




Sandy Bridge核外架构的进化——英特尔Sandy Bridge 处理器分析测试之四
作者 Lucifer | 2011-04-01 07:50 | 类型 专题分析, 芯片技术 | 4条用户评论 »
系列目录 英特尔Sandy Bridge处理器分析测试
原文发布于《计算机世界》2011年第8期,有修订 Sandy Bridge核外架构的进化 计算机世界实验室 盘骏 和微架构方面一样,Sandy Bridge的架构方面也具有了很大的变化。这个变化来自两个方面的考虑:性能和可扩展性,其中后者包括了要面对越来越多的处理器核心的问题,还有要面对来自GPU挑战的问题。针对GPU的压力,英特尔一方面采取了更宽的256位AVX向量运算提升CPU处理能力,一方面采取了在CPU内直接融合GPU的方法。关于GPU的部分可以写出多个长篇,因此这里主要谈及Sandy Bridge其它方面的架构变化。
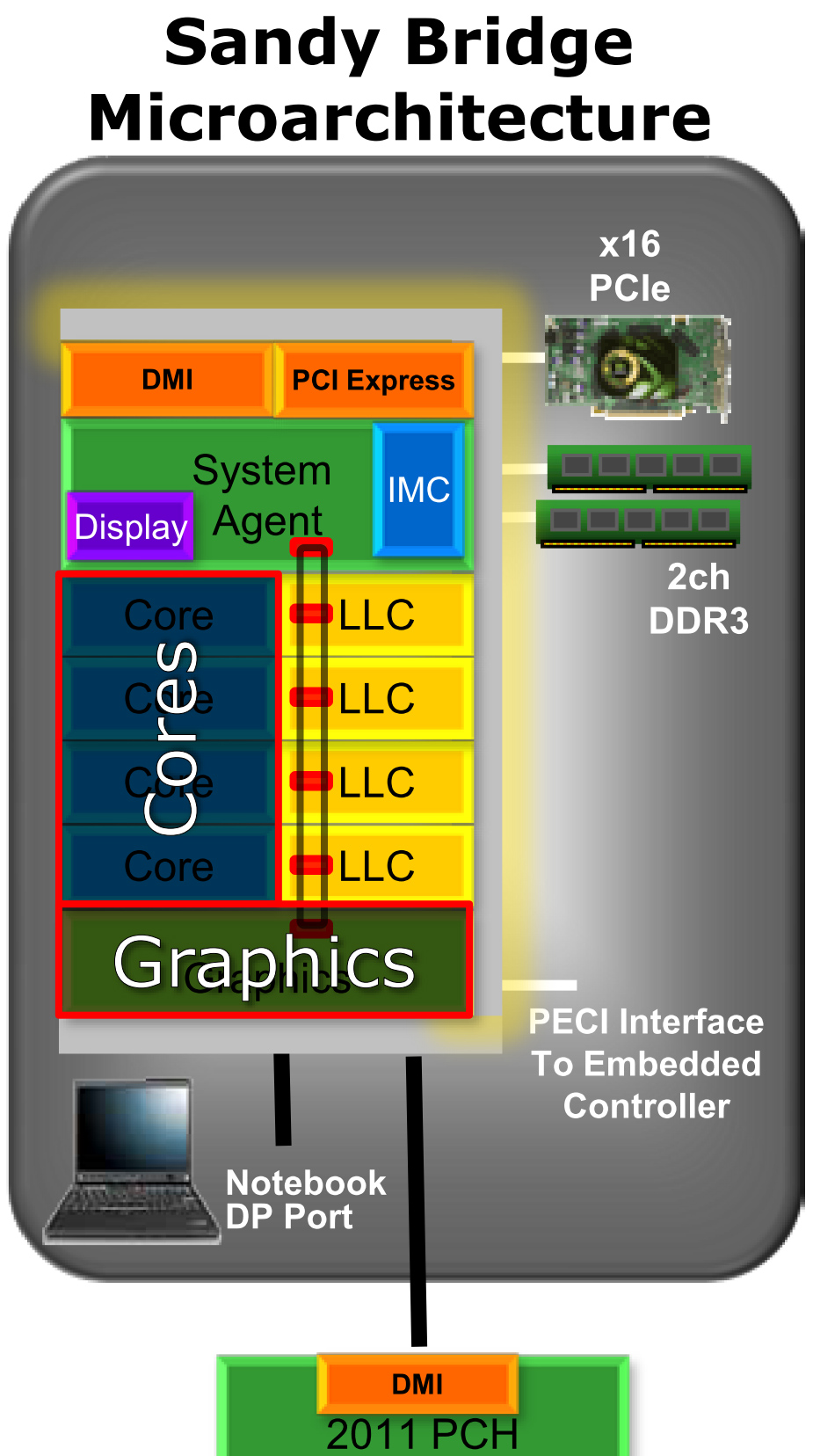
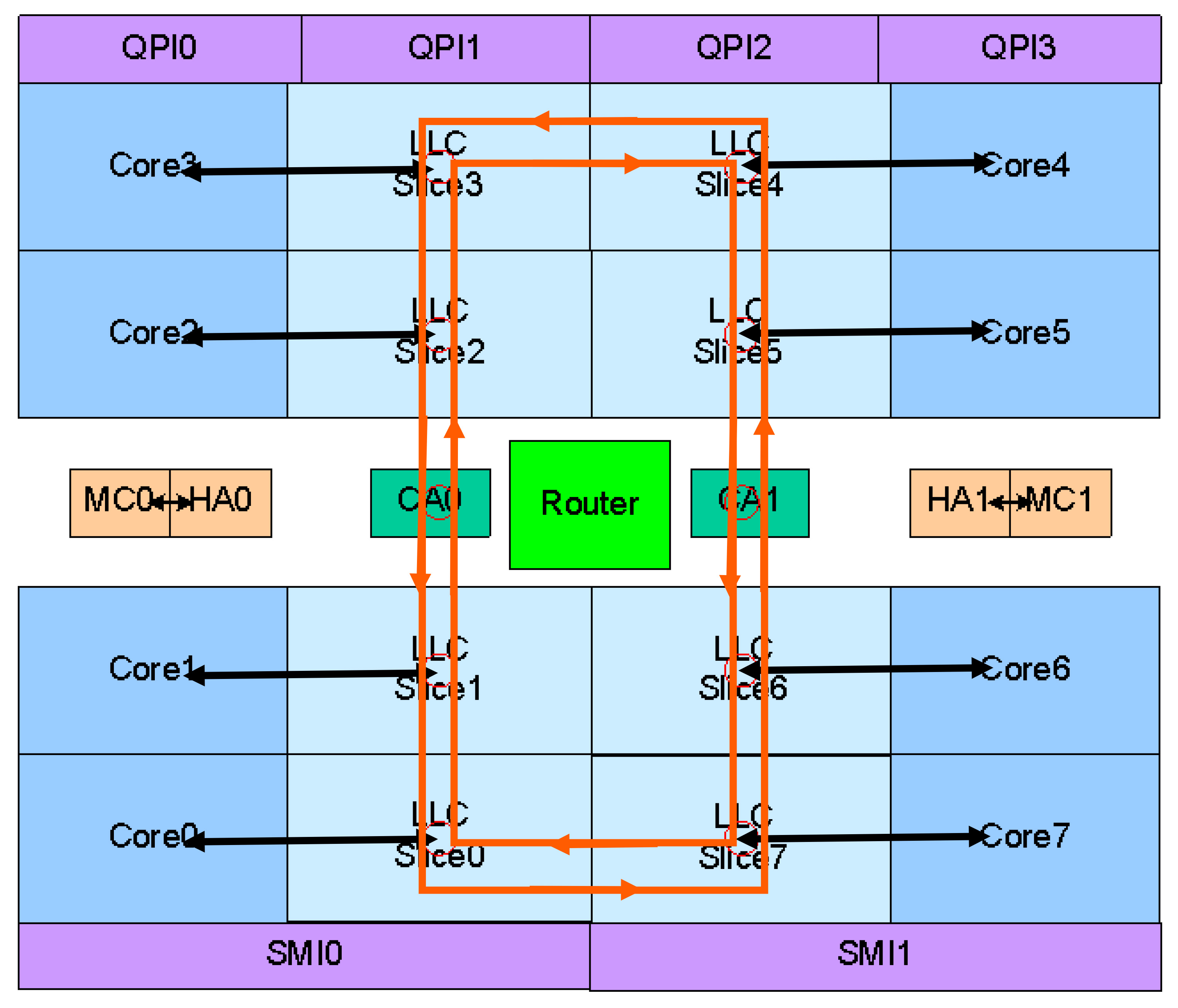
这个变化就是Sandy Bridge采用了新的Ring Bus环形总线来连接各个CPU核心、LLC缓存(就是L3缓存)、融合进去的GPU以及System Agent(就是系统北桥)部分。自从Nehalem开始使用融合核心策略后,不同产品线的处理器都基于同一种核心,只是具有不同的核外架构(称为Uncore架构),这个核外架构在不同的产品线上必须进行不同的设计,对应地芯片组也要进行变化。在核心数量比较少的时候,这很容易办到,然而在高端服务器上,核心数量很高,这种方式就难以具有匹配的性能,并且开始变得难以实现。实际上,高端8核心的Nehalem-EX处理器就采取了和桌面/移动端完全不同的Uncore架构:使用了一个环形总线,而在后来加入GPU的Westmere,新加入的GPU迫使内存控制器和CPU核心分立,并和GPU一起集成到一个相对落后的45nm制程的芯片上,影响到了性能和功耗。现在,这个环形总线技术被应用到了Sandy Bridge全线产品线上来。 革命性的环形总线
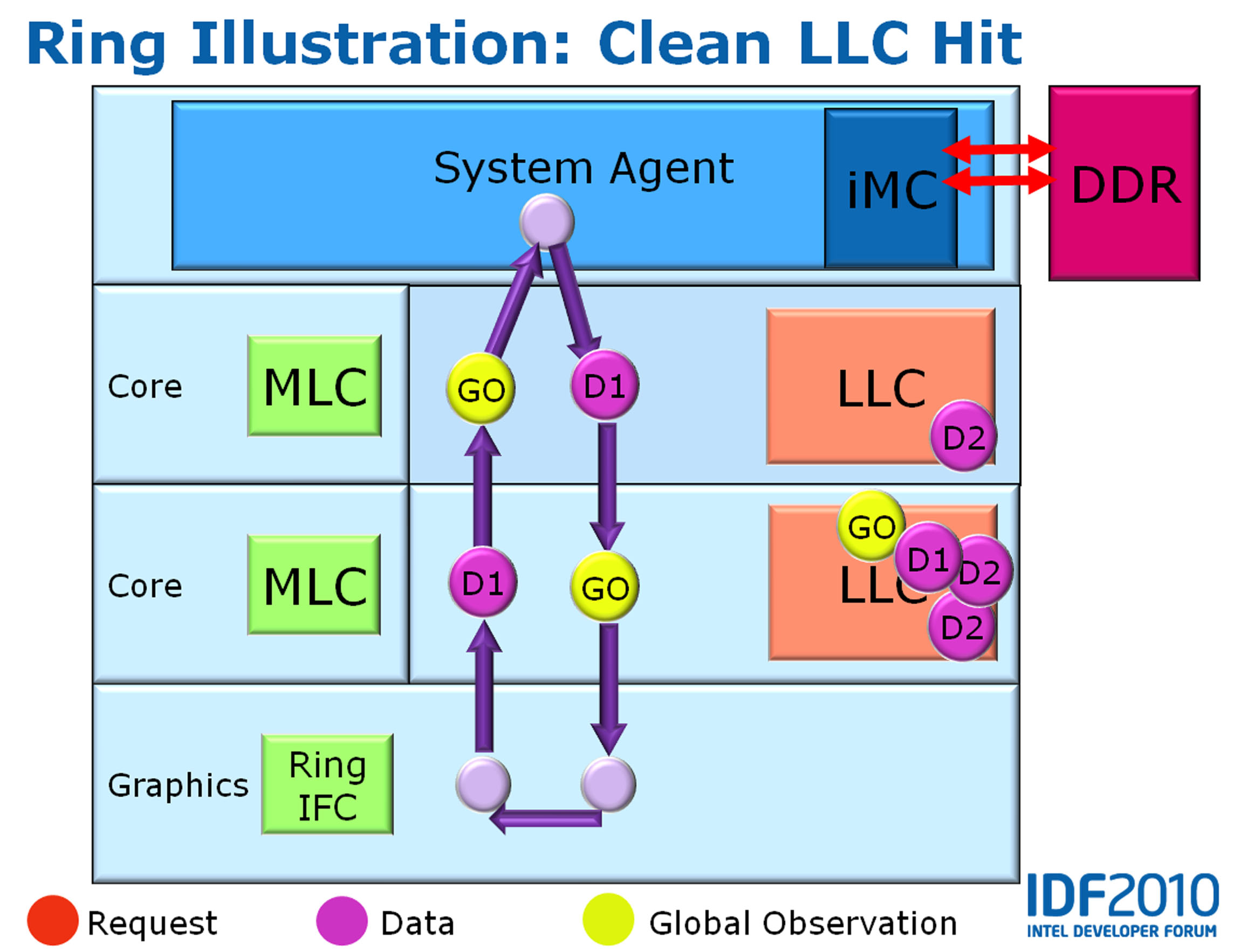
这个环形总线其实由四条独立的环组成,分别是数据环(Data Ring)、请求环(Request Ring)、响应环(Acknowledge Ring)、侦听环(Snoop Ring)。其中用来传输数据的数据环的宽度是32B(256bit),刚好是L3缓存线的一半。和Nehalem-EX的一样,这个数据环应该还是双向的,这样通过自动选择最近的线路,对目标的存取延迟可以降低到平均只有一个环的一半。 Sandy Bridge环形总线上分布着多个Ring Stop,叫做“站台”,这个“站台”和Nehalem-EX的并不太一样,其实仔细看的话,Sandy Bridge的环形总线和Nehalem-EX的也不太一样。Nehalem-EX的环显得更大一些,每个CPU/LLC块上只有一个连接点,而Sandy Bridge的显得很纤细,每个CPU/LLC块上具有两个连接点,这种差异的具体细节尚不清楚。 环形总线是全流水线化的,并且运行在核心频率/电压上,因此其带宽会根据不同的型号/工作状态而变化,并且可以根据加入站台的数量而扩展。当然,站台数量的增加会增长总线的宽度,并会对应地增加延迟,每个站台之间的传输时间是一个时钟周期。理论上,3.4GHz的Sandy Bridge每个站台可以具有108.8GB/s的带宽,4个核心就具有435.2GB/s的理论带宽,由于数据经过不同的站台的时候,该站台需要等待而无法传输数据,因此实际的带宽无法达到理论值。 LLC:L3缓存的变化 环最主要的作用是将CPU核心与L3缓存联结起来,L3缓存是处理器的最低一级缓存,因此也叫Last Layer Cache(LLC)。每一个CPU/LLC块上具有一个称为Interface Block(接口块)的部件来负责和Ring通信,每个接口块上包含了一个独立的缓存控制器,负责回应缓存请求、维持一致性和排序,并在L3缓存未命中、侦听以及遇到不可缓存请求时和System Agent通信。实际上,Sandy Bridge实现了一个分区化的分布式仲裁缓存架构。
除去使用环形总线的EX系列,Nehalem/Westmere的L3是一个单块的大缓存,具有统一的32B(256bit)带宽,到了环形总线架构之后,就不再是这样了。和Nehalem-EX/Westmere-EX一样,Sandy Bridge将LLC分成多个具有32B宽度接口的Slice,物理地址还使用Hash机制分布到所有的缓存块上,因此实际上所有的缓存块都可以同时运作,增加了带宽、简化了一致性问题并避免了热区效应,其性能和没采取环形总线的时候具有着巨大的提升。 每一个LLC缓存块都具有和原来Nehalem/Westmere的大缓存块类似的结构,在桌面处理器上,每个核心将会对应一个LLC缓存块,而每个2MB容量的LLC块属于16路组相连。在服务器产品线上,每个核心仍然对应一个缓存块,然而由于去掉了GPU模块,因此LLC缓存块获得了更大的面积,其容量提升到了2.5MB,对应地,组相连也提升到20路,这些进一步提升了其缓存命中率表现。Sandy Bridge的L3缓存仍然使用了包含式的设计,在上级缓存上具有的内容在L3缓存上具有同样的副本,和Nehalem一样,Sandy Bridge也使用核心有效位来起到侦听过滤器的作用,只是增加了GPU对应的位,因为Sandy Bridge的缓存是CPU、GPU共享。 除了缓存的分布式仲裁、运作带来的高带宽之外,Sandy Bridge的缓存延迟实际上也得到了降低,大约从原有的35-40个时钟周期降低到26-31个时钟周期。延迟的降低一部分是因为小的缓存块本身就具有较低的延迟,存取对应的标记和数据都比原有的单个大缓存块要快。延迟降低的另一个原因是现在LLC缓存运行的频率和核心频率保持了一致。在Nehalem/Westmere上,LLC缓存运行于Uncore频率,通常是比核心频率要低的。一致的运行频率还避免了不同频率区间传递信号的惩罚,最终让Sandy Bridge延迟表现更好。 System Agent:更快速的北桥 System Agent系统代理扮演原有的北桥角色,连接内存控制器、PCI Express总线以及PCH(类似南桥芯片),此外还带有PCU功率控制单元管理其他部件的频率/电压,实现Turbo Boost 2.0功能,System Agent还负责引出GPU的显示输出。在带有GPU的Sandy Bridge处理器上,CPU/LLC、GPU运行于动态的电压和频率,而System Agent则运行于固定的电压和频率。和传统的分立北桥和上一代Lynnfield的多芯片同封装相比,完全集成在一起的System Agent尽可能地消除了各个部件间的联线,可以提供更好的延迟表现。 通过使用了新的环形总线,Sandy Bridge以更有效率的方式对CPU、LLC、GPU和System Agent进行了组织,提供了更高的内部带宽和更低的L3存取延迟,并且可以很好地融合新加入的GPU模块,并适应高端服务器市场上的大数量处理器核心场景。在下回,笔者将介绍Sandy Bridge全新的GPU部件,敬请期待。 | |
   (6个打分, 平均:3.50 / 5) (6个打分, 平均:3.50 / 5) |
雁过留声
“Sandy Bridge核外架构的进化——英特尔Sandy Bridge 处理器分析测试之四”有4个回复
看来XLR/XLP的环形总线和多块Bank是技术的方向啊。
核越来越多,各种总线都会涌现
ring是通往mesh道路上的一个过渡
半导体这个世界没有最好,只有更好。bus, crossbar, ring, mesh 各有优缺点,关键看谁跑的快了,能够更有效率的发挥硅片面积和集成更多CPU。