




《产业互联网研讨论文集》(稿)
作者 陈怀临 | 2014-08-09 21:10 | 类型 科技普及 | 2条用户评论 »

经典文献: 麦卡锡 。《大数据:下一个竞争、创新和生产力的前沿领域》
作者 陈怀临 | 2014-08-07 11:06 | 类型 大数据 | Comments Off

北极光创投 。TMT投资 。高薪招聘 。北京 。上海
作者 陈怀临 | 2014-08-06 21:01 | 类型 行业动感 | Comments Off
|
联系方式:valleytalkjobs@gmail.com ————————————————— 北极光创投是一家以“扶持世界级的中国企业家,培育世界级的中国企业”为宗旨的风险投资机构。 创立于2005年的北极光,伴随着高速发展的中国经济快速成长。目前,旗下共管理3支美元基金和3支人民币基金,管理资产总额10亿美元。北极光创投的投 资机构来自美国、欧洲和亚洲的一流大学捐赠基金、主权基金、家族基金、慈善基金以及国内最优秀的政府背景的母基金等。 北极光先后在高科技,新媒体,通讯(TMT),清洁技术,消费及健康医疗等领域投资近百家公司。 北极光的投资团队在国内外都有丰富的投资、创业和管理经验,对国内外市场有深刻的了解,能够在所投资公司迅速成长的过程中提供必要的帮助。
投资策略
早期和成长期初期,“中国概念”,技术驱动型或商业模式创新型投资机会。
北极光专注于寻找早期和成长期初期的技术驱动型或商业模式创新型的“中国概念”企业。强调“团队,市场,创新”。“中国概念”指利用中国具有比较优势的生产要素,或中国自主研发的具有独立知识产权的技术,或以中国为主要市场。
投资阶段
投资阶段主要为早期和成长期初期,即企业在公开市场发行上市前的4-5年,同时也策略参与发行上市前1-2年的投资机会。
投资行业
通讯、媒体、高科技(TMT)领域为主,同时涵盖清洁技术、医疗健康、新材料、先进制造以及消费等多个行业。
福利特色
在北极光创投,我们倡导团队分享,独立平等; 在这里,浓郁的家庭文化感能让你更单纯和安心的工作; 在这里,每位员工携家属可以参加每年一度的公司度假游(一年国内,一年国外),来享受大家庭的温暖 ;
在这里,我们给员工承保高端的医疗保险(涵盖二位家属)和健康体检,让你对自己和家人的身心无后顾之忧;
在这里,我们每年提供给员工健身和学习教育费用,让你在付出的时候不要忘记健康和成长。
虽然我们还年轻,但我们着眼构建“百年老店”,我们付出耐心等待员工和公司一起成长,在此我们诚邀您的加入!更多信息,请登陆我们的公司主页:www.nlvc.com
我们需要:
合伙人高级业务助理
行业:TMT
工作地点:上海
职位描述:
1. 协同合伙人参加创业项目面谈及部分董事会,做好重要内容的整理;
2. 协助合伙人进行创业项目的初步接触及后期安排、跟踪;
3. 理顺并安排合伙人日常工作内容及会议,合伙人资源协调;
4. 撰写TMT相关投资项目报告及文件;
5. 协助合伙人日常业务相关助理工作的开展,例如各种会议的对外联系,演讲及会议内容的梳理等
任职资格:
1. 著名院校本科及以上学历,海外学习及工作经历者优先;
2. 聪明、主动,有较强的商业敏感度;沟通能力强,做事效率高,为人踏实可靠;
3. 了解投资的业务逻辑及原理;
4. 对TMT行业有天然的兴趣及悟性;
5. PPT技能较高,英语书写及口语流利。
投资总监/投资副总
行业:TMT
工作地点:上海/北京
职位描述:
1. 根据公司的投资策略和投资偏好,寻找合适的投资项目;
2. 较强的项目执行能力,包括不限于项目条款谈判、尽职调查、管理和控制整个投资过程;
3. 协助对于被投资企业的管理和提供增值服务,包括不限于提供发展战略建议、协助企业寻找
优秀人才、介绍业务合作等;
4. 定期参加行业会议,适时发声建立基金影响力。
任职资格:
1. 著名院校本科及以上学历;
2. VC行业背景出身,或是互联网行业从事运营或产品管理背景;
3. 对TMT行业有较深的理解,丰富的行业人脉关系;
4. 对行业有自己独立的观点和看法;
5. 英语书写及口语流利。
投资经理/投资分析师
行业:TMT
工作地点:上海/北京
职位描述:
1. 积极的通过各种渠道和方式接触创业项目;
2. 对国内TMT相关领域的梳理、接触和跟踪;
3. 负责国际TMT行业发展趋势的跟踪;
4. 对行业新技术、新模式的研究;
5. 协助参与部分投后管理工作.
任职资格:
1. 著名院校本科及以上学历;
2. 擅长人际沟通,较强的找项目能力;
3. TMT行业背景或媒体背景;
4. 了解投资的业务逻辑及原理;
5. 对TMT行业有天然的兴趣及悟性;
6. 英语书写及口语流利。 | |
 (没有打分) (没有打分) |
高端招聘:Pre-IPO公司市场总监
作者 陈怀临 | 2014-08-04 13:12 | 类型 行业动感 | Comments Off
|
地点:北京 . 公司: Pre-IPO公司。 著名VC投资 联系方式: valleytalkjobs@gmail.com
CMO招聘启事
工作职责: 1、
制定和实施年度市场推广计划,指导线上线下的商业活动计划;
2、
根据公司发展战略,制订公司中长期营销规划和目标,
3、
管理市场团队,并对团队成员和相关部门进行市场培训和指导。
4、
负责进行公司市场战略规划,制定公司的市场总体工作计划,
5、
负责协调涉及市场活动的各种关系;
6、
制定市场推广费用预算及市场部全年整体财务预算
7、
协调、统筹公司内外推广资源;密切沟通协调公司内部各职能部门,
8、
负责公司大客户的开发和维护,
9、
掌握市场动态,了解竞争对手发展进度,
10、
指导、参与市场的开拓、渠道管理等日常工作;
岗位要求: 1、
本科及以上学历,市场营销、广告、旅游等专业优先;
2、
8年以上市场营销推广经验,互联网、旅游行业优先考虑,
3、
具有丰富的海外生活或者出国旅行的优先;
4、
良好的人际沟通能力,分析能力,正直诚实,勤奋敬业,
5、
熟悉现代管理模式,熟练运用各种激励措施;s
6、
具备一定媒体及活动执行资源,能够整合发力;
7、
丰富的管理、协调、沟通、谈判及组织经验;
8、
流利英语交流掌握多门外语者优先;
9、
拥有丰富的高端人脉、客户资源者优先。
| |
|
(没有打分) |
Andrew Ng谈Deep Learning
作者 陈怀临 | 2014-08-04 09:05 | 类型 Deep Learning, 大数据, 机器学习 | Comments Off
|
《程序员》:Amara法则说,“我们倾向于高估科技的短期影响力,而又低估其长期影响力。”在你看来,Deep Learning的短期和长期影响分别是什么?历史上,我们曾对实现人工智能有过错误估计,对于Deep Learning的前景,人们是否过于乐观?
Andrew Ng:我对Deep Learning的前景很乐观,它的价值在过去几年已得到印证,未来我们还会沿着这个方向继续努力。语音识别、计算机视觉都将获得长足进步,数据与科技的碰撞,会让这一切变得更具价值。在短期,我们会看到身边的产品变得更好;而长期,它有潜力改变我们与计算机的交互方式,并凭借它创造新的产品和服务。
不过围绕Deep Learning,我也看到存在着某种程度的夸大,这是一种不健康的氛围。它不单出现于媒体的字里行间,也存在于一些研究者之中。将Deep Learning描绘成对人脑的模拟,这种说法颇具吸引力,但却是过于简化的模仿,它距离真正的AI或人们所谓的“奇点”还相当遥远。目前这项技术主要是从海量数据当中学习,理解数据,这也是现今有关Deep Learning技术研究和产品发展的驱动力。而具备与人的能力相匹配的AI需要无所不包,例如人类拥有丰富的感情、不同的动机,以及同感能力。这些都是当下Deep Learning研究尚未涉及的。
《程序员》:关于神经网络的研究,在很多方面依靠生物学、神经科学等领域。在你看来,Deep Learning的模型是否已经完善?若没有,目前最大的缺陷或困难在于何处?
Andrew Ng:Deep Learning模型尚未完善,主要存在两项挑战。一项是可扩展性,我们坐拥海量数据,却难以建造计算能力足够强大的计算机系统,处理这些数据。我青睐百度的原因之一,即在于它拥有复杂而强大的海量数据处理基础架构,但对Deep Learning来说,问题尚未得到解决。另一项挑战在于算法,我们也不知道恰当的算法是什么。从这两点看,尽管我们已取得了不小的进步,但前路依然漫漫。
《程序员》:为了开发智能机器,许多年前,Daniel Hillis和他的Thinking Machines曾尝试突破von Neumann架构,你觉得当今的硬件是否是实现智能机器的最好选择?如果不是,当前的计算机架构有哪些限制,我们需要做哪方面的突破?
Andrew Ng:这是一个有趣的话题。我们尚不知道怎样的硬件架构是智能机器的最佳选择,因而更需要拥有灵活性,快速尝试不同的算法。在这方面,GPU相对易于编程,因而可以高效地尝试不同的算法。作为对比,ASIC(专用集成电路)的运行速度比GPU更快,但开发适合Deep Learning的ASIC难度高、周期长,在漫长的研发过程中,很可能我们早已发现了新算法。
GPU与CPU结合是目前的首选硬件平台,不过随着技术的进一步成熟,这种现状有可能发生改观。例如,目前已有几家初创公司正在研发专门用于Deep Learning的硬件系统。
《程序员》:有一种说法是,对人脑机制理解的缺乏是我们开发智能机器的最大限制之一,在这个存在许多假设和未知的前沿领域进行研究,你怎样判断自己研究的方向和做出的各种选择是否正确?
Andrew Ng:诚然,神经科学尚未揭开人脑的运作机制,是对这项研究的一种制约。但如今我们尝试的算法,大多只是粗略地基于神经科学研究的统计阐释,这些研究启迪我们的灵感,鼓励我们尝试新算法。但现实中,我们更主要地依据算法真实的运行效果进行评判,假如一味追求模拟神经的运作方式,不一定能带来最优的结果。有时我们偏重神经科学原理,例如某些模拟大脑局部的算法;但更多时候,性能是准绳。若按比例划分,前者大约只占2%,后者则占据98%。
因为我们不知道何种算法最优,所以才不断尝试,衡量是否取得进步的方式之一(并非唯一方式),是观察新算法能否在应用中表现得更好,例如Web和图像搜索结果是否更准确,或者语音识别的正确率更高。假如回望五年,你就会发现,那时我们曾认为颇有前景的算法,如今已然被抛弃。这些年,我们有规律地,甚至偶然地发现一些新算法,推动着这个领域持续前进。
《程序员》:关于Deep Learning的原理,已有许多人知晓。为了做出一流研究和应用,对于研究者来说,决胜的关键因素是什么?为何如今只有少数几人,成为这个领域的顶尖科学家?
Andrew Ng:关于决定因素,我认为有三点最为关键。
首先是数据,对于解决某些领域的问题,获取数据并非轻而易举;其次是计算基础架构工具,包括计算机硬件和软件;最后是这个领域的工程师培养,无论在斯坦福还是百度,我都对如何快速训练工程师从事Deep Learning研究,成为这个领域的专家思索了很长时间。幸运的是,我从Coursera和大学的教学经历中获益良多。创新往往来自多个观念的整合,源于一整支研究团队,而非单独一个人。
从事Deep Learning研究的一个不利因素在于,这还是一个技术快速发展的年轻领域,许多知识并非依靠阅读论文便能获得。那些关键知识,往往只存在于顶尖科学家的头脑中,这些专家彼此相识,信息相互共享,却不为外人所知。另外一些时候,这群顶尖科学家也不能确定自己的灵感源于何处,如何向其他人解释。但我相信,越来越多的知识会传递给普通开发者;在百度,我也正努力寻找方法,将自己的灵感和直觉高效地传授给其他研究者。尽管我们已有这方面的教程,但需要改进之处仍有很多。
此外,许多顶尖实验室的迭代速度都非常快,而Deep Learning算法复杂,计算代价很高,这些实验室都拥有优秀的工具与之配合,从快速迭代中学习进步。
《程序员》:十年前,Jeff Hawkins在《On Intelligence》中已经向普通人描述了机器与智能之间的关系,这些描述与我们现在看到的Deep Learning似乎非常相似。在这最近的十年中,我们新学到了什么?
Andrew Ng:包括我在内,Jeff Hawkins的作品启发了许多AI研究者,多年以前,我个人还曾是Hawkins这家公司的技术顾问之一。但在现实中,每个人的实现细节和算法迥异,与这本书其实颇有不同。例如在书中,Hawkins极为强调与时间相关的临时数据的重要性,而在Deep Learning中,虽然用到了临时数据,但远没有那重要,另外网络的架构也大不相同。在最近十年中,我们认识到了可扩展的重要性,另外我们还找到了进行非监督式学习更好的方式。
关于工作选择
《程序员》:为什么选择百度开展你的工作,它的哪些特点,是你觉得其他公司所不具备的?
Andrew Ng:我喜欢在任务高度驱动的环境下工作,通常我是这些任务的发起者。我为能更好地发展AI,令互联网上的每个人都能从中受益而兴奋。
几个月前,我仔细评估了几个选项后,决定加入百度。一方面在于王劲团队打造了非常优秀的基础设施,同时百度还拥有庞大的数据。另一方面,我为百度的灵活快速所吸引,当我的朋友余凯和徐伟决定搭建GPU集群,马上就得到了实现,此外没有任何一家公司推出Deep Learning产品的速度快过这里,而且还是应用在互联网广告这种核心业务上。对于Deep Learning这样未知因素很多的技术来说,灵活性至关重要。我还发现北京的互联网公司讨论的往往是日活跃用户,而在硅谷则是月活跃用户,或许这也可以作为灵活性的一个注解。
还有一点我很少谈起,却非常重要——因为这里的人。与他们相处,我感到非常愉快。当我开始在百度工作后,妻子Carol曾对我说,她从未见过我如此努力,却又如此开心。
《程序员》:你在百度的研究产品和成果能为外界带来什么(例如是未来否有可能将你的成果共享给其他人,推动整个领域的发展)?
Andrew Ng:我希望能将成果与外界分享,也许不是所有内容都适合,但希望通过某种形式,分享我们的研究。不过我加入的时间尚短,接下来我希望能有更多成果可以公布。 | |
 (2个打分, 平均:3.00 / 5) (2个打分, 平均:3.00 / 5) |
科技一周~The Age of AI
作者 硅谷寒 | 2014-08-03 15:54 | 类型 硅谷科技周报 | Comments Off
系列目录 科技一周
科技一周~The Age of AI 2014/08/02 下一个时代是什么?我想,那不会是最好的时代,也不是最坏的时代,只是个平凡的,历史早已注定的时代:人工智能。 2011年初春,午后阳光暂时偷走了硅谷里的料峭寒意,在山景城(Mountain View)的临街转角处,渐渐多起了行人,以及她们的低眉细语。我正坐在一间叫做Red Rock的咖啡馆里,却忽然看到一个机器人进来,径直走到前台,点了一块蛋糕。当咖啡师(Barista)故意询问它,“是在店内吃呢,还是带走?”,全屋子的人们都笑了出来。毫无疑问,机器人自然是要把蛋糕带回去给主人吃的。
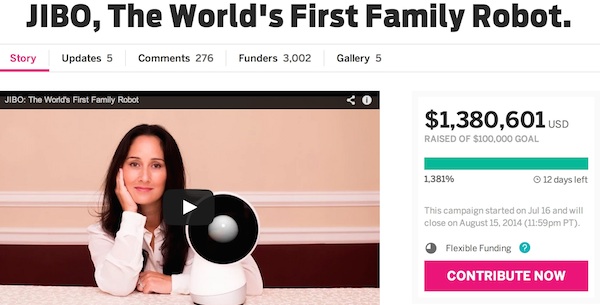
本周来聊一下在机器人设计中几乎必备的一项技术:目标跟踪(Object Tracking)。在上文中提到的两个机器人,都离不开这项技术,比如,JIBO通过内嵌的可以360度旋转的摄像头来捕捉并跟踪家庭成员的面容,然后根据脸部分析,拍下一张最好的全家福照片。那么JIBO是如何做到跟踪人脸呢?当然,第一步是要先识别出来人脸,关于识别的技术有待以后再讲。今天要讲的是识别出来之后的跟踪技术。 相对于识别技术,跟踪技术并不是在单一图像上实现的,而是利用了连续的多帧图像。可以说,如果图像识别是个二维技术,那么目标跟踪则是个三维(多了个时间上的维度)技术。当机器人在当前帧上识别出来某个物体后,那么它需要在下一帧里快速的“跟踪”上这个物体,并不需要重新分析整个下一帧图像(因为如果重新分析的话,那么速度就太慢了,达不到实时的效果)。在目标跟踪技术里,一个很关键的算法是运动估计(Motion Estimation),越快速地估计出下一帧里的运动方向,则可以越快速的跟踪上目标。 运动估计的算法有很多种,其本质上是一种搜索算法。在当前的硬件设计里,最常用的是基于块匹配的递归搜索算法:3D recursive search block matching[3]。这个算法是利用当前帧的运动向量值,在下一帧的几个备选向量里,搜索出来最匹配的像素块,从而确定下一帧的运动向量。这种算法在最初的几帧里,并不能找到真正的运动向量,但由于它的递归迭代性,当经过十几帧之后,估计的运动向量就会收敛到真正的向量值。通常,摄像头采集的频率在30~60Hz,也就是说,该算法可以在0.25秒~0.5秒的时间里跟踪上目标物体。这样的跟踪速度,基本上可以满足家庭的需要了。
[1]. JIBO, the world’s first family robot, https://www.indiegogo.com/projects/jibo-the-world-s-first-family-robot , July 2014. [2]. Brandon Griggs, Hitchhiking robot is halfway across Canada, http://www.cnn.com/2014/08/01/tech/social-media/hitchhiking-robot-hitchbot/, July 2014. [3]. G. de Haan, P. W. A. C. Biezen, H. Huijgen, and O. A.Ojo, “True-motion estimation with 3-D recursive search block matching,” IEEE Trans. Circuits Syst. Video Tech., vol. 3, no. 5, pp. 368-379, Oct. 1993. 图2. [1]. | |
|
(没有打分) |


科技一周~那时未必花开,只有曾经的年少
作者 硅谷寒 | 2014-08-01 10:32 | 类型 硅谷科技周报 | Comments Off
系列目录 科技一周
科技一周~那时未必花开,只有曾经的年少 2014/07/27 小时候,我家附近有一些樱花树,听祖母说,是当年日本人栽的,曾经盛开过,整树整树都是白色的花瓣,但不知出于何种原因,自八十年代以来,这些樱花树便再也不曾绽放过。那时,我经常一个人偷跑出去,给樱花树浇水,梦想着某天之后,会有无数的樱花在我面前盛开。二十年过去了,我的梦想并没能变成现实,樱花树依然瘦骨嶙峋地立在原地,直到有天被市政厅的人将它们一一拔去。 如今我已长大,虽不再奔跑呼喊,却从未失去梦想,心中仍有一株“樱花”,正自生根发芽,静静地在那里,等着我来看它美丽的绽放。当然,偶有彩云飘过,我也会回想往事:那时未必花开,只有曾经的年少。 本周的科技新闻,等来的正是Amazon,这株没有盛开的“樱花树”:
本期科普将围绕着樱花树的“存活性”来聊一聊:)试想,倘若我在事先就知道那些樱花树早已死亡,根本不会开花,我便不会再浪费时间去浇灌它们。那么,我该如何去判断樱花树是否能盛开呢?我不是植物学家,自然无法判断,但我的目的是,把这一概念类比到机器学习里来。在机器学习理论里,有一个很重要的判断,就是“某一个待学习的概念是不是可学习的”?类比我的樱花树,就是“这一株待浇灌的樱花树是不是可存活的”?只有事先判定了概念的“可学习性”,我们再去设计相应的算法来学习它,才会有意义。 哈佛大学教授Leslie Valiant[2]给出了一种概率意义下的“可学习性”判断:PAC Learnability。简单说来:如果在某种算法下,某个待学习的“真实概念”与逼近它的“假设概念”可以在概率意义下达到误差为零,那么这个“真实概念”就是PAC可学习的。对照计算理论里的时间复杂度和空间复杂度,Leslie定义了机器学习算法中的样本复杂度,并给出了PAC可学习概念的样本量下限值。这个“样本复杂度”可以类比为,我浇灌樱花树的难度,简而言之,就是“我们需要多少样本才可以学习好一个概念”vs“我需要浇灌多少水才能看到樱花盛开”。其实,在前述BookLamp的新闻里,其推荐算法中要学习的“书籍类型”就是一个PAC可学习的概念,有兴趣的同学不妨参考[3]中Conjunction of Boolean Literals的例子。当然,真正实现起来,要比[3]里例子复杂一些。Leslie Valiant也凭此奠基性的理论,获得了2010年度的ACM图灵奖。
[1]. Josh Constine, Ingrid Lunden, http://techcrunch.com/2014/07/25/apple-booklamp/, July 2014. [2]. http://amturing.acm.org/award_winners/valiant_2612174.cfm, 2010. [3]. Mehryar Mohri, “Foundations of Machine Learning”, ISBN-13: 978-0262018258, The MIT Press, August 2012, pp. 18-19. 图1. http://timedotcom.files.wordpress.com/2014/07/amazon-q2-2014-earnings-report.jpg?w=1100 图2. [1]. | |
|
(没有打分) |


{kind=link}
{kind=link}