总占地万亩以上 盘点各地云计算基地中心
作者 hid | 2012-05-09 17:01 | 类型 行业动感 | Comments Off
|
【PConline 资讯】云计算也有几年的发展,随着时间的推移,当初如火如荼的云计算领域也有了更多的理性思考与警惕,云圈地这一对云计算产业的质疑也越来越多,更是有某地云计算数据中心圈地2000余亩良田的消息爆出。我国各地云计算基地中心有说多少呢?光是本文中出现的云计算基地中心前前后后加起来总共达到6842192平方米,约合1万亩左右。要是将所有的都统计起来,其面积可想而知。 自从2010年国家发改委将云计算确定为重点发展项目,同时批准北京、上海、杭州、深圳以及无锡为我国首批云计算五大示范城市,仅仅两年的时间,各地的已建、在建或者将建的云计算基地中心如雨后春笋般涌现。下面就来看看各地云计算基地中心发展状况。 为何要建云计算基地中心 云计算,自然离不开数据中心的支持,云计算的核心就是把业务运行处理都移到云端,减轻单个企业用户的开支,例如大家最为熟知的云存储,是必要一个庞大的数据中心才能应对云计算平台的需求。虽然云计算服务有着三种不同的模式,基础设施即服务(IaaS)、平台即服务(PaaS)、软件即服务(SaaS), 但是,云计算服务的平台需要搭建在一个硬件的基础上。 云计算中心选址要求 云计算中心的选址有何要求呢,这和普通的数据中心选址有何不同呢?为什么首批试点城市是北京上海杭州深圳无锡这几个呢?除了常规的数据中心选址的考虑因素外,更过的从潜在市场,信息服务业发展状况考虑。 北京上海自然不必多说,作为我国内地最大的两个城市,入围自然不在话下,云计算的市场、交通、信息服务业发展状况都有着得天独厚的优势。 深圳作为经济特区,其国家超算中心也为云计算提供了必要的支持。发展云计算也有独特的优势。 杭州入围则是得益于其众多的中小型信息服务企业。杭州市多年来一直在大抓信息港建设。虽然杭州地下没矿产,地面没有大的交通枢纽,空中也没有大的空港,海陆空方面没有太多天然的优势。但是近十年来,杭州重点发展信息港等项目,软件业在此基础上获得了一定的发展。 而无锡则是应为其在云计算发展上的先见之明,早在2008年,IBM中国云计算中心就落户无锡,到2010年,其云计算产业发展已有两年的历史。
当然,政府牵头建立的云计算产业基地又与企业投资的云计算数据中心有着区别,政府更多是从招商投资角度选择,北京上海杭州深圳无锡,无一不是经济发展较好的地区。而企业投资建立云计算数据中心,则是更多的从数据中心的选址考虑,例如百度云计算数据中心的选址在山西阳泉,想必大家都没怎么听过吧。>> 北京祥云工程计划
北京祥云工程
作为中国的首都,北京在云计算中心的建设上自然是起到领头羊的作用,早在2010年,发改委将云计算确定为重点发展项目,北京就被列为首批云计算五大示范城市之一,北京的“祥云工程”计划也应景出台,计划到2015年,云计算的三类典型服务(IaaS、PaaS、SaaS)形成500亿元产业规模,带动产业链形成2000亿元产值,打造世界级的云计算产业基地。 云计算离不开数据中心的支持,2010年8月,祥云工程有了第一个云计算示范基地,位于北京亦庄的北京云计算基地,占地7000平方米,大约70个三室一厅的套房大小。虽然比起谷歌最新占地面积15公顷(150 000平方米)还差的远,是实际上在寸土寸金的北京来说,已经足够大了。
祥云工程计划不仅仅是一两个云计算基地,2011年9月,“中国云产业园”正式启动,位于亦庄的“中国云产业园”,初期规划占地3平方公里(3000000平方米),预留建筑面积2平方公里(2000000平方米)。相比于北京亦庄云基地的7000平方米,占地面积又有了几倍的增长。 中国云产业园由云技术研发基地、云计算设备研制中心、系统平台及应用软件研发中心、大规模数据处理及计算中心、云后台服务中心、新一代移动通信技术研制中心、下一代互联网技术研发中心、终端设备研制中心、显示技术研发中心等单元组成。 首批云产业园的项目包括百度云计算中心项目、云计算系统设备制造基地项目、云计算研发运营中心项目、KDDI数据中心项目、北京电信数据中心项目的5个项目,总投资规模达261亿元。
除去云产业园与亦庄云计算基地,有关云计算的项目计划还有许多,例如中科院参与的北京超级云计算和国家重要信息化基础平台建设项目。上图是在国土资源部网站查到的。位于怀柔区的超级云计算平台,占地约1.44公顷(14400平方千米),是亦庄云基地的两倍大小。>> 上海云海计划
上海云海计划 作为我国最大的城市,上海在进军云计算领域的脚步也不算慢,2010年入围首批云计算示范城市后,云海计划也随机推出,相比于北京祥云工程,云海计划更为紧迫,根据云海计划,在2010年到2012年三年的时间内,上海将被打造为亚太数据中心,同时带动信息服务业新增经营收入千亿元。
上海云海计划有着十百千的发展目标:即建成十个云计算示范平台,服务对象涉及城市管理,电子政务,中小企业等等;推动百家服务和创新企业向云计算服务转型;最后是带动千亿元的信息服务业的新增收入。 上海云海计划的五个重点目标:突破虚拟化核心技术、研发云计算管理平台、建设云计算基础设施、鼓励云计算行业应用、构建云计算安全环境。
与上海云海计划发布同时推出的还有上海市云计算产业基地的揭牌,上海市云计算产业基地落户在闸北区国家级市北高新园区,闸北区国家级市北高新园区占地面积3.13平方公里(3 130 000)。2010年10月26日,上海市云计算创新基地又落户在杨浦区。 2011年10月22日,上海云海数据中心正式在浦东洋山保税港区揭牌。一期规划占地面积320亩(213 333平方米),由数据中心产业区、商务运营区和扩展区这三个大区组成。数据中心产业区将重点发展以国内用户为主的数据中心、灾备中心、云计算中心、电子商务、金融后台、物流后台、结算中心等产业。商务运营区将重点吸引数据增值服务产业、动漫及网游、软件测试与外包、研发设计等产业,同时提供商务配套服务。
而扩展区则将用于相关数据产业、服务外包产业和服务贸易产业后续发展的需要。 虽然云海计划是2010年到2012年的规划,但是上海云海数据中心的建设远非到2012年就能结束。上海云海数据中心的开发建设将分三步走,知道2020年才算不如尾声。可以说上海云海数据中心是一个在云计算领域长期的投资项目。>> 杭州云计划及深圳鲲云
杭州 相比于北京以及上海宏伟庞大的云计算规划,杭州云计算似乎更为低调,没有一个具体的5年规划或者三年规划公布,杭州首个云计算产业园也是2011年10月20日正式开园。不过也有消息称杭州整体布局云计算产业规划到2013年,杭州市云计算产业年收入超过500亿元,带动产业链经营收入超过2000亿元。云计算产业发展脚步比北京上海还要快。
早在2011年8月,杭州云计算产业园落户西湖区的消息就传出来了,位于杭州西湖区转塘科技经济园区的杭州云计算产业园,一期占地18亩(12000平方米),即使到最后通过三期建设形成楼宇总规模面积近30万平方米,相比北京上海的云计算产业园或者基地都要小的多。 杭州云计算产业园共分为三期,历时四年,最终将建成一个楼宇总规模近30万平方米,可容纳100至200家云计算相关企业入驻的专业产业园。
按照三期的建设计划,杭州云计算产业园将建立一个先进的、能够辐射全市乃至全省的云计算IDC中心,这与北京打造世界级云计算中心以及上海的亚太区数据中心的定位又有不同。杭州主要致力于打造“政务云”和“商业云”,为杭州电子信息企业提供高水平的云计算产业研究、技术开发、业务咨询、人才培训等服务。同时 | |
   (7个打分, 平均:3.29 / 5) (7个打分, 平均:3.29 / 5) |









用Kinect来实现3D全息视频会话
作者 hid | 2012-05-09 17:00 | 类型 行业动感 | 2条用户评论 »
|
The Verge消息,来自加拿大皇后大学的一支研发团队正在利用Kinect开发一种名为Telepod的3D全息设备,用以取代旧式视频会话。Kinect是微软公司为Xbox 360打造的一种体感设备。 该系统最显眼的部分是一个高约1.8米的柱状显示屏,在其顶部,六个微软Kinect摄像头环绕放置,还有一个投影仪放在柱状体中。当进行会话时,每一个与会者只需要站在设备前面,该设备就能够定位并追踪人们的动态,并以3D模式呈现。于是你就将看到对方的全息影像,并且可以走动来查看对方的侧面和背面。 据The Verge报道,该团队甚至还为Telepod开发了一款用于医学用途的应用,名为Bodipod。该应用使用相同的硬件,可以让你与一个3D的人体解剖图互动。你可以从不同角度去查看它,也可以将其层层剥离,了解人体解剖的每一部分。或许在不远的将来,远程学习外科手术就不再是梦想了。 | |
|
(没有打分) |

关于数据中心大二层的一点小吐槽
作者 kkblue | 2012-05-08 17:18 | 类型 行业动感 | 11条用户评论 »
|
hi 首席,这是有感于某厂商微博的投票,想到的一些感想,技术含量不大,就是给大家一乐而已 天也不早了,人也不少了,做完了ppt,也可以吐吐槽了,有感于某厂商的挖坑站队帖,随便吐吐口水,和技术关系不大,有字数无营养,纯属逗大家一乐 weibo.com/kkblue (1)数据中心大二层 | |
|
(10个打分, 平均:4.70 / 5) |
龙星课程报名:《并行体系结构——低功耗计算技术》
作者 Huiwei | 2012-05-08 17:16 | 类型 行业动感 | 1条用户评论 »
|
【更正:授课时间改为5.14~5.18的8:00 – 16:30,请以http://asl.ncic.ac.cn/ljj/dragonstar/dragonstar.html公布的日期为准。】 新一期龙星课程开始报名了! 龙星课程是一个杰出的海外华人教授回国系统讲授研究生课程的计划。旨在为国内的研究生提供高质量原汁原味的课程。 本次课程由Prof. Xiaobo Sharon Hu讲授《并行体系结构 —低功耗计算技术》。
课程无需提前报名,请大家上午8点准时参加。欢迎大家转发本条消息。 授课人简介 Course Summary
This course intends to expose students to both fundamental approaches and cutting-edge research results in lower power computing. Power consumption is becoming a limiting factor in many electronic systems due to heat dissipation and battery capacity. Low power design is no longer an expendable topic, but require comprehensive treatments in all phases of electronic system design. In this course, students will learn low power design techniques from a variety of areas including hardware, software, compilers and operating systems. Representative research papers in these areas will be studied in detail. The course will culminate with a final project for students to investigate a low-power design approach in an area of his/her choice.
| |
|
(2个打分, 平均:5.00 / 5) |
丁雪丰 . 《了解Instagram背后的技术》
作者 陈怀临 | 2012-05-07 11:47 | 类型 行业动感 | 8条用户评论 »
|
[丁雪丰 是InfoQ中文站编辑,满江红翻译组核心成员,出版过《Spring攻略》、《JRuby实战》等多部译著。主要关注领域:企业级应用、海量数据计算、动态语言应用等。] 刚被Facebook以10亿美金收购的著名手机照片分享应用Instagram最近吸引了无数人的眼球,Android版本登陆Google Play不到一个月下载量就突破1000万,总用户数即将超过5000万。Instagram联合创始人Mike Krieger说他们用了8周时间打造了最初的Instagram,但现在的系统肯定已经今非昔比。Instagram技术团队曾发表过一篇文章,介绍了Instagram背后的技术,日前Mike Krieger在名为Scaling Instagram的演讲里,又介绍了更多细节,让人们能了解到5名技术人员是如何支撑起整个系统的。 一张照片上传的过程是这样的: 采用同步的方式写入媒体数据库 由于只有5名技术人员(其中仅2.5名后端工程师),精力有限,选择Amazon的云服务是个不错的选择。目前他们使用了超过100个EC2实例用于提供各种服务,运行的操作系统是Ubuntu 11.04,之前的一些版本在高流量时表现不够稳定。在负载均衡方面,他们使用Amazon的Elastic Load Balancer实现负载均衡,后端运行了3个Nginx实例,SSL只到ELB上为止,降低了Nginx上的CPU负载。DNS和CDN分别由Amazon的Route 53和CloudFront提供,所有的照片都存放在S3上,目前已经有几TB的规模了。 用于处理请求的应用服务器运行于Amazon High-CPU Extra-Large Instance之上,由于他们的请求更多是CPU密集型的,因此这能更好地平衡CPU与内存。采用的开发框架是Django,WSGI服务器是Gunicorn,通过Fabric在所有机器上进行并行部署,一次部署仅需几秒钟。 大多数数据都存放在PostgreSQL里,主分片集群运行于12个High-Memory Quadruple Extra-Large Instance(68.4GB内存)上,另有12个位于不同可用区里的副本,通过repmgr以Streaming Replication的方式进行同步。由于Elastic Block Store的磁盘IOPS不高,因此需要将正在使用的数据都加载到内存里,vmtouch能帮助管理内存中的数据。他们在EBS上使用mdadm实现了软件Raid,以此提升写吞吐量;数据库的文件系统用的是XFS,在从库获取快照时,会先冻结RAID阵列,保证快照的一致性。 应用程序在连接数据库时,由Pgbouncer建立连接池。目前,Instagram的数据按照用户ID进行分片,某些分片可能会超出物理节点的容量上限,为此他们将数据分成了很多个逻辑分片,映射到少数几个物理节点之上;当一个节点被填满之后,可以将某些逻辑分片移到别的节点上,以缓解该节点的压力。随着数据量的增长,以后他们也会进行垂直分区,Django DB Router能让一切轻松不少。 Instagram也大量使用Redis来存放复杂的对象(对象的大小做了一定的限制),用于主Feed、活动Feed、会话系统及其他相关系统。因为要将Redis的所有数据都放在内存里,此处同样也用了High-Memory Quadruple Extra-Large Instance,并对数据做了分片。当Redis实例的请求达到4万/秒后,它渐渐成为了瓶颈,于是Redis也做了主从复制,副本的数据会经常导出到磁盘上,通过EBS快照进行备份。 除了Redis,他们还使用Memcached来做缓存,目前运行了6个实例,应用服务器通过pylibmc和libmemcached进行连接。虽然Amazon提供了Elastic Cache服务,但该服务的价格并不便宜,相比之下,还是运行自己的Memcached实例比较划算。异步任务队列使用的是Gearman,目前有大约200个工作进程来处理各种任务,比如把照片分享到Twitter和Facebook,通知用户有新照片等等。Pyapns已经处理了十亿的推送通知,非常稳定,他们还自己开发了基于Node.js的node2dm,用于向Android设备发送推送通知。 监控方面,Instagram使用Munin以图形化的方式呈现整个系统的运行状况,还通过Python-Munin定制了一些插件,用来显示业务数据;网络守护进程Stated可以实时收集数据并做汇总;Dogslow会监控进程,一旦发现运行时间过长的进程,便会保存该进程的快照,以便后续分析,比如响应时间超过1.5秒的请求,通常都是卡在Memcached的set()和get_many()方法上。对于Python的错误,只要登上Sentry就能实时获取错误信息。 HighScalability上还根据整理Mike Krieger的演讲整理了一些值得借鉴的经验,比如: 找那些你熟悉的技术和工具,在简单的使用场景里先做一些尝试 | |
|
(8个打分, 平均:4.75 / 5) |
弯曲推荐: KPang 。《浅谈 数据中心 。 高压直流》
作者 陈怀临 | 2012-05-06 21:07 | 类型 专题分析, 云计算, 弯曲推荐, 研发动态, 行业动感 | 10条用户评论 »

Android 移植到 C#
作者 hid | 2012-05-06 10:04 | 类型 行业动感 | 2条用户评论 »
|
甲骨文和谷歌正就谷歌在Android中使用Java一案展开一场10亿美元的大较量。但是Java并非在Android中建立本地应用的唯一方法。事实上,它甚至不是最好的文法:Xamarin 开发组已经将C#提供给Android开发者作为一个高性能、低功耗的Java的替代语言。Xamarin 的平台,Mono,是.Net框架的一个开源的实现。它使得开发者用C#写成的程序,能运行在带有Java的操作系统上,然后与iOS和Windows Phone共享同一代码。 不同于Sun对Java的做法,微软向ECMA(欧洲电脑制造商协会)提交了C#和.NET VM标准化申请,并一路保证这些标准完全符合ISO牢固专利承诺。.NET框架同样也为微软受法律约束的社区承诺所覆盖。 去年七月,Xamarin 开发组在波士顿小聚,讨论Mono在iOS和Android中的成长。查尔斯河一天的荡舟过后的晚宴席间,开发组将注意力转向了如何提升Android上应用的性能并降低能耗,使他们的Mono更加适合于Android。
一次次地,开发组回到最根本的话题:Dalvik是个年轻的虚拟机,它不如Mono那么高效与协调,并受制于Java的许多性能极限,而且享受不到来自甲骨 文的热点(HotSpot)的高端优化。那次晚宴开发组冒出的一个疯狂的想法,是将Android的源码翻译成C#。Android将能从C#的性能特性 如结构体、P/调用、真实泛型以及他们更加成熟的运行时中受益。 虽然七月什么也没有发生,但这一想法深深扎根在了开发组的心里。 快进几个月:专用于Android的Mono做得非常好,开发组开始再次考虑提升自己产品在Android上的性能。如果扫除Java,使用更快的 C#并同时去除Dalvik的极限,结果将会怎么样?Xamarin 能否创造出一个完全不含Java,并且突破Dalvik VM极限的Android电话? 它如此疯狂,Xamarin 开发组决定尝试。于是他们开始了一个小型的专案工作组项目,致力于做一个从Android到C#的机器翻译工作。他们称这一项目为XobotOS。 XobotOS研究项目 努力的结果是,今天,他们已经将Android大多数布局和控件完全移入了C#。下图是运行在一个Linux 工作站的XobotOS 的截图,不涉及一点Java: 到达这一个节点,需要将Android Java源码的主要部分翻译成C#。因此你可以想见上图代表的里程多么有意义。那他们是如何做到的呢? 基于Sharpen的Java翻译 Android的代码库包含一百万多行Java代码,而且他们知道必须得与Android的新发行操持同步——事实上,2011年的时候他们是从 Android 2.x 的源码起步的;随后当谷歌在今年早期开放Ice Cream Sandwich 源码的时候,他们已经将XobotOS 升级到了Android 4.0。因此对于他们,唯一可行的选择是,做一个Java到C#的机器翻译,在这一过程中构建并维护任何必要的工具。 开发组所使用的作为起点的工具是Sharpen。Sharpen因帮助Frank Krueger在两个月内将Java小程序移植到一个赢奖了的iPad应用而著名了起来。 开发组对Sharpen做了改进,使之成为了一个高度改进的通用的Java2C#翻译工具。他们将在发布XobotOS源码的同时发布这一新版本的Sharpen,希望更多的人能够从中受益,并参与贡献。 性能 一旦你让Android在Mono上运行,首先想到的一个问题一定是——Mono的性能同Dalvik相比如何? 当C#出来的时候,微软以一些意义重大的方式修改了该语言,使之更加易于优化。值类型的引入,使小的对象占用更低的负载,并使虚函数opt-in而非opt-out,十分适合更加简单的VM。之后,Java和C#在泛型的实现上出现的分歧。Java走了完全向后兼容的道路,而C#则将这一支持放到了运行时中。C#的做法形成了一个易用、易于理解的泛型机制,并且更加高效与完整。 自那时开始,两大语言以及各自的运行环境都有了持续的发展与改进。C#从一个略微优秀的Java,长成了一个比Java多走了一光年远的语言。拥抱动态编 程,带来异步机制,引入迭代器,功能性编程构建,拥抱并行并实现了一个伟大的泛型。许多这些特性都来自于Don Syme 的调查和他的持续给该语言注入新思想的F#开发组。 而且,Mono作为一个虚拟机,已经在过去的十年里充分地成长;如今,马上要考虑其第八版的发布工作了。 所有这些加起来,你可以从开发组运行的一个简单的二叉树实现的基准测试(如下图)中,看到Java和C#在结构体和泛型性能上巨大的差别。
下一步怎么走 目前,开发组已经在Github上发布了XobotOS。你可以亲手试试。 作为一家公司,Xamarin 的目标是提供建立移动应用最佳的平台,因此XobotOS 将不是他们今后工作的重心。但是使用它也是一个不错的体验。并且正如结果所显示的,部分技术已经在它的帮助之下浮出水面,它们或将进入我们将来的产品中: 直通Skia的图形访问:当前用于Android的Mono仍是通过Java访问底层图形库;使用Xamarin 建立XobotOS的代码,开发组将可以跳过中间件,使用Mono的P/Invoke直接连接到Sika中的本地渲染代码。 Java2C#工具:开发组新版本的Sharpen 已经作为其XobotOS发行的一部分发布。 用C#代码取代Java代码:开发组已经有了用C#代码替换某些性能关键且C#能提供更优解决方案的的Java代码块所必要的工具。他们的计划是从这一调查项目中取材,将它们集成到自己的产品当中。 一个因为认为它好玩而启动的项目,最终竟为公司的产品提供了一些意义重大的益处。创业很有必要集中精力办实事,但偶尔你应该尝试某些疯狂的想法,以取得进步。或许谷歌某天会感谢Xamarin,这也说不定。 Xamarin 的很多职位正在招人,有志者可与他们携手,引领移动开发的先潮! | |
|
(1个打分, 平均:5.00 / 5) |



Appied Micro宣布首款64位ARM架构服务器
作者 hid | 2012-05-06 04:27 | 类型 研发动态, 芯片技术, 行业动感 | 5条用户评论 »
|
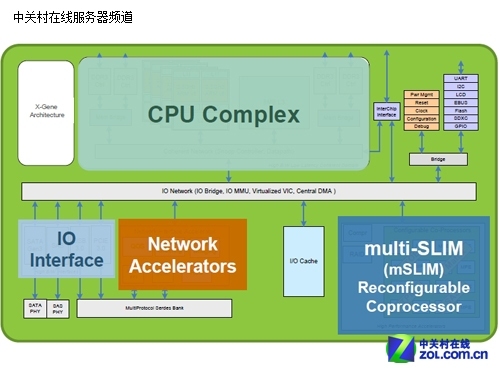
Applied Micro Circuits Corporatio(应用微电路)公司今天宣布了全球第一款基于64位ARMv8架构的Web服务器,基于其率先推出的64位ARM架构处理器方案“X-Gene”。 同时,这也是业内第一套64位ARM生态开发平台。 X-Gene方案采用SoC高集成度设计,面向下一代云计算数据中心,可大大降低系统成本。自去年十月底宣布以来,Applied Micro已经将最初单纯的SoC处理器发展成了能够自由扩展、运行实际应用的服务器,OEM、ODM、ISV、CSP(云服务供应商)和其它开发伙伴都可以一边进行芯片开发,一边进行早期的性能测试和软件开发。 这套服务器拥有多颗并行的ARMv8架构多核心处理器,均有自己的一级、二级、三级缓存,但具体数量、型号、规格均未披露。此外还可提供高性能内存子系统、以太网卡和其它通信设备、一致性光纤、SoC外围和相关桥接,操作系统是Linux,能够运行一整套LAMP软件堆栈,包括Apache、MySQL、PHP。
总部为于美国加利福尼亚森尼维耳市的这家AppliedMicro公司,是一家致力于设计和开发网络、嵌入式Power架构和服务器处理器的ARM、光传输和存储解决方案的无晶圆半导体公司。早在2004年,这家公司就以2.27亿美元,从IBM手中购入了PowerPC 400微处理器和IBM的SoC设计技术,以及先进的CMOS工艺技术。在今年5月或者6月份,还将有望购入韦洛切技术公司(Veloce Technologies Inc)。
自从宣布推出X-Gene以来,AppliedMicro就开始踏入了多核Server-on-Chip应用、在完整服务器上运行工作负载的旅程。 这种开源Web服务器应用的推出,可被视作X-Gene发展的另一个重要里程碑。AppliedMicro的SoC解决方案主要面向下一代云计算数据中心,旨在帮助降低总体拥有成本。它也代表着首个64位ARM加速推广服务器系统丰富生态社区的势头。而此次AppliedMicro公司,借势推出全球首款64位ARMv8架构服务器,也可谓是“第一个敢吃螃蟹的人”。 架构之争虽然ARM凭借其低功耗芯片设计的微服务器在市场上有不少影响力,尤其是包括48位内存寻址和硬件虚拟化扩展功能的Cortex-A15“Eagle”微处理器架构,然而,在应用得到普及的道路面前该公司还是面临着这样的障碍:不同于x86芯片,ARM处理器基于32位核心。 ARM宣布可以在64位芯片上工作,尽管如此但其在64位架构上的影响力也很薄弱。也就是说,到现在为止,ARM授权AppliedMicro被称为X-Gene的SoC解决方案,该解决方案首次针对64位ARM服务器市场设计。
X-Gene平台支持多核心ARMv8架构64位处理器,也提供有高性能内存子系统模块,提供有整合以太网卡的云服务器I/O功能和其他连接外围设备所具备的通信接口。其他硬件方面的特色还有: 1、拥有多颗并行的ARMv8架构多核心处理器,支持L1、L2、L3高速缓存; 3、一致性光纤、SoC外围和相关桥接。 X-Gene架构下最多可以扩展至128个内核,最高主频可达3.0GHz。AppliedMicro通过其生产合作商TSMC在40nm和28nm处理器技术平台上,生产这种64位ARM架构的SoC片上系统。
X-Gene设计旨在将服务器打造成类似平板电脑一般的低功耗:待机功耗每核心为500毫瓦、睡眠模式为300毫瓦,工作状态也仅为2瓦每核心。该芯片还具有动态调频功能??也就是常说的支持turbo-boost模式,能够根据业务负载需要调整时钟频率。由于X-Gene支持非阻塞和1Tb/sec连接速率,可以在多个X-Gene插脚之间为数据提供100Gb/sec连接速率,从而实现80Gb/sec的总带宽。 作为全球首个64位基于ARM架构的X-Gene,在虚拟化、I/O、多核性能和功耗等方面,都有着不错的表现。X-Gene实现了从原有的Cortex-A15基础上进行扩展,而且其虚拟化的加入,对于云端虚拟化环境的支持完全能够胜任。 市场之争对于ARM的的传统目标市场,也就是嵌入式和移动计算系统领域,已经占有了相当一部分份额,相比其他竞争对手拥有很多优势。然而,如果该公司想要进入英特尔强有力的数据中心市场,还是面临着很大的压力,尤其是需要真正解决64位架构的实现问题??而不仅仅是对Cortex-A15扩展寻址那么简单。 AppliedMicro通过ARM架构的X-Gene搭建云服务器,相比传统面向密集型计算的服务器,它主要针对大量相对轻量级业务负载??这被很多业界人士认为是下一轮市场增长点之一。
去年美国厂商Calxeda发布了业界第一款基于ARM架构、专门面向服务器应用的处理器“EnergyCore ECX-1000”。它采用高度集成的SoC片上系统设计, 拥有最多四个ARM Cortex-A9处理器核心,每核心32KB一级指令缓存、32KB一级数据缓存,所有核心共享4MB ECC二级缓存。
前不久AMD斥资3.34亿美元购买微处理器厂商SeaMicro,英特尔不断开拓OEM合作生态链,大力推广其低功耗Atom产品,都在说明业界对功耗的重视。可以说谁能在未来占据低能耗市场制高点,谁就有可能取得了未来制胜的法宝。 此次AppliedMicro推出首款基于64位ARM架构的服务器,可以被认为是ARM领域对传统服务器市场发出宣战的利器,也是ARM对传统x86服务器首次提出挑战。作为ARM和x86两大阵营,ARM和英特尔公司,在原有市场占有优势地位的同时,都将目光盯向了对方的优势领域。 | |
|
(没有打分) |








社交网络的几个数据的PK
作者 陈怀临 | 2012-05-04 08:05 | 类型 行业动感 | 1条用户评论 »

中国拟定自主指令集架构标准?
作者 hid | 2012-05-04 07:00 | 类型 行业动感 | 8条用户评论 »
|
中国政府正着手打造一个能够作为全国计算机芯片的统一指令集架构,也就是全国统一的CPU架构标准(ISA)。不过相比于国产CPU本身,自主CPU的周边生态系统才是一个CPU能不能持续发展的主要因素,想想当年Wintel是如何实现双赢的。
目前已经甄选出来的共有五种架构及备选: ARM ARM(Advanced RISC Machines),既可以认为是一个公司的名字,也可以认为是对微处理器的通称,还可以认为是一种技术的名字。
ARM处理器是一个32位元精简指令集(RISC)处理器架构,其广泛地使用在许多嵌入式系统设计。
ARM作为苹果、Acorn、VLSI、Technology等公司的合资企业,其本身并不生产芯片,只将芯片技术授权转让给其他厂商,但是ARM在移动智能芯片市场的占有绝对的优势,近年来随着智能手机以及平板电脑的走红,ARM也从名不见经传到为数码爱好者所熟悉。 目前中国共有34家公司持有ARM架构的许可证,但仅Cortex-A9芯片的许可证,ARM公司就要价500万美元,因此ARM可能不太会得到青睐。 Power POWER是IBM开发的一种基于RISC指令系统的架构,相对于我们常见的X86架构的处理器,采用POWER架构的处理器具有结构简单和高效率的特点。 为了市场发展的需求,IBM公司联合Apple和Motorola两大巨头合力研发了基于POWER架构的新一代的PowerPC构架。PowerPC在低功耗和处理性能上都非常出色,同时它又具有与POWER架构软件完全兼容等特点,在嵌入式系统领域和IBM的超级计算机中都被广泛使用。
POWER架构首次大批量出现于1990年,IBM公司为满足客户对工作站以及可以支持UNIX操作系统的中型系统的需求发布了RS/6000系列产品,这一系列产品主要由POWER架构实现。 2010年2月8号,IBM在纽约正式发布了其Power7处理器。在x86处理器Nehalem占据人们视线许久之后,作为CISC外另一处理器常见架构RISC的Power系列CPU蛰伏三年后终于推出新品:Power7处理器。 相比上一代的Power6处理器,在多核、多线程方面有了很大提高:POWER6只有双核,而Power7达到了8核,且每核最多可以并行执行4路线程。虽然主频较上一代降低了,但仍有4.14GHz,例如同为八核的Nehalem-EX主频在2.66G至3GHz之间。UltraSparcT2处理器则只有1.4GHz。不过UltraSparc T2有8核64线程。这比Power7的8核32线程以及Nehalem-EX的8核16线程、安腾9300的4核32线程都要多。
POWER4,POWER5,POWER6以及POWER7处理器和其他厂商生产的POWER PC处理器都是采用这个架构的。目前POWER架构的处理器广泛在各个领域采用,大到超级计算机和跨国企业的UNIX服务器,小到蜂窝电话、车载系统的设备,都有它的身影。 Power架构相对便宜,不过它缺少像MIPS和ARM架构那样具有活力的软件生态系统。 MIPS MIPS是世界上很流行的一种RISC处理器。MIPS的意思是“无内部互锁流水级的微处理器”(Microprocessor without interlocked piped stages),其机制是尽量利用软件办法避免流水线中的数据相关问题。它最早是在80年代初期由斯坦福(Stanford)大学Hennessy教授领导的研究小组研制出来的。 我国自主研发的龙芯便是基于MIPS,目前在百万计的学校计算机上都能看到。
中国于2002年起投资50亿美元开发龙芯处理器,32位的龙芯一代运行频率只有266 MH;二代是64位,速度提高至1.2 GHz;针对服务器的龙芯3A处理器推迟一年推出。 它采用65纳米制造工艺,主频1 GHz,浮点运算16 gigaflops,有4.25亿个晶体管,功耗只有10瓦,芯片集成了4个核心,两个16位HyperTransport 1.0控制器,4MB二级缓存,内存控制器支持DDR2和DDR3;龙芯3B同样是65纳米工艺,主频仍然是1 GHz,集成了8个核心,每个核心2个256位矢量协同处理器,5.83亿个晶体管,浮点运算128 gigaflops,功耗40瓦。
龙芯发展到现在,10年的时间里已经发展到了第三代。从当初的龙芯1号到现如今的龙芯3A、3B。英文名从起初的Godson到现如今Loogson,从当初的应用在玲珑笔记本,到如今要实现超级计算机上完全应用龙芯。龙芯CPU的性能据称已经达到64位,以这样的速度不知20年后能否实现赶上美国水平。 龙芯期间从轰动一时到渐渐淡出人们视线,期间很大的原因在于龙芯与MIPS架构的说不清道不明的关系,从最初的法国意法半导体公司合作,再到后来购买MIPS指令授权。 MIPS公司的R系列就是在此基础上开发的RISC工业产品的微处理器。这些系列产品为很多计算机公司采用构成各种工作站和计算机系统。 MIPS是出现最早的商业RISC架构芯片之一,新的架构集成了所有原来MIPS指令集,并增加了许多更强大的功能。 由于MIPS技术公司最近经营不善,因此有传闻认为,这家位于美国加里福利亚森尼维耳市的公司很可能逃不出被收购的命运。对财力雄厚的中国政府来说,从资金上来讲,收购MIPS技术公司绝对是小事一桩,我国政府有足够的纳税人来支付这笔交易。 Alpha处理器 Alpha处理器最早由DEC公司设计制造,在Compaq(康柏)公司收购DEC之后,Alpha处理器继续得到发展,并且应用于许多高档的Compaq服务器上。自1995年开始开发了21164芯片,那时的工艺为0.5mm,主频为200MHz。1998年,推出新型号21264,当时的主频是600MHz。 而中国首台超级计算机神威蓝光MPP的神威处理器,则是基于Alpha架构。由国家并行计算中心研制,处理器采用的8704片16核的申威1600,其最大特点是核芯处理器全部采用国产CPU申威1600处理器。
目前较新的21264芯片主频达到1GHz,工艺为0.18mm。在该芯片具有完善的指令预测能力和很高的存储系统带宽(超过1GB/s),并且其中增加了处理视频信息的功能,其多媒体处理能力得到了增强。
神威Alpha架构有可能最终入选,可它仍无法与MIPS的用户基础相抗衡。 本土研发的CPU 自从1991 年以来CPU的架构就未曾有过大的变化,但现在CPU的发布改变了这一切,它完全由中国自主发展。可以说是CPU领域的一大进步。 国内超级计算机排名第一的天河1号已经尝试着试用国产CPU,天河1号采用了国防科大研制的飞腾-1000处理器,但并不是完全采用。而神威蓝光则是跨时代的全部采用国产CPU。 早在2009年,中国工程院院士、国家并行计算机工程技术研究中心主任金怡濂就说,中国完全有能力采用国产CPU(中央处理器)芯片,在短期内完成国家千万亿次巨型计算机的研制任务。本次的神威蓝光恰好是其预言的印证。 在国产处理器三大系列当中,国防科大的飞腾系列、中科院计算所的龙芯系列、都在此前有过风光无限。 备选 中国发布一种全新的架构作为标准。除了上面提到的五种待选架构外,中国的决策层还有意表示,发布一种全新的架构作为标准。在今年三月份的时候,由华为、中兴等企业代表以及多位政府官员、高校老师召开了一次全国性指令集架构的第一次会议。根据MIPS的副主席所说,在未来的几个月最终的结果就会公布于众。 说到备选方案,开发一个全新的架构。这是一项让人望而却步的工作。因为需要从零开始,这将耗费大量的人力物力,去开发软件(编译器,培养程序员,码软件),硬件(CPU,芯片组,主板等),创建一个由软件和硬件共同组成的生态系统。 http://servers.pconline.com.cn/news/1204/2763331_all.html#content_page_1
近年来中国越来越注重本土自主的设计标准协议,而不仅仅是从国外企业购买设计专利。例如,中国已经在从CD/VCD播放机到视频监控系统上有着自己的标准。另外在通信技术上,3G通信网络技术的TD-SCDMA标准就是由中国制定,而同时中国移动对4G标准TD-LTE的研发也是稳步进行。而对于自主处理器的研究,中国已经有了数十年的历史,其中的代表龙芯,是基于MIPS架构设计的国产CPU。不过业内对于龙芯的态度褒贬不一。 除了龙芯之外,在国产处理器三大系列当中,还有国防科大的飞腾系列、江南计算所得申威系列。 国内第四个超级计算机中心济南中心2011年10月底正式挂牌成立,作为全国3个千万亿次超级计算中心之一,其采用的神威蓝光高效能计算机,由国家并行计算中心研制,按照MPP万万亿次架构设计,处理器采用的8704片16核的申威1600,其最大特点是核芯处理器采用国产CPU申威1600处理器。 神威蓝光 目前,我国至少有6个现成的处理器架构是新标准参考的样本,而提议的未来处理器标准既有可能是现有架构,也可能是另外自行建立一个新的指令集架构设计。
| |
|
(2个打分, 平均:4.00 / 5) |