




Data Structures and Algorithms for Big Databases
作者 Echo | 2013-06-13 07:16 | 类型 大数据 | Comments Off
|
这是近几年对大型数据库基础算法与数据结构写得最深入浅出,既有广度又有深度的文章之一。 其中描述了大数据处理中的问题,用来解决的数据结构和算法,以及它们的实验结果和性能比较。 对于有意从事大数据工作的朋友们,可谓福音。 如果能精通这长达208页ppt中所有算法与数据结构,其它犹如浮云,会有登高望远,一览众山小之感,所谓“五岳归来不看山,黄山归来不看岳”。
| |
 (1个打分, 平均:5.00 / 5) (1个打分, 平均:5.00 / 5) |

从一个疯狂下载者变成学习者
作者 Echo | 2013-06-13 07:15 | 类型 弯曲推荐 | 7条用户评论 »
|
(编者按——这篇文字最早见于数年前的某英语论坛,原始出处已不可考。尽管内容偏重英语学习,但文中指出的很多学习者存在的问题,以及对学习方法的体悟,却是具有普适性并值得借鉴的。 古人云:“临渊羡鱼,不如退而结网”,这样的现象屡见不鲜:满满的硬盘,没有几份资料是真正认真读过;看到好的资料,总是想先存起来,下载后慢慢看。但到了真正想看的时候,不是没有时间,就是收集的资料太多,不知从何看起。号称碎片化阅读之王的微博,也有“收藏”功能,然而,收藏下来的资料和文档,真正能够再次认真阅读的,却寥寥无几。 资料需要下载和阅读,但最重要的还是思考,消化与交流。希望弯曲评论一直以来所倡导的“深度阅读”的理念,能为您的学习与工作带来启发与帮助。)
先从我自己说起,我没来到网络学英语前也是个英语学习的积极梦想者,因为我知道说一口流利的英语会带给自己多少好处,就这样一头扎进了网络。刚来到英语类网站时,简直是进入了天堂,看到很多人都可以用英文发帖子,帖子里很多精品资料,于是乎开始疯狂下载收集资料,把过去买盗版英语资料的习惯抛弃了,一张张的刻盘,当手里拿着上百张英语资料盘时那种满足感,好像自己已经掌握了英语,就这样不断下载,半年多过去了。有一天猛一回头,发现自己除了沉颠颠的盘包,满满的硬盘,对英语我还是一无所有。可以不客气的说,包括自己在内大多数上网学习英语的人还都是幻想者,很多人都是英语很差,但都梦想着能攻克英语。于是一个怪圈出现了,这也频繁发生在现实生活中。开始寻找捷径,开始研究李阳好,还是新东方好,还是钟道隆好。每样都学几天,然后觉得不好,不好的理由就是见效慢,然后再寻找。于是下载就给了这样的人想象空间,今天看到站长斑竹发个帖子说这个软件好,也看到很多人说好,那就赶快下载下来,正下载中间,又看到另一个帖子,人气十足,那一会也要下载,不好的东西人气能高么? 希望能有捷径攻克英语的人都忽略了一个实质问题,那就是学习知识是要靠自力,而不是他力,他人的帮助只能推动学习的步伐,但代替不了学习的全部过程。如果我说英语是各种学科里最好学的,恐怕很多人都不会相信,但事实就是如此,这是个几岁的孩子就可以学习的东西,英语没有理解不理解之说,只有会与不会的区别,它不是高数,物理,那些有些人就是理解不了,而英语呢?只需要拿出人类最基本的本能来就可以掌握,那就是记忆。将近十年的疯狂英语到新东方和无数小培训班到书店里琳琅满目的英语图书和资料,中国人为了学习英语拿出了一百多个亿,造就了不少英语神话,培养了几个教育大腕。而大多数人的英语水平并没有得到真正的提高,很多所谓过了四六级的人还不如国外的小孩子。说不能说,听不能听。这说明了个什么问题?学习英语是资料的堆积?是某个培训者的培训?有人会强调学校教育方法的原因,可传统的教育甚至没有教育的前提下,学好英语的也不少。我们可以问问网上身边英语学习真正好的人,他们看过几G或者是几十G的资料?我的听力老师他说,很多学听力的人毕业的时候和刚进来一个样,为什么呢,上课也认真听,听的也很心花怒放,可回去了不记忆,不背诵。这就是问题,老师的单词再多,知识点再多也只是他自己的,要转换到个人的大脑里,就要听完后下工夫去记忆,去背诵。上海有个小姑娘14岁托福考了600多分,她怎么培养的?就是朗读,背诵,复述故事和文章,再加上父母的语法指点。我的邻居一个北大的法律硕士,她托福647分,我问她怎么学的,她说也没突击,就考试前买点习题集做做,就去考试了,其它都是基础底子。她的底子是什么?那就是从初中开始学习英语的时候把老师教的都掌握,都装到自己大脑里,大学四年学的也不是英语专业,可她听和说都不差。就是把大学英语精读四册和听力四册学好,掌握好,这就很厉害了,考研的时候也没有像我在各大论坛看到的那些人一样,到处抓新东方的英语培训资料,跟救命稻草一样。
再看看那些张口就是要新概念美音版一到四册下载的人,又有几个把新概念从头学到尾了?还口口声声要什么美音版,好象学了英音就不是英语了。一都没有学就想着四,有人会说要四是留着以后学,可我相信,如果现在连一都不去学,还会以后学什么四呢?而且有些人下载着的时候,恐怕家里的书架上还摆着新概念一的书本和磁带吧。就跟钟道隆老先生说的一样,很多人今天买这个教材,连录音带的塑料都还没全拆开,就又去买那个资料了。还有到处抢着新东方网络课程的人,谁有就好象是大爷一样,那个得意洋洋。没有的就要好声言语,想方设法去搞到手。可现在有这些资料的人,有几个敢说他认真的一课一课去学了,而且一直坚持到现在?大多数人恐怕是冲着那个东西贵才去下吧,好象免费下了以后就拣了天大的便宜一样。更多的还有一种人云亦云心理,觉得大家都说好,都抢着要,那自己要下,不下是不是就少点什么。我不否认一部分人是确实需要这些资料才下载的,但我敢肯定大多数人都是跟风下,下了也不看。还有那些张口就要什么环境英语,走遍美国第七八张光盘资料的人,好象他们已经学到那第七八张光盘了一样,说实话,走遍美国要是真学到那里还掌握了,也就没必要去要后面的光盘了,那水平就提高一下单词量就可以了。 这世界上没有免费的午餐,这句话是一点都不错,当我们为下载了几G和几十G的免费英语资料而沾沾自喜的时候,当我们不停的去寻找更多的资料的时候,我们已经失去了最宝贵的东西,那就是时间,那就是生命,人生能有几回搏?我们浪费掉一个小时,我们的生命中就失去了一个小时。本来我们一生中就做很多无意义的事浪费时间了,那么学习上就不要再浪费了,多去下点苦工夫认真背点东西也比在下载中自我陶醉有意义的多。语言的学习没有新旧资料之分,只要不是中古语言,对于我们来说看好哪一个教材和课本就坚持学下去,都会通往攻克英语的山峰的。只有去下工夫一个一个字,一个一个句子的去掌握,才会有收获,英语学习是没有捷径的。在这里也希望网上这些搞下载的网站能够清醒认识到这一点,不要耽误自己和别人,有利可图那就另当别论,但那些为大家无私奉献的网站的斑竹们,感谢他们的付出,但希望头脑都能清醒一些,把浮躁的心压下来,大家在一起多交流一下心得,多多做一些既提高自己又帮助别人的工作,一起学习,而不是把大堆的资料拿出来搬回去。 掌握科学的学习方法,风雨无阻,有勇气和毅力,相信自己”我行我一定能做到”,把自己真正的“从一个疯狂下载者变成一个学习者”,那么你也一定会再雄心勃勃。
| |
 (14个打分, 平均:4.86 / 5) (14个打分, 平均:4.86 / 5) |
超级计算机科普系列——Top500
作者 Echo | 2013-06-12 05:19 | 类型 行业动感 | 12条用户评论 »
|
Top500(http://www.top500.org)是目前比较超级计算性能的一个排行榜, 其创始人为四位大学教授:Hans Meuer、Erich Strohmaier、 Jack Dongarra和Horst Simon。 Meuer当年是德国University of Mannheim的教授,也是该校计算中心的主任,如果大家关注高性能计算领域,就会知道Meuer教授是曼海姆超级计算机研讨会(Mannheim Supercomputing Seminar)的创始人之一。该研讨会随后发展成现在超算领域两大知名会议之一的“International Supercomputing Conference”(简称ISC)。另一知名会议为“The International Conference for High Performance Computing, Networking, Storage, and Analysis”(简称“SC”)。当时Strohmaier在Meuer手下工作,他的职责之一就是把当时世界上超级计算机的统计数据汇编起来,以便在6月份举办的曼海姆超级计算机研讨会上展示。一开始,他们并未打算长期更新这个列表。然而后来他们改变了主意,决定五个月以后看看上面的机器会有什么样的变化。也就是说,他们打算在当年11月份的SC上展示。既然要比较计算机的性能,就需要用到一个测试性能的程序,而Dongarra教授是线性代数数值算法及并行计算的专家,于是就采用了他的名为Linpack的程序。Horst Simon是2000年以后加入到Top500的编辑工作中的。从1993年起,Top500的排名每年都会更新两次,一次是在6月份举办的ISC上,另一次是在11月份举办的SC上。今年的ISC将于6月16日在德国莱比锡举行。 任何一个机器,想要在Top500上崭露头角,都需要运行Linpack测试程序,然后以FLOPS(FLoating-point Operations Per Second,每秒浮点数操作)作为衡量性能的指标。需要注意的是,在Linpack中,浮点数特指64位的双精度浮点数。而在运行完Linpack测试程序之后,还需要通过对结果的验证,来保证其正确性。由于测试时可以选择不同的待求解问题规模,所以不同的机器在运行Linpack时,都会选取最合适的规模来获得最佳性能。而通常想要获得最佳性能的话,求解问题的规模需要同超级计算机所拥有的内存相匹配,这样才能使得随着机器计算性能以及内存容量的加大,使用Linpack测试性能所使用的时间也逐步变长。由最开始的几个小时,到现在的几天。这样的好处就是能够最大限度的榨取机器性能,以获得准确的数据。但是现在这个测试时间实在有些太长,而且还有可能更长。因此Jack Dongarra教授正在考虑是否只运行部分计算,使得测试时间保持在一个较为合理的范围。 Linpack到底是一个怎样的测试程序呢?简单说来,这个程序就是用来求解线性方程组的。通常,一组线性方程组都可以表示成Ax=b的形式,其中x是未知变量组成列向量,而A是各项系数组成的矩阵,b是常数项组成的列向量。根据线性代数知识,通常用高斯消元法求解x,将有n个变量的方程组通过代数运算,消去(n-1)个未知数,然后求解出剩下的唯一一个变量,再用得到的变量一次求解剩下的(n-1)个变量。那么,使用计算机该如何求解呢?通常采用的方法是先对系数矩阵A进行LU分解。其中L为下三角矩阵(矩阵主对角线上方全为0),U为上三角矩阵(矩阵主对角线下方全部为0)。如果系数矩阵为L或者U类型的矩阵,求解起来是非常容易的。其实,高斯消去法的一些列操作步骤,可以用等价的高斯矩阵表示。而高斯矩阵就属于L或者U。 问题在于,一个矩阵A并不一定能够分解为A=LU的形式,即使A是非奇异矩阵。但是数学家们已经证明:只要A是非奇异矩阵,总可以找到一个变换矩阵P,使得PA=LU存在。这样的话,原来需要求解的问题就由Ax=b变成了PLUx=b。这里,P是置换矩阵(permutation matrix),它仅由0或者1构成,并且满足每一行每一列有且仅有一个元素为1。为什么叫置换矩阵?因为用P乘以一个矩阵,其实相当于把该矩阵的行与行(或者列与列)之间进行了一些交换。 置换矩阵有很多非常有用的性质,例如置换矩阵都是正交矩阵,其逆矩阵就是其转置矩阵,等等。所以其逆矩阵总是存在。因此也就说明方程组的求解最后总可以变成LUx=PTb的求解。 接下来对Linpack中的浮点数操作(FLOP)进行分析。假定需要求解方程组Ax=b,其中A是n阶非奇异矩阵,即大小为n * n的可以求逆的矩阵。 有了这样一个标准化的程序之后,要比较各个超级计算机的性能就很容易了。把这个程序在机器上运行一遍,计算出测试得到的峰值FLOPS,大的排在前面。 Linpack根据问题的规模与优化,可以选择100* 100,1000 * 1000以及n * n三种测试。其中Top500使用的是HPL(High Performance Linpack,高度并行计算基准测试),它是一个开源的基于MPI的Linpack测试软件包。该测试对问题规模的大小没有限制,主要针对分布式内存的大规模并行计算系统设计。其要求是Linpack标准中最为宽松的,用户可以对任意大小的问题规模,使用任意个数的处理器。Linpack中使用了BLAS(Basic Linear Algebra Subroutines,基础线性代数子程序),该软件包含了矩阵的基本操作,Linpack软件包就是构建在BLAS之上的。HPL中大量的浮点运算通过BLAS实现,这样增加了HPL的可移植性,只要对被调用的BLAS进行修改,便可适应不同的计算机硬件。 Top500上提交的性能通常是最好结果,而针对Linpack的调优主要包括分块矩阵大小,以及二维处理器矩阵上的分布的参数调优等。对于HPL来说,多处理器并行所带来的通信开销以及冗余计算,一定程度上制约了峰值性能。 通常,每个Top500上的表项,都包含该机器的多个相关信息,其中比较重要的有: 关于峰值性能,常用单位如下: 通过下载Top500的xls表格,可以看到更详细的信息。比如该系统是同构体系,还是由处理器+协处理器(加速部件)构成的异构系统;所用处理器以及协处理器的具体型号、节点之间所用的互联技术、操作系统种类等。以Titan超级计算机为例,可以看到制造商为Cray公司,该超级计算机坐落在美国,启用时间或者上一次大规模升级的时间为2012年。一共由56万个频率为2.2GHz的Opteron 6274 16C处理器和26万个Nvidia的K20x加速部件(GPU)组成。运行的操作系统为Cray公司定制的Linux环境,通过Cray公司的Gemini技术进行互连。 机器的理论峰值FLOPS通常经过计算得到。以Xeon Phi 5110P为例,其每个核每周期能够提供16个双精度浮点数操作,而一块Xeon Phi 5110P拥有60个核,工作频率为1.053GHz,那么单块Xeon Phi 5110P的理论峰值为16 * 60 * 1.053 = 1.01088 TeraFLOPS。1000块Xeon Phi5110P就可以提供高达1010.88 TeraFLOPS的处理能力。但理论峰值是计算能力的上限,实际是无法达到的,因此,有另外一个重要的性能指标,就是运行Linpack测试程序对超级计算机理论计算能力的利用率。该值可以用运行Linpack获得的峰值FLOPS除以理论峰值FLOPS得到。那Top500上机器的利用率大概是多少呢?这与编程人员针对特定超级计算机对Linpack进行调优的程度有关。如果参数调得比较好,那么机器的性能就能很好的发挥出来,所获得的峰值性能就更接近理论峰值,效率就比较高。目前,按照效率排名来看,靠前的主要是日本的超级计算机,然后就是美国。前三名都是日本的机器,其中曾经在2011年拔得头筹的K compter可获得高达93.17%的峰值性能,这是相当高的一个数字。另外一个比较有意思的现象,就是使用处理器+协处理器构架的机器,效率都比较低,大约在50%~60%左右。比如说使用了GPU的Tianhe-1A(54.58%),Titan(64.88%),以及使用了Intel Xeon Phi的Stampede(67.2%)。这一方面与协处理器的海量计算单元很难做到百分百的使用有关;另一方面也与使用协处理器的超级计算机需要在处理器与协处理器之间拷贝数据,因此增加了通信上的开销有关。 下面几张图展示的是从1993年以来Top500上机器的变化趋势。第一张图显示的是体系结构上的区别。Top500上的机器在90年代的时候主要以MPP+SMP为主,有着少量的Single Proc以及SIMD机器。随着时间的推移,Single Proc,SMP以及SIMD的机器都消失了,而Cluster的体系结构开始风光起来。到现在,基本上放眼Top500上的机器,是80%的cluster加上20%的MPP。第二张图显示的是Top500上超级计算机所使用的芯片。最开始是Proprietary的芯片,到了20世纪90年代末21世纪初,则进入了百花齐放的时代。当时的超级计算机用到的芯片有Alpha,IBM,HP,MIPS,SPARK。但到最后Intel逐渐发展起来,到现在的一家独大,剩下的只有AMD和IBM的powerPC了。第三张图显示的是超级计算的安装种类,这个图上变化并不明显,基本上是研究院、高校以及工业界三部分。第四张图显示的是超级计算机中所使用的加速部件/协处理器的变化趋势。从图上可以看出,在2006年之前,是没有使用协处理器的系统的。从2006年开始,出现了使用Clearspeed CSX600的超级计算机。而2008年起,出现了使用IBM PowerXCell 8i作为协处理器的超级计算机。2010年出现了使用Nvidia的GPU的超计算机(Tianhe-1A),标志着GPGPU进入了超级计算机的大舞台。而Intel也不甘示弱,在2012年推出了Intel Xeon Phi协处理器,并部署到超级计算机Stampede中。而目前排名第一的Titan,则使用了Nvidia下一代Kepler构架的K20x。
从1993年起,Top500上的机器不断刷新着最高的FLOPS,也代表着人类计算的极限速度在不断改写。从最开始Fujitsu Numerical Wind Tunnel的124.5GigaFlOPS,一路水涨船高,在1997年,Intel ASCI Red/9152已经突破了TeraFLOPS的大关。 随着ISC开幕日期的临近,Top500上的排名又将更新。届时,天河二号是否能有令人惊艳的表现,让我们拭目以待吧。
| |
 (没有打分) (没有打分) |

超级计算机科普系列——概述
作者 陈怀临 | 2013-06-11 21:25 | 类型 行业动感 | Comments Off
|
5月28日,一则发表在国外知名高性能计算新闻网站HPC Wire上的消息,显得格外引人注意。该新闻的标题为“Is China Set to Unveil Record-Shattering Supercomputer?”。文中指出,“根据多方消息,中国已经有了高达50 PetaFLOPS(Peta FLoating-point Operations Per Second,每秒千万亿次浮点运算)的新一代超级计算机。该超级计算机基于Intel 的MIC众核体系结构,即将在今年6月份最新更新的Top500(超级计算机排行榜)上揭开其神秘面纱。”之后,华尔街日报等多家国外媒体也推出了类似报道。 与此同时,国内在微博上开始转发天河二号的消息,相关人士纷纷提醒大家关注6月份更新的Top500。美国田纳西大学ICL(Innovative Computing Laboratory,创新计算实验室)的主任,同时也是美国橡树岭国家实验室的Jack Dongarra教授更是在6月3日在自己的个人主页上传了一份技术报告。据称,该技术报告来自于他于5月底被邀请前往国防科大参加的一个国际高性能计算研讨会。里面详细提到天河二号的一些技术细节和性能指标。至此,可能封顶Top500的中国下一代超级计算机呼之欲出。 超级计算机,通常代表的是人类先进掌握的处理数据速度的极限。超级计算机的概念由知名超级计算机制造公司 Cray的创始人Seymour Cray在20世纪60年代提出。不过那时的计算机仅仅是体积庞大而已,至于性能,可能还比不过当今的袖珍计算器,更比不上桌面台式机。当时所谓的超级计算机其实也就是由若干个处理器组成。进入20世纪?年代,随着个人PC的兴起,超级计算机才开始走向由成百上千个处理器组成的真正“庞然大物”。以在2012年11月公布的Top500排行版上占据首位的Titan超级计算机为例,其一共由560640个核组成,峰值计算能力高达17.6 PetaFLOPS,是世界首台超级计算机CDC 6600的200亿(21010)倍。 研发制造超级计算机具有重大意义:首先,超级计算机广泛应用于科学研究、国防建设等尖端领域。在科学研究方面,基因以及蛋白质序列分析,地球气候建模分析,分子动力学仿真、高能物理等都需要借助超级计算机强大的数据处理能力;在国防军事领域,现代化的战争对信息化、兵力部署、后勤保障等的要求都可以归结为基于大数据、多变量的实时优化问题。实时求解该类问题,需要有强大的计算能力作为保证。其次,以核试验为例,传统的核试爆由于对环境破坏巨大,需要承受巨大的国际舆论压力,目前基本上已经不被各国采用。与之相对的、采取小规模临界核试验获取部分实验数据,并且综合以往经验、数据构建模型进行仿真的方式,逐渐成为主流。而模型的仿真求解,对数据处理能力也是一种挑战 。在这些有着海量数据,并对时效性要求较高的高精尖领域,超级计算机都发挥了巨大的作用。 从技术层面上看,超级计算机由于经历了半个多世纪的发展,产生了巨大的变化。现今,通过海量处理器而组成的集群系统是主流设计。在单个节点上,部署多核、众核的处理器,并且伴以协处理器或者专用加速部件;而不同的节点之间,通过高速网络连接通信,进而组成超级计算机。从硬件上看,高性能处理器,协处理器以及专用加速部件都是组成系统的重要计算单元。早期的超级计算机,大多由大量单一种类单一处理能力的处理器构成,这种结构被称为“同构”(homogeneous)。但如今,“异构”(heterogeneous)平台变得越来越流行。异构是指计算单元由不同处理能力及种类的处理器构成。例如天河一号以及当今最快的Titan超级计算机就都是由CPU以及GPU组成的异构机器。同样,TACC(Texas Advanced Computing Center,德州高级计算中心)的超级计算机“Stampede”以及即将发布的天河二号都采用了多核与众核混合集成的构架。除了高性能的计算单元,高性能存储、高性能的互联以及包括操作系统、文件系统,编译器、编程模型等在内的整个软件生态环境也是超级计算机的关键技术。 截至2012年11月,根据Top500超级计算机排行榜上的分布,世界上现有超级计算机主要在以下几个地区:美国(251)、 中国(72) 、法国(21)、德国(19)、英国(24)和 日本 (22)。不管在超级计算机的数量上还是排名上,美国在该领域都遥遥领先,而中国、法国、德国、英国和日本都有不俗的实力。其中特别是日本,虽然超级计算机的数量不多,但大都占据Top500较为靠前的位置,有着强劲的实力。值得一提的是,虽然美国是Top500上的头把交椅的常客,但中国和日本都在近10年内有机器问鼎。在目前Top500上进入前10名的机器,美国、欧洲、日本、中国都有,由此可以看到在超级计算机领域的激烈竞争。 本系列将以天河二号的发布为契机,旨在向公众介绍关于超级计算机及其相关背景知识。所涉及的内容包括超级计算机的排名方式、所采用的先进技术、世界部分知名的超级计算机 介绍等。另外,本系列文章也会简要介绍美国、欧洲、日本和中国的超级计算机发展历史和现状。通过以史为鉴,对未来在高性能计算领域各个国家的角力提供参考。
| |
|
(2个打分, 平均:4.00 / 5) |
七牛存储 。 《从技术人到创业者》
作者 陈怀临 | 2013-06-09 04:14 | 类型 行业动感 | 1条用户评论 »

2013 。《Silicon Valley Index》
作者 陈怀临 | 2013-06-09 03:47 | 类型 行业动感 | Comments Off

信息安全新领域——可信网络连接(TNC)架构的研究
作者 lightsource | 2013-06-06 16:03 | 类型 网络安全, 行业动感 | 1条用户评论 »
|
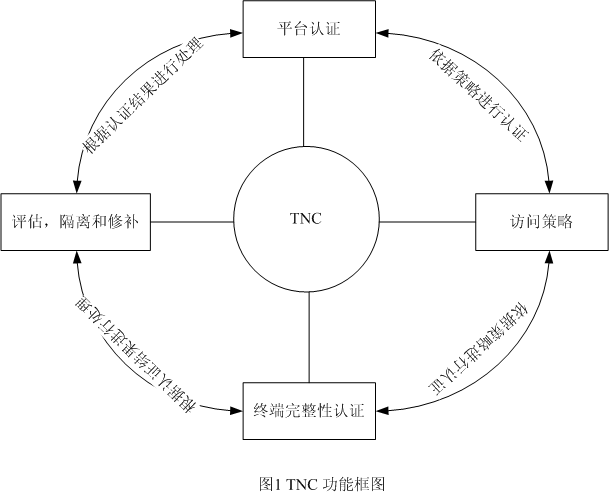
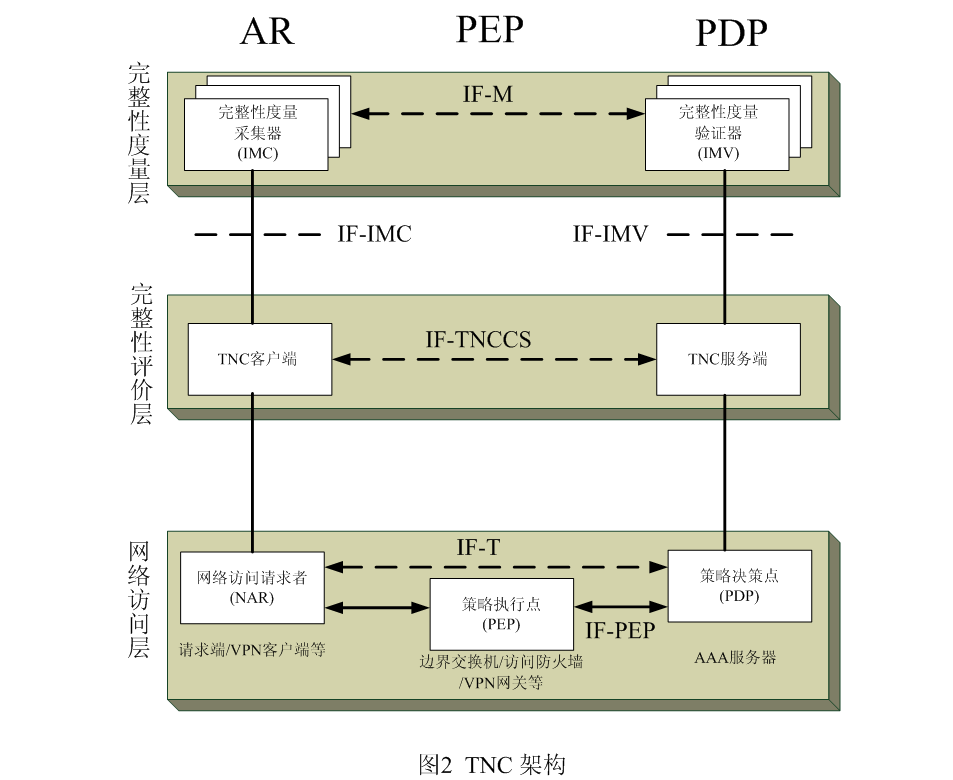
随着互联网应用的迅速普及,人们与网络的关系变得越来越紧密。然而,由于互联网具有开放性、互联性等特征,致使网络存在很多不安全因素,恶意软件的肆意攻击,黑客不轨的破坏行为都严重地威胁了人们的利益安全。因此,现在非常需要一套既能够保护计算机不受恶意攻击,又能够为访问网络提供安全保障的解决方案。 由可信计算组织(TCG)提出的可信网络连接(TNC)架构就是在这样的背景下产生的。TNC能够解决在网络环境下的终端安全问题,并且通过对终端进行完整性度量,来评估终端对于要访问网络的适用性,以便确保只有合法并且自身安全的终端才能够接入到网络。TNC利用结合终端完整性检验的访问控制技术,来实现终端主机的安全连接。本文首先对TNC架构进行深入研究,分析其中的各种原理与设计思想,然后对TNC架构进行实现。 TNC架构研究 TNC是TCG提出的一种新概念的模型,同时它也是一个开放的通用架构,TNC不依赖于具体的技术或者模型,但又能和各种技术进行良好的互操作。TNC架构将利用并且结合现存的网络访问控制技术,例如802.1x来提供下面的功能。 a、平台认证:验证一个网络访问请求者的平台身份和平台完整性验证。 b、终端完整性认证(授权):建立一个终端的可信等级,例如确保指令应用程序的表现,状态和软件版本,病毒签名数据库的完整性,入侵检测和防御系统程序,以及终端操作系统和程序的补丁等级。注意策略遵从性也可以被看作是授权,这种意义上终端完整性检验被当作授权决策的输入来获得对网络的访问。 c、访问策略:确保终端机器和/或它的用户授权并且公开了他们的安全状况在连接网络之前,利用一些现存的和出现的标准,产品或者技术。 d、评估,隔离和修补:确保那些要求访问网络的系统,但是不满足终端安全策略需求,能够被隔离或者检查从网络的其他部分,并且如果可能进行适当的修补,例如更新软件或者病毒签名数据库来加强对安全策略的适应并且使与网络其他部分的连接变得合格。 通过上述方法,TNC允许检验合格的终端能够接入网络,并且对检验不合格的终端,能够进行隔离修补。另外,通过对用户以及平台的认证,来确保用户及使用平台的合法性。 TNC架构 TNC架构采用服务器/客户端模式,从纵向考虑,TNC包含三个逻辑实体:访问请求者AR(Access Requestor),策略执行点PEP(Policy Enforcement Point)和策略决策点PDP(Policy Decision Point)。访问请求者是请求访问受保护网络的逻辑实体。策略执行点是执行PDP的访问授权决策的网络实体。策略决策点是根据特定的网络访问策略检查访问请求者的访问认证,决定是否授权访问的网络实体。 从横向考虑,TNC又分为完整性度量层、完整性评价层和网络访问层。
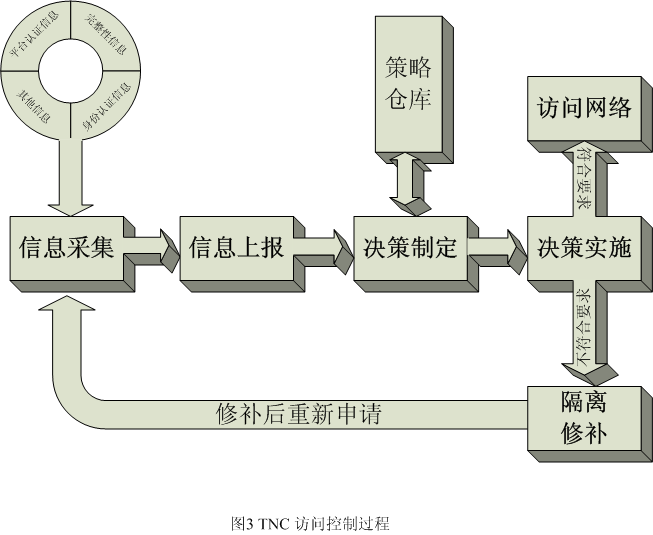
在TNC架构的设计中,重点强调了接入终端的完整性和安全性,充分体现的一个理念就是只有一台自身完整,并且具有很高安全度的终端主机才能接入到危险的网络环境中。所以,TNC在原有AAA架构的基础上,力图添加度量与报告终端完整性安全状态的内容,把它作为进行认证和授权的一部分。这样,在成熟的认证架构的基础上,TNC添加了平台证书认证,完整性检验握手等内容在很大程度上提高了访问网络的安全性。正是基于上述目的,TNC架构中的完整性度量层用来收集、度量、分析设备完整性信息,并把分析结果提供给完整性评价层使用,作为评价终端安全状态的依据。 TNC访问控制过程 如图3所示,TNC的访问控制过程包括信息采集、信息上报、决策制定、决策实施、隔离修补等几个步骤。首先,在信息采集阶段AR实体要收集一些关于终端的信息,包括是否安装反病毒软件,是否安装防火墙,是否给系统打补丁等一些设备完整性的信息,在图2中完整性采集器IMC(Integrity Measurement Collectors)主要负责收集信息的工作。然后,在信息上报阶段AR把这些信息通过策略实施点PEP发送给策略决策点PDP。在决策制定阶段,PDP根据先前制定好的策略,根据上报的各种信息来做出决策,其中图2中完整性分析器IMV(Integrity Measurement Verifiers)主要负责这项工作。在策略实施阶段,PDP把决策结果传达给PEP,如果检测合格,就允许终端访问网络,如果检测失败,就让PEP把终端进行隔离,并进行相应的修补工作,例如给终端安装最新的补丁,或安装防护软件等。在修补工作完成后,终端又可以重新申请访问网络资源,继续重复上面的过程。 | |
|
(没有打分) |
CMU老教授对Ph.D的理解
作者 lightsource | 2013-06-06 16:02 | 类型 学术园地, 海外学人, 行业动感 | Comments Off
|
多年前看到的CMU教授写给自己学生的一篇关于如何读Ph.D的文章,甚是经典,特转来与诸位共勉。
USEFUL THINGS TO KNOW ABOUT PH.D. THESIS RESEARCH (Prepared for “What is Research” Immigration Course, 1. Introduction 1. Introduction - Ph.D. thesis is treated very seriously at leading universities. * Expectation is high. - Ph.D. thesis represents a substantial work. Faculty * Ph.D. thesis research is a task to ensure that the student * Through the Ph.D. thesis process the student is * Faculty are judged by the theses of their Ph.D. students. * High standard Ph.D. thesis is probably one of the most * Ph.D. thesis is probably the only real challenge for - Ph.D. qualifier is seldom a problem for motivated - Ph.D. thesis research is probably more mechanical than a new * Knowing this mechanism can be more important than thesis * Some information presented here may be relevant to your - This talk consists of pragmatic advice. * The talk is based on my personal experience (i.e., not - I happen to have research experience in both theory * This is a common sense talk and will have down to earth - “I wish someone told me this before.” | |
|
(2个打分, 平均:2.00 / 5) |
信息时代存储的演变
作者 lightsource | 2013-06-05 07:13 | 类型 存储系统 | 5条用户评论 »
|
到底是信息技术的发展推动了存储,还是存储促进了信息技术的发展.可以说两者之间是一种相辅相成的关系。随着信息类型的多样化以及信息量的迅猛增长,对于存储的要求无疑越来越高。同时,随着存储设备单位存储粒度的不断提升以及存储设备价格的下降,也使得存储成本明显降低。(1956年,IBM最先引入了数据存储设备。第一块硬盘是1956年随IBM 305 RAMAC计算机一起出现的IBM Model 350磁盘。它由50个24英寸圆盘构成,总容量略小于5兆字节。)
为了能够观察存储的发展历史,需要对HDD(Hard Disk Drive)的进化过程进行研究。从1980年到2003年期间,HDD的存储密度提高了7个数量级,而相同设备所占用的空间却降低了7个数量级。同时,价格也降低了2.5个数量级。但是,比提高了存储密度以及降低的价格更有意义的是对于存储的新型应用出现了。在1996年,数字存储比用纸来存储更具性价比(证明了存储的价值);1998年,电影所使用的存储媒介也可以用更加经济的数字化实现(体现了对于存储的需求)。随着消费市场的兴起,对于机顶盒式存储设备的需求更加巨大,强有力的推动了存储的发展。同时,也引发了新型存储技术的研发。随着存储设备价格的不断降低以及存储能力的不断提高,直接影响了现有的存储架构。存储的管理功能在整个存储系统的花费中所占的比例大幅增加。用户已经由对存储设备的购买转向了对存储功能的购买,各种存储功能软件的出现也为信息的管理提供高效与安全保障。 随着存储设备的不断发展,存储系统的概念也逐步被建立起来。存储系统不单单包括硬件设备,同时也包含了软件部分,比如存储管理系统,操作系统等。存储已经不再是存储子系统的概念了,而是独立出来单独的系统。而且存储的目标不单是容量的扩充,也包括性能与可用性等方面。从信息技术整个演化过程来看,包括处理,传输与存储三大步骤。其中,信息的存储是前两者的重要保障。每一次存储技术的发展都带来了信息技术的变革。从早期对于单机设备之中关于存储设备的研究,到互连网络的发展,再到云计算,物联网等新型网络形态的出现,都与存储密切相关,现阶段逐步发展起来的集群存储是新型网络的有力支撑。在不同阶段都产生了很多存储技术,这些技术追求的目标都是高性能,高可靠,高可用,低成本。这些技术包括RAID,虚拟化,卷管理,容错,容灾备份,分级,镜像,自精简,快照,ISCSI等等。
单机的存储发展历程:刚开始存储直接由CPU控制,随着对于容量、性能以及可靠性需求的出现,人们开始在存储中引入多个控制器,从而加强可靠性。当RAID技术被引入后,存储系统的概念逐渐发展起来,期间也出现了备份系统,灾难恢复系统。这些组件共同组建了存储系统。同时由于RAID技术的不断发展,使得存储系统的性能与可用性都有了很大的提高,特别当校验的概念出现后。并且随着各种类型的存储介质共存现象出现,也需要将数据进行分级存储。同时,为了解决磁带的使用浪费现象,也是用了虚拟磁带技术。随着本机存储的发展告一段落,现阶段已经迎来了存储网络时代,NAS,SAN等不同的网络存储形态已经顺势而生,未来将对网络存储进行更多深入讨论。 | |
|
(2个打分, 平均:2.50 / 5) |


ARM Linux 3.x的设备树(Device Tree)
作者 zhangguoqiang | 2013-06-03 16:15 | 类型 弯曲推荐 | 3条用户评论 »
