




《 孙钟秀 。操作系统教程》注释(稿)--第六章:文件管理
作者 陈怀临 | 2014-12-27 12:16 | 类型 操作系统, 科技普及 | Comments Off

存有超过2PB肿瘤基因组数据的GDC将于2015年开始运行
作者 弯曲评论 | 2014-12-27 12:06 | 类型 生物医学 | Comments Off
|
12月2日,芝加哥大学跟美国国家癌症研究中心联合宣布启动用于存储肿瘤基因组数据的Genomics Data Commons项目(简称GDC),项目负责人是芝加哥大学的Robert Grossman教授。
众所周知,NCI资助了大量的肿瘤研究项目,比如TCGA。这些项目累计完成了超过一万个病人的基因组测序工作,但这些数据都散落在各地。NCI觉得应该把这些数据攒在一起,发挥更大的作用。根据GDC项目的Q&A,这些数据总共有大约2.2PB。GDC未来每年会增加1PB的存储以应对NCI的新项目。
新闻稿里面专门说明:“GDC所使用的存储和分析技术跟Google和Facebook等公司使用的技术很相似”。相似到什么程度?NoSQL?HDFS?Spark?还是Spanner?不得而知。
Grossman在生物云计算耕耘很久了。他领导了 Open Science Data Cloud项目(https://www.opensciencedatacloud.org/)。通过芝加哥大学内部的合作开发了The Bionimbus Protected Data Cloud,这是唯一一个由NIH资助的用于存储TCGA项目数据的云计算平台。
感觉NCI已经是科研主管机构中在云计算方面最激进的组织了。刚刚给ISB、Broad和SBG发了1900多万美元用于建设癌症云计算平台,现在又启动了用于存储数据的GDC。
NCI似乎已经把数据存储和数据分析拆成了两个部分。两个部分之间的接口会如何设计?GA4GH的Genomics API会得到NCI这些项目的支持吗?ISB、Broad和SBG的癌症云计算平台如何跟GDC进行对接与合作?美国人依然在领跑全世界,2015年肯定会有更加精彩的东西。
我们的差距依然明显,无论是数据量、成果还是投入。863、973等诸多癌症研究项目产生的数据还捏在极少人的手中,落满灰尘。
比历史,我们已经没办法了。1937年8月5日,富兰克林罗斯福总统签署美国癌症法案,成立了NCI。在此前一周,日本借口卢沟桥事件全面占领北平。未来呢?我们还有机会。 | |
 (1个打分, 平均:5.00 / 5) (1个打分, 平均:5.00 / 5) |
Hadoop之父聊大数据和他LOGO里的那只象!
作者 弯曲评论 | 2014-12-24 11:35 | 类型 大数据 | Comments Off
|
(来自 英特尔商用频道 微信公众平台)
英特尔中国研究院院长吴甘沙先生首先进行了分享。院长分别从数据的爆炸式发展、英特尔大数据的分析框架、研发布局以及与Cloudera在中国的合作进行几个方面进行了讲演。
大家经常听说在我们IT这个产业有这样一种指数的规律,而这样一种规律如果应用到传统的产业来说是不得了的事情。
下面这条曲线前面经过长时间的缓慢增长,一旦过了临界点以后,就会产生爆发式的增长,如果在这么一个时间点T,它是X的话,下一个时间点就是X的平方,如果X是一个大数的话,这样一个指数规律使得在任何一个周期里面,它的新的值将远远把前一个周期的值抛在后面。
比尔盖茨曾经有一个比喻:如果汽车产业像IT产业这么发展的话,到现在我们一辆汽车是25美金,一加仑汽油能够跑一千英里,这就是指数带来的威力。
大数据要说人话,它要提取人能够理解的价值,怎么能够让数据的工具跟我们的人,跟数据科学家,跟领域专家,跟我们的终端用户天人合一,降低数据分析的门槛,这又是一个挑战。
基于这些挑战,英特尔推出了大数据的分析框架,在最底层是基础设施,计算存储互联成为软件可定义,我们把它做成开放式、模块化的这些标准的模块,使得我们行业能够降低门槛,更多的创新者能够进来。
上面一层是数据平台,我们跟Cloudera一起推动基于Apache Hadoop开放、可信的数据处理平台,推动整个生态基础创新,上面是分析应用,我们希望能够把高级的分析功能平民化,使得它能够迈入主流的应用,使得它能够实现规模的经济。最上面是解决方案,我们跟生态系统伙伴一起构建示范性的解决方案,把它变成可扩展的参考架构,使得在示范的领域成功能够被复制到每一个行业、每一个企业上面去。 | |
 (没有打分) (没有打分) |
百度语音识别新突破–Deep Speech系统
作者 AbelJiang | 2014-12-24 11:33 | 类型 Deep Learning, 机器学习 | Comments Off
|
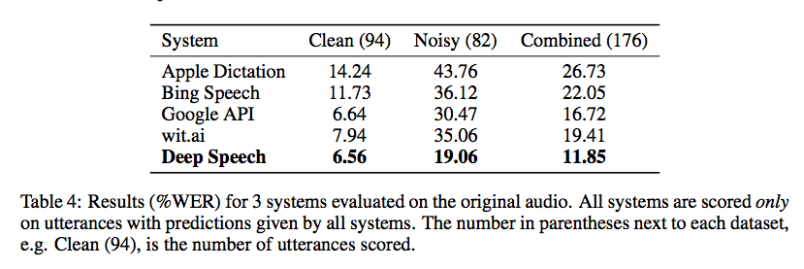
原文转载自:https://gigaom.com 相关论文:DeepSpeech: Scaling up end-to-end speech recognition Chinese search engine giant Baidu says it has developed a speech recognition system, called Deep Speech, the likes of which has never been seen, especially in noisy environments. In restaurant settings and other loud places where other commercial speech recognition systems fail, the deep learning model proved accurate nearly 81 percent of the time. That might not sound too great, but consider the alternative: commercial speech-recognition APIs against which Deep Speech was tested, including those for Microsoft Bing, Google and Wit.AI, topped out at nearly 65 percent accuracy in noisy environments. Those results probably underestimate the difference in accuracy, said Baidu Chief Scientist Andrew Ng, who worked on Deep Speech along with colleagues at the company’s artificial intelligence lab in Palo Alto, California, because his team could only compare accuracy where the other systems all returned results rather than empty strings.
Ng said that while the research is still just research for now, Baidu is definitely considering integrating it into its speech-recognition software for smartphones and connected devices such as Baidu Eye. The company is also working on an Amazon Echo-like home appliance called CoolBox, and even a smart bike. “Some of the applications we already know about would be much more awesome if speech worked in noisy environments,” Ng said. Deep Speech also outperformed, by about 9 percent, top academic speech-recognition models on a popular dataset called Hub5’00. The system is based on a type of recurrent neural network, which are often used for speech recognition and text analysis. Ng credits much of the success to Baidu’s massive GPU-based deep learning infrastructure, as well as to the novel way them team built up a training set of 100,000 hours of speech data on which to train the system on noisy situations. Baidu gathered about 7,000 hours of data on people speaking conversationally, and then synthesized a total of roughly 100,000 hours by fusing those files with files containing background noise. That was noise from a restaurant, a television, a cafeteria, and the inside of a car and a train. By contrast, the Hub5’00 dataset includes a total of 2,300 hours. “This is a vast amount of data,” said Ng. ” … Most systems wouldn’t know what to do with that much speech data.”
Another big improvement, he said, came from using an end-to-end deep learning model on that huge dataset rather than using a standard, and computationally expensive, type of acoustic model. Traditional approaches will break recognition down into multiple steps, including one called speaker adaption, Ng explained, but “we just feed our algorithm a lot of data” and rely on it to learn everything it needs to. Accuracy aside, the Baidu approach also resulted in a dramatically reduced code base, he added. You can hear Ng talk more about Baidu’s work in deep learning in this Gigaom Future of AI talk embedded below. That event also included a talk from Google speech recognition engineer Johan Schalkwyk. Deep learning will also play a prominent role at our upcoming Structure Data conference, where speakers from Facebook, Yahoo and elsewhere will discuss how they do it and how it impacts their businesses. | |
|
(2个打分, 平均:1.00 / 5) |

《 孙钟秀 。操作系统教程》注释(稿)--第五章:设备管理
作者 陈怀临 | 2014-12-17 12:28 | 类型 操作系统, 科技普及 | Comments Off

【邢波】机器学习需多元探索,中国尚缺原创引领精神
作者 陈怀临 | 2014-12-17 11:49 | 类型 Deep Learning, 机器学习, 科技普及 | 1条用户评论 »
|
【邢波Eric P. Xing】清华大学物理学、生物学本科;美国新泽西州立大学分子生物学与生物化学博士;美国加州大学伯克利分校(UC,Berkeley)计算机科学博士;现任美国卡耐基梅隆大学(CMU)计算机系教授,2014年国际机器学习大会(ICML)主席。美国国防部高级研究计划局(DARPA)信息科学与技术顾问组成员。(他在中国大数据技术大会上的报告请参考阅读原文链接) Professor of Carnegie Mellon University Program Chair of ICML2014Dr. Eric Xing is a Professor of Machine Learning in the Schoolof Computer Science at Carnegie Mellon University. His principal researchinterests lie in the development of machine learning and statisticalmethodology; especially for solving problems involving automated learning,reasoning, and decision-making in high-dimensional, multimodal, and dynamicpossible worlds in social and biological systems. Professor Xing received aPh.D. in Molecular Biology from Rutgers University, and another Ph.D. inComputer Science from UC Berkeley.
【杨静lillian】这次您受邀来中国参加大数据技术大会,在您看来,中国大数据相关技术和生态发展到了什么水平?与美国的差距主要体现在哪些方面? 【邢波Eric P. Xing】中国的大数据技术与题目跟进国外趋势还做得不错。但在原创性部分有欠缺。也许由于工程性,技术性上的原创工作通常不吸引眼球且风险极大这样的特点,所以没人愿意啃硬骨头。整体不算太差,但缺少领军人物,和领先的理念。还有在导向上,倾向于显著的效益和快的结果,但对于学术本身的追求不是很强烈。如果效果不是立竿见影,愿意碰的人就少。大部分人都这样,就是趋向于平庸。整个生态系统上看,中国大数据发展水平与欧洲、日本比并不差,公众的认知也热烈。整个环境还蛮好。与中国学生有点像,群体不见得差,但缺少特别杰出的领袖,和有胆识的开拓者。
人工智能的目标没有上限,不应以人脑为模板
【杨静lillian】您说过深度学习只是实现人工智能目标的一种手段,那么在您看来,人工智能的目标到底是什么?抛开《奇点临近》的科学性,您认为机器智能总体超越人类这个目标在2050年前后有可能实现么?或者说在2050年前后,世界的控制权会不会由人工智能主导? 【邢波 Eric P. Xing】人工智能的目标其实是没有上限的。人工智能的目标并不是达到动物或人类本身的智力水平,而是在可严格测量评估的范围内能否达到我们对于具体功能上的期待。例如用多少机器、多长时间能达成多少具体任务?(这里通常不包含抽象,或非客观任务,比如情绪,感情等。)人的智力不好评价,尤其标准、功能、结果及其多元,很多不是人工智能追求的目标。科幻家的浪漫幻想和科学家的严格工作是有区分的。大部分计算机科学家完成的工作可能不那么让人惊叹,但很多任务已经改变世界。例如,飞机自动驾驶装置可能没有人的智能,但它完成飞行的任务,却比人类驾驶员好。 再比如弹钢琴,机器也可以弹钢琴,精确程度肯定超过人。但是否有必要发明机器人代替人弹钢琴来上台表演,或机器人指挥家甚至机器人乐队?从这个角度看,我个人没有动力或必要去发明机器人来弹钢琴,至少我不认为应该去比较机器和人类钢琴家。钢琴大师如霍洛维茨,鲁宾斯坦是不能被机器替代的、比较的,虽然他们也弹错音。一个武术大师,如果现在用枪来和他比武力,把他打死,有意义吗?那么标准是什么?我认为我们应该去想和做一些更有意义和价值的事情。 关于2050年的未来预测,如果非要比较的话,我认为人工智能不会达到超越人类的水平,科学狂人或科幻家也许喜欢这样预测未来,博得眼球,但科学家需要脚踏实地做有意义的工作。所谓奇点是根本不可能的。未来学家这样去臆测也许是他们的工作;政治家、企业家、实践学家向这个方向去推动则是缺乏理性、责任和常识;而科学家和技术人员去应和,鼓吹这些则是动机可疑了? 人工智能脱离人类掌控?这种可能性不能排除。但要是咬文嚼字的话,如果是计算机的超级进步涌现出智能,以至脱离人类掌控而自行其道,那还何谓“人工”?这就变成“自然智能”。我认为“世界的控制权会不会由人工智能主导”这类题目定义就不严肃,无法也无益做科学讨论,也不能被科学预见。
【Ning】能否通俗科普一下机器学习的几个大的技术方向,和它们在实践中可能的应用。 【邢波 Eric P. Xing】很难科普的讲,不使用专业术语。机器学习不过是应用数学方法体系和计算实践的一个结合,包罗万象。比如图模型(深度学习就是其中一种),核(kernel)方法,谱(spectral)方法,贝叶斯方法,非参数方法,优化、稀疏、结构等等。我在CMU的机器学习课和图模型课对此有系统全面的讲解。 机器学习在语音、图形,机器翻译、金融,商业,机器人,自动控制方面有广泛的应用。很多自然科学领域,例如进化分析,用DNA数据找生物的祖先(属于统计遗传的问题),需要建模,做一个算法去推导,数学形式和求解过程与机器学习的方法论没有区别。一个成熟的,优秀的机器学习学者是应被问题、兴趣和结果的价值去激励、推动,而不是画地为牢,被名词所约束。我本人在CMU的团队,就既可以做机器学习核心理论、算法,也做计算机视觉、自然语言处理,社会网络、计算生物学,遗传学等等应用,还做操作系统设计,因为底层的基本法则都是相通的。
【李志飞】大数据,深度学习,高性能计算带来的机器学习红利是不是差不多到头了?学术界有什么新的突破性或潜在突破性的新算法或原理可以把机器学习的实际应用性能再次大幅提升? 【邢波 Eric P. Xing】大数据、深度学习、高性能计算只是接触了机器学习的表层,远远不到收获红利的时候,还要接着往下做。算法的更新和变化还没有深挖,很多潜力,空间还很大。现在还根本没做出像样的东西。另外我要强调,机器学习的所谓红利,远远不仅靠“大数据、深度学习、高性能计算”带来。举个例子,请对比谷歌和百度的搜索质量(即使都用中文),我想即使百度自己的搜索团队也清楚要靠什么来追赶谷歌。
【Ning】世界各国在机器学习方面的研究实力如何?从科普的角度来看,人的智能和人工智能是在两个平行的世界发展么? 【邢波 Eric P. Xing】不太愿意评价同行的水平。人的智能和人工智能可以平行,也可以交互。
【杨静lillian】您既是计算机专家,还是生物学博士,在您看来,如果以未来世界整体的智能水平作为标准,是基因工程突破的可能性大,还是人工智能领域大,为什么? 【邢波 Eric P. Xing】基因工程其实突破很多。在美国和全球转基因的食品也有很多。胰岛素等药物也是通过转基因菌株来生产,而不是化学合成。诊断胎儿遗传缺陷的主要手段也基于基因工程技术。但是舆论风向在变,也不理性。例如我小时候读的《小灵通看未来》里,“大瓜子”等神奇食品现在已经通过基因技术实现。从技术上看,我们已经实现了这个需要,但公众是否接受,是个问题。科学家要对自己的责任有所界定。例如造出原子弹,科学家负责设计制造,但怎么用是社会的事。 人工智能领域也已经有很多应用型的成果,但也还有很大空间。人工智能就是要去达到功能性的目标,有很多事情可以用它去达成,但这里不见得包括感情思考。人的乐趣就是感情和思考,如果让机器代替人思考,我认为没有这个需要。 靠基因工程提升人的智能基本不可能,人的成就也未必与基因完全相关,例如冯.诺依曼,很大程度是后天环境教育形成的。基因只是必要条件,而非充分条件。作为一个生物学博士,我反对用基因工程改变人的智能的做法,认为这很邪恶。科学家应该对自然法则或上帝有所敬畏。在西方,优生学是不能提的,因为它违反了人本主义的原则和人文人权的理念。我个人认为这个题目在科学道德上越界了,是不能想象的。
【杨静lillian】您说过美国的大脑计划雷声大雨点小,请问欧盟的大脑工程您怎么看,会对人工智能发展起到促动作用么?或者说,人工智能研究是否应以人的大脑为模型? 【邢波 Eric P. Xing】欧洲大脑工程的争议很大,包括目标和经费分配。但这个目标也提升了社会和公众的对于科学的关注,工程的目的不用过于纠结。这个项目就是启发式的,培养人才,培养科学实力的种子项目。 大脑工程,无论欧洲和美国,对人工智能发展没有直接的促进作用。以仿生学来解释人工智能工程上的进步,至少在学术上不是一个精确和可执行的手段,甚至是歧路。只是用于教育公众,或者通俗解释比较艰深的科学原则。 人工智能不必也不应以人脑为模型。就像飞机和鸟的问题,两者原理手段完全不同。人工智能应该有自己的解决办法,为什么要用人脑的模型来限制学科的发展?其实有无数种路径来解决问题,为什么只用人脑这一种模板?
机器学习领域应多元探索,巨大潜力与空间待挖掘
【李志飞】更正一下我的问题: 现有的机器学习算法如深度学习在利用大数据和高性能计算所带来的红利是不是遇到瓶颈了?(至少我所在的机器翻译领域是这样) 接下来会有什么新机器学习算法或原理会把大数据和高性能计算再次充分利用以大幅提升应用的性能?我觉得如果机器学习领域想在应用领域如机器翻译产生更大的影响,需要有更多人做更多对应用领域的教育和培训,或者是自己跨界直接把理论研究跟应用实践结合起来 【邢波 Eric P. Xing】机器学习的算法有几百种,但是目前在深度学习领域基本没有被应用。尝试的空间还很大,而且无需局限在深度学习下。一方面机器学习学者需要跨出自己的圈子去接触实际,另一方面应用人士也要积极学习,掌握使用发展新理论。
【杨静lillian】您认为谷歌是全球最具领导性的人工智能公司么?您预测人工智能技术会在哪几个领域得到最广泛的应用?人工智能产业会像互联网领域一样出现垄断么? 【邢波 Eric P. Xing】谷歌是最具有领导性的IT公司。世界上没有人工智能公司,公司不能用技术手段或目标定义名称和性质。人工智能是一个目标,而不是具体的一些手段。所以有一些界定是不严肃的。关于应用领域前面已经谈过了。
【杨静lillian】您曾经比喻,中国的人工智能领域里,有皇帝和大臣,您怎么判断中国人工智能产业的发展水平和发展方向?最想提出的忠告是什么?
【邢波 Eric P. Xing】中国整个IT领域,以至科学界,应该百花齐放,有的观点占领了过多的话语权,别的观点就得不到尊重。目前业界形成一边倒的局面,媒体的极化现象比较严重。建议媒体应该平衡报道。中国目前深度学习话语权比较大,没人敢批评,或者其他研究领域的空间被压缩。这种研究空间的压缩对机器学习整个领域的发展是有害的。学界也存在有人山中装虎称王,山外实际是猫的现象。坦率的说,目前中国国内还没有世界上有卓越影响的重量级人工智能学者,和数据科学学者。中国需要更多说实话,戳皇帝新衣的小孩,而不是吹捧的大臣、百姓和裸奔的皇帝。不要等到潮水退去,才让大家看到谁在裸奔。 现在一些舆论以深度学习绑架整个机器学习和人工智能。这种对深度学习或以前以后某一种方法的盲目追捧,到处套用,甚至上升到公司、国家战略,而不是低调认真研究其原理、算法、适用性和其它方法,将很快造成这类方法再次冷却和空洞化,对这些方法本身有害。行外人物、媒体、走穴者(比如最近在太庙高谈阔论之流)对此的忽悠是很不负责的,因为他们到时可以套了钱、名,轻松转身,而研发人员投入的时间、精力和机会成本他们是不会在乎的。美国NSF、军方和非企业研究机构与神经计算保持距离是有深刻科学原因的,而国内从民到官这样的发烧,还什么弯道超车,非常令人怀疑后面的动机和推手。
【杨静lillian】确实如您所说,现在大多数中国企业或学术机构,被一个大问题困扰。就是缺乏大数据源,或者缺乏大数据分析工具,那么怎样才能搭上大数据的时代列车呢? 【邢波 Eric P. Xing】首先我没有那样说过,我的看法其实相反。即使给那些企业提供了大数据,他们真会玩么?这有点叶公好龙,作为一个严肃的研究,应该把工具造出来。得先有好的技术,别人才会把数据提供给你。有时小数据都没做好,又开始要大数据,没人会给。可以用模拟,更可以自己写爬网器(crawler)自己在网上抓。例如我们的实验室,学生就可以自己去找数据源。研究者的心态有时不正确,好像社会都需要供给他,自己戴白手套。其实人人都可以搭上“大数据”这个列车,但需要自己去勤奋积极努力。
【杨静lillian】Petuum开源技术系统会成为一种大数据处理的有效工具么?可以取代Spark? 【邢波 Eric P. Xing】希望如此。更客观地说,不是取代。是解决不同的问题,有很好的共生、互补关系。
中国学术界的原创性待提高,缺乏灯塔型领军人物
【刘成林】@杨静lillian问题提的好!期待详细报道。另外我加一个问题,请Eric给中国人工智能学术界提点建议,如何选择研究课题和如何深入下去。 【邢波 Eric P. Xing】希望中国人工智能学术界要对机器学习、统计学习的大局有所掌控,全面判断和寻找,尚未解决的难题。这需要很多人静下来,慢下来,多读,多想。而不是跟风或被热点裹挟。得有足够的耐心,屏蔽环境的影响和压力。在技术上得重视原创性,如果只把学术看成是一个短时期的比赛,价值就不大。得找有相当难度,而自己有独特资源的方向,就保证了思想的原创性和资源的独特性。要分析清楚自己的优势。 例如我们做的Petuum,很多人就不敢碰。我们开始时甚至都不懂操作系统,从头学;我们放缓了步子,两年近十人只出两篇文章。但不尝试怎么知道?得给自己空间。
【张宝峰】邢老师提到过在机器学习领域,美国可以分成几个大的分支,比如Jordan 算一个,能否再详细的阐述还有哪些其他分支和流派? 【邢波 Eric P. Xing】这算八卦。原来有几个流派,但现在流派的界限已经非常模糊了。
【刘挺-哈工大】您认为哪些方向或组织有希望出现领军人物? 【邢波 Eric P. Xing】国内的同行思路有些短板,所以研究领域比较割裂。上层不够高,下层也不够深,横向也不宽,因此扎根不够,影响有限。所以比较缺憾,体现为很多割裂的领域。 在中国的企业界和学术界哪里会出现领军人物?这个问题我认为:对什么叫“领军人物”国内的同行的定义还相当肤浅,功利。除了商业上的成功,或者学术上获奖,这些显性成就,还需要有另外的维度。例如从另外一个角度,具有个人魅力,他的思想、理论、人格被很多人追随和推崇的,有众多门生甚至超越自己的,就没有。中国的研究者不善于建立自己的体系,去打入一个未知的境界,做一个灯塔型的人物。这种人物在中国特别少,基本上没有。 在美国M.Jordan就是这样的人物,就有灯塔型的效应,被众人或学术界效法,敬佩,和追随,包括他的反对者。他也不是中国最典型的最年轻教授等成功人物,而是大器晚成,到了45岁才开始发扬光大,上新台阶。但他的做为人的魅力(会五国语言,年轻时弹琴挣钱,平时风趣博学);他的勤奋自律(到Berkeley后正教授了还和我们一起在课堂听课,从头学统计,优化,到现在还天天读文献);他的工作和生活的平衡(现在自己组乐队,和孩子玩儿);他的众多学生的成就(很多方向和他大不相同,甚至相对);他的严谨,严肃的学风;和他的洞察力。这些都是除了学术成就之外他成为领军人物的要素。我们国内知识分子接近这个境界的太少了。不要说学术上的差距,就连上餐桌品酒、懂菜,说话写作遣词造句的造诣都差不少。所以,先不要急出领军人物;先从文化上培育土壤,培育认真、一丝不苟的习惯和精神,培育热爱教学、热爱学生的责任;培育洁身自好、玉树临风的气质;注重细节、小节、修养,再由小至大、由士及贤、由贤入圣。在这个境界上,学问就变成一种乐趣了,就可以做出彩了。
【张宝峰】欢迎回国,把Pleuum变成实际产业标准。 【邢波 Eric P. Xing】不是没有可能,但也需要好的平台和环境、机缘。这次回国参会,很兴奋的是,学术界和产业界都对机器学习的技术有很大的热情,也有信念去获取成功,相当积极。我个人的观点,通过交流,收获很大。期望这种交流继续,也期待国内的学界、媒体、企业能够共同促进产业生态的发展,利益多样化。可以是金钱的成功,也可以是原创性的增长。而不是被某一个目标来一统天下。 如果回国发展,应该有更多商业上的机会。但是国内的起点低,有些规则两国不一样。现在人生的目标不是钱,而是对乐趣的满足,以及服务社会。实现自我的价值,也让家人,朋友,学生,师长,同事开心。 下个月还有机会回国,到时也期待与大家继续交流互动。非常感谢@杨静lillian 提供这个和大家交流的机会。也钦佩她专业敬业。这次结识很多朋友,后会有期! | |
|
(3个打分, 平均:5.00 / 5) |
谷歌斯坦福“说图”
作者 AbelJiang | 2014-12-17 11:46 | 类型 行业动感 | Comments Off
|
内容比较冗长,没有把插图加进来,但插图很直观的反应了效果,可以点进链接看,也可以跳过新闻看干货,点击以下链接: 1.Stanford University Technical Report 2.Show and Tell: A Neural Image Caption Generator by Google 3.Deep Visual-Semantic Alignments for Generating Image Descriptions by Stanford MOUNTAIN VIEW, Calif. — Two groups of scientists, working independently, have created artificial intelligence software capable of recognizing and describing the content of photographs and videos with far greater accuracy than ever before, sometimes even mimicking human levels of understanding. Until now, so-called computer vision has largely been limited to recognizing individual objects. The new software, described on Monday by researchers at Google and at Stanford University, teaches itself to identify entire scenes: a group of young men playing Frisbee, for example, or a herd of elephants marching on a grassy plain. The software then writes a caption in English describing the picture. Compared with human observations, the researchers found, the computer-written descriptions are surprisingly accurate. The advances may make it possible to better catalog and search for the billions of images and hours of video available online, which are often poorly described and archived. At the moment, search engines like Google rely largely on written language accompanying an image or video to ascertain what it contains. “I consider the pixel data in images and video to be the dark matter of the Internet,” said Fei-Fei Li, director of the Stanford Artificial Intelligence Laboratory, who led the research with Andrej Karpathy, a graduate student. “We are now starting to illuminate it.” Dr. Li and Mr. Karpathy published their research as a Stanford University technical report. The Google team published their paper on arXiv.org, an open source site hosted by Cornell University. In the longer term, the new research may lead to technology that helps the blind and robots navigate natural environments. But it also raises chilling possibilities for surveillance. During the past 15 years, video cameras have been placed in a vast number of public and private spaces. In the future, the software operating the cameras will not only be able to identify particular humans via facial recognition, experts say, but also identify certain types of behavior, perhaps even automatically alerting authorities. Two years ago Google researchers created image-recognition software and presented it with 10 million images taken from YouTube videos. Without human guidance, the program trained itself to recognize cats — a testament to the number of cat videos on YouTube. Current artificial intelligence programs in new cars already can identify pedestrians and bicyclists from cameras positioned atop the windshield and can stop the car automatically if the driver does not take action to avoid a collision. But “just single object recognition is not very beneficial,” said Ali Farhadi, a computer scientist at the University of Washington who has published research on software that generates sentences from digital pictures. “We’ve focused on objects, and we’ve ignored verbs,” he said, adding that these programs do not grasp what is going on in an image. Both the Google and Stanford groups tackled the problem by refining software programs known as neural networks, inspired by our understanding of how the brain works. Neural networks can “train” themselves to discover similarities and patterns in data, even when their human creators do not know the patterns exist. In living organisms, webs of neurons in the brain vastly outperform even the best computer-based networks in perception and pattern recognition. But by adopting some of the same architecture, computers are catching up, learning to identify patterns in speech and imagery with increasing accuracy. The advances are apparent to consumers who use Apple’s Siri personal assistant, for example, or Google’s image search. Both groups of researchers employed similar approaches, weaving together two types of neural networks, one focused on recognizing images and the other on human language. In both cases the researchers trained the software with relatively small sets of digital images that had been annotated with descriptive sentences by humans. After the software programs “learned” to see patterns in the pictures and description, the researchers turned them on previously unseen images. The programs were able to identify objects and actions with roughly double the accuracy of earlier efforts, although still nowhere near human perception capabilities. “I was amazed that even with the small amount of training data that we were able to do so well,” said Oriol Vinyals, a Google computer scientist who wrote the paper with Alexander Toshev, Samy Bengio and Dumitru Erhan, members of the Google Brain project. “The field is just starting, and we will see a lot of increases.” Computer vision specialists said that despite the improvements, these software systems had made only limited progress toward the goal of digitally duplicating human vision and, even more elusive, understanding. “I don’t know that I would say this is ‘understanding’ in the sense we want,” said John R. Smith, a senior manager at I.B.M.’s T.J. Watson Research Center in Yorktown Heights, N.Y. “I think even the ability to generate language here is very limited.” But the Google and Stanford teams said that they expect to see significant increases in accuracy as they improve their software and train these programs with larger sets of annotated images. A research group led by Tamara L. Berg, a computer scientist at the University of North Carolina at Chapel Hill, is training a neural network with one million images annotated by humans. “You’re trying to tell the story behind the image,” she said. “A natural scene will be very complex, and you want to pick out the most important objects in the image.” | |
|
(1个打分, 平均:5.00 / 5) |
思科起诉Arista Networks 。起诉书全文 。解密
作者 陈怀临 | 2014-12-10 18:47 | 类型 行业动感 | 1条用户评论 »

亚信大数据 。《产业互联网入口初探-下一个二十年IT人改变世界的机会》
作者 陈怀临 | 2014-12-09 21:05 | 类型 行业动感 | 1条用户评论 »
|
之所以要聊起这个话题,一方面是因为入口这个词近几年开始变得火热,另一方面,从田董事长提出产业互联网的概念开始,大家都在试图寻找产业互联网的入口在哪。 那么,我们首先从消费互联网开始。 (一)消费互联网入口的洗牌与颠覆 最近几年,我们看到了越来越多的新鲜事。 小米不到四年做到了400亿美元估值,成为仅次于BAT的第四大互联网公司。阿里和腾讯两大巨头,半年时间就在打车软件上烧了近20个亿。罗永浩仅靠一张嘴就拿到了千万风头,做出了锤子手机。
这几件事都与“入口”这个词有或多或少的关联。入口的本质是连接人与信息的通道,体现的是人们获取信息的形式,比如手机可以是一个入口,手机里的APP也可以是一个入口。 什么才是真正有价值的入口,其实没有定论。消费互联网时代,一波又一波的互联网人,不断的试图构建、推翻和重建人们访问互联网的路径。从以上几个例子也可以看出一些端倪。 小米的高估值,MIUI功不可没。MIUI作为跨平台的操作系统入口,随着纵向的黄页、商店、支付等功能的不断丰富,横向的手机、智能家居、可穿戴设备的不断延伸,其入口价值已经逐渐开始显现。有人曾说MIUI是小米的最后一道防线,其实,MIUI不仅仅是一道防线,更是未来小米能够实现“连接一切”的终极目标的希望。 快的打车和嘀嘀打车的疯狂补贴,源于对移动支付入口的渴望。阿里和腾讯以激励改变习惯,试图通过无卡支付入口来打破银联靠一个POS机就能坐地分钱的状态,并获取因入口连接而带来的价值增值。这将移动支付入口混战的局面进一步推向高潮。结果,阿里和腾讯的支付用户数短期大幅增加,银联无限恐慌,早在2012年即推出的“闪付”,推进缓慢。 仅从现在的情况看,强调工匠精神的锤子手机似乎只是做一款纯粹的产品,这条路看起来步履维艰。如果罗永浩不能早日从其OS出发进行社交化和跨平台的布局,昙花一现的结果也许是注定的。 这三个入口的例子,分别是手机操作系统,手机APP和手机。所以我们看到,入口形态是多样的。但是不仅如此,入口还可能变化。 在互联网出现以前,电视和报纸曾经是非常重要的入口。在智能手机出现以前,桌面PC是一个比手机重要得多的入口。现在,一切都变了。 入口代表的价值,像是传统行业的“渠道为王”,传统行业生产的是产品,产品流通的关键地位使得国美苏宁这样的渠道成为强势入口。而消费互联网生产的是信息,信息需求的多样性和增长速度远甚于传统行业,这使得消费互联网入口的形态多样并且容易发生变化。消费互联网的入口越来越像是一个生态系统,正由简单变得越来越复杂。 什么是入口生态系统?简单来说,就是需求和供给围绕着入口聚集,有生产有消费,有协作有互补。生态系统的特性决定了入口需要规模性的用户。所以,有价值的入口,首先要有足够多的用户,然后还能留住这些用户。 如何获取这足够多的用户就是我们要解决的第一个问题。 总结消费互联网的成功企业,我们发现,有四种手段,在入口用户的积累上被广为使用,他们分别是技术手段、成本手段、体验手段和情感手段。 依靠不断更新迭代的领先技术,英特尔在桌面处理器市场上睥睨天下,占据了桌面处理器近九成的市场份额。360杀毒依靠免费手段迅速抢占市场,将瑞星、金山、卡巴斯基等行业元老遥遥甩在身后。iPhone不是首部触摸大屏手机,但却是重新定义了行业格局,其产品设计从本质上改变了技术导向的方式,而在用户体验上做到了极致。小米成功的核心,黎万强总结为“参与感”, 核心就是让用户参与进来,建立一个可触碰、可拥有,和用户共同成长的品牌,靠粉丝情感获取了千万用户。从这一个个鲜活的例子,我们看到了入口用户积累的策略。 不过,用户的获取只是一个开始。老祖宗有句话,创业难,守业更难。如何留住这些用户就是我们要解决的第二个问题。 先进的技术,合理的价格,良好的体验,大批的粉丝的确可以获取大批量的用户,如微软英特尔,地位看似已无可动摇。但是,我们提到危险时,总喜欢说“危险的角落”。因为,入口的颠覆经常发生在外部或者边缘。蒸汽机、汽车、计算机、互联网等技术的发明,在促进社会发展的同时,无不给当时如日中天的某个行业造成了毁灭性打击。当前,移动端和桌面端的份额变化也说明了,微软的敌人不是其他的桌面系统厂商而是谷歌和苹果。英特尔最大的对手也不是AMD而是高通。 这是入口攻守策略的第一个观点:外部式、边缘式创新将颠覆入口形态。 飞信和米聊做的都比微信早,用户基数也曾经很庞大,但是后来却是微信横扫了市场,这是因为,飞信只是一个产品,而微信却发展成为了一个生态。生物学告诉我们,如同麦田与森林一样,生态系统越简单,越容易被颠覆,越复杂则越趋于稳定。所以,以微信为连接集成的大量的周边服务,形成了一个复杂的生态系统,现在已变得牢不可破。 所以我们看到,以产品为核心的诺基亚倒在了Android系统+应用商店+众多手机品牌的生态组合拳之下。 而小米则以多元化的方式结构化和复杂化自己的生态:MIUI系统、小米手机、小米盒子、小米电视、小米路由器、小米手环……最终实现以MIUI为入口连接整个生态系统。 这是入口攻守策略的第二个观点:产品可以简单,生态一定复杂。去年年初,当所有人在替百度思考搜索以后还是不是第一入口的时候,李彦宏直接挂帅移动部门,意图增强以搜索为核心的移动互联网生态。去年年底,腾讯15周年大会上,马化腾提出了通往未来的“七个路标”,第一是“连接一切”,而微信将作为重要入口进行“连接一切”的尝试。 今年年初,在支付宝实名用户数朝着3亿进发的时候,马云通过浙江融信收购了恒生集团100%的股权,被外界视作支付宝平台入口的进一步纵向延伸。 消费互联网的入口之争,本质就是一个不断洗牌与颠覆的过程。 (二)产业互联网入口的混沌与初醒 BAT这三家企业,在消费互联网领域有很强的代表性,他们分别是搜索入口、电商入口和社交入口的掌控者。 除了这些,我们还能看到安全入口(360)、旅游入口(携程)、视频入口(优酷土豆)……这些入口造就了很多十亿、百亿、甚至千亿美金的公司。 这看上去真是一个令人激动的信息,那么产业互联网的入口在哪?要不要马上开工,开始布局搜索、支付和社交? 别急,产业互联网的入口形态,与消费互联网有着非常大的差异。 互联网的入口形态归根结底是由需求所决定。消费互联网的需求主体是个人,人与人以及人与信息通过各种入口来连接。而在产业互联网领域,入口实现的是企业与企业之间的连接,承载的是流通过程中的信息。 我们知道,商流、物流、资金流和信息流是流通过程中的四大组成部分,企业和企业之间的连接也基于此。商流主要是指买卖交易活动和商情信息流动,物流则涵盖了运输、储存、流通加工、配送、信息处理等过程,资金流是在企业间因业务活动而发生的资金往来,信息流既包括各类商品信息、营销信息、售后信息等内容,也包括交易方的支付能力和信誉。 据此,我们就有了一个最基本的判断:产业互联网的入口,将围绕着交易活动、商品流转、资金往来和信息流动四者形成服务性连接。并且基于我们对于商业流通的理解,从这些服务性连接的核心点出发,我们可以看到,交易活动的公平性、商品流转的高效性,资金流转的安全性,信息流动的充分性将是影响整个流通环节非常关键的要素。 明白了这些,产业互联网的入口似乎变得有些眉目。 第一,从交易的公平性角度出发,不公正条款和欺瞒性信息是两大核心难点。前者多是利用自身在产业链上的优势地位迫使关联企业接受不公正的格式条款。后者则是利用信息的不对称,通过欺骗或者隐瞒的方式达到趋利避害的目的。前者问题似乎源远流长且永远存在。而对于后者,不少企业也在某些垂直链条上做了很多的尝试和努力,征信平台便是一例。 目前,银行的金融征信系统相对成熟和稳健,但是其局限性也很明显。由于银行征信系统的目的是降低授信风险,关注偿债能力。所以其数据流有两大特征,一是偏向偿债能力的资产数据,二是偏向企业和银行之间的链式数据而非企业间的网状数据。但是企业与企业的交易性连接,不止限于资金层面的往来,这使得银行征信系统面对企业合作、企业并购、企业投融资以及竞争性决策等领域均不具备相当的指导意义。 因此,解决企业间欺瞒性信息的问题,银行征信系统并不能完全满足我们的需求,产业互联网需要更全面的,更网络化的征信平台来促进交易公平。由此我们也得到了第一个产业互联网入口:交易活动公平要求的平台级征信中心。 第二,随着人工、能源等成本的持续推高,商品流转已经成为困扰企业最严重的问题之一。2005年顺丰速运的年营业额是16亿,2012年暴增到了200亿。顺丰的高速成长印证了商品流转领域的大市场和大机遇。 信息化和智能化,是社会发展的两个演进阶段。顺丰在信息化阶段实现了全过程业务信息实时监控与调度,包括客户下单、上门收件、运输调度、储存保管、转运分拨、快件集散、流通加工、信息服务等诸多物流功能要素的数据收集与监管。而顺丰的演进方向,则是实现智能的动态实时控制,通过整合内部商品数据、客户数据,外部气候数据、交通数据等关键数据集,实现全自动的流程控制和优化。马云的菜鸟网络,也志在于此。 值得注意的是,估值达到300亿元的顺丰只是一个实体物品的快递物流公司,所选择的领域只是商品流转过程中的一部分。所以,在未来,各类非实体物品诸如能源等非实体商品的广义流转过程,蕴含着无限的市场机遇。想象一下亿万人能够在网上分享自己多余的能源,就像我们现在在网络上分享信息一样。而这种能源互联网和智能物流一样,仅仅是整个物联网统一平台的一个组成部分。由此,我们得到了第二个产业互联网入口:商品高效流转要求的平台级物联网中心。 第三,与消费互联网的小额支付不同,企业间支付通常是以现汇、承兑和电汇三种方式进行的大额支付,且移动支付的需求暂时并不强烈。这是因为,消费互联网领域的个人支付关注的更多的是效率和体验,所以我们看到,简化了非常多的验证机制的支付宝快捷支付受到广泛的追捧。银行有苦难言,为了规避安全风险设置的一大堆文本合同和流程机制反而成为限制客户使用的桎梏。而企业支付关注的更多的是安全和保密,并不过分追求极致效率和客户体验。因此对企业间支付入口来说,安全是一桩大生意。 以安全为突破点形成一个全面的企业支付入口生态,以数据云的方式连接政府、金融机构、企业及其上下游的安全厂商和硬件厂商,实现智能的安全布控与风险识别,将成就第三个产业互联网入口:资金安全往来要求的平台级的安全中心。 第四,消费互联网努力打破个人,与个人的信息不对称,而产业互联网则致力于减少企业和企业之间的信息不对称。而实现这一目标的方式,就是使数据充分的共享和流动。 无数例子可以证明在大数据领域1+1>2的事实,但是大家都是想通过得到外部数据而非贡献自己的数据来形成数据合力。这里面最重要的原因就是,没有一个合适的平台来让数据流动更具合理性和高效性。 如何判断数据流动形成价值后,谁的贡献更大?如何保证数据流动后数据不被别人拿走?如何保证数据流动的成本不高于由此带来的价值提升?……一系列问题将伴随数据流动而生,而这些问题的答案就是构建一个规范的、前瞻的平台级数据交易中心。唯有交易,才是促进流动的不二法门。这便是产业互联网的第四个入口:信息充分流动要求的平台级数据交易中心。 在以上入口尚未真正形成的时候,如何建立入口并获取规模性的企业用户就成为先决问题。我们谈到消费互联网入口积累用户可以依靠技术、免费、体验和情感四种手段,产业互联网入口的用户积获取策略是否可以照搬前面探讨的消费互联网的用户获取策略? 如果有技术垄断的实力,这应当是获得用户的最直接方式。但是,一个不容置疑的事实就是,当前在企业软件领域,开源已经成为趋势,技术垄断变得越来越难。与单一企业的软件工程师相比,开源拥有庞大的开源网络开发社区,通过开放式的社区模式,让形形色色的不同企业参与到研发队伍中来。未来的关键软件可能不是由某家企业开发出来,而是由分布在全球不同地方的开发企业共同完成。可以预见,在不久的将来靠卖许可证赚钱的商业模式将终结,软件即服务将会体现得更加明显。通过极具优势的技术获取用户,目前还将是重要的手段,但是提高个性化服务水平才是未来的策略。 免费在消费互联网极为常见,但是在产业互联网鲜有案例。这是因为,免费的商业模式依赖的是以互联网广告为主的后向付费模式。而互联网广告面对的更多的是个人客户市场,对于企业客户而言,传统广告行销仍然占据主流。只有当免费形成的入口能够带来相关领域的增值时,免费策略才有意义。 用户体验在对个人用户来说以感官体验和使用体验为主,但是在企业间连接中,这两种体验都要让步于效率体验。通过特殊的流程或技术形成的产品作为一个入口如果可以使企业间的连接效率获得成倍提高,那么此入口的用户积累就会变得非常容易。 情感与消费互联网领域所指差异更大,获取和维系企业间服务性连接的情感因素,指的不是所谓的粉丝或情怀,而是“人际关系”。这一点毋庸多言。
以上分析,仅是针对流通领域形成的企业连接来探讨产业互联网的入口形态和用户获取策略,权作抛砖引玉。不过关于产业互联网的入口形态和客户积累策略,现在还处于混沌状态。谁能初醒、布局、发力,谁就有可能成为产业互联网的BAT。 | |
 (4个打分, 平均:3.75 / 5) (4个打分, 平均:3.75 / 5) |
The Wall Street Journal吴恩达专访
作者 AbelJiang | 2014-12-08 13:47 | 类型 Deep Learning, 机器学习, 行业动感 | Comments Off
|
原文转载自:http://blogs.wsj.com Six months ago, Chinese Internet-search giant Baidu signaled its ambitions to innovate by opening an artificial-intelligence center in Silicon Valley, in Google’s backyard. To drive home the point, Baidu hired Stanford researcher Andrew Ng, the founder of Google’s artificial-intelligence effort, to head it. Ng is a leading voice in “deep learning,” a branch of artificial intelligence in which scientists try to get computers to “learn” for themselves by processing massive amounts of data. He was part of a team that in 2012 famously taught a network of computers to recognize cats after being shown millions of photos. On a practical level, the field helps computers better recognize spoken words, text and shapes, providing users with better Web searches, suggested photo tags or communication with virtual assistants like Apple’s Siri. In an interview with The Wall Street Journal, Ng discussed his team’s progress, the quirks of Chinese Web-search queries, the challenges of driverless cars and what it’s like to work for Baidu. Edited excerpts follow: WSJ: In May, we wrote about Baidu’s plans to invest $300 million in this facility and hire almost 200 employees. How’s that coming along? Ng: We’re on track to close out the year with 96 people in this office, employees plus contractors. We’re still doing the 2015 planning, but I think we’ll quite likely double again in 2015. We’re creating models much faster than I have before so that’s been really nice. Our machine-learning team has been developing a few ideas, looking a lot at speech recognition, also looking a bit at computer vision. WSJ: Are there examples of the team’s work on speech recognition and computer vision? Ng: Baidu’s performance at speech recognition has already improved substantially in the past year because of deep learning. About 10% of our web search queries today come in through voice search. Large parts of China are still a developing economy. If you’re illiterate, you can’t type, so enabling users to speak to us is critical for helping them find information. In China, some users are less sophisticated, and you get queries that you just wouldn’t get in the United States. For example, we get queries like, “Hi Baidu, how are you? I ate noodles at a corner store last week and they were delicious. Do you think they’re on sale this weekend?” That’s the query. WSJ: You can process that? Ng: If they speak clearly, we can do the transcription fairly well and then I think we make a good attempt at answering. Honestly, the funniest ones are schoolchildren asking questions like: “Two trains leave at 5 o’ clock, one from …” That one we’ve made a smaller investment in, dealing with the children’s homework. In China, a lot of users’ first computational device is their smartphone, they’ve never owned a laptop, never owned a PC. It’s a challenge and an opportunity. WSJ: You have the Baidu Eye, a head-mounted device similar to Google Glass. How is that project going? Ng: Baidu Eye is not a product, it’s a research exploration. It might be more likely that we’ll find one or two verticals where it adds a lot of value and we’d recommend you wear Baidu Eye when you engage in certain activities, such as shopping or visiting museums. Building something that works for everything 24/7 – that is challenging. WSJ: What about the self-driving car project? We know Baidu has partnered with BMW on that. Ng: That’s another research exploration. Building self-driving cars is really hard. I think making it achieve high levels of safety is challenging. It’s a relatively early project. Building something that is safe enough to drive hundreds of thousands of miles, including roads that you haven’t seen before, roads that you don’t have a map of, roads where someone might have started to do construction just 10 minutes ago, that is hard. WSJ: How does working at Baidu compare to your experience at Google? Ng: Google is a great company, I don’t want to compare against Google specifically but I can speak about Baidu. Baidu is an incredibly nimble company. Stuff just moves, decisions get made incredibly quickly. There’s a willingness to try things out to see if they work. I think that’s why Baidu, as far as I can tell, has shipped more deep-learning products than any other company, including things at the heart of our business model. Our advertising today is powered by deep learning. WSJ: Who’s at the forefront of deep learning? Ng: There are a lot of deep-learning startups. Unfortunately, deep learning is so hot today that there are startups that call themselves deep learning using a somewhat generous interpretation. It’s creating tons of value for users and for companies, but there’s also a lot of hype. We tend to say deep learning is loosely a simulation of the brain. That sound bite is so easy for all of us to use that it sometimes causes people to over-extrapolate to what deep learning is. The reality is it’s really very different than the brain. We barely (even) know what the human brain does. WSJ: For all of Baidu’s achievements, it still has to operate within China’s constraints. How do you see your work and whether its potential might be limited? Ng: Obviously, before I joined Baidu this was something I thought about carefully. I think that today, Baidu has done more than any other organization to open the information horizon of the Chinese people. When Baidu operates in China, we obey Chinese law. When we operate in Brazil, which we also do, we obey Brazil’s law. When we operate in the U.S. and have an office here, we obey U.S. law. When a user searches on Baidu, it’s clear that they would like to see a full set of results. I’m comfortable with what Baidu is doing today and I’m excited to continue to improve service to users in China and worldwide. | |
|
(没有打分) |