




弯曲财经:欧债危机告一段落 市场或迎来回调
作者 ibluesea | 2011-10-31 06:05 | 类型 弯曲财经, 行业动感 | 16条用户评论 »
|
上周欧债危机的戏剧达到了阶段的高潮,继周末峰会之后,周三抛出了一个欧债危机的解决方案,提出要把救援资金扩大四倍,同时还要让债券投资人自己消耗50%的损失。同时,还暗示说资金也可能来自外储充沛的我国。消息一出,市场疯狂上涨,整个一周都在疯狂上涨中度过,欧洲各大银行的涨幅都在2位数以上。标普从1075点回升到1290左右只用了很短的时间。 | |
  (2个打分, 平均:3.00 / 5) (2个打分, 平均:3.00 / 5) |
MapCG: Writing Parallel Program Portable between CPU and GPU
作者 陈怀临 | 2011-10-30 07:22 | 类型 科技普及 | 3条用户评论 »

申威1600处理器是自主指令集,系统也得自己编,可喜可贺!
作者 cracked | 2011-10-30 07:16 | 类型 行业动感 | 41条用户评论 »
|
http://bbs.zhongsou.com/3/20111030/2903592.html 人民网济南10月27日电(记者徐锦庚)今天上午,国家超级计算济南中心正式建成挂牌,这是国内首台全部采用国产中央处理器(CPU)和系统软件构建的千万亿次计算机系统,标志着我国成为继美国、日本之后第三个能够采用自主CPU构建千万亿次计算机的国家。山东省省委书记姜异康,山东省省长姜大明,第十一届全国政协教科文卫体委员会主任、中科院院士徐冠华为济南中心揭牌。省委常委、副省长孙伟,省委常委、济南市市委书记焉荣竹,济南市市长张建国出席揭牌仪式。 高性能计算机的研制能力和应用水平是一个国家科技发展水平和综合国力的重要标志之一,也是世界发达国家竞相争夺的科技战略制高点。为此,我国《国家中长期科学和技术发展规划纲要》将千万亿次高效能计算机研制列入了优先主题,科技部明确要求掌握千万亿次高效能计算机研制的关键技术,并将“高效能计算机及网格服务环境”列为“十一五”863重大项目。 国家超级计算济南中心是科技部批准成立的全国3个千万亿次超级计算中心之一,由山东省科学院计算中心负责建设、管理和运营。济南中心使用的神威蓝光千万亿次系统由国家并行计算机工程技术研究中心按照万万亿次架构设计,装机8704片16核的“申威1600”处理器,是在国家“核高基”重大专项支持下、由国家高性能集成电路(上海)设计中心自主研发,采用自主指令集。 经国家权威机构测试,济南中心神威蓝光系统线性系统软件包效率为74.4%。系统全面采用高密度组装和低功耗技术,单机仓组装密度1024个CPU,系统性能功耗比超过741MFLOPS/W(每瓦功耗所获取的运算性能),组装密度和性能功耗比居世界领先水平,系统综合水平处于当今世界领先行列。济南中心的建设成功,实现了国家大型关键信息基础设施核心技术的自主可控目标,符合国家自主创新科技发展战略。 在建设济南中心的同时,山东省科学院始终坚持建设与应用相结合,多次组织项目团队针对海洋、石油、金融、动漫、农业、工业、大型工程等领域或行业的计算需求进行调研,充分挖掘用户应用。近期,为配合“山东半岛蓝色经济区”和“黄河三角洲高效生态经济区”两大国家发展战略,促进国产神威蓝光千万亿次系统应用,山东省科学院在山东省科技厅支持下,设立了“山东省超级计算科技专项”,首期已开展海洋科学、新药研制、气象预报、金融分析、工业仿真等领域中的一些重点课题,并保证应用稳定运行。 山东省科学院依托国家超级计算济南中心,坚持“技术研发、计算服务和人才培养”三位一体的工作思路,引进和培养专业人才,探索万核规模的并行框架、支持语言以及调试环境等前沿技术,深入研究计算模型与算法、并行识别与优化、海量数据处理、虚拟化和平台运维等超级计算关键技术,开发行业重大应用软件,提供高质量的计算服务和技术支持,推动高性能计算技术的应用和发展。 国家超级计算济南中心的成功建设和广泛应用,能够大大提升山东省乃至国家的科技创新能力、推动重大行业应用、促进重点和新兴产业跨越式发展,为国家经济建设贡献力量。 | |
 (6个打分, 平均:4.67 / 5) (6个打分, 平均:4.67 / 5) |
首台国产超级计算机在济南投入运行
作者 cracked | 2011-10-30 07:15 | 类型 行业动感 | 2条用户评论 »
|
http://news.china.com.cn/rollnews/2011-10/28/content_10861990.htm 首台国产超级计算机在济南投入运行 时间: 2011-10-28 07:48:02 来源: 兰州晚报 发表评论>> 据新华社电 10月27日,国家超级计算济南中心正式揭牌,我国首台全部采用国产CPU和系统软件构建的千万亿次计算机系统正式投入运行,标志着我国成为继美国、日本之后能够采用自主CPU构建千万亿次计算机的国家。 济南中心装配的神威蓝光计算机系统,由国家并行计算机工程技术研究中心研制,全机装配8704片由国家高性能集成电路(上海)设计中心自主研发的“申威1600”处理器,组装密度和性能功耗比居世界先进水平,系统综合水平处于当今世界先进行列。济南中心全部采用国产CPU和系统软件,实现了国家大型关键信息基础设施核心技术的自主可控。 | |
|
(1个打分, 平均:1.00 / 5) |
SOSP2011论文集
作者 陈怀临 | 2011-10-27 03:26 | 类型 学术园地 | 6条用户评论 »
|
23rd ACM Symposium on Operating Systems Principles
October 23-26, 2011 — Cascais, Portugal
General Chair: Ted Wobber
Program Chair: Peter Druschel
Monday 24th, 08:30-09:00
Welcome and Awards
Monday 24th, 09:00-10:30
Key-Value
Chair: Marvin Theimer
SILT: A Memory-Efficient, High-Performance Key-Value Store
Hyeontaek Lim, Bin Fan, David G. Andersen (CMU), Michael Kaminsky (Intel Labs)
Scalable Consistency in Scatter
Lisa Glendenning, Ivan Beschastnikh, Arvind Krishnamurthy, Thomas Anderson (University of Washington)
Fast Crash Recovery in RAMCloud
Diego Ongaro, Stephen M. Rumble, Ryan Stutsman, John Ousterhout, Mendel Rosenblum (Stanford)
Monday 24th, 11:00-12:30
Storage
Chair: Eddie Kohler
Design Implications for Enterprise Storage Systems via Multi-Dimensional Trace Analysis
Yanpei Chen (UC Berkeley), Kiran Srinivasan, Garth Goodson (NetApp), Randy Katz (UC Berkeley)
Differentiated Storage Services
Michael Mesnier, Jason B. Akers, Feng Chen (Intel), Tian Luo (Ohio State)
A File is Not a File: Understanding the I/O Behavior of Apple Desktop Applications
Tyler Harter, Chris Dragga, Michael Vaughn, Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau (University of Wisconsin, Madison)
Monday 24th, 14:00-15:30
Security
Chair: Adrian Perrig
CryptDB: Protecting Confidentiality with Encrypted Query Processing
Raluca Ada Popa, Catherine M. S. Redfield, Nickolai Zeldovich, Hari Balakrishnan (MIT)
Intrusion Recovery for Database-backed Web Applications
Ramesh Chandra, Taesoo Kim, Meelap Shah, Neha Narula, Nickolai Zeldovich (MIT)
Software fault isolation with API integrity and multi-principal modules
Yandong Mao, Haogang Chen (MIT), Dong Zhou (Tsinghua), Xi Wang, Nickolai Zeldovich, M. Frans Kaashoek (MIT)
Monday 24th, 16:00-17:30
Reality
Chair: George Candea
Thialfi: A Client Notification Service for Internet-Scale Applications
Atul Adya, Gregory Cooper, Daniel Myers, Michael Piatek (Google)
Windows Azure Storage: A Highly Available Cloud Storage Service with Strong Consistency
Brad Calder, Ju Wang, Aaron Ogus, Niranjan Nilakantan, Arild Skjolsvold, Sam McKelvie, Yikang Xu, Shashwat Srivastav, Jiesheng Wu, Huseyin Simitci, Jaidev Haridas, Chakravarthy Uddaraju, Hemal Khatri, Andrew Edwards, Vaman Bedekar, Shane Mainali, Rafay Abbasi, Arpit Agarwal, Mian Fahim ul Haq, Muhammad Ikram ul Haq, Deepali Bhardwaj, Sowmya Dayanand, Anitha Adusumilli, Marvin McNett, Sriram Sankaran, Kavitha Manivannan, Leonidas Rigas (Microsoft)
An Empirical Study on Configuration Errors in Commercial and Open Source Systems
Zuoning Yin, Xiao Ma (UIUC), Jing Zheng, Yuanyuan Zhou (UCSD), Lakshmi N. Bairavasundaram, Shankar Pasupathy (NetApp)
Monday 24th, 17:30-19:15
Posters
Tuesday 25th, 09:00-11:00
Virtualization
Chair: Gernot Heiser
Cells: A Virtual Mobile Smartphone Architecture
Jeremy Andrus, Christoffer Dall, Alex Van’t Hof, Oren Laadan, Jason Nieh (Columbia)
Breaking Up is Hard to Do: Security and Functionality in a Commodity Hypervisor
Patrick Colp, Mihir Nanavati (UBC), Jun Zhu (Citrix), William Aiello (UBC), George Coker (NSA), Tim Deegan (Citrix), Peter Loscocco (NSA), Andrew Warfield (UBC)
CloudVisor: Retrofitting Protection of Virtual Machines in Multi-tenant Cloud with Nested Virtualization
Fengzhe Zhang, Jin Chen, Haibo Chen, Binyu Zang (Fudan University)
Atlantis: Robust, Extensible Execution Environments for Web Applications
James Mickens (MSR), Mohan Dhawan (Rutgers)
Tuesday 25th, 11:30-12:30
OS Architecture
Chair: Nickolai Zeldovich
PTask: Operating System Abstractions To Manage GPUs as Compute Devices
Christopher J. Rossbach, Jon Currey (MSR), Mark Silberstein (Technion), Baishakhi Ray, Emmett Witchel (UT Austin)
Logical Attestation: An Authorization Architecture for Trustworthy Computing
Emin Gün Sirer (Cornell), Willem de Bruijn (Google), Patrick Reynolds (BlueStripe Software), Alan Shieh, Kevin Walsh, Dan Williams, Fred B. Schneider (Cornell)
Tuesday 25th, 14:00-16:00
Detection and Tracing
Chair: Rebecca Isaacs
Practical Software Model Checking via Dynamic Interface Reduction
Huayang Guo (MSR and Tsinghua), Ming Wu, Lidong Zhou (MSR), Gang Hu (MSR and Tsinghua), Junfeng Yang (Columbia), Lintao Zhang (MSR)
Detecting failures in distributed systems with the FALCON spy network
Joshua B. Leners, Hao Wu, Wei-Lun Hung (UT Austin), Marcos K. Aguilera (MSR), Michael Walfish (UT Austin)
Secure Network Provenance
Wenchao Zhou, Qiong Fei, Arjun Narayan, Andreas Haeberlen, Boon Thau Loo (University of Pennsylvania), Micah Sherr (Georgetown University)
Fay: Extensible Distributed Tracing from Kernels to Clusters
Úlfar Erlingsson (Google), Marcus Peinado (MSR), Simon Peter (ETH Zürich), Mihai Budiu (MSR)
Tuesday 25th, 16:30-18:00
Work in Progress
Chair: George Candea
Wednesday 26th, 09:00-11:00
Threads and Races
Chair: Bryan Ford
Dthreads: Efficient Deterministic Multithreading
Tongping Liu, Charlie Curtsinger, Emery D. Berger (UMass Amherst)
Efficient Deterministic Multithreading through Schedule Relaxation
Heming Cui, Jingyue Wu, John Gallagher, Huayang Guo, Junfeng Yang (Columbia)
Pervasive Detection of Process Races in Deployed Systems
Oren Laadan, Nicolas Viennot, Chia-che Tsai, Chris Blinn, Junfeng Yang, Jason Nieh (Columbia)
Detecting and Surviving Data Races using Complementary Schedules
Kaushik Veeraraghavan, Peter M. Chen, Jason Flinn, Satish Narayanasamy (University of Michigan)
Wednesday 26th, 11:30-12:30
Geo-Replication
Chair: Ant Rowstron
Transactional storage for geo-replicated systems
Yair Sovran, Russell Power (NYU), Marcos K. Aguilera (MSR), Jinyang Li (NYU)
| |
|
(3个打分, 平均:5.00 / 5) |
ISF2011邀请函
作者 陈怀临 | 2011-10-25 08:41 | 类型 弯曲推荐, 研发动态, 网络安全 | 10条用户评论 »

弯曲财经:欧债危机吸引了全部注意力,市场继续反弹
作者 ibluesea | 2011-10-24 07:13 | 类型 弯曲财经, 行业动感 | 1条用户评论 »
|
美国市场的注意力完全集中在欧洲债务危机的解决上。上周美国市场持续上涨,投资人期待着欧洲可以在晚些的周日峰会上取得一些进展,并在本周三的再次会议上达成一个彻底的,结构性的,可以保护欧洲免于金融危机的解决方案。市场情绪期盼着这次的会议最终可以解决这个已经长达两年的问题。法德仍然在救援方案上有分歧,但是随着压力的增加(包括美国和中国,以及法国被评级机构列入可能降级的观察名单),相信他们会顾全大局,给出一个能够稳定市场信心的协议。 | |
|
(1个打分, 平均:3.00 / 5) |
《弯曲评论文集》(一)的筹备工作
作者 陈怀临 | 2011-10-22 07:54 | 类型 行业动感 | 33条用户评论 »
|
各位江湖上的朋友, 《弯曲评论》创办以来,有不少的好文章。多谢江湖上的弟兄们秉承着Open Source的精神,将自己的所学反馈于社会。 现在,希望将过去的一些优秀的文章整理成集,并作为GPL Doucment的版权发表。 希望大家支持,并给出文章推荐列表。 | |
|
(8个打分, 平均:4.50 / 5) |
程序分析-原理和实践之控制流分析
作者 Guoping | 2011-10-21 22:43 | 类型 专题分析 | 5条用户评论 »
|
排版不好,请包涵。待完成后后一定出一个干净的合集。 2 控制流分析 2.1 控制流图 控制流图是对程序中分支跳转关系的抽象,描述程序所有可能执行路径,定义如下:
图2.1控制流图 控制流图的节点是语句集合,从A到B的边表示语句A执行完后可能直接执行语句B,整个控制流图必须有唯一的入口和出口。这是以每个语句为节点的控制流图,实际操作的控制流图一般以基本块(basic block)为基本节点,每个基本块包括若干条语句,基本块本身有唯一的入口和出口。 2.2 Dominator和Post-dominator 在控制流图中,Dominator描述节点之间在实际执行轨迹中的顺序关系。如果A是B的Dominator,那么意味着从程序入口执行到B的任意路径则一定经过A,称A Dom B,定义如下:
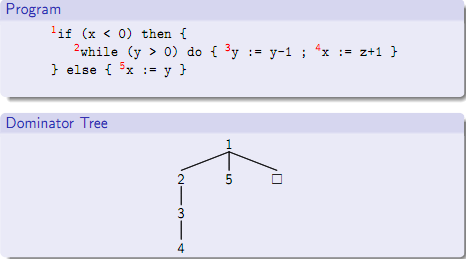
图2.2 Dominance关系定义 Dominance关系具有自反(x Dom x)、传递(x Dom y 且 y Dom z,有x Dom z)和反对称(x Dom y不意味着y Dom x)等性质。如果x Dom y且x!=y,那么称x是y的strict dominator。进一步的,如果x是y的strict dominator(记为Dom!),并且对任意除x以外的y的任意dominator w,有w Dom x,那么称s是y的immediate dominator(记为IDom),直观上,immediate dominator就是dominance关系链上最近的一个。Post-Dominator和Dominator是对偶的,如果x PDom y,那么任意从y到程序出口的路径都必须经过x。 考察dominator关系对一些程序分析很有价值。如检测对变量的初始化语句是否出现在所有对该变量的使用之前,或者在多线程程序中检测是否每一个lock都对应unlock。 根据Dominator关系的上述定义,任意一个节点都有唯一immediate dominator。如果把控制流图中所有其余的边删掉,只保留immediate dominator边,就得到一颗dominator树。给定控制流图,只要求得其dominator树,就能得到节点间的所有dominator关系。下图2.3给出了一个Lingo程序以及对应的dominator树:
图2.3 dominator树举例 接下来的问题,给定控制流图,如何快速找到所有dominator关系,图2.4是一个基本迭代算法:
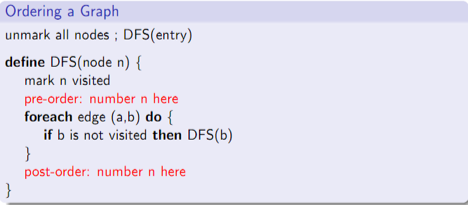
图2.4 dominator关系求解算法 首先初始化,entry节点的dominator集合初始化为一个元素(entry自身),所有其他节点的集合初始化为整个节点集。接下来进入迭代过程,每次迭代考察每个节点,将该节点所有前驱的集合求交集,整个迭代过程直到解不变为止(即不再有新的Dom关系添加进来)。这个算法不关心不同节点的计算顺序,但事实上由于节点间的依赖关系,合理计算顺序对整个dominator关系求解的性能至关重要。 考虑图2.5的深度优先遍历过程:
图2.5 DFS过程中的先序和后序编号 遍历过程中对节点升序编号,可见有两种基本的方式:先序(pre-order)和后序(post-order)。直观上,分析dominator关系应该采用先序,因为前驱节点应该尽可能先处理,但对于有环(循环)的控制流图仍可能需要多次迭代。直接采用后序违反直观,对任何节点,前驱节点处理之前无法完成处理该节点。但如果将后序倒过来(reverse post-order),就能确保任意节点在其后继节点之前处理。reverse post-order不同于pre-order,更多的分析可以参考文献[1]。 Dominance Tree的高效计算方法如图2.6所示。算法基本框架和图2.4一样,需要留意几点细节。首先初始化时,对入口节点外的节点不是初始化为节点全集而是初始化为空(undefined)。进入迭代过程每轮循环需要遍历所有节点更新dominance关系,对所有节点(入口节点无需处理)采用reverse postorder来顺序处理。对选定的待处理节点b,首先选择第一个处理过(processed)的前驱,所谓处理过就是doms[b]不再是Undefined状态的节点,这一点很重要,否则有环时算法可能终止不了,接下来就是遍历所有处理过的前驱寻找b的immediate dominator,这一步通过intersect(b1,b2)实现。 intersect()过程中的变量都表示后序(post order)的节点编号,目标是找到b1和b2最近的公共前驱节点的编号,内层两个while循环按照reverse postorder的顺序找到reverse postorder编号小 (即postorder编号大) 的公共节点。图2.6的算法给每个节点找到其唯一的immediate dominator,所有这些信息合起来构成一颗dominance tree。 图2.4和2.6的算法都是从入口节点(entry node)出发构造dominator关系集合,一组节点的信息被分析出来的前提是从入口可达,因此这两个算法都分析不到死代码(从入口节点无论什么路径都无法到达)内的dominance关系。这点关系不大,因为人们一般只关注死代码的位置,对其内部结构兴趣不大。
图2.6 Dominance Tree算法 2.3 控制依赖 控制依赖直观上很好理解,但在控制流图的准确定义存在需要注意的细节,定义如图2.7所示。
图2.7控制依赖的定义 这就是说节点y和x之间存在控制依赖需要满足三个条件。第一个条件即存在一条x到y的执行路径P;第二个条件进一步要求x到y之间没有其他控制语句,换言之对路径P上的任意节点n,n到出口的任意路径上一定经过y,也就是说y是n的post dominator。第三个条件要求y一定不是x的strict post dominator,直观上就是说在x和y之间一定有一条流程控制语句,进而使得除了从x到y之外一定还会有跳转到其他地方的路径。例如图2.8所示的程序中,语句5控制依赖于语句4,但语句6和语句4之间没有直接的控制依赖关系,因为4和6直接的语句5是一条控制语句。但另一方面,语句6,7,8都控制依赖于语句5,语句7 PDOM! 语句6,语句8 PDOM! 语句7。
图2.8 控制依赖举例 2.4 循环和强连通子图 控制流分析的另一个应用是检测循环。对控制流图进行深度优先遍历(DFS)能得到一个生成树,生成树中边叫forward edge。另外还有两种边:cross edge和backward edge。backward edge表示控制流图中存在循环。问题是如何区分cross edge和backward edge,下面以图2.9中的程序为例来说明。 图中每条语句用数字标出,显然从语句8到语句3的边回到循环条件,构成回边(backward edge)。语句6到8和语句7到8分别有一条边,这两条边只有一条可能出现在DFS遍历的生成树中,剩下的一条就是交叉边(cross edge)。假设有一条从A到B的边,判断其是交叉边还是回边的方法是:如果在生成树中可以从B到达A,那么该边是回边;否则是交叉边。
图2.9 循环举例 从另一个角度,控制流图中的循环本质上构成了图中的一个强连通子图(Strong connected component)。检测图中强连通子图的标准算法是Tarjan算法,如图2.10所示。 Tarjan算法只需要对图进行一次深度优先遍历即可完成,需要O(n+m)的复杂度,其中n是边数目,m是顶点数目(算法中有对每个顶点的栈操作)。preorder按照优先遍历的顺序对节点编号,n.order表示节点n自身的编号,n.root表示n所在循环根节点的编号,算法先初始化节点所在的根为节点自身的编号。接下来首先顺序处理n所有邻接节点,然后更新n的根节点编号,原因在于可能存在从n的邻接节点到祖先节点(编号可能比n小)的回边,这一步确保能找到最大的强连通子图。递归处理完所有邻接节点后,由每个连通子图的根节点输出该子图的所有节点,每输出一个节点,就将该节点“删除”,这样确保任何节点只可能出现在一个强连通子图中,即不可能出现多个子图交叉的情况。 还有一个实现上的细节:当找到并输出该连通子图的所有节点时,需要子图中每个节点的root域(即让子图中每个节点指向新的根)。如果在图2.10中,repeat/until循环体中增加一个语句才会更准确:v.root = n.order。这样确保连通子图中每个节点的root域指向其所在子图的根节点,否则在存在嵌套循环的时候会有问题。 关于Tarjan算法原理的更多细节请参考文献[2],关于该算法的实现细节请参考本文第二部分基于Clang的实现参考源码。
图2.10 检测强连通子图的Tarjan算法 2.5 自然循环和可化简控制流图 自然循环(natural loops)就是只有单一入口的循环。两个自然循环要么完全不相交,要么嵌套。对于没有goto语句的语言,所有的循环都是自然循环。一般循环可能存在多个到循环体的入口,如通过goto语句直接跳转到一个循环的循环体中。 如果一个控制流图仅通过如下T1和T2两种变换能化简为一个节点,则称该控制流图是可化简的(reducible):
没有循环的控制流图都是可约简的,对存在循环的控制流图,当且仅当所有循环是自然循环时此图是可化简的。有一些程序分析算法只对可化简的控制流图有效。 [1] Keith D. Cooper, Timothy J. Harvey and Ken Kennedy. “A Simple, Fast Dominance Algorithm”. Software: Practice and Experience, 2001; 4:1-10. | |
|
(1个打分, 平均:5.00 / 5) |







对李先静文章中volatile变量的量化小分析
作者 陈怀临 | 2011-10-21 06:02 | 类型 科技普及 | 26条用户评论 »
|
下面是一段简单的代码,试图对李先静文章中的volatile进行一些量化分析。变量foo是一个static变量。下面分析了non volatile和volatile的不同的汇编语言结果。
static int foo;
void bar(void) {
foo = 0;
while (foo != 255)
;
}
.text
.align 4,0×90
.globl _bar
_bar:
LFB2:
pushq %rbp
LCFI0:
movq %rsp, %rbp
LCFI1:
movl $0, _foo(%rip)//变量初始化为0
L2:
jmp L2//死循环,因为编译优化,认为foo变量永远是0;
如果对变量做volatile处理,禁止编译优化。
static volatile int foo;
void bar(void) {
foo = 0;
while (foo != 255)
;
}
.text
.align 4,0×90
.globl _bar
_bar:
LFB2:
pushq %rbp
LCFI0:
movq %rsp, %rbp
LCFI1:
movl $0, _foo(%rip) //foo变量赋初值为0
.align 4,0×90
L2:
movl _foo(%rip), %eax
//必须force做memory的load操作。从而在多CPU下,或者系统
//中有其他逻辑,例如DMA,FPGA操作的情况下,CPU能感知
cmpl $255, %eax
jne L2 //如果变量有变化,函数返回
leave//离开while控制逻辑
ret
| |
|
(没有打分) |