




2011 Google I/O大会今天开幕
作者 陈怀临 | 2011-05-10 07:11 | 类型 行业动感 | 47条用户评论 »
|
美国数字媒体新闻网站PaidContent今天撰文称,在谷歌本周二(5月10日)举行的2011年度I/O开发者大会上,该公司很可能公布(或重点讨 论)五大新产品和服务,其中包括新版Android操作系统、新版网络电视服务Google TV、Chrome OS操作系统及云音乐服务等。 谷 歌I/O大会于2008年5首次举行,每年一次。2011年谷歌I/O大会将于5月10日到11日在旧金山市Moscone会议中心举行,届时将近 5500名人员将参加本次大会。谷歌联合创始人、新任CEO拉里・佩奇((Larry Page))此前刚刚对公司高管层进行了改组,改组后的新高管层将高调亮相本次大会。 PaidContent预计,谷歌有望于今年I/O大会上宣布(或重点讨论)以下5大新产品和服务: 1、新版Android操作系统 众 所周知,Android手机平台已取得巨大市场成功。Android在很短时间内,就成为全球智能手机产业的主要平台之一,Android平台也成为谷歌 除搜索引擎服务之外最为成功的业务。此前Android平台主要是针对各类智能手机,但该平台能否在平板电脑上运行,进而使Android平板电脑成为苹 果iPad的强有力竞争对手,这尚需谷歌高管层在本届I/O大会上给出答案。可以预见的是,谷歌高管层肯定会在本次大会上透露平板电脑版Android的 更多技术详情。 2、新版网络电视服务Google TV 在2010年谷歌I/O大会上,谷歌公布了其网络电视Google TV计划。该服务主旨是为了实现互联网同传统电视节目的联姻。然而Google TV计划进展并不顺利。首先是各大电视网络服务商对于谷歌该计划持观望态度,其次是谷歌必须同电视机硬件制造商合作,以推出支持Google TV的电视机及外围设备。 PaidContent预计,谷歌将在本届I/O大会上阐述新版Google TV的市场战略和相应技术细节。美国科技博客网站Silicon Alley Insider(SAI)上月报道称,Google TV硬件有望采用速度更快的处理器,并能够运行更多Android应用程序。《华尔街日报》旗下博客网站AllThingsD则透露,新版Google TV将于今年年底时发布。 3、Chrome OS操作系统 谷歌2009年11月公布了其Chrome OS操作系统的技术详情和上市计划,表示该操作系统启动时间最多只用7秒钟,且绝大部分计算任务是基于互联网操作。只是Chrome OS发布时间已被数次推迟。最新传闻称,该操作系统有望于今年年中正式推出。 PaidContent 指出,现在已经是2011年5月,如果Chrome OS今年年中发布的传闻属实,则谷歌目前应该已经做好推出Chrome OS上网本的前期准备工作。谷歌在宣布开发Chrome OS之初,称该操作系统主要针对上网本。但目前平板电脑比上网本更受消费者欢迎,预计谷歌将在本次I/O大会上透露Chrome OS是否也适用于平板电脑。 4、新型Web技术标准 在前几届I/O大会上,谷歌声称业界应尽快采用HTML5等技术标准。时至今日,谷歌这项倡议远远还没有达到目标。可以预见的是,在今年I/O大会上,谷歌高管层仍将继续“鼓吹”HTML5等新型技术标准。 5、云音乐服务等 在 2010年谷歌I/O大会上,谷歌曾重点讨论了基于云计算的网络音乐服务。云音乐服务的大致理念是:此类服务可同时支持台式机、平板电脑及智能手机等设 备,使用户能够随时随地访问自己所存储的网络音乐。今年初有媒体报道称,谷歌即将在美国市场推出新型云音乐服务。但直到目前,谷歌仍未就此发布正式消息。 PaidContent认为,除云音乐服务外,谷歌还有可能在本届歌I/O大会上宣布谷歌Docs增加离线访问功能,并有可能透露Android平板电脑的硬件合作伙伴名单。 大会解读 PaidContent 指出,在谷歌过去数届I/O大会上,该公司曾公布了大量新产品和服务,但不少产品和服务目前已销声匿迹。其典型例子就是谷歌于2009年I/O大会上宣布 推出协作通信服务谷歌波浪(Google Wave)。但该公司去年8月表示,将不再继续谷歌波浪的后续开发。此外,谷歌离线应用开发工具Google Gears、通用登录系统服务Friend Connect等也被网民抛在了脑后。 但无论如何,本届I/O大会将是佩奇出任谷歌CEO后,该公司新高管层的首次高调亮相。从这个角度上讲,谷歌在本届I/O大会上所发布(或重点讨论)的新产品和服务,无疑将体现出佩奇及其核心管理团队的市场战略方向。 | |
 (没有打分) (没有打分) |
生活大爆炸–Juniper QFabric之父加入思科!
作者 libing | 2011-05-10 01:17 | 类型 行业动感 | 38条用户评论 »
|
谁说狗血的新闻只发生在娱乐圈,闷骚的IT宅男们也有博头条的勇气。 就在今天,Cisco发布了一条出人意外的消息,那奏是,当当当当~~~ ××××××××××××××惊魂未定的昏割线××××××××××××××××××××××××××××× Juniper QFabric之父,IT老兵David Yen被挖角到Cisco担任Nexus和UCS产品线老大! Juniper网站上,David Yen还在慈祥地讲解着QFaric的种种~~~ 观看此搞笑video请猛击以下链接:http://www.juniper.net/us/en/dm/datacenter/details/ 勤奋的Coders和首席口中不会coding的废柴们,尽情地八一八吧! | |
 (3个打分, 平均:5.00 / 5) (3个打分, 平均:5.00 / 5) |
关于移动终端安全的一本书
作者 wangsec | 2011-05-09 08:15 | 类型 行业动感 | 74条用户评论 »
|
【半年攒了一本书,主要是介绍移动终端安全。大家看有价值吗?值得出版吗?】 目 录 | |
 (4个打分, 平均:4.25 / 5) (4个打分, 平均:4.25 / 5) |
浅谈高端CPU Cache Page-Coloring(5)
作者 陈怀临 | 2011-05-08 17:58 | 类型 专题分析 | 18条用户评论 »
系列目录 高端CPU Cache Page Coloring上几节中,笔者试图介绍并强调了Cache Bin在理解大CPU大Cache中Cache Coloring的关键作用。读者最关键要理解的是: Cache Bin是当OS或者应用程序分配数据结构时,最后映射Cache这个层面中出现的一个“逻辑”概念,而非CPU中存在一个类似的的电路【Cache对SET中TAG和内容的寻找,是具体的电路的,通过一个Local Bus寻址。】 上图所示的就是两个层面的映射图。 在Cache中,这个x的位置或者值取决与Cache的大小。 在上几节中,这个x的值是18. 为什么? 这个2M的L2 Cache有多少SET(集合或者组)? 2M/(32 × 4) = (2 ×2^20)/ (2^5 * 2^2)=2^14=16K=16*1024 大家知道,0-4bit是32bytes cache line的offset。所以,贡献的bit是从5开始的。 因此, x-5+1=14–》x=19-1=18. 换言之,一个32位的物理地址的5-18是SET的bits。 在上图的第一个部分是一个物理页面的分解图。0-11是4K的offset。 5-31是Page Frame. 现在把Cache的分解图平移上去,我们会发现一个(x-12+1)的红色区域。 这个红色区域就是:Color Bits。或者说,Cache Bin Bits。再或者说,决定了上节所描绘的一个4K的物理页面会去那个Cache Bin。 同学们,这个时候要非常注意了:Page Frame是OS或者应用程序在做物理内存分配时可以控制的。 换言之:OS和/或应用程序可以控制Color Bits,或者Cache Bin,从而把一个物理内存,有意思的(Intentionally) 布局。 这类似与,中央或者机关的部长可以指派手下的小部长或者经理们去外研所当个钦差大臣。喜欢的去美国;不喜欢的去古巴。或者反之。总之,权力就是春药。 也也类似于,妈咪看见一个大款来了,或者公安局长来了,一定是去西厢。好好伺候。如果是个煤老板;让他去东厢。应付一下算了。 总之,有了Cache Bin,就预备了权力,具备了预算,有了权力,就可以调配了。 下面我们来做一些case study: x=19是什么意思? 如果仍然是一个4Way和32Byte的Cache,其意味着是一个4M的Cache。 依次类推, 当x=20的时候,是一个4Way/32byte的8M Cache。系统有9个color bit,有2^(20-12+1)=512个Cache Bin区域。 同学们这时会问一个问题了。。。 陈首席你现在,up to now,讲的都是经典的4K Page。这已经out of date了。。。 现代操作系统和CPU都已经支持大页面(Big Page)的allocation了。 那么Page Coloring或者Cache Coloring还适合嘛? Yes,kids。 其实数学就是一个抽象。学术就是玩符号。 我们把12这个fixed的value变成y。 我们就得到了下面这张General的图: Number of Color/Bin Bits b= (x-y+1). Number of Bins BIN = 2^B , if b>=0; BIN = 0 , if b<0;
例如,如果一个操作系统或者应用程序分配的物理页面上512K。其y的值就是18. 下面来做一些定量讨论: 如果系统还是我们文章中例子的2M Cache。其x是18. 任何两个512K的物理页面或者数据结构,一不小心就在一个Bin里。 512K的数据结构在大型通信系统里比比皆是。 有多少人想过,两个512K的数据结构有可能是在互相残杀?? 例如,如果一个操作系统或者应用程序分配的物理页面上1M。其y的值就是20. 如果系统还是我们文章中例子的2M Cache。其x是18. 大家随便踩了。 OS或者应用程序脱离对Cache Friendly的任何控制。 换言之,如果想通过应用程序或者OS对Cache能够进行干涉,要确保: x>=y. 从而,(x-y+1)>=1. 从而 2^(x-y+1)>=2. 从而确保系统中至少存在2个Cache Bin区域。 | |
|
(3个打分, 平均:4.67 / 5) |


3-D and III-V Transistors will be mass production,Moore’s Law Will Go on
作者 thunder1814 | 2011-05-08 08:45 | 类型 新兴技术, 新闻稿 | 8条用户评论 »
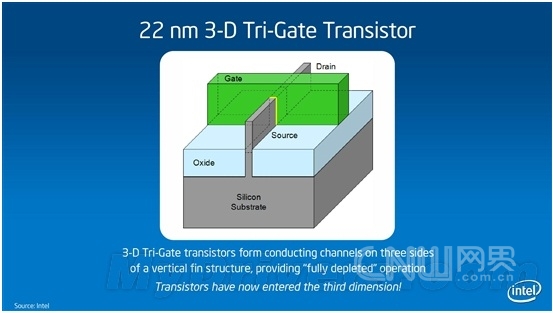
Intel宣布革命性3-D晶体管 22nm Ivy Bridge尝鲜摘要:5月4日,英特尔宣布在晶体管发展上取得了革命性的重大突破–被称为三栅极(Tri-Gate)的世界上首款3-D晶体管进入生产技术阶段。使用3-D三栅极晶体管的22纳米英特尔芯片(代号为Ivy Bridge)将在2011年底进行批量生产。 标签:英特尔 3-D三栅极晶体管 Ivy Bridge 5月4日,英特尔宣布在晶体管发展上取得了革命性的重大突破–被称为三栅极(Tri-Gate)的世界上首款3-D晶体管进入生产技术阶段。使用3-D三栅极晶体管的22纳米英特尔芯片(代号为Ivy Bridge)将在2011年底进行批量生产。 3-D三栅极晶体管续写摩尔神话 晶体管是现代电子设备的基石。自五十多年前硅晶体管发明以来,我们使用的一直是2-D平面晶体管。3-D三栅极晶体管则代表着晶体管结构的根本性转变:传统”扁平的”2-D平面栅极被超级纤薄的、从硅基体垂直竖起的3-D硅鳍状物所代替。电流控制是通过在鳍状物三面的每一面安装一个栅极而实现的(两侧和顶部各有一个栅极),而不像2-D平面晶体管那样,旨在顶部有一个栅极。更多的控制可以使晶体管在”开”的状态下让尽可能多的电流通过(为了获得更高性能),而在”关”的状态下尽可能让电流接近零(为了获得更低能耗),同时实现在这两种状态之间的迅速切换(也是为了获得更高性能)。
32nm平面与22nm立体对比
22nm 3-D Tri-Gate晶体管结构简图 就象通过盖高楼大厦而获得更多使用空间一样,这种3-D三栅极晶体管结构提供了一种管理晶体管密度的方式。由于这些鳍状物本身是垂直的,晶体管也可以更加紧密地封装起来。而且,未来设计师还可以不断增加鳍状物的高度,从而获得更高的性能和能效。 Intel声称,与32纳米平面晶体管相比,22纳米3-D 三栅极晶体管可带来最多37%的性能提升,而且同等性能下的功耗减少一半,这意味着它们更加适合用于小型掌上设备。 很多人都听说过著名的摩尔定律,即晶体管密度大约每18个月便会增加一倍,同时其功能和性能将提高,成本则会降低。40年来,摩尔定律已经成为半导体行业的基本商业模式。然而,随着处理器制程的不断提高,延续摩尔定律也变得越来越困难。 事实上,英特尔的科学家早在2002年就发布了三栅极晶体管设计,接着是单鳍片晶体管展示(2002年)、多鳍片晶体管展示(2003年)、三栅极SRAM单元展示(2006年)、三栅极后栅极(RMG)工艺开发(2007年),直至今日方才真正成熟。这一突破的关键之处在于,Intel可将其用于大批量的微处理器芯片生产流水线,而不仅仅停留在试验阶段。摩尔定律也有望继续保持活力。 不过,在英特尔高级院士马博(Mark Bohr)看来:”3-D三栅极晶体管实现了前所未有的性能提升和能耗节省,这一里程碑的意义要比单纯跟上摩尔定律的步伐更深远。低电压和低电量的好处,远远超过我们通常从一代制程升级到下一代制程所得到的好处。它将让产品设计师能够更加灵活地将现有设备创新的更智能,并且有可能开发出全新的产品。” ARM王位难保? 在记者看来, 尽管3-D 三栅极晶体管在性能上实现了惊人的37%的提升,但其在能耗上的提升,可能对英特尔的未来的影响更深远,甚至可能改变整个移动互联处理器市场格局。 当前,在手持设备和平板电脑处理器领域,ARM占据了90%的市场,可谓当之无愧的老大,而ARM芯片的主要优势就是低能耗。英特尔一直借凌动处理器来进攻该市场,但效果并不是特别理想。主要的理由也就是能耗逊色于ARM芯片。如今,3-D 三栅极晶体管实现了前所未有的低能耗,势必对ARM芯片的王者地位造成巨大挑战。在发布会现场,记者曾经向英特尔半导体(大连)有限公司柯必杰(kirby Jefferson)求证过基于3-D 三栅极晶体管的22奈米芯片与ARM芯片之间能耗孰优孰劣的问题。柯必杰回答说:”我还不能给你具体数据,但我们英特尔内部有实验比对数据,我只能说我们的处理器无论是性能还是能耗都有极大的优势。” 不过,英特尔表示,会优先生产基于3-D 三栅极晶体管的服务器和台式机芯片。柯必杰表示那毕竟是目前英特尔的主要领域,无疑,3-D 三栅极晶体管将使得英特尔在22纳米甚至14纳米时代保持巨大的领先优势。 可以预见的是,不久的将来,我们将迎来更轻更薄更高性能也更加环保的各种电子设备。总之,这将又是一场可能影响我们整个社会的技术革命。 本文转载自企业级IT信息服务平台-网界网-CNW.com.cn 更多图片见:http://tech.163.com/digi/11/0505/10/739JUKFF00162OUT_2.html | |
|
(1个打分, 平均:5.00 / 5) |

矽映公司2550万美元收购SiBEAM
作者 高飞 | 2011-05-07 15:13 | 类型 初创公司, 行业动感 | 7条用户评论 »
|
2011年4月14日,矽映电子科技(Silicon Image, Inc,NASDAQ: SIMG)宣布以2550万美元的现金和股票,作价收购高速无线通信芯片设计公司SiBEAM。交易预计在2011年第二季度完成,交易完成后,SiBEAM仍然独立运作。 作为一家初创公司,SiBEAM身上曾有接近完美的光环。弯友硅谷老人在2009年3月曾撰文介绍:《SiBeam: 60Ghz CMOS 无线通信的先驱》。笔者每天几乎都经过SiBEAM位于Sunnyvale的总部,和里面许多层面的员工都是好朋友。
2007年,SiBEAM的60GHz芯片荣获CES Best Enabling Technology。2010年Computex上,华硕发布了搭载基于SiBEAM芯片的WirelessHD笔记本,在10米之内无损无压缩传输1080p高清视频。2011年CES上,SiBEAM集中展示了一系列基于其芯片的WirelessHD产品,包括戴尔Alienware游戏笔记本,VIZIO、LG、松下、索尼的高清电视,Monster的HDMI适配器等等。 从耀眼的技术到商业应用到盈利毕竟有一段差距。60GHz需要高额的研发,同时高清视频传输市场上其他的技术也对SiBEAM形成挑战。笔者收集了SiBEAM的融资历史:
从以上数字统计,SiBEAM七年融资总额超过一亿三千七百万美元,这次以2550万美元卖给矽映,对投资人而言并非好消息。但是至少,矽映承诺让SiBEAM独立运作,而且承诺将结合SiBEAM的无线技术和矽映的高清连接技术方案,推动60G无线通信的标准发展,推进这一技术进入移动和消费平台。对于消费者和工程师而言,这是个好消息。 | |
|
(1个打分, 平均:5.00 / 5) |

《云计算核心技术剖析》即将出版!!!
作者 吴朱华 | 2011-05-07 09:47 | 类型 云计算, 弯曲推荐, 行业动感 | 26条用户评论 »
|
人生最重要时刻之一即将到来,《云计算核心技术剖析》原名《剖析云计算》即将出版了,这本书本身起始于在弯曲发表的“探索UCS”这个系列,可以说弯曲就是《剖析云计算》的诞生地。在这里,我感谢吴健康与朱兰娣、以刘江、傅志红和王军花为代表图灵出版社、以王庆波、赵阳和陈滢为代表的IBM中国研究院,还有陈怀临和孔华威这两位师长,还有很多同济和北大的校友,下图就是本书的封面:
| |
|
(没有打分) |

性能优化的方法和技巧:系统
作者 kernelchina | 2011-05-06 06:43 | 类型 专题分析, 行业动感 | 19条用户评论 »
系列目录 性能优化方法和技巧从系统层次去优化系统往往有比较明显的效果。但是,在优化之前,我们先要问一问,能否通过扩展系统来达到提高性能的目的,比如:
使用更强的硬件当然和优化没有半点关系,但是如果这是一个可以接受的方案,为什么不用这个简单易行的方案哪?替换硬件的风险要比改架构,改代码的风险小多了,何乐而不为? Scale out的方案就有一点麻烦。它要求系统本身是支持scale out,或者把系统优化成可以支持scale out。不管是哪一种选择,都不是一个简单的选择。设计一个可以scale out的系统已经超出了本文所要关注的范围,但是,scale out应该是系统优化的一个重要方向。 下面会讨论一些常见的系统优化的方法,如果还有其他没有提到的,也欢迎读者指出来。 1) Cache
2) Lazy computing Lazy computing(延迟计算),简而言之,就是不要做额外的事情,特别是无用的事情。最常见的一个例子就是COW(copy on write),可以参考这个链接http://en.wikipedia.org/wiki/Copy-on-write。
Lazy computing在哪些情况下有效?目前能想到的只有内存复制。用时分配内存算不算哪?用时分配内存不能节省时间,但是可以节省空间。静态内存对时间性能有好处;动态内存对空间性能有好处。就看目标是优化哪个性能了。 3) Read ahead Read ahead (预读),也可以称之为pre-fetch(预取)。就是要提前准备所需要的数据,避免使用时的等待。
4) Hardware assist Hardware assist (硬件辅助),顾名思义,就是用硬件实现某些功能。常见的,比如加密,解密;正则表达式或者DFA engine,或者规则查找,分类,压缩,解压缩等等。逻辑简单,功能确定,CPU intensive的工作可以考虑用硬件来代替。
5) Asynchronous Asynchronous(异步)。同步,异步涉及到消息传递。一般来说,同步比较简单,性能稍低;而异步比较复杂,但是性能较高。
6) Polling Polling(轮询)。Polling是网络设备里面常用的一个技术,比如Linux的NAPI或者epoll。与之对应的是中断,或者是事件。
7) Static memory pool Static memory pool(静态内存)。如前所述,静态内存有更好的性能,但是适应性较差(特别是系统里面有多个 任务的时候),而且会有浪费(提前分配,还没用到就分配了)。
系统层次的优化应该还有很多方法,能想起来的就这么多了(这部分比较难,酝酿了很久,才想起来这么一点东西^-^),读者如果有更好的方法,可以一起讨论。性能优化是关注实践的工作,任何纸上谈兵都是瞎扯,与读者共勉。 参考资料: 1:http://en.wikipedia.org/wiki/Copy_on_write 2:http://en.wikipedia.org/wiki/Readahead 3:http://en.wikipedia.org/wiki/Sliding_window 4:http://en.wikipedia.org/wiki/Asynchronous_I/O 5:http://en.wikipedia.org/wiki/Coprocessor 6:http://en.wikipedia.org/wiki/Polling_(computer_science) 7:http://en.wikipedia.org/wiki/Static_memory_allocation | |
|
(没有打分) |
英特尔将批量生产3D晶体管 芯片耗电量大幅降低
作者 cracked | 2011-05-06 06:42 | 类型 行业动感 | 5条用户评论 »
|
http://www.sina.com.cn 2011年05月05日 11:08 新浪科技 被称为三栅极的世界上首款3-D晶体管进入生产技术阶段左边为32纳米平面晶体管,右边为22纳米 3-D三栅极晶体管,示意电流通过的样子 新浪科技讯 北京时间5月5日上午消息,英特尔周三在旧金山展示了一项全新的3D晶体管技术,可以在性能不变的情况下,将处理器能耗降低一半。 英特尔宣布其研发的3D晶体管将首次投入批量生产,并将用于英特尔代号为Ivy Bridge的22纳米处理器。采用该技术的产品有望于2012年初发布。 据介绍,英特尔的3D晶体管使得芯片能够在更低的电压下运行,并进一步减少漏电量,与之前最先进的晶体管相比,它的性能更高、能效更低。此前的芯片所用晶体管都为平面晶体管。 英特尔表示,基于Ivy Bridge的英特尔酷睿系列处理器将是首批采用3D晶体管进行批量生产的芯片,将可用于笔记本电脑、服务器和台式机。随后,英特尔凌动处理器也将采用最新的3D晶体管,但目前还没有具体时间表。 摩尔定律预言,电脑的性能每2年可提高一倍,因为芯片上的晶体管数量每2年约增加一倍。对于消费者来说,英特尔晶体管的新设计意味着摩尔定律可继续有效。 重大变革 英特尔号称将推动半导体行业50多年来的最大技术变革,通过一款全新的设计为消费电子产品提供更为强大的芯片,而且不会以牺牲电池续航时间为代价。 该公司计划将每款芯片的一个关键部件改造成垂直的鳍状结构,这种理念类似于在城市中修建超高层建筑来增加办公空间。本次改造的部件是晶体管,这是一种基本的电子元件,几乎所有的电子产品都会用到。当今的微处理器已经能够包含数十亿个这种微型开关元件。 英特尔表示。这种最新的设计能够为智能手机和平板电脑提供更强大的计算能力,同时加快企业数据中心的速度,而且还能大幅降低能耗。 尽管竞争对手也在研究类似的技术,但英特尔却是首家承诺将使用所谓的3D方法进行量产的企业。分析师认为,这一冒险之举可以帮助英特尔在性能上与竞争对手相匹敌,从而扭转被智能手机市场排挤的命运。 美国市场研究公司VLSI Research芯片制造专家丹·哈奇森(Dan Hutcheson)说:“我们讨论这种3D电路已经有十多年了,但是没有人有信心将其投入生产。” 英特尔高管周三在旧金山的一次会议上演示了采用这种新方法生产的芯片。他们指出,首款采用这种技术生产的芯片可能会着眼于高端台式机和服务器系统,并将于2012年初推出。 设计原理 2D平面半导体制造工艺是由飞兆半导体公司(Fairchild Semiconductor)的吉恩·赫尔尼(Jean Hoerni)于1959年发明的。该技术后来被英特尔联合创始人罗伯特·诺伊斯(Robert Noyce)采纳,并用来生产集成电路。 英特尔高管表示,采用3D晶体管设计将比单纯推出新一代生产技术带来更多的益处。例如,在性能不变的情况下,新技术的能耗将比现有生产技术低一半。 “这是一种空前的成就。我们从来没有以低电压实现过这种性能。”负责新生产工艺开发的英特尔研究员马克·波尔(Mark Bohr)说。 芯片设计师长期以来都在努力突破2D设计,这种设计会在晶体管上覆盖着一层层的互连线缆。而英特尔这款新设计的关键在于晶体管上的一个元件,它决定着电流的速度以及电流的泄露量,从而影响到能耗。 英特尔的工程师将电子的扁平传输渠道替换成一个鳍状的结构,有三个面被一种名为“门”(Gate)的设备包围,这种设备的作用是开关电流。波尔表示,3D形状增大了晶体管“开启”状态下的电流通过量,但在“关闭”的状态下却可以减少泄露量。 英特尔在2002发表的多篇论文中披露了基本方法,并且花了多年时间对其进行完善。该公司已经准备在今后的22纳米生产工艺中全面采用新的设计。英特尔当前的生产工艺为32纳米。 成本因素 放弃传统制造技术可能会导致成本上涨,因此芯片公司通常都会尽力避免这种行为。波尔表示,使用新技术将导致英特尔的成品晶圆成本上涨2%至3%,每个晶圆都包含数百个芯片。 美国市场研究公司Endpoint Technologies Associates市场研究员罗杰·凯(Roger Kay)说:“新的结构足以让该公司生产出大量可靠的22纳米芯片。” 其他企业今后也有望采用这种3D生产方法,但必须要等到生产工艺降到22纳米以下。从AMD剥离出来的芯片制造商Globalfoundries周三表示,将在今后的20纳米工艺中使用传统的晶体管。该公司发言人称,在推出后续生产工艺前,没有必要使用3D晶体管技术。 英特尔架构集团执行副总裁大卫·珀尔马特(David Perlmutter)在下一代开发代号为“Ivy Bridge”的微处理器中证明了这一技术。他表示,该技术可以对提升图形电路的性能起到一定的帮助,英特尔在这一方面落后于AMD和英伟达(Nvidia)。 但更大的问题在于,3D设计方法能否帮助英特尔的芯片在能耗效率上赶上使用ARM架构的竞争对手。珀尔马特并未透露何时使用新工艺生产专门针对移动设备设计的凌动(Atom)处理器。(书聿) | |
|
(没有打分) |
中国计算机学会NetMagic网络创新实验平台技术与应用研讨会
作者 tpstar | 2011-05-04 08:09 | 类型 新闻稿 | 13条用户评论 »
|
NetMagic是面向互联网络技术创新研究和教学开发的可重构网络交换平台。通过支持研究人员定义网络交换设备的功能和处理流程,为各种新型网络机制和协议研究提供实验手段。 NetMagic网络创新平台技术与应用研讨会(NMTA Workshop 2011)由中国计算机学会主办,计算机学会互联网专委会协办,国防科学技术大学计算机学院承办。本次研讨会将邀请境内外多所知名大学和科研机构的专家学者参加,从网络创新研究和教学试验需求出发,讨论平台的设计思想、组成结构、开发指南和代码开源计划等,并现场进行相关的试验演示。 更多netmagic信息参见www.netmagic.org 附:会议安排和报名方法 (1)会议日程
(2)会务相关信息 会议地点暂定为湖南省长沙市国防科技大学科苑宾馆;会议不收取会务费,差旅费自理;参会请填写报名回执,并通过邮件于2011年05月10日前通知会务人员。会务人员可协助定房。 会务组联系方式: 苏丁:电话:13787137594 邮箱:suding2006@sina.com 龙飞:电话:18607019888 邮箱:zxy@jxtvnet.com (3)报名回执 会议回执模板
中国计算机协会 2011年5月3日 | ||||||||||||||||||||||||||||||||||||||||||||
|
(没有打分) |