




《 孙钟秀 。操作系统教程》注释(稿)--第六章:文件管理
作者 陈怀临 | 2014-12-27 12:16 | 类型 操作系统, 科技普及 | Comments Off

存有超过2PB肿瘤基因组数据的GDC将于2015年开始运行
作者 弯曲评论 | 2014-12-27 12:06 | 类型 生物医学 | Comments Off
|
12月2日,芝加哥大学跟美国国家癌症研究中心联合宣布启动用于存储肿瘤基因组数据的Genomics Data Commons项目(简称GDC),项目负责人是芝加哥大学的Robert Grossman教授。
众所周知,NCI资助了大量的肿瘤研究项目,比如TCGA。这些项目累计完成了超过一万个病人的基因组测序工作,但这些数据都散落在各地。NCI觉得应该把这些数据攒在一起,发挥更大的作用。根据GDC项目的Q&A,这些数据总共有大约2.2PB。GDC未来每年会增加1PB的存储以应对NCI的新项目。
新闻稿里面专门说明:“GDC所使用的存储和分析技术跟Google和Facebook等公司使用的技术很相似”。相似到什么程度?NoSQL?HDFS?Spark?还是Spanner?不得而知。
Grossman在生物云计算耕耘很久了。他领导了 Open Science Data Cloud项目(https://www.opensciencedatacloud.org/)。通过芝加哥大学内部的合作开发了The Bionimbus Protected Data Cloud,这是唯一一个由NIH资助的用于存储TCGA项目数据的云计算平台。
感觉NCI已经是科研主管机构中在云计算方面最激进的组织了。刚刚给ISB、Broad和SBG发了1900多万美元用于建设癌症云计算平台,现在又启动了用于存储数据的GDC。
NCI似乎已经把数据存储和数据分析拆成了两个部分。两个部分之间的接口会如何设计?GA4GH的Genomics API会得到NCI这些项目的支持吗?ISB、Broad和SBG的癌症云计算平台如何跟GDC进行对接与合作?美国人依然在领跑全世界,2015年肯定会有更加精彩的东西。
我们的差距依然明显,无论是数据量、成果还是投入。863、973等诸多癌症研究项目产生的数据还捏在极少人的手中,落满灰尘。
比历史,我们已经没办法了。1937年8月5日,富兰克林罗斯福总统签署美国癌症法案,成立了NCI。在此前一周,日本借口卢沟桥事件全面占领北平。未来呢?我们还有机会。 | |
 (1个打分, 平均:5.00 / 5) (1个打分, 平均:5.00 / 5) |
Hadoop之父聊大数据和他LOGO里的那只象!
作者 弯曲评论 | 2014-12-24 11:35 | 类型 大数据 | Comments Off
|
(来自 英特尔商用频道 微信公众平台)
英特尔中国研究院院长吴甘沙先生首先进行了分享。院长分别从数据的爆炸式发展、英特尔大数据的分析框架、研发布局以及与Cloudera在中国的合作进行几个方面进行了讲演。
大家经常听说在我们IT这个产业有这样一种指数的规律,而这样一种规律如果应用到传统的产业来说是不得了的事情。
下面这条曲线前面经过长时间的缓慢增长,一旦过了临界点以后,就会产生爆发式的增长,如果在这么一个时间点T,它是X的话,下一个时间点就是X的平方,如果X是一个大数的话,这样一个指数规律使得在任何一个周期里面,它的新的值将远远把前一个周期的值抛在后面。
比尔盖茨曾经有一个比喻:如果汽车产业像IT产业这么发展的话,到现在我们一辆汽车是25美金,一加仑汽油能够跑一千英里,这就是指数带来的威力。
大数据要说人话,它要提取人能够理解的价值,怎么能够让数据的工具跟我们的人,跟数据科学家,跟领域专家,跟我们的终端用户天人合一,降低数据分析的门槛,这又是一个挑战。
基于这些挑战,英特尔推出了大数据的分析框架,在最底层是基础设施,计算存储互联成为软件可定义,我们把它做成开放式、模块化的这些标准的模块,使得我们行业能够降低门槛,更多的创新者能够进来。
上面一层是数据平台,我们跟Cloudera一起推动基于Apache Hadoop开放、可信的数据处理平台,推动整个生态基础创新,上面是分析应用,我们希望能够把高级的分析功能平民化,使得它能够迈入主流的应用,使得它能够实现规模的经济。最上面是解决方案,我们跟生态系统伙伴一起构建示范性的解决方案,把它变成可扩展的参考架构,使得在示范的领域成功能够被复制到每一个行业、每一个企业上面去。 | |
 (没有打分) (没有打分) |
百度语音识别新突破–Deep Speech系统
作者 AbelJiang | 2014-12-24 11:33 | 类型 Deep Learning, 机器学习 | Comments Off
|
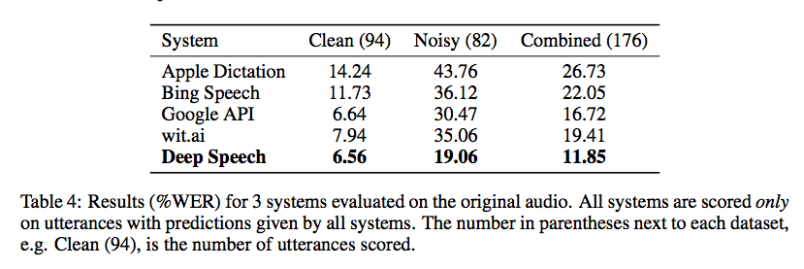
原文转载自:https://gigaom.com 相关论文:DeepSpeech: Scaling up end-to-end speech recognition Chinese search engine giant Baidu says it has developed a speech recognition system, called Deep Speech, the likes of which has never been seen, especially in noisy environments. In restaurant settings and other loud places where other commercial speech recognition systems fail, the deep learning model proved accurate nearly 81 percent of the time. That might not sound too great, but consider the alternative: commercial speech-recognition APIs against which Deep Speech was tested, including those for Microsoft Bing, Google and Wit.AI, topped out at nearly 65 percent accuracy in noisy environments. Those results probably underestimate the difference in accuracy, said Baidu Chief Scientist Andrew Ng, who worked on Deep Speech along with colleagues at the company’s artificial intelligence lab in Palo Alto, California, because his team could only compare accuracy where the other systems all returned results rather than empty strings.
Ng said that while the research is still just research for now, Baidu is definitely considering integrating it into its speech-recognition software for smartphones and connected devices such as Baidu Eye. The company is also working on an Amazon Echo-like home appliance called CoolBox, and even a smart bike. “Some of the applications we already know about would be much more awesome if speech worked in noisy environments,” Ng said. Deep Speech also outperformed, by about 9 percent, top academic speech-recognition models on a popular dataset called Hub5’00. The system is based on a type of recurrent neural network, which are often used for speech recognition and text analysis. Ng credits much of the success to Baidu’s massive GPU-based deep learning infrastructure, as well as to the novel way them team built up a training set of 100,000 hours of speech data on which to train the system on noisy situations. Baidu gathered about 7,000 hours of data on people speaking conversationally, and then synthesized a total of roughly 100,000 hours by fusing those files with files containing background noise. That was noise from a restaurant, a television, a cafeteria, and the inside of a car and a train. By contrast, the Hub5’00 dataset includes a total of 2,300 hours. “This is a vast amount of data,” said Ng. ” … Most systems wouldn’t know what to do with that much speech data.”
Another big improvement, he said, came from using an end-to-end deep learning model on that huge dataset rather than using a standard, and computationally expensive, type of acoustic model. Traditional approaches will break recognition down into multiple steps, including one called speaker adaption, Ng explained, but “we just feed our algorithm a lot of data” and rely on it to learn everything it needs to. Accuracy aside, the Baidu approach also resulted in a dramatically reduced code base, he added. You can hear Ng talk more about Baidu’s work in deep learning in this Gigaom Future of AI talk embedded below. That event also included a talk from Google speech recognition engineer Johan Schalkwyk. Deep learning will also play a prominent role at our upcoming Structure Data conference, where speakers from Facebook, Yahoo and elsewhere will discuss how they do it and how it impacts their businesses. | |
|
(2个打分, 平均:1.00 / 5) |

《 孙钟秀 。操作系统教程》注释(稿)--第五章:设备管理
作者 陈怀临 | 2014-12-17 12:28 | 类型 操作系统, 科技普及 | Comments Off

【邢波】机器学习需多元探索,中国尚缺原创引领精神
作者 陈怀临 | 2014-12-17 11:49 | 类型 Deep Learning, 机器学习, 科技普及 | 1条用户评论 »
|
【邢波Eric P. Xing】清华大学物理学、生物学本科;美国新泽西州立大学分子生物学与生物化学博士;美国加州大学伯克利分校(UC,Berkeley)计算机科学博士;现任美国卡耐基梅隆大学(CMU)计算机系教授,2014年国际机器学习大会(ICML)主席。美国国防部高级研究计划局(DARPA)信息科学与技术顾问组成员。(他在中国大数据技术大会上的报告请参考阅读原文链接) Professor of Carnegie Mellon University Program Chair of ICML2014Dr. Eric Xing is a Professor of Machine Learning in the Schoolof Computer Science at Carnegie Mellon University. His principal researchinterests lie in the development of machine learning and statisticalmethodology; especially for solving problems involving automated learning,reasoning, and decision-making in high-dimensional, multimodal, and dynamicpossible worlds in social and biological systems. Professor Xing received aPh.D. in Molecular Biology from Rutgers University, and another Ph.D. inComputer Science from UC Berkeley.
【杨静lillian】这次您受邀来中国参加大数据技术大会,在您看来,中国大数据相关技术和生态发展到了什么水平?与美国的差距主要体现在哪些方面? 【邢波Eric P. Xing】中国的大数据技术与题目跟进国外趋势还做得不错。但在原创性部分有欠缺。也许由于工程性,技术性上的原创工作通常不吸引眼球且风险极大这样的特点,所以没人愿意啃硬骨头。整体不算太差,但缺少领军人物,和领先的理念。还有在导向上,倾向于显著的效益和快的结果,但对于学术本身的追求不是很强烈。如果效果不是立竿见影,愿意碰的人就少。大部分人都这样,就是趋向于平庸。整个生态系统上看,中国大数据发展水平与欧洲、日本比并不差,公众的认知也热烈。整个环境还蛮好。与中国学生有点像,群体不见得差,但缺少特别杰出的领袖,和有胆识的开拓者。
人工智能的目标没有上限,不应以人脑为模板
【杨静lillian】您说过深度学习只是实现人工智能目标的一种手段,那么在您看来,人工智能的目标到底是什么?抛开《奇点临近》的科学性,您认为机器智能总体超越人类这个目标在2050年前后有可能实现么?或者说在2050年前后,世界的控制权会不会由人工智能主导? 【邢波 Eric P. Xing】人工智能的目标其实是没有上限的。人工智能的目标并不是达到动物或人类本身的智力水平,而是在可严格测量评估的范围内能否达到我们对于具体功能上的期待。例如用多少机器、多长时间能达成多少具体任务?(这里通常不包含抽象,或非客观任务,比如情绪,感情等。)人的智力不好评价,尤其标准、功能、结果及其多元,很多不是人工智能追求的目标。科幻家的浪漫幻想和科学家的严格工作是有区分的。大部分计算机科学家完成的工作可能不那么让人惊叹,但很多任务已经改变世界。例如,飞机自动驾驶装置可能没有人的智能,但它完成飞行的任务,却比人类驾驶员好。 再比如弹钢琴,机器也可以弹钢琴,精确程度肯定超过人。但是否有必要发明机器人代替人弹钢琴来上台表演,或机器人指挥家甚至机器人乐队?从这个角度看,我个人没有动力或必要去发明机器人来弹钢琴,至少我不认为应该去比较机器和人类钢琴家。钢琴大师如霍洛维茨,鲁宾斯坦是不能被机器替代的、比较的,虽然他们也弹错音。一个武术大师,如果现在用枪来和他比武力,把他打死,有意义吗?那么标准是什么?我认为我们应该去想和做一些更有意义和价值的事情。 关于2050年的未来预测,如果非要比较的话,我认为人工智能不会达到超越人类的水平,科学狂人或科幻家也许喜欢这样预测未来,博得眼球,但科学家需要脚踏实地做有意义的工作。所谓奇点是根本不可能的。未来学家这样去臆测也许是他们的工作;政治家、企业家、实践学家向这个方向去推动则是缺乏理性、责任和常识;而科学家和技术人员去应和,鼓吹这些则是动机可疑了? 人工智能脱离人类掌控?这种可能性不能排除。但要是咬文嚼字的话,如果是计算机的超级进步涌现出智能,以至脱离人类掌控而自行其道,那还何谓“人工”?这就变成“自然智能”。我认为“世界的控制权会不会由人工智能主导”这类题目定义就不严肃,无法也无益做科学讨论,也不能被科学预见。
【Ning】能否通俗科普一下机器学习的几个大的技术方向,和它们在实践中可能的应用。 【邢波 Eric P. Xing】很难科普的讲,不使用专业术语。机器学习不过是应用数学方法体系和计算实践的一个结合,包罗万象。比如图模型(深度学习就是其中一种),核(kernel)方法,谱(spectral)方法,贝叶斯方法,非参数方法,优化、稀疏、结构等等。我在CMU的机器学习课和图模型课对此有系统全面的讲解。 机器学习在语音、图形,机器翻译、金融,商业,机器人,自动控制方面有广泛的应用。很多自然科学领域,例如进化分析,用DNA数据找生物的祖先(属于统计遗传的问题),需要建模,做一个算法去推导,数学形式和求解过程与机器学习的方法论没有区别。一个成熟的,优秀的机器学习学者是应被问题、兴趣和结果的价值去激励、推动,而不是画地为牢,被名词所约束。我本人在CMU的团队,就既可以做机器学习核心理论、算法,也做计算机视觉、自然语言处理,社会网络、计算生物学,遗传学等等应用,还做操作系统设计,因为底层的基本法则都是相通的。
【李志飞】大数据,深度学习,高性能计算带来的机器学习红利是不是差不多到头了?学术界有什么新的突破性或潜在突破性的新算法或原理可以把机器学习的实际应用性能再次大幅提升? 【邢波 Eric P. Xing】大数据、深度学习、高性能计算只是接触了机器学习的表层,远远不到收获红利的时候,还要接着往下做。算法的更新和变化还没有深挖,很多潜力,空间还很大。现在还根本没做出像样的东西。另外我要强调,机器学习的所谓红利,远远不仅靠“大数据、深度学习、高性能计算”带来。举个例子,请对比谷歌和百度的搜索质量(即使都用中文),我想即使百度自己的搜索团队也清楚要靠什么来追赶谷歌。
【Ning】世界各国在机器学习方面的研究实力如何?从科普的角度来看,人的智能和人工智能是在两个平行的世界发展么? 【邢波 Eric P. Xing】不太愿意评价同行的水平。人的智能和人工智能可以平行,也可以交互。
【杨静lillian】您既是计算机专家,还是生物学博士,在您看来,如果以未来世界整体的智能水平作为标准,是基因工程突破的可能性大,还是人工智能领域大,为什么? 【邢波 Eric P. Xing】基因工程其实突破很多。在美国和全球转基因的食品也有很多。胰岛素等药物也是通过转基因菌株来生产,而不是化学合成。诊断胎儿遗传缺陷的主要手段也基于基因工程技术。但是舆论风向在变,也不理性。例如我小时候读的《小灵通看未来》里,“大瓜子”等神奇食品现在已经通过基因技术实现。从技术上看,我们已经实现了这个需要,但公众是否接受,是个问题。科学家要对自己的责任有所界定。例如造出原子弹,科学家负责设计制造,但怎么用是社会的事。 人工智能领域也已经有很多应用型的成果,但也还有很大空间。人工智能就是要去达到功能性的目标,有很多事情可以用它去达成,但这里不见得包括感情思考。人的乐趣就是感情和思考,如果让机器代替人思考,我认为没有这个需要。 靠基因工程提升人的智能基本不可能,人的成就也未必与基因完全相关,例如冯.诺依曼,很大程度是后天环境教育形成的。基因只是必要条件,而非充分条件。作为一个生物学博士,我反对用基因工程改变人的智能的做法,认为这很邪恶。科学家应该对自然法则或上帝有所敬畏。在西方,优生学是不能提的,因为它违反了人本主义的原则和人文人权的理念。我个人认为这个题目在科学道德上越界了,是不能想象的。
【杨静lillian】您说过美国的大脑计划雷声大雨点小,请问欧盟的大脑工程您怎么看,会对人工智能发展起到促动作用么?或者说,人工智能研究是否应以人的大脑为模型? 【邢波 Eric P. Xing】欧洲大脑工程的争议很大,包括目标和经费分配。但这个目标也提升了社会和公众的对于科学的关注,工程的目的不用过于纠结。这个项目就是启发式的,培养人才,培养科学实力的种子项目。 大脑工程,无论欧洲和美国,对人工智能发展没有直接的促进作用。以仿生学来解释人工智能工程上的进步,至少在学术上不是一个精确和可执行的手段,甚至是歧路。只是用于教育公众,或者通俗解释比较艰深的科学原则。 人工智能不必也不应以人脑为模型。就像飞机和鸟的问题,两者原理手段完全不同。人工智能应该有自己的解决办法,为什么要用人脑的模型来限制学科的发展?其实有无数种路径来解决问题,为什么只用人脑这一种模板?
机器学习领域应多元探索,巨大潜力与空间待挖掘
【李志飞】更正一下我的问题: 现有的机器学习算法如深度学习在利用大数据和高性能计算所带来的红利是不是遇到瓶颈了?(至少我所在的机器翻译领域是这样) 接下来会有什么新机器学习算法或原理会把大数据和高性能计算再次充分利用以大幅提升应用的性能?我觉得如果机器学习领域想在应用领域如机器翻译产生更大的影响,需要有更多人做更多对应用领域的教育和培训,或者是自己跨界直接把理论研究跟应用实践结合起来 【邢波 Eric P. Xing】机器学习的算法有几百种,但是目前在深度学习领域基本没有被应用。尝试的空间还很大,而且无需局限在深度学习下。一方面机器学习学者需要跨出自己的圈子去接触实际,另一方面应用人士也要积极学习,掌握使用发展新理论。
【杨静lillian】您认为谷歌是全球最具领导性的人工智能公司么?您预测人工智能技术会在哪几个领域得到最广泛的应用?人工智能产业会像互联网领域一样出现垄断么? 【邢波 Eric P. Xing】谷歌是最具有领导性的IT公司。世界上没有人工智能公司,公司不能用技术手段或目标定义名称和性质。人工智能是一个目标,而不是具体的一些手段。所以有一些界定是不严肃的。关于应用领域前面已经谈过了。
【杨静lillian】您曾经比喻,中国的人工智能领域里,有皇帝和大臣,您怎么判断中国人工智能产业的发展水平和发展方向?最想提出的忠告是什么?
【邢波 Eric P. Xing】中国整个IT领域,以至科学界,应该百花齐放,有的观点占领了过多的话语权,别的观点就得不到尊重。目前业界形成一边倒的局面,媒体的极化现象比较严重。建议媒体应该平衡报道。中国目前深度学习话语权比较大,没人敢批评,或者其他研究领域的空间被压缩。这种研究空间的压缩对机器学习整个领域的发展是有害的。学界也存在有人山中装虎称王,山外实际是猫的现象。坦率的说,目前中国国内还没有世界上有卓越影响的重量级人工智能学者,和数据科学学者。中国需要更多说实话,戳皇帝新衣的小孩,而不是吹捧的大臣、百姓和裸奔的皇帝。不要等到潮水退去,才让大家看到谁在裸奔。 现在一些舆论以深度学习绑架整个机器学习和人工智能。这种对深度学习或以前以后某一种方法的盲目追捧,到处套用,甚至上升到公司、国家战略,而不是低调认真研究其原理、算法、适用性和其它方法,将很快造成这类方法再次冷却和空洞化,对这些方法本身有害。行外人物、媒体、走穴者(比如最近在太庙高谈阔论之流)对此的忽悠是很不负责的,因为他们到时可以套了钱、名,轻松转身,而研发人员投入的时间、精力和机会成本他们是不会在乎的。美国NSF、军方和非企业研究机构与神经计算保持距离是有深刻科学原因的,而国内从民到官这样的发烧,还什么弯道超车,非常令人怀疑后面的动机和推手。
【杨静lillian】确实如您所说,现在大多数中国企业或学术机构,被一个大问题困扰。就是缺乏大数据源,或者缺乏大数据分析工具,那么怎样才能搭上大数据的时代列车呢? 【邢波 Eric P. Xing】首先我没有那样说过,我的看法其实相反。即使给那些企业提供了大数据,他们真会玩么?这有点叶公好龙,作为一个严肃的研究,应该把工具造出来。得先有好的技术,别人才会把数据提供给你。有时小数据都没做好,又开始要大数据,没人会给。可以用模拟,更可以自己写爬网器(crawler)自己在网上抓。例如我们的实验室,学生就可以自己去找数据源。研究者的心态有时不正确,好像社会都需要供给他,自己戴白手套。其实人人都可以搭上“大数据”这个列车,但需要自己去勤奋积极努力。
【杨静lillian】Petuum开源技术系统会成为一种大数据处理的有效工具么?可以取代Spark? 【邢波 Eric P. Xing】希望如此。更客观地说,不是取代。是解决不同的问题,有很好的共生、互补关系。
中国学术界的原创性待提高,缺乏灯塔型领军人物
【刘成林】@杨静lillian问题提的好!期待详细报道。另外我加一个问题,请Eric给中国人工智能学术界提点建议,如何选择研究课题和如何深入下去。 【邢波 Eric P. Xing】希望中国人工智能学术界要对机器学习、统计学习的大局有所掌控,全面判断和寻找,尚未解决的难题。这需要很多人静下来,慢下来,多读,多想。而不是跟风或被热点裹挟。得有足够的耐心,屏蔽环境的影响和压力。在技术上得重视原创性,如果只把学术看成是一个短时期的比赛,价值就不大。得找有相当难度,而自己有独特资源的方向,就保证了思想的原创性和资源的独特性。要分析清楚自己的优势。 例如我们做的Petuum,很多人就不敢碰。我们开始时甚至都不懂操作系统,从头学;我们放缓了步子,两年近十人只出两篇文章。但不尝试怎么知道?得给自己空间。
【张宝峰】邢老师提到过在机器学习领域,美国可以分成几个大的分支,比如Jordan 算一个,能否再详细的阐述还有哪些其他分支和流派? 【邢波 Eric P. Xing】这算八卦。原来有几个流派,但现在流派的界限已经非常模糊了。
【刘挺-哈工大】您认为哪些方向或组织有希望出现领军人物? 【邢波 Eric P. Xing】国内的同行思路有些短板,所以研究领域比较割裂。上层不够高,下层也不够深,横向也不宽,因此扎根不够,影响有限。所以比较缺憾,体现为很多割裂的领域。 在中国的企业界和学术界哪里会出现领军人物?这个问题我认为:对什么叫“领军人物”国内的同行的定义还相当肤浅,功利。除了商业上的成功,或者学术上获奖,这些显性成就,还需要有另外的维度。例如从另外一个角度,具有个人魅力,他的思想、理论、人格被很多人追随和推崇的,有众多门生甚至超越自己的,就没有。中国的研究者不善于建立自己的体系,去打入一个未知的境界,做一个灯塔型的人物。这种人物在中国特别少,基本上没有。 在美国M.Jordan就是这样的人物,就有灯塔型的效应,被众人或学术界效法,敬佩,和追随,包括他的反对者。他也不是中国最典型的最年轻教授等成功人物,而是大器晚成,到了45岁才开始发扬光大,上新台阶。但他的做为人的魅力(会五国语言,年轻时弹琴挣钱,平时风趣博学);他的勤奋自律(到Berkeley后正教授了还和我们一起在课堂听课,从头学统计,优化,到现在还天天读文献);他的工作和生活的平衡(现在自己组乐队,和孩子玩儿);他的众多学生的成就(很多方向和他大不相同,甚至相对);他的严谨,严肃的学风;和他的洞察力。这些都是除了学术成就之外他成为领军人物的要素。我们国内知识分子接近这个境界的太少了。不要说学术上的差距,就连上餐桌品酒、懂菜,说话写作遣词造句的造诣都差不少。所以,先不要急出领军人物;先从文化上培育土壤,培育认真、一丝不苟的习惯和精神,培育热爱教学、热爱学生的责任;培育洁身自好、玉树临风的气质;注重细节、小节、修养,再由小至大、由士及贤、由贤入圣。在这个境界上,学问就变成一种乐趣了,就可以做出彩了。
【张宝峰】欢迎回国,把Pleuum变成实际产业标准。 【邢波 Eric P. Xing】不是没有可能,但也需要好的平台和环境、机缘。这次回国参会,很兴奋的是,学术界和产业界都对机器学习的技术有很大的热情,也有信念去获取成功,相当积极。我个人的观点,通过交流,收获很大。期望这种交流继续,也期待国内的学界、媒体、企业能够共同促进产业生态的发展,利益多样化。可以是金钱的成功,也可以是原创性的增长。而不是被某一个目标来一统天下。 如果回国发展,应该有更多商业上的机会。但是国内的起点低,有些规则两国不一样。现在人生的目标不是钱,而是对乐趣的满足,以及服务社会。实现自我的价值,也让家人,朋友,学生,师长,同事开心。 下个月还有机会回国,到时也期待与大家继续交流互动。非常感谢@杨静lillian 提供这个和大家交流的机会。也钦佩她专业敬业。这次结识很多朋友,后会有期! | |
|
(3个打分, 平均:5.00 / 5) |
The Wall Street Journal吴恩达专访
作者 AbelJiang | 2014-12-08 13:47 | 类型 Deep Learning, 机器学习, 行业动感 | Comments Off
|
原文转载自:http://blogs.wsj.com Six months ago, Chinese Internet-search giant Baidu signaled its ambitions to innovate by opening an artificial-intelligence center in Silicon Valley, in Google’s backyard. To drive home the point, Baidu hired Stanford researcher Andrew Ng, the founder of Google’s artificial-intelligence effort, to head it. Ng is a leading voice in “deep learning,” a branch of artificial intelligence in which scientists try to get computers to “learn” for themselves by processing massive amounts of data. He was part of a team that in 2012 famously taught a network of computers to recognize cats after being shown millions of photos. On a practical level, the field helps computers better recognize spoken words, text and shapes, providing users with better Web searches, suggested photo tags or communication with virtual assistants like Apple’s Siri. In an interview with The Wall Street Journal, Ng discussed his team’s progress, the quirks of Chinese Web-search queries, the challenges of driverless cars and what it’s like to work for Baidu. Edited excerpts follow: WSJ: In May, we wrote about Baidu’s plans to invest $300 million in this facility and hire almost 200 employees. How’s that coming along? Ng: We’re on track to close out the year with 96 people in this office, employees plus contractors. We’re still doing the 2015 planning, but I think we’ll quite likely double again in 2015. We’re creating models much faster than I have before so that’s been really nice. Our machine-learning team has been developing a few ideas, looking a lot at speech recognition, also looking a bit at computer vision. WSJ: Are there examples of the team’s work on speech recognition and computer vision? Ng: Baidu’s performance at speech recognition has already improved substantially in the past year because of deep learning. About 10% of our web search queries today come in through voice search. Large parts of China are still a developing economy. If you’re illiterate, you can’t type, so enabling users to speak to us is critical for helping them find information. In China, some users are less sophisticated, and you get queries that you just wouldn’t get in the United States. For example, we get queries like, “Hi Baidu, how are you? I ate noodles at a corner store last week and they were delicious. Do you think they’re on sale this weekend?” That’s the query. WSJ: You can process that? Ng: If they speak clearly, we can do the transcription fairly well and then I think we make a good attempt at answering. Honestly, the funniest ones are schoolchildren asking questions like: “Two trains leave at 5 o’ clock, one from …” That one we’ve made a smaller investment in, dealing with the children’s homework. In China, a lot of users’ first computational device is their smartphone, they’ve never owned a laptop, never owned a PC. It’s a challenge and an opportunity. WSJ: You have the Baidu Eye, a head-mounted device similar to Google Glass. How is that project going? Ng: Baidu Eye is not a product, it’s a research exploration. It might be more likely that we’ll find one or two verticals where it adds a lot of value and we’d recommend you wear Baidu Eye when you engage in certain activities, such as shopping or visiting museums. Building something that works for everything 24/7 – that is challenging. WSJ: What about the self-driving car project? We know Baidu has partnered with BMW on that. Ng: That’s another research exploration. Building self-driving cars is really hard. I think making it achieve high levels of safety is challenging. It’s a relatively early project. Building something that is safe enough to drive hundreds of thousands of miles, including roads that you haven’t seen before, roads that you don’t have a map of, roads where someone might have started to do construction just 10 minutes ago, that is hard. WSJ: How does working at Baidu compare to your experience at Google? Ng: Google is a great company, I don’t want to compare against Google specifically but I can speak about Baidu. Baidu is an incredibly nimble company. Stuff just moves, decisions get made incredibly quickly. There’s a willingness to try things out to see if they work. I think that’s why Baidu, as far as I can tell, has shipped more deep-learning products than any other company, including things at the heart of our business model. Our advertising today is powered by deep learning. WSJ: Who’s at the forefront of deep learning? Ng: There are a lot of deep-learning startups. Unfortunately, deep learning is so hot today that there are startups that call themselves deep learning using a somewhat generous interpretation. It’s creating tons of value for users and for companies, but there’s also a lot of hype. We tend to say deep learning is loosely a simulation of the brain. That sound bite is so easy for all of us to use that it sometimes causes people to over-extrapolate to what deep learning is. The reality is it’s really very different than the brain. We barely (even) know what the human brain does. WSJ: For all of Baidu’s achievements, it still has to operate within China’s constraints. How do you see your work and whether its potential might be limited? Ng: Obviously, before I joined Baidu this was something I thought about carefully. I think that today, Baidu has done more than any other organization to open the information horizon of the Chinese people. When Baidu operates in China, we obey Chinese law. When we operate in Brazil, which we also do, we obey Brazil’s law. When we operate in the U.S. and have an office here, we obey U.S. law. When a user searches on Baidu, it’s clear that they would like to see a full set of results. I’m comfortable with what Baidu is doing today and I’m excited to continue to improve service to users in China and worldwide. | |
|
(没有打分) |
Spark的现状与未来发展
作者 陈怀临 | 2014-12-02 10:17 | 类型 Deep Learning, 机器学习 | 1条用户评论 »
|
[转载文章] Spark的发展对于一个具有相当技术门槛与复杂度的平台,Spark从诞生到正式版本的成熟,经历的时间如此之短,让人感到惊诧。2009年,Spark诞生于伯克利大学AMPLab,最开初属于伯克利大学的研究性项目。它于2010年正式开源,并于2013年成为了Aparch基金项目,并于2014年成为Aparch基金的顶级项目,整个过程不到五年时间。
由于Spark出自伯克利大学,使其在整个发展过程中都烙上了学术研究的标记,对于一个在数据科学领域的平台而言,这也是题中应有之义,它甚至决定了Spark的发展动力。Spark的核心RDD(resilient distributed datasets),以及流处理,SQL智能分析,机器学习等功能,都脱胎于学术研究论文,如下所示:
Discretized Streams: Fault-Tolerant Streaming Computation at Scale. Matei Zaharia, Tathagata Das, Haoyuan Li, Timothy Hunter, Scott Shenker, Ion Stoica. SOSP 2013. November 2013.
Shark: SQL and Rich Analytics at Scale. Reynold Xin, Joshua Rosen, Matei Zaharia, Michael J. Franklin, Scott Shenker, Ion Stoica. SIGMOD 2013. June 2013.
Discretized Streams: An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters. Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, Ion Stoica. HotCloud 2012. June 2012.
Shark: Fast Data Analysis Using Coarse-grained Distributed Memory (demo). Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Haoyuan Li, Scott Shenker, Ion Stoica. SIGMOD 2012. May 2012. Best Demo Award.
Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker, Ion Stoica. NSDI 2012. April 2012. Best Paper Award and Honorable Mention for Community Award.
Spark: Cluster Computing with Working Sets. Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, Ion Stoica. HotCloud 2010. June 2010.
在大数据领域,只有深挖数据科学领域,走在学术前沿,才能在底层算法和模型方面走在前面,从而占据领先地位。Spark的这种学术基因,使得它从一开始就在大数据领域建立了一定优势。无论是性能,还是方案的统一性,对比传统的Hadoop,优势都非常明显。Spark提供的基于RDD的一体化解决方案,将MapReduce、Streaming、SQL、Machine Learning、Graph Processing等模型统一到一个平台下,并以一致的API公开,并提供相同的部署方案,使得Spark的工程应用领域变得更加广泛。
Spark的代码活跃度
从Spark的版本演化看,足以说明这个平台旺盛的生命力以及社区的活跃度。尤其在2013年来,Spark进入了一个高速发展期,代码库提交与社区活跃度都有显著增长。以活跃度论,Spark在所有Aparch基金会开源项目中,位列前三。相较于其他大数据平台或框架而言,Spark的代码库最为活跃,如下图所示:
从2013年6月到2014年6月,参与贡献的开发人员从原来的68位增长到255位,参与贡献的公司也从17家上升到50家。在这50家公司中,有来自中国的阿里、百度、网易、腾讯、搜狐等公司。当然,代码库的代码行也从原来的63,000行增加到175,000行。下图为截止2014年Spark代码贡献者每个月的增长曲线:
下图则显示了自从Spark将其代码部署到Github之后的提交数据,一共有8471次提交,11个分支,25次发布,326位代码贡献者。
目前的Spark版本为1.1.0。在该版本的代码贡献者列表中,出现了数十位国内程序员的身影。这些贡献者的多数工作主要集中在Bug Fix上,甚至包括Example的Bug Fix。由于1.1.0版本极大地增强了Spark SQL和MLib的功能,因此有部分贡献都集中在SQL和MLib的特性实现上。下图是Spark Master分支上最近发生的仍然处于Open状态的Pull Request:
可以看出,由于Spark仍然比较年轻,当运用到生产上时,可能发现一些小缺陷。而在代码整洁度方面,也随时在对代码进行着重构。例如,淘宝技术部在2013年就开始尝试将Spark on Yarn应用到生产环境上。他们在执行数据分析作业过程中,先后发现了DAGSchedular的内存泄露,不匹配的作业结束状态等缺陷,从而为Spark库贡献了几个比较重要的Pull Request。具体内容可以查看淘宝技术部的博客文章:《Spark on Yarn:几个关键Pull Request(http://rdc.taobao.org/?p=525)》。
| |
|
(没有打分) |
机器学习应用–Smart Autofill
作者 AbelJiang | 2014-12-02 10:13 | 类型 机器学习, 行业动感 | Comments Off
|
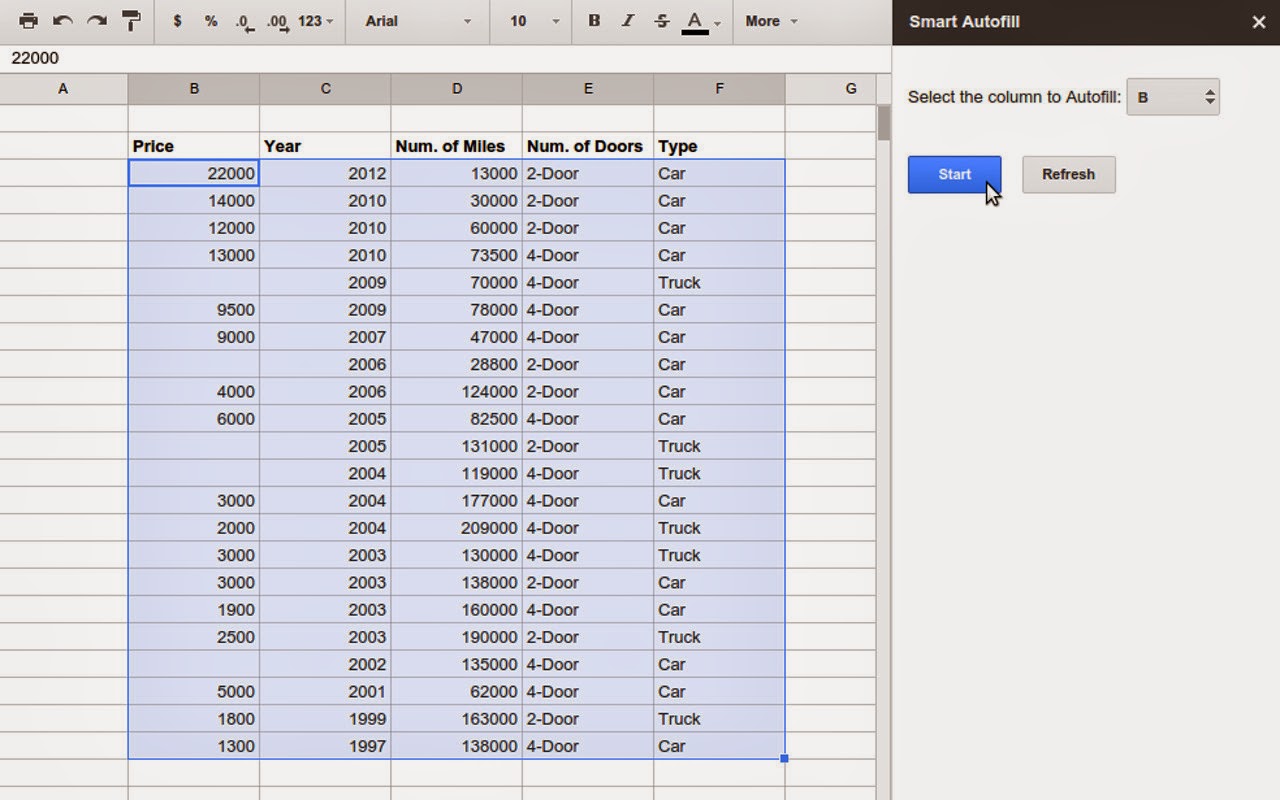
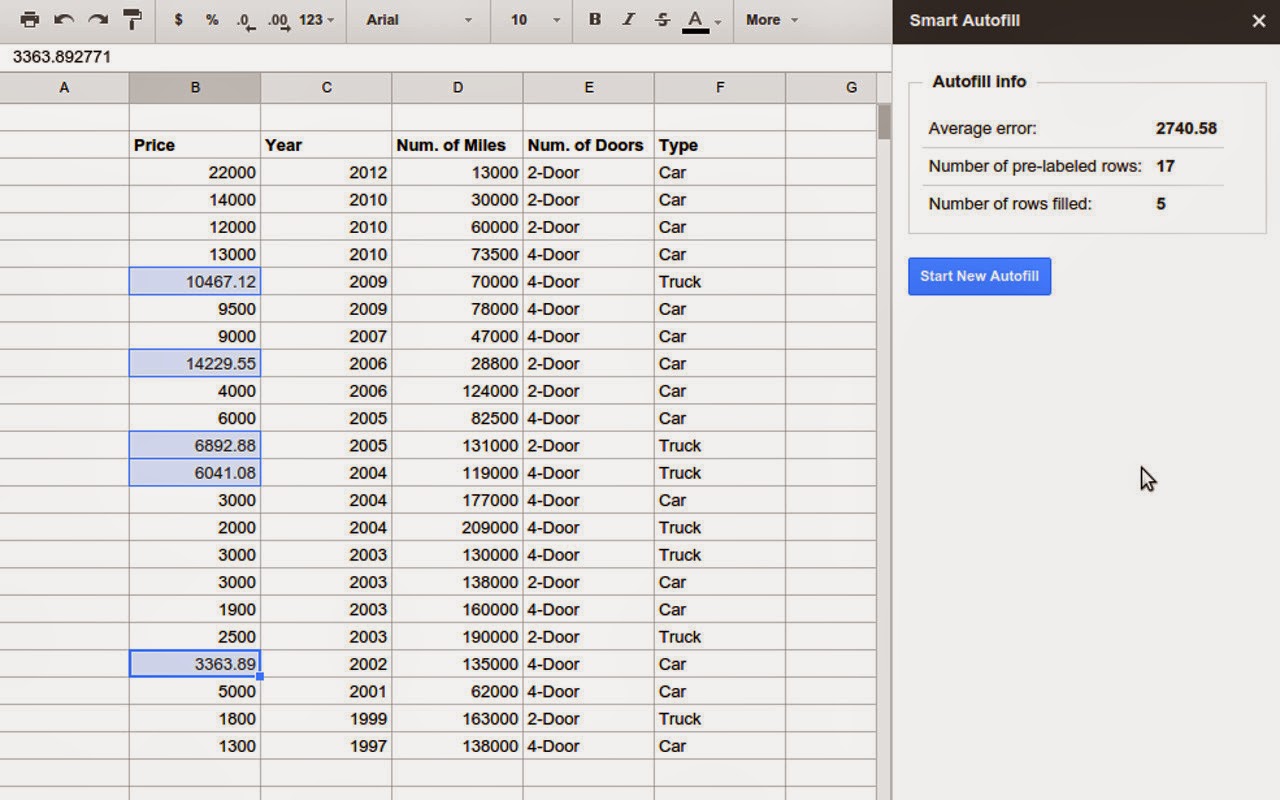
机器学习算法被广泛的应用在谷歌家的语言语音处理,翻译,以及视觉图像处理方面的应用上,看起来都是比较拒人千里的东西,但是最近,谷歌把这项技术用在了自家的Google Sheets上,貌似在我朝较难使用Google Sheets,但是感兴趣还是可以在Chrome Webstore里找到这款叫做Smart Autofill的插件试用一下。 那么Smart Autofill是干什么用的呢?顾名思义,它是用来填表的。经常用Excel的读者一定知道一个功能叫自动填充,能够填充的信息包括日历日期,星期,以及有序数字等。Smart Autofill干的是类似的事,但由于融入了机器学习,逼格又稍高,它可以根据表格中与缺失信息栏相关栏中的数据,学习其中的模式,推测出缺失信息栏中缺失的数据。 Smart Autofill使用了谷歌基于云的机器学习服务–Prediction API。这项服务可以训练多种线性或非线性,分类和回归模型。他会通过对比利用cross-validation算出的Misclassification error(针对分类问题)或RMS error(针对回归问题),自动选出最佳的模型,用于数据预测。 让我们来举个例子: 在下图的截图中,我们给出车的五个非常简单的数据,分别为使用购买年份,行驶里程,车门数量,车辆类型以及价格。因为车的价格可能和车的这些特质有关,因此可以把那些包含价格的行作为训练数据,用Smart Autofill来估测缺失的价格数据。
/*高亮所需数据,选中目标栏*/
参考: | |
|
(没有打分) |
【王涵:物理八卦】星际穿越、相对论和Kip Thorne
作者 陈怀临 | 2014-12-01 14:02 | 类型 科技普及 | 7条用户评论 »
|
这是一篇“戏说+八卦+观后感”的文章,笔者主要的目的,是做个纪念。其中更多的是一些物理八卦,而且笔者一扯这些东西就收不住,然而有关电影中的一些桥段,虽有涉及,却并不多。请各位看官知悉。 1.这部电影对笔者的特殊意义:跟Interstellar套个近乎:1.1 从师承上,往Interstellar上套个近乎:本人和太太在美国读天体物理PhD的时候,导师是Washington University 的Clifford Will教授,而本片的Executive Producer之一的Kip Thorne又是Clifford Will的博士导师,所以尽管本人在学术上算是相对论界不入流的小人物,但从师承上来说,算是Kip Thorne的嫡亲徒孙。换句提高Bigger的话说“这是俺师爷出品的电影”。
顺便说一句:前几天有朋友说到生活大爆炸里的Sheldon认不认识Kip Thorne,我记得有一集里面,Sheldon说要去听Kip Thorne的讲座,所以Sheldon对Kip应该是属于敬仰的那种吧。在物理学界来说,Kip Thorne与霍金是同级别的人物(实际上两人也是非常好的朋友),而Sheldon遇到霍金时候有多紧张,我记得有一集里演过的。嘿嘿。
1.2 “2006年,那是一个冬天”,再往Interstellar上套个近乎:相对论这个圈子说小不小,说大不大。不知道从什么时候开始,这个圈子里比较重要的学者过60岁生日的时候,大家都会聚在一起开个学术会议,顺带为其办一个生日fest。印象里Kip Thorne的生日Kip Fest是2000年开的。而2006年的时候,赶上我导师60岁生日,于是就在我们学校搞了一次相对论的会议(2006 Midwest relativity meeting),开了Cliff Fest。
当天晚宴,恰巧安排我和Kip及其夫人Carolee一桌,那次应该是俺第一次在非正式学术的场合和Kip接触,也是在那晚的餐桌上第一次听Kip说起前些时候斯皮尔伯格大叔找他,希望他写个剧本。用Kip的话来说,其目标是要拍一部“时空旅行、平行宇宙、但又不违反物理定律”的电影。由于Kip是俺们这个圈子里大神一样的人物,因此之后虽然偶2009年离开物理界,来到金融圈子里混饭吃,但仍会时不时的关心一下那个电影的进度。8年磨一剑,真是等的花都要谢了。好在电影从制片、导演到演员,没有一个是低规格的,算是对得起俺们的苦等。而片中一些对奇异物理现象深入浅出的解释,简直就是当年读书、搞研究时候的情景再现,八年过去,物是人非,看完差点掉眼泪。扯远了……
1.3 Michael Caine扮演的Prof.Brand与Thorne的关系Interstellar里面,当型男主角走进NASA那个会议室,Michael Caine扮演的Prof.Brand第一次出场的时候,俺直接就叫出声来了,那活脱脱就是一个当年有头发时候的Kip Thorne的形象(好像08年之后Kip Thorne开始剃光头,偶戏称之为“龟仙人老爷爷造型”)。偶认为,Michael Caine就是按照Thorne的形象来装扮的。此前也一直有传言Kip可能会在片中扮演一个角色,最终以Michael Caine来出演,也算了不错。当然,像不像这个事情,仁者见仁智者见智。下面几张照片,供看官自行判断:
【Thorne有头发时候的形象】
【片中的Prof.Brand】
【Thorne光头的“龟仙人老爷爷”形象】 2. Kip Thorne与理论物理界的Wheeler系【照片:Thorne和Wheeler】
要八KipThorne,就得从他的导师John Archibald Wheeler开始谈起。Wheeler本人在研究方面已经是大牛了,但Wheeler对理论物理学界更大两件贡献,第一个,是在学界对相对论理论的理解,从“几何化”向“物理化”过程中,做了非常多的贡献;第二个,是Wheeler一系培养了大量牛X的徒子徒孙,Wheeler的学生里,除了Kip Thorne之外,还有大名鼎鼎的费曼。
2.1 相对论:数学还是物理?【注:本部分有一些物理内容,和Interstellar无关,主要是为后面八卦Wheeler用的,无兴趣者可跳过】
物理理论的发展史上,数学在其中一直起着非常重要的作用。例如经典力学的发展,就离不开牛顿、莱布尼兹等人对微积分的贡献。但至少整个经典理论里面,数学更多的是一种辅助的作用,物理的本源仍然是可以独立于数学存在的。而到了老爱的广义相对论这里,情况就变了。
简单的一个结论,狭义相对论是有一个有关世界观的理论,而广义相对论,则是将这种世界观拓展到了有引力存在的情况下。
所谓的狭义相对论的世界观,即是说,在狭义相对论之前,人类是从“三维空间+一维时间”的角度去理解世界的。而老爱的狭义相对论,第一次把“空间+时间”放在了一起,让我们从“四维时空”的角度去理解这个世界。
”4维”时空到底有啥特别的呢?简单的来说,如果我们认为世界的本质应该用四维时空来描述(其中包括3维空间+1维时间),那么时间仅仅是某个物理量在时间轴上的投影。就像我们在中学解析几何中学到的那样,对于X-Y直角坐标系中的一个矢量,我们可以通过垂直投影的方式,读出这个矢量在两个轴上投影的长度。但如果我们将坐标轴本身(顺时针或逆时针)旋转一下,则尽管这个矢量本身没有任何的变化,但我们在新坐标轴上读出的两个投影长度就发生了变化。换句话说,在这个问题里面,这个矢量是一个本质的东西,而其在各个坐标系下的投影,会因为观察角度和立场(坐标系)的不同而不同、并非物理本质。
如果我们把上面的Y轴,想象成时间轴,则会发生什么呢?明白了吧?简而言之,老爱的狭义相对论,认为我们应该用四维时空来描述世界,时间只是和空间的x,y, z维度一样,并非物理现象的本质,而是物理现象(准确来说是物理事件event)在坐标轴上的一个投影。当观察者所处的坐标系(观察系)不同,距离(比如尺子的长端),时间(或者说时钟的快慢)就会有差异。
在经典物理学中,引力和电磁力是有比较完备理论的。但是,老爱在狭义相对论里面,是没有考虑引力的。狭义相对论和经典的电磁学结合的很好,但当老爱开始考虑把引力也纳入相对论的框架时,开始遇到问题。最终的解决办法,是通过黎曼几何,即老爱用时空弯曲来解释了引力的本质。
关于时空弯曲和引力的关系,一个科普读物中常出现的例子:想象有一个巨大的床垫,其表面柔软且平滑,我们在上面滚玻璃球。如果床垫上没有别的东西,床垫是平的,则玻璃球在上面总是沿着直线运动(牛顿第一定律)。现在想象一下,我们在这个床垫的中间放一个很重的保龄球,这个时候,床垫的表面就发生了弯曲(中间陷下去了)。如果这个时候在上面玩玻璃球,玻璃球的轨迹就会不由自主的偏向中间的保龄球。对于速度慢或者一开始静止的玻璃球,最终会掉到保龄球旁边(俘获)。而如果玻璃球的初速度比较快,且角度合适,玻璃球就会绕着保龄球转上几圈(轨道);如果速度再快一点,玻璃球的轨迹只是会在途径保龄球附近时候发生比较明显的弯曲,然后就跑远了(逃逸)。
现在让我们想象,中间的这个保龄球是太阳,床垫是四维时空,小玻璃球是行星。牛顿认为,行星的轨迹之所以会受到太阳的影响,是因为两者之间有“引力”。而老爱认为,两者之间的这种关系,本质可以用时空(床垫)弯曲来解释。质量大小,决定了时空弯曲的程度。
上面的这个比方,只是科普读物为了让读者理解,对老爱理论的一种简化,实际上的情况复杂得多。但老爱的广义相对论,把引力等同于时空弯曲,这是其最核心的理念。但这种处理方法,也带来了一个麻烦,就是传统意义上的数学在广义相对论里很多都失效了。想象一下,弯曲时空有多麻烦,比方说,在平直时空里面,两条平行线是不会相交的,但弯曲时空中就不同。比如地球上所有的经度线,在赤道上的时候都是平行的,但都会在南极、北极两个点上相较,这是因为地球表面是一个2维曲面。2维曲面已经如此复杂,现在来让我们想象一下四维曲面。所以,为了更好的描述引力场下的相对论理论,必须要引入黎曼几何。
2.2 从物理的角度理解相对论:Wheeler系与MTW前面说了,广义相对论对于数学的要求很高,尤其是对于非平直时空的数学(黎曼几何)。但就像李政道说过”数学书只有两种,一种是看了一页就看不下去的,另一种是看了第一句话就看不下去的“,物理学家尽管看起来都是nerds,但此nerds和数学家的那种nerds还是差了很多数量级的。黎曼几何那种高深的东东,在20世纪初对物理学家来说还是很新鲜的玩意儿,所以老爱的理论诞生之后有一段时间里,物理界的老少爷们儿们,大多数都是除了膜拜之外不知道该咋办。就像爱丁顿接受采访的那个经典段子:记者说”听说您是世界上三个真正懂得相对论的人之一“,爱丁顿老爷回答”我得仔细想想第三个人是谁“。
理解相对论就得搞定黎曼几何,弄不懂相对论主要是因为黎曼几何没学好。从本人在相对论的学习经历来说,这个结论是对的,对于黎曼几何的理解,的确有助于学好相对论。但过于执着于数学,又似乎有些脱离了物理学的本质。
应该说,在那些最初的年代里,无数理论物理大牛,在如何使得”相对论更加物理,更加容易被物理界的新人们理解”方面,做出了巨大的贡献。而这些精华最终汇集到了一本1000多页的相对论圣经级别的教材–《gravitation》(中文翻译成“引力论”)。这本书的三位作者,就是前面说到的Wheeler、和Interstellar有着千丝万缕联系的KipThorne、以及Wheeler的另一个学生Misner。理论物理界喜欢用三位作者的lastname来称呼这本书,即Misner-Thorne-Wheeler,或者简称为MTW。
MTW中尽管汇集了前人很多的智慧,因此不能说其中所有内容全部都是三位作者的贡献,但其在相对论界的地位,是绝对的No.1教材,其最大的贡献,在于把物理和数学做了近乎完美的结合。我想,看完Interstellar的人,应该都会对其中那段”三维空间中的虫洞是个球体”深入浅出的解释印象深刻。现在让我们想象一下,在几十年前,当所有人都不知道该怎么样让学生对相对论入门的时候,突然出现了一本1000多页的教材,其中覆盖了从基础到前沿几乎所有相对论有关的分支,且其中几乎对每个难懂的物理现象、公式都进行了类似前面“虫洞”那样深入浅出的解释。这个影响有多大,不用说了吧?
顺便说一句,由于MTW实在是太厚,因此后来Thorne的一名PhD学生,德国马克思普朗克研究所的所长BernardF. Schutz又出了一本轻薄版的《Afirst course in general relativity》,堪称本科生学广义相对论的不二之选。而为了解决相对论学习过程中,做题的问题,Thorne的另外两个学生Lightman和Press又出了相对论学习最好的一本题集。可以说,基本上相对论这个圈子里的人,绝大多数都是一路读着Schutz,MTW,做着Lightman-Press的题目成长起来的。
任何物理问题都要用“普通人能读懂的语言解释清楚”,为什么Wheeler系在相对论和理论物理界如此举足轻重,我想和Wheeler及其这一系中的各位牛人延续下来的特点是分不开(记得电影margincalls里面,投行老大说“speakto me as if I am a child, or a golden retriver”,其实也是一样的道理)。 顺便说一句,在美国搞物理的那些年里,实实在在感受到,美国的优秀学者们很多都是非常好的演讲家。换句话说,就是能把“最复杂的内容用最平实易懂的语言表述出来”。举个例子,读博第一学期,学高等数学物理,有一节课一开始,俺们系那位大牛老师就说“让我花10分钟,给你们讲清楚量子电动力学”,十分钟之后,大家都明白了。而这一点上,后来俺去德国做博士后,以及回国以后,就深刻感受到美国这个理念的特殊性。无论是在德国,还是国内,似乎越牛的学者,越是”说话如天书,听不懂是你自己笨”为准则。这个不知道是个啥原因。
扯远了,还是那句话,大道至简,Wheeler系在相对论方面,把这一点发挥到了极致。为什么Wheeler一系出现了那么多牛人,我想与之是有很大关系的。
2.3 Wheeler、Thorne与“黑洞”、“虫洞”及时空旅行Interstellar里出现了很多天体的名称,其中听上去Bigger比较高的两个,一个是黑洞(Black Hole)、一个是虫洞(Worm Hole)。Wheeler是最早在物理界公开使用黑洞这个名词的人,他也是最早创造出“虫洞”这个名词,指出虫洞可以被用来进行时空旅行的人。而Thorne的研究中,则有很多内容都与此有关。
其实在牛顿理论和相对论里,都存在这样一个问题,当一个天体的质量太大的时候,引力会导致自身有收缩的趋势,如果没有足够的其他力量相抵消,这个物体向内的塌缩就不可避免。举个例子:我们的太阳。太阳巨大的能源来自于核聚变反应,换句话说,我们可以认为太阳是一个巨大的氢弹。由于这种聚变带来的力量,使得太阳现在还不会塌缩(氢弹爆炸的时候,会把各种物质从内向外炸飞,这种力量是抵消太阳向内的引力的本源),但当最终其燃料用尽的时候,就有可能发生塌缩。如果质量像太阳这么大的恒星,其塌缩到一定程度,会因为电子、或是中子的简并力而最终变成白矮星或者中子星。而如果一个恒星的质量超过一个叫“钱德拉塞卡极限”的数值,其塌缩就没有力量能够抵消,最终这颗恒星就会收缩为一个点,这个点的质量很大,但体积是0,于是质量密度无穷大,是一个奇点。而离这个点距离比较近的地方(电影中所说的视界面,event horizon以内)的地方,由于引力太强,连光也无法逃逸。这是“黑洞”这一名词的通常理解。(顺便说一句,像太阳那么大质量的一个恒星,塌缩后的视界面半径大概是3公里,这质量和半径两者是线性关系,所以像interstellar里面那个Gargantua那么大视界面积的黑洞,大家可以想象有多大了吧)
“黑洞”这个词的创始(推广)人是Wheeler。据说是这样的,1967年老先生在纽约开一个学术会,正讲到引力塌缩的问题,不知道台下是哪个路人甲喊了一句“就叫这玩意儿黑洞吧”。老先生很兴奋,于是这个名词就这么诞生了。
如果去读MTW的话,里面有很长的一段解释,为什么黑洞这个名词是很贴切的。首先,黑洞为什么是黑的?因为光跑不出来。其次,为什么我们称之为“洞“,物理的解释是,如果有一个宇航员掉进视界面的话,他看着自己的手表,然后等啊等啊,会发现永远也无法掉到中间的那个奇点上(撞上任何物质),也就是说,对宇航员来说,这的确就是个掉进无底洞的感觉。怎么样,这个名词贴切吧?
实际上的情况呢?反正问问法国人就知道了。“黑洞”一词在法语的俚语里面,是非常猥琐的一个词(对的,不要怀疑,就是你想的那个意思)。甚至于当第一次物理界有人给杂志投稿用到这个词的时候,那位法国的主编喊道“除非我死掉了,否则绝对不会让这么猥琐的词汇出现在我的杂志上”。最后的结果呢?“黑洞”这个词在物理界的这帮宅男们中间迅速传播,最终那位主编未能挡住”历史的洪流”。几年后,Wheeler老先生又创造了一个词–“黑洞无毛”!!!个人的经验来说,认识的法国人研究天体物理、相对论的不算太少,研究引力波的也有很多,但专注于研究黑洞的,好像还真不多。
虫洞这个词的创造者也是Wheeler,实际上“虫洞“(1957)这个词的出现比“黑洞”(1967)要早。1921年,Weyl在一篇论文里,就提出了虫洞的概念。从当前的理论来说,由于虫洞的稳定存在(即允许一个物体来回通过),需要在其周围有一圈稳定的负能量(而是密度为负值的能量)。所以在经典的框架下,是不存在这样的虫洞的。但由于在量子场论的框架下,真空并非真空,而是不断的有正负粒子对创生和湮灭,因此也可能在某个点上存在巨大的负能量,所以包括Thorne,霍金等人,都认为在这一框架下,是可能存在允许来回穿梭、且稳定存在的虫洞的。KipThorne的很多研究都与此有关,俺以前读博时候的一个officemate也是做这一块研究的。不过,这玩意儿一直没被找到(如果虫洞需要负能量,是否意味着这玩意儿没被找到的原因,是因为不利于“和谐社会”?:p),以至于在他60岁生日时候,还被人开玩笑“你都六十啦,看样子时间旅行也没戏了,咋办捏?”。
2.4 五维时空、膜(Brane)理论、与Interstellar中幽灵的通讯方式应该说,Interstellar里面,幽灵(就是主角)和女儿通讯的方式,应该是整个电影中最炫的一部分。实际上,这其中也隐含了很前沿的理论物理学思想。的确符合kip当年所说“一部有关时空旅行、平行宇宙、不违反物理定律的电影”。先来看一副剧照:
那个关键词是啥呢?Brane! Brane(膜)是个很火的词。本质上来说,搞弦论的里面,有一套Brane相关的理论,其中比较有名的,是MIT和哈佛双教授美女Lisa Randall和马里兰大学的Raman Sundrum共同创造的那个Randall-Sundrum模型。(顺便说一句,当年Randall找Sundrum一起做这个理论的时候,Sundrum正因为做博士后太久,失去信心,决定去华尔街,结果没想到一鸣惊人,于是华尔街少了一名牛人,马里兰大学多了一名正教授)
简单的来说,Randall-Sundrum试图解决这样一个问题:为什么引力会比其他力弱那么多?举个例子,当我们用吸铁石从地上吸起一个铁钉的时候,一方面,是吸铁石的磁力(电磁力)向上吸引铁钉,另一方面则是整个地球在向下(通过引力)吸引铁钉,结果呢?吸铁石赢了。小小的一块吸铁石产生的磁力,就打败了整个地球那么大的对手,这是一个非常不可思议的现象。在理论物理界,这被称之为“hierarchy problem”(咋翻译呢?等级制度问题?数量级问题?汗)。
Randall-Sundrum模型是这样解释这个问题的,其认为,我们所处的四维时空(3维空间+1维时间),实际上就像是五维时空里面的一层膜(Brane),而同时,实际上还存在着其他类似的Brane。如果我们认为一层膜就是一个宇宙,则也可以用来说是平行宇宙的一个理论。像电磁力这样的相互作用,只能在同一层膜上面传播(换句话说,只能存在于四维时空中),而引力,则可以在不同的膜之间传播(即引力可以在五维时空中传播)。
如果我们相信Randall-Sundrum模型是正确的,则就可以解释为什么引力会比其他相互作用(如电磁力)弱那么多。举个例子,一页纸的表面是一个2维平面,我们用一小管墨水,如果要涂满10X10厘米的一页纸很容易,但如果要涂满这样一叠10厘米厚的纸,可能就会不够用,因为这样一叠纸都要涂满,就多了一维(厚度),变成了一个三维的物体。如果非要涂满,且墨水不够的话,就得兑水稀释,于是单位面积上的颜色就浅了。简单来说,按照膜理论,引力扩散的范围是五维时空,比四维时空中的相互作用扩散范围大,所以导致其更弱。
回到电影中,只有引力可以在膜之间传播的特性,也就是为什么幽灵(男主角)只能通过引力来与女儿交流,而喊话则女儿听不见。因为只有引力能够穿梭于他所处的brane和女儿所处的brane之间,喊话(声音传播)本质上是基于电磁相互作用,被限制在他自己的Brane里了。
2.5 引力、引力波、与手表的指针。好了,上面说到了引力可以在Brane之间传播,这解释了幽灵(男主角)和女儿之间的交流途径,也可以解释沙子奇怪的掉落方式,书掉到地上(把垂直向下的引力场,变成水平的引力场就行了)等等,但是为什么他女儿手表的指针会走出那样奇怪的节奏? 其实这个也不奇怪,有两种可能的解释:1)引力场导致时钟的变化,这个的逻辑,跟那个Miller星球上时钟变慢一个逻辑;2)引力波导致物体的运动,简而言之,当引力波穿越一个物体时,会导致物体出现横向的摆动。 理论上说,这两种解释都有道理,不过考虑到:1)Kip Thorne对引力波研究做出的巨大贡献(现在就等着引力波探测器LIGO探测到引力波,然后极有可能拿诺贝尔奖);2)如果是时钟变化的话不可避免的导致戴着表的主角女儿受到影响。3)如果是时钟变化的话,按说不应该会看到时间往回走。综上来说,偶还是比较倾向于引力波的这一种解释。
2.6.其他的一些杂项
Miller行星为啥会有那么大的浪? 潮汐。就像月球绕着地球转,导致了地球上有潮汐,Miller由于离黑洞太近,所以在自转过程中带来了巨大的潮汐。应该不是公转导致的潮汐,否则潮汐就是一个鼓包,不会相对于Miller行星的表面移动。不过,自转说也有一个漏洞,就是如果是自转导致的潮汐,则应该是每一昼夜出现一次,显然当时电影里我们没看到天黑。电影嘛,黑布隆冬怎么拍,而且还得解释为啥一个小时转一圈。。。
为啥Miller星球离黑洞那么近都没掉进去? 这个也简单,就像月球为啥离地球那么近也没掉进去是一个道理,毕竟没有穿过视界面。按说这里面值得好好算算Miller离视界面到底有多近。另外也可以算算,由于引力波辐射导致的轨道衰减,多久之后Miller星球的轨道就会缩小到掉进视界面里面等等。不搞物理太久了,有兴趣的看官可以查一查相关的推导,应该是不难的。
弦理论与10维空间 片子里面最显眼的一个公式,应该是主角女儿推导出终极理论时写的那个公式,那时一个清晰的镜头给出,那是一个十维时空中的积分(积分里面有个d^10x)。OK,弦论。Btw,电影里黑板上的公式有很多都是KipThorne及其学生亲自写的,反正偶看到的都是靠谱的公式。其实想想也是,有一物理大牛坐阵,要往黑板上写乱七八糟的公式,好像更麻烦。
Mann星球上的那个机器人 OK,这个机器人的名字是KIPP,而不是Kip,不过俺宁愿相信是和Kip有关。 | |
|
(5个打分, 平均:5.00 / 5) |
