




对 OpenSSL 高危漏洞 Heartbleed 的感慨、分析和建议
作者 陈怀临 | 2014-04-13 20:10 | 类型 网络安全, 行业动感 | Comments Off
|
[原文可参阅: 作者:编程随想 http://program-think.blogspot.com/2014/04/openssl-heartbleed.html]  ★关于 Heartbleed 漏洞这个 Heartbleed,直译成中文就是“心脏出血”。听上去挺吓人滴,现实中也确实挺吓人滴。简而言之,这个漏洞足以载入史册。这几天,大伙儿正在经历信息安全历史上的一个重要时刻。或许你应该觉得荣幸 ★先发点感慨先发一通抱怨。不喜欢听俺抱怨的,请直接略过。 ◇安全行业的耻辱对整个安全行业而言,这是巨大的耻辱。 ◇开源社区的耻辱对整个开源社区而言,这是巨大的耻辱。 ★对该漏洞的风险评估该漏洞曝光前后,风险是不同滴。以下俺分别介绍。 ◇漏洞曝光【之前】——作为“未公开漏洞”目前已经有报道指出,在4月7日之前,这个漏洞就已经被骇客利用(报道在“这里”)。另外,圈内也有小道消息流传,说某些攻击者早已拿到此漏洞并加以利用。 ◇漏洞曝光【之后】——作为“零日漏洞”4月7日那天,OpenSSL 发布了公告。发现漏洞的 CloudFlare 公司也发布了公告。于是这个漏洞瞬间传遍全球。几小时之内,大量的攻击工具应运而生(这个漏洞太容易利用了)。然后大量的“脚本小子”(洋文叫 script kiddie)就拿着这些别人写好的工具,对大量的网站进行扫描。 ★对该漏洞的技术分析(本节聊的是该漏洞在技术层面的细节。对 C 语言了解不多的同学,请自行略过,以免浪费时间)
如果对端发来的心跳包有猫腻——包长度跟实际载荷不匹配,那么在发送回应包的时候,那句 memcpy 语句就会把心跳包之后的内存区块也一起 copy 进去,然后发给对端。内存信息就泄露了。
★给普通用户的建议前面的“风险评估”已经分析了——对于普通网友而言,你的风险主要在于“漏洞曝光之后那1-2天”(也就是“0day”导致的风险)。 ★给程序员/架构师的建议
◇“多进程”在安全方面的优点刚开博的头一个季度,俺就发过一篇帖子《架构设计:进程还是线程?是一个问题!》,其中提到了多进程的若干优点。今天再来老调重弹,说说“多进程”在安全方面的优点。 ◇关于密码的“客户端加密/散列”如今比较成熟的网站,应该不会采用“明文”的方式存储用户密码了。很多程序员/架构师都明白,要把用户密码进行散列(Hash)之后再存储。但是这里面有一个细节,很多人忽略了。那就是:“服务端散列”vs“客户端散列”? ★给有志于成为黑客的同学的建议先声明:“黑客”与“骇客”是完全不同的两类人。俺之前发过一篇《每周转载:关于黑客文化和黑客精神》,或许有助于你了解两者的差异。 如果能够搞定上述三点,并且你的运气足够好,那么你有望独立发现一个高危漏洞。 | |
  (2个打分, 平均:3.00 / 5) (2个打分, 平均:3.00 / 5) |
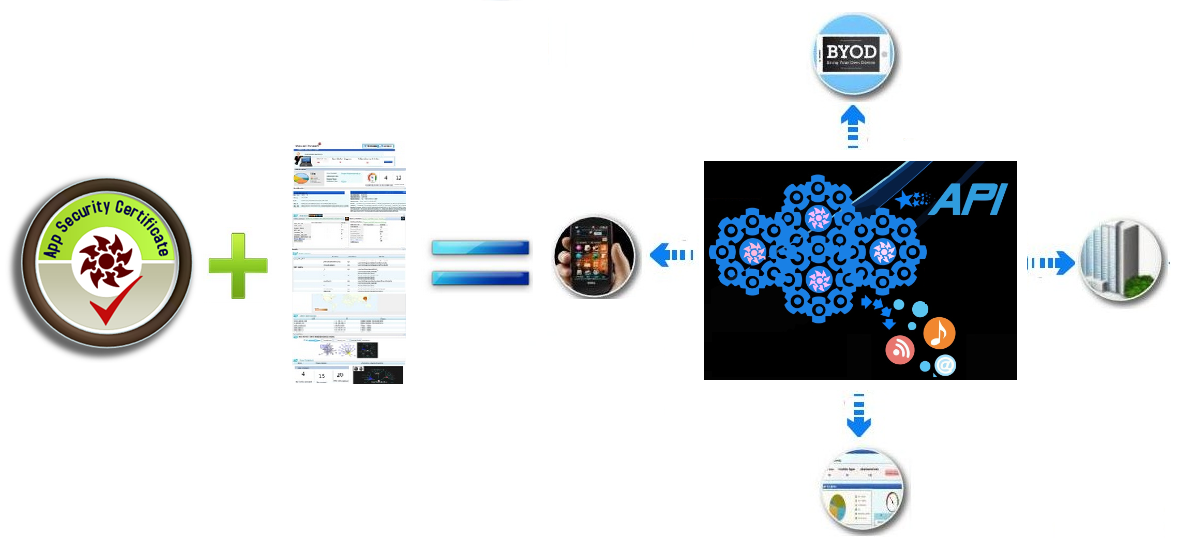
VisualThreat 免费开放移动应用隐私泄露分析API和云端沙盒动态分析服务
作者 yI1kB1tK9k | 2014-04-13 16:28 | 类型 行业动感 | 1条用户评论 »
|
[投稿文章。以下技术观点不代表弯曲评论立场] VisualThreat 免费开放移动应用隐私泄露分析API和云端沙盒动态分析服务 移动安全和传统PC安全看似一对兄弟:手机病毒和PC病毒沿着类似的发展轨迹:从简单的压缩壳我们看到类似UPX UPack的影子,内存分页解密而后擦除数据的手法神似Obsidium和Molebox,马上会出巨烦无比的VM壳了。难道以前写PC壳的兄弟们都跑过来做手机壳了。 手机病毒分析员开始变成样本队列血汗工厂的重复脱壳工人。PC病毒从2005到2012年演变将在手机上加速完成。然而,移动安全解决方案和PC方案相差很多,仅仅偷流量和短信扣费使得移动安全隐患同APT相比相形见绌。BYOD厂商名单中竟然没有传统安全大佬,反而让container技术大行其道。 愚见:与PC是病毒感染终端不同,移动设备对于手机病毒而言,是一个散布渠道,顺便打打广告,刮刮流量赚点外快;移动设备是一贴烂膏药,贴到哪个行业,这个行业就有了移动威胁的隐患。未来的移动安全产品应该是和不同行业结合,监控移动设备数据流量,整合该行业的行为管理策略。换句话说,就是做手机安全要从手机杀毒向信息泄露,隐私泄露和行为管理上转换。 为此,VisualThreat开放了移动应用隐私泄露分析RESTful API调用接口,使得第三方可以使用API把 隐私泄露分析流畅地嵌入到他们的应用或平台上。 API可以让用户查询安卓应用的MobileThreatCert安全分数,风险分析报告, 威胁关联度,并以JSON格式返回结果。其中MobileThreatCert分数可以帮助企业,第三方开发者、应用商店、应用搜索引擎,和测试平台更好地筛选管理应用,进行排名和安全认证App Security Certificate。
VisaulThreat 生成应用隐私泄露风险分析报告,并在此基础上计算出对应MobileThreatCert值,使用1到100之间的数字去指示应用程序的安全指数。API还支持批量样本上传处理,可以一次性处理上千个应用查询。此外,云服务提供应用安全报告管理, 可以进行报告的汇总,合并,趋势分析等。 使用人员不需要安装任何工具,只要打开浏览器,访问账户页面即可。整套服务基于移动数据云端自动化处理流程。 同时,云端沙盒动态分析服务测试版也为API调用提供了移动应用动态行为信息查询,即通过沙盒模拟进行应用行为分析,生成截图,行为信息,流量数据和行为阻断规则库,这里不赘述了。下面介绍一下如何使用API。
调用方法: 调用语法举例: 更多信息在http://cn.visualthreat.com/api_cn.htm
如何申请沙盒和API服务? 申请沙盒测试服务,只需发邮件给我们,申请成为试用客户。 申请使用API,只需在VisualThreat 网站上注册,然后获得访问令牌,参考API网站页面上不同方法的代码样例,嵌套要查询的MD5即可使用。 由于服务正在测试阶段,有任何问题和建议,随时联系我们: http://www.visualthreat.com/contact_us.action | |
|
(1个打分, 平均:5.00 / 5) |






Aerohive Networks IPO路演中文PPT
作者 William | 2014-04-12 16:06 | 类型 行业动感 | Comments Off
|
Aerohive Networks 新型企业无线网络解决方案 Reference: xueqiu.com | |
|
(没有打分) |

开源开发工具大会2014(原HelloGCC技术讨论会)话题和赞助征集
作者 teawater | 2014-04-10 22:06 | 类型 行业动感 | Comments Off
|
http://www.hellogcc.org/?p=33749 ************************************************************************* 开源开发工具大会2014(原HelloGCC技术讨论会) 开源开发工具大会(原HelloGCC技术讨论会)是开源软件开发者的大会,您可以在这里分享自己在开源软件方面的开发工作,研究成果,经验学习。我们的话题主要面向开源开发工具。 话题内容可以为: 话题形式可以为: 如果您有相关话题,欢迎和我们联系: 重要日期: 往届会议: 如果贵公司有意提供赞助,欢迎和我们联系 hellogcc.workgroup@gmail.com。 | |
|
(没有打分) |
2013-2014 DDoS安全报告
作者 陈怀临 | 2014-04-09 10:42 | 类型 网络安全 | Comments Off

亚马逊AWS需解决的五项问题
作者 陈怀临 | 2014-04-08 21:58 | 类型 OpenStack+SDN | 2条用户评论 »
|
[原文可参阅: http://www.openstack.cn/p1330.html] (一)共享EBS卷。EBS(Elastic Block Store,弹性块存储)为亚马逊EC2提供永久存储。由于去除了对速度缓慢的亚马逊S3(另一个云计算产品)的依赖,它在2009年一经推出就得到了高度评价。 许多工程师只要加载一个Amazon EC2实例,就会马上附加一个EBS卷,并将长期需要的数据移动过去。然而四年过去了, EBS需求最旺盛的功能-将同一个EBS卷附加到多个EC2 实例上还尚未实现。 AWS鼓励在一个load balancer(负载平衡器)后台运行多个亚马逊EC2实例来获得最佳的性能。然而仅在一个EC2实例上运行应用不是个好主意。大多数内容管理系统和媒体驱动的应用程序依赖于共享的存储。当这些系统都迁移到AWS并放在一个 ELB(Elastic Load Balancing,弹性负载均衡)之后,没有简单的策略使得在运行相同应用程序的EC2实例之间来共享内容。 举例来说,一个终端用户上传一个新图片到由负载平衡器随机选取的一个内容服务器上。目前而言,复制这一图片到所有正在运行的服务器是留给开发人员做的。AWS建议使用亚马逊S3存储 静态内容,而许多流行的CMS框架期望可以在本地文件系统实现存储。为了确保所有的服务器共享最新的内容,需要强制实现类似Gluster或NFS式的分布式文件系统。这需要前沿技术,其中涉及启动一个专用的虚拟机来运行该文件服务器。这也使得配置很不稳定:文件服务器很容易成为单点故障。 如果亚马逊支持多个EC2实例共享同一个EBS卷,这就能避免对专用文件服务器的需求和对每个服务器进行额外的配置。这其实也不复杂:谷歌计算引擎(Google ComputeEngine)支持在多个实例上同时安装永久磁盘。虽然只有一个实例有对文件系统的读写许可,但是所有的实例将能立即访问该内容。虽然还只是在技术测试阶段,谷歌计算引擎已经在性能和特性方面把目标瞄准了跨越式发展的亚马逊EC2。早期指标显示GCE将是亚马逊EC2的一个可行替代方案。 (二)可配置的ELB流量。ELB(ElasticLoad Balancing,亚马逊弹性负载均衡,是在EC2基础上实现的负载均衡服务)提供了一种能将流量均匀地分布在多个亚马逊EC2实例上的服务。亚马逊把ELB这种服务定位为近乎神奇,它能提供长久的稳定运行和高可扩展性。根据ELB的官方描述,“它能使你在你的应用程序中获得更大的容错能力,无缝地提供用来响应传入应用流量所需的负载平衡能力。” 对负载均衡容量可以无缝增加的承诺肯定带有误导性,因为ELB旨在随着流的线性增加而逐渐扩展。这对于像电子商务门户网站或机票销售那类开始流量较少,随着时间不断增长的模式是可行的,但是如果是在那种建于ELB之上的网站,当它流量飙升,ELB性能就会显著下降。这种模式通常见于发布考试成绩或者发布重大新闻的门户网站。为了使ELB能够随时准备处理这种突发状况, 亚马逊期待AWS用户每月支付最低49美元,以支持服务使ELB能提前“热身”。虽然这一问题有足够多的指导资料来解决,但它们仍然被湮没在AWS的浩瀚文档之中。就像EBS中置备的IOPS功能,亚马逊应当使ELB流量可自定义化,这样客户可以事先选择流量模式以确保可扩展性。 (三)每分钟计费模式。亚马逊EC2用户需按小时支付他们的实例运行。也就是说即使该实例仅运行几分钟,亚马逊还是会按一整个小时收费。当AWS于2008年推出EC2,它被认为是在自助服务和按需供应计算资源方面取得了突破性创新。然而快进到2013年,这就被诟病成了虚拟机定价不合理。如果亚马逊能转换到按分钟计费,那么许多客户就会好好利用这一成本结构带来的好处。但是由于还有许多竞争对手比如Windows Azure以及谷歌Compute Engine (计算引擎)也在用分钟计费法,用户都在观望亚马逊的计费模式将怎样变化。(OpenStack中国社区注: 国内创业公司青云已经提供按秒计费,走在世界前列) (四)可改进的CloudWatch度量。亚马逊的CloudWatch(亚马逊云服务监控,有针对性的监控并有警报响应)提供与许多AWS服务有关的度量,包括亚马逊EC2,亚马逊RDS,和亚马逊DynamoDB。虽然它支持一系列的服务,亚马逊EC2的度量却仍有很多值得改进的方面。虽然对有关CPU、磁盘和网络有关的基本度量是在监控级别进行的追踪,它仍不尽人意。尽管客户为亚马逊CloudWatch付费,他们仍然需要依靠外部服务如Pingdom来跟踪基本度量,例如网站可用性。为了监测基于网络服务器或数据库服务器的高级服务,客户不得不建立一个基于代理的架构比如Nagios或zabbix。虽然CloudWatch 支持自定义度量, 但需要相当可观的工作量,并且没有对于高级度量的现成支持。 WindowsAzure中最近新增了终端监测,它提供了基本的网站稳定运行时间监控。 Rackspace公司获得了Cloudkick,并将其与众所周知的具有稳定监控功能的Rackspace云 服务器进行了整合。亚马逊可以将一个代理轻松嵌入每个EC2实例来跟踪并报告那些粒状的和精确的度量。 事实上,依附于AWS豆茎(beanstalk)的Amazon EC2实例已经使用代理驱动的监控引擎来跟踪服务器的运行状况。亚马逊应该将该代理从AWS豆茎扩展到所有亚马逊EC2实例,来跟踪和报告有意义的度量。
(五)动态虚拟机大小。如果你认为微软总是用多种不同版本的Windows来迷惑客户,那是因为你还没有见过亚马逊EC2实例类型的数量。 Amazon EC2实例共计6大类,若细分则有18种。每一实例类型都有一特定负载量。 如果你在看过这些实例类型的详细介绍后还没有迷惑,那么接下来你就要开始选择与你的应用程序相匹配的实例类型了。一般你需要选高 CPU ,高内存,高容量,集群计算等等。等这些都有了,用户就一定会得到他们想要的了吗?还不一定。因为通常情况下,本地物理服务器和Amazon EC2实例之间的映射还不完全匹配。在一些情况下是由于存储器,在其他情况下是CPU不合格。无论如何,实际性能永远不能匹配实例类型的能力。那么实例类型的能力是不是很难达到呢?也不是,因为最近加入IaaS竞争的公司 ProfitBricks提供了对虚拟服务器的动态配置。 ProfitBricks还声称它使用InfiniBand互联与SSD存储,因而能提供更佳性能。现在是亚马逊转向动态实例类型的时候了,在这里客户可以拖动滑块以选择内存、核心数量、CPU和磁盘容量。这将简化对Amazon EC2的配置,并且客户能够获得服务器配置的控制权。他们可以停止、调整配置,并重新启动亚马逊EC2实例,直到性能令人满意。
以上这些都是基于Amazon EC2上的一些特性的讨论,相信我们还有许多与亚马逊RDS相关的问题需要解决。我们将在以后的博客予以介绍。 | |
|
(1个打分, 平均:3.00 / 5) |
Google Flu Trends: Big Data Hubris
作者 彩筆 | 2014-04-08 15:29 | 类型 大数据, 行业动感 | Comments Off
|
前一篇文章探讨了Big Data Hubris的准确含义,也整理了原文作者对大数据应用的立场: 1. There are enormous scientific possibilities in big data. 2. Foundational issues of measurement and validity & reliability & dependencies among data cannot be ignored.
加注:系列(二)的评论中有网友爆料,一个天才同行创造了一个中文词汇能够表示Big Data Hubris的含义。笔者反复思量,仍觉得此译法生动传神,甚至能够折射出Big Data Hubris对应于中文时表示对“人”的指代功能,甚好!特此广而告之。
作为一篇严谨的议论文,作者(以下均指Lazer D, Kennedy R, King G, et al. The Parable of Google Flu: Traps in Big Data Analysis[J]. Science, 2014, 343(6176): 1203-1205.一文作者)列举了若干GFT在数据处理过程中的细节,以支持自己的观点:这些处理方法欠妥。本文及后续若干篇文章将以介绍作者的论证过程为主题。 在系列(二)中提到,笔者在落实原文细节、以及将作者提供的事实论据与论点建立联系时遇到困难。所幸笔者在系列(一)见到很多评论类似:这(GFT)是老例子了。于是,笔者大胆推断,本文所纠结之细节,应该不缺少围观群众吧。这毕竟不是一个哗众取宠的系列,我希望自己的文章能够吸引的不仅是眼球。
言归正传。
GFT方法体系的核心是在5千万个检索词中找到与1152个数据点的最佳匹配。(原文:Essentially, the methodology was to find the best matches among 50 million search terms to fit 1152 data points.) “50 million search terms”是这样产生的: By aggregating historical logs of online web search queries submitted between 2003 and 2008, we computed a time series of weekly counts for 50 million of the most common search queries in the United States.(Ginsberg J, Mohebbi M H, Patel R S, et al. Detecting influenza epidemics using search engine query data[J]. Nature, 2009, 457(7232): 1012-1014.)而“1152 data points”的来源则未得落实。关于这一点,还希望会继续有深藏功与名的伟大网友不吝赐教。 不明白“1152”这个数字如何得来,仍然可以理解作者接下来的思路:The odds of finding search terms that match the propensity of the flu but are structurally unrelated, and so do not predict the future, were quite high.也就是说,即便Google(用大数据的方法)找到了跟CDC报告的ILI案例比例波动吻合的检索词,这两个变量在结构上不相关(structurally unrelated),因此(选出的检索词)没有预测将来的能力——这种情况发生的可能性是很大的。这是作者的观点。 笔者的疑惑是:既然能够match the propensity,为什么会fail at predicting the future? 诚然,对过去拟合效果好并不代表能准确预测未来。然而我们平时在用小数据做回归分析并进一步预测时,不也是这样的思路吗?不同的是,在日常的小数据分析中,参与回归的解释变量和被解释变量通常被认为有“相关性”,甚至是有“因果关系”。作者认为GFT使用的Google检索词和ILI病例比例之间不存在相关性(这种相关性包括了对潜在因果关系的暗示),由此导致了在预测未来时的显著误差。 笔者对这种主观地暗示两个变量之间“相关性与因果关系对应”存疑。举例说明:人们认为学历与收入(正)相关,这一陈述隐含的观点是:高学历导致高收入(因为高学历,所以高收入)。GFT选用的检索词与ILI病例比例的相关性很高,但作者仍然因为检索词与ILI病例比例之间structurally unrelated而心生嫌隙。不难想象,要达到作者structurally related的要求,变量之间的causal relationship不可避免。来看一段划时代的论述: 不是因果关系,而是相关关系 知道“是什么”就够了,没必要知道““为什么为什么””。在大数据时代,我们不必非得知道现象背后的原因,而是要让数据自己。在大数据时代,我们不必非得知道现象背后的原因,而是要让数据自己““发声发声””。。 ——大数据时代/(英)迈尔-舍恩伯格,(英)库克耶著;盛杨燕,周涛译. – 杭州:浙江人民出版社,2013.1 对于笔者(典型的“大数据婊”)来说,这段旗帜性的理论已经足够了。笔者相信,相关关系足以说明问题(即便存在人们能普遍理解的“相关关系”,这种“普遍理解”有会多接近“真实的客观”,这种接近的程度又如何衡量?)。
现在,让我们姑且忽略因果关系,来看看Google是怎样确保“相关性”的。 首先,选用2003-2008年间美国用户使用最频繁的5千万个检索词,按“周”汇总数据;同时也按“州”来整理数据。By aggregating historical logs of online web search queries submitted between 2003 and 2008, we computed a time series of weekly counts for 50 million of the most common search queries in the United States. Separate aggregate weekly counts were kept for every query in each state. 然后,逐个检查者5千万检索词中的每一个,每周提交检索的次数与对应时间CDC发布的ILI病例比例波动之间的相关性(区分全国和9个不同区域)。相关性最好的排在最前面。Each of the 50 million candidate queries in our database was separately tested, to identify the search queries which could most accurately model the CDC ILI visit percentage in each region. Our approach rewarded queries that showed regional variations similar to the regional variations in CDC ILI data. 接着,从前面选若干个检索词(最终确定为45个)参与最后的建模。Combining the n = 45 highest scoring queries was found to obtain the best fit.在超过81个检索词参与建模时,模型的效果迅速下降,如下图。
最后,用这45个检索词在全部检索词中的占比作为解释变量,与ILI病例比例的周数据建立线性回归模型。Using this ILI-related query fraction as the explanatory variable, we fit a final linear model to weekly ILI percentages. The model was able to obtain a good fit with CDC-reported ILI percentages, with a mean correlation of 0.90 (min = 0.80, max = 0.96, n = 9 regions). 实验用2003-2007年的数据作为训练数据,用2007-2008年的数据作为测试数据。下图展示的是mid-Atlantic region的实际(红色,CDC report)和预测值(黑色)。可以看出,效果很好。
(信息来源:Ginsberg J, Mohebbi M H, Patel R S, et al. Detecting influenza epidemics using search engine query data[J]. Nature, 2009, 457(7232): 1012-1014.) 粗略地看(笔者有计划结合Ginsberg 2009原文及supplementary介绍GFT的处理细节),每一步处理有理有据,完备科学实验的全部要点(可以认为变量之间的相关性)。笔者愿意相信,通过这系列步骤得到的算法能够实现对未来的预测。
总结 无论是大数据,还是小数据,统计分析只能证明相关关系,因果关系需要结合实验过程来证明。用这个普适的理由拒绝GFT,那全天下的统计分析结果岂不是都要受到质疑(果然是树大招风,人怕出名猪怕壮么)。调转思路,所有的统计分析都是建立在相似假设之上,GFT以这种假设为基础,即便说不上“合情合理”,至少“无可厚非”。作者首先从这个角度质疑大数据的准确性,对大数据应用精益求精的发展道路,莫非用心良苦?(这其实是反语,也极有可能只是笔者的个人偏见。) 注:这里的假设是指,“观测数据”经统计分析得到的相关性仅能证明变量间的相关关系,其因果关系是通过人为解释、推断得出,其结果(因果关系)存在不同程度的“不确定性”。举例:通过可靠的统计分析过程得到结果“收入与学历正相关”。于是研究人员解释道“因为高学历,所以高收入”,并能够结合“已知”(或“常识”)罗列很多细节以支撑逻辑过程。然而,真正的原因总是不可知的。正因为其不可知,所以我们根本无法想象我们现有认知水平在整个“已知+未知”中所占比重(是的,笔者是“不可知论”的忠实初级信徒)。 | |
|
(没有打分) |
科技一周–打仗,得找个靠谱的军备商
作者 硅谷寒 | 2014-04-05 23:14 | 类型 硅谷科技周报 | Comments Off
系列目录 科技一周
打仗,得找个靠谱的军备商 2014/04/05 “二十年岁月流金,五十弦寒暑争荣”,时至今日,芯片巨擎Intel终于告别自己二十年的黄金时期,来到了产业巨变的拐点:摩尔定律难以维持,SOC大行其道,PC处理器逐渐让位于移动处理器。当下的Intel,虽然没能赶上七年前那场移动处理器的大变革,但也并不意味着它将就此消失。这个巨人正在拼尽全力去追赶,无论采用什么盘内盘外的招数,因为它清楚得很:自己手里那数百亿的现金,也可以成为击败ARM CPU的最佳武器。
我唯一可以想到的方案,就是“金元策略”,Intel给平板电脑厂商巨额回扣,以此来换取自己芯片的出货量。这种办法,Intel并非没有干过,当年在与AMD竞争64位处理器市场时,Intel就一直给Dell、HP等厂商不菲的补贴,直到把AMD彻底打垮。此番,Intel欲故技重施,补贴的力度甚至更大,即使赔本赚吆喝,也在所不惜。其实,在科技产业里,创新与金钱,从未停止过竞争:创新者首先凭借技术优势领导市场;跟随者利用金钱优势(或补贴回扣,或价格低廉)后来居上,挤垮创新者;然后,又有更新的技术出来,把原先的跟随者打败,重新领导市场;如此循环往复,生生不息,谁也不能把另一方彻底降服,而我们的世界则得益于这种竞争,向前发展。
本周科普,继续聊聊图灵奖得主Lamport的论文[3],这次主要来侃侃他所定义的在分布式并发系统里的“物理时钟”概念。我还是会摒弃艰深的学术词汇,用一个历史故事来讲解。
那么究其原因,为什么瞿能不等其他三军,而独自攻击呢?其实,这也怪不得瞿能,他并非是贪功冒进之徒,实在是运气太差,吃了山寨货的亏。在约定当晚,瞿能所用的计时器(沙漏),出现了故障,比其他三军的计时器走得快了许多,所以当瞿能以为子时已到的时候,其他三军还在饱餐战饭呢!唉,不得不说,以后打仗的时候,千万要找个靠谱的军备供应商呀:) 话说回来,就算计时器的速率不一样,假如能有一套自动校正的规则,使得各军的计时器“误差缩小在某个可以接受的范围内”,那么李景隆的军队也是可以在约定的时刻发起全面攻击。我们不妨把李景隆的各个军队看做不同的并发进程,而他们各自的计时器就是用来同步各个进程的“物理时钟”。所谓“把误差缩小在某个可以接受的范围内”,正是Lamport关于分布式并发系统里“物理时钟”概念的精髓。Lamport在论文里给出了物理时钟的两个必要条件:1)各个进程的时钟速率相对于1的误差要小于某个值k;2)各个进程时钟的延迟误差也要小于某个值e。并且,Lamport还推导出了k和e的计算公式。有了物理时钟的同步,整个并发系统就可以完全有序地运转起来啦!要是Lamport能穿越回去,当建文帝的国师,大明历史岂不是要改写? [2]. http://www.amazon.com/Amazon-CL1130-Fire-TV/dp/B00CX5P8FC [3 Cialis]. Lamport, L. “Time, clocks, and the ordering of events in a distributed system”, Communications of the ACM, 1978, 21(7): 558-565. 图2. [2]. 图3. https://itunes.apple.com/cn/app/ming-chao-na-xie-shi-er-wang/id553783706?mt=8 注:故事纯属原创性虚构。 | |
|
(没有打分) |



作者 AbelJiang | 2014-04-01 21:27 | 类型 Deep Learning, 机器学习 | Comments Off
|
这份来自谷歌的新的研究论文详细阐述了如何训练神经网络在无人为干预的情况下读取数以百万计的门牌号。与以往不同的是,这项技术能像人一样,一整串的识别门牌号,而不是将其拆分成单独的数字来识别。谷歌方面表示,目前已用该系统识别一亿个街道号。这项技术的价值就在于,在用户使用谷歌地图时,为用户提供准确的位置信息,特别是在建筑编号非线性的地区。这份来自谷歌的新的研究论文详细阐述了如何训练神经网络在无人为干预的情况下读取数以百万计的门牌号。与以往不同的是,这项技术能像人一样,一整串的识别门牌号,而不是将其拆分成单独的数字来识别。谷歌方面表示,目前已用该系统识别一亿个街道号。这项技术的价值就在于,在用户使用谷歌地图时,为用户提供准确的位置信息,特别是在建筑编号非线性的地区。 | |
|
(没有打分) |

1
作者 破 布 | 2014-04-01 21:06 | 类型 科技普及, 芯片技术 | Comments Off
|
第一章:天降大任 1945年8月6日与9日,广岛和长崎两座日本本土城市先后在惊天动地的原子弹爆炸中被毁灭,核武器首次步入公众视野,全世界都被那两朵巨大蘑菇云的威力所震慑。这两道重击也直接摧毁了日本最后的抵抗意志,一周后的8月15日,日本宣布无条件投降,在人类历史上写下最惨痛一页的第二次世界大战终于结束。核武器横绝古今沛然莫御的威力,使得它成为战后制衡国际局势的一大王牌,对它的研究和制造在战后仍然未曾停息。 (图注:两次原子弹爆炸的照片,来自维基百科。) 半年过后的1946年2月14日,第一台通用电子计算机ENIAC的存在被公之于众。这台27吨重的庞然大物原先被设计用于加快火力弹道计算,但迅速吸引了核武器设计者们的注意。每秒5000次加减法运算,400次乘除法运算,远高于人力的计算速度使得基于机器模拟的核爆炸研究初露端倪,检验原子弹之后的下一代核武器——氢弹设计可行性的程序便在战后被提交给ENIAC运行。核爆炸模拟需要科学家们将核爆反应“碎片化”,在空间上将核爆模拟区域切片,在时间上将核爆过程细分,用远远慢于真实核爆速度的步伐,逐一重现核爆当中各个区域在各个时间点上的状态。这一过程需要很快的计算速度才能让模拟耗时和精度达到要求,科学家们极度渴求速度更快的计算机。每秒几百至几千次的计算速度,甚至远不及今天的可穿戴设备中使用的嵌入式处理器,这么巨大的差距是由谁来弥合的呢?又是怎样弥合的呢? 有能力推动早期计算机突破速度上界的人,在当时仍屈指可数。ENIAC的主要设计者John Mauchly和J. Presper Eckert看上去似乎是两个条件接近的人选。在开展ENIAC项目之前,此二人只是宾夕法尼亚大学的普通学生,随着ENIAC的面世,他们只花了四五年时间就功成名就,在战后迅速成为光芒耀眼的超新星。在日后载入史册的宾夕法尼亚大学摩尔系列讲座中[1],这两位俨然大师风范,担当了大约三分之一课程的讲授工作,而讲台下的学生,则是包括信息论之父Claude E. Shannon在内的一批顶尖科学家与工程师,其地位显赫可见一斑。可惜的是宾大当时的主事者对校内科研接受外部公司的研究资助一事感到担忧,试图逼迫二人签署新的专利协议,这一愚蠢举动最终将二人逼离宾大[2],下海创办Eckert–Mauchly Computer Corporation (EMCC) 公司。久居象牙塔的学者与商战中搏杀的豪雄毕竟不同,EMCC不出意外地命途多舛,由于缺乏资金,经营不善以及运气因素[3],EMCC仅过了三年就被卖给Remington Rand公司,成为了Remington Rand旗下负责开发新一代计算机的UNIVAC部门。随着这次收购,John Mauchly和J. Presper Eckert也被Remington Rand一同招安,而新东家也很给面子,为他们安排的直接上司就是当年曼哈顿计划的军方主管Leslie Groves。加入Remington Rand之后,UNIVAC I运行的程序成功预测了次年美国总统大选结果[4],这次事件为新东家做了一个极好的广告宣传,也为John Mauchly和J. Presper Eckert的名声再度锦上添花。 (图注:左侧为John Mauchly,右侧为Presper Eckert,中间是 Gladeon Barnes将军,三人正在审阅ENIAC维护记录。图片来源fi.edu) 看上去此二人又将成为天降大任的继承者。但,历史不会让这两位已经享受了诸多殊荣的传奇人物专美于前。 Remington Rand收购EMCC之后数月,一只来自明尼苏达州圣保罗市的团队也被Remington Rand收编,与UNIVAC团队形成双雄鼎立之势。这支团队名为Engineering Research Associates,其骨干成员以William C. Norris为代表,是一批来自二战时期美国海军密码破译团队的科学家和工程师,ERA创立过程中甚至得到过时任美国海军元帅Nimitz的出面帮助,来头不可轻视。一山难容二虎,ERA与UNIVAC两支团队在公司内部形成了公开的竞争关系,UNIVAC的成员们以Mauchly和Eckert为代表,出身于世人瞩目的常春藤盟校,是典型的学院派,ERA的成员们则大多来自稍显平庸的明尼苏达大学,身为ERA领导者之一的Norris在内布拉斯加大学电子工程专业毕业后,甚至曾一度在老家农场卖牲口[5]。这些人普遍没有接受过最顶尖的教育,但是在为海军与ERA工作期间获取了大量的工程经验,是典型的工程师队伍。两支团队在出身上的巨大反差令UNIVAC充满优越感,UNIVAC团队不以为意地以“工厂”“农夫们”这样的词汇来指代ERA团队,似乎在UNIVAC团队的眼中,宾夕法尼亚人的工作就是探索最前沿的理论,至于建造实际可工作的机器,则应该交给更低等的明尼苏达人。Eckert曾非常直白而粗鲁地对Norris说:ERA完全不具备创新能力[6]。种种蔑视令ERA的成员们感到异常窝火。然而站在ERA的角度上看,UNIVAC浑身上下也没几处顺眼。ERA团队虽为Eckert精湛的学识感到惊艳,但同时也震惊于UNIVAC团队对工程规则的无知。在ERA团队设计的1103型计算机接近完成时,Eckert仍然在尝试说服工程师们引入新的理论,这让ERA团队感到震惊,难道UNIVAC团队进行工程设计的时候完全不顾deadline的么?骇人听闻的是,他们竟然真没看走眼。通用电气公司向Remington Rand订购了一台UNIVAC I计算机,并筹划了与之配套的一系列媒体报道来造势,试图证明自己是一个追逐前沿技术,位于浪潮之巅的公司。不想UNIVAC团队一再更改设计,把本该在两周内交付的输入输出设备拖延了两年之久,令通用电气大发雷霆。过度苛求设计完美,忽视工程Deadline,还只是问题的一部分。未在残酷市场中成功存活过的UNIVAC团队对报价与预算毫无概念,UNIVAC的研发超支达到荒唐的五倍之多,而UNIVAC I计算机极其低劣的运作可靠性也与ENIAC一脉相承。Norris终于发现,两支团队的区别其实已经深入到哲学的层面。Norris对宾夕法尼亚人说:“ERA在经营公司,而你们经营的是实验室”。 除了来自UNIVAC团队的贬低,Remington Rand管理层对通用电子计算机商业前途的迟钝也在消磨着ERA团队的耐心。时至1956年,这个领域里的几乎每一个公司都已经意识到通用电子计算机将是下一片广阔的蓝海。而原本处于行业领先地位的ERA团队却无法从公司管理层获得足够的研发支持。IBM研发一系列新机器的动作送出了一个明显的信号,这艘几乎无人可敌的企业巨舰正在朝着这片蓝海开进。Norris等人终于按耐不住了,他们携带一部分ERA团队成员出走,自筹资金在明尼苏达州东南部城市明尼亚波利市的一间旧仓库里创办了Control Data Corperation,缩写CDC。 宾夕法尼亚人做梦也没想到,低等生物明尼苏达人竟然强横到敢于直面IBM的剑锋。卖牲口的Norris卖起电脑来比Mauchly和Eckert实在强出一筹不止。这个在初期募资时低贱到1美元1股的CDC,一度困难到只能使用次品晶体管作为原材料,却成为Norris手中令IBM俯首称臣、纵横驰骋了整个60年代的王牌部队。CDC技术团队一手制造了与核爆模拟有着千丝万缕联系的世界上第一台超级计算机,基于记分板(Scoreboarding)技术第一次实现了指令的乱序执行,第一次利用多个功能单元实现超标量执行,为今日的现代高性能处理器微结构绘制了第一份蓝图,迫使IBM的掌门人Thomas J. Watson无可奈何地写下了流传后世的“守门人备忘录”…… (图注:八年后的CDC CEO Norris与使用早期CISC体系结构的CDC 3600。图片来源www.computerhistory.org ) 开创历史的力量用这种奇妙的方式完成了从Eckert–Mauchly到CDC的转移。 而站在Norris身后充当“里子”,创造这些不世传说的人,就是当时ERA团队中一位来自明尼苏达大学的天降奇才。在CDC创立之时想要追随Norris而去的他,还因为担忧美国军方的特别关注而不得不暂留Remington Rand。 To be continued… =================================== [1]这个系列讲座英文原名Moore School Lectures,它将设计电子计算机的第一手经验传播了出去,对后世带来了深远影响。值得注意的是,这个Moore与Intel的Gordon Earle Moore并无关系。这个“Moore”代表宾夕法尼亚大学的摩尔电子工程学院 Moore School of Electrical Engineering [2]根据J. Presper Eckert与Nancy Stern在1977年所做的采访记录,逼迫二人签订新的专利协议背后似乎并没有抢夺成果用于商业目的的动机,Nancy Stern多次追问这一点,但是Eckert并未给予确认。此外,Eckert在访谈中透露,他并非如外界传闻那样是从宾大主动辞职,而是被炒了鱿鱼,只不过有一封假装“同意辞退”的礼貌信件用以掩人耳目。 [3]根据Jean Bartik的回忆,EMCC的员工被指控有“共产主义倾向”,这在麦卡锡主义盛行的年代导致EMCC失去了大批政府订单。 [4]机器预测选票结果为438 vs 93,实际结果为442 vs 89,相当接近。 [5]Norris的经营天赋在卖牲口中得到了很好的体现。Norris在老家农场期间正值美国经济大萧条和中西部旱灾,牲口没有谷物可以吃,收购商则趁机压低牲口价格。Norris决定冒险,让牲口以俄国蓟(Russian thistles)为食,成功地将牲口养至高价出售。 [6]“ERA’s creative capabilities simply didn’t exist” | |
|
(3个打分, 平均:5.00 / 5) |


