




二层多路径环境中的网关负载
作者 tree | 2011-04-19 07:30 | 类型 行业动感 | 84条用户评论 »
|
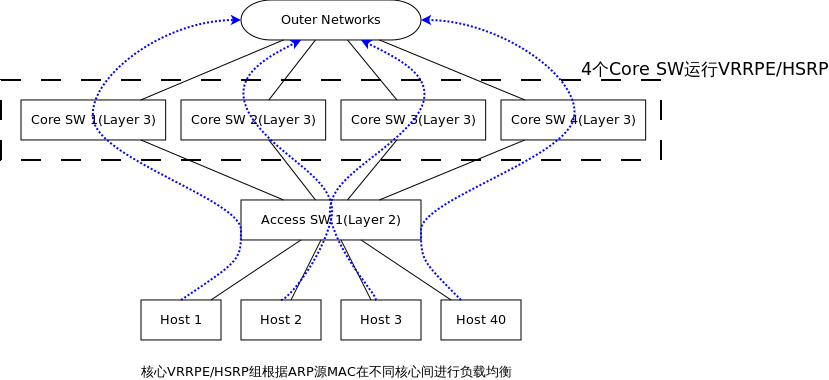
在目前的数据中心解决方案中,二层多路径应该是一个大趋势,它可以消除环路,同时还能提供多路径负载。 但二层多路径中网关的设置在目前的方案中却提的比较少,收集了一些信息,目前的解决方案主要: 第一种方案,TRILL/SPB + VRRPE/HSRP
在这张图中看不出来存在环路,这是因为只画了一台接入层交换机,如果存在N台接入层交换机,Core之间就存在二层环路了,TRILL/SPB可以使任何一个接入层交换机到4个Core的链路都处于转发状态,4个Core之间可以运行VRRPE/HSRP,使4台Core都可以转发,VRRPE/HSRP的负载均衡模式是基于ARP应答: 1. 如Host 1请求GW的ARP,应答Core 1 MAC,依次类推,每个Host都有属于自己的1个GW访问外部网络 2. 当Core 2连接Outer Network断开,会降低其权重,通知其余同伴自己失去了能力,这时同伴首领如Core 1可以立即发送一个ARP刷新所有Host上GW ARP,將发往Core 2的流量引向其余Core 第二种方案,不使用TRILL/SPB,使用IRF/VSS等N->1虚拟化技术,这是目前在TRILL/SPB标准尚未成熟的解决方案:
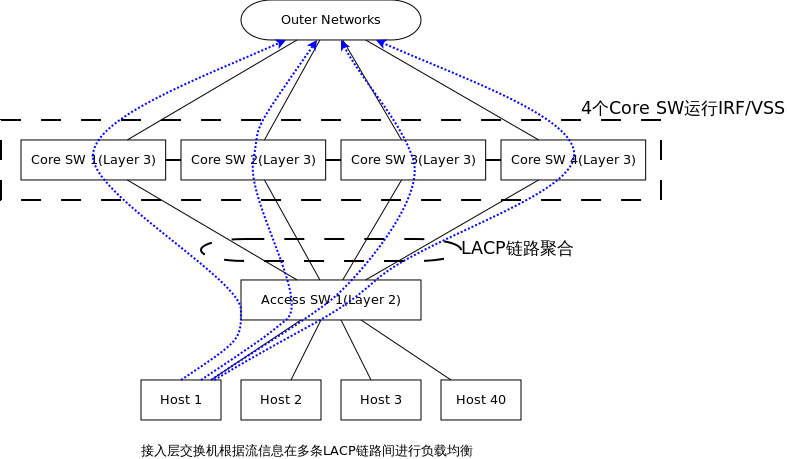
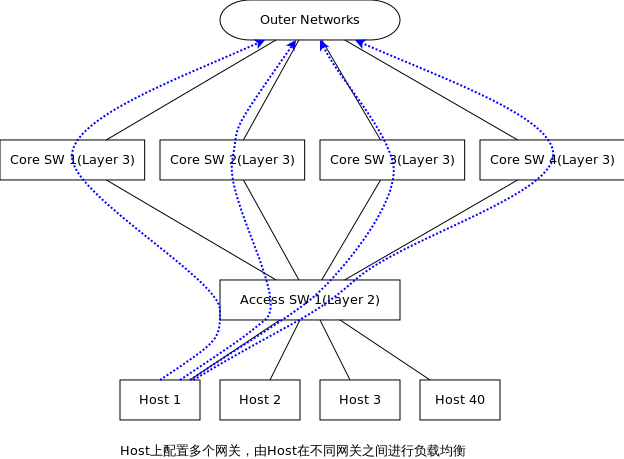
这种方式的特点: 1. 多个Core通过专属互联,运行私有协议虚拟化成1台物理设备,这种虚拟化和服务器的1->N虚拟化正好相反 2. 当Core 1连接Outer Networks歇B,由于4个Core已经虚拟成1台设备,所以流量会自动切换到 3. 接入层交换机上联的4个Core的链路就变成连接到1台物理设备,所有接入层交换机和虚拟物理设备之间可以运行LACP进行链路聚合,在逻辑连接上消除了环路隐患,这种方案中Host的GW也是1台虚拟化的设备,负载均衡在接入层交换机和虚拟核心的LACP链路上,负载均衡要素可以是5元组、7元组等等,负载均衡的灵活性上要比第一种方案要好,但IRF/VSS都是私有化技术,并不被业界所喜欢。 第三种方案是在第一种方案基础上,抛弃VRRPE/HSRP,而是在Host上配置多个GW,也就是说把3层负载均衡交给Host来做:
1. Host上分别配置4个默认GW,分别是Core 1~4的IP地址,就和路由器有4条默认路由的ECMP情况一致,4条路由都处于激活状态,Host可以根据Application在4个GW之间负载均衡,也可以指定其余顺序使用策略,负载灵活性上要比前2种方案都高。这种方式对操作系统也是蛮大的,但基于Linux的Server数量多,又可以改造,应该也是可行的方案。 2. 问题是当Core 1外联Outer Network歇B,怎么样切换到其余Core上,Core之间差不多完全独立,所以只能是Core 1告诉Host失去能力了,找其它Core吧,那么当Core 1又恢复了怎么办?Core 1再通知Host?前一个问题可以通过”信任制ICMP destination unreachable-route”来搞定,第二种情况就只能单独开发一套系统了,差不多是一种GW与Host之间的轻量级路由协议,这估计是这个方案的最大挑战。 | |
  (1个打分, 平均:3.00 / 5) (1个打分, 平均:3.00 / 5) |
雁过留声
“二层多路径环境中的网关负载”有84个回复
一般是两个方案:
1、L3设备和主机都始能动态路由,靠路由收敛,可能是秒级。
2、靠OAM协议及其与接口状态、静态路由等的联动,包括EHT OAM,BFD等,收敛时间看设备上OAM实现的性能,可以达到100ms level
三个方案的差别还有负载均衡的颗粒度,VRRPE/HSRP使用ARP做负载的颗粒度无疑是最粗的,VRRPE/HSRP使用BFD等联动技术可以使路由发生切换,但通告给主机的ARP更新未必有那么快,因此主机在一定时间内可能还是会选择上行路由已经歇B的核心作为网关。
有个小疑问请教,既然是二层多路径,为何在Core switch上还启用了L3功能呢?图中表达的是每个Core switch上都启用L3,分别接各种的Internet出口。
是否会有另一种部署情况,Core Switch仍然工作在2层,由外部设备来实现L3及NAT功能。Juniper的Qfabric应该属于后面这种部署吧。
改host的方案实施起来有点麻烦;N->1的方案scale是个问题,但是不太明白为什么私有协议会是个问题,一般部署会上多家的设备吗?好像每一层都是一家的设备,不会多家一起用,出问题也不好找啊;至于方案1,路由收敛速度是秒级,那和RSTP的收敛速度差不多啊,好处是有多条路径,这就是STP树不能做到的。
to floor 3
无论哪种方案,IDC服务器最终还是要和外部网络互联,也就是说服务器必须要有L3的网关,网关部署还涉及网关的冗余,二层多路径的冗余往往就是负载均衡,QFabric也同样面临这个ISSUE,外部设备部署在哪,1台还是2台,估计你会选择2台,那2台的话,流量如何在2台之间进行负载呢?
to floor 4
N->1方案的确很不错,不过在当前开放的大环境下,客户也是比较青睐开放的东西,不被绑架。这和Linux Kernel流行于各个互联网公司是类似的道理。
将IRF/VSS扩展到两台以上有难度,这种机制本身是一个依赖心跳线的系统级别虚拟化,当规模扩展后,任意两点之间都要建立full mesh联系,实现起来很麻烦。听说IRF已经支持多点,不知道实际情况如何?
to tree 的确,二层多路径的确是个大趋势。个人的一些看法:
1、相同的应用才会处于一个二层中。
2、不同的应用还是通过不同的VLAN区分开。
3、交换机只构建内部的Fabric
4、VLAN间的安全防护和NAT交给外围设备来处理,比如防火墙。则只需要防火墙能根据自己的能力处理相应的VLAN流量即可,即假设N个防火墙处理M个VLAN。由于M远大于N,则防火墙上处理的VLAN数至少再10个以上。如果某个VLAN上的流量徒增,则只需要将这台防火墙的部分VLAN切换到其它防火墙处理即可。
结论:二层多路径仅适合二层Fabric内部的多路径。
外部流量的负载均衡,需要依靠外围设备,别期望一项技术解决所有的问题。
STP收敛时间看突破复杂度和网络半径,简单情况甚至可以达到几百毫秒,路由协议使用fast convergence,也能达到这个级别,但此时的网络规模和复杂度要远大于STP达到这个级别的情况
个人支持a123的观点4,三层设备应该放到核心层交换机外面来做。多台三层网关集中部署,甚至可以把路由器/FW一类的网关设备集中在一起单独做个pod。
每个三层网关都针对不同的1个到几个VLAN,两两一组互为备份,这可以极大的简化网络部署的复杂性,也可以降低网关的负载。
甚至可以更极端一点,干脆用多台LB设备作为三层网关,给不同的路由器做负载分担算了。
通过NAT同样可以做到负载均衡,没那么费劲。也不需要用那么多交换机。
To ABC:
用NAT当然也可以做,但是NAT设备自身就成为故障点或者性能瓶颈。LB设备还是有些自身的均衡策略可以用的。
使用NAT的场景也只能是对外部网络,许多IDC内部互联就没必要使用NAT了。
多台LB作网关的话,这些LB也是通过私有的技术虚拟成一台设备还是继续采用VRRPE的方式,这也回到多网关部署问题。
为什么不描述一下CSS集群技术呢?与VSS和IRF走的是不同的路线。
VSS实现的效果与IRF近似。不过H3C也是比较NB,把3COM用于中端交换机堆叠的技术搞出了个高端应用的IRF2+来。
记得03年做65交换机的老尤在跟我聊天的时候,还对3com的东西不懈一顾呢:“鬼知道他们那些私有协议规定的网元间跑的报文是什么东西~”
TO libing
这个是正解。IRF如果多台设备,心跳链接和状态保持是很大的问题。本质上不管是IRF还是VSS,如果扩展到多台设备,都是利用私有协议组成了一个小网络,同样需要连、找、发。没什么可神秘的。
不同意把三层交换机当L2使用。
L3和ROUTER干不同的事情,局域网内部VLAN间的互访流量,应该充分利用L3的快速转发能力。
to 15楼兄弟。
可是一般情况下,局域网内部VLAN间的互换都需要防火墙来做安全隔离啊,这样就利用不上L3的快速转发能力了哦。
在加上安全防护的需求后,L3和router也就一样了。所以虚拟数据中心搞个大二层就可以了,没有必要用L3交换机。
大家观点相差比较大啊。二层多路径转发看起来很美。H3C的IRF2貌似据传支持4台设备了。感觉N->1的这种方式逻辑上看起来更简洁些,更有利于传统的网络管理人员思路平滑过渡。至于不被同一家厂家绑架,这个情况用户和业界看法估计不会太一致。
如果现在就有两个大二层IDC互访的需求呢,我其实关注的是这个问题,如果不怎么互访,没有性能的要求,用防火墙、LB都没有问题,但在高性能VLAN互访的时候,现在就是有点小疑问。
TO 16楼的兄弟
你的观点与我是一致的。对于超级数据中心来说,考虑到各类业务的隔离,确实在核心交换机与汇聚交换机之间需要增加一层安全防护,这个时候网关就在FW上了。而对于一些中心机房来说,中间这层防护层可要可不要,这个时候就是L3发挥作用的时候了。
我也认为,未来的数据中心,根本就没有必要用L3。前两天还遇到一个项目,客户的老观点太根深蒂固了。一定要用H3C推荐的L3内置FW的方案,原因在于不希望将FW部署在L3与汇聚交换机之间,而如果要做安全域管理,VLAN是要透传到L3上面的FW进行终结的。而H3C宣传的通过FW内置,把L3变层万兆墙了,倒是挺迎合客户胃口的。
改天把我对H3C L3内置各类模块的分析放上来,吼吼。
TO 17楼的兄弟
N年前H3C的IRF还叫堆叠技术的时候,白皮书里已经宣称支持8个(也有可能是16个或24个,时间太长了记不住了)网元咯。
08年的时候,在北京跟H3C国内的一大佬,还有以前做技术的几个同事吃饭,聊到了VSS和IRF,我笑称IRF太土了,还堆叠那,看看VSS,和IRF有啥区别,人家叫虚拟化,多时髦?没想到过了不长时间,就看到IRF2+的资料了。我还暗自纳闷那,是我提醒的结果?嘿嘿
看来我得画一个新图,让大家知道这个是考虑高性能(比如80G以上带宽)Inter IDC三层互联问题探讨的。
FW插卡的吞吐量只有5G,用不了的。
这个讨论用的拓扑图本身就是有问题的,为何中央是四个核心设备 ?为了冗余,两个就够了;为了核心层面的 scale-out ?那么你就要考虑超过4台的情况;当access SW 上行超过两个核心时,access SW们和 Core SW们 应该运行一种协议,来了解网络的拓扑 (至于为什么,相比搞过VSS/IRF-X/CSS的群众应该知道), 这个时候 TRILL或是 L3@Access就是需要考虑采用的技术方向了…
在很多情况下,Fabric Path和VSS不是一个层面的解决方案,Fabric Path应对的需求更大,提供的带宽更大,往往采用FabricPath的地方,就不适合用VSS来实现了。
网关的设计往往和具体业务相关,南北流量的大小与类型都影响了网关的数量和位置,最好还是具体问题具体分析。
这个问题其实就是Server上网关IP-MAC ARP表项上的负载问题:
1. Server上网关IP唯一,但不同Server上对该IP的MAC是不同的,VRRPE/HSRP就是如此,负载均衡和收敛都依赖于ARP
2. 所有Server上网关IP-MAC都是唯一和一致的,IRF/VSS上是如此,负载均衡和收敛依赖于LACP和IRF/VSS
3. 所有Server上有多个网关IP,每个IP对应MAC的ARP自然也是不同,负载均衡依赖于服务器调度,收敛依赖于网关和Server的交互,估计和ARP差不多
4. 如果使用STP,那么多个网关中只有1个处于转发状态,很浪费,所以通常是MSTP域+VRRP组合作方式实现,因为这种方式越来越不被认可,所以才会有前面3种方式的出线
二层网还是不能做得太大,否则会有问题。
比较好的办法是用类似肖容说的方法,就是当年的3Com Cisco的堆叠技术组一个跨switch的貌似物理上比较大,但是逻辑上比较小的2层网。
其实在园区网里二层还是三层,我觉得问题不大,但是在数据中心里,可能一个二层的网络会更好些。
其实应该是有办法让上层调用的时候不用考虑太多网络拓扑的问题。就认为只要扔出去包就能去。
其实3Com当时做那个4xxx的交换机的时候还是很有想法的。不过3Com有个问题是当时已经不会做路由了。所以推出很长时间都没有路由的功能出来。
H3C这个东西卡网站也能够看出来,所有什么FW、IPS等都是一个图片,再看“H3C OAA”。明白了吧,就是L3内部以太网接口把个多核处理器接上去了。
FW盒子什么性能,内置模块就是什么性能吧。
“改天把我对H3C L3内置各类模块的分析放上来,吼吼。”
27楼是正解,跟我的思路是一致的。我深入一步,是按照OAA的定义,区分模块的工作模式,然后再分析一下每种工作模式的数据流向。哈哈。敢问ZC是哪个公司的?不会是“我司”的吧?
华三/HP的同志们开始发力了
IRF2的虚拟系统并不需要fullmesh互联,一般有环形和链型两种拓扑,互联接口一般是跨接口板多借口互联,实现更高可靠性。IRF2技术只对虚拟组的设备有要求,对上下左右互联设备没有任何要求,不存在绑定用户的问题。目前可以做到4台核心设备的虚拟化,低端接入设备可以最多10台虚拟化。
数据中心的大二层网络需求目前看来主要有两个需求驱动:一个是虚拟机vmotion无缝迁移的需要,迁移前后由于物理位置变化,为了保证业务不中断需要在一个二层网络中迁移。另一个需求是服务器集群的需求,服务器集群一般都需要二层网络传送心跳报文的。
目前在数据中心实现跨DC的大二层互联,各运营商都在做这方面的实验,不知腾讯的MAN有没有做到二层DCI互联?
EC2这次当机,影响挺大的,不过馊了下这几年EC2down机每年都有,看来跨DC的二层互联和备份真的非常重要啊!受影响的都是一些新兴公司,可能没有购买跨DC的备份服务。
看来H3C的兄弟们出来了。不管IRF2+组网模式是全链接、星形或是环状,只是在其区域内运行的私有协议而已,还是那句话,必须连找发,肯定会有各类表项的同步,肯定要有各类状态保持的机制,即使你使用万兆接口互联也一定会存在区域内的带宽问题,对么?
我还是认为CSS的物理级扩展方式要优于VSS和IRF2+的方式。
此外,虚拟机的迁移更多是需要跨VLAN的,并非是在一个VLAN内的迁移(IDC的设计,惯例是将一类应用划归在一个VLAN里对么?),也就是跨越了二层网络的迁移。
CSS就是一个吹牛皮的东西,到现在也没有实际的应用案例,好像还没出来吧。看来你还没想明白这个东东的精髓,呵呵,互联带宽是不是越高越好呢?不是那么回事。
为什么VSS不能>2?
VSS不是任何一个网络协议栈的一部分,它即没有修改OSPF,也没有成为Portchannel的一部分,VSS只是跑在这些协议栈之外的一个保证高可靠性的东西。
VSS的命根子是双机之间的心跳连接,但任何一个网络协议都不知道这个心跳线的存在。因此,一旦心跳出现问题,要有一个非常高效的机制保证这个问题不会影响到网络协议的运行,并能做到快速回复,这是非常不容易的,如果再扩展到4台设备的规模,难度会更大,cisco折腾了这么多年,最终还是在大于两台设备的环境中选择了fabricpath的路子,使用一个“路由协议”来完成这个任务。
how about IRF2?
IRF2的实现细节我不清楚,但我大胆地猜测其原理同VSS不会差得太远,甚至是更简单的集群技术,那么它在扩张到多机时必然面临同VSS一样的问题。
光看厂家白皮书没用,IRF2上实际跑OSPF的情况如何,最好有H3C的童鞋来说说。
另外,IRF2的环形联接也许能跑起来,但在单台设备出现问题的时候,信息的传递还要通过二道手传播,这种拓扑是不是能够做到快速恢复,我也表示怀疑。
如果IRF2能保证在这几个方面确实都没问题,用起来杠杠的,那我只能说H3C现在已经灰常灰常牛B了!
vss与irf主机数量不能太多的瓶颈在引擎性能。
To zeroflag
引擎性能是个很笼统的概念。
我认为VSS本身的极限是客观存在的,否则cisco在新一代引擎上不会不考虑采用VSS来扩展。
to libing:
关于VSS实现的细节不是很清楚,能不能详细解释一下,你上面说的不是很明白。VSS本身的极限究竟在哪里?需要同步的表项过多?算法本身在超过两台以上的环境下不能很好的工作(好比RIP算法在超过16台以上路由器上就不能很好的工作一样)?还是别的什么原因?
H3的IRF2受限于引擎的性能瓶颈是可以很简单的看出来的。一是同样的协议,在低端设备(如58)上就可以支持更多的台数。二是,新出的10500可以支持到四台。这说明,要么降低整个虚拟系统的负载,要么采用更高性能的引擎,都可以扩展到更多数量的设备上。不过对IRF2的实现细节也不是非常了解,不知道算法本身是不是也有上限的问题。
IRF/VSS这样的系统在OS升级环境中会受到OS一致性的挑战
TO:33楼的兄弟
不管CSS是否已经有商用案例了(不过据说93的CSS是来自于NE5000E的集群技术,NE5000E至少是开过背靠背的集群局点的),这种物理级扩展背板的思路,要比利用协议进行集群有更多的优势。这与互联网的带宽是有本质的区别的。互联网的带宽当然是越大越好,只不过利用率的提升还需要在管理上做更多的工作。CSS的具体的内容我也记得不是很清楚的,好像是“光背板互连方式实现多机框集群”。这怎么能和互联网带宽进行类比呢?
能把“光背板互联实现集群”的模式类比互联网带宽,不知道这个“精髓”是怎么被上面的兄弟掌握的。
PS:千万别误会,我可不是华为的托,我也不喜欢现在的华为数通。就事论事儿哈~~
IRF来自3COM的XRN,这个东西很早就有了。IRF有自己的状态机,保证区域内部的稳定。对外做了很多花里胡哨的东西,比如说不管数据报文经过区域内部多少个设备,路由表现上,就是一跳。内部应该是用了类似于路由协议的机制,呵呵,细节在技术白皮书上是不会体现的。还是老尤那句话:鬼知道内部跑的数据流是什么,鬼知道它们的开销有多大!
TO 37楼的兄弟
我感觉还有协议开销的问题,58等低端设备上能吹NB,是因为在这个层面上基本上没有客户会傻到用IRF等堆叠技术攒一台高端设备的。但75以上就不一样了,在目前的技术条件下,想提高稳定性,又要不浪费带宽,还要开局维护简单,核心层采用集群技术是一个不错的选择,这个时候,如果NB吹过了,真的搞出多台来,只要跨设备的流量一大,肯定出现延迟、丢包等问题,嘿嘿。H3C的兄弟们还是很聪明的。
to 肖容:
您说的有道理,我私下也怀疑IRF2在不同的设备上的实现有很大的差别。58上的实现说不定比高端设备简单很多,75E和95E的实现说不定细节上也不一样。最起码到现在为止,没看到跨型号混合做IRF2(比如一台75E和一台95E做IRF2)的案例。
这种私有协议的一个坏处也是好处的地方是,屏蔽了所有实现的细节。厂家实现起来相对会轻松很多,大差不差的也能用,只要自己的工程师严格按照配置指导书做一般不会出问题。
两位仁兄是不是经常和IRF2打交道啊?
to 44楼
没有没有,多年前看过他们的技术白皮书,也跟H3C以前的兄弟们聊过(呵呵,我没在H3C呆过),所以印象比较深而已。
To 肖容
麻烦你仔细看看清楚再喷,我说的是互联带宽,和互联网带宽有本质区别! 太让人惊讶,还有这么激动的人呀,范不着这么激动吧,你激动不激动也没人多看你几眼!
关于这个技术的讨论就此打住!
呵呵
to Andyfly
这个是我没看清楚。但在光背板互联的情况下,理论上带宽越大,对于跨设备的流量越有利。这有什么问题么?没啥好激动的,只是由于看岔了一个字,意思理解上确实出现了问题,还以为你老人家”精髓”掌握得通通透透呢。
还有,你咋看出来我想让人多看几眼的?我自己咋都不知道?这个“精髓”你也掌握了?
嗯,知错就改,还算不错,呵呵。
对于一个设计合理的虚拟系统来说,他的流量应该均匀的分布在不同的机框上,所以跨框的大流量转发只有在系统出现异常的情况下才会发生,也就是说正常转发情况下,互联链路的流量不大的。
IRF2的精髓是简化二层网络的结构,实现快速的故障收敛,提高链路利用率。如果说的更直接一点就是,它在保证节点冗余和链路冗余的情况下,有效的避免二层环路的发生,STP的弊端有目共睹,逐步被冷落,跨设备的链路聚合技术,多虚一的横向整合,转发表项的全局同步是IRF2对网络技术的革命性贡献!!
看来这个帖子只有咱们俩人关注了。咱们就聊聊吧。
你的发言有一个前提,就是设计合理的虚拟系统,流量均匀分布在不同机框。
试想,你都虚拟成一台设备了,完全可当一台设备使用,一落到流量模型上,怎么还在提多台设备呢?
还有,你这个前提是不成立的,虚拟化后,跨设备的流量会很多,为什么?用了这种技术,一定会做跨设备的链路聚合,没人会傻到在一台设备上甚至一块单板上进行聚合。聚合都跨设备了,流量怎么能均匀的分布在不同机框内?除非IRF NB到聚合端口1要到聚合端口2的流量,从A设备上走的流量只从A设备转出去。不知道我是否表述清楚了。即使真做到了,那么IRF设备还得维护另外一张复杂的表,这个表也得全局同步。
IRF的思想很好,它的问题在前面我和其他几位朋友也讲清楚了,在这里就不累述了。
我只是感觉,要实现你所说的“简化二层网络的结构,实现快速的故障收敛,提高链路利用率”,最简单的就是物理级的扩展就可以了,也就是CSS的方式,呵呵。不知道是否有理论上和技术上的瑕疵。如果还是“没有商用”之类的泛泛之谈,就不用讨论了。
还有,IRF也并非原创,源自XRN是不争的事实,看看华为的istack(不知道是否拼错了),跟IRF是不是一样的?:)呵呵。
IRF(XRN)的问题与它的成就都是并存的,设备前的交互问题是绝对的死结。
Andyfly朋友,你是H3C研发的还是市场的?最后一段话特别像市场宣传口径。我对IRF2+也非常好奇,03年就有兄弟非常激动的跟我聊XRN了,04年做65的老尤也和我聊过,但对细节都不清楚,光看技术白皮书也看不出来什么,呵呵。如果你是研发的,咱们继续深入讨论一下?
举个例子吧
A设备和B设备之间运行IRF2+。A设备上有端口A1,A2,A3,A4……,B设备上有端口B1、B2、B3、B4……,我们极端一点,该系统上的聚合端口为J1(A1+B1),J2(A2+B2),J3(A3+B3),J4(A4+B4),分别L2交换机S1、S2、S3、S4。
你所说的流量均匀分布,就是说A+B系统要做到,J1去J2的流量,从A1进来的,就要转发到A2上,B1进来的就要转发到B2上,以此类推。802.3ad可没这项功能吧?IRF(或者应该说是XRN)是对协议进行了扩展,增加了一个TLV域,也只是侦测多活使用的(MAD),可没对上述表述做任何的工作。
一个简单的例子,所以说,你说的流量均匀分布,在IRF或VSS系统是不成立的。
对牛弹琴!
to Andyfly:
你这个风格可不好,拿出点实在的分析出来,别一副高高在上,NB哄哄的样子。故作高深谁都会,沼泽地里的一洼泥水谁知道下面是吃人的深潭还是连鞋都湿不了的浅坑。
从你前面的发言来看,内容基本没超出过IRF2技术白皮书的范畴,对实际的实现基本没有涉及。比如肖容提到的,采用跨设备链路聚合,如果处理等价链路?非对称连接的情况下怎么办?
你前面提到设备互联的带宽不需要很大,是在什么情况下有效?比如,我就认为非对称连接的时候就会产生大量的跨设备流量。
请正面回答问题,而不要摆出高高在上的姿态。就算我们的问题很白痴,也请您老有教无类,可以吗?
Andyfly,你就是那个“牛”吧?“小母牛”?
看来你不过就是H3C市场的后生而已,整天就把一指禅、宣传彩页、技术白皮书一背,就NB哄哄的以为老子天下第一了。 IRF2还革命性的贡献呢,你跟H3C研发的那帮老家伙们说这话,连他们的大牙都得笑掉了。
我要是做研发或是专门做技术的,跟你这儿辩论是欺负你。我也不是研发的,我是市场的,只不过不在H3C也不在HW数通而已。
TO zeroflag,兄弟,不用理那个“小母牛”了,我也是脑袋短路了,怎么跟这种SB解释这么多?SB年年有,今年突然又冒出一个Andyfly而已。
不准备对anyfly这种小母牛弹琴了。背了点儿技术白皮书、一指禅什么的,从来不带思考的,就自以为老子天下第一了。什么分析都没有,就扯什么革命性的贡献。anyfly这种极品如果在H3C的话,对其他厂家来说,也是“革命性”的贡献。
上个周末还在看白皮书,里面原理性的东西实在有限。肖容、Zeroflag能够从白皮书挖出那么多东西,非常令人敬佩,估计华三许多潜水员们看了之后,会去改进他们的白皮书的。
to tree,其实IRF的技术白皮书写的还是很不错的,分成了好多部分,共同来阐述理念。就是看不上现在H3C的那些市场的产品经理,大部分不求甚解,就知道背书。2年前面试过他们一个做存储的,让解释一下IP SAN与FC SAN的优缺点,上来就跟我介绍IP网络的发展趋势,忽悠万兆带宽,一点儿技术含量的没有。
再罗嗦两句。不管是VSS还是IRF,既然你号称虚拟化成一台设备,一台核心交换机,核心交换机最基本的要求是什么?无阻塞转发,全线速,对么?你设备之间就算是10G的链路的链接,也就能满足10G的设备间全线速数据转发(1个10G端口、10个GE端口而已),还不算你的协议开销。看明白了么,“觉得互联带宽不是越大越好”的“小母牛”,“革命性”?
以华三/华为的风格,内部员工不会来披露实现细节,甚至内部也不太可能拿到。肖容提到的问题,他们肯定是会遇到的,甚至实现方式可能你想的那样。
我个人觉得,VSS、irf间的,用于系统本身控制方面(如协议、心跳、同步、路由同步……)的流量,不会很大(小于1G吧?)。
因此,主要问题是,数据流量跨机框的转发。
理论上来说,群集的两个机箱间的数据通道,应该要达到同一个机箱内的效果。
一个交换机机箱内,单板与单板之间,要达到线速;跨机箱后,单板与单板之间,也要达到线速。
而且,这个还是全连接的线速。(任意单板互联都是线速)。
当然,这是理论的。实际应用中,个人认为,跨机箱是不可能需要这么高的带宽的。
看一下,现在很多园区网,出口也就1G吧,如果内部真的有几百G,甚至几TB的流量,出口早就爆了~~
因此,群集跨机框的流量,应该不会很多。
以上考虑,分析,主要基于以下2点:
1、HW的NE5000E群集,管理板的互联,用的是1000M端口。
2、RJ做了一个S8600的群集VSU(有没有应用不知),只是/只能用2个万兆的端口互联,也就是机框间只有20G带宽。这样也敢用的话,IRF、VSS还有什么不放心?
更多是在最佳实践上面做文章,并没有太依赖与互联高带宽,互联带宽通常倒是用在应急。
59楼的兄弟,我很久没做过数通了,但好像NE5000E的管理板之间的连接不是1000M的端口,93交换机上宣传的互联最大带宽好像能到250G。
还有,既然在核心层面宣传的虚拟化,你就应该达到一台设备的水平,用到跨设备的链路聚合,跨设备的流量大就是不可避免的。
肖兄:
NE5000E的管理板之间的连接是1000M的端口。我也是昨天才看的手册。。。
93交换机上宣传的互联最大带宽能到256G(双向)。
还有,既然在核心层面宣传的虚拟化,你就应该达到一台设备的水平,用到跨设备的链路聚合,跨设备的流量大就是不可避免的。
——我也是这样认为。但这是属于理论,讨论。
——实际上应用,可以(可能)不需要这么高带宽。。。
兄弟,你说的是管理平面的连接,用的是超五类线。
框间数据转发平面的连接是光纤(72芯光纤,规格有10m、20m和50m三种,理论上最长可以到300m)互连、每束光纤含72芯3.125G光纤,32路入32路出8芯保留,每束光纤最高传输能力可达225G。
去看这个网址吧:http://support.huawei.com/support/pages/kbcenter/view/product.do?actionFlag=searchManualContents&web_doc_id=SC0000535313&material_type=ProductManual&part_no=10032
介绍的非常清楚。
兄弟,如果我是客户的话,厂家跟我来忽悠什么IRF、CSS之类的,我肯定会问设备间的互联是不是瓶颈?忽悠还是要想的更全面些~~嘿嘿,讨论讨论。
to 肖容:
如果是我推销irf的话,我会说应该采用对称连接来解决问题互联带宽问题,这样的设计才是最优的。
另:貌似S125可以最大8万兆链路捆绑做IRF2,这条不确定。
IRF,VSS,CSS都是类似虚拟化堆叠的应用,没有必要支持无阻塞满带宽,那个成本太高了,而且实际有多少客户需要呢?无阻塞集群不适合白菜价格的企业网交换机市场,数据中心倒是可以考虑,象J的Qfabric,C的N3000 Matrix,Force10的Z9000。而NE5000E采用的是集群方案,数据平面的高密光阵列互连,但也没有做到无阻塞吧,好像CCC的收敛比是2:1的。
C,J,Z的集群倒是满带宽的,不知H是怎么考虑的,但是我觉的H比较务实,所以才会选择2:1的收敛比。另外H3C的IRF的用的是客户口接口,理论上可以自由扩展。而H的CSS用的是专用的接口,直接挂在交换网上,更像是背靠背的集群的思路。以上为个人观点,欢迎拍砖。
to 64楼的兄弟,还是那句话,不管什么情况,跨设备的链路聚合总会产生跨设备的流量的,请看我对“小母牛”的回复。(对于2台设备组成的IRF,没什么对称不对称的,下级设备都会双上行到两台设备进行链路捆绑的)。
to 65楼的兄弟,在没有把IRF忽悠的太NB的时候,我个人感觉你说的是靠谱的。毕竟企业网的流量不大。但你后面说的是有问题的,如果用客户端口,你没考虑到交换网的容量。如果真要做到无阻塞全交换,你要用一半的交换容量去互联,比如你用2台设备做IRF,实际上2台设备的交换容量仅相当于1台,又失去了虚拟化的意义了(你花了2台的钱,买到了一台设备的性能)。而H的NE5000E是在交换网的套片上预留了光背板扩展的交换平面的,呵呵。
讨论结束了???
To 爆粗口的傻X:
白皮书里有没有讲过“本地转发优先”呀
没事又过来扯了下蛋!前几天没时间上来看,没想到还在扯这个呀!
我也不是什么厂家的人,只不过在做这方面的工作,不要人身攻击。看来大家还是非常想了解细节的哈。
估计骂人的傻X是华为的吧!
这个讨论我不再参加了哈,不要人身攻击了哈!
再说了你不做研发你问那么多实现细节干屁呀。你知道怎么应用不就行了吗,H3C网站上多得是这方面的资料。
借楼主宝地引出一个问题:L2 MULTI-PATH 除了在数据中心外,在城域网里将有更大的应用场景?
NO
你丫就是找骂,活该骂你丫的。谁问你MD技术细节?你知道个P技术细节。白皮书里写什么本地优先了?就你这样的还研究呢?研究革命性贡献?你这样的极品真是对业界“革命性”的贡献!
本来大家就在弯曲里讨论问题,就事论事,就这SB在哪儿故作高深,扯宣传口径,还自以为伟光正,看这孙子发言,没有一点儿实际的东西,遇到提问就抓瞎了,理屈词穷的一句“对牛弹琴”就没影儿了,冲你丫这态度就该骂你。这傻逼回骂了后又来了句“不要人身攻击了哈!”,就跟一个小孩A打了另外一个小孩B,小孩B怒了反击了,小孩A吃不消了,打不过了,用了一个很缺心眼的手法,再占一下便宜,马上转换个笑脸说:“咱到此为止哈,不要人身攻击了哈!”你不是傻逼是啥?
好了,我道歉,我没啥文化,平时爱吃狗肉,吃多了,脾气就差。大伙别瞧不起我,你们可以往死里抽我。
肖容童鞋肝火太盛,要注意了
to tom,昨天回复的不知道怎样没有显示。Andyfly这种傻货是爷们就站出来堂堂正正的辩论,尽整些鬼魅的小伎俩。兄弟,你去看看前面的讨论,看看我骂人的前因后果。你想想,你用人类的方式交流,纯粹的讨论技术,就碰到这种Andyfly非人类的傻缺,你不抓狂么?
阿容,看在愚兄的份上,peaceful一些就好了:-)
to 肖荣,这个帖子我看过几遍了,他不淡定是他的事情,你不淡定就是你的问题,其实有些东西不必太计较。我被我的朋友+上司出卖了,我都很淡定,因为我知道,他要养老婆孩子。
宠辱不惊,闲看庭前花开花落,去留无意,漫随天外云卷云舒。
好的,陈老大,我保证,以后再也不吃狗肉了。再也不粗口了,如果我再暴粗口,你们抽死我
你都爆了多少粗口了, 别得理不饶人, 蛋定些好.
Andyfly是H3C的?
怎么最近弯曲里面火药味越来越浓了?
回楼上:
因为关注弯曲的人越来越多了,弯曲上免费的发言可能不仅仅代表自己,也可能代表利益。
因为有了不同的利益,于是有了不同立场,因为有了不同的立场,于是有了对立,有了争斗!
经过大家讨论,让我想起了QFabric,在它的启示下,对我自己的问题也基本上有了结论,网关不部署在核心上,而是另外找2台比较强悍的Box,放置在接入的位置,运行VRRPE/GLBP,作为网关。核心还是只关注简单的转发好了。