




铁臂阿童木——Intel ATOM处理器剖析与研究(2)
作者 帅云霓 | 2010-01-03 13:35 | 类型 专题分析, 弯曲推荐, 行业动感 | 11条用户评论 »
系列目录 铁臂阿童木—Intel ATOM处理器剖析与研究
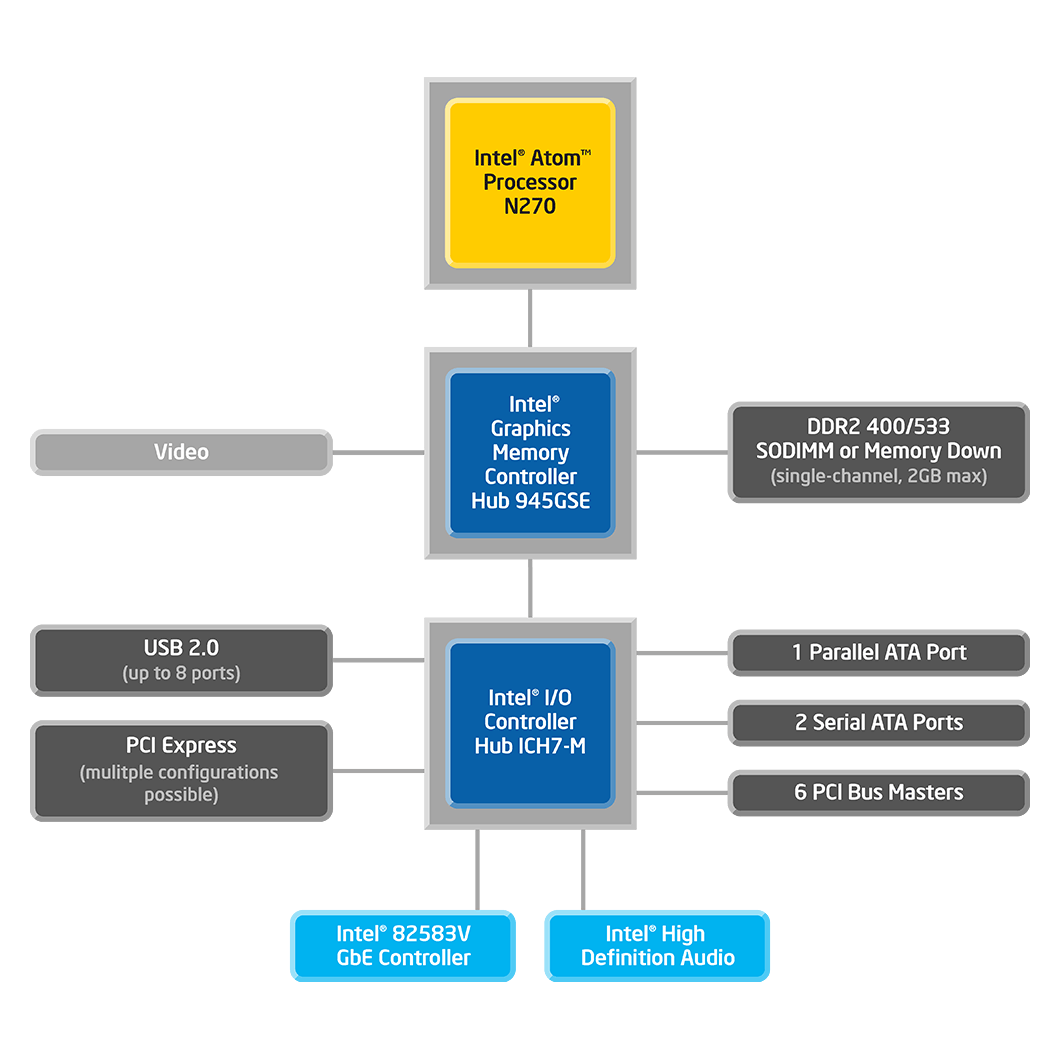
一 逆风飞翔——ATOM系统架构概览 ATOM是Intel推出的一系列处理器的总称。它包括第一代的N270(Diamondville)、Z5xx(Silverthorne)等,其指令集和寻址方式仍然基于Intel的IA32架构,也就是说,在指令集方面同通用的x86系列处理器兼容。因而,原有的x86处理器上的操作系统内核,往往只需要做不大的修改就能够在ATOM上运行,而应用软件的移植(porting)也不是一件困难的事情。 基于Intel x86处理器的系统,有三芯片系统和二芯片系统的区分。对于三芯片系统,三个主要芯片为CPU,北桥(GMCH)和南桥(ICH)。北桥和CPU之间由FSB相连,北桥集成了内存控制器、PCI/PCIE总线控制器等复杂大规模逻辑,一面连接到DRAM,如EDO DRAM/SDRAM/RAMBUS/DDR 等不同标准的内存。目前最新的动态内存(Dymatic RAM)标准为DDR3。 北桥和南桥之间通过PCI-E或PCI总线连接。PCI是旧的标准,其传输理论最大带宽,按PCI-X的标准,为1064MBps(64bit * 133MHz/8bit)。而且,由于PCI总线的地址/数据复用机制,在PCI的非Burst传输,特别是从外设读的效率非常低下。更加雪上加霜的是,PCI总线属于共享总线,一条总线上所有的设备,在总线仲裁机制下,共享这一有限的带宽。熟悉计算机网络的同学,可以用基于Hub的半双工以太网来类比PCI总线,整个总线上,在某一时刻只能有两个设备在单向交互(Transaction)。因此,在Pentium III及以后的系统中,PCI总线越来越成为南北桥之间的瓶颈。随着时代的进步,PCI-E在最新的计算机系统中逐渐取代了PCI/PCI-X,成为新一代局部总线(Local Bus)的标准。 PCI-E总线在软件操作上同PCI总线没有本质的不同,都是通过对配置空间的读写,获取到DMA和I/O地址段后对之使用常规的内存地址读写指令进行访问。用官方的语言来说,就是:系统从PCI到PCI-E的升级,对于软件(这里指驱动)来说是平滑的。PCI-E相对与PCI的改进主要是在硬件上,使用Serdes取代了PCI的并行传输,因此速率大大提升,并且减少了连接器引脚,降低了PCB布线的难度。另外就是引入了PCI-E Switch的概念,替代了原有的PCI-PCI Bridge。PCI-E Switch实际上是将多个PCI-E桥集中在一起,彼此之间都是Full-mesh的无阻塞Crossbar交换。因此,在一些中低端分布式处理的系统中,也常使用PCI-E实现Switch fabric的功能。PCI-E的传输带宽是可变的,通常以Lane为单位来度量。一个Lane包括两对高速串行差分信号线,工作在2.5GHz下,能够实现双向全双工通信,带宽为5Gbps。由于PCI-E使用8b/10b编码,每个Lane的字节传输速率可折算为0.5GBps。一个16个Lane的PCI-E总线的传输速率高达8GBps,这是传统PCI总线无可匹敌的。另外,PCI-E数据传输使用数据包方式,这一方式在数据组块传输时,开销大大小于PCI的Burst方式。这也进一步拉开了PCI-E和PCI之间的差距。另外,PCI-E还支持基于流量类别(TC)/虚拟信道(VC)的QoS/流控功能。 如前文所述,由于PCI-E具有如此多的社会主义优越性,在现代计算机系统中,使用PCI-E作为局部总线(Local Bus),也就是理所当然的了。 为了降低成本,增加系统的可靠性,降低功耗,Intel在某些产品解决方案中,将南北桥集成在了一个芯片里,也就是所谓的二芯片系统。易言之,在一颗芯片集成了PCI-E总线控制器、内存控制器、GPU,以及传统南桥芯片中的各种集成I/O设备。这样,用以连接北桥与南桥之间的PCIE/PCI总线就不需要了。 ATOM的N270系列使用了三芯片系统方案,而Z5xx系列使用的是二芯片系统方案。 N270的系统结构图如图1-1所示:
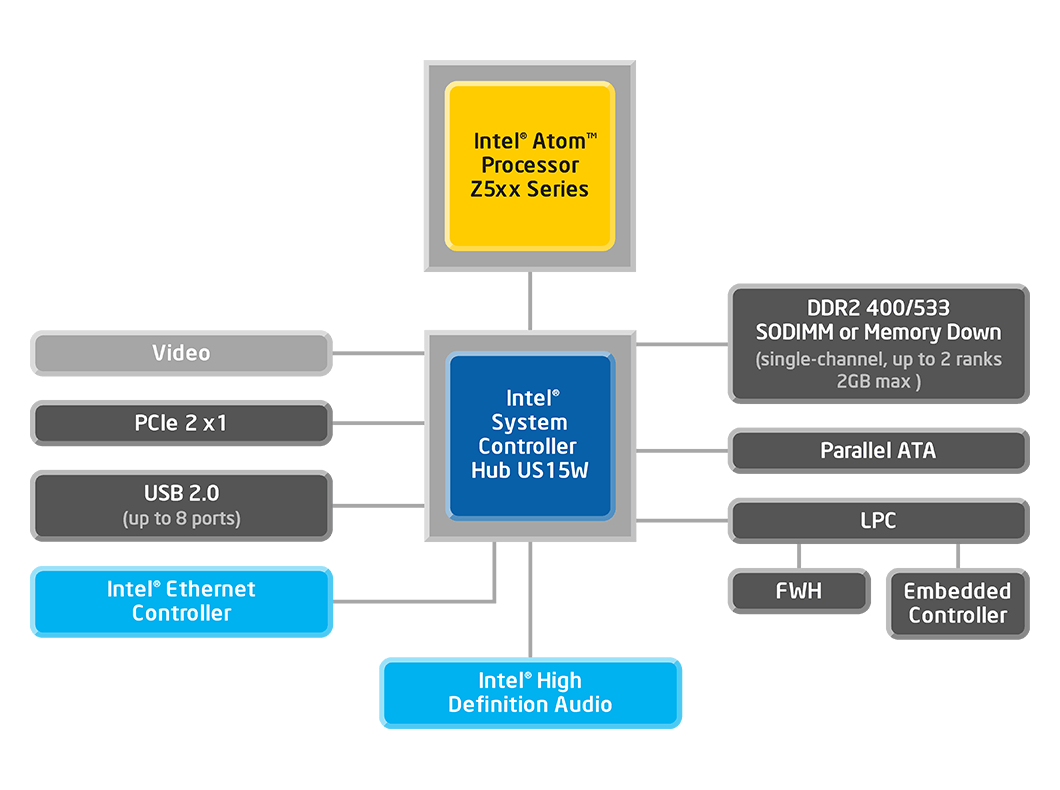
图1-1 ATOM N270典型系统框图 与经典的x86 Pc类似,ATOM N270的系统由CPU、北桥和南桥构成。北桥为Intel 945芯片,Intel称之为Graphics Memory Controller Hub(GMCH),也就是集成了动态内存(DRAM)控制器、PCI-E总线控制器、GPU(即俗称的集成显卡)。而南桥为Intel ICH7-M,ICH是IO Controller Hub的简称,基本上,整个系统的“粗活杂活”都由它承担:连接海量存储器的SATA/PATA接口;连接扩展PCI/PCIE接口的PCIE-PCI Bridge;USB2.0控制器;Intel的Audio Controller(俗称的集成声卡);82583 GigabitEthernet Controller (集成千兆以太网卡)。由于集成了PCIE-PCI Bridge,ICH-7还可以引出PCI-E和PCI扩展接口,可以连接SCSI控制卡、以太网网卡、WLAN(802.11)卡、高速模拟采集卡等外设。另外,传统Intel x86系统的Flash(BootROM/BIOS)控制接口、定时器8253、并行IO控制器8255,均集成在这颗南桥芯片中。 而ATOM Z5xx系列的集成度,比N270系列来得更高。图1-2是基于Z5XX系列的系统硬件框图: 图1-2 ATOM Z5xx典型系统框图
可以看出,Z5xx系统与N270系列系统的差别,就在于南桥和北桥整合到了一个芯片中。Intel给它起名为System Controller Hub,与CPU直接通过FSB相连。
图1-3 几张表现ATOM尺寸的照片
上图是几张摘自Intel官方文档的照片。从这张照片可以看出,ATOM非常小巧,die的面积只有几十mm2,而整个芯片面积也只有不到200mm2。这个面积是多大呢?大约比一颗围棋子略小。回忆一下火柴盒大小的PentiumIII/P4处理器,可以看出,Intel在这方面的确下了大功夫。 综上所述,Intel的ATOM实际上可以视为一套低功耗、低成本的轻量级嵌入式系统解决方案。在硬件设计的层面上,Intel的工程师们也为这个目的而付出了很多的心血。现在,就让我们继续通过Intel公开的资料,来剖析这个五脏俱全的ATOM的内在世界。 | |
 (6个打分, 平均:5.00 / 5) (6个打分, 平均:5.00 / 5) |



雁过留声
“铁臂阿童木——Intel ATOM处理器剖析与研究(2)”有11个回复
Intel的GMA显卡最新驱动至少有三个Bug被我修补,不过并没有上报开源社区,由此可见Intel的GMA显卡驱动质量。
上个月新发布的Atom的下一代产品Arrandale已经有了大的改动了。采用了32nm的生产工艺,Arrandale集成了内存控制器,另外还和一块45nm工艺的Gfx芯片封装在一起。
Atom的下一代是Pineview,双芯片系统架构,包括Atom N4xx/D4xx/D5xx系列,还是45nm的. 集成了nothbridge和graphics,配套干”粗活杂活”的是NM10 Express Chipset”,估计Q1就launch了。下下代是Cedarview,32nm,还用Pineview的架构。
Arrandale是core系列的。
我对x86系列很外行啊,最近刚刚开始了解Atom,问几个问题
1. 为什么Z5xx的桥片System Controller Hub用PATA而不是SATA呢?是否会很影响应用
2. N270和Z5xx的桥片是否能混用?反正CPU都是FSB的
3. N270和Z5xx除了功耗外,还有什么明显区别吗?为什么型号差别这么大。与Pentium-M的性能差别大吗?希望作者能就在新的嵌入式系统选择中如何选择这些x86 CPU给些更多的建议,非常感谢!
To BO: 没错。本文介绍的都是ATOM第一代处理器。第二代ATOM已经有坊间的公司拿到了评估板,容我慢慢搜集整理相关材料……
To digiwolf:你问的问题都非常不错。后面我会慢慢揭开这些问题的谜底。当然,可能还会出现一些更深入的,有些问题只能问Intel的工程师了。不过,对事物的认识正是在这个过程中逐渐加深的。
非常感谢大家的支持!
“PCI-E数据传输使用数据包方式,这一方式在数据组块传输时,开销大大小于PCI的Burst方式。”
难道基于TLP的PCIE没有开销?
不解,请解释。
aaa同学,我的《PCI-Express系统体系结构标准教材》被从前的一个同事借去看了,一直没有还给我。待我把书要回来再看看TLP的开销有多大。
不过,传统并行PCI的开销是很大的。因为,除非是Burst,否则都是一个地址,一个数据,再一个地址,一个数据这样读写……如果是从外设读,还有可能插入等待周期,那就更慢了。一般工程上计算的时候就认为它的效率大致是1/3,也就是理论带宽133M对应实际速率40M左右。
PCI的效率看包长情况了,根据本人实际的经验,在大包的情况下,有效数据传输率大概是总线带宽的80%,正常情况50~60%,最差也会有30~40%。
帅兄,你确信北桥和南桥之间的连接方式是PCIE或PCI,而不是DMI吗?
“一般工程上计算的时候就认为它的效率大致是1/3,也就是理论带宽133M对应实际速率40M左右。”。。。。
看来你确实是没算过。。。
好文章,要了解一些东西,我还是爱弯曲评论。