




系统领域的经典文献
作者 陈怀临 | 2014-03-18 10:47 | 类型 学术园地, 科技普及 | Comments Off
系统架构是一个工程和研究相结合的领域,既注重实践又依赖理论指导,入门容易但精通很难,有时候还要讲点悟性,很具有“伪科学”的特征。要在此领域进阶,除了要不断设计并搭建实际系统,也要注意方法论和设计理念的学习和提炼。经常有同学询问如何学习,特贴一篇学习材料,供大家参考。09年时写的,在系统领域浩如烟海的文献中提取了一些我认为值得研究和学习的项目,没包括近几年出现的一些工作,也不够全面。不过,其实也足够了,看paper是一个从少到多再到少的过程。对问题本质、背景和发展历史有大致了解,再辅以hands-on的实践(长期的真正的实践),足以摸到本领域的门径。 此文在网上转载不少,但多数没有说明出处。今天在这里重发,也顺便向315致敬。 — 对于工程师来说,到一定阶段后往往会遇到成长瓶颈。要突破此瓶颈,需要在所属技术领域更深入学习,了解本领域的问题本质、方法论与设计理念、发展历史等。以下提供一些架构相关领域的学习材料,附上简单点评,供有兴趣的工程师参考。希望大家能通过对这些领域的了解和学习,掌握更多system design principles,在自己的工作中得心应手,步入自由王国。 1. Operating SystemsMach [Intro: http://www-2.cs.cmu.edu/afs/cs/project/mach/public/www/mach.html,Paper: http://www-2.cs.cmu.edu/afs/cs/project/mach/public/www/doc/publications.html] 传统的kernel实现中,对中断的响应是在一个“大函数”里实现的。称为大函数的原因是从中断的入口到出口都是同一个控制流,当有中断重入发生的时候,实现逻辑将变得非常复杂。大多数的OS,如UNIX,都采用这种monolithic kernel architecture。 1985年开始的Mach项目,提出了一种全新的microkernel结构,使得由于70年代UNIX的发展到了极致而觉得后续无枝可依的学术界顿时找到了兴奋点,也开始了沸沸扬扬的monokernel与microkernel的争论。 插播一个花絮:Mach的主导者Richard Rashid,彼时是CMU的教授,受BillGates之托去游说JimGray加盟MS。结果把自己也被绕了进来,组建了Microsoft Research。他到中国来做过几次21Century Computing的keynotes。 Exokernel [Intro:http://pdos.csail.mit.edu/exo/,Paper:http://pdos.csail.mit.edu/PDOS-papers.html#Exokernels] 虽然microkernel的结构很好,但实际中并没有广泛应用,因为performance太差,而且大家逐渐发现OS的问题并不在于实现的复杂性,而更多在于如何提高application使用资源的灵活性。这也就是在kernel extension(例如loadable module in Linux)出现后,有关OS kernel architecture的争论就慢慢淡出人们视线的原因。 Exokernel正是在这样的背景中出现的,它并不提供传统OS的abstraction(process,virtual memory等),而是专注于资源隔离与复用(resource isolation and multiplexing),由MIT提出。在exokernel之上,提供了一套库,著名的libOS,用于实现各种OS的interface。这样的结构为application提供了最大的灵活度,使不同的application可以或专注于调度公平性或响应实时性,或专注于提高资源使用效率以优化性能。以今天的眼光来看,exokernel更像是一个virtual machine monitor。 Singularity [Intro:http://research.microsoft.com/os/Singularity/,Paper: http://www. Singularity出现在virus,spyware取之不尽、杀之不绝的21世纪初期,由Microsoft Research提出。学术界和工业界都在讨论如何提供一个trust-worthy computing环境,如何使计算机系统更具有manage-ability。Singularity认为要解决这些问题,底层系统必须提供hardisolation,而以前人们都依赖的硬件virtual memory机制并无法提供高灵活性和良好性能。在.Net和Java等runtime出现之后,一个软件级的解决方案成为可能。 Singularity在microkernel的基础上,通过.Net构建了一套type-safed assembly作为ABI,同时规定了数据交换的message passing机制,从根本上防止了修改隔离数据的可能。再加上对application的安全性检查,从而提供一个可控、可管理的操作系统。由于.NetCLR的持续优化以及硬件的发展,加了这些检查后的Singularity在性能上的损失相对于它提供的这些良好特性,仍是可以接受的。 这种设计目前还处于实验室阶段,是否能最终胜出,还需要有当年UNIX的机遇。 2. Virtual MachinesVMWare ["MemoryResource Management in VMware ESX Server",OSDI’02,Best paper award] 耳熟能详的vmware,无需多说。 XEN [“Xen and the Art of Virtualization”, OSDI’04] 性能极好的VMM,来自Cambridge。 Denali [“Scaleand Performance in the Denali Isolation Kernel”, OSDI’02, UW] 为internetservices而设计的application level virtual machine,在普通机器上可运行数千个VMs。其VMM基于isolation kernel,提供隔离,但并不要求资源分配绝对公平,以此减少性能消耗。 Entropia [“The Entropia VirtualMachine for Desktop Grids”, VEE’05] 要统一利用公司内桌面机器资源来进行计算,需要对计算任务进行良好的包装,以保证不影响机器正常使用并与用户数据隔离。Entropia就提供了这样的一个计算环境,基于windows实现了一个application level virtual machine。其基本做法就是对计算任务所调用的syscall进行重定向以保证隔离。类似的工作还有FVM:“AFeather-weight Virtual Machine for Windows Applications”。 3. Design Revisited“Are Virtual Machine Monitors Microkernels Done Right?”,HotOS’05 这个题目乍听起来,十分费解,其意思是VMMs其实就是Microkernel的正确实现方法。里面详细讨论了VMM和Microkernel,是了解这两个概念的极好参考。 “Thirty Years Is Long Enough: Getting Beyond C”, HotOS’05 C可能是这个世界上最成功的编程语言,但其缺点也十分明显。比如不支持thread,在今天高度并行的硬件结构中显得有点力不从心,而这方面则是functional programming language的长处,如何结合二者的优点,是一个很promising的领域。 4. Programming Model单使用thread结构的server是很难真正做到高性能的,原因在于内存使用、切换开销、同步开销和保证锁正确性带来的编程复杂度等。 “SEDA: An Architecture for Well-Conditioned, Scalable Internet Services”,OSDI’01 Thread不好,但event也没法解决所有问题,于是我们寻找一个结合的方法。SEDA将应用拆分为多个stage,不同stage通过queue相连接,同一个stage内可以启动多个thread来执行queue中的event,并且可通过反馈来自动调整thread数量。 Software Transactional Memory 如果内存可以提供transaction语义,那么我们面对的世界将完全两样,language, compiler, OS, runtime都将发生根本变化。虽然intel现在正在做hardware transactional memory,但估计可预见的将来不会商用,所以人们转而寻求软件解决方案。可想而知,这个方案无法base在native assembly上,目前有C#,haskell等语言的实现版本。资料比较多,参见Wikipedia。 5. Distributed AlgorithmsLogical clock, [“Time,clocks, and the ordering of events in a distributed system”, Leslie Lamport, 1978] 这是一篇关于Logic clock, time stamp, distributed synchronization的经典paper。 Byzantine [“The ByzantineGenerals Problem”, Leslie Lamport, 1982] 分布式系统中的错误各种各样,有出错就能停机的,有出错了拖后腿的,更严重的是出错了会做出恶意行为的。最后的这种malicious behavior,就好像出征将军的叛变,将会对系统造成严重影响。对于这类问题,Lamport提出了Byzantine failure model,对于一个由3f+1个replica组成的statemachine,只要叛变的replica数量小于等于f,整个state machine还能正常工作。 Paxos [“The part-time parliament”, Leslie Lamport, 1998] 如何在一个异步的分布式环境中达成consensus,这是分布式算法研究的最根本问题。Paxos是这类算法的顶峰。不过这篇paper太难了,据说全世界就3.5人能看懂,所以Lamport后来又写了一篇普及版paper:“Paxos Made Simple” ,不过还是很难懂。另外,也可参看Butler Lampson写的“The ABCD’s of Paxos”(PODC’01),其中关于replicated state machine的描述会严重启发你对并行世界本质的认识,图灵奖的实力可不是盖的。 这上面反复出现了一个名字:Leslie Lamport,他在distributed computing这个领域挖坑不辍,终成一代宗师。关于他,也有几则轶事。记得以前他在MSR的主页是这么写的,“当我在研究logicalclock的时候,BillGates还穿着开裆裤(in diaper)…”(大意如此,原文现在找不到了)。另外,他在写paper的时候,很喜欢把其他牛人的名字变换一下编排进去。这可能也是他还没拿到图灵奖的原因。 关于Lamport的其他成就,还可以参见这篇向他60岁生日献礼的paper:“Lamport on mutual exclusion: 27 years of planting seeds”, PODC’01。 6. Overlay Networking, and P2P DHTRON [“Resilient Overlay Networks”, SOSP’01] RON描述了如何在应用层搭建一个overlay,以提供秒级广域网网络层故障恢复速度,而现有的通过路由协议来恢复通信的时间至少在几十分钟。这种快速恢复特性和灵活性使得overlay networking现在被广泛应用。 Application Level Multicast “End System Multicast”, SigMetrics’00 “Scalable Application Layer Multicast”, SigComm’02 关于ALM的paper很多,基本上都是描述如何搭建一个mesh network用以鲁棒的传输控制信息,另外再搭建一个multicast tree用以高效传输数据,然后再根据多媒体数据的特点做一些layered delivery。前几年出现的coolstream, pplive等系统都是这类系统的商业化产品。 P2P P2P的出现改变了网络。按照各种P2P网络的结构,可以分为三种。 1. Napster式,集中式目录服务,数据传输Peer to peer。 2. Gnutella式,通过在邻居间gossip来查询,也被称为unstructured P2P。 3. DHT,与unstructured P2P不同的是,DHT进行的查询有保证,如果数据存在,可在一定的hop数内返回。这个hop数通常为logN,N为系统节点数。 典型的DHT有CAN, Chord,Pastry, Tapestry等四种。这些研究主要在算法层面,系统方面的工作主要是在其上建立广域网存储系统。还有一些人在机制层面进行研究,例如如何激励用户共享、防止作弊等。 7. Distributed SystemsGFS/MapReduce/BigTable/Chubby/Sawzall Google的系列paper,大家比较熟悉,不再多说。在此可查。 Storage Distributed storage system的paper太多了。下面列出几篇最相关的。 “Chain Replication for Supporting High Throughput and Availability”, OSDI’04。 “Dynamo: Amazon’s Highly Available Key-value Store”,SOSP’07。 “BitVault: a Highly Reliable Distributed Data Retention Platform”, SIGOPS OSR’07。 “PacificA: Replication inLog-Based Distributed Storage Systems”, MSR-TR。 Distributed Simulation “Simulating Large-Scale P2P Systems with the WiDS Toolkit”, MASCOTS’05。Distributed simulation有意思的地方是simulated protocol是distributed的,而这个simulation engine本身也是distributed的。Logical和physical的time和event交杂在系统中,需要仔细处理。 8. Controversial Computing Models现在的软件系统已经复杂到了人已经无法掌握的程度,很多系统在发布时都仍然带着许多确定性(deterministic)或非确定性(non-deterministic)的bugs,只能不断的patch。既然作为人类,不够精细的特性决定了我们无法把系统的bug fix干净,我们只能从其他角度入手研究一种让系统在这令人沮丧的环境中仍能工作的方法。这就像一个分布式系统,故障无法避免,我们选择让系统作为整体来提供高可靠性。 以下3个便是典型代表。基本上,主要研究内容都集中于1) 如何正确保存状态;2)如何捕捉错误并恢复状态;3)在进行单元级恢复时,如何做到不影响整体。 Failure oblivious computing, OSDI’04 Treating Bugs as Allergies, SOSP’05 9. Debugging系统很复杂,人类无法从逻辑上直接分析,只能通过data mining的方法在宏观上进行观察。 Black box debugging[“Performance debugging for distributed systems of black boxes”, SOSP’03] 对大型系统的performance debugging非常困难,因为里面的问题很多都是非确定性的,而且无法重现。只能通过对log的挖掘,找出配对的调用/消息以定位问题。 CP-miner [“A Tool for Finding Copy-paste and Related Bugs in Operating System Code”, OSDI’04] 很多人在重用代码的时候,都使用copy-paste。但有时候简单的CP会带来严重的问题,例如局部变量的重名等。CP-miner通过分析代码,建立语法树结构,然后mine出这类错误。 | |
 (11个打分, 平均:5.00 / 5) (11个打分, 平均:5.00 / 5) |
NAND FlashNANDNOR
作者 冬瓜头 | 2014-02-28 17:06 | 类型 存储设备, 科技普及 | 1条用户评论 »
|
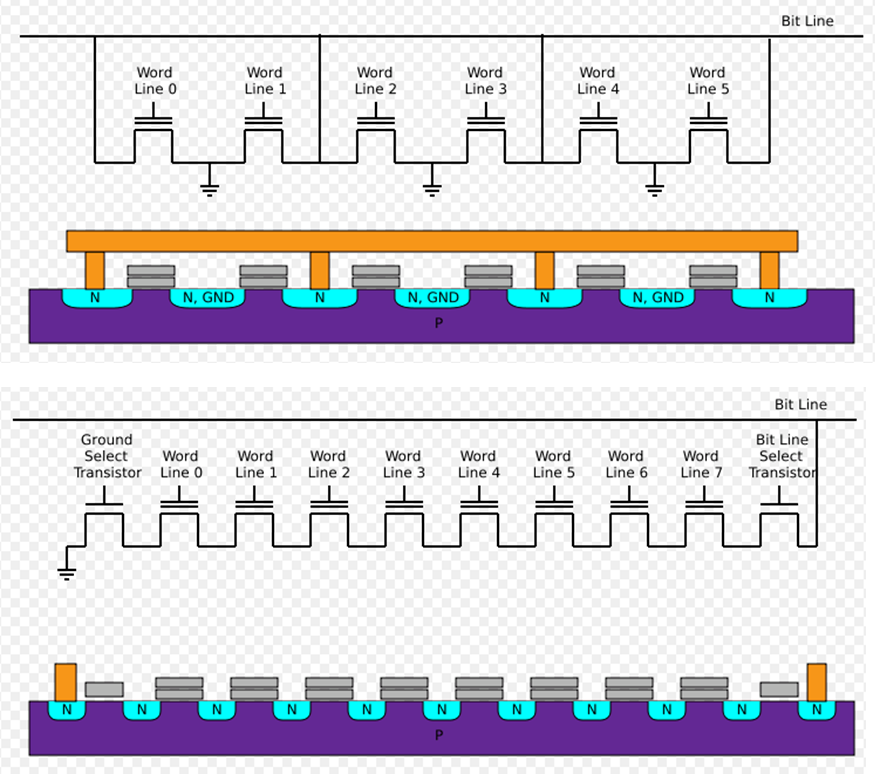
很多人只知道NAND Flash却不知道NOR Flash,知道NAND Flash却不知道“NAND”和“NOR”是什么意思,以及其底层机制。本文做了说明。由闪存前沿厂商@PMC官方微博 提供支持!更多内容可参考《大话存储2》修订版。这里不过多叙述NAND Flash基础原理和知识。 当需要读出某个Page时,Flash Controller控制Flash芯片将相应这个Page的字线,也就是串连(实际上属于并联)同一个Page中所有Cell上的CG的那根导线,电势置为0,也就是不加电压,其他所有Page的字线的电势则升高到一个值,也就是加一个电压,而这个值又不至于把FG里的电子吸出来,之所以抬高电势,是为了让其他Page所有的Cell的S和D处于导通状态,而没被加电压的Cell(CG上的电势为0V),也就是我们要读取的那些Cell,其S和D的通断,完全取决于其FG中是否存有电子。说白了,未被选中的所有Cell,均强制导通,被选中的Cell的FG里有电,那么串联这一串Cell的位线就会被导通,这是一种AND也就是与的关系;被选中Cell的FG里如果没电,那么其所处的Cell串的位线就不能导通(虽然串上的其他Cell均被强制导通),这也是AND的关系。也就是一串Cell,必须全导通,其位线才能导通,有一个不导通,整条位线就不通。这就是NAND Flash中的“AND”的意义。那“N”表示什么?N表示Not,也就是非,NAND就是“非与”的意思。为什么要加个非?很简单,导通反而表示0,因为只有FG中有电才导通,上文也说了,FG中有电反而表示0,所以这就是“非”的意义所在。 还有一类NOR Flash,NOR就是“非或”的意思,大家自然会想到,位线一定不是串联的,而是并联的,才能够产生“或”的逻辑。实际上,在NOR Flash里,同样的一串Cell,但是这串Cell中的每个Cell均引出独立的位线,然后并联接到一根总位线上,另外一点很重要的是,每个Cell的S和D之间虽然物理上是串连,但是电路上不再是串联,而是各自有各自的接地端,也就是每个Cell的S和D之间的通断不再取决于其他Cell里S和D的通断了,只取决于自己。以上两点共同组成了“或”的关系,同时每个Cell具有完全的独立性,此时只要通过控制对应的地线端,将未被选中的Cell地线全部断开,这样它们的S和D极之间永远无法导通(逻辑0状态),由于每个Cell的位线并联上联到总位线,总位线的信号只取决于选中的Cell的导通与否,对于被选中的Cell,NOT {(“地线接通”AND“FG是否有电”)OR “未被选中Cell的输出”} = “总位线的1/0值”,这就是NOR非与门的逻辑。 由于NOR Flash多了很多导线,包括独立地线(通过地址译码器与Cell的地线相连)和多余的上联位线,导致面积增大。其优点是Cell独立寻址,可以直接用地址线寻址,读取效率比NAND要高,所以可以直接当做RAM用,但是写入时由于擦除效率比NAND低,所以不利于写频繁的场景。
| |
|
(3个打分, 平均:5.00 / 5) |
RISC的前世今生
作者 陈怀临 | 2014-01-28 15:25 | 类型 科技普及 | 2条用户评论 »
|
[编者注:原文可参阅:http://blog.sina.com.cn/s/blog_685fc2ec0101h1ws.html ] 【注:本文缩减版已发表在电脑报2013年第44期 A.新闻周刊,这个版本是写给实验室内部刊物《国重快讯》的加长版,写作过程中得到中科院计算所包云岗老师的大力指点,在此表示感谢。】 导语:RISC与CISC两大体系结构设计哲学的争斗已经成为大家耳熟能详的历史,但是RISC的由来,在学术界和工业界以外却很少见到有人提及。本文基于伯克利RISC项目领导者之一David Patterson的口述自传以及ACM数据库的公开文献整理,向大家介绍RISC从发明到广为流传的那段故事。
三十年前的论战
“我们认为,基于RISC理念设计的处理器只有在极少数情况下慢于CISC处理器……过多的指令使得CISC处理器的控制逻辑复杂……研发成本上升……编译器也不知道该如何利用这么复杂的指令集……CISC的设计思路应当反思。” —— RISC的早期倡导者之一,David Patterson
“RISC与CISC的区别缺乏明确定义,而且RISC缺乏有力实验证明其宣称的优势,仅停留在纸面的设计是不够的,我们在VAX结构的设计中发现很多与RISC理念相反的地方……实验数据证明RISC的出发点有误……”—— CISC结构的设计者代表,Douglas W. Clark和William D. Strecker. 时势造英雄,在1980年前后,几乎所有的新处理器设计都在按照CISC的路线发展,惯性的车轮越滚越远,CISC不断加入新的指令,使用微码控制,试图在指令集架构层面对高层编程语言提供更直接的支持,这种发展路线使得硬件研发成本不断提高,研发周期变长,最终甚至殃及软件,连编译器都不知道该如何利用越来越复杂的指令集。CISC流派的不断前推,实质上是令体系结构在错误的发展方向上越陷越深。来自IBM研究院的John Cocke首先意识到,更加精简清爽的指令集设计将有助于减少硬件开发难度和成本,同时也有利于编译器进行代码优化工作,于是在他领导下的IBM 801项目第一次对RISC的概念进行了实践,这项起步于1975年的项目,直到80年代后才将成果公开发表,其中就包括改变了产业技术格局的graph coloring寄存器着色算法。稍落后于IBM研究院,来自加州大学伯克利分校,斯坦福大学的几位科学家也逐渐认清CISC的弱点,开始尝试反其道而行之,着手进行新的设计。那时刚刚博士毕业四年,在伯克利任教的年轻老师David Patterson就是其中一员,他决定在研究生课程中检验自己的想法,让学生们试着构建一个指令精简化的微处理器作为大作业。
在微处理器流片成功之前,David就撰写了文章发表在《计算机体系结构通讯》上,描述自己构建处理器的新方法,认为这种精简设计将降低硬件设计成本,缩短开发周期,方便编译器进行代码生成,达到更高的性能,结果引起争论和质疑,于是有了这场载入体系结构发展史的论战。 反败为胜
ACM数据库收录的影印文档中保留下的点点墨迹,似乎象征着这场论战中四溅的火星。当时站在David对立面的人,包括当时深受尊敬的VAX CISC结构设计者Douglas W. Clark和William D. Strecker,David在文章中大量转述VAX的工程经验,试图证明RISC的优势,但VAX结构设计者们的现身说法使得局面对David非常不利,他们以自己的第一手数据将David文章中宣称的RISC优势逐一驳倒,而David手中并没有自己的硬件实测数据,十分被动。更加雪上加霜的是,第一组学生们流片回来的处理器,并未能体现出具备说服力的速度优势,其主频尚不到当时部分商业级芯片的三分之一,于是进一步引发了嘲笑。 所幸第二组学生进行的设计较为成功,于是David和学生们的成果得以登陆1983年国际固态电子电路大会(ISSCC)进行展示,这个会议只接受流片成功的芯片设计投稿,因此门槛较高,同时也因为成果卓越,受到学术界和工业界的广泛关注,是集成电路领域的顶级学术会议。David在这里打了一个漂亮的翻身仗,尽管制造工艺是老旧的MOSIS,主频仍旧比VAX,摩托罗拉,Intel等竞争对手同期制造的处理器慢上几乎一半,晶体管数量也只有几分之一,但是更加清爽的新式设计在编译器等其他工具的辅助下竟然将来自工业界的竞争对手们尽数击败,完成了漂亮的反击。David领导的学生团队凭借这一全新理念进行的课程设计,仅有区区几十条指令,竟胜过指令数目多达几百条的商业级芯片,这一事实对于CISC流派的支持者们是极大的冲击,ISSCC大会现场所有的大牌人物都目睹了这一历史性时刻,业界哗然。RISC提倡简化指令集设计,固定指令长度,统一指令编码格式,加速常用指令,在当时来看与当时占据主流的CISC哲学颇有些背道而驰的意味,RISC和David Patterson早年受到质疑和攻击也就不难理解。但有了流片成功的芯片与硬件测试结果在手,加之1983年的ISSCC大会上聚集了几位与David Patterson观点相同的支持者,RISC流派已经开始占据上风。
风靡业界
出于兼容性的考虑,David和学生们设计的芯片从未流入商业市场售卖,但是在David等人的推动和宣传下,RISC的设计理念随后如星火燎原般扩散,一大批公司开始采用这种理念设计新处理器,包括后来几近统一武林的Intel。而当初提倡RISC的先行者们也纷纷功成名就,John Cocke在1987年将计算机科学领域的最高奖项“图灵奖”收入囊中,而David Patterson在芯片设计与计算机体系结构领域也已经与“泰山北斗”划上等号。
RISC的设计理念催生的一系列新结构中包含了许多我们耳熟能详的名字,包括学术上认为比较成功的DEC Alpha,后来写入经典教科书的MIPS,绕过指令级并行度障碍,追求线程级并行的SUN SPARC,以及现在统治嵌入式市场的ARM。这些雨后春笋般涌现的RISC处理器将CISC vs RISC的世纪之战推向更高潮,复杂指令集和精简指令级划分为两个阵营,争论不断。以x86为代表的复杂指令集,其指令编码格式混乱,导致编码器复杂,流水线设计较为困难,指令不定长也带来指令对齐方面的额外挑战。而RISC指令集的编码格式相对整洁,流水线设计容易,但是由于指令定长,导致一些比较大的常数\地址必须拆散才能加载,代码密度不够高,某些情况下会浪费指令缓存的容量和带宽,因此两种指令集都不是不败金身,本质上都属于双刃剑。在计算机体系结构还未发展成熟的时候,内存与编译器的缺憾给CISC留下了立足之地,但随着编译技术的进步以及存储体系的进化,程序大小所带来的间接优势越来越不明显,而RISC指令集上能够简化流水线设计,这项优点对架构师们反倒越来越具有吸引力,以至于连Intel都举棋不定,只得两条腿走路。Intel在继续更新CISC产品线的同时,也推出了i860系列RISC处理器,安迪•格鲁夫当时表示,CISC处理器是Intel一直在做的产品线,兼容所有软件,而RISC处理器速度更快,但没有什么软件能在它上面运行。连Intel都不知道未来发展方向会是在RISC还是CISC,只好两头下注。在风头最劲的时候,RISC处理器一度在服务器市场占据统治地位。当时的争论与工业实践中提炼出的RISC优势,直到现在仍被许多人谈论,但是,历史的进步无情地碾碎了这一切。
融为一炉 强大的Intel进入90年代后开始逐渐发力,追赶性能领先的RISC阵营,在90年代中期的P6结构里,Intel引入了乱序多发射技术,从微结构的角度上看,这标志着 Intel已经在CISC阵营中拔得头筹,但与当时RISC阵营中的旗舰之一MIPS R10000相比仍有不足,与另一龙头DEC Alpha更无法相提并论。值得一提的是,P6第一次实现了CISC指令集在解码阶段上向RISC类指令的转化,将后端流水线转换成类RISC的形式,弥补了CISC流水线实现上的劣势。许多人认为这是Intel在向RISC指令集学习,是在事实上宣布了RISC的胜利,可是ARM也于同期引入了代码密度更高的Thumb新指令集,力图提高指令缓存等劣势项目上的效率,这表明RISC也在向CISC取经,双方都在相互取长补短。而RISC风格的设计的确能输出速度优势,这在一部分人心目中催生了错误的RISC优越论。实质上随着体系结构和微电子技术的进步,CISC在结构上的所谓劣势逐渐缩小,乃至消失, 而RISC阵营却在Intel的猛攻下节节败退,时至今日,Intel的服务器CPU占据了95%的市场份额,RISC的优越论也逐渐偃旗息鼓,大家开始转而关注微结构与物理设计实现,并发掘操作系统、编译器与上层应用当中埋藏的可能性。 在P6这一微结构中,Intel第一次引入RISC风格的流水线 今年的国际高性能计算机体系结构大会上,来自美国威斯康辛大学的一个研究小组做了一个测量分析报告,根据他们披露的测试数据,CISC与RISC在指令集架构层面上的差异已经被弥合,在Cortex-A8以上级别的处理器中,由先进的微结构和物理设计、工艺实现带来的改进足以掩盖指令集架构层面的劣势。因此我们可以说,CISC vs RISC的世纪之战实际上没有胜负,双方的精华已经融为一炉。结果这个报告受到一些学者的批评,有意思的是,批评的原因并不是在于报告本身结论错误,而是因为这个报告所得出的结论,其实是大家早都已经认可的共识,没有必要再在大会上宣读! 如何评价一个结构设计理念是好是坏呢?笔者认为,应当是后人们看来理所当然的 —— “为什么不这样做呢?还好当初没有放弃这条路!”今天我们谈到RISC留下的遗产时,已经很难找到负面评价的理由,RISC不再是缺乏支持的异类,而是现代计算机体系结构的基本组成部分之一,没有人再对RISC存在的必要性提出怀疑,这大概就是对它最好的认可。 参考文献 [1] Douglas W. Clark and William D. Strecker. Comments on “The Case for the Reduced Instruction Set Computer,” by Patterson and Ditzel. ACM SIGARCH Computer Architecture News, 1980. 8(6), pp. 34-38. | |
  (3个打分, 平均:3.67 / 5) (3个打分, 平均:3.67 / 5) |
The Evolution of Operating System
作者 陈怀临 | 2014-01-25 07:09 | 类型 学术园地, 科技普及 | 2条用户评论 »

Yan Dong SOSP 2013 Analysis
作者 陈怀临 | 2013-11-11 16:48 | 类型 科技普及 | 3条用户评论 »
|
NOV 9TH, 2013
SOSP 2013共计30篇论文, 分成9个session. 其每逢奇数年召开, 今年是第24届, 而OSDI在偶数年召开, 去年是第10届. 作为一个有将近50年历史的老牌会议, SOSP一直严格控制论文的数量. 相比于SIGGRAPH动辄上百篇, KDD同时四个分会场, 系统界还是相对保守的. 从这两年的SOSP/OSDI上看, 论文的标题趋向文艺, 内容也更加丰富有趣. 每年会议设置的session完全根据投稿内容而定, 没有事先指定的topic, 因此很能反映学术界和工业界当前的潮流. 世界范围内, 基本上只有最顶尖的20所大学和机构能够比较稳定的在SOSP/OSDI上灌水, 其他学校可能十几年才冒出来一个天纵奇才的哥们中一篇. 顺带提一句, 欧洲只有三所学校在系统方面能够在最顶级的会议上灌水, 分别是Cambridge, ETH和EPFL, 剩下所有的学校都在美国. 国内完全本土培养起的系统届大牛”陈海波”(复旦本硕博,现为上交的教授), 在2011年的时候给<中国计算机学会通讯>写了一篇论述系统届各大会议及研究方法的文章一名系统研究者的攀登之路. 就是由于他在SOSP11上发表了国内第一篇不与国外的工业界(如MSRA, Google)合作而独立完成的顶级论文(CloudVisor), 讲如何在云上使用虚拟机技术进行安全保护的. 三年前他曾来清华与我们组交流过一次, 介绍了他们组当时的四个工作, 为人非常谦恭有礼. 这篇SOSP11发表后不久, 就被上海交通大学挖了过去, 直接给了正教授. 开始正题, 后面的文章中若碰到我熟悉的学校, 实验室和教授我会一一介绍. Session 1: Juggling Chainsaws, Chair: Rebecca Isaacs这个session的主席Rebecca Issacs是微软的一名女性研究员, 发表了一堆的顶级论文. 无独有偶, 本session下第二篇文章中的作者Barbara Liskov也是一名女性,可见系统虽然苦, 但并不是纯爷们的领域.
本文考察了interface(如system call)对软件扩展性的影响. 核心问题是, 如果把接口和实现良好的分离开来, 那接口的设计中是不是就蕴含了一些天然的限制, 使得无论怎样实现, 都无法突破这些天然限制. 作者编写了一个称为COMMUTER的工具, 以及一个原型操作系统SV6. 实验表明对COMMUTER产生的13664个test而言, linux能对其中的68%良好扩展, 而SV6能良好扩展其中的99%. 这个问题我以前也想到过, 掂量了下自己的能力和完成这个idea的工作量, 就知难而退了. 他们在文中实现的SV6应该不是白手起家. 因为他们组一直在用一个名为XV6的教学操作系统给本科生上操作系统的课程, 我猜这个SV6就是XV6的改型. COMMUTER工具是另外一个硬活, 需要Frans教授这样在系统界摸爬滚打的数十年的经验来指导, 才能真正指出interface内涵的限制. 相比之下, 就算我自己再头悬梁锥刺股的去在上面改一个原型系统出来. 没有这样真正懂得OS的大神指导, 也是没可能完成这样的论文. 这篇文章来自大名鼎鼎的MIT CSAIL实验室下的PDOS小组, 五个作者中的三个我都很熟悉. Frans Kasshoek教授是在SOSP/OSDI上发表论文最多的作者, 曾担任了三年清华的客座教授, 可能后来嫌我们学校烂泥扶不上墙就没再来了……Frans教授师承自系统届祖师爷级别的人物Andrew S. Tanenbaum, 如今在系统届活跃的研究人员向上追溯师承关系有几乎一小半都可以追到Andrew身上. 我曾听过两次Frans的讲座, 给我印象最深刻的是, 有次我坐在第二排, 正在嘉宾席后面. 他讲完自己的topic之后, 坐在嘉宾席上等待他手下的一个faculty讲另一个topic. 竟然分分钟掏出个Thinkpad打开VIM界面就开始编程了. 当时Frans已经是美国工程院院士了, 年龄也超过了50岁, 竟然还抓紧这种零散时间写程序. 这是我个人见到的最高龄的, 也很可能是最高水平的程序员现场编程. Nickolai Zeldovich曾经在去年跟我合作过一篇文章, 也是他们到清华讲座. 我发现这哥们懂symbolic execution, 当时我正好有一个idea, 就上去跟他套磁. 他表示pretty cool, 最后就做了篇文章出来, 但不幸跟EPFL的发表在PLDI 12上的一篇文章撞车了, 于是这篇文章只能躺在我的硬盘深处, 没机会再去推动人类进步. 当时跟这哥们的合作主要是通过email, 我把文章发给他, 他给我提建议应当如何继续试验, 如何分析结果, 包括文章内容的取舍, 短短几封信就受益匪浅. 顺便一提, 这哥们是stanford的博士, 期间主要是搞信息流的, 写了第一个支持信息流的操作系统原型HiStar. 学术界一直企图用信息流去在理论上优美的解决信息的控制, 审计等问题, 但据我所知好像一直没在工业界得到大规模的应用. Robert Morris, 单看这个名字大家可能看着有点眼熟. 没错, 就是他, 1988年在Cornell读研究生的时候发布了世界上第一个蠕虫. 他爹也是个大名鼎鼎的Morris, 曾任美国国家计算机安全中心(隶属于美国国家安全局NSA)首席科学家. 称得上是老子搞安全, 儿子来捣蛋. 以前我第一次读到这哥们的论文的时候, 去他们实验室主页瞎晃, 发现MIT开了一门计算机安全的课程. 课程的introduction就把这位开启蠕虫时代的活化石拉到eager young man们面前, 讲述自己的心路历程… 多核上的扩展性是PDOS小组的传统方向, 从Frans教授算起已经折腾了20多年, 这也是为什么Frans教授是二作, 而Nickolai是三作, 因为Nickolai的主研方向是信息流, 而这样超一流实验室发表的文章的作者顺序, 真的是按贡献大小排序的. 两年前我还在折腾Linux Kernel的时候, 正碰上他们组发表了一篇修改Linux内核的锁实现, 以在众核(单机超过32核)情况下提升应用性能的文章. 文章效果非常好, 使用的几个workload都达到了近乎线性的加速比. 我在学术讨论会上报告这篇文章的时候, 大老板听闻这篇文章只不过编写了1600+行代码, 大手一挥让我们大干快上, 也搞个类似的出来. 可是改内核这种事情, 别说修改1600行, 就是改一行代码, 想要知道在哪里修改能够取得预期的效果, 对普通的博士生来说其背后的工作量都是难以估算的. 不知道他们的技术如今是否被并入了linux kernel distribution的 mainline. 他们组的研究方向相对传统, 很少去赶时髦. 往往是去深入考察一些大家都习以为常的系统的设计和实现, 从中发现改进的机会, 工作都特别的硬. 这个组曾经是我的dream team, 因此对他们的情况比较了解, 在这里介绍的比较多.
这篇文章是in-memory浪潮的又一体现, 从头实现了一个新的database, silo. 尽量避免所有可能产生数据竞争的设计, 比如transaction ID的分配. 核心贡献是一个commit protocol, 号称能够提供极好的扩展性. 使用TPC-C做测试, 在一台32核机器上能够每秒处理7000000个transactions, 数倍于之前的记录. 许多次跟新的朋友聊起我的研究方向的时候, 我的开场白都是”我们系统界是夕阳产业”. 早在千年之交的时候, Rob Pike大神就做过报告<Systems Software Research is Irrelevant>, 在其中明确表示我们的黄金时代已经过去了, 纯粹的系统研究已经很难再出现破坏性的新idea了. 牛逼的idea只有那些, 已经被大家不知道轮了多少遍了. 所以现在不得不开始走结合的路线, 如软件跟硬件的co-design; OS跟Application的配合(即研制domain specific的kernel); 以及最普遍的Hybrid, 在几个方向上都有所改进, 然后攒在一起, 获得一个considerable improvement, 象这篇文章一样. 四作Barbara Liskov奶奶, 是2008年的图灵奖获得者, 以表彰其在数据抽象, 容错和分布式系统上的卓越贡献. 巴奶奶近些年比较出名的文章是”Practical Byzantine Fault Tolerance“, 发表在99年的SOSP上. 巴奶奶也是历史上第二位女性图灵奖得主. 多提一句, 2006年Frances E. Allen由于在编译器优化和自动并行化领域的奠基性贡献而成为第一位获得图灵奖的女性. 这两位奶奶干的都是系统届最硬的活, 真是名符其实的tough granny. | |
|
(4个打分, 平均:5.00 / 5) |
H3C . 《网络之路》(15-19)
作者 陈怀临 | 2013-09-13 22:00 | 类型 弯曲推荐, 数据中心, 科技普及, 网络安全, 通讯产品 | 4条用户评论 »
H3C . 《网络之路》(14)-监控专题
作者 陈怀临 | 2013-09-13 15:05 | 类型 科技普及, 通讯产品 | Comments Off

Jeff Dean: 谷歌大型基础软件建设的经验教训
作者 陈怀临 | 2013-09-12 22:44 | 类型 云计算, 数据中心, 科技普及 | Comments Off

谷歌:The Datacenter as a Computer (第二版)
作者 弯曲评论 | 2013-09-12 15:36 | 类型 数据中心, 科技普及 | Comments Off

H3C .《网络之路》(13)-WLAN
作者 陈怀临 | 2013-09-08 11:27 | 类型 科技普及, 通讯产品 | 2条用户评论 »
