且有兄弟所在公司和Panabit合作过,Panabit的性能,应用识别率在国内是无敌的,人家是真牛。
但你看看人家Panabit怎么做的?你回头看看人家那文章,再看看人家那回帖,甚至跟大家透漏了很多Panabit的核心技术问题,懂行的人都知道Panabit说的东东的价值。
比一比吧,水军门。
最后几个comments:
1. 对于说 Tilera 是 MIPS 的,请参考 http://www.mips.com/customers/licensees/#TT;
2. 对于说 Tilera 有 FPU 的,请参考 http://www.tilera.com/sites/default/files/productbriefs/PB025_TILE-Gx_Processor_A_v3.pdf http://www.tilera.com/sites/default/files/productbriefs/PB019_TILEPro64_Processor_A_v3.pdf http://www.tilera.com/sites/default/files/productbriefs/PB020_TILEPro36_processor_A_v2.pdf http://www.tilera.com/sites/default/files/productbriefs/PB020_TILEPro36_processor_A_v2.pdf http://www.tilera.com/sites/default/files/productbriefs/PB010_TILE64_Processor_A_v4.pdf 反而是 Freescale 的 QorIQ 有 FPU,Netlogic 的 XLP 有 FPU
3.对于说处理器两年更新一代,谁不是两年就更新一代了?Intel周期更快;
4.关于通用处理器的定义:http://en.wikipedia.org/wiki/General_purpose_macro_processor,从这个角度,ASIC/NPU 不是通用处理器,任何可以用标准的标准编程语言编程的处理器都是通用处理器;
5. 关于 DSP 功能,你怎么知道别人的多核处理器不能取代别人的 DSP 呢?DSP 也有很多不同的使用方向,有通信的、有控制的、有多媒体的;
6. 还有你怎么知道别人的多核处理器不能取代 Intel 做一些通用计算方面的处理呢?
Will 你有email吗?我的是 xiao.qiushui@yahoo.com,如果有可能,给我发一个email
To 122楼所有糊涂蛋
请你先搞清楚T的指令集,首先他不是MIPS架构,这个很多人都似乎有严重的误解。那只是一种instruction similar to MIPS,而且是一种Very long instruction word(VLIW)指令集, It is Tilera’s ISA,而根本不是什么MIPS!
另外你对专用处理器还是通用处理器的理解是错误的,120楼说的没错。一个处理器是不是要有FPU,是不是要支持多媒体,和是不是要做DDR控制器,是不是要集成各种I/O是一样的,都是处理器设计中可以灵活选择的,并不是说你没有做FPU,这个处理器就做不了浮点运算,也就不能称之为通用处理器了。这样的理解是不对的。
给你扫扫盲,当今几种主要的通用处理器架构:X86(IA32/IA64/AMD64)、PowerPC、MIPS(MIPS32/64)、ARM(ARM9/ARM11/ARM Cortex A9)、SPARC,当然还得算上已经消失了的牛逼的Alpha,别再搞混了!
“现在处理器有两种架构:一个是以Intel为代表的x86架构,一个是以Freescale、C、N、ARM为代表的MIPS架构。”
这不是搞笑么?我来给看不懂的人解释一下吧,呵呵
Freescale在嵌入式处理器领域的主打产品为PowerPC架构,C/N为MIPS64架构,而ARM虽然是一个公司,但同时也是一个处理器架构的名称,和PowerPC/MIPS/X86属于一类名词。所以前面那段话说的简直牛唇不对马嘴。
真难以想象在这里还需要我给别人解释这个!
通过看panabit的文章, 回帖, 学到了非常多的东西, 很多不明白的, 再针对性的google, 学习也慢慢弄明白了.
btw: “你知道基于packet的并发和基于flow的并发问题么? 你知道保序的设计和上面两个并发问题的关联么?” – 我想弄明白这两个问题, 应该看一些什么资料呢? 我是硬件出身转行做软件的, 基础比较差, 烦劳指点一下, 谢谢!
怎么看怎么感觉好像是Tilera找了一堆虾兵蟹将在这里胡搅蛮缠啊,这样可不好啊,名声是要被搞坏的!
Tilera想提高知名度,这本来无可厚非,找枪手、写软文、提高人气、也都无可厚非。但是弄得技术讨论变成口水仗似的乱作一团就很不好了!还是希望大家聚焦技术,市场,有些专业精神!
一些概念需要有一点context才好更准确的理解。
个人浅薄理解:
packet的并发,一般指逐包的负载均衡的转发,就是同一类报文(同一条流),但处理引擎可能不同,这样就有乱序问题,但负载均衡较好
flow的并发,一般指逐流负载均衡的转发,就是同一类报文(同一条流)使用相同的处理引擎,此时可以说不必考虑保序问题,但负载均衡可能会不够均匀
当然,实际上两种不同的模式带来的实际业务处理还有更多的不同。
看,懂行的就像理客这样,能真正讨论清楚问题,凡是为T家说话的,一个有懂技术的都没有,而且都是平时见不到的,突然冒出来的,太有特征了。
谢谢131楼理客! packet并发大致明白了, 以前做ixp板的时候, 常听微码组同事这么说, 再下去看看flow并发, 多跟牛人们学习.
首席以前就说过“一个流可以被多个core处理,一个core可以处理多条流,是superscaler的结构”,搜一下看看。
多个core处理一个流,必然会引起乱序的问题。但是一个流只能被一个core处理,又会有性能的问题。不能并行的话,单个流的吞吐是提不上来的;但是对多条流来说,总的吞吐量却是提高了。所以,单个core的性能也很重要,一条流不能并发,可以多条流并发。
这里面的load balance和reorder,以及序列化等等,是多核应用的难点。使之最大可能并行化,是多核追求的目标,但是有时受限于应用的要求,很难并行化,所以core多了,性能并不一定高。
to 128:
首先,我承认错误,把similar to MIPS看成MIPS了
其次,你要给我扫盲的,PPC的e600,e500,e500mc,搞过几年。MIPS搞过cavium,arm多年前玩过sc44b0和2410,还有ixp。能力有限,IA没搞过,SPARC和aplha没见过。所以,对于你这种动不动就想给人扫盲的的态度表示不屑
再次,没有FPU当然可以做浮点运算。但是不管cavium和RMI,从来没有给他们的chip装上FPU的一丁点意愿,为什么取而代之的是一大堆包处理加速引擎。为什么server比拼的重要指标之一是flops。如果你要在通用处理器的概念上搅浑水我也不陪你,只是答复120楼,C和R是彻彻底底的专用处理器。除了codec和pktproc,一点生存空间都没有。
最后,对你的幽默感表示遗憾。我想情商正常的人都应该知道120楼那句话是什么意思。我也很难想象你为什么要给别人解释这个。。。
国内好像有个习惯,凡是跟自己意见不一致的就是五毛,一定要一杆子全部扫死。逐渐丧失跟人类正常交流的能力
同意楼上的说法,却深有体会。200条UDP流的测试确实在82576上比单流提供至少一倍以上。
TO: Will Chie
如果方便,希望当面指教,当然你可能觉得我公司一无是处,但你的意见我们还是希望认真听取。 我的邮件pliang@tilera.com. 至于TILERA是否适合做通讯,只有结果才能说明一切,TILERA在努力学习,希望能够快速进步,RMI,CAVIUM, FSL, TI都是很好的老师。 我们希望能比这些老师强,希望能够为我们的客户提供更好的产品,更高的性价比,希望用我们产品的客户成功。批评我们不怕,至少今天能有135楼的帖子,很感动,是发自内心的。也非常感谢大家。我不是技术大牛,但觉得技术这个东西,没有最好,只有更好,没有是不适合,只有是不是可以更适合。 创新不宜呀,不仅要在技术上做到,还要能在心理上承受,最后还是要靠结果说话。
实在忍不住潜水了。
To 129, 你确认你理解Macro和Micro的区别?你确认你理解维基百科那个链接的含义?
我早就说过所谓通用与专用根本不是学术上的定义,正如嵌入式的概念一样,完全是以应用为基础的一种分类而已。就目前而言,相对于C、R以及TI DSP这些产品,x86,ARM都是明显的通用处理器,FSL的PPC可以勉强算得上通用,T的目标也是通用处理器,这些还需要争论么?
至于2年更新一代的说法,我的原话是通用处理器至少2年更新一代,intel更是摩尔定律的代表。处理器工业界目前受制于频率极限的问题,要继续延续2年或所谓18个月更新一代的路标,无奈之下只能求助于CMP技术,而能够在单个硅片上不断进行核心数扩展,目前看来二维MESH是唯一可行之路,Intel的SCC和T的产品都是这方面的佼佼者,你觉得在新的芯片架构出来之前,采用Bus,Ring以及CrossBar等技术的产品有可能跟得上这个节奏么?
To 137,在Codec领域,C和R也是一点机会没有。
对于功能较单一并且用量很大的应用,比如网络摄像机、监控市场等,目前是各类ASIC的天下,C收购来的那个产品基本上没啥机会。对于需要海量视频集中处理并且功能很灵活的应用,C和R的问题在于核心数不够多!
再补充一下,第一类应用所有多核处理器都没机会,目前还是ASIC的天下。第二类就比拼看谁的总体性能更强,在频率有上限的前提下,那就看谁核心数多了。其实大家可以看看Intel的SCC,24个Tile,每个Tile是双核的IA32。
对不起,维基百科上的那个的确没有看得太仔细,刚才仔细看了一下,果然是讲得不同的内容!多谢指正!
To 140:
Intel的SCC恐怕只是为了研究大规模并行计算而设计的实验芯片吧?Tilara也是给大型机设计的?
你的回复基本可以总结为下面两句话:Tilera的总线很牛X;Tilera的核很多,也牛X。
如果设计CPU的都以这两条作为标准的话那就有意思了,要做的其实很简单,把ARM核拿过来,越简单越好的那种,用Tilera的总线堆成一个200核的处理器不就完了?干嘛还要搞ILP,干嘛还要OoO,连Pipeline都省了算了,核多不就行了?
我觉得吧这个世界里还是有些自然规律是人类无法突破的,就好像人类无法突破能量守恒,人类也无法逃脱自然界的生态平衡。
举个例子,我们都玩过星际,星际里最便宜造的最快的就是虫族的小狗,假设给你1000块钱,1000个气,同样都造地面部队,你全都拿来造小狗可绝对不是战斗力最优的配置方案。虽然这个例子不能说明所有的问题,但是我想用它说明的是,事物的效能是受多方面因素影响的,而这些因素对事物效能所产生的影响是此消彼长的,在这点上,上帝总是公平的!
1.就单个物体战斗力而言,如果小狗跑得快又便宜,那就一定不扛打,攻击力也弱。要是小狗既跑的快又便宜,还怎么打也不死,然后还能秒杀所有生物,那这游戏玩着还有什么意思啊,这样的星际绝火不到今天。
2.就群体战斗力而言,小狗虽然人多势众,但是腿短够不到更远,所以他只能攻击眼前的敌人。当他面对的敌人数量很少又集中,或者躲在一个狭小的空间时他的攻击就无法有效展开,能够释放的战斗力也就很少。这个时候,大多数小狗都在到处乱跑,却找不到一处下手的地方,因为周围到处挤满了自己的同类;而同时在敌人面前血拼的小狗又因为攻击力太弱,还不禁打,被一个接一个的干掉。。。但是当对付数量较多且相对位置比较分散的敌人时,小狗的数量优势就体现出来了。小狗迅速分散贴近敌人,最后四五个小狗围着一个敌人乱啃,此时的攻击效能最为突出。
上面的例子虽然不够严谨,仅仅是为了描述一种现象,但是我们还是能够看出来,一味加强某一方面的因素(比如数量)永远不会是整体效能最优的方案,除非你能做到像细菌和病毒那样的水平,否则在有限的资源和空间内,大家拼的是最优配比。因为你在加强某一方面的因素时,一定有另外一些因素被削弱了,而最终的效能不取决于你在某一方面有多强,这个是自然界的平衡。
Intel有能力去豁一个SCC试着玩,Tilera也有这个能力么?
俺也为T说句话,俺认为Tilera适合做企业路由器:)
主要理由如下:
1、相对于NP来说,Tilera编程简单,并且更灵活。Tilera里面有很多可编程的核,但是几乎没有专用的报文加速硬件,不需要程序员去理解和学习那些加速硬件的工作原理和寄存器,也不需要软件去兼容那些复杂硬件加速器的Bug。并且Tilera是在用户空间编程,软件调试的效率更高,所以说它编程简单。对比Cavium和RMI来说Tilera也是相对简单的,而且灵活。
2、Tilera用于中端企业路由器,做报文转发性能是足够的,虽然他每个核的处理能力不是特别强,但是它的数量足够多。企业路由器并不需要非常高速的报文转发,但是需要支持很多业务。
当然Tilera也有缺点,例如:通过它那个MESH网络访问内存的延迟很大。而偏偏Tilera每个核心的cache又很少。不爽。
多核并不适合所有应用,但是有些应用的确可以被很容易的解,IP报文转发就是其中一种。
Some applications, such as packet processing and multimedia, can easily be divided into many small pieces. These applications work well on multicore processors, which include 4 to 64 CPUs on a single chip.
上面一段话是去年linley Group关于有一个关于高速嵌入式CPU的分析报告里面的,其中的Executive Summary写的很好,是对目前CPU市场的一个很简短的总结,但很全面。推荐阅读。
http://www.linleygroup.com/Reports/embedded_processors_guide.html
TO 145:
1:你用过Cavium的加解密协处理器么?你觉得那个复杂么?在应用层编程是由处理器决定的不是由开发人员决定的?
2:早就提过这个问题了,我问你,同样IO带宽,假设同样的处理器核心架构,1个4G核和4个1G核,到底哪个快?
都是反问句,没指望谁回答。
我觉得弯曲水平一向很高,怎么在T的问题上,居然发现了很多最基本的程序员的判断力都没有的同学。
To 145:
黄岩说的有道理,用Tile确实不用去理解更多硬件加速模块,但是同样的功能用软件实现,软件复杂度也增加了。同样软件的开发维护成本也会变大。另外还有一点很多人都没有注意,软件复杂度增加意为着ICache Miss会大幅增加,同时对核心取指译码带来的压力都会增加,由此产生的开销往往是不为人注意的,但其实影响很大
多核系统最让人头疼的问题其实是对共享资源的处理,比如你在处理报文的时候得查表吧,那这个表项就得是共享的吧,如果很多核都来参与共享数据的存取,要增加很多额外的I/O开销不说,单数据加锁带来的开销,就比核数相对少一些的方案多得多。这种场景下Tile核心多的优势其实是发挥不出来的。
真正能够发挥其多核能力的应该还是流媒体加速,这种应用需要的共享资源并不多,而Tile的众多计算资源可以相对独立的工作,性能得以充分发挥。
对黄岩兄道歉,最近被一些有的没的的人搞的头大,所以态度出了问题。
是这样的,我一句一句的来分析,真诚讨论,希望黄岩兄见谅:
“1、相对于NP来说,Tilera编程简单,并且更灵活。”
这个是总结性的一句话,下面分开来分析:
“Tilera里面有很多可编程的核,但是几乎没有专用的报文加速硬件,不需要程序员去理解和学习那些加速硬件的工作原理和寄存器,”
是这样的,以我用过的最典型的加解密协处理器来分析:Cavium的加解密协处理器是同步的,所以其实编程很简单,而RMI则是异步的,所以软件架构上就需要考虑异步问题,所以RMI在架构上比Cavium复杂,而如果用T家处理器,一个核负责IPSEC的流程处理,另一个用于加解密,如果同步,那么还不如不分核来分别处理IPSEC流程和加解密流程,所以一定是异步架构,那么好,如果是异步架构,那么T家没有硬件保序,那么软件保序和异步处理,这种架构是不是很复杂呢?
“也不需要软件去兼容那些复杂硬件加速器的Bug。”
个人觉得有逻辑就有bug,即使没有硬件加速器,那么也有SDK,可能会出bug。
“并且Tilera是在用户空间编程,软件调试的效率更高,所以说它编程简单。对比Cavium和RMI来说Tilera也是相对简单的,而且灵活。”
事实上,国内能力够的公司,不管是x86、还是RMI、还是Cavium都已经做到用户态了,所以T没优势。
“2、Tilera用于中端企业路由器,做报文转发性能是足够的,虽然他每个核的处理能力不是特别强,但是它的数量足够多。”
这个问题就是我之前一直说的,相信参与过多核平台预研的同学在测试的时候都遇到过这个问题,就是核多了性能可能反而下降,主要就是核多了会占用更多的总线开销,另外还会产生更多的资源的抢占。
“企业路由器并不需要非常高速的报文转发,但是需要支持很多业务。”
这个个人觉得有协处理器的NP会更有优势。
以上为在下愚见,望与黄岩兄交流,希望黄岩兄大人不计小人过。
同意MacOS的观点。
已经到150了,大家都谈论了很多;有很多理论,经验方面的碰撞;小弟学习到了不少东西,个人观点没有一个处理器是完美的,适合所有应用产品,但每一类应用,可能都有其技术方面最适合的处理器;
如果能有基于实际的应用比如防火墙,路由器,DPI,防DDOS设备,WEB服务器等;讨论每一类应用场景下哪类处理器更适合,可能会更有意义;
当一个团队选择硬件平台,必定会综合考虑各种因素,权衡之后作出;比如各种处理器的优势和劣势,厂商的技术支持能力,应用都的主要性能瓶颈,团队软硬件开发的经验,成本,上市时间等等;最后选择一种最适合自己的处理器,构建其软硬件平台
用一个核专做IPSEC性能是多少?1Mpps?
用一个核专门做ACL性能是多少?2Mpps?
一个核做session处理性能多少?3-?Mpps?
用一个核专门做流负载均衡性能是多少?4Mpps?
…
有没有对比测试数据?
To Will Chie,欢迎讨论,俺不认为自己的看法是完全正确的,也希望通过讨论发现自己的错误观点。
1、关于有“专用硬件”复杂,还是“软件实现”更复杂的问题,的确没有量化数据,只是个人感觉,对自己实现的软件更加放心一点:)
2、多核编程简单,还是单核编程更简单?这个
问题估计大家没有什么争议,单核简单。64核简单,还是16核简单?我认为差不多,都要处理多核共性问题。核多一点,任务调整粒度更细一点,比如你用一个专用核做free_packet_buffer管理如果不够用了,就可以用两个。如果处理器只有2个核,就不能这么做了。
俺对于这些Cavium、RMI、Tilera、Freescale等,俺曾经做过一些测试,主要目的是对比性价比。但是没办法对所有型号进行测试,有些型号在选型的时候,还没有样片。俺就用已有的测试数据去估计未来型号的性能。方法如下:
throughput = func(ips, cache_size, mem_if_num, mem_if_freq)
上面公示中ips是整个芯片所有CPU核加起来每秒中能够执行的指令数量,另外三个分别是cache的总容量、内存接口的数量、内存接口的频率。俺粗略的认为这些因素对throughput的影响都是线性。然后根据已有的测试数据,去调整每个因素的影响因子。然后在用这个模型去估计待选型号的性能。
估计这里很多兄弟都曾经参与过CPU选型,大家都说说,你们都用什么方法?
To 理科,限于某种原因,具体数据俺不能说。
To MacOS:“单数据加锁带来的开销,就比核数相对少一些的方案多得多”
对于查找频率很高的表,比如路由表,ARP表等,一般这样做:
1、查表的时候不加任何锁,没有锁开销;
2、更改的时候,先把数据拷贝一份,然后更改,然后再用单指令去修改指向这个表项上一级指针。让去芯片保证这个指针修改的动作是原子的,无锁的。
3、对于被修改旧表项,以及被删除的过时表项,等一段时间,等不再有人使用的时候,再删除。
Linux核心也有类似的RCU技术,锁不是必须的。
To 154:
呵呵,RCU确实是一种读写锁的替代方案,但是他也不是万能的,RCU带来的问题是表项更新的开销变的很大,而且增加了很多不确定性因素。比如你什么时候才能删除老的表项是不确定的,因为你无法知道什么时候老的表项没有人访问了。这对系统的可靠性是一个极大的挑战。
RCU确实可以优化查表操作,但是却使得表项更新操作变得更加困难,开销更大。在一个经常发生路由震荡,ARP更新的网络中使用这种方式的软件可要吃苦头了。
所以RCU还不是普遍应用的技术,他的可靠性等方面还有待验证
在Tile这种硬件环境下,RCU恐怕是唯一的选择了,但是其他的环境就可以有更多的选择,当然也包括RCU
TO 黄岩兄:
1:上面有关于ipsec的例子,也是我的一点体会,呵呵。
2:我不否认核多了编起程来更简单,例如我们可以不考虑Dataplane如何和ControlPlane分享core的问题,但为什么核多了比核少了更舍得专门拿出一些core来做一些事情呢?就是因为核多到了没处用了,已经冗余了,目前的基于其他处理器的架构的核都是满负荷运转(只要有包),这正是T家处理器核多其他资源少的一个劣势(有些核因为比较空闲等同于浪费,能耗却已经消耗进去了),当然编程的确简单了些。
关于多核系统对CPU处理性能的建模问题,这个相信大多公司都做过,但我不知道其他公司如何,我们这边并不成功,这里面影响因素也很多,首先就不能使用相同的软件架构,例如Cavium的就不需要保序,RMI的保序有很多种实现方案。
我对您的模型给个建议:加入核数,软件并行度,各种IO带宽这几个参数。
其实最后还是测来测去的。成本高啊。
TO 黄岩兄的154楼问题:
事实上,路由表项要看怎么组织,这个问题才能成立,举个例子:如果同样是hash table的,如果是拉链法解决这个问题,因为存在链表,所以这个更新一旦是添加或者删除这样的操作,链表则还是需要保护,所以不加锁就不可能了。
要是顺延法解决这个问题,读的时候的确不需要加锁,但写的时候还是要加锁。
但更实际的情况是,似乎没有人用顺延法的hashtable去存放路由表,因为这种数据结构对路由表并不适用。
RCU锁是有个全局的锁的:
static inline void rcu_read_lock(void)
{
__rcu_read_lock();
__acquire(RCU);
rcu_read_acquire();
}
sorry,上面讲错了,顺延法的hash table也避免不聊对整个结构的免锁。
To 144,你说SCC是专为大型机设计的?现在还有大型机这个概念么?我再次重申一下我的观点:
1. 如果采用单核的方法可以继续将处理器性能按时间的指数来增长(也就是所谓的摩尔定律),没人愿意用多核;
2. 单核的频率提升遇到暂时不可克服的困难,目前学术界和工业界一致认为只有多核才能延续摩尔定律;
3. 实际上,目前CPU的设计在技术上确实是一件相对容易的事情,更多的考虑就是市场需求,前面有兄弟讲过,所谓FPU、VLIW、SIMD、Pipeline等就像各种IO接口一样,根据市场定位取舍就得了;
4. 当然在考虑以上特性的条件下,还能把主频做到2GHz以上就只有Intel,AMD和IBM等寥寥几家了,这才是真正显示功力的地方,只可惜没有办法继续沿着时间的指数关系继续提升了;
5. 同样,能把多个核心高速互联起来也是一件很困难的事情,你可以向任何一位搞处理器研究的人员询问一下MIT的RAW Processor在学术界的地位以及Mesh的贡献;
6. 至于多核编程带来软件模型上的变化,我想这是所有软件人员必须面对的问题,在目前这个手机CPU都是双核1G的时代,这个转变是无法抗拒的。
To 144,你说SCC是专为大型机设计的?现在还有大型机这个概念么?Top500中还有多少系统可归为大型机范畴?我再次重申一下我的观点:
1. 如果采用单核的方法可以继续将处理器性能按时间的指数来增长(也就是所谓的摩尔定律),没人愿意用多核;
2. 单核的频率提升遇到暂时不可克服的困难,目前学术界和工业界一致认为只有多核才能延续摩尔定律;
3. 正如你所MACOS所言,目前处理器的设计在技术上确实是一件相对容易的事情,更多的考虑就是市场需求,前面有兄弟讲过,所谓FPU、VLIW、SIMD、Pipeline等特性就像各种IO接口一样,根据市场定位取舍就得了;
4. 虽然设计处理器核是一件简单的事情,但把主频做到2GHz以上就只有Intel,AMD和IBM等寥寥几家了,这才是真正显示功力的地方,只可惜没有办法继续沿着时间的指数关系继续提升了;
5. 同样,能把多个核心高速互联起来也是一件很困难的事情,你可以向任何一位搞处理器研究的人员询问一下MIT的RAW Processor在学术界的地位以及Mesh的贡献;
6. 谈到功耗问题,Konstantakopoulos博士的研究表明,即使只有4个处理器核心,在同样运算性能的条件下,采用MESH互联将会比总线互联节省60%以上的功耗,大家可以去查阅他的博士论文了解详细信息;
7. 至于多核编程带来软件模型上的变化,我想这是所有软件人员必须面对的问题,在目前这个手机CPU都是双核1G的时代,这个转变目前看起来是无法抗拒的。
TILERA GX产品已经增加了硬件加密和无损压缩加速器MICA。 包保序也通过packet处理引擎mPIPE来提供。http://www.tilera.com/sites/default/files/productbriefs/PB025_TILE-Gx_Processor_A_v3.pdf。
如果需要更详细的信息可以直接联系我。CAVIUM, RMI都是我们老师,我们会努力学习的。同时我们也努力提供更高的性价比。
TO 159楼长期潜水员:
“1. 如果采用单核的方法可以继续将处理器性能按时间的指数来增长(也就是所谓的摩尔定律),没人愿意用多核;
2. 单核的频率提升遇到暂时不可克服的困难,目前学术界和工业界一致认为只有多核才能延续摩尔定律;”
这两个观点都没错,但并不完全,如果单纯的算计算能力,核越多性能越好这个观点没错;
但问题在软件,不考虑软件来算处理器的运算能力是没有意义的,否则就不会有amdahl定律和gustafson定律了。所以需要想“算出”一个处理器在跑一个软件的性能时,一定要考虑的一个问题是:串行化比率。其实引入串行化比率这个参数后,核越多越好这个观点就被否定了大半,但问题是计算机系统性能不是单由处理器决定的,否则试着买个I7处理器,64M内存的电脑用用试。个人觉得另外还必须考虑一些IO问题,注意是必须,正如我前面所说,相信有过多核平台性能评估的同学都有过我的体会,就是在有限IO带宽的情况下,核数的增加使得性能不增反降,这个不是什么理论或者假说,和多普勒效应一样,这是一个亲历的事情,经过对各种总线、内存的调换后,得出试验结论,IO带宽瓶颈导致的。其实远不止IO问题,还需要考虑cache的问题,数据的同步过程会导致cache的刷新,导致内存访问的增加。
To 162,自从计算机系统出现以来,CPU和IO以及主存之间的带宽一直就是一个瓶颈问题。另外你说的针对某些应用的串化比率问题、Cache刷新问题等等都不是问题的关键,通用处理器的目标从来都不是针对所有应用都极致高效,而是对绝大多数应用有效即可。x86架构的功耗、网络吞吐能力多年来一直为人所诟病,反倒是NP在这个领域做到了极致,但现在你还能看到几家NP?x86已经是市场最大占有者了。
TO 159楼长期潜水员:
“3. 正如你所MACOS所言,目前处理器的设计在技术上确实是一件相对容易的事情,更多的考虑就是市场需求,前面有兄弟讲过,所谓FPU、VLIW、SIMD、Pipeline等特性就像各种IO接口一样,根据市场定位取舍就得了;”
有的处理器适合运算量大,IO量少的应用,有的处理器适合运算量相对较少,IO量大的应用。
“4. 虽然设计处理器核是一件简单的事情,但把主频做到2GHz以上就只有Intel,AMD和IBM等寥寥几家了,这才是真正显示功力的地方,只可惜没有办法继续沿着时间的指数关系继续提升了;”
同意此观点,这也是为什么通信行业还是对x86抱有很大期望的原因。
看好x86的原因其实就是看好摩尔定律,Intel一年2颗芯片,即使今年还不能做某些事情,2年以后怎样呢?已经有人用x86做基站了。
TO 163:
“另外你说的针对某些应用的串化比率问题、Cache刷新问题等等都不是问题的关键,通用处理器的目标从来都不是针对所有应用都极致高效,而是对绝大多数应用有效即可。”
问题是,我从来都是在讲通信设备的应用,无论是不是通信设备,串行化比率对多核处理器都是个很重要很重要的问题。事实上amdahl定律和gustafson定律只有两个参数:核数、串行化比率。你是做软件的么?做过针对多核平台的软件架构么?你说大多数应用,用的最多的应用是桌面应用和嵌入式应用,你觉得100个核在这两种应用场景下有意义么?
“x86架构的功耗、网络吞吐能力多年来一直为人所诟病,反倒是NP在这个领域做到了极致,但现在你还能看到几家NP?x86已经是市场最大占有者了。”
所以我一再说对x86都是抱有很大期望的。
总结:对软件的忽视单纯讨论处理器是完全没有意义的。
我只想说,如果一颗处理器仅仅限定某一个特定市场,那么迟早会死掉,你不也看好x86么?
一个极端的看法是未来基本上只有手机和PC这两个产业还会有ASIC以及专用处理器的生存空间,其他都是通用处理器的天下。
软件不是忽视的问题,而是从来都落后于硬件发展的问题。目前看起来只有转换思路,从算法上着手,适应多核时代才是一条光明大道。
当然,这只是总的趋势,吹吹牛是可以的。针对某些具体的案子,还是要从多个角度综合考虑的。
之前一直说T家处理器的不是,导致了很多人可能觉得我有所偏颇,这里也的确有我对某人的言辞所产生的对抗情绪,但也不完全是。我重申观点:
我只是觉得目前(注意是目前)T家处理器并不适合通信设备(注意是通信设备)。
之所以说目前是因为我找到的资料和我所在的公司及兄弟公司都是做过测试都证明的确不适合,但并不说明T家哪天出来个为通信设备订制的会非常不错,试试上我也是关注的,也是希望能出来一个很好的适合通信行业的处理器的。
另外,相信T家处理器在云计算及服务器领域和多媒体领域在过去已经证明了是成功的(如果不是网上找到的资料又都是吹牛的水文的话),多媒体可能是前面说到的运算多IO少的应用(猜测,不同多媒体行业),说说云计算: 和通信设备不同的是,通信设备软件往往都可以根据硬件来订制,软件架构对于通信厂商来说是完全清晰的,所以可以通过软件架构的设计来完全充分的发挥硬件系统的能力。而云计算厂商则不同,就PAAS来说,软件的某些部分是未知的,所以在设计架构的时候,就不见得能够完全发挥硬件能力,这就好比socket的编程模型一样,选择异步模型或者选择同步模型,通信设备就好比是异步模型,而云计算就不可能完全做到异步模型,顶多是部分异步部分同步的模型,相信在这种应用场景下,核多(但性能并未被完全发挥)会有较大优势。其实对云计算也不熟,PAAS是不是每个应用都相当于一个虚拟机?如果是虚拟机相信核多也会有优势,总之的确会简化编程模型,但有不能充分发挥硬件性能。
另外,我不在这个问题上再做过多讨论,我相信上面的讨论已经足够说明问题了,有空看看书,呵呵。
唉,我都懒得再说了
你说的没错,只有一点我想强调一下:一直以来硬件的发展都远远领先于软件,因此是否能完全发挥硬件性能在大多数领域都不是关键问题,设计者也不提倡为了充分发挥那一点点性能而浪费软件人员过多的精力。
假如说你基于某款专用处理器设计了产品,而竞争对手基于通用处理器设计了产品。当你还在某些专用处理器上不断优化软件来提升性能的时候,竞争对手的产品由于通用处理器的飞速发展已经推出了好几代产品,这时候你如何竞争?
这就是x86这类通用处理器的可怕之处,我的第一台电脑是AMD的5×86,价值8k多元,需要硬件解压卡才能播放VCD碟片,没过多久奔腾133出来后就可以流畅的用Xing Player播放了,自那以后市场上就再没看到过硬件解压卡,呵呵。
To Will Chie
关于您说的”我只是觉得目前(注意是目前)T家处理器并不适合通信设备(注意是通信设备)。
之所以说目前是因为我找到的资料和我所在的公司及兄弟公司都是做过测试都证明的确不适合,”
麻烦你给出实际测试的数据来?
我觉得有些人把楼给歪了。
本楼的核心是T在并行运算中在硬件Mesh架构上带来的巨大革新,而不是在讨论软件的东西。
第一,软件总是要改的,不信请看x86。除了SCC的48核,双路或四路的Sandy Bridge,算上超线程,软件可控制的处理器数量也达到了32和64,那么仅仅为了把x86用好,你也要好好搞搞并行处理的软件。
第二,为什么Intel要搞SCC?因为x86也痛苦,从Bus到Ring,只是延缓了增加核数的困难,并不解决问题,所以他要提前预研Mesh架构。
目前来看,T也是有问题的。我的一个测试,当代码段超过50M字节,随机访问的内存超过20G(可不是内存压力测试,呵呵),它的IPC降到了30%。当然了,这对x86也带来同样大的问题。RMI的IPC到是降的不太多,但总体运算能力实在是太少了一些。Cavium就不谈了,核也不多,也没有多线程来分担IO。当然了,各位的应用会不会这么极端,也是个很大的问题。
弯曲评论的重心是评论而不是弯曲。曲径通幽处,禅房花木深。。。
读者一定要通过一篇文章,阅读评论,然后做总结。反思。这样才能达到学习,提高的目的。
市场人员可以从中知道自己产品定位,业界接受度的许多信息。
从而可以指导一下针对性的工作。。。。。。
弯曲评论愿意帮助大家。。。。。。
从具体技术而言。我的观点是:应用决定系统;系统决定硬件。一定要从做什么应用,来看用什么硬件。。。。。。
谢谢
首席脑子还是清楚的,呵呵
to 173过客:
我个人感觉,tilera的low ipc是不能像RMI用multi-thread去cover能解决的。因为bottle neck在memory bandwidth上面而不是pipeline bubble。如果用multithread去榨取更多的内存带宽,情况只会更糟糕。
我想这也是所有manycore system必须垮过的一步,要想马儿跑的欢(high ipc),又不想给马儿吃饱(low mem bw),估计马儿也不干。
tilera领先了interconnect的第一步,如果能解决mem的问题。我想overall一定是很有前景的。
对于软件,软件代码的组织和行为很可能成倍的影响T的性能。我想至少在通信领域,在一段时间内像通用处理器那样在linux下开发的应用还不会太多。也许C,H,Z等也许已经在研究baremetal上面的TOS了。。。
T现在在manycore的interconnect上领先了一步,一定得走农村(嵌入式,网络,媒体)包围城市(SERVER)的路线。看看ARM就知道了。
—-回复一下118层kevin
冒个泡 嵌入式和Sever是两个不同的领域 严格意义上 嵌入式在资源管理的技术含量远高于Sever
可不能有农村城市之分哪
而且不管是嵌入式和sever都有网络和媒体的应用