




解密:UCloud北京BGP-A机房 . DDOS攻击
作者 陈怀临 | 2014-05-26 17:24 | 类型 网络安全 | 3条用户评论 »
UCloud北京BGP-A机房被攻击声明2014年5月26日 11:38
UCloud北京BGP-A机房于2014年5月25日20:18遭受人为DDOS攻击。经有关部门调查,攻击者调用几十万台肉鸡进行攻击,攻击流量达到63G,严重影响部分用户的正常使用。 UCloud已联合运营商、安全厂商进行修复,攻击已于5月26日凌晨0:02被成功抵御,网段已被隔离。 针对此次事件受到影响的用户,UCloud根据相关协议将履行相应的赔偿措施。 众所周知,DDOS攻击是互联网的恐怖袭击,严重影响了中国互联网的发展,制约互联网企业成长。UCloud作为国内领先的云计算服务平台,一直以为用户提供安全、稳定的云服务为己任。对于如此恶意之行为,UCloud强烈谴责,并已联系相关行政机构进行取证、追查,希望相关知情人士能积极提供线索。 为保障中国互联网的有序发展,打击互联网恐怖袭击事件,UCloud宣布将投入1000万作为互联网安全基金,为中国互联网创业者打造一个安全、稳定的互联网环境。 最新进展2014年5月26日 15:37
1. 针对北京BGP-A被攻击事件受影响的用户,我们的客户经理正在联络进行相关赔偿。 2. 我们的技术团队正在对原有抗DDOS黑洞设备进行全面升级并逐步部署在UCloud国内所有的数据中心上。此外,技术团队已联合国内安全厂商出具优化安全方案,加大机房带宽并优化人工处理流程形成预案机制。 3.同时,我们正在收集和整保存相关证据配合执法部门调查取证,也请相关知情人士提供线索,我们将进行奖励。 -----
| |
 (没有打分) (没有打分) |
迈普通信 。IPO。解密
作者 陈怀临 | 2014-05-25 01:30 | 类型 行业动感 | 1条用户评论 »

美国司法部起诉中国五位中国军官的原文起诉书
作者 陈怀临 | 2014-05-23 01:21 | 类型 行业动感 | 1条用户评论 »

OpenStack 2014 Atlanta Summit 视频集锦
作者 陈怀临 | 2014-05-22 23:45 | 类型 行业动感 | Comments Off
|
作者:郑晨,OpenStack中国社区,转载请注明出处 编者按:OpenStack Atlanta 峰会正在如火如荼的进行,这里OpenStack中国社区将峰会的热点视频分类汇总,让大家可以及时跟进社区最新动态,视频集锦将随峰会进行不断更新,希望能够帮助国内OpenStacker紧跟社区发展脚步,共同构建OpenStack生态圈。
一、热点视频Rise of the superuser (超级用户的崛起) 在过去的一年里,我们见证了社区的转变,随着用户在社区中越来越多的声音,以及在技术合作伙伴的帮助下,用户在软件产品上影响力的增强,我们看到了用户给自身产品中增加革命性变化所带来的竞争力。在下面视频中,Jonathan Bryce 将介绍社区Superuser(超级用户)项目的发展,其中还包括来自Wells Fargo 银行和Walt Disney 公司的特约嘉宾Glenn Ferguson和Chris Launey对于超级用户的理解。 Just Rebels? Or A Rebel Alliance?(孤军奋战还是合从连衡) OpenStack的快速发展正逐步引领用户和社区对于因计算的改变。但是这不足以让我们看清这日渐激烈的竞争和日趋复杂的面貌。现在,我们必须要将眼光放长远,这意味着我们需要将云扩展开来,拥抱所有我们可以拥抱的,接纳多元化的贡献者。这意味着我们需要共同定义用户需要的是什么,并且使OpenStack足够强大 Innovation in the Enterprise Dell副总裁兼CTO Sam Greenblatt 从Dell的视角诠释OpenStack在未来的企业级领域中是如何进行创新的,并且与Red Hat的高级副总裁 Tim Yeaton一同介绍了 Dell 与 RedHat 是如何让OpenStack在企业级领域成功的 Jonathan Bryce announces launch of the OpenStack Marketplace Jonathan Bryce给我们带来本届峰会中新概念,OpenStack大卖场(Marketplace),当用户想构筑、应用、消费混合云时,大卖场将帮助用户作出正确决定,卖场中包括培训,公有云,咨询等服务。 Software is driving the revolution 来自OpenStack基金会的首席运营官 Mark Collier带来主题是“云计算,开源和敏捷的基础架构正在改变世界,OpenStack推动是这场变革的核心”的峰会第二日开场。Mark谈到,现在每家公司都在和Startup竞争(every computing is competing with a startup),开源软件的无处不在,以及云计算服务平台、软件组件API生态快速发展使得开发和运营各种创新软件变得越来越容易和便捷,进入一个行业并占据巨头的时间正在逐步逐步缩短,领军的公司时刻都有可能被新兴公司超越,快速和不断创新是时代的主旋律,软件在推动变革(Software is driving the revolution)。 二、核心讨论The Future of OpenStack Networking 包括Neutron Core,Red Hat SDN项目组长在内的四名活跃在OpenStack网络领域专家齐聚Atlanta, 他们针对Neutron网络的未来发展方向进行了深入讨论,内容包括更多插件,高可用,让Neutron真正可以提供网络虚拟化等,点此观看 OpenStack Security Group (OSSG) An Update on Our Progress and Plans OpenStack 安全项目组在2012年秋天成立,从软件脆弱性管理项目组到提供安全最佳实践,OSSG一直非常忙碌,这届峰会,安全项目组主要就Ironic、项目的安全评测标准以及安全测试方面进行讨论,点此观看 Software Defined Networking Performance and Architecture Evaluation 这里Symentec将对超过100个节点,分别处于Overlay 网络与普通VLAN网络的架构和性能特点进行分析,并且向大家介绍Symentec的架构设计思想,点此观看 Using OpenDaylight Within an OpenStack Environment OpenDaylight是一个开源平台,旨在为网络功能虚拟化(NFV)提供坚实支持,并且通过可编程特性引入软件定义网络(SDN)概念。OpenDaylight和OpenStack Neutron项目组已经合作实现虚拟租户网络的构建。这里,我们将讨论实现的技术细节,并且举例说明结合OpenStack Neutron与OpenDaylight的好处,点此观看 Continuous Integration Testing for Your Database Migrations 来自Rackspace的joshua Hesketh 将对OpenStack数据库迁移中的持续集成测试的测试架构,可搭建测试架构过程中遇到的问题及解决方案进行介绍,鉴于持续集成测试一直是社区所关注的,而大规模数据库迁移性能问题也在视频中被提到,点此观看 Nova’s March Towards Live Upgrade Capability Red Hat的 DanSmith将为大家介绍Nova在线升级的最新动态,在生产环境中,这个话题一定是大家热切关注的,Icehouse发布中包含了很多支持在线升级的新特性,点此观看 The State of OpenStack Data Processing Sahara, Now and in Juno 来自Red Hat,Mirantis, Hortonworks的 Matthew Farrellee, Sergey Lukjanov 和 John Speidel 将在这段视频中为大家带来Sahara的宏观介绍,项目主要目标以及Icehouse中的新功能。其中具体包括了:如何与Heat集成,Tempest基本的API测试,以及一系列弹性数据处理等。最后它们还对Juno版本中的项目发展路线进行了总结,点此观看 三、技术动态OpenStack Python and the Holy Grail A New Proposal for Image Portability 我们对可移植性,联邦,互联性都非常熟悉。Holy Grail表示,不仅虚拟机可以迁移,虚拟机镜像现在也可以具备编写性。由于互联网数据中心的数据迁移需求,OpenStack来实现镜像迁移也许才是最好的选择,点此观看 Initial Use Cases for OpenStack _ Cinder In Your Enterprise IT Strategy 来自SolidFire的OpenStack块存储PTL John Griffith和来自PayPal/Ebay的OpenStack存储架构师将就Cinder在企业环境中的应用进行讨论,特边针对了块存储在测试和开发环境中的应用,希望对运维OpenStack环境的人带来生产效率的提高,点此观看 A Globally-Distributed Storage Cloud with Disaster Recovery 像电力资源一样,计算资源可以轻易扩展,并且可以跨地域运行工作。而存储资源则更像水,像移动大量水资源一样,大规模数据移动具有挑战性,尤其是长距离移动。SwiftStack CEO Joe Arnold 为我们带来新的存储异地部署架构和解决方案,点此观看 The Biggest Thing in OpenStack Swift Since it was Open-sourced Storage Policies 这里OpenStack对象存储的PTL John Dickinson将为大家带来OpenStack Swift重大的新功能——在对象存储中添加存储策略。在视频中,John将为我们说明社区是如何合作完成这项新功能,并且说明存储策略意味着什么,点此观看 Customizing Horizon Without Breaking on Upgrades Red Hat软件工程师与大家分享如何在不影响升级的基础上自定义Horizon,并支持持续升级和维护,点此观看 OpenStack as the Key Engine of NFV Ericsson 云计算系统架构师 Alan Kavanagh和 云计算系统和平台产品副总裁 Jan Söderström带我们了解运营商级别OpenStack作为NFV核心平台的技术细节,点此观看 Security for Private OpenStack Clouds 首先,私有云并不是位于防火墙后面的共有云,Nebula 安全领域专家 Bryan D Payne首先为我们从技术和应用角度分析了共有云和私有云的异同,之后给出了针对不同需求的不同私有云安全解决方案,视频中既包含了高级的概念解析,又包含了技术细节,点此观看 Troubleshooting Neutron Virtual Networks Rackspace的云计算技术官 Phel Hopkins将针对OpenStack云计算平台较为复杂的网络排错问题进行分析,结合Linux中最为流行的一些排错工具,通过对Neutron创建的承载虚拟机通信数据流网络的分析找到如何修复Neutron问题的方法。对于OpenStack运维人员来说,这段视频不可错过,点此观看 Delivering OpenStack Clouds as a Factory eNovance 产品副总裁 Nick(Nicolas) Barcet 就如何像工厂一样提供OpenStack云服务一话题与大家分享, Bridging The Gap OpenStack For VMware Administrators 随着OpenStack的发展,越来越多的VMware企业级用户希望将OpenStack平台与自身虚拟化环境相整合, Migrating Workloads from Amazon Web Services to HP Public Cloud OpenStack Environment 将亚马逊云中主机迁移到HP OpenStack共有云之上, HP 的工程师们在这段视频中给大家带来它们的解决方案,点此观看 四、Demo演示Metacloud: A New Take on Hybrid Cloud 刚刚融资3500百万美金的Metacloud为我们带来它们的混合云演示,点此观看 Oracle:Modern Cloud Infrastructure with Oracle Enterprise OpenStack Oracle为我们介绍自身OpenStack 现代企业级云计算平台架构,点此观看 Suse:HA Out of the Box Easily Deploying a Highly Available Cloud Suse将为我们带来便捷部署高可用云平台解决方案,点此观看 NetApp:Optimize Cloud Storage with NetApp NetApp 带来了他们的云存储优化解决方案,点此观看 Piston Cloud:All the OpenStack Goodness and More! Piston带来了它们增强、优化版的OpenStack,点此观看 五、社区发展So You Want to Be an OpenStack Contributor 如果你想要贡献OpenStack社区,那么可以从这里开始,这段培训视频包括如何注册Gerrit、Git、launchpad,签署贡献者认证协议等,如果你对编程不感兴趣,还可以参与到文档和翻译的社区工作中来,点此观看 OpenStack Training – Community Created and Delivered Training for OpenStack 来自Nexus IS 首席云架构师 Colin Mcamara 和Yahoo的Sean Roberts 将为我们分析OpenStack 培训的目前状况和长远计划,OpenStack的普及与培训密不可分,如何提供培训服务也成为社区和广大OpenStack关注的焦点,点此观看 How Community Can Make OpenStack Customer Centric 社区如何才能吸引用户,Mirantis 联合创始人Alex Freedland强调,加入OpenStack开源社区最大的好处在于,我们可以影响项目的发展和动向,使OpenStack向真实用户所需求的方向发展,Mirantis作为OpenStack的主要提供商,我们自身就由一系列关于如何欢迎新用户、帮助新用户得到OpenStack的最佳实践,点此观看 | |
|
(没有打分) |
GFT你这么diao,你的伪粉丝们造吗(3)
作者 彩筆 | 2014-05-21 01:37 | 类型 大数据, 行业动感 | 1条用户评论 »
|
GFT 3.0: updated (2013) 副标题:旁观一个技术主管的verbal reasoning ability
注:本文“内容”若非特别注明,均来自“Copeland P, et al. Google Disease Trends: an Update. International Society for Neglected Tropical Diseases. 2013. available at: http://patrickcopeland.org/papers/isntd.pdf”一文。
GFT 2.0针对GFT 1.0对非季节性流感的Underestimate做出改进(在建模过程中增加了09年H1N1爆发期间的检索数据)。GFT 3.0是针对在2012年流感季节,GFT 2.0对实际数据的overestimate作出的改动。 第一次更新时,GFT 1.0 underestimate的原因被归结为季节性流感和非季节性流感期间用户的health-seeking behavior不同,但并未明确指出究竟为何不同。 在构建GFT 3.0时,GFT团队将导致GFT 2.0 overestimate的原因归结为媒体的放大效应。表现为:大众媒体对流感疫情的报道,使更多的未患病个体也进行flu-related检索,导致检索词出现次数与ILI病例比例之间原有的数字关系不再“有效”。
作者尝试在文章中给出以下问题的答案。 1. 为什么12-13年度的流感季节中,GFT的预测过高?Why were this season’s predictions so high? 2. GFT模型是否过于简单粗暴?Is our model too simple? 3. GFT 2.0中是否仍有未考虑到的影响因素?Were there unforeseen side effects from the 2009 update? 4. GFT是否能表现出CDC的ILI数据之外的现象?Does this reveal a phenomenon not captured in incidence data provided by the US Centers for Disease Control and Prevention (CDC)?
旁白:都是好问题,从实际问题出发(overestimation),既有对GFT本身的反思(too simple),也对有关GFT的舆论做出回应。层层递进,有理有据。
1. 怎么就overestimate了 GFT 1.0刚上线时,计划对它每年更新一次。然而在GFT 2.0和GFT 3.0之间,未有annually update。原因是,每个流感过后对GFT模型评估,GFT 2.0的表现so far so good。团队的观点是:不断添加新数据确实能够提高估计的准确性,但对于truly anomalous years的情况无改善。 GFT 2.0一直doing well,直到2012-2013 flu season,模型输出的预测结果明显偏离了真实数据源,(However, in the 2012-13 season, the overestimation peaked at 6.04 percentage points, an estimate more than twice the CDC-reported incidence (week starting Jan. 13: CDC data 4.52%, GFT estimate 10.56%).),drastically overestimated peak flu levels [1]。
2. 简单粗暴,不失有效 GFT团队承认,他们的算法容易受到短期内检索词数量不规则变化的影响,而这些“数量的不规则变化”可能是concerned people对流感相关的媒体报道做出反应的结果。(所以,GFT的直接目的是预测CDC ILI data,但它所能描述的远不止于CDC ILI data。) GFT团队在承认他们的算法sensitive to sudden changes in query volume的同时,也巧妙地表达了不能公开组成模型的检索词的必要性。作者回忆在2008年发布GFT 1.0时,New York Times的一篇报道碰巧包含一个模型中的检索词。他们马上就看到了这条检索词流量的增加。笔者不禁想到,Lazer [2]在他的文章中一边要求Google公开GFT的内部细节,一边也担心所谓的red team issues(用户有预谋地操纵“数据生成过程”),是赤裸裸的自相矛盾啊。
3. Unforeseen side effects肯定是有的了 基于上述推理,GFT团队进一步修正了模型,以摆脱媒体报道的影响。 (1)为降低算法的sensitivity,GFT团队用“spike detectors”监测数据中inorganic检索词流量,并将其从模型中剔除。做法:The system receive time series data of the flu-related queries as input and validates whether the latest counts are within expectation, based on statistical variations from what we have seen in the past. 从2008年以来的数据得知:大多数由新闻报道引发的关注所导致的query spikes大约持续3-7天。这种情况导致,上述处理过程只能solve for short-term spikes,对在整个流感期间延续的high query volume无能为力。 (2)除此之外,作为对于外界普遍吐槽的GFT模型简单的回应,GFT 3.0也尝试了几个高大上的优化算法。
LARS是更适合高维数据(比如:变量数多,案例数少)的一种回归算法。在对多个自变量回归分析,得到1个因变量的预测的分析过程中,LARS算法可以确定哪些自变量参与回归,并得到这些自变量的系数。
LASSO和Elastic Net均是对回归模型进行规范化(regularization)的方法。LASSO(Least Absolute Shrinkage and Selection Operator)的penalty function为
。Penalty function为包含λ1(线性)和λ2(二次)的部分。 写这些并不是为了让每个读者都看懂甚至理解,而是为了给大家营造一种身临其境的感觉:GFT不再是那个国内本科学生毕业设计的非专业水平了。各个优化版本模型的预测效果可见下图。
从图中可以明显看出Current Model对CDC data的overestimate,但究竟哪个优化的模型效果最好却不显而易见。特此为每个模型的预测输出计算RMSE,Elastic Net的RMSE最小(1.22),即其效果最好。
写在最后的话 纵使笔者心中仍有千万次的问,作者的文章到此便戛然而止了。笔者很忧伤,却也毫无办法,只能开始总结。 从逻辑上讲,GFT的一切行为都是合理的。对于在每一处关键点上的选择,不排除其他alternatives的存在,但是不存在比GFT的选择明显更优的处理方式。 纵观整个GFT模型更新的过程,第一次更新向仅有季节性流感数据的旧模型添加非季节性流感的数据,自此,GFT双腿健全,可以稳健地丈量CDC数据。 CBS热播剧《BONES》中的starring actress有一句频繁出现的台词:I believe in patterns。还没想清楚的人不妨认真考虑一下了:GFT并不是literally“神来之笔”,它的诞生机制和工作原理决定了它的输出结果(对CDC数据的预测值)是依赖统计学习习得的“规律”,将现有值与未来某时间的“可能值”建立联系,而已。期待它给出一个确定的真实值这个愿望是不切实际的。 私以为,pattern比truth更加客观。每个人都可以把自己坚持的称作“真理”,并拒不接受说教。Pattern却不然。A出现10次中,有8次B也同时出现(贝叶斯[崇拜样]),这就是一个pattern。下次A出现时,笔者愿意投入成本做好B伴随出现的准备。也许有人会问,会不会A出现的10次中B也出现10次?To这样可爱的同学:当然会啦。只是这样的情况,如何确定B不是A的天然组成部分)?哈利波特偷偷去霍格莫德村,穿着隐形衣帮忙打架,不小心将头露了出来,马尔福少爷回学校打小报告时的推理过程是这样的:你的头出现在了那里,那么你的身体也一定在那里。See the beauty of uncertainty。换句话说,当pattern变成了“注定”的(definite),也便失了趣味性。【写这一段的目的是想传达:GFT是应用统计学习方法做出来的一个产品,各界都需要调整好对GFT的期望值。同时,也从逻辑上引出下一段。】 所以说GFT团队的vision也是极其精辟的。对GFT的第二次更新并没有纠结那些学者们不肯放手的检索词问题,可重复性问题——这些都不重要。GFT的核心矛盾必须是对统计学习方法的无上限的完善过程好么。按照大数据的处理思维,从原始数据中直接捞出来的(may not be perfect),但一定是best | available了。文章[3]点到为止地总结了入选模型的几个检索词的主题,以及数量和体量(占比)等,只不过是可视化不可见“模型”的一种手段而已。一些矫情的人类个体给点儿阳光就灿烂,嫌弃“描述性”的内容太少,各种,已经不单是避重就轻的迟钝,甚至是买椟还珠的愚蠢。 GFT的第二次更新考虑了多种优化模型的算法,反映了统计领域的state of art,不管从战略还是战术上看,都妙极,妙极。
关于副标题:都说是“旁观”了,顺便看一下得了。总的来说,原文是一篇虎头蛇尾的文章。前面铺垫的絮絮叨叨,像极了革命战士喜欢的千层底儿的鞋,结尾却只有戛然而止,断没有余音绕梁,徒留笔者独自在电脑前神伤好嘛。
相关文献: [1] Butler D. When Google got flu wrong[J]. Nature, 2013, 494(7436): 155. [2] Lazer D, Kennedy R, King G, et al. The Parable of Google Flu: Traps in Big Data Analysis[J]. Science, 2014, 343(6176): 1203-1205. [3] Ginsberg J, Mohebbi M H, Patel R S, et al. Detecting influenza epidemics using search engine query data[J]. Nature, 2009, 457(7232): 1012-1014. | |
 (1个打分, 平均:5.00 / 5) (1个打分, 平均:5.00 / 5) |

包云岗 。《浅谈产业界与学术界的合作研究》
作者 陈怀临 | 2014-05-19 19:50 | 类型 行业动感 | Comments Off
|
[编者注:原文可参阅: http://blog.sciencenet.cn/blog-414166-795432.html ] 最近网络上有一个流传甚广的微故事:“某企业引进了一条香皂包装线,结果发现经常会有空盒流过。厂长聘请一个博士后花了200 万设计出一个全自动分检系统。一个乡镇企业遇到了同样的问题,民工花90 元买了一台大电扇放在生产线旁,一有空盒经过便会吹走。”这个微故事不断出现在笔者的视线中,想必在网络上得到了公众的认可、引起了共鸣,所以大家争相转发。平心而论,大多数人的内心其实是崇尚知识的,而用这个故事来揶揄以博士后为代表的科研人员,也许更多的是想表达对国内科研现状的不满。 其实在国内不仅是普通民众对学术界不认可,即使在同一领域,产业界与学术界之间也存在明显的隔阂,这在信息技术领域似乎尤为突出。产业界认为学术界的研究是自娱自乐、毫无用处,纯粹浪费国家资源,而学术界则认为产业界的研发是山寨复制、水平低下,没有技术含量。 相比较而言,美国信息技术的产业界与学术界则融洽得多,既相互尊重又互惠互利,既有分工又有合作,共同推动信息技术的发展。面对中美两国产业界与学术界关系的巨大差异,我们不禁会产生很多疑问——美国是否也经历过中国这样的阶段?他们今天的模式是如何形成的?美国的产业界与学术界之间是如何分工合作的?中国该如何改变产业界与学术界的关系?美国有哪些经验教训可以借鉴? 本文将就这些问题谈一下笔者的个人观察和粗浅看法,由于一个人的视角有限,难免有片面与不当之处,所以希望抛砖引玉,能引起更多对这个话题感兴趣的朋友的探讨,为改善我国信息技术领域产业界与学术界之间的关系提供一些建言。 一、美国学术界的探索 美国的学术界在与产业界互动过程中的分工是比较清晰的。为产业界输送人才是学术界最重要的目标之一。从美国高校整个范围来看,实习生模式是连接学术界与产业界的一种最普遍而又有效的方式,几乎所有学校都允许和鼓励学生到企业去实习。但是每所大学在具体的人才理念、培养方式、流动模式等方面又有所不同,或者说是各具特色。于是不同学校培养出来的人才也会有一些比较鲜明的特点,比如斯坦福大学的学生更喜欢创业,麻省理工学院的学生则更热衷于攻克技术难题。这些模式是各大学不断探索逐渐形成的。 斯坦福大学的硅谷之路【1】 今天的硅谷是名副其实的世界信息技术中心,是产业界与学术界有机融合的典范。斯坦福大学在硅谷的诞生和崛起过程中起了决定性的作用。正是20 世纪60 年代斯坦福大学工程学院院长特曼的天才创意——将1000 英亩校园象征性地廉价长期租给企业,才奠定了今天硅谷的辉煌。 然而,斯坦福大学与硅谷企业之间的合作模式也是在经历了多次转型和探索后才逐渐发展起来的。斯坦福大学成立于1891年,在最初的几十年效仿了欧洲大学的“象牙之塔”理念,认为大学应该从事高雅的、形而上的研究,而开展应用研究则被认为是功利的、物欲的。 二战期间,斯坦福大学调整了办学理念,认为大学不应当是“不食人间烟火的象牙塔”,而应该是为社会公众服务的机构,于是斯坦福大学积极参与美国联邦政府与军工企业的一些科研项目。然而这种转变并不是一帆风顺,毕竟大学和企业关注的侧重点有所不同,双方的做事方式与文化也有很大区别,所以在合作过程中不可避免地产生了一些矛盾。比如在20 世纪30 年代末,斯坦福大学曾经和企业有过一次不成功的合作。当时斯坦福大学物理系教师发明了微波电子管,美国斯佩里公司看中了该技术的市场前景,支付经费希望联合产业化。但在合作过程中,斯佩里公司完全掌控了实验室,干涉实验方向,强制加快实验速度,甚至限制教师发表学术论文,最终导致双方不欢而散。这次失败的经历促使斯坦福大学反思到底该如何与企业合作。 二战结束后,斯坦福大学开始探索建立新型的与政府和企业需求直接对接的教学科研与人才培养体制,推出了一系列新的措施。表1 列出了一些有代表性的措施,比如调整薪水,热门专业教授的薪水可能是冷门专门的两倍。这些措施的目标是让各个院系能获得尽可能多的外部企业资助,但这引起了抱怨——“办大学像办公司,教授都成了雇员”。
不过,这些改革措施为斯坦福大学的崛起奠定了坚实的基础,而硅谷的企业和斯坦福大学也实现了深层次融合。由斯坦福大学的教授和学生们创办的信息领域的公司包括惠普(HP)、思科(Cisco)、谷歌(Google)、雅虎(Yahoo)、威睿(VMWare)、贝宝(PayPal)、英伟达(NVidia)、硅谷图形公司(SGI)、MIPS、升阳(Sun)、邻客音(LinkedIn)、网飞(Netflix)、罗技(Logitech)……,还包括已跨入可穿戴设备产业的耐克(Nike)。2012 年的一项研究显示斯坦福大学的毕业生每年创造2.7万亿美元的收入【2】。尽管“2.7万亿”这个数字大得让人难以置信,但斯坦福大学确实在以其独特的方式推动信息产业的发展。 “斯坦福- 硅谷”模式是否可以在世界其他地方复制?这个问题相信有很多人都在研究。我们肯定无法全盘复制,但其理念和一些措施也许值得借鉴。 加州大学伯克利分校计算机系的业界交流会 加州大学伯克利分校的计算机研究水平在全世界首屈一指,特别是在计算机系统结构方面。该校计算机系诞生了很多推动计算机产业发展的经典之作,例如Berkeley Unix, RISC, RAID,NOW, Berkeley AMP 实验室的Spark。体系结构泰斗、发明RISC 和RAID 的加州大学伯克利分校教授大卫·帕特森(David Patterson) 曾多次提到这些项目成功的关键,其秘诀就是每年举办两届为期3 天的业界交流会。 帕特森教授在其最近的文章《如何建设一个糟糕的研究中心》(How to Build a Bad Research Center)【3】 中提到,这种交流会使实验室每位成员都有机会与数十位来自业界的专家交流。专家会对项目的各个方面提出建议,这对项目的理解与研究方向的调整非常重要。而在学术界要得到这样面对面的交流机会是非常难得的。这种交流会对学生的培养也起到了非常积极的作用。每位博士生在攻读博士期间可以获得至少10 次交流机会,这不仅有利于推进学生研究工作的阶段性进展,也有利于培养学生的表达能力,而且还能扩大学生的社交圈,对他们未来择业有很大帮助。一份针对已毕业的加州大学伯克利分校计算机系校友的问卷调查显示,100% 的校友对业界交流会都给予了积极的评价。这样的交流会在加州大学伯克利分校已经实行了近30 年,取得了非常显著的效果,使该校的计算机研究始终处于国际最前沿,推动了计算机产业的发展。 除了每年定期举行的业界交流会外,帕特森教授在其文章《您的学生是您的财富》(Your students are your legacy)【4】 中提到派学生去工业界实习的重要性。帕特森称,当他的学生在寻找研究问题上遇到困难停止前进时,他就会让这些学生到工业界工作6 个月。他们回来之后就能清楚地了解他们想做什么研究,更重要的是,他们知道了为什么要去做这个研究。 加州大学伯克利分校的这些举措从研究成果与人才培养两方面来看都是卓有成就的,为计算机产业不断输送动力。与斯坦福大学自上向下的设计不同,这些举措并不需要学校层面上的特殊支持,更容易实施与操作,且不受地域和时间的限制,对我们国内的大学和研究机构有更大的借鉴意义。 美欧主流高校的理念转变 大学最早是在11 世纪的欧洲诞生,其办学理念与原则逐渐沉淀为“大学自治、学术自由”。这种理念让大学在朝代频繁更替的历史进程中得以生存并不断发展,成为人类历史上最有生命力的社会机构。比如英国牛津大学创办于1096 年,距今已有近千年历史;剑桥大学创办于1209年,也有800 年历史。19 世纪初,德国人洪堡创建了柏林大学,将研究和教学结合,开辟了现代大学新模式,但仍以“大学自治、学术自由”为原则。一直以来,大学注重的是基础学科和纯粹学术的研究,离社会民生需求很远。美国早期的大学如哈佛、耶鲁等,都是模仿欧洲的大学建起来的,也继承了这些办学理念。 如今许多世界著名大学的理念发生了转变。2011 年, 哈佛大学校长德鲁·吉尔平·福斯特教授在哈佛建校375 周年之际接受媒体采访时谈到了哈佛的新治校理念。福斯特校长认为,“终生的学问始于学校,终于社会”,大学不再是“象牙之塔”,而应该服务于社会。为此, 哈佛大学通过一系列措施来践行这一理念,比如创建了一个新的工程和应用科学院,加强应用技术研究;2011 年又筹建了创新实验室(ilab),鼓励教授、学生参与创业。其他大学如普林斯顿大学、麻省理工学院,参与创业的教授与学生的比例也在不断增加,在课程设置上也相应地有所改变。普林斯顿大学计算机系的辛格教授(J.P. Singh) 开设的“技术、商业与市场的跨界创新”【5】 课程会邀请很多风投专家、技术专家和有创业经历的人士为学生介绍技术发展趋势、管理方法、创业经验等。 欧洲的大学与研究机构的理念也有转变,比如剑桥大学的计算机实验室主任安迪·霍珀(Andy Hopper) 教授极力推崇科学家与企业家结合的模式。霍珀教授身体力行,曾与人共同创办过13家公司, 其中有3 家公司已经上市,包括如今可比肩英特尔的ARM 公司。霍珀教授在管理实验室时鼓励研究人员创业,并引入新的管理模式,例如实验室项目的优先级会根据商业前景来动态调节,提出和实施共同财富创造框架(mutual wealth creation framework) 等。剑桥大学计算机实验室在这些理念的贯彻下,在过去几十年研制出了ARM、Xen等对计算机产业起到巨大推动作用的技术,也诞生了200 多家企业,霍珀教授本人则被英国广播公司誉为“英国计算机历史中的一位偶像级人物”。 这些理念的转变值得学术界思考。一方面,国外顶尖大学的顶尖教授与工业界的联系非常密切,这些顶尖教授几乎都创办过公司或在一些公司担任首席科学家或首席技术官职务【6】。另一方面,许多大学教授在学术休假期间会选择去企业工作,其中有不少最终选择留在企业。德州大学奥斯丁分校的道格·伯格(Doug Burger) 教授和凯瑟琳·麦利金(Kathryn McKinley) 教授便先后去了微软研究院。而哈佛大学的马特·威尔士(Matt Welsh) 教授在学术休假期间到谷歌工作了一年后,决定从哈佛大学辞职留在了谷歌。 纵观历史,人类的研究活动越来越多地从探索客观规律的科学研究向利用客观规律的技术研究倾斜,而记录重大技术突破的技术发展史其实就是一部人类社会发展的技术选择史。这个观点对于计算机这门应用性很强的学科而言尤其突出。如果说实践是检验真理的唯一标准,那么除了少数发现客观规律的计算机理论工作外,对于绝大多数计算机系统与应用技术而言,市场才是检验其价值的核心标准。 二、美国产业界的努力 美国的产业界对基础研究与前沿研究非常重视,除了产品研发,很多企业还专门设立了从事基础研究与前沿研究的实验室。这些研究院与实验室在一定程度上为企业提供了技术储备。但企业内部的小循环并不能让整个产业持续发展,因为推动整个产业发展不仅需要单项技术进步,还需要整个技术生态环境的支持,这包括大量的科研人员和足够的科研投入。而培养人才与开展研究正是现代大学的社会职责,因此产业界一直以来都非常重视与学术界的联系,并不断探索新模式来加强这种联系。 SRC:企业社团模式 20 世纪70 年代末到80 年代初,美国的半导体工业的发展进入了瓶颈期,一方面AT&T、IBM、施乐、西屋公司、通用电气等大公司由于经费紧张,已不能像以前那样继续维持大规模的企业实验室,因此都大幅削减了对基础研究的投入,这导致美国企业在全球半导体产业中的份额和竞争力不断下滑。另一方面,因为集成电路的设计和生产成本不断增加,而联邦政府投入的研究经费却不断减少,导致只有很少的大学开展半导体相关的研究。1982 年,全美上千所大学中只有不到100 位教授和学生从事半导体相关的研究【7】,美国的半导体产业前景一片灰暗。 面对如此严峻的局面,有“硅谷市长”之称的英特尔联合创始人之一罗伯特·诺伊斯(Robert Noyce) 挺身而出,在1982 年给了拉里·桑尼(Larry Sumney) 一张个人支票,委托他负责启动半导体研究社团(Semiconductor Research Corporation, SRC)。该社团是一个非盈利组织,其目标是定义半导体相关的研究方向、探索重要的潜在新技术、引导大学培养半导体研究方面的人才。 半导体研究社团的运作方式很像美国国家科学基金会(NSF),但经费来源主要依靠加盟企业的会员费以及政府、军方的部分支持。在半导体研究社团成立之初,其会员主要有IBM、英特尔、摩托罗拉等11 家企业,如今已经发展到20 多家。半导体研究社团负责收集企业的研究需求,并反馈到大学。大学教授则可以根据自己的研究兴趣与优势向半导体研究社团申请经费,一个项目几十万美元。例如,2011 年,多家企业因为对集成系统设计有研究需求,于是向半导体研究社团提交了一份3 页长的白皮书,其中包含多核片上系统(system on a chip, SoC) 设计、系统功耗优化等5 大类35 个具体研究需求。大学教授可以根据该白皮书向半导体研究社团提交与这些需求相配的研究申请,半导体研究社团将会邀请专家对项目申请书进行评审,择优资助。 在具体项目管理方式上,半导体研究社团根据不同的研究方向制定相应的研究计划,每个研究计划包含5~6个研究中心。笔者在普林斯顿大学时开展的PARSEC项目就得到了半导体研究社团的资助,隶属于FCRP(Focus Center Research Program) 研究计划中的GSRC(Gigascale System Research Center) 研究中心【8】。图1 左侧列出了参与GSRC 的大学教授,这些教授几乎都是来自加州大学伯克利分校、斯坦福大学、麻省理工学院、卡耐基梅隆大学、普林斯顿大学、伊利诺伊大学香槟分校等顶尖大学。随着时间的推移,有的教授在项目结束后退出,同时又会有新的教授加入。以GSRC 为例,该研究中心启动于2008 年,2013 年结束。5 年期间共有来自25 所大学的84 位教授、561 位学生参与。GSRC的主管是普林斯顿大学电子工程系的沙拉克·马利克(Sharad Malik) 教授。在他的精心组织下,GSRC 的教授与学生几乎每周都可以通过网络视频会议系统WebEx 参加学术报告,了解其他研究小组的最新研究进展。此外,GSRC 每年还有两次为期3 天的面对面交流会,会上各个大学的教授都会带领学生参加,同时还有很多企业代表参加。在过去5年,GSRC 一共发表了3318 篇学术论文,12 项专利获得了授权。参与资助的企业会员不仅可以共享这些研究成果,而且也吸引了很多学生加入企业。
半导体研究社团自成立以来不仅向学术界累计输送了来自产业界的超过20 亿美元的研究经费,而且还帮助产业界将需求及时有效地反馈到学术界,引导了学术界的研究方向,培养了大量半导体技术人才。20 世纪80 年代初全美高校不足100 人参与半导体研究的尴尬历史一去不复返。在过去30 多年间,半导体研究社团累计资助了上万名高校的学生参与半导体相关的项目,任何时候都有1200~1500 名学生参与到半导体研究社团项目中,而且绝大多数都是博士生。正是由于半导体研究社团在学术界与产业界之间扮演了重要的桥梁作用,推动了半导体产业的发展,2005 年美国联邦政府授予半导体研究社团美国科技界的最高荣誉——国家技术创新奖章(National Medal of Technology and Innovation)。 企业联合资助模式 企业联合资助模式是一种定向资助模式,一般由若干公司联合起来直接资助某个大学的实验室,资助的力度达数百万甚至上千万美元。例如,2007 年3月,英特尔与微软宣布联合出资2000 万美元,分别资助加州大学伯克利分校的“并行计算实验室PARLab”与伊利诺伊大学香槟分校的“通用并行计算研究中心UPCRC”开展多核并行计算方面的研究工作。2011 年2 月,加州大学伯克利分校获得了来自亚马逊、谷歌和SAP 的联合资助,成立了AMP(algorithm, machine, people) 实验室,开展面向数据中心与大数据挑战的研究。此后,AMP 实验室又吸引了包括苹果、微软、脸谱、雅虎、英特尔、三星和华为等十几家企业的资助。 企业联合资助模式更像是一种捐赠模式,企业会对被资助的实验室提出一些要求,比如研究人员投入力度、相应的匹配经费等,也可以分享研究成果。这种模式是建立在互惠互利的基础上的,从实验室角度来看,既获得了经费又保留了学术自由度以及成果的支配权,这样可以吸引更多更好的学生加入,开展一些富有挑战的研究项目;从企业角度来看,通过这种方式与顶尖实验室建立密切的联系,可以参与到实验室的研究过程和交流活动中,提供前沿需求信息,及时反馈实验室研究工作中的不足,分享实验室研究成果,同时还有利于从这些顶尖实验室招募到优秀的毕业生。比如,资助AMP 实验室的企业会被邀请参加实验室内部每年两次为期3天的交流会,而实验室的毕业生也大都去了这些企业工作。 开源社区模式 近年来,开源已成为越来越流行的开发模式,世界各地的开发者根据自己的兴趣逐渐形成各个开源社区,比如Linux 开源社区、Hadoop 开源社区等,促进了技术生态系统的快速发展。如今,越来越多的企业加入到开源社区,如雅虎发起和推动了Hadoop社区,IBM 投入了很多资源到Linux 社区。而脸谱更是打出“开源一切”(open source everything)的口号,公开了一系列内部项目,包括关于数据中心设计的开放计算项目(open compute project)、NoSQL 数据库Cassandra、数据仓库平台Apache Hive等。 企业开源对学术界有很大的吸引力,能吸引大量的科研人员参与到开源项目的完善和优化中, 实现双赢。一方面大学的教授和学生可以从开源项目中找到有意义的研究问题,做出好研究、发表好文章或找到好工作;另一方面,企业也能从大学研究成果中直接受益,将学术界提出的优化方案应用到产品系统中,同时还能吸引参与开源项目研究的博士生毕业后加入到企业。华人学者、俄亥俄州立大学的张晓东教授就是参与开源项目研究的典范。他的团队通过对Apache Hive 存储系统的研究,发现了其低效存储的根源,提出了RCFile优化技术,该技术很快被脸谱采用,并在此基础上作了改进应用到产品中。张晓东的团队也因此在VLDB、SIGMOD 等顶级会议上发表了一系列文章,参与研究的学生在脸谱工作期间也得到了可观的收入。对于脸谱而言,他们的系统性能得到了大幅提高,产生了巨大的经济效益,而且还发表了顶级论文,吸引了更多博士毕业生加入企业,提升了企业的技术竞争力。这些正是得益于脸谱的开源计划。 其他传统模式 产业界与学术界之间的互动,除了上述新兴模式,还有不少传统模式: 1. 很多企业设立一些面向大学教授的研究资助项目(faculty research program),大学教授可以向企业提交项目申请,通过评审后能获得资助。这些项目经费额度并不多,往往只有几万美元,但企业对项目管理很宽松,教授在研究内容与经费支配上有很大的自由度。 2. 很多企业将一些最先进的产品免费捐赠给大学实验室,希望实验室能基于这些产品开展研究。例如,英特尔推出众核芯片Xeon Phi 后,向普林斯顿大学李凯教授的脑科学课题组免费提供了60 颗Xeon Phi 芯片以及一批配套的Xeon 芯片,用于搭建一个基于Xeon Phi 的机群系统;英特尔为加州大学伯克利分校的并行计算实验室提供一套搭载了支持硬件缓存划分的Sandy Bridge处理器原型系统,用于评估缓存划分效果。这些实验芯片对研究非常有价值,但在市场上却买不到,所以基于该实验芯片的相关研究成果很快发表在2013 年度的国际体系结构顶级会议ISCA 上。 3. 企业面向大学招收实习生。学生在企业实习的过程中可以直接接触企业的前沿需求,从而反馈到学术界。当他们回到大学后,很多人还是会继续开展与实习相关的研究工作。 三、中国的机遇 笔者相信本文开篇的“博士后与民工”的故事是杜撰的,中国目前正面临着产业升级,大多数企业是相信知识的力量、尊重知识的。事实上,中国的企业对前沿技术的需求越来越强。以华为公司为例,2013 年营业额高达2400 亿元,利润为210 亿元,已经成为全球最大的通信公司。华为的4G 产品已经在全球占有最大市场份额,而对于5G 通信技术,更是处于全球领跑者的地位,这使得华为有着更强烈的掌握前沿核心技术的需求。国内互联网企业拥有与国际一流企业相当的30% 左右的高利润率,具备探索前沿新技术的经济基础。 事实上,国内的学术界与产业界之间的合作已经越来越密切了,合作的模式也愈加丰富,很多企业也在尝试与学术界的各种合作模式。例如,华为公司与中国科学院计算技术研究所达成了合作协议,华为投入研究经费资助计算所研制面向云计算的高通量数据中心技术;腾讯公司不仅通过中国计算机学会设立“CCF- 腾讯犀牛鸟科研基金项目”,还出资3000 万元与清华大学成立联合实验室;而淘宝公司则一直在积极地推动开源社区的发展。 与国外相比,国内学术界的观念转变似乎稍慢一些,科研人员很少主动与产业界交流。这种局面的打破需要科研人员与企业多交流,多向企业请教,多与企业合作。只有更深入地了解企业,科研人员才能获取真正的产业前沿需求,才能做出真正有价值、有影响力的研究工作,才能赢得企业的信任与尊重,通过更广泛深入的合作研究,共同推进信息技术发展。 参考资料: 【1】《南大教授龚放谈斯坦福大学崛起之路:从象牙塔走向社会轴心》,南京大学新闻网,2012年2月27日。 【3】Communications of the ACM, Vol. 57 No. 3, March 2014。 【4】 Communications of the ACM, Vol. 52 No. 3, March 2009。 【5】 Princeton Computer Science 448, Innovating Across Technology, Business, & Markets, J.P. Singh。 【6】包云岗,谁推动了信息产业发展?中国计算机学会通讯,2012年9月。 【7】SRC: Celebrating 30 Years, 2012。 | |
|
(3个打分, 平均:5.00 / 5) |


DeepMind公司研究–利用深度强化学习教计算机玩小游戏
作者 AbelJiang | 2014-05-19 19:45 | 类型 Deep Learning, 机器学习 | Comments Off
|
去年,Google买过一个机器学习的初创公司,叫DNNresearch。这个小公司是有多伦多大学的Geoffrey Hinton教授和他的两位研究生共同建立的。Geoffrey Hinton教授算是神经网络领域男神级的人物了,贴一下他在Coursera开过的神经网络课程。今年,Google又花了将近五亿美刀买下同样研究机器学习的初创公司DeepMind。Facebook,以及雅虎等公司也曾以不菲的价格买过研究机器学习的初创公司,抢人的节奏啊。下面贴一下DeepMind在被收购之前比较有名的成果,教计算机玩小游戏。详情戳图。 | |
|
(没有打分) |

计算所 。《体系结构研究者的人工智能之梦》
作者 陈怀临 | 2014-05-16 18:48 | 类型 行业动感 | 2条用户评论 »

谷歌新专利–利用机器学习优化手机消息通知顺序
作者 AbelJiang | 2014-05-16 18:44 | 类型 机器学习, 行业动感 | Comments Off
|
手机经常会从不同的应用中接收到各种提示信息,比如短信,邮件,未接电话,闹铃,地理位置提醒,以及第三方应用的各种通知。多数手机都会在有新通知的时候提醒用户,但是无时无刻的夹杂广告的提醒是很烦人的,于是一些新近的系统允许用户设定通知优先级,以期改变通知的呈现顺序。但是这些系统多数缺乏智能排序的能力,而谷歌的这项新专利提供的解决方案想要解决的就是这个问题–提供给用户一个智能的系统,无需手动设置就能通过学习算法发现那些对用户重要的通知,并自动设置优先级。详情戳图。
| |
|
(没有打分) |

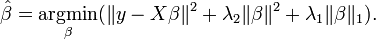{kind=link}
从蛋白质到计算机
作者 冬瓜头 | 2014-05-13 14:49 | 类型 行业动感 | 16条用户评论 »
|
说道硬件,不得不又走入了幻想里去。学生时代学习过一段分子生物学方面的知识,当时还想考中科院上海生化所研究生,但是苦于某些扯淡科目,最终还是没报名,后来稀里糊涂从事了IT行业,至今半瓶水,虽身在PMC这么高端的公司,但是心里一直很惭愧。在学习分子生物的时候,对计算机其实一点都不了解的。当从事了几年IT之后,越发觉得生物就是计算机,上帝的代码令人叹为观止,迄今为止人类也仅仅探知了少许皮毛。我一直在思考一个问题,就是什么才是最高效最智能的计算机,那一定是仿生计算机,仿生怎么仿?那一定是从分子层面去仿。现在已经出现了利用蛋白质组成逻辑门的简单器件,但是我个人不认为用生物器件搭建成逻辑门是多么高效的办法。我们必须搞清楚生物体在分子层面是怎么完成生命逻辑的,说白了,目前发现的地球生物体,是使用大量的数不尽种类的蛋白质之间的相互作用,通过化学力、物理力相互连接、释放,各自产生形变,又导致其他一系列瀑布连锁反应。这些过程,就像函数调用一样。整个生化过程,有输入信号、输出信号。比如从某病毒被T细胞表面蛋白质感受并接触,一直到最后B细胞大量生成对应抗体和其他免疫分子释放到血液,这期间就是在完成免疫的生命逻辑。这里有问题就是,对于计算机,多数逻辑都是需要CPU运行代码来完成,那么这些生命逻辑的代码在哪里?有人说在DNA里的碱基对,其实DNA更加类似计算机里的存储设备,其碱基对其实是对文件存储的编码格式。真正的逻辑体现在哪?其实就是体现在蛋白质的三维构象当中,一个蛋白质相当于一个线程,完成一定的逻辑,但是蛋白质完成逻辑并不需要像计算机CPU一样去读入代码执行,而是有输入,就有输出,这更像数字电路里的组合逻辑的行为,所以把每个蛋白质比喻成一个ASIC电路更加形象,蛋白质无处不在,有的嵌入在细胞表面,有的游离于细胞内,有的在血液内,他们靠高速运动相互碰撞完成API(更确切的应该是ABI)调用,也有主动引导方式,比如通过某些物质的浓度梯度,将对应的蛋白质引入到对应的地方,完成逻辑。也就是说,生物体是由大量ASIC电路组成的、组合逻辑+时序逻辑共同作用的,一台计算机。试想一下,这和我们常用的计算机完全不一样,后者是软件定义,而生物体,则是硬件定义,而生物体软件定义的部分,在于大脑的学习单元,也就是智能、感情等属于软件定义,其他生命过程,都是硬件定义的。最高效的计算机,就是要把线程做成ASIC,然后用一种特殊的总线连接所有ASIC,但是永远赶不上生物体的是,这些相互连接的ASIC是不能随便运动的,这就要求必须使用超高速的互联通道。将来的计算机是否会是这种仿生的形态?有生之年可能得不到答案了。 | |
 (5个打分, 平均:4.60 / 5) (5个打分, 平均:4.60 / 5) |