




铁臂阿童木——Intel ATOM处理器剖析与研究 (5)
作者 帅云霓 | 2010-01-23 09:57 | 类型 行业动感 | 11条用户评论 »
系列目录 铁臂阿童木—Intel ATOM处理器剖析与研究
二十万马力——ATOM 处理器硬件系统浅析 (3) 对于现代CPU来说,高速缓存(cache)是不可少的。这里说的高速缓存指的是为了消弭速度较快的CPU(速度为亚ns级别)和速度较慢的DRAM(速度为10ns级别)之间的瓶颈,而在处理器内部内建的高速SRAM。Cache对于IA-32架构来说,并不是一个必需的部分。对于软件来说,高速缓存可以认为是透明的,然而,高速缓存对处理器性能的影响,却实实在在地体现在应用程序的运行之中。 同所有通用处理器一样,ATOM的高速缓存是按照缓存行(cache line)组织的,分配的最小单位为64字节的cache-line。我们知道,大多数32位处理器的缓存行大小(cache-line size)为32字节,而Intel从NetBurst 微结构开始,全新设计的高速缓存子系统(cache subsystem)中,高速缓存行的大小增加了一倍。按照Intel的“葵花宝典”《Intel® 64 and IA-32 Architectures Software Developer’s Manual》的说法,这是为了增加批量读取时的传输速度。 ATOM的L1 cache有一个有趣或是奇怪的设计。它的指令cache大小为32kB,而数据cache则为24kB写回式(write back)。我们知道,通常地,L1 cache中,指令cache和数据cache大小一般是相等的,而ATOM为什么采用这种奇怪的“非对称”(asymmetric)设计呢?我们猜想,这应该是基于节省芯片面积和功耗的考虑。另外,同传统的每bit由6个晶体管构成的SRAM不同的是,ATOM的L1 Cache的每bit为8个晶体管。
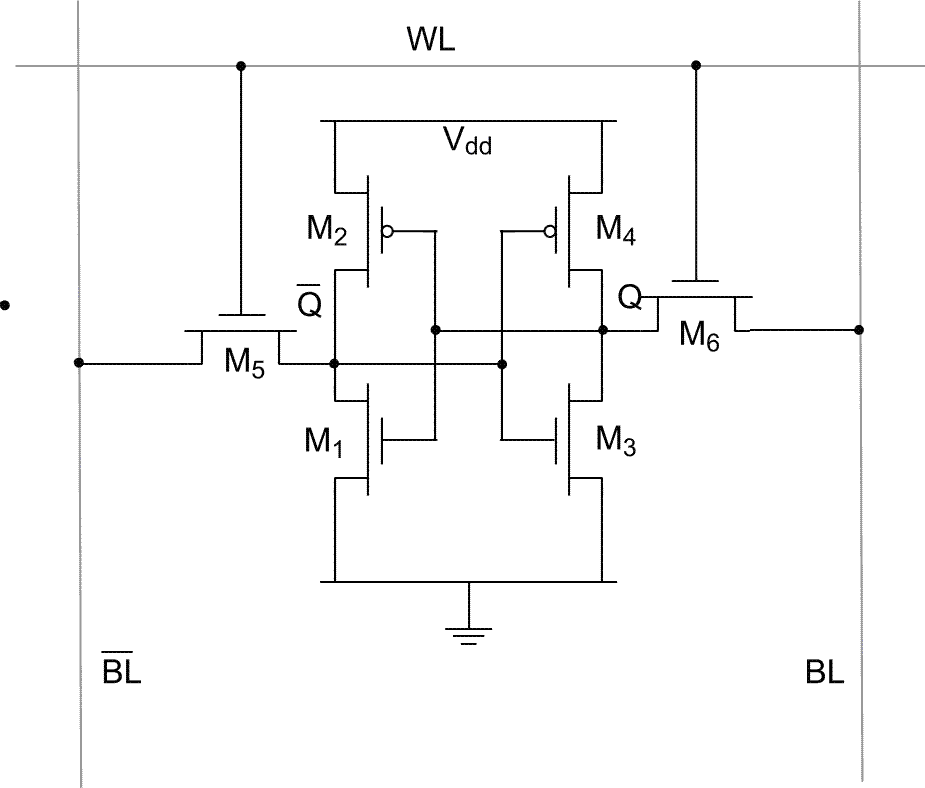
图4-1 6个MOS体管构成的SRAM cell 如图,传统的6-transistor SRAM cell中,M1和M2构成一个反相器(inverter)A,M3和M4构成一个反相器B。M5与A的输入、B的输出相连,而M6反之。这就构成了一个双稳态触发器,可以存储0或1两个状态。这就是SRAM的最小单元。
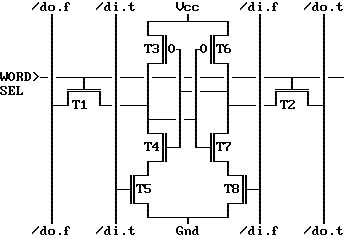
图4-2 8个MOS管构成的SRAM Cell 这是一张8-transistor的SRAM Cell线路图。它在经典的6-transistor SRAM unit的基础上增加了两个晶体管,实际上相当于用三态门替代6-transistor SRAM中的反相器。这样,虽然增加了两个晶体管,但由于可以通过关断T5和T8,将三态门设定为高阻状态,来降低功耗。这就是ATOM处理器采用8-transistor SRAM作为Cache的原因。 ATOM的L2 Cache与Core微结构大同小异,均为8路(8-way)512kB。高速缓存(cache)的way数量,是体现其灵活性的一个重要指标。它的一个极端为直接映射高速缓存(direct-mapped cache),简单地说,直接映射高速缓存的缓存行(cache-line),和内存地址直接是简单的线性映射关系。假设高速缓存大小为512kB,那么,地址为0×00000040到0x0000007F的一个cache line大小的内存区域,和0×00080040到0x0004007F的这段内存,会被映射到同一片cache。这样,如果反复轮流读写这两个区域的内存,那么每次读写都会发生高速缓存冲突,而造成缓存不命中(cache-line miss)。显然,这是很严重的一个缺点。这种设计的优点在于简单和低成本。在现代CPU中,采取这种cache设计的已经不多见了。 Cache设计的另一个极端为全相连高速缓存(fully-associative cache)。这种设计中,任何一个主存(RAM)地址都可以映射到任何一个高速缓存行,以最大程度上避免高速缓存冲突的产生。然而,其高高在上的成本和功耗让桌面处理器设计者望而却步。 我们知道,工程设计的一个特点,就是妥协和折中。组相联高速缓存(set associative cache)就是斡旋于Cache灵活性与成本之间的矛盾的一种设计思路。在这种设计中,内存中的一个地址可以映射到多个不同的Cacheline。比如,ATOM处理器提供的8-way的高速缓存,每个地址最多可以有8个Cacheline供选择。这样,大大减小了Cacheline冲突的可能性,又不会造成严重的成本上升。 | |
  (3个打分, 平均:3.00 / 5) (3个打分, 平均:3.00 / 5) |

雁过留声
“铁臂阿童木——Intel ATOM处理器剖析与研究 (5)”有11个回复
一聊到cache和硬件线路设计,咋都沉默了……
它的一个极端为直接映射高速缓存(direct-mapped cache),简单地说,直接映射高速缓存的缓存行(cache-line),和内存地址直接是简单的线性映射关系。假设高速缓存大小为512kB,那么,地址为0×00000040到0×0000007F的一个cache line大小的内存区域,和0×00080040到0×0004007F的这段内存,会被映射到同一片cache。
貌似不是这样的…您再查查书?
帅帅,写的很好。我不知道你的写作计划。希望在这个集子里,有一章是:Intel ATOM与ARM的比较。这样,视野就展开了。。。。。。
直接映射的理解错了。。。顾名思义。直接映射就是512KB,8K个cacheline直接映射到mem spcae。
直接映射只有教科书上解释原理的时候才会有了。直接映射也绝对不可能出现冲突,只是会引起严重的cache bounce。
“那么,地址为0×00000040到0×0000007F的一个cache line大小的内存区域,和0×00080040到0×0004007F的这段内存,会被映射到同一片cache。”
这种方式是很常见的组相联。。。具体怎么分组跟体系相关了。
至于全相联,不是成本和功耗的问题。是根本不可能设计出全相联的cache。几K个cacheline,仅仅检查cachehit估计比直接从内存取还慢了。现在用组相联也只能用PLRU算法置换。全相联意味着真LRU。同样,也仅仅存在于教科书中。
这个基本上是计算机课程,看不出跟atom有啥关系啊。。
“直接映射高速缓存的缓存行(cache-line),和内存地址直接是简单的线性映射关系。”
帅帅应该没犯低级错误。他的意思是对的。估计是表达具体例子时(0×40–0x7f.。。)的时候confusing ppl了。
当然,这篇文章从ATOM拽到谈cache的SET, Assoc稍微有点牵强。即使要谈,可以谈点hit rate,miss penatly的优缺点.
首席说的是。这个问题的表达上的确不清楚。
写cache是一件很麻烦的事情,如果简要概述太简单,而详细展开说又很难解。
ATOM和ARM的比较是一个很有趣的话题,but,ARM的vendor实在太多了……正好有朋友送了我一个ARM的开发板,可惜只有一个网口……
这样吧,与ARM Cortex-A8做一些比较吧。在处理器方面,切入一点,突破。。。
期待你的佳作。将会非常有价值。慢慢来。。。
它的一个极端为直接映射高速缓存(direct-mapped cache),……这样,如果反复轮流读写这两个区域的内存,那么每次读写都会发生高速缓存冲突,而造成缓存不命中(cache-line miss)。
您的结论没错, 但举的例子是全相联而不是直接映射.
正好我手头上有本书, 我又正好看到这一章…
这篇文章大多数是教科书电脑报试的陈述,关于atom的特性很少很少,受益不多。
同意,但还是值得鼓励。
最重要的一点没有点破。 ATOM的流水线是顺序执行的,与乱序执行相比功耗上要省很多。但对编译器的要求也很高,即指令级调度要做的很好以弥补顺序执行的缺陷。