




AVX高级矢量扩展指令集——英特尔Sandy Bridge 处理器分析测试之三
作者 Lucifer | 2011-03-03 21:04 | 类型 专题分析, 芯片技术 | 11条用户评论 »
系列目录 英特尔Sandy Bridge处理器分析测试
原文精简版发布于《计算机世界》2011年第7期,本文为原稿,篇幅略多
AVX高级矢量扩展指令集 计算机世界实验室 盘骏
在上一篇连载中,笔者介绍了Sandy Bridge微架构中对性能有很大影响的几处改进,然而最重要的执行单元的变化没有涉及到,这部分的变化还跟Sandy Bridge新加入的AVX指令集相关。AVX(Advanced Vector Extensions,高级矢量扩展)是X86上重要的指令集改进,不仅仅在于其对性能的明显提升,还在于其对现有X86指令集的多种革新。
强大的性能:256位向量计算
向量就是多个标量的组合,通常意味着SIMD(单指令多数据),就是一个指令同时对多个数据进行处理,达到很大的吞吐量。早期的超级计算机大多都是向量机,而通过随着图形图像、视频、音频等多媒体的流行,PC处理器也开始向量化。X86上最早出现的是1996年的MMX(多媒体扩展)指令集,乃至1999年的SSE(流式SIMD扩展)指令集,分别是64位向量和128位向量,比超级计算机用的要短得多,所以叫做“短向量”。
Sandy Bridge的AVX将向量化宽度扩展到了256位,原有的16个128位XMM寄存器扩充为256位的YMM寄存器,可以同时处理8个单精度浮点数和4个双精度浮点数,在理想情况下,Sandy Bridge的浮点吞吐能力可以达到前代的两倍。目前AVX的256位向量仅支持浮点,不像128位的SSE那样,也能支持整数运算。
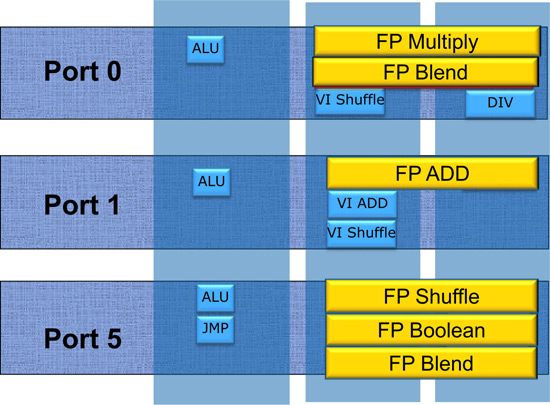
Sandy Bridge微架构的所有执行单元都经过了修改以执行256位AVX指令,特别是对于3个运算端口而言。Sandy Bridge微架构并没有直接将所有浮点执行单元扩充到256位宽度,而是采用了一种较为节约晶体管乃至能耗的方法:重用128位的SIMD整数和SIMD浮点路径。
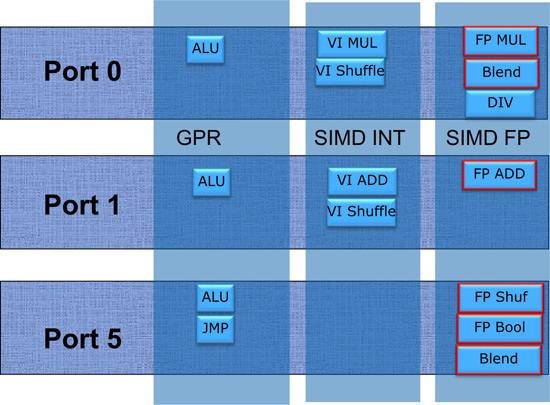 从Nehalem开始的微架构包含了3个运算端口:0、1和5,每个运算端口分为三个功能区域:ALU整数、SIMD INT、SIMD FP,分别执行整数和逻辑运算、SIMD整数和SIMD浮点运算,操作的是32/64位GPR通用寄存器和128位的XMM寄存器。在每一个时钟周期,每个运算端口可以分发一个uop,这个uop可以是三种运算中任意的一种。不同的运算区域可以同时运作,例如在浮点运算进行长耗时计算的时候,仍然使用ALU单元进行通常的整数和逻辑运算。基于执行单元的流水化设计,尽管一些运算耗时比较长,然而每个时钟周期都可以流入新的指令,因此吞吐量也能够得到保证。例外的是除法单元,线路复杂、长耗时并且目前仍未能全流水化。不同运算区域之间的数据传递需要1~2个时钟周期。
 除了AVX带来的性能增强之外,Sandy Bridge还继续增强了AES指令集的性能,提升其吞吐量,此外,SHLD(移位)指令、ADC(进位加)指令和Multiply(64位乘数128位积)运算的性能也都得到了提升,SHLD指令性能提升增强了SHA-1计算能力,ADC吞吐量翻倍提升了大数值运算能力,而最后者提升了现有RSA程序25%的性能。
精简X86指令集
除了明显提升浮点运算性能之外,AVX指令集还是对X86指令集的一个精简。我们知道由于是不定长的CISC指令集,X86指令集可以很容易地进行扩展,每一代处理器都像不要钱似的增加扩展指令集,然而目前的这种通过增加各种Prefix前缀来扩展指令集的方式已经达到了其极限,并且这种方式导致的指令集复杂化和长度增加,导致了执行文件的臃肿和解码器单元的复杂化和低效化。如笔者说过的那样,解码器一直是X86处理器的一个瓶颈所在。
AVX指令集带来了新的操作码编码方式,这种编码方式叫做VEX(Vector Extension),其动机就是压缩各式各样的Prefix前缀,集中到一个比较固定的字段中,缩短指令长度,降低无谓的代码冗余,并且也降低了对解码器的压力,实乃一举多得。VEX编码方式使用了两种VEX Prefix,除了一个字节的字头之外,分别具有1到2个字节的Payload(负载),在这个Payload里面就包括了所有的Prefix的内容,达到了精简指令集的目的。
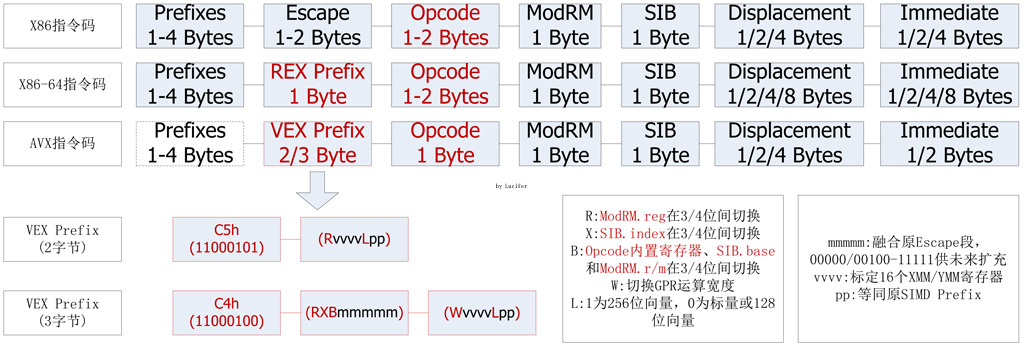 这两种VEX前缀分别是以C5h开头的2字节Prefix和C4h开头的3字节Prefix,前者主要用于包含传统的128位SIMD整数、SIMD浮点运算,后者则主要用来进行新的256位AVX运算以及未来可使用的更多指令集扩展。
VEX前缀包含了X86-64指令使用的REX前缀以及原SSE指令使用的前缀,还融合了普通操作码带有的Escape字段,从某种意义上来说,VEX让CISC的X86指令集往RISC精简指令集靠近了一点,当然,CISC易于扩充、支持复杂灵活的寻址方式的特性依然无损。
如图所示,VEX前缀的RXBW字段包含了原REX前缀的所有功能,pp字段包含了原SIMD指令的所有前缀,在三字节C4h格式的VEX前缀中,mmmmm字段包含了原Escape字段并提供了极大的扩展空间。X86指令总长度不大于15个字节的规定仍然维持不变。
强化X86指令集
基于历史上X86处理器缺乏存储单元的原因,X86指令集属于双操作数的破坏性指令集,例如,指令add ax, bx包含了ax和bx两个操作数,作用是将寄存器ax和bx的数值相加,并保存到寄存器ax当中去,计算结束后,源操作数ax的内容就被计算结果“摧毁”了。如果源操作数的内容在其他运算中还需要用到的话,那么你通常需要保存到堆栈中去,或者保存到主内存中去。实际上X86指令集采用的就是时间换空间的方法。
在传统的仅具有8个通用寄存器的X86处理器上,这种编码方式的使用实属没有办法,同时期具有更多通用寄存器的RISC处理器都采用的是多操作数的非破坏性句法。在应用了Register Renaming寄存器重命名技术之后,X86处理器事实上也具有了很多的寄存器可供使用,如Sandy Bridge内部每个线程具有160个64位整数寄存器,和144个256位浮点寄存器,因此Intel就动起了新的念头,SandyBridge带来的AVX指令集提供了新的3~4操作数的非破坏性句法,在某种程度上,这弥补了X86指令集的体系缺陷。
例如,要实现xmm10 = xmm9 + xmm1,传统X86处理器需要两条指令:
movapps xmm10, xmm9
addpd xmm10, xmm1
在应用AVX指令集新的3操作数格式之后,只需要一条指令就能完成这个功能:
vaddpd xmm10, xmm9, xmm1
而使用4操作数指令的话,下面三条指令可以直接简化为一条:
movaps xmm0, xmm4
movaps xmm1, xmm2
blendvps xmm1, m128
变为:
vblendvps xmm1, xmm2, m128, xmm4
显然,新的指令操作数明显降低了指令的数量,处理器吞吐量得到了提升,代码运行更快速,同时能耗也降低了。
除了对指令集体系的增强之外,AVX指令集还强化了访存不对齐时的性能。传统的指令集当进行不对齐内存访问(unaligned memory access)的时候会需要较长的时钟周期,甚至会有惩罚性延时,极大地降低速度。而在AVX指令集中,各种运算和访存指令现在降低了访存不对齐的延迟损失,在某些情况下甚至能达到和对齐访问一致的性能,显得更加灵活。
X86指令集:不断进化
CISC指令集的思想就是用复杂的硬件来完成尽可能多的工作,RISC则是使用尽量少的指令并通过复杂的程序来完成同样的功能。每一代的X86指令集,都会对不同的应用增加新的指令集,这些指令集能高效地处理对应的应用,例如,上一代Westmere处理器的AES-NI就对加密运算具有非凡的加速比。同样,在AVX指令中也增加了不少浮点运算指令,提升了多种运算的性能。
Sandy Bridge新加入的AVX指令集让X86从128位提升到256位向量运算,大幅度提升了性能,此外,AVX精简了X86指令集的设计,并弥补了破坏性句法的体系缺陷,可以说是一个非常重要的改进。需要注意的是,AVX指令集带来了新的处理器状态和更宽的寄存器宽度,因此需要操作系统的支持才能正常运作,如,Linux Kernel 2.6.30以及Windows 7/Server 2008 R2 SP1版本才能支持。关于Sandy Bridge的微架构就介绍到这里,下回笔者将介绍Sandy Bridge的架构,这部分的变化也非常大,请等继续分解。
| |
 (2个打分, 平均:5.00 / 5) (2个打分, 平均:5.00 / 5) |

雁过留声
“AVX高级矢量扩展指令集——英特尔Sandy Bridge 处理器分析测试之三”有11个回复
is it like a vliw chip with simd ?
不是,只是一个标准的cisc x86,只是simd部分格式和以前的不一样
“AVX指令集带来了新的处理器状态和更宽的寄存器宽度,因此需要操作系统的支持才能正常运作”
如何理解?新的指令通过OS扩充进了ISA?普通用户(编译器)仍旧不能生成AVX指令?
这玩意比较像power的AltiVec
不同的线程使用到的avx宽度可以不同,有些线程可能就没使用avx而用的是sse,不同的线程之间的切换需要保护现场,需要操作系统的支持
avx代码只能在支持的操作系统上运行
altivec是个vector simd扩展指令集,从这点上来说,和sse之类的也没什么分别,重点是avx和之前的sse不同,和cisc x86传统的架构也不同。avx所以和altivec有相似的地方但是这么说没什么意义
我的意思是用户代码编译完后可否生成avx指令。
还是这些指令是通过操作系统API扩充进用户代码的?
Any compiler that can perform auto-vectorization can generate the AVX instructions.
Basically there are three ways to use the AVX instructions.
1. Inline assembly
2. Intrinsics
3. Compiler auto-vectorization
There is nothing to do with OS in using AVX except the OS has to save/restore the AVX registers during context switch, which the popular OS has already supported.
Compiler auto-vectorization
这个比较神。
另,按intel的习惯。AVX应该也会吸收进IA的架构中继承下去吧。
没有avx也可以实现自动向量化……这是编译器的事情。avx应该是一个新的基础指令集架构
AVX is a simple SSE extension, from 128bits to 256bits. That’s it!
自动向量化没那么神,靠谱的优化方法还是6楼提到的前两个。
上两个星期做完了avx 指令的 memcpy, aligned/unaligned 条件下都达到了cpu 理论值 16bytes/cycle,比为nhm 做的版本(他已经进入glibc) 非对齐 并且在小于 一级cache 的情况下 快 40% 大字节(大于 8M)的情况下 快了 20%。