




说说SIEM与SOC
作者 tom | 2011-01-21 22:50 | 类型 行业动感 | 17条用户评论 »
|
缘起:看到弯曲中有审计和SOC的文章,正好自己做了一段时间,有点心得,希望得到诸位高手的指教。 | |
  (3个打分, 平均:4.00 / 5) (3个打分, 平均:4.00 / 5) |
Intel CEO正在阅读的文章。。。
作者 coder | 2011-01-20 18:18 | 类型 弯曲推荐, 行业动感 | 21条用户评论 »
|
Looking Back on the Language and Hardware Revolutions: Measured Power, Performance, and Scaling 点击这里下载 阅读 final-asplos021 Abstract: This paper reports and analyzes measured chip power and perfor-mance on five process technology generations executing 61 diversebenchmarks with a rigorous methodology. We measure representa-tive Intel IA32 processors with technologies ranging from 130nmto 32nm while they execute sequential and parallel benchmarkswritten in native and managed languages. During this period, hard-ware and software changed substantially: (1) hardware vendors de-livered chip multiprocessors instead of uniprocessors, and indepen-dently (2) software developers increasingly chose managed lan-guages instead of native languages. This quantitative data revealsthe extent of some known and previously unobserved hardware andsoftware trends. Two themes emerge. (I) Workload: The power, performance,and energy trends of native workloads do not approximate managedworkloads. For example, (a) the SPEC CPU2006 native benchmarkson the i7 (45) and i5 (32) draw significantly less power than managedor scalable native benchmarks; and (b) managed runtimes exploitparallelism even when running single-threaded applications. Theresults recommend architects always include native and managedworkloads to design and evaluate energy efficient designs. (II) Ar-chitecture: Clock scaling, microarchitecture, simultaneous multi-threading, and chip multiprocessors each elicit a huge variety ofprocessor power, performance, and energy responses. This varietyand the difficulty of obtaining power measurements recommendsexposing on-chip power meters and when possible structure spe-cific power meters for cores, caches, and other structures. Just ashardware event counters provide a quantitative grounding for per-formance innovations, power meters are necessary for optimizingenergy. 很高兴有一篇paper进到了ASPLOS (ASPLOS 是Architecture, programming language, operating system 结合领域的最好会议)。虽然我是Co-author,但也从这个paper里边学到了很多东西。这篇paper其实是我们去年在ISCA一个workshop上发的一篇论文的后续工作(H. Esmaeilzadeh, S. M. Blackburn, X. Yang, and K. S. McKinley, “Power and Performance of Native and Java Benchmarks on 130nm to 32nm Process Technologies,” in Sixth Annual Workshop on Modeling, Benchmarking and Simulation, MoBS 2010, Saint-Malo, France, 2010 http://users.cecs.anu.edu.au/~steveb/downloads/pdf/javavc-mobs-2010.pdf) 目前我在ANU读Master. 我自己的research领域是内存管理,大概想法就是在Run-time (JVM) 层面,把application的语义带进系统。一些paper在review过程,最后结果出来后我会在这写总结。 功耗是我RA部分的工作。 这两篇文章最开始的时候挺好玩。我记得最早的时候是 Hadi (这个系列文章的一作) 有一篇讨论 Dark silicon 的文章,然后我们开会一起讨论。在文章里边有一些是基于TDP或者模型的功耗计算, 我觉得基于模型的完全没有意义,建议测量真正的功耗。Hadi的文章里边讨论了power density 随着工艺变化对系统的影响。 印象中我在 linux symposium 看过一篇测量CPU功耗的文章。然后检查ATX的specification, 主板上4个pin的口是给CPU专门供电的,这样我们只需要一个电流计就可以测量CPU的功耗了。我当时奇怪的是为什么在学术界用类似的方法去测量功耗的很少,大部分是无意义的模型。再加上我们实验室正好有一些不同工艺和不同微结构的PC机。同时老板们是 managed language领域的专家。 那去从功耗的角度,不同工艺不同微结构对native language 写的 benchmark 和 managed language 写的 benchmark 的影响显然是我们关心的一个问题。然后就开始了漫漫测量路。 这是一篇测量文章,或者说是一个抛砖引玉的文章。所有的数据大家都可以访问,每个人的背景不同,看到的和想到的也不同。在ASPLOS review的过程中,有的reviewer 给了非常高的分数,但也得到了非常低的分数。文章接受以后,量化的两位作者对这个论文非常感兴趣,他们也给了我们很多很好的建议。 Dave 让他的一个学生用 data mining 的办法去评估体系结构不同的变化对系统的影响 (Mining火啊,看看Zhou Yuanyuan的文章)。 John 则对 SMT 的 power efficiency 非常感兴趣。 其他成员在和 两位牛人讨论的时候我正好在国内,非常遗憾的错过了这个机会。不过从邮件里边还是看到了两个大牛的风采,思路非常清晰。很多公司也对这个paper很感兴趣。IBM 和 Intel 都很喜欢并且邀请老板去讲了一下。我其实很不解的是难道Intel 或者 IBM 内部没有做过这样的分析? 我想再强调一遍,这是一个抛砖引玉的文章。借用文章里边的一句话 Measurement is key to understanding and optimization. 我总结一下这篇文章我个人的一些想法: *这个论文讨论的是硬件的变化。但是如果把硬件的变化当成一个镜子。镜子里边就是软件的行为。可以说软件对CPU资源的利用是非常非常差的。这个里边充满了机会。比如说double cache, 性能基本没什么变化。 Yale Patt, 曾经说“CPU厂家实在不好意思再加大cache了”。 其实这句话反过来就是 “你们作软件的怎么这么垃圾!!“。 但是这里边机会多多!!! *Managed language workload 的重要性。他们一般都有一个run-time system 作 Jit, 内存管理,和 其他的一些管理工作。 即便是single thread 的 managed language applications 也能够在多核下得到加速。同时 run-time system 对功耗,性能的影响非常大。CPU厂家应该重视起来这部分。目前就小道消息,硬件厂商内部貌似队这些理解不是很深刻。 *软件对功耗的影响非常大。比如同样的Java application, 不同的 JVM,跑出来的 performance, power, energy 差距非常大。目前CPU还没有一个类似performance counter 的东西帮助软件优化。 *对功耗决定性作用的其实是工艺。但是把成本考虑进来以后就不好说了。 *Energy efficiency 的 SMT。 ARM 貌似调侃过 P4年代的 SMT。 但是我们的结果显示从 energy & power efficiency 角度, SMT 是非常好的。这也许是 Intel 把 SMT 又高回来的原因。当然,想在 SMT 下边获得非常好的性能还是需要考虑很多 resource contention 的问题。 *强大的 Tick-Tock. Tock的时候尝试新的微结构,利用尽可能多的transistor,性能, power都上去 然后 Tick 的时候 die shrinking,功耗会下来,成品率会上去,可以提高频率。 这个基本就跟一个战车一样。 你说ARM能来 高端市场和 intel 打拼一下? 我看现在根本没有机会。 *引入多核的一个重要的原因是功耗。 打个比方,同样推高一个core frequency 20%, 不如两个Core 同时推高5%。这是其实是不得不走多核的一个非常重要的原因。 有兴趣的读着可以下载数据自己分析。 严重感谢首席,没有您多年来的指导和鼓励,我根本不可能懂 architecture, operating system, compiler! 感谢CLF上边前辈门留下的只言片语。比如首席当年没提过L4, V总当年没提过RTEMS,我本科的毕业设计也不会去作 RTEMS ON L4。
| |
 (6个打分, 平均:4.33 / 5) (6个打分, 平均:4.33 / 5) |
Patterns in network system design (8)
作者 kernelchina | 2011-01-19 15:04 | 类型 行业动感 | 7条用户评论 »
一代硅谷创业者的两世人生。。。
作者 陈怀临 | 2011-01-18 23:02 | 类型 行业动感 | 51条用户评论 »
|
[陈怀临注:原文来自:《创业家》2010年12月刊。感觉内幕消息确实不少。该知道的不该知道的;该写的不该写的;都写了。] 二十年前,一批大陆留学生在硅谷相继创办了自己的上市公司。十年前,他们回到中国开始以投资为主的第二人生。两世人生,哪一个是他们的顶峰?他们还会有第三次辉煌吗? | |
|
(13个打分, 平均:5.00 / 5) |
重大新闻:陈首席第一代弟子的一篇文章
作者 陈怀临 | 2011-01-18 21:58 | 类型 行业动感 | 43条用户评论 »
|
重大新闻,刚刚获悉,陈首席第一代弟子的一篇文章(co-author)被体系结构红宝书的两位大师亲自(请注意,是亲自)推荐给了Intel的CEO Paul Otellini!当然不知道Paul的人请飘过! 这个弟子是我长期以来培养的,隐藏在学术界的一把利剑!是目前除了Panabit(大弟子,更关注与工程和系统实现方面)中最得意的弟子之一。 这个弟子天天就在这里灌水! 文章还没有最后finalized。该弟子会在ready之后发文。 首席我在前天其实已经得到该文章! 我非常兴奋和自豪! | |
|
(3个打分, 平均:3.67 / 5) |
Patterns in network system design (7)
作者 kernelchina | 2011-01-18 19:51 | 类型 行业动感 | 19条用户评论 »
系列目录 网络系统设计模型概论
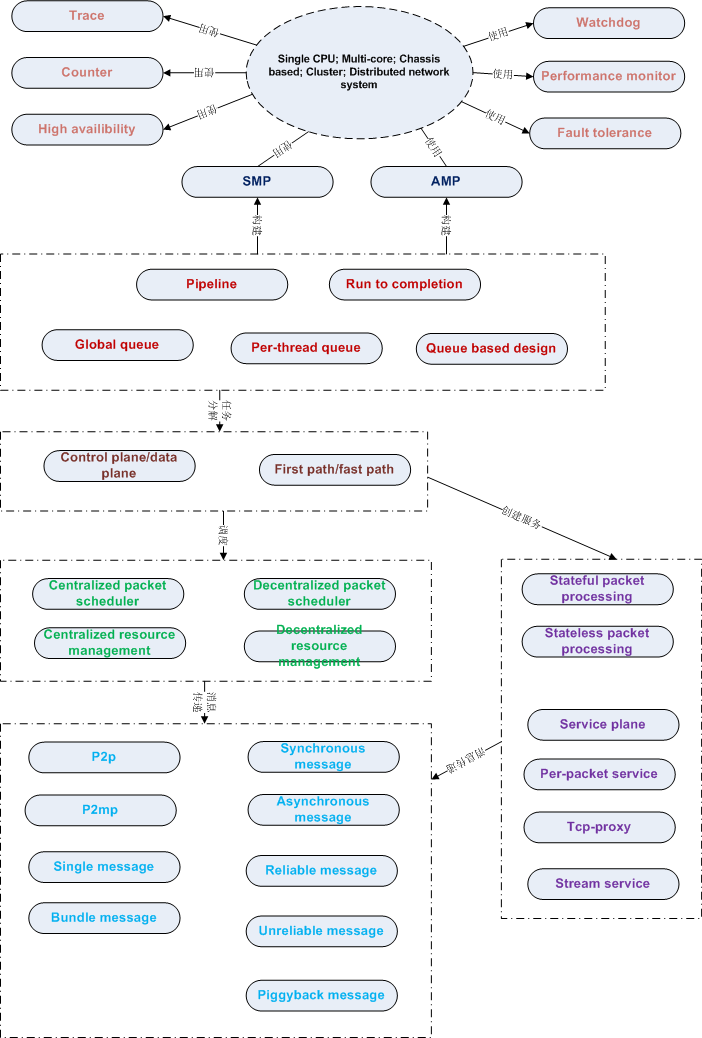
29) Trace Pattern Name and Classification: Trace 在系统出问题的时候,如何有效的跟踪定位问题?答案就是有效的Trace系统。这里所说的Trace和通常在Debug image里加的Debug信息是不一样的,在Debug image里面的Debug信息,在Releaseimage通常会通过开关去掉;而这里所说的Trace是指在Release image里面所包含的Trace。包括对关键路径和出错路径的记录。这里的Trace正常情况下应该是关闭的,但是可以通过开关来打开。有了这样的工具,定位错误就会方便很多。 系统出错并不可怕,可怕的是不能快速定位并解决问题。所以系统一般都会包含一个Trace系统,也会包含一个在系统崩溃情况下,保存寄存器,调用栈,内存等内容的工具。这些是集成在Release image里面的,出错的时候可以帮助定位问题。 Trace并不是越多就越好,最好是能够理清楚系统有多少个调用路径。一般来说,data plane的调用路径都不会太复杂,应该还是可以理清楚。Trace太多了,反而找不到有用的信息;太少了,又得不到有用的信息。由于Trace是在Release image里面,太多了也会影响系统性能。所以最好是对每一个Trace都经过Review才加进来,尽量避免多加或者少加。 1: http://en.wikipedia.org/wiki/DTrace 2: http://en.wikipedia.org/wiki/SystemTap 30) Counter Pattern Name and Classification: Counter Known Uses: network system 1: www.cc.gatech.edu/~jx/8803DS08/counter.pdf 2: http://www.cc.gatech.edu/classes/AY2010/cs7260_spring/plentycounter-ancs2009-slides.pdf 31) Performance monitor Pattern Name and Classification: Performance monitor 在产品的生命周期里面,维持或者提高系统性能是很重要的一个工作。黒盒测试可以了解系统的性能变化趋势,但是不能告诉开发者系统性能为什么发生变化。这个时候,就需要集成的performance monitor来跟踪系统性能变化。performance monitor应该只针对主要路径,主要函数。因为performance monitor本身会耗费一定的时间。如何把performance monitor集成到release image并使得performance monitor对系统性能的影响最小,需要仔细设计。performance monitor有时也可以帮助开发者了解系统的热点,这样有助于性能优化。 1: OProfile – A System Profiler for Linux 2: Smashing performance with OProfile 32) High availibility Pattern Name and Classification: High availibility High availibility是系统设计必须面对的问题。所谓的high availibility,就是那些99.9%, 99.99%, 99.999%,99.9999%。没有100%可靠的系统,除非系统不用,或者只用一次,用过之后就不再用了,否则的话100%是没法测试的。在电信领域,一般都用一年宕机多长时间来衡量系统的可靠性。如何保证系统的可靠性哪?最直接的就是系统冗余,不管是硬件还是软件,提供冗余。冗余包括某些部件的冗余,也包括整个系统的冗余;有双机的冗余,也有多机的冗余。 引入High availibility的概念后,很多软件设计就需要做相应的变化,比如说配置同步,状态同步,NSR,ISSU等。虽然系统本身是冗余的,但呈现给用户的还是单一系统,这就是high availibility所面临的难题,用户不需要了解,也不能感知切换,为了这个目标,需要做很多工作。 1: http://en.wikipedia.org/wiki/High_availability 2: http://en.wikipedia.org/wiki/High-availability_cluster 33) Fault tolerance Pattern Name and Classification: fault tolerance Fault tolerance与high availibility不同。简单地说,fault tolerance是high availibility的基础,但是faulttolerance并不能保证high availibility,是必要条件,而不是充要条件。Fault tolerance有很多方面,最简单的,系统要能处理收到的任何包,这里的处理也包括丢弃。畸形包是最常见的攻击之一,如果不能正确处理,就会导致系统崩溃,或者系统的功能错误。 Be conservative in what you do,
be liberal in what you accept from others.
(http://graphcomp.com/info/rfc/rfc1812.html) 避免崩溃是一方面,系统的功能正确才是最终目的,任何异常处理都不能损害系统的功能,否则就是在功能定义阶段没有把功能定义清楚。 1: http://en.wikipedia.org/wiki/Fault-tolerant_design 2: http://en.wikipedia.org/wiki/Fault-tolerant_system 34) Watchdog Pattern Name and Classification: watchdog 一般来说,网络系统是实时系统,任何一个任务,都应在规定的时间内结束,否则就是系统错误。所以需要watchdog来监控每个任务。watchdog还可以帮助开发者发现系统中的死锁,过长的循环,任务分配不合理等问题。如果某一任务执行时间过长,它就会阻塞其他任务,如果所有的CPU都被这类任务占用了,系统就无法相应事件,也有可能无法将这些任务调度出去。 有些需要定时执行的任务,比如HA里面的heartbeat,IPsec里面的DPD等,与watchdog类似,用途也差不多。 有些公司拿watchdog来复位整个系统,当然这个watchdog的粒度就比较大了,和前面说的watchdog不一样。在某些情况下(比如无法定位的错误),必须重启机器才能使系统正常工作,这个办法还是可以用一用的,当然这是最后的选择,不要轻易使用。 | |
|
(没有打分) |
Nehalem的遗憾——英特尔Sandy Bridge处理器分析测试之一
作者 Lucifer | 2011-01-18 11:22 | 类型 专题分析, 弯曲推荐, 芯片技术 | 21条用户评论 »
系列目录 英特尔Sandy Bridge处理器分析测试
原文发布于《计算机世界》2011年第3期
Nehalem 的遗憾 ——英特尔Sandy Bridge 处理器分析测试之一 计算机世界实验室 盘骏 英特尔的“Tick-Tock” 战略已经为人熟知,根据这个策略,英特尔每年都会交替在处理器的制程和微架构上进行更新。上一年,英特尔将处理器工艺从45nm 提升到了32nm,今年,英特尔将处理器架构从Nehalem 升级到最新一代的Sandy Bridge,这个早期被叫做Gesher(希伯来文:桥梁)的处理器微架构担任着特别的桥梁角色。 Bridge 和Gesher 都含有桥梁的意思。而Sandy Bridge 微架构将这个含义发挥到了极致,它是一个集NetBurst 微架构与Nehalem 微架构大成的产品,也是一个首先将CPU和GPU 进行真正融合的产品,更是一个首先将浮点运算密度从128 位引向256 位的X86 处理器产品,它确实像是一个桥梁,引导着芯片设计上和计算模式上的转变。 Sandy Bridge 微架构为什么会是现在这个样子呢? Sandy Bridge 在上一代Nehalem 微架构的基础上进行改进,如果不了解Nehalem 微架构,就无法真正理解Sandy Bridge的进化。 Nehalem 无疑是一个很成功的架构,QPI、IMC 带来的直联架构,再加上超线程的回归,其性能比起上一代提升了一到两倍以上,在企业级市场、主流乃至高端桌面市场以及移动市场的压倒性的占有率充分地说明了Nehalem 的强大。当然,Nehalem 微架构也不是完美的,以笔者的眼光看来,至少有几点Nehalem 微架构是有待改进的: 指令拾取和预解码 Nehalem 微架构在Pentium M微架构的基础上进行改进,整个流水线上几乎所有的组件都得到了增强,变化最少的就是在指令拾取和预解码阶段了。这个阶段的作用是将要执行的指令从L1 I-Cache 中提取到CPU 核心里面来,并随后对其进行预解码。预解码的主要作用就是在一块代码块中辨认每条x86 指令的长度。 和Penryn 一样,Nehalem 以及其改良版Westmere 都仍然采用了16Bytes 的指令拾取宽度,而竞争对手早已经采用了32Bytes 的拾取宽度。由于x86 指令的长度可以从1到15Bytes,因此在很糟糕的情况下,某个时钟周期拾取到的代码块里只包含一个x86 指令,和后端动辄6个、4 个uop(微指令)的能力不相符合。Nehalem 微架构的指令拾取/预解码单元无法跟上后端处理的速度,因此在运行计算密集型的代码中,它很容易成为瓶颈。 寄存器读停顿 这个情形发生在uop 经过RAT(Register Alias Table,寄存器别名表)进行寄存器重命名并发往ROB(ReOrder Buffer,重排序缓冲)之后,在这个被称为ROB-read 的流水线阶段中,uop 们需要读取相关的操作数,也就是读取对应的寄存器,如果这些内容在ROB 当中不存在的话。Nehalem 微架构的RAT 每时钟周期可以输出4 个uop,每个uop可以具有最多两个输入寄存器。这样它最多需要同时读取8 个寄存器。不幸的是,Nehalem 微架构用于保存寄存器的RRF(Retirement Register File,回退寄存器文件)仅具有3 个读取端口,无法充分满足寄存器读取的需求,这很容易导致ROB-read 以及前方流水线的停顿。 访存能力 Nehalem 微架构具有6 个执行端口,其中的3 个运算端口具有充足的计算能力,基本不会是瓶颈。然而,访存能力却不一定足够。Nehalem 微架构只有一个Load 载入端口和一个Store 保存端口。由于Load 操作是如此常见,可以达到uop 总数的1/3,因此相对于3 个运算端口,这个Load 端口是个潜在的瓶颈,特别是对于内存密集型计算来说。 最后, 早期的Nehalem 架构上还存在大页面TLB 数量较少的问题,TLB:Translation Lookaside Buffer,旁路转换缓冲,或称为页表缓冲,里面存放的是虚拟地址到物理地址的转换表。Nehalem 具有较多的标准4KB 页面TLB 项,但是更大容量页面的TLB 很少,因此,相对来说不适合大规模内存下的应用(如大型数据库和大型虚拟化环境,后来的Westmere 通过增加了对1GB 页面的支持缓解了这个问题)。 除了Nehalem 微架构的一些问题之外,英特尔或者说CPU 本身还面临着挑战,来自GPU 的挑战。目前,主要的GPU 厂商包括NVIDIA和AMD ATI 都提供了超越CPU 的强劲浮点处理能力,很多超级计算机通过采用了附加GPU 的方式获得了很强的计算指标。CPU 能力的增强导致了如硬件解压卡、独立声卡被融合进CPU,而GPU 强大的处理能力则被认为是CPU 的有力挑战者。如果运算能力足够强大,CPU 被GPU 取代也不无可能,英特尔怎么应对这个局面? Sandy Bridge 进行了什么样的改进、能不能解决这些问题呢?请看下回分解。 | |
|
(4个打分, 平均:5.00 / 5) |

深信服十周年–2000/12/15-2010/12/15
作者 dean | 2011-01-18 07:20 | 类型 行业动感 | 13条用户评论 »
Patterns in network system design (6)
作者 kernelchina | 2011-01-17 23:01 | 类型 行业动感 | 6条用户评论 »
系列目录 网络系统设计模型概论
23) stateless packet processing Pattern Name and Classification: stateless packet processing 无状态的包处理应该是一个很自然的选择,因为ip协议就是一个无状态的协议。无状态意味着每个包都是独立转发的,相互之间没有关系。无状态和有状态的主要区别在于包是否匹配session或者是flow(session和flow这两个词在大多数应用场景里面所指的东西是一样的,所以后面直接用session来代替了,读者明白这个意思就行)。session是路由,策略,MAC地址的cache,这个和“一次路由,多次交换”的机制是一致的。在无状态的处理过程中,每个包都需要查找路由,匹配策略,查找出口的MAC地址等;而在有状态的处理里面,如果存在session,先查找session;如果查找失败,再查找路由,匹配策略,然后创建session。 无状态好处是在路由,策略,MAC地址等改变时,可以快速感知,而且可以做到per-packet的ECMP。但是无状态对某些应用是不可能实现的,比如NAT和IPSEC。NAT通常是session based,因为它要求同一个session的packet,转换后也是同一个session;IPSEC的每个包都是编号的,而且SA本身也要求有状态。从匹配效率来说,policy/acl/route 匹配并不一定比session匹配效率低,看具体应用。如果是单纯的包转发,当然是无状态处理好;如果要加上更多的service,比如netflow,nat, ipsec等,就需要有状态的处理。 1: https://www.mikrotik.com/testdocs/ros/2.9/ip/flow_content.php 2: http://www.multicorepacketprocessing.com/ 24) stateful packet processing Pattern Name and Classification: stateful packet processing stateful packet inpsection (SPI)是防火墙技术的一次飞跃。早期stateless packet filter防火墙,在处理动态协议时碰到了问题。而Checkpoint发明的SPI技术通过动态创建session来解决这个问题。所以stateful packet processing首要任务是创建session或者flow 。什么是session?session是cache;是什么的cache?路由,策略,MAC地址等。能够匹配session,就说明相应的流被允许通过,并且在这之上,有一系列处理。session一般是用五元组(协议,源地址,目的地址,源端口,目的端口)匹配的。在处理动态协议的时候,可能还需要用到expect(请参见linux netfilter),expect是一个不完整的session,在匹配expect之后,可能还需要匹配策略以确定expect是否可以转化成一个session。一句话,session是stateful packet processing的基础。 stateful的好处是什么?一是有些应用必须是stateful的,比如前面提到的NAT,IPSEC,以及ALG等。stateful的坏处是什么?在系统状态变化时,比如路由,策略,MAC地址变化,维护session的状态比较困难。 Known Uses: stateful packet inspection firewall 1: http://en.wikipedia.org/wiki/Stateful_firewall 3: http://netfilter.org/documentation/HOWTO/netfilter-hacking-HOWTO.html 4: http://www.soapatterns.org/stateful_services.php 25) per-packet service Pattern Name and Classification: per-packet service 不管是无状态还是有状态的包处理,有些应用是针对单包的,比如NAT,IPSEC。当然,在处理之前,这个包在IP层已经完成了分片组装。对基于UDP的协议来说,per-packet的处理是很自然的,但是对基于TCP的协议来说,由于协议的边界并不是IP包,所以per-packet的处理就不适用了。当然,对基于TCP的协议应用per-packet处理在很多情况下也能工作,只是不能适用于所有情况,特别是包在TCP层被分片的情况。 Known Uses: NAT, IPSEC etc 1: http://en.wikipedia.org/wiki/Deep_packet_inspection 26) stream service Pattern Name and Classification: stream service 基于TCP的协议,上层应用看到的是一个字节流,而不是单个的packet。协议的边界是基于流的,而不是基于单个包。所以,必须先完成流组装才能进行更高层的处理。协议是分层的,每一层做好自己的事就可以了。stream可以算一个层次,在这之上,有很多应用协议,比如http,还有很多基于http协议的应用协议,所以可能还需要一个http协议层。这样,每一层只关注自己的工作,向上层提供相应的服务。 1: http://en.wikipedia.org/wiki/Flow_(computer_networking) 2: http://en.wikipedia.org/wiki/Data_stream_mining 27) service plane Pattern Name and Classification: service plane
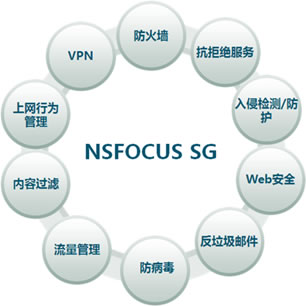
(http://www.nsfocus.com/1_solution/1_2_10.html, 这张图来自绿盟的网站,如有版权问题,请联系本文作者) 如上图,在有这么多service运行的情况下,如何把这些service组成一个有机的整体? 是callback based, event-driven, pool-based,或者其他?这些都是细枝末节,最重要的是把service的层次要定义出来,这样才能和传统的data plane区分开来。service这么多,调用顺序是一个问题;如何在规定的时间内完成处理是另一个问题(realtime系统的要求);service之间如何通讯,service如何管理,service如何配置等等。netfilter做的完全动态,可扩展的框架就很不错,不过性能稍差一点,可以用做参考。 1: http://www.nsfocus.com/1_solution/1_2_10.html 2: http://en.wikipedia.org/wiki/Software_framework 3: http://en.wikipedia.org/wiki/Osgi 4: http://en.wikipedia.org/wiki/Netfilter 28) tcp-proxy Pattern Name and Classification: tcp-proxy 把tcp-proxy单列出来,看似有凑数之嫌,其实不然。我们常见的application proxy,比如squid,apache等,是应用层的代理,和这里所说的data plane的tcp-proxy完全不同。以squid为例,它完成代理,需要建两个socket,一个包进出内核,需要两次拷贝,这样的开销是不能容忍的。如果忽略内核空间与用户空间之间的内存拷贝,这个tcp-proxy应该能提供哪些功能?首先要支持多种应用协议,其次需要支持多种service(多个service,一个tcp-proxy),而且需要支持多个tcp-proxy同时运行(有可能是per-session的tcp-proxy)。tcp-proxy是TCP协议的一个完整实现,能够工作的实现已经不容易了,高性能的实现是很困难的事情,是业界的难题之一。 | |
|
(没有打分) |
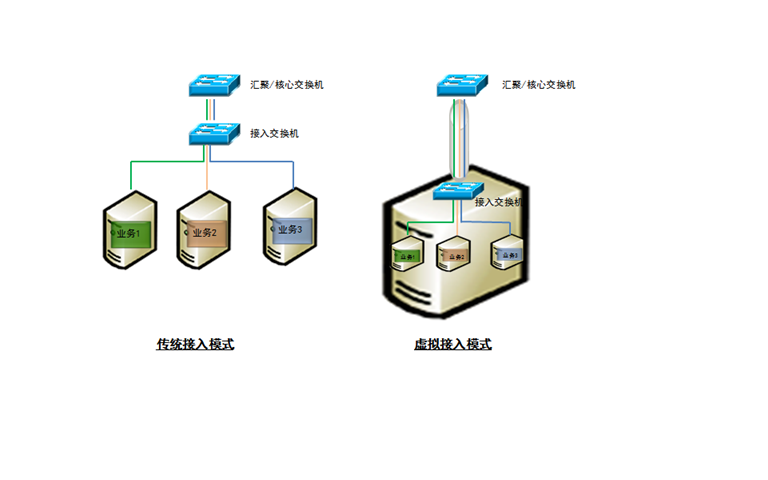
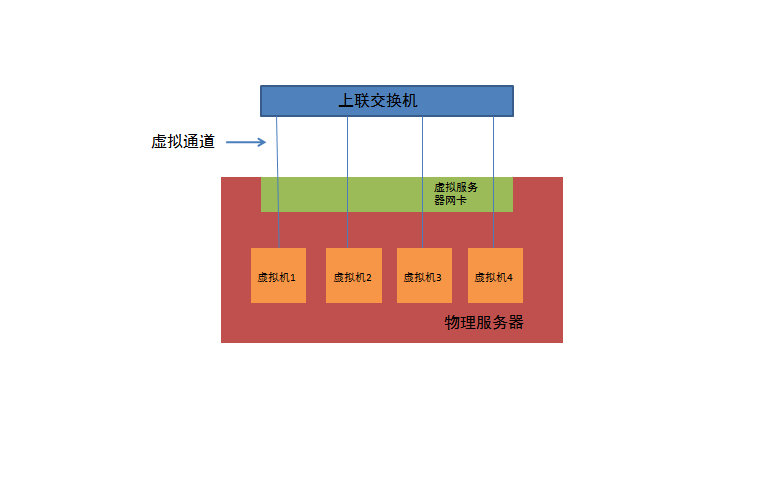
下一代数据中心的虚拟接入技术–VN-Tag和VEPA
作者 libing | 2011-01-16 11:10 | 类型 专题分析, 弯曲推荐 | 132条用户评论 »


{kind=link}
工具箱
本文链接 |
|
打印此页 | 132条用户评论 »