




ARM芯片系列的微结构图
作者 陈怀临 | 2010-11-26 16:00 | 类型 芯片技术, 行业动感 | 1条用户评论 »
|
【陈怀临注:这里收集了ARM7,9,11和Cortex-A(8,9,15)和R,M的微结构图。希望有兴趣的读者喜欢。。。。通常而言,ARM9 Core是基于ARMV5TE指令集。Marvell的XScale也是ARMV5TE指令集的芯片。首席对XScale比较(或者说相当的)熟悉。。。ARM11是基于ARMV6指令集的;大致来说,Cortex-[A|R|M]都是基于ARMV7指令集的。A,R和M的意思就是ARMV7的Subset。A:Application;R:Realtime;M:Microcontroller。在基于ARM5,6,7结构的处理器核中,其中ARM7多是3级流水线;ARM9多是5级流水线;ARM11是8级流水线;Cortex-A8多达14级流水线。Cortex-A9回到了8级流行线。可见Pipeline是祸害呀。。。Cortex-A15似乎又上去了,多余20级流水线。。。】
| |
  (1个打分, 平均:4.00 / 5) (1个打分, 平均:4.00 / 5) |









ARM与x86:Eagle’s coming!
作者 陈怀临 | 2010-11-26 08:55 | 类型 弯曲推荐, 行业动感, 读者文摘 | 74条用户评论 »
系列目录 ARM与x86
【陈怀临注:通过读者推荐,看到了来自Intel的sailing关于ARM的系列文章。非常的优秀。现转载若干以飨读者。Eagle是ARM Cortex-A15的codename。是目前ARM阵容里最强悍的CPU,是A9的下一代。估计会在2012年有芯片。。。】 EAGLE is Coming!ARM的崛起使Intel陷入长考。 PC领域尚无需担忧,这个领域尚属Wintel帝国。帝国的成员历经过多次优胜劣汰,Wintel制定的多数策略都能得到这些成员的支持,更重要的是使他们最终受益。Intel从PC领域切走了最大的一块蛋糕,却是众望所归,这与Intel在这个领域的付出成正比。PC帝国偶尔出现的纰漏,总能够被Intel及时发现并加以修补。进入PC帝国的大门被Windows系统牢牢把持,ARM阵营虽多次试探,最终仍被拒之门外。 在手机领域,Intel还不是局中人。XScale架构之后,世上没有任何一款手机正在使用Intel制造的处理器。在这个领域,手机厂商,代工厂商,芯片提供商,操作系统提供商,相互交融,有合作也有竞争,尚未形成动态平衡。Nokia仍然暂居最大的手机市场份额,却在智能手机输给了Apple和Andriod。 Apple执着的封闭式系统在这个领域取得了意想不到的成功。Google的加入使得本已混乱的市场,变得更加难以琢磨。Microsoft在这个市场中屡战屡败依然不离不弃。2010年10月11日Microsoft正式发布了Windows Phone7[105],Google Android 2.3即将到来的谣言也在漫天飞舞。 乱哄哄你方唱罢我登场,却是处理器领域之外的故事。 在手机处理器领域,ARM是最大的收益者。无论是Nokia,Apple,HTC还是Motorola都在使用ARM处理器。Intel对这个市场垂涎三尺,也无可奈何。已经发布的Atom系列处理器,无论是Silverthorn(Atom Z5xx)系列,Diamondville(Atom N2xx,2XX和3XX),Pineview(Atom N4xx, D4xx和D5xx)距离手机领域都很遥远。 Intel近期发布的代号为Lincroft的Atom Z6xx系列处理器,却应者聊聊。基于这个内核的Moorestown平台,难显Intel昔日的振臂一呼。尚未有任何一个手机厂商宣布使用这个平台生产手机。正在业界似乎还在等待Intel即将在2011年推出的Medfield平台,这个平台将沿用Atom Z6xx内核,采用32nm工艺,进一步提高性能功耗比[107]。Intel却很难选择继续等待,因为Intel的后院再一次燃起了熊熊烈火。 借助ARM处理器,Apple的iPad已率先向Intel发难。这也标志着手机领域和PC领域融合的开始。融合的进度虽然缓慢,绝大多数参与者却已先知先觉。Intel选择在手机领域进行反击,经过一系列的合作与收购,进军手机领域一支的先头部队已悄然组建。 Intel的这一系列动作,不足以改变手机领域的格局,却足以使其震惊。这个领域的既得利益者很难接收这位巨人。Intel的能力不容置疑,胃口却太大了些。过小的手机上放满了运营商和生产厂商的Logo,实在无法再加入一个Intel inside。 Intel并不在乎这些阻力。在短时间内,Intel的Atom处理器依然无法在性能功耗比上压倒Cortex处理器,对于Intel这确实是一个长期而艰巨的任务。这一些并不值得担忧。性能功耗比这个词汇是ARM发明的,主要目的是为了掩盖ARM处理器当时过于低下的性能。 这个词汇无法阻碍Intel进军手机领域的步伐。Intel很清楚只要Atom处理器能够在功耗上满足手机领域的需求,就可以利用自身强大的Ecosystem逐步切入手机领域。加以时日增强对手机领域的理解,Intel完全可以在手机领域向ARM阵营发起强有力的挑战。 Cortex系列处理器的横空出世打乱了Intel的部署。Intel在最不应该失败,也最失败不起的性能上,莫名其妙地输给了ARM。从Cortex A9起,ARM处理器实现了对Atom内核性能上的反超[i],而Cortex A15完成了对Atom内核的全面超越。虽然目前尚未有基于Cortex A15内核的处理器,但这只是时间问题。 Intel的时间所剩无几。如果在Moorestown/Medfield平台上使用的处理器内核性能没有明显超过Cortex系列处理器。Intel近期的所有努力将付之东流。在今后两到三年左右的时间,Intel必须发布一个全新的Atom内核[ii],在性能上需要明显高于Cortex A15内核。Intel必须在本质上提高Atom内核的性能,这需要一个激进的变革,而不是渐变。Intel可以暂时依靠并不完美的Atom内核在商务上取得成功,但是商业与技术不会长久背离。Cortex系列处理器的出现敲响了Intel的警钟。 第一颗Cortex内核于2004年10月19日发布[108],这个内核并不是Cortex-A8,而是Cortex-M3。Cortex A8内核于2005年10月4日发布[109]。随后ARM在2006年5月15日发布了Cortex-R4内核[110]。至此Cortex内核完成了在嵌入式领域的布局。Cortex M,R和A内核都使用ARMv7的指令集,应用于嵌入式的不同领域。M内核[iii]应用在一些对成本较为敏感的微控制器领域,R内核主要应用在实时控制领域,而A内核用于手机与PC领域。 ARM11之后,ARM处理器内核不再以ARM作为前缀[iv]。ARM公司取消这个前缀完全是出于迷信的考虑[v]。在ARM的历史上,所有以偶数结尾的ARM内核,包括ARM2,6,8和10,都没有获得成功。ARM不想使用12,而13似乎更加糟糕,于是换了一个新名字。ARM这个单词并没有在Cortex系列中消失,Cortex的三大系列M-R-A,合起来就是ARM。 更换前缀后的内核,已焕然一新。Cortex A8内核的DMIPS指标达到了2.0DMIPS/MHz,相比ARM11取得了巨大的进步。Cortex A8处理器在大幅提高性能的同时依然保持了低功耗优势。一个含有32KB的指令和数据Cache,256KB的L2 Cache的Cortex A8,在使用600MHz的时钟频率时,总功耗仅为300mW。 Cortex A8内核不再使用简单的Enhanced DSP指令,而是引入了NEON部件。NEON的功能与Intel的SSE类似,用于支持SIMD类指令。Cortex A8是第一颗引入Superscaler技术的ARM处理器。在每个时钟内,Cortex A8可以并行发射两条指令[111]。出于降低功耗的考虑,Cortex A8内核依然使用了静态调度的流水线和顺序执行方式。 为了进一步提高时钟频率,Cortex A8内核使用了13级的整型指令流水线和10级NEON指令流水线,流水线级数高于ARM11内核的8级。流水线级数的增加有利于处理器主频的提高,却对指令分支预测的成功率提出了更高的要求。 Cortex A8在ARM11的基础上,将BTB使用的Entry数目从64增加到512,同时设置了GHB(Global History Buffer)和RS(Return Stack)部件。这些措施极大提高了指令分支预测的成功率,从ARM11的88%提高到Cortex A8的95%[112]。 Cortex A8在Cache的设计中,首次引入了Way-Prediction部件。在现代处理器中,Cache由多个Way组成,如8-way,16-way或者32-way。Way-Prediction部件的主要功能是预测当前Cache访问将使用哪个Way,从而可以暂时关闭不使用的Cache行,从而到达节电的目的。Intel从Pentium M处理器起使用了这种Cache访问方式,并一直应用到x86处理器的后续产品中。Atom处理器也可能使用了这种方式。 与ARM11相比,Cortex A8内核在Cache Memory系统上,进行了较大的优化。Cortex A8内核访问L1 Cache只需要一个时钟,而ARM11需要使用两个。Cortex A8支持L2 Cache,大小为128KB~1MB,ARM11虽然也支持L2 Cache,却几乎没有被SoC厂商使用。Cortex A8可以使用64位或者128位总线连接外部设备,而ARM11只能使用64位总线。 Cortex A8使用Architecture-Gating和Functional-Gating两种技术进一步降低功耗。所谓Architecture-Gating是指,处理器内核执行WFI(Wait for Interrutp)指令之后,将进入idle-loop模式。Cortex A8的Functional-Gating技术的本质是使用Clock-Gating,分离各个功能部件。当处理器运行运算时,与其不相关的功能部件,如Cache,指令队列,Write Buffer和NEON所使用的时钟可以临时关闭,以达到节电的目的。Clock-Gating技术的大规模使用使得Cortex A8内核获得了300mw/MHz的功耗频率比[111]。 在前45nm时代,Clock-Gating技术也已经在x86处理器上得到了广泛的使用,Cortex A8之所以获得了高于x86处理器的性能功耗比的重要原因,一是使用了更少的晶体管,二是因为没有象x86处理器那样去挑战处理器运算能力的极限。 在Cortex A8之后,ARM加快了处理器内核的更新速度,每3年就会推出一个A系列处理器内核。这个速度远低于Intel的Tick-Tock。而对于人数不满两千,同时要兼顾Cortex R和M系列内核升级的ARM,已经是一个不小的奇迹。 2007年10月3日,Cortex A9正式推出[113]。Cortex A9具有两个版本,一个是传统的单内核,另一个是MPCore,最高主频可达2.0GHz,最多支持4个内核。Cortex A9的整型运算的性能在Cortex A8的基础上提高了25%,达到了2.5DMIPS/MHz和2.9CM/MHz[43][114],恰好超过Atom处理器的2.4DMIPS/MHz和2.8CM/MHz[vi]。 Cortex A9采用了更高的成产工艺,整型流水线的级数虽然只有8级[vii],时钟频率却高于Cortex A8。在Cortex A9中,ARM引入了高端处理器常用的乱序执行(Out-of-Order)和猜测执行(Speculative Execution)机制,进一步扩大了L2 Cache的容量(128KB~8MB),可使用Snooping和Directory两种机制实现Cache的一致性。 与Cortex A8相同,Cortex A9依然使用MESI模型进行Cache的共享一致性,但是对MESI模型进行了许多优化,支持更多的Cache-to-Cache传送方式,进一步减少了处理器对主存储器的访问[114][115]。 这些更新极大地提高了Cortex A9的性能。从Cortex A9开始,ARM处理器正式完成了对Intel Atom内核性能上的超越,Cortex A9在性能上超越的不仅是Atom,还包括同时代用于嵌入式系统的处理器,如PowerPC和MIPS处理器[115]。ARM依靠性能功耗比的日子已一去不复还。但是Cortex A9距离Intel的主流处理器,Nehalem,Westmere和Sandy Bridge处理器依然有不小的差距。 ARM并没有停下脚步,2010年9月8日,代号为Eagle的Cortex A15正式发布[116]。对于Intel而言,狼外婆终于来了。Cortex A15内核并不是Cortex A9的继承者,事实上Cortex A9虽然与Cortex A8的功能较为相近,也不是完全的继承关系。 与Intel频繁更新处理器内核的策略并不相同,ARM的内核具有更长的生命期。1993年发布的ARM7内核仍然在被大规模使用。依次估计,Cortex A8,A9和A15这三颗内核所关注的领域虽然有所重复,这三颗内核仍将在相当长的一段时间里并存,深入到嵌入式应用的各类高端领域。 Cortex A15已经拥有足够的性能,具备进军了Laptop和Server领域的能力。在未来的3到5年里,Cortex A9和Cortex A15组成的ARM处理器阵营将与Intel的Atom,Sandy Bridge处理器展开全方位的较量。 Cortex A15最高主频将达到2.5GHz,最多可支持8个内核,采用Superscaler流水线技术,具有1TB的物理地址空间,支持虚拟化技术,乱序执行,寄存器重命名,并行设置了多个执行单元。几乎在现代高端处理器技术中涉及的技术都可以在这颗芯片中找到。 Cortex A15内核的性能将在Cortex A9的基础上继续提高50%。ARM公司尚未公开Cortex A15的功耗指标,但是可以预计在性能大幅提高的前提下,Cortex A15的功耗也必随之大幅提高。 首先是处理器主频的提高。Cortex A15使用了超长的24级流水线结构[viii],前12级用于指令预取,译码与分发,这部分指令流水是顺序执行的;后3~12级用于指令的执行,在这一阶段,指令可以乱序执行[117][118]。 超长的流水线结构利于处理器主频的提高,但是与Cortex A8相比,在使用相同的工艺时Cortex A15的主频仅仅提高了10%[117],以此推测Cortex A15使用的超长流水线,可能为了降低功耗。 Cortex A15另外40%的性能提高,需要流水线其他部件和Cache Memory系统的协调工作。Cortex A15必须极大增强分支指令的预测命中率。过长的流水线也意味着巨大的流水线中断惩罚。Cortex A15分支预测部件的工作原理与Cortex A8/9基本相同,只是将BTB的条目增加到了2K个,而且采用2-way组相连结构。 Cortex A15的GHB由Taken阵列,Not Taken阵列和Seletor阵列[ix]组成。Cortex A15对非直接跳转指令进行了一些优化,设置了256个Entry的BTB阵列,每一个Entry可以存放多个目标地址。除此之外Cortex A15还引入了64个Entry全互连结构的MicroBTB。Cortex A15的这些功能增强进一步提高了转移指令的命中率,但是与Nehalem处理器的分支预测单元相比仍有不小的差距[117]。 Cortex A15的流水线与Cortex A8的基本结构较为类似,由Fetch,Decode,Rename,Dispatch,Neon/VFP,Interger Issue和Load/Store Issue等部件组成,只是在Cortex A15中,指令需要更多的时钟节拍才能通过这些部件[117]。例如在Cortex A15中,Fetch单元由5级组成,Decode单元由3级组成[117]。 Cortex A15的指令预取总线的宽度为128b,一次可以预取4~8条指令,与Cortex A9相比,提高了一倍。Decode部件一次可以译码3条指令,而Cortex A9一次可以译码2条指令。 Cortex A15引入了Micro-Ops的概念。Micro-Ops指令与x86的μops指令表现形式不同,但是基本想法较为类似。在x86处理器中,指令译码单元将复杂的CISC指令转换为等长的μops指令,再进入指令流水线中运行;而在Cortex A15中,指令译码单元将RISC指令进一步细分为Micro-Ops,以充分利用指令流水线中的多个并发执行单元。Cortex A15的Decode部件在一个时钟节拍内可以同时译码3条指令,并将这3条指令转化为5个micro-ops[117]。 Cortex A15进一步扩大了Interger Issue部件的发射能力,从Cortex A9的3条提高到4条。Cortex A15分离了Cortex A9的Load/Store Issue部件,具有独立的Load和Store部件,并开始在流水线使用128位宽的数据总线。 Cortex A15还使用了32个Entry的Loop Buffer,当处理器执行一段较长的循环指令时,指令流水线将直接从Loop Buffer中获得Micro-Ops,而无需使用Fetch和Decode部件。此时这两个部件可以暂时关闭,以节约功耗。Intel也在Core 2架构中使用了相同的机制[119]。 从体系结构的角度上看,Cortex A15相对与ARM处理器自身而言是一次飞跃,但是与Intel的Nehalem/Sandy Bridge处理器相比,仍处于入门阶段。上文所提到的在Cortex A15中出现的技术,对于Nehalem处理器而言都是微不足道,更不用说是Sandy Bridge处理器。但是Cortex A8/9+Cortex A15依然可以凭借性能功耗比向Atom+Nehalem/Sandy Bridge处理器发起强有力的冲击。 制约x86处理器继续向前发展的主要原因有两个。一是Intel已经处于处理器体系结构的最前沿,每前进一步的代价过于巨大,Cortex A15虽然取得了巨大进步,但是仍处于高端处理器的入门阶段,仍有巨大的潜力。更重要的是,跟随者可以以更小的代价获得最新的技术。另外一个原因就是Intel的向前兼容策略,在某种程度上束缚了Intel前进的步伐。 ARM公司一再强调Cortex系列处理器的性能功耗比的优势,也在不自觉地掩饰ARM处理器相对较为简单的架构。从处理器体系结构本身出发,决定一个处理器功耗的最直接的要素依然是使用的晶体管数目。x86系列处理器功耗较高的主要原因是集成了较多的晶体管。在ARM处理器中使用的低功耗技术没有哪一个是独门绝技,这些技术也出现在x86系列的处理器中,包括Atom处理器。 从低功耗的设计理论上讲,一个处理器的功耗主要由动态功耗和静态功耗两部分组成。而对于CMOS电路,动态功耗主要由开关功耗和短路功耗两部分组成,公式描述如下。 Pdyn = (CL × Ptrans × Vdd2 × fclock) + (tsc × Vdd × Ipeak × fclock) [120] 其中CL指电路总负载电容,Ptrans指工作电路所占的比例,Vdd指工作电压,fclock指工作频率。而tsc指PMOS和NMOS同时打开的时间,在多数情况之下tsc的值较小,因此上述公司的后半段几乎可以忽略不计,因此Pdyn ≈ (CL × Ptrans × Vdd2 × fclock)。 其中CL参数由电路设计的复杂度决定,这也是x86处理器和ARM处理器目前功耗差距的最重要来源。Ptrans参数由处理器设计的电源管理策略决定,这也引出了另外一个低功耗设计的热点问题,处理器的低功耗设计更应侧重于在不同的场景之下,功耗的使用情况,而不应关注平均值。放之四海而皆准的电源管理最优策略并不存在,没有人能做到又让马儿跑,又让马儿不吃草。 Vdd参数的降低可以有效的降低功耗,近些年Vdd的值在不断下降,从5.0V,3.3V,2.5V到1.2V和0.8V。Vdd的不断下降,导致Vt[x]也随之降低,不断降低的Vt最终导致Isub[xi]呈指数上升,反而极大了增加了静态功耗,这个现象在45nm及以下工艺的设计中更为凸现。fclock更似一面双刃剑。频率的提升有利于性能的提高,却也极大提高了功耗。 从CL和Ptrans两个指标上分析,不难发现ARM在CL层面上做得更好,更简练的设计决定了ARM处理器的低功耗。而在Ptrans层面上分析,x86更胜一筹,x86处理器在ACPI规范中定义了一系列处理器状态,运比ARM处理器定义的状态复杂。x86处理器获得了较低的Ptrans值,但也无法掩盖因为较高的CL而获得的总功耗。 随着处理器制作工艺的不断前进,静态功耗所占的比例在不断地提高,这使得一些可以显著降低动态功耗,却提高了静态功耗的技术不再适用。静态功耗是指在晶体管处于上电状态时,晶体管的漏电流(Leakage)引发的功耗。漏电流主要由ISUB,IGATE,IGIDL和IREV组成。使用45nm工艺时的静态功耗是90nm工艺的6.5倍,使用32nm,22nm工艺时,静态功耗所占的比例呈指数上升[120]。 这些变化使低功耗的设计从降低动态功耗逐步转移到降低静态功耗上,在管理策略上从Clock Gating逐步转移到Power Gating。在Cortex A8处理器中,ARM将Clock Gating技术发挥到了极致,而由于缺乏工艺上的领先,在Power Gating领域上落后于Intel。从纯技术的角度上看,无论在降低动态功耗还是静态功耗的领域上看,Intel都是领先的。Intel在工艺上领先的事实,也在一定程度上说明了从门级电路的实现上看,天下半导体厂商的合力尚不足与之抗衡。 Intel却没能实现性能功耗比最优的处理器,这是技术之外的故事。在商业上,Intel一直坚持着向前兼容。多年以来Intel依靠向前兼容,战胜了一个又一个对手。向前兼容需要额外使用更多的晶体管数量,在服务器领域,因为保留向前兼容所浪费的晶体管并不是太大的问题,在手机领域却不容忽视。 Pentium Pro处理器大约使用了30%的晶体管数目处理x86向前兼容,包括Microcode ROM,指令译码和控制逻辑[121],而Pentium Pro处理器一共使用了5.5M个晶体管数目[36]。但是不要认为x86处理器在处理向前兼容时仅仅需要使用1.65M颗晶体管。因为除了进行指令变化(Instruction Transforming)这段逻辑之外,随着L1指令Cache的增加,向前兼容所付出的代价也在等比例上升。更重要的是由于乱序存储器访问模型的出现,向前兼容需要付出更大的代价。 Atom处理器在实现中使用了In-Order的流水线,并没有采用乱序执行的μops指令流水线,在很大程度上也在回避着因为向前兼容而带来的巨大惩罚[xii]。x86处理器继续背着向前兼容的大山,与针对性能功耗比进行了一轮又一轮优化的Cortex系列之间的竞争并不公平。 对Intel更不公平的是其长期坚持的通用平台战略。因为Intel的努力,PC处理器更加标准,更加通用,更加廉价。通用平台使得Intel获得了巨大的成功,却在一定程度上阻碍了Intel进军嵌入式领域。 嵌入式领域是一个备受Intel通用平台战略挤压的系统,通用处理器每进一步,嵌入式处理器便后退一步。嵌入式处理器在不断后退,不断细分的过程中,顽强地活了下来,更加根深蒂固地坚守了自己的阵地,回首却发现一直在前进的通用处理器x86,生活在最大孤岛中,被其包围得密不透风。这一次x86处理器需要从孤岛中游回彼岸,却无法使用ARM阵营的细分市场策略。 Intel和ARM两个公司本身并不具备可比性。Intel自1992年起,一直在半导体厂商中排名第一,而ARM公司从来没有进入过半导体厂商的排名,甚至可以说ARM并不是一个半导体厂商,因为ARM没有生产过一颗商用处理器。Intel一年的销售额是几十个Billion,而ARM仅为几百个Million。Intel有7,8万名员工,而ARM仅有1700余名员工。 虽然单独的ARM没有办法与Intel比较,但是ARM阵营所蕴含的能量却足以与Intel的x86阵营抗衡。在2009年排名TOP20的半导体厂商,除了Intel,AMD和Elpida之外,全部License了ARM内核。不仅如此ARM阵营还包括Apple,Microsoft和Google。诸多形态各异厂商的参与使ARM阵营更加立体化。 在x86处理器阵营中,AMD近期很少有声音[xiii],VIA在持续的亏损,真正努力的只剩下Intel。在Intel的Ecosystem中,除了Intel和提供基础BOIS的厂商外,其他的OEM/ODM并没有在处理器体系结构方面给予Intel必要的帮助。有些OEM厂商更像是依托在x86处理器之上的寄生虫。 严酷的外部环境使得Intel更加需要使用统一平台战略进入嵌入式市场,虽然这个策略与嵌入式系统要求的进一步定制,进一步细分的原则背道而驰。Intel不能在统一平台上有所动摇,目前以及在很远的将来,x86处理器阵营都无法向ARM处理器那样深入到嵌入式的每一个领域。多数嵌入式领域所提供的空间也无法容纳Intel这样的庞然大物。 Intel的目标非常明晰,就是进军手机处理器。虽然ARM处理器在手机领域处于垄断地位,在技术上Intel也并非没有任何机会。与ARM处理器相比,Intel的Atom处理器性能功耗比相对较为落后,但这并不是Intel在技术上的最大劣势。从整型运算的角度上看,Cortex A9略高与Atom处理器,而Atom处理器在Cache memory的表现更优。内核上的相比,两者各有千秋。 最使Intel尴尬的是,x86处理器并没有一个与AMBA总线类似的SoC平台总线,这是Intel进军嵌入式领域一个不小的障碍。Intel或者定义一条全新的SoC平台总线,或者集成AMBA总线。从加速推出产品的角度上,直接使用AMBA总线无疑是一条捷径。而世上没有捷径,从更长远的时间上看,借用AMBA总线,会使ARM阵营更加强大。最初的所谓捷径不过是为他人做的嫁衣裳。 Intel却很难有其他选择。在x86处理器系统中广泛应用的PCIe总线,不能使用在SoC内部。这条总线的设计目标是作为局部总线,连接片外的外部设备。PCIe总线可以提供巨大的带宽,也带来了较大的传送延时。更为重要的是与基于AMBA总线的外部设备相比,实现基于PCIe总线的外部设计需要更多的资源,也因此带来了巨大的功耗。 基于PCIe总线的低功耗设备,与基于AMBA总线的低功耗设备,在性能功耗比上没有可比性。AMBA总线是一个在SoC领域使用的事实上的标准。AMBA总线阵营的强大超乎多数人的想象。 AMBA总线V1.0于1995年正式发布[122],用于SoC内部各个模块间的互联,支持多个主设备,支持芯片级别测试。AMBA V1.0定义了两条总线,ASB(Advanced System Bus)和APB(Advanced Peripheral Bus)。V1.0还定义了一个连接存储器的外部接口,这个外部接口还可以用做测试。 ASB总线是一个快速总线接口,使用独立的地址数据总线,支持流水传送方式,支持多个主设备与从设备,采用集中译码和仲裁方式。ASB总线的主要作用是连接CPU,DMA引擎,内部存储器和一些快速外部设备。而APB总线连接一些慢速设备,APB是ASB的Secondary Bus,两者的关系如图4所示。 从今天的技术上看,AMBA V1.0总线十分简陋,设计这样的总线标准甚至可以作为几个研究生的毕业论文。而AMBA总线是一个开放标准,使用AMBA总线用户不需支付任何费用[123]。开放的总线标准使AMBA总线迅速普及的同时,极易吸收整个半导体业界的成果。 1999年AMBA总线更新到V2.0[124],增加了一个新的总线AHB(Advanced High-Performance Bus)。AHB取代了ASB在系统中的位置,并使ASB进一步下移,增加了Split传送方式进一步提高了存储器读的效率,总线宽度最高可达128位。 2001年,ARM发布了AMBA V3.0总线规范,引入ATB(Advacned Trace Bus)和AXI(Advanced eXtensible Interface)总线。AXI总线的引入,使得AMBA总线迈向新的台阶,性能已经可以与IBM的CoreConnect抗衡[126]。 AXI是一条现代总线。AXI总线分离了一个总线周期的地址阶段和数据阶段,更便于实现在现代总线中常用的Pipelining和Split技术。AXI总线进一步分离了总线通路,将AHB的单通路分解为Read Data,Read Address,Write Data,Write Address和Write Response共5个独立通路,进一步加速了对存储器的读写访问。 AXI总线接口逻辑设计较为复杂,与AHB总线相比多使用了50%的资源。AXI的一次总线周期至少需要传送64字节的数据,而AHB总线是16字节,这也导致AXI总线的传送延时高于AHB总线[125]。AXI总线的目标不是用于替换AHB总线,事实上在一个SoC中,AXI总线和AHB依然并存,只是AXI总线更接近ARM内核,而AHB总线更贴近外部设备。 AMBA总线阵营已经统治了整个嵌入式的平台总线,而且正在日益壮大。2010年3月8日,ARM正式推出AMBA V4.0总线,引入了QoS机制,进一步增强了多层结构,将AXI总线细分为AXI4,AXI-Lite和AXI-Stream[127]。 AMBA总线标准提供的AXI,AHB,ASB,APB和ATB总线,不仅使用在ARM处理器系统中,MIPS和PowerPC处理器也开始使用AMBA总线。除了嵌入处理器之外,TI,Freescale的DSP也在使用AMBA总线。AMBA总线已经无孔不入,在整个嵌入式领域,没有可以向其挑战的对手[xiv]。 面对ARM内核,Intel并不畏惧,面对AMBA总线阵营,Intel只能剩下无奈。可以预计在相当长的一段时间里,Intel无法推出一条能和AMBA总线抗衡的SoC平台总线。Intel只能暂时向AMBA总线示弱。Intel自身具有强大的图形处理芯片,却在Moorestown平台中不得已使用了PowerVR SGX 535[128][129]图形处理芯片。PowerVR SGX 535也是Apple A4,Samsung Hummingbird和TI的OMAP4处理器使用的图形处理芯片。 基于低功耗的考虑,Intel依然需要依赖ARM阵营提供的外部设备。而如果最终的结局是Atom处理器依赖AMBA外设战胜了Cortex内核,Atom处理器也会被ARM阵营重新绑架。对于多数厂商,通过简单的系统集成,快速推出市场需要的产品是第一位的,而这些厂商却无法获得更高利润。 ARM的廉价License策略实际上已经清楚地向Intel转告了一个事实,单纯依靠处理器内核无法在嵌入式领域取得暴利。而无法获取暴利的领域是不会有持续的资金注入。Intel并不会例外。 也许Intel一直等待Medfield平台的成熟。但是不要给予这个平台太多的期望。Medfield,这颗Intel有史以来第一个基于Atom处理器单芯片解决方案[130],如果仅是将Moorestown平台的Lincroft处理器和Langwell和二为一,前景并不光明。Medfield平台所提供的外设,很难与ARM平台的外设抗衡,最多只是打个平手。 在外部设备领域,ARM不是一个人在战斗,而是利用AMBA总线控制了整个半导体界。整个世界已有的用于手机的处理器平台都在使用基于AMBA总线的各类外设,而没有一个使用PCI/PCIe总线的外部设备。 Intel的Medfield平台可能的优势依然是在处理器内核上全面战胜Cortex A9和A15。而这一切对于Atom Z6xx内核来说几乎是一件不可能完成的任务。可以预见,Medfield平台诞生后,依然与基于Cortex A9内核的手机平台旗鼓相当。而对于后入者,仅靠旗鼓相当,很难获取太多的市场份额。 而在抛开技术之后,Intel所面临的处境更加艰难。Intel所主导的Wintel帝国统治IT世界已有多年,芸芸众生对Wintel帝国产生了严重的审美疲劳。Intel需要进入的手机领域,与其说被ARM把持,不如说被剩余的几乎所有半导体厂商把持。Intel动了ARM的奶酪也意味着动了全天下半导体厂商的奶酪。Intel的进军手机领域更像是一场大的赌博,没有人知道结局。可以肯定的是,Intel再放弃了XScale架构之后,不会轻易地放弃Atom架构。 也许Intel需要急迫解决的并不仅是技术问题。与许多巨型公司相似,在更多时候,最大障碍不在颛臾而在萧墙之内。与不到2000员工的ARM相比,来自Intel内部的故事复杂得多,也深刻得多。 多年以来,Intel在PC领域取得巨大成功的同时,也滋生了巨大的执拗。x86处理器之前取得的辉煌,使得改变成为Intel一个尽力回避的观念。Medfield平台的成功,对于Intel可能不是一件好事。也许Intel需要的是一场大的失败,因为使用失败统一内部意见往往比使用胜利容易得多。 2011年,Intel将发布Medfield平台。ARM阵营也许依然会战胜Medfield平台。这仅是决战的开始。永远不要低估Intel这颗巨人的心。 [i] 有关Atom处理器与Cortex A9的性能对比见ATOM的前生今世。 [iii] M内核实际上不是ARM内核,而是16位的Thumb 2内核。 [iv] 对我而言这是一件非常快乐的事情。从这时起,我再也不用写ARM公司的ARM7内核这样绕口的文字了。 [v] 没有找到ARM的官方说法,所以没有列出参考文献。这个说法很可能是网上的谣言。 [vi] 我更相信这是Cortex A9处理器的预谋。Cortex A9可以超过的更多,不过ARM选择将更多的风头留给Cortex A15。 [vii] 8级流水做到了2.0GHz,又是乱序,又是猜测访问,又是多发射,实在是佩服。 [viii] 使用了这么长的流水线,却不是为了提高主频,想必是基于降低功耗的考虑。应该有些独特的设计,目前尚无找到详细描述。Cortex A15的这种做法有别于x86。 [ix] 在多数处理器中,GHB具有4个状态Taken,Not Taken,Weekly Taken和Weekly Not Taken,Cortex A15将后两种状态合并。采用这种方法可以进一步减少晶体管数目,但其效果仍需观察,目前尚未找到采用这种方法的最终量化分析结果。 | |
 (4个打分, 平均:4.75 / 5) (4个打分, 平均:4.75 / 5) |

给力吧,x86(1)——11月10日测试记录
作者 老韩 | 2010-11-25 23:28 | 类型 互联网, 网络安全, 通讯产品 | 101条用户评论 »
|
系列内容:
测试环境 DUT:DIY的Panabit,其中
测试仪:Spirent Avalanche 2900 / IXIA 1600T
测试结果
Avalanche2900只有4个电口,自环后直接接在DUT的4个口上,配置不变直接打,得到100000的结果,验证为测试仪性能瓶颈。DUT的CLI下把拆链接Timeout时间置为0,测的90000左右稳定值,测试仪取样峰值90014。 瞎想
摘抄一句新闻稿:英特尔公司推出的六款英特尔® 凌动™ E600系列系统芯片(研发代号“Tunnel Creek”),能帮助客户轻松设计差异化定制产品,加快产品上市速度。今天,英特尔公司进一步发布了可配置的英特尔凌动处理器 E600C 系列,它将英特尔凌动E600 处理器和 Altera* 现场可编程逻辑门阵列(FPGA)融入了一个封装内。 关于这个E600C,以及传说中Intel倡导下,风河6Wind推出的基于x86的高性能网络软件基础架构,欢迎大家发表见解。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
(1个打分, 平均:5.00 / 5) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


工具箱
本文链接 |
|
打印此页 | 101条用户评论 »
ARM的演化–64位计算与高端服务器市场
作者 陈怀临 | 2010-11-25 23:15 | 类型 行业动感 | 15条用户评论 »
|
ARM的演化从1981年开始酝酿,从1985年4月25日的第一个ARM流片,ARM一路走来。没人能想到ARM的今天;ARM自己也没有想到自己的今天。系统是演化出来的;系统是长出来的。没人能在1985年设计出ARM的今天。目前ARM公司自己的演化主要是ARM7, ARM9, ARM11 and Cortex(A,R,M)。其中Cortex-A9的MP可以支持1-4个多核。在9月份,ARM也宣布了其Cortex-A15,与A9 MP类似,A15可以支持更大的cache和其他的一些MMU特性,和最重要的:硬件虚拟化技术;基于A15的芯片估计会在2012年才能有芯片。据说A15的性能可以比A8好5倍。。。下面是A15的微结构图一览: 这几天,媒体有透露出一个重大新闻–64bit的ARM芯片要出来了。而且据说已经流片出样品了!!! 这是个非常重要的事情。这其实意味这ARM要正式的进军服务器行业了!!! 相关的谣言新闻如下: Rumours hint at imminent ARM 64-bit processor 64bit计算对于大型数据库,数据处理等是非常重要的。这也是EM64T和CSI(现在的QPI)是Intel得以咸鱼翻身的重要技术环节。AMD没有牢牢抓住在64位的领先和HT互联的优越,确实令人可惜。。。。。。 | |
|
(1个打分, 平均:5.00 / 5) |


云计算背后的秘密(1)-MapReduce
作者 吴朱华 | 2010-11-25 22:32 | 类型 弯曲推荐, 行业动感 | 9条用户评论 »
系列目录 云计算的秘密之前在IT168上已经写了一些关于云计算误区的文章,虽然这些文章并不是非常技术,但是也非常希望它们能帮助大家理解云计算这一新浪潮,而在最近几天,IT168的唐蓉同学联系了我,希望我能将云计算背后的一些核心技术介绍给IT168的读者,虽然我本身已经忙于其它事务,但是由于云计算的核心技术是我最熟悉和最擅长,而且宣传这些技术也是我写《剖析云计算》一书和建立PeopleYun.com站点的初衷,所以我毫不犹豫地接受了这个邀请,这就是“云计算背后的秘密”这个系列的由来。 在这个新系列中将介绍多种云计算所涉及到的核心技术,包括分布式处理、分布式数据库、分布式锁、分布式文件系统、多租户架构和虚拟化等,而且将会介绍这些技术相关的产品和用例,以帮助大家进一步理解这些技术。预计每周会更新一篇,总长度会在10篇左右,希望大家能喜欢,而本文则是这个系列的第一篇。
在Google数据中心会有大规模数据需要处理,比如被网络爬虫(Web Crawler)抓取的大量网页等。由于这些数据很多都是PB级别,导致处理工作不得不尽可能的并行化,而Google为了解决这个问题,引入了MapReduce这个分布式处理框架。 技术概览MapReduce本身源自于函数式语言,主要通过”Map(映射)”和”Reduce(化简)”这两个步骤来并行处理大规模的数据集。首先,Map会先对由很多独立元素组成的逻辑列表中的每一个元素进行指定的操作,且原始列表不会被更改,会创建多个新的列表来保存Map的处理结果。也就意味着,Map操作是高度并行的。当Map工作完成之后,系统会接着对新生成的多个列表进行清理(Shuffle)和排序,之后,会这些新创建的列表进行Reduce操作,也就是对一个列表中的元素根据Key值进行适当的合并。下图为MapReduce的运行机制:
图1. MapReduce的运行机制 接下来,将根据上图来举一个MapReduce的例子来帮助大家理解:比如,通过搜索引擎的爬虫(Spider)将海量的Web页面从互联网中抓取到本地的分布式文件系统中,然后索引系统将会对存储在这个分布式文件系统中海量的Web页面进行平行的Map处理,生成多个Key为URL,Value为html页面的键值对(Key-Value Map),接着,系统会对这些刚生成的键值对进行Shuffle(清理),之后,系统会通过Reduce操作来根据相同的key值(也就是URL)合并这些键值对。 优劣点谈到MapReduce的优点,主要有两个方面:其一,通过MapReduce这个分布式处理框架,不仅能用于处理大规模数据,而且能将很多繁琐的细节隐藏起来,比如,自动并行化、负载均衡和灾备管理等,这样将极大地简化程序员的开发工作;其二,MapReduce的伸缩性非常好,也就是说,每增加一台服务器,其就能将差不多的计算能力接入到集群中,而过去的大多数分布式处理框架,在伸缩性方面都与MapReduce相差甚远。而 MapReduce最大的不足则在于,其不适应实时应用的需求,所以在Google最新的实时性很强的Caffeine搜索引擎中,MapReduce的主导地位已经被可用于实时处理Percolator系统所代替,其具体细节,将在本系列接下来的文章中进行介绍。 相关产品除了Google内部使用的MapReduce之外,还有,由Lucene之父Doug Cutting领衔的Yahoo团队开发,Apache管理的MapReduce的开源版本Hadoop,而且一经推出,就受到业界极大的欢迎,并且衍生出HDFS、ZooKeeper、Hbase、Hive和Pig等系列产品。 实际用例在实际的工作环境中,MapReduce这套分布式处理框架常用于分布式grep、分布式排序、Web访问日志分析、反向索引构建、文档聚类、机器学习、数据分析、基于统计的机器翻译和生成整个搜索引擎的索引等大规模数据处理工作,并且已经在很多国内知名的互联网公司内部得到极大地应用,比如百度和淘宝。 最后,如果大家对MapReduce感兴趣的话,可以到Hadoop的官方站点上下载并试用。
| |
|
(2个打分, 平均:4.00 / 5) |

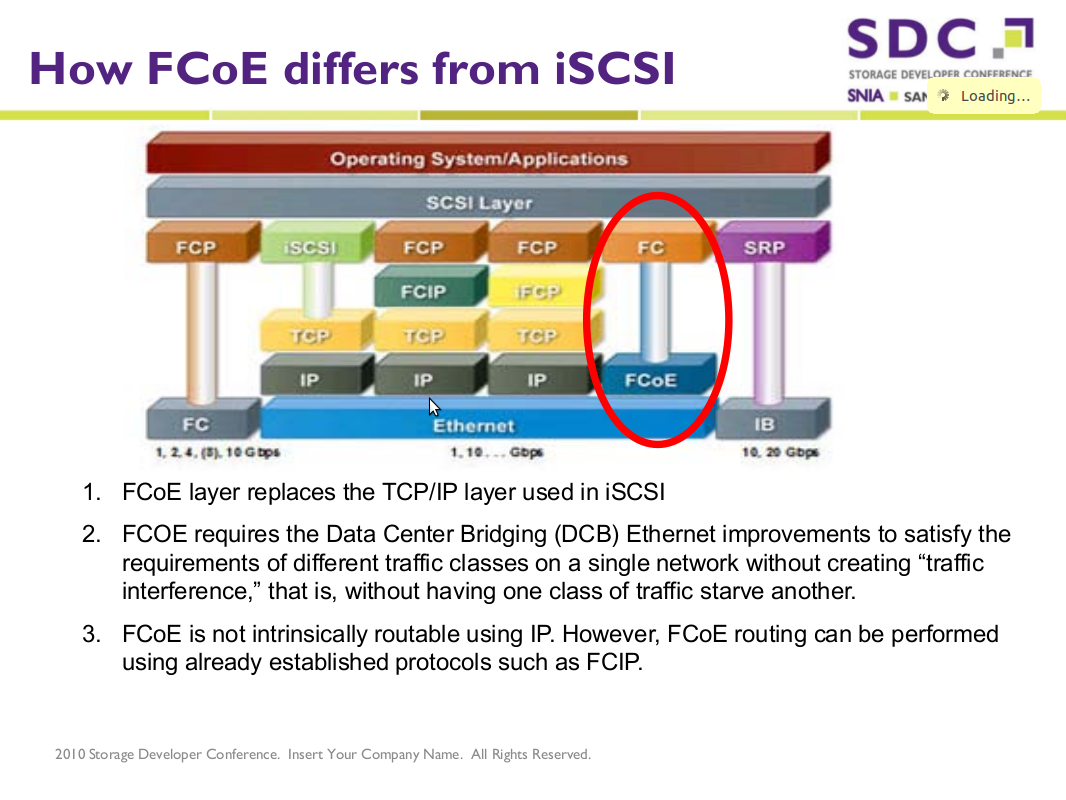
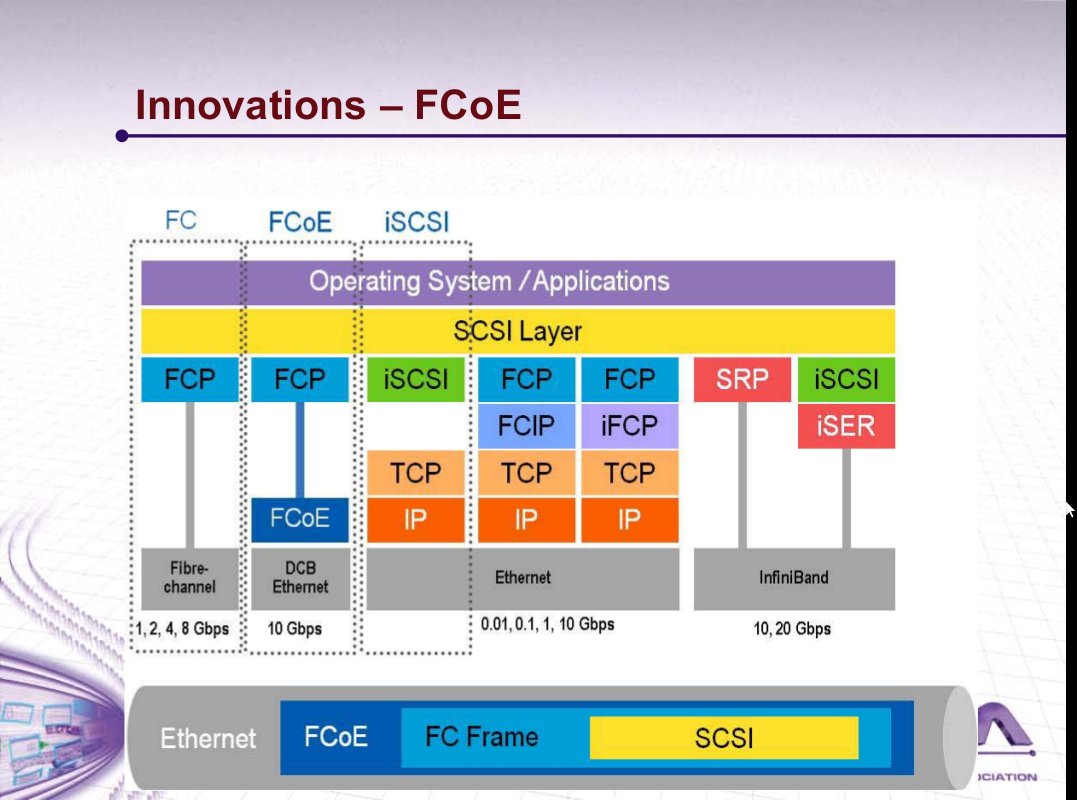
10Gbit 以太网 FCoE 与 iSCSI 之对决 (FCoE vs. iSCSI. vs ATAoE)
作者 Cheng | 2010-11-25 17:27 | 类型 行业动感 | 38条用户评论 »
|
SNIA SDC2010: 10Gbit 以太网 FCoE 与 iSCSI 之对决 (FCoE vs. iSCSI. vs ATAoE) 存储网络工业协会 (SNIA, 不是SINA) 组织的一年一度的 Storage Developer Conference 2010 会议今年九月份照例在硅谷 Santa Clara 召开,本文试图透过此会议之 presentation slides 对当前存储行业之热点问题分析一二: 首先面临的问题是如何取得这些 slides, 直接点击左侧 “2010 Presentations” 会到达登录页: http://www.snia.org/events/storage-developer2010/presentation 可能拦住了大部分访问者,不过这边有人去了现场,拿到了用户名和密码可以登录: ID: SDC2010_SantaClara 登录后你会发现其实是个小把戏:多一个 ‘s’, 单数变复数,并且这个URL也可以不经登录、直接访问的,只是未公开而已, http://www.snia.org/events/storage-developer2010/presentations (其实这几年SNIA的惯例都是如此,大家以后熟悉了可以自己猜出来,这也是包括 SNIA 在内各会议举办方的惯例:花了报名费到现场参加会议的人才能知晓某个特别URL或ID&Password之为特别途径去取得 slides, 要不然每年上千美元的报名费找谁收去。嘘——潜规则大家知晓就好,不要没事找事去通知SNIA的人、下一年改了规则就不好玩了) ========================= 正文 ========================= 关注近几年 SDC 会议材料 (上面URL中2010可以换成2009,2008,2007同样有效), 有几个传统话题:
新兴话题:
======================= 正文 FCoE ======================= 干货在我看来就只有 FCoE 了,这是个相对很新的协议,全名是 Fibre Channel over Ethernet, 直到2009年6月才有INCITS 的 T11组的 FC-BB-5规范,设计之意图就是运行在以太网之上的光纤存储协议; SDC2010上有 LSI 的 Distinguished Engineer 在同时测试两种HBA的过程中有一些总结:
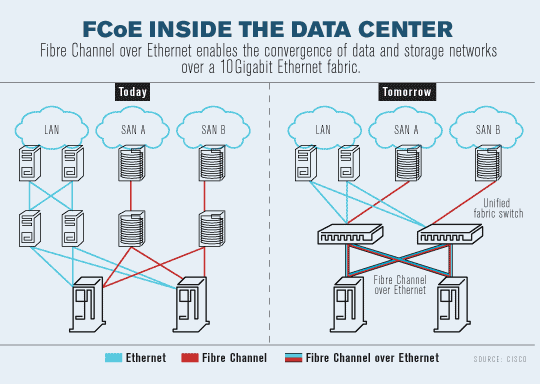
从部署方面说,早在2009年加州洛彬矶县给1千万居民的档案data-center考虑升级时就在考虑了FCoE,有了这张图: http://www.networkworld.com/supp/2009/ndc1/012609-fiber-channel-over-ethernet.html
这个领域目前是方兴未艾,就连许多名词都尚未达成业界共识:
另一篇 slides 在谈 FC updates 也提到了 FCoE 的一些详细协议细节,特别一点是上面提到 DCB Ethernet, 并不是普通的10Gbit Ethernet, 查了一下主要区别在于 PAUSE 信号, Priority Flow, Congestion Notification 等, 将 普通 10Gbit Ethernet 进一步打造成为 Lossless Ethernet, 上层的 FC 协议并没有 TCP 之类重传的智能;
更进一步可以看看 “Intro to FCoE by EMC” 视频; http://www.youtube.com/watch?v=EZWaOda8mVY iSCSI 已死? FCoE 当立?话说 iSCSI 协议进 RFC3720 还是2003年的事情,话犹在耳,但 FCoE 的概念自2005年出道以来,就不断有人预示了 iSCSI 的最终没落,且看评论: http://www.theregister.co.uk/2008/10/15/fcoe_io_kill_iscsi/ The Storage Architect 的观点认为 iSCSI 最终失败的原因有几个:
另外, iSCSI 虽有 TCP/IP 带来的路由能力,但在企业存储网几乎无用;FC界早有FCIP和iFCP尝试把FC运行在TCP/IP之上、失败告终。 The Storage Architect 的观点 既然 iSCSI 失败,那么 FCoE 将显然地成功。 http://virtualgeek.typepad.com/virtual_geek/2009/06/why-fcoe-why-not-just-nas-and-iscsi.html 再看 FCoE 背后的 Big Players, 今年 lisa10 中有个 slides 总结了一张如下:
插曲:提到以太网层面上的存储协议竞争,还不得不提及另一家小公司 Coraid 早在2004年就已实现的 相当轻量级的 ATA over Ethernet 协议, http://en.wikipedia.org/wiki/ATA_over_Ethernet 轻量级到了什么程度呢? 相比于 FCoE iSCSI 动辙上百页的描述文件,ATAoE 甚至只用了9页就描述完了。而且它甚至是无连接的,就不用说 iSCSI 的 Login/Session Phase 了,AoE 可以类比于 UDP 之 over IP, 而且 AoE 只放了14字节头在 Ethernet header 之上(于是共28字节)、等等;可惜小公司似乎不关注于此类大公司大市场所需要的合纵连横之术,找遍了互联网就只有一家 Coraid 在死守,甚至在 LinuxJournal Magazine 上每月都整版广告 “Professional ATAoE”, … 是啊,有谁能比你更专业于 AoE 呢。 国内依然是 IP-SAN (iSCSI) / NAS 市场的火热,只在今年SNW世界有思科有一人略讲了FCoE协议,其它仍停留在”大云存储”之类比较虚的概念层面。不过就国内相对滞后发展的特性而言,FC 的 dominant地位也许并不存在,一旦10Gbit普遍流行,依然可以在上面运行TCP/IP和iSCSI, 对应于上面LSI所做的 FCoE vs iSCSI 的测试;不知在硬件层面国内有没有厂商能做得出10Gbit以太网芯片、或是交换机芯片,可以比肩 Cisco Brocade ?; 但至少存储整机方案方面,不要再停留在 IET SCSI Target + Samba 就出一个 IP-SAN (iSCSI) / NAS 了,想想 FCoE, 是代替 iSCSI 翻牌的另一次良机。 | |
|
(3个打分, 平均:5.00 / 5) |

我为什么要离开哈佛–一个大学教授的故事
作者 陈怀临 | 2010-11-25 10:26 | 类型 行业动感 | 8条用户评论 »
|
Why I’m leaving Harvard Rather than let rumors spread about the reasons for my move, I think I should be pretty direct in explaining my thinking here. I should say first of all that I’m not leaving because of any problems with Harvard. On the contrary, I love Harvard, and will miss it a lot. The computer science faculty are absolutely top-notch, and the students are the best a professor could ever hope to work with. It is a fantastic environment, very supportive, and full of great people. They were crazy enough to give me tenure, and I feel no small pang of guilt for leaving now. I joined Harvard because it offered the opportunity to make a big impact on a great department at an important school, and I have no regrets about my decision to go there eight years ago. But my own priorities in life have changed, and I feel that it’s time to move on. There is one simple reason that I’m leaving academia: I simply love work I’m doing at Google. I get to hack all day, working on problems that are orders of magnitude larger and more interesting than I can work on at any university. That is really hard to beat, and is worth more to me than having “Prof.” in front of my name, or a big office, or even permanent employment. In many ways, working at Google is realizing the dream I’ve had of building big systems my entire career. As I’ve blogged about before, being a professor is not the job I thought it would be. There’s a lot of overhead involved, and (at least for me) getting funding is a lot harder than it should be. Also, it’s increasingly hard to do “big systems” work in an academic setting. Arguably the problems in industry are so much larger than what most academics can tackle. It would be nice if that would change, but you know the saying — if you can’t beat ‘em, join ‘em. The cynical view is that as an academic systems researcher, the very best possible outcome for your research is that someone at Google or Microsoft or Facebook reads one of your papers, gets inspired by it, and implements something like it internally. Chances are they will have to change your idea drastically to get it to actually work, and you’ll never hear about it. And of course the amount of overhead and red tape (grant proposals, teaching, committee work, etc.) you have to do apart from the interesting technical work severely limits your ability to actually get to that point. At Google, I have a much more direct route from idea to execution to impact. I can just sit down and write the code and deploy the system, on more machines than I will ever have access to at a university. I personally find this far more satisfying than the elaborate academic process. Of course, academic research is incredibly important, and forms the basis for much of what happens in industry. The question for me is simply which side of the innovation pipeline I want to work on. Academics have a lot of freedom, but this comes at the cost of high overhead and a longer path from idea to application. I really admire the academics who have had major impact outside of the ivory tower, like David Patterson at Berkeley. I also admire the professors who flourish in an academic setting, writing books, giving talks, mentoring students, sitting on government advisory boards, all that. I never found most of those things very satisfying, and all of that extra work only takes away from time spent building systems, which is what I really want to be doing. We’ll be moving to Seattle in the spring, where Google has a sizable office. (Why Seattle and not California? Mainly my wife also has a great job lined up there, but Seattle’s also a lot more affordable, and we can live in the city without a long commute to work.) I’m really excited about the move and the new opportunities. At the same time I’m sad about leaving my colleagues and family at Harvard. I owe them so much for their support and encouragement over the years. Hopefully they can understand my reasons for leaving and that this is the hardest thing I’ve ever had to do. | |
|
(2个打分, 平均:5.00 / 5) |
 【陈怀临注:这不是徐志摩的资产阶级小情调,在康桥腻腻歪歪。这是这几天发生的,
【陈怀临注:这不是徐志摩的资产阶级小情调,在康桥腻腻歪歪。这是这几天发生的,2010年第二批中关村高端领军人才公示公告
作者 陈怀临 | 2010-11-25 08:10 | 类型 行业动感 | 2条用户评论 »
|
按照《关于开展2010年第二批中关村高端领军人才评定的工作方案》部署,由中关村高聚工程工作小组办公室委托中关村企业家顾问委员会推荐评审委员会并负责评审工作。评审委员会现已评出21名“2010年度中关村高端领军人才”候选人(团队)。并由中关村高聚工程工作小组办公室直接推荐1名“2010年中关村高端领军人才–战略科学家”候选人,现定于11月16日至11月21日对王晓东、吕建光、范丽、朱立南等22人(团队)“2010年度中关村高端领军人才候选人”进行公示。 一、中关村高端领军人才-创业未来之星候选人10人(团队) 1、陈啸,男,1974年出生,2009年底创立北京网友聚众网络科技有限责任公司,并担任首席执行官。 2、宋中杰,男,1967年生,2010年9月,宋中杰发起成立北京今日都市信息技术有限公司并担任首席执行官。 3、唐朝晖,男,1969年出生,2007年3月注册成立北京艾德思奇科技有限公司并担任首席执行官。 4、赵国栋,男,1979年出生,2009年2月注册成立网银在线(北京)电子支付技术有限公司并担任首席执行官。 5、团队:程静,女,1976年生,2006年注册成立北京纽曼腾飞公司并担任公司总裁。 王洪锋,男,1974年出生,2006年注册成立北京纽曼腾飞公司并担任公司董事长。 6、吕建光,男,1952年出生, 2005年注册成立北京国智恒电力管理科技有限公司担任公司董事长及总裁。 7、团队:杜国楹,1973年出生,2009年7月创立北京壹人壹本信息科技有限公司并担任公司董事长。 蒋宇飞,1973年出生,2009年7月成立北京壹人壹本信息科技有限公司并担任公司总裁。 8、李纪阳,男,1963年出生, 2007年6月注册成立北京海瑞祥天生物科技有限公司并担任公司董事长及总裁。 9、何为无,男,1965年生, 2006年8月成立北京傲锐东源生物科技有限公司并担任公司总裁。 10、刘治平,男,1958年出生, 2008年7月成立北京九州泰康生物科技有限责任公司并担任公司董事长。 二、中关村高端领军人才-科技创新人才:(5人) 11、杨士宁,男,1959年出生,于2010年加入中芯国际集成电路(制造)有限公司,现任中芯国际总公司首席运营官兼首席技术官。 12、吴以岭,男,1949年出生,1999年成立河北以岭医药集团有限公司任董事长,于2008年任北京以岭药业有限公司任首席科学家至今。 13、范丽,女,1973年出生,2010年9月加入百度中国,现任百度中国高级技术总监。 14、周骅,男,1958年出生,2009年2月任国家作物分子设计工程技术研究中心执行主任,北京凯拓迪恩(未名凯拓与杜邦的合资公 司)生物技术研发中心有限责任公司总经理,北京未名凯拓农业生物技术有限公司代总经理、执行董事至今。 15、易爱民,男,1966年出生,2010年加入软通动力现任软通动力信息技术(集团)有限公司副总裁。 三、中关村高端领军人才-风险投资家:(6人) 16、朱立南,男,1962年生, 2001年4月至今任联想控股有限公司常务副总裁、联想投资有限公司总裁。 17、张颖,男,1973年生,2008年1月至今任经纬创投中国基金创始管理合伙人。 18、邝子平,男,1963年生,2006年1月至今任启明创投创始人,董事总经理(中国)。 19、伍伸俊,男,1968年生,2004年12月至今任金沙江创业投资基金创始人及董事总经理。 20、崔健,男,1970年生,2008年1月至今,担任领航资本(中国)管理合伙人兼董事总经理。 21、曾之杰,男,1968年生,2008年5月至今任开信创业投资管理有限公司总经理兼管理合伙人。 四、中关村高端领军人才–战略科学家(1人) 22、王晓东,男,1963年出生,美国科学院院士,2009年全职回国担任中关村生命科学研究所所长、资深研究员。 联系人:中关村管委会人才资源处 王 健 颜 梅 联系电话: 82691716 82690613 中关村高聚工程工作小组 二〇一〇年十一月十六日 | |
|
(没有打分) |
“青年千人计划”引进工作
作者 ss201009 | 2010-11-25 08:00 | 类型 千人计划 | Comments Off
|
根据有关文件,中央将在近期启动青年海外高层次人才引进计划工作(简称“青年千人计划”),各有关单位要高度重视“青年千人计划”引进工作,积极物色青年海外高层次人才,提前做好准备工作,现就申报“青年海外高层次人才引进计划”预通知如下: 来源站:千人计划 一、“青年千人计划”引进对象和条件 1、属自然科学或工程技术领域,年龄不超过40周岁; 2、在海外知名高校取得博士学位,并有3年以上的海外科研工作经历; 3、申报时在海外知名高校、科研机构或知名企业研发机构有正式教学或科研职位; 4、引进后全职回国工作; 5、为所从事科研领域同龄人中的拔尖人才,有成为该领域学术或技术带头人的发展潜力;对博士在读期间已取得突出研究成果的应届毕业生,或其他有突出成绩的,可以破格引进。 二、中央财政给予“青年千人计划”支持措施 1、引进人才每人人民币50万元的一次性补助; 2、根据拟引进人才所在学科领域、能力水平等差异,科研经费补助标准(100-300万元/名),一次核定,按进度拨款。 三、其他 1、鼓励将引进人才作为院士、“千人计划”入选者等学术带头人领衔的科技创新团队成员进行申报。 2、具体的申报、评审程序待进一步通知。 引文地址:http://www.1000plan.org/bbs/viewthread.php?tid=1835&extra=page%3D1 | |
|
(没有打分) |
操作系统界的又一个Over–Novell出售
作者 陈怀临 | 2010-11-23 21:22 | 类型 行业动感 | 46条用户评论 »
|
曾几何时,Novell如日中天。是微软的主要竞争对手。Netware时代,懂IPX/SPX就是网络的代名词。没人懂TCP/IP,也似乎没人关心。之后的N年,双方官司不断。。。但在2006年,双方又互相合作。为此,Novell还害怕Open Source界对其“背叛”开源,而写出了与微软的公开解释信。 在(无耻的)SCO声称其拥有UNIX版权,矛头还直接指向Linux Kernel,并狮子大开口的要包括IBM等在内的N家公司付出美金的时候,Novell倒是站在了正义的一方。。。其的支持直接导致了SCO的败诉,并从此声名藉。。。。。。详情可参阅:http://en.wikipedia.org/wiki/SCO_v._IBM http://en.wikipedia.org/wiki/SCO-Linux_controversies Novell的现在,其最重要的部分其实是2003年收购的SUSE操作系统。SUSE在服务器市场的地方是非常深厚的。。。从这次收购的结果来看,SUSE会接着独立运行。“On November 22, 2010, Novell announced that it had agreed to be aquired by Attachmate for $2.2 billion. Attachmate plans to operate Novell as two units, SUSE becoming a stand-alone business and anticipates no change to the relationship between the SUSE business and the openSUSE project as a result of this transaction.” 今天另外一个人一定会失眠–他就是现在Google的CEO Eric Schmidt。Eric曾在1997-2001年出任Novell的CEO。Eric是2001年3月加入Google的董事会,并在8月正式出任Google的CEO的。在Novell被微软整趴下了,在Google从新做。。。并成就大业! | |
|
(6个打分, 平均:4.67 / 5) |
 “11月23日下午消息,
“11月23日下午消息,