




OpenFlow技术及应用模式发展分析
作者 老韩 | 2011-05-21 10:34 | 类型 互联网, 弯曲推荐, 新兴技术 | 88条用户评论 »
|
近来OpenFlow的话题比较多,INFOCOM上清华土著又给上了一课,就找了些资料学习了一下,顺带编写了这篇科普文章。感谢许多朋友在撰写过程中的帮助和启发,另外yeasy兄发在弯曲的系列文章也非常有价值。很喜欢LiveSec团队的开放心态,希望能帮他们的产品和理念做尽量广泛的传播。 原文发于《计算机世界》。顺带说下,最近要做NFGW的选题了,感兴趣的朋友来找我吧,Email和GTalk是hanxu0514 aT gmail dOt com。
4月10日至15日,第30届IEEE计算机通信国际大会 (INFOCOM 2011)在上海国际会议中心隆重举行。本次会议吸引了国内外1000多名计算机和通信领域的专家、学者和企业的科研人员到场,重点围绕云计算、网络安全、数据中心网络、移动互联网、物联网等一系列研究领域的前沿问题进行了深入的探讨。在倍受关注的现场展示环节中(Live Demo),来自清华大学信息技术研究院网络安全实验室的师生们展示了基于OpenFlow的网络安全管理系统LiveSec,引起了与会者的普遍关注。该系统的成功运行,是国内通信领域的研发团队对前沿技术跟踪、创新工作的完美诠释,在科研成果转化为可用产品的道路上占据了先机。 OpenFlow扬帆起航 OpenFlow技术最早由斯坦福大学提出,旨在基于现有TCP/IP技术条件,以创新的网络互联理念解决当前网络面对新业务产生的种种瓶颈,已被享有声望的《麻省理工科技评论》杂志评为十大未来技术。它的核心思想很简单,就是将原本完全由交换机/路由器控制的数据包转发过程,转化为由OpenFlow交换机(OpenFlow Switch)和控制服务器(Controller)分别完成的独立过程。转变背后进行的实际上是控制权的更迭:传统网络中数据包的流向是人为指定的,虽然交换机、路由器拥有控制权,却没有数据流的概念,只进行数据包级别的交换;而在OpenFlow网络中,统一的控制服务器取代路由,决定了所有数据包在网络中传输路径。OpenFlow交换机会在本地维护一个与转发表不同的流表(Flow Table),如果要转发的数据包在流表中有对应项,则直接进行快速转发;若流表中没有此项,数据包就会被发送到控制服务器进行传输路径的确认,再根据下发结果进行转发。 OpenFlow网络的这个处理流程,有点类似于状态检测防火墙中的快速路径与慢速路径的处理,只不过转发与控制层面在物理上完全分离。这也意味着,OpenFlow网络中的设备能够分布部署、集中管控,使网络变为软件可定义的形态。在OpenFlow网络中部署一种新的路由协议或安全算法,往往仅需要在控制服务器上撰写数百行代码。加州大学伯克利分校的Scott Shenker教授对此有着很到位的评价:“OpenFlow并不能让你做你以前在网络上不能做的一切事情,但它提供了一个可编程的接口,让你决定如何路由数据包、如何实现负载均衡或是如何进行访问控制。因此,它的这种通用性确实会促进发展。” 在得到学术界的普遍认可后,工业界也开始对这项新技术表达出浓厚的兴趣。OpenFlow已经在美国斯坦福大学、Internet2、日本的JGN2plus等多个科研机构中得到部署,网络设备生产商思科、惠普、Juniper、NEC等巨头也纷纷推出了支持OpenFlow的有线和无线交换设备,而谷歌、思杰等网络应用和业务厂商则已将OpenFlow技术用于其不同的产品中。就在半个月前,以OpenFlow为产品核心设计理念的初创企业Big Switch Networks成功完成了总额1375万美元的第一轮融资,标志着资本市场对这项新技术及其发展前景的充分认可。目前,OpenFlow的推广组织开放网络基金会(Open Networking Foundation)的成员基本涵盖了所有网络及互联网领域的巨头。 好用才是硬道理 使用新技术的代价往往十分高昂,好在OpenFlow具有足够的开放性,给在传统网络中的融合实现带来可能。清华大学信息技术研究院网络安全实验室在本届INFOCOM大会上现场展示的部署在清华大学信息楼内的LiveSec网络安全系统,就是一个非常好的范本。该系统在传统的以太网之上,通过无线接入技术和虚拟化技术引入了基于OpenFlow协议的控制层,显著降低了构建成本。
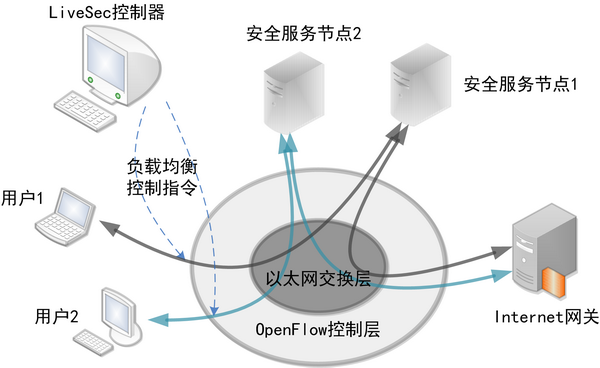
LiveSec网络安全系统包含三层架构:
基于上述架构,LiveSec相对传统的安全部署模型具有多重优势。首先,该系统解决了安全设备的可扩展问题。通过全局细粒度的负载均衡,LiveSec支持安全设备在网络的任意位置进行增量式部署。新部署的节点会按照OpenFlow协议自行入网,并自动将控制权交由LiveSec控制器。所有的用户和服务节点均可在LiveSec网络内动态迁移,包括无线接入和虚拟机的无缝迁移。记者在展示现场尝试进行了基于虚拟机的服务节点动态加入网络的实验,当具有安全检测能力的虚拟机加入网络中时,LiveSec的可视化界面会显示出该虚拟机在网络中的拓扑及其具备的业务能力(如杀毒功能,协议识别功能等)。LiveSec控制器会依据新增节点的处理能力将需要安全处理的网络流量均衡到新的节点上,从可视化界面中也可以看到新增节点引起的链路流量变化。
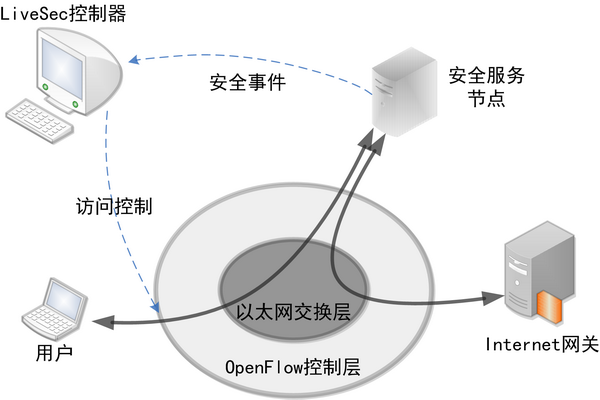
传统网络中,安全设备一般被部署在边缘,对进出流量进行访问控制。这种方式虽然成熟有效,对内网中的安全问题却无能为力。LiveSec创新的交互式访问控制特性则能很好地解决这一难题,由于系统提供了安全节点到控制器的信息交换通路,并针对安全事件设计了一套信息交换协议,LiveSec可以根据安全节点传来的安全事件,在用户接入层实施访问控制。这意味着,该系统做到了全网的点到点安全控制,任何攻击流量在不离开接入交换机的情况下就被扼杀在萌芽状态,内网安全的顽疾可以从根本上得到解决。
在OpenFlow网络中,控制服务器管控着所有的数据流,又能实时感知其他节点的状态,为可视化提供了足够的基础。记者在展示中看到,LiveSec结合OpenFlow协议以及应用层业务识别服务节点,将网络中所有的拓扑、流量、应用、安全变化都按照统一格式写入中央数据库,并在动态界面中实现了包括当前状态及历史事件回放在内的全网业务可视化。当使用无线设备的用户通过OpenFlow无线路由器接入后,立即会显示在系统的可视化界面中。该用户上网所涉及的应用层协议,也会实时显示在用户图标一侧。当用户访问不良网站或者进行攻击时,图标上会出现红色警示,LiveSec也会依据安全策略在用户接入端实时阻止用户的部分或所有流量。历史回放功能也相当实用,可以回放特定时间段内LiveSec的所有事件,攻击发起者包括地理位置在内的所有信息均可以通过数据库查找获取。 图4. 在清华大学信息楼部署的LiveSec系统 商业模式定成败 虽然OpenFlow网络从根本上解决了传统网络存在的很多问题,却也因标准化过程刚刚起步,缺乏大众化的、实用的落地方案,至今仍然多被用于各类实验性质的网络。在其发展的道路上,势必还要经历扩大用户规模和商业模式创新两大阶段。而纵观近年来IT行业巨头们的发展情况,缔造一个成功的商业模式,其重要性显然远远超过了技术创新。
未来的数据中心网络越来越趋向于由虚拟机和服务器群所组成,数据中心的交换架构则趋向扁平,使用高性能交换机群组或clos 网络甚至可以支持百万个节点的无阻塞互联。在这种情况下,网络服务质量及高可用性成为用户最为关心的问题。以LiveSec为代表的基于OpenFlow的网络操作系统支持网络设备的分布式部署,有效避免了单点失效问题。控制服务器的分布式部署,则可以利用分布式哈希技术同步全网拓扑和策略。当网络出现局部故障时,系统可以利用OpenFlow协议迅速构建全新的互联拓扑,甚至可以为不同的业务和应用分别构建不同的拓扑,以满足安全和服务质量的需求。这又是新的商业机会,试想一下,在OpenFlow网络的支持下,IaaS提供商可以为用户交付一个独一无二的网络,用户甚至可以自行设定数据流在本网内的路径和安全策略,而不仅仅是几个虚拟设备的控制权。 从系统实现模式的角度看,LiveSec的模式是构建网络操作系统(基于开源项目Nox),这个发展方向已经被许多业内人士所认同。不管对象是桌面还是网络,操作系统存在的根本意义都是管理设备和提供编程接口。众所周知,想发挥一块高性能显卡的处理能力,必须先安装该硬件的驱动。基于OpenFlow的网络操作系统也是如此,仍以LiveSec为例,所有OpenFlow交换设备和安全服务节点都可看作网络系统中的硬件设备,安全业务的实现则通过服务节点上的软件完成。当新的服务节点加入网络时,LiveSec控制器首先要知道这个节点能处理什么业务,以及如何与设备建立通信机制,才能让安全处理的执行者和决策者有效地互动起来。出于商业层面的考虑,这种机制的建立往往由服务提供者主动告知控制器,需要一个与电脑安装硬件驱动十分相似的过程。对网络管理者来说,这个步骤简化了部署及使用难度;而对设备制造商而言,这种方式也有利于将现有针对传统网络的产品快速移植到OpenFlow网络中。 受当前流行的运营模式影响,基于OpenFlow的网络操作系统也在加入更多的应用发行元素。当用户在控制台中添加服务如同在App Store获取应用般便捷时,OpenFlow网络的建设必然会步入高速发展阶段。实际上,这种发行模式与当前许多云安全服务的商务模式是可以无缝对接的,为云安全的落地提供了绝佳的渠道。以抗DDoS需求为例,在用户购买对象大量地由专用设备转向清洗服务的今天,供应商可以通过系统内置的发行体系为用户提供自助服务,然后按次数或处理能力收取费用;用户完全不必考虑现实中令人头疼的部署问题,只需通过“软件商店”下载安装相应服务,就能为OpenFlow网络添加抗DDoS的能力。
| |
  (8个打分, 平均:4.38 / 5) (8个打分, 平均:4.38 / 5) |




《云计算核心技术剖析》即将出版!!!
作者 吴朱华 | 2011-05-07 09:47 | 类型 云计算, 弯曲推荐, 行业动感 | 26条用户评论 »
|
人生最重要时刻之一即将到来,《云计算核心技术剖析》原名《剖析云计算》即将出版了,这本书本身起始于在弯曲发表的“探索UCS”这个系列,可以说弯曲就是《剖析云计算》的诞生地。在这里,我感谢吴健康与朱兰娣、以刘江、傅志红和王军花为代表图灵出版社、以王庆波、赵阳和陈滢为代表的IBM中国研究院,还有陈怀临和孔华威这两位师长,还有很多同济和北大的校友,下图就是本书的封面:
| |
 (没有打分) (没有打分) |

华为赛门铁克N8500集群NAS系统刷新SPEC记录
作者 黄 岩 | 2011-04-18 19:43 | 类型 弯曲推荐, 行业动感 | 131条用户评论 »
|
尊敬的陈首席,存储界发生了一件大事。 下面这个独立评论员写文章,请参考。 (http://www.theregister.co.uk/2011/04/18/hs_specsfs2008_crown/) 陈首席,考验您判断力的时刻到了。如果弯曲评论错过了报道‘存储行业大地震’的机会,您将愧对‘首席科学家’之称号,也必将因此遗恨终生:) 【陈怀临注:华赛已经发展到对人民的首席赤裸裸的威胁。。。首席很生气,后果很严重。我决定,一定亲自赴成都去耍,吃垮华赛的粉丝群。。。。。。】 我现在担任N8500这个产品的性能专项SE,非常愿意在弯曲评论上与大家一起讨论NAS性能和SPECsfs2008测试的相关技术问题,特别是技术细节和调优方法。 黄岩 —–
华为赛门铁克N8500集群NAS存储系统在标准性能评估机构SPEC的 SPECsfs2008测试中性能全球排名第一,打破NFS和CIFS两项业界记录。此次测试也是华为赛门铁克自2009年获得最高测试结果后,再一次刷新SPEC基准测试记录,分别获得636,036 OPS和712,664 OPS的最高性能得分。 SPEC(Standard Performance Evaluation Corporation, SPEC®)标准性能评测机构,是国际上对系统应用性能进行标准评测的权威组织。SPECsfs2008是SPEC组织发布的面向文件服务应用的核心基准,衡量文件访问的吞吐量和响应时间,为比较不同厂商的文件服务器性能提供了一个标准的评测方法。目前已有18家主流NAS制造商通过该评测基准的验证,输出了核心产品的性能数据。 N8500系统属于华为赛门铁克推出的中高端Scale-out NAS产品N8000家族一员,该产品定位于中高端NAS市场。N8000系列集群NAS存储系统架构上采用了多节点全Active集群技术,所有的引擎节点均处在同一个集群,可以协同工作,并发进行事务处理,各引擎节点也可以同时访问同一个文件。其次,N8500系统最多可支持256个单一命名空间,每个命名空间最大可以支持10亿个文件。N8500系统最大可以支持16引擎节点,引擎节点的数量扩展可带来系统性能上的线性增长。本次发布的性能值是使用 8个引擎节点达到的SPEC测试数据,因此系统整体性能依然具有很大的扩展潜力。 华为赛门铁克科技有限公司副总裁范瑞琦表示:“N8500集群NAS存储系统具有高性能、可扩展性和可获得性的特点,是我们的旗舰型产品。我们一直致力于产品开发并持续保持竞争力,连续破纪录的基准测试结果也证明了N8500系统是业界最高性能的产品。与友商产品相比,N8500系统能够帮助客户采用更低的运营成本,而获得更高的性能”。 关于SPECsfs2008基准 | |
|
(9个打分, 平均:4.11 / 5) |
工具箱
本文链接 |
|
打印此页 | 131条用户评论 »
Hillstone山石网科欢迎您的加盟
作者 Hillstone老童 | 2011-04-13 07:22 | 类型 弯曲推荐, 行业动感 | 773条用户评论 »
|
尊敬的陈首席及弯曲评论的朋友们,大家好! 我在弯曲评论里潜水很久了。 在这里,有许多高手的独到见解,多样性的争议与评论,让我收益非浅。 坛子里有许多朋友对Hillstone有过许多批评,很多是一针见血,常常让我读后一身冷汗,却又痛快淋漓。我常想,如果这些关注,关心Hillstone的朋友们能够聚在一起,会对Hillstone的成长一定有巨大的帮助。 我96年至04年在美国工作,许多身边的华人朋友都陆续成为所在公司的技术骨干力量。04年到06年,又回国帮助Juniper成立北京研发中心。在短短的两年里,北京研发中心陆续出品了日后成为市场销售主力的产品,并成为当时Juniper内部的耀眼明星。 这些经验让我深信,中国人的创造力是无限的。我们不仅仅可以成为世界的工厂,也可以成为世界的研发中心。怀揣这这个梦想,我和四个伙伴于06年底,一起创立了Hillstone。 工程师创业,一定有许多新东西要学。我们对销售和市场一无所知,前几年也走过不少弯路。好在陆续有志同道合的朋友加入我们,给Hillstone带来一些新的知识与力量,也帮助公司渐渐走上正轨。 这些年的经验和教训,让我深刻地认知到人才的重要性,Hillstone要有所发展,人才的招募和培养是第一要务。为此,今年我们已经开始大力扩大在北京的团队规模,新增一倍的办公场地,人员数量也将翻倍。我们在积极招募开发,测试,市场,售前,售后,销售,IT等等各方面的人才。 除了继续扩大北京研发中心外,我们专门在苏州成立了第二研发中心,计划在五年左右的时间内,成长为一个千人以上规模的基地。我们之所以选择苏州,是因为他是一个非常适合居住与发展的城市,距离上海仅仅30分钟路程,房价相对一线城市更合理些,人文和区域环境都非常好。我们有一个信条,企业要以客户和员工为中心。只要让客户满意,让员工安心,企业自然会得到发展。 Hillstone的企业文化是以人为本,秉承开放坦诚,客户第一,诚实低调的信条。我们希望可以打造一个平等,开放的工作氛围,让每个人都能发挥最大的潜力。 我很幸运,赶上了96-99年网络设备飞速发展的年代;而现在,我们再次面临一个新的巨大机遇的到来:虚拟化与消费者时代。五到七年以后,网络世界会有天翻地覆的变化,我们看到了其中的机遇与挑战。为此,我们刚刚完成了超过2个亿人民币的融资,我们已经准备好,去积极迎接世界的变化与挑战。我诚挚地邀请大家,无论你是常常批评我们还是赞许我们,一起参与这个激动人心的变革时代。欢迎您随时指教,更希望您可以加盟Hillstone. Let’s change the world. 童建 除了直接联系我以外,也可以直接联系我们的研发副总裁莫宁,或者人力资源总监陈瑞鹏 莫宁 陈瑞鹏 | |
|
(11个打分, 平均:4.45 / 5) |

工具箱
本文链接 |
|
打印此页 | 773条用户评论 »
弯曲上海张江聚会(2011年4月13日)
作者 吴朱华 | 2011-04-12 21:22 | 类型 弯曲推荐, 行业动感 | 39条用户评论 »
|
[陈怀临注:各位弟兄,我狠不能现在就空投到黄浦江边。请多喝几杯。人生一世,草木一丘。要的就是结交义气相投的江湖弟兄!] 今天晚上,正好有几个弯曲的朋友到上海张江来,所以借这个机会大家一起聚聚,而且希望在上海的其他弯友也一起过来聊聊,大家借此机会认识认识,有朋自远方来,非常happy。 聚会时间:4月13日6:30(当然PM啦); 聚会地点:张江地铁站旁的顾姐小厨; 联络方式:13811518208; 预计参加的人物:Billy、韩勖、吴朱华等,预计10人左右。 | |
|
(8个打分, 平均:4.75 / 5) |
网络存储领域巨作《大话存储2》即将出版,附全书目录和前言、序言
作者 冬瓜头 | 2011-04-08 20:37 | 类型 图书推荐, 学术园地, 弯曲推荐, 科技普及, 行业动感, 读者文摘 | 72条用户评论 »
|
当当网预售链接:(折后¥73) http://product.dangdang.com/product.aspx?product_id=21058708&ref=search-1-pub
各位读者好,在《大话存储2》即将出版之际,我将这本书的写作过程做一个总结,也是对自己的一种鼓励,希望能够让自己继续卧薪尝胆,写出《大话存储3》。 前言 各位读者好,很高兴再次为大家“大话”存储。记得上一次是在2年前。当《大话存储》一书在2008年11月出版面世之后,我当时就许下承诺,要写《大话存储2》。当时之所以敢于夸下海口要继续写第二本,是因为《大话存储》只介绍了存储领域最基本的概念和架构,而并没有包罗存储领域最新的技术,比如重复数据删除、Thin Provision、动态分级存储、CDP连续数据保护、SSD固态硬盘、FCoE、SAS、云计算和云存储等等。《大话存储》确实满足了广大读者的需求,出版之后也获得了好评和诸多奖项,至今已经销售了超过一万四千册,这个数字对于技术书籍,而且是受众面如此狭窄的技术书籍来讲,已经是个不小的数字了。但是这些成果逐渐让我感觉到更大的责任和压力,即中国的IT行业确实迫切需要被普及存储基本知识。正因如此,所以我深知我绝对不能就此停歇,学习是永无止境的,技术是不断发展的,所以我先向大家做了承诺,这样就可以无时无刻的激励我继续学习研究下去了。 写作的过程是极其困难的,尤其是当一字一句都需要精雕细琢,并且时刻以通俗表达且让所有人都能看懂的原则和基准去写的时候,其所耗费的精力和脑力是巨大的。记得在一年前撰写本书主体的时候,基本上每天都是早晨七八点钟起来,从床上直接到书桌上开始写,直到中午吃饭,吃饭过程中依然在脑海中构思着,就这样一直到晚上,最晚的一次记得是做一个实验,通宵达旦,直到第二天天亮,实在体力不支,去床上躺到中午,然后继续写。每次睡觉之前,都会带着一个疑问入睡,躺下之后就在脑海中构思、建模,一旦想到某些重要的东西,就用笔记几个关键词,否则第二天准忘。大部分时间一般都是没想到什么思路就已经呼呼大睡了。这种状态持续了半年之久。当完成了所有主体稿件之后,真的有一种如释重负的感觉。可惜,好景不长,随着不断的学习和深入,逐渐发现已经写完的内容当中有大量需要补充完善、修饰的部分,在修饰完善的过程中,继续思考,结果发现又引申出更多的东西,有些甚至推翻了以前的结论。这种状态又持续了半年。最终定稿交给编辑之后,依然发现还有零碎的东西需要完善甚至推翻,结果一再将更新的内容同步给编辑,直到最后一个月的时间内没有再发现需要完善的内容,达到了最终收敛。后面这个过程感觉更加耗费精力,因为当你重新审视之前内容的时候,一旦发现不完善甚至错误,就会感觉到一种挫败感和愧疚感,使你的激情和斗志有所丧失。 写书不但是给他人共享知识的过程,它更是一个总结自身知识体系、提高自身修养以及让自己学习更多知识的途径。比如,我在写书过程中,不但通过各方面渠道纠正了之前对某项技术的一些错误认识,而且还学习了更多的知识,并且将这些知识进行深度理解分析,之后通俗的表达出来。当你发现其他人通过你所共享的知识快速提高之后,这种感觉是最充实的。人只有在奉献之后才会感到充实,而不是一味的去索取,这样只能更加空虚。 冬瓜头 2011年3月10日于北京
序言1 我关注张冬这个名字是在«大话存储»一书刚出版的时候。作为一个长期从事信息存储技术研究与教学的大学教师,自认为对于国内外关于网络存储方面的各种书籍和资料比较熟悉,对业界有哪些牛人也算比较了解。但我在书店偶然发现一本名为«大话存储»书的时候,确实感到有点意外和惊喜。好像在熟悉的武林圈子之外,突然出现一位武林高手在那里论道。好奇心驱使我赶紧买了一本书回家研读,结果发现这本书确实与众不同。 与我们这些所谓学院派写的中规中矩的书相比,此书风格特立独行,语言形象生动,潇潇洒洒,颇具武侠之风。书中充满着智慧的思考和有趣的比喻,将各种原本枯燥深奥的技术概念和原理论述得十分透彻明白。不仅如此,该书还收集了大量的实例,使读者在系统获得网络存储知识的同时,还能了解典型实际系统的工作原理和技术细节,具有很好的实用性。我读完之后,对这本书的作者十分好奇。一个80后而且还是学化学出身的年轻人,如何就能写出这种行文老到而风格独特的专业技术书籍呢?上网查了一下冬瓜头(张冬的网名)的技术博客和他在各种论坛留下的文字,我得到了答案。这是一个完全由兴趣驱动而对技术极端痴迷的人,也是一位善于思考、富于想象力的人。这种纯粹的、不含任何功利成份的兴趣与痴迷,才是促进科学技术发展的真正原动力。 真正和张冬接触,是因为他来信质疑我们实验室申报的一项专利。收到质疑的来信,我和提出这项专利的博士生经过仔细研究,发现我们提供的图上因为少了一个非门,结果将会因为反相而出错。对如此细致具体的问题,一般人是难以发现的。如果没有打破砂锅问到底的较真精神,哪里会发现如此细节的错误呢?这种质疑的精神,在科学研究中是极为宝贵的。我们学校被称为“根叔”的李培根校长,在2010年的新生开学典礼大会上,就以“质疑”为题作了讲演,激励青年学子发扬质疑精神。有质疑精神的人,不唯上,不唯权威,只认真理,这正是我们这个时代所稀缺的精神。 强烈的兴趣,对技术的痴迷,加上质疑精神,成就了一本存储领域的一本好书。我在研究生新生入学之后,就推荐他们先读一下«大话存储»这本书。一方面此书对研究生而言,确实是一本网络存储技术入门的好书,另一方面我还有一个用意,就是让他们知道,要从事科学研究,强烈的兴趣比什么都重要。 信息存储是信息跨越时间的传递,也是人类传承知识的主要手段。在信息存储技术上,人类有超过万年的发明创造史。早期就地取材,人类利用石刻、泥板、竹简和羊皮来记录信息,后来发明了纸张和活字印刷来保存和传播信息,近代发明了照相、录音和录像技术来存储信息。利用这些发明和创造,人类留下了极为丰富的文字、绘画、图像、语音和视频信息。正是这些信息,记录了人类创造的知识体系,使我们能够传承文明,并在此基础上创造新的文明。 从计算机的发明为开端,人类的信息技术进入了一个以数字化为特征的历史性新阶段。各种形式的信息被转换成数字后,以统一的方式进行处理、传输和存储,然后再转换为各种形式的信息被人们所利用。这种前所未有的方式发明之后,一个以数字化为特征的信息革命浪潮就波澜壮阔地形成。各种信息都被大规模数字化,使数字化的信息呈爆炸性增长。特别是互联网的兴起和普及,大大加快了信息的流通过程,使数字信息加速产生。图灵奖获得者Jim Gary观察这种数据急速增长的趋势后,总结出一个规律:人类每十八个月新增的数据量,将是历史上所有数据量之和!如此下去,对信息存储的需求将是无止境的,信息存储技术在这种强烈的需求驱动下得到了空前的发展。 为了保存数字化的信息,当代的科学家和工程师在最近的几十年中发明了磁存储、光存储、半导体存储等多种存储技术,其中大容量的硬盘在海量信息存储中扮演了主要的角色。硬盘的密度在短短几十年中增长了一百万倍以上,在近期,硬盘密度每年增长都接近一倍,而且还有不小的增长空间。由硬盘作为基本单元,通过各种总线、网络将硬盘连接成不同层次和不同规模的存储系统,就构成了我们目前的网络存储系统。例如由硬盘组加上冗余纠错技术构成磁盘阵列,再由磁盘阵列通过局部高速网络连接形成存储区域网;又如通过包含硬盘的大规模集群和文件系统形成的海量存储系统成为大型网站和数据中心新的存储架构。人们发明了各种技术来提高存储系统的容量、性能、效率、可用性、安全性和可管理性。存储虚拟化、归档存储、集群存储、云存储、绿色存储等新名词不断涌现,SSD固态存储、重复数据删除、连续数据保护、数据备份与容灾、数据生命周期管理等新技术层出不穷,令人应接不暇。 在这种情况下,广大的信息领域的从业人员,信息系统的用户,以及学习信息技术的大学生和研究生,迫切需要一本既全面论述网络存储技术原理、又有丰富实例,既反映最新技术进展、又通俗易懂的书来满足他们的需求。张冬的«大话存储»就是这样一本恰逢其时的好书。 «大话存储»已在业界产生了很大的影响,对存储技术在我国的普及起到了良好的推动作用。该书还被引进到我国的宝岛台湾,可见其影响深远。张冬再接再厉,以他对技术的痴迷继续钻研,对第一本书作了工作量巨大的改动与增补,并增加了云存储等全新的三章内容,全面反映了他对技术的重新思考和对最新技术的深刻理解。我相信,这些新的内容将给读者带来惊喜。 在技术发展十分迅速的领域,赶时髦的书籍多如牛毛,书店里充满了应景之作,真正经过深入思考、用心写作的书是不多的。而«大话存储II»却是一位技术高手的呕心沥血之作,书中对每一项技术的介绍都经过深入的思考和反复的推敲,这在当前浮躁的气氛中显得弥足珍贵。在«大话存储II»即将出版之际,我要向作者表示深深的敬意和衷心的祝贺,并郑重向读者推荐这本学习网络存储技术的好书。 谢长生 华中科技大学计算机学院 教授 信息存储系统教育部重点实验室 主任 序言2 在过去的近二十年中,存储领域在国内外都发生了巨大的变化。存储系统已经从早期的服务器附庸形态中脱离出来,而作为独立的产业走向了应用的前台。作为存储领域的一个从业人员,我有幸地经历了其中许多变化阶段。而更为幸运的是存储领域的发展势头不是日趋渐微,而正是方兴未艾。 中科院计算技术研究所 研究员 许鲁 序言3 第一次听说冬瓜头是因为《大话存储》,而见到冬瓜头本人时,已经听他说在写《大话存储2》了,我们一起有过不长时间的沟通,全是讨论最新的存储技术, 有一些内容,我相信他在书中都有写到,在同他见面前,我一直在嘀咕怎么去跟他沟通,但是,看到现实中的他朴实、憨厚、腼腆,但是对技术极其敏感,说起来一套一套的,我就开始为这个山东大汉折服了,还好我是做了准备的,否则非被问倒不可。 他是个靠笔说话和表达的人,在网络论坛里,写的文字常常是洋洋洒洒,时而言辞激烈,时而意气风发,这分明是一位才高八斗的江南才子,又像是一个书场中幽默诙谐的说书人。从此之后,我经常关注他的个人博客,他会经常在博客释放一些思想出来,豪放不羁,甚至还写过长诗以及各种各样的打油诗,有些还写得非常棒,配上那个流着鼻涕的冬瓜头漫画形象,真是绝配了。 这么一个内秀的北方大汉,用的豪放气势描述一个个生涩、枯燥的技术领域,他的思想遍布他的文字,通过笔端流放在读者面前,并且还一直这么坚持,听他说,大话2出来后,还会继续写大话3,毕竟技术是日新月异的,尤其是在IT领域,正如他所言,昨天的中国同仁在存储技术还是个初学者,今天已经开始从蹒跚学步到自主创新了,而明天,有什么理由不能期盼他们引领潮流的身影呢,我想,这也是冬瓜头要写大话3的动力所在吧。 《大话存储2》的篇幅已经超过了一千页。在浏览了全部章节之后,发现这一千页中真的是字字珠玑!看得出来,是冬瓜头一个字一个字写出来的,更加可贵的是,全书字里行间透着他那独特的思想,对技术、对世界的理解以及他做人的态度,能够将这些世界观的东西融入一本技术书籍,这在以前是绝无仅有的!比如书中多次提到“轮回”、“阴阳”等,最后还有一节是用中医的思想来“诊治”系统性能瓶颈,看后真是另我等感叹至极!世间万物都是相互联系的,都可以找到类比和轮回,这也是冬瓜头所描述的世界观的一种。 在和冬瓜头的交谈中获知,他大学学习的专业是化学,因为高中时他化学成绩最好所以就报了化学专业,而且其间还自学过分子生物学领域的内容,我更加惊讶了!按照他的话来说,就是“兴趣是第一驱动力”。是的,好奇和探索正式人类不断发展的第一动力,说到这我对《大话存储2》中关于冬瓜头所设想的“机器如何认知自身”这段内容产生了强烈共鸣,人可以认识自身认识世界,那么机器为何不能呢?冬瓜说他学习和接触存储业不过三四年的时间,在这短短的几年内,竟然能有如此造诣,到这里我感觉到,强烈的好奇心可以创造奇迹!可以让机器开口,可以让机器进化!这也正是冬瓜头所表述的世界观的一种! 《大话存储2》对各项存储技术的细节描述已经可以说是达到了研发级别,有很多部分甚至可以指导我们的研发!但是他却并没有用代码来表述,而是用通俗的语言和详实的图示,将原本通过阅读代码才可以理解透彻的原理,就这么轻而易举的表述了出来,这是目前我所看到的任何存储书籍或者文章都无法做到的。就这一点我曾经也问过冬瓜头,问他如何做到的。他每次的回答很简单,一针见血,实实在在,他这么说:“因为我就是一个从不懂钻到懂的草根,我深知一个根本不懂存储的人最想了解的东西和切入角度,并且愿意毫无保留的帮助其他草根生长!” 是啊,只有亲历过那悬梁刺股的学习之路的不易,才能产出精华! 在与冬瓜头的交谈中,他还常提到一句口号:“振兴民族科教”。从他说话的眼神和口气看得出来,振兴民族科技已经成为他的信仰,他也说到,他现在所做的一切都围绕着这个信仰,他愿意为中国存储事业鞠躬尽瘁死而后已,出版《大话存储》只是他要做的第一个环节而已,今后他还会有一系列的动作来兑现他的诺言。信仰可以改变一个人的心态与行为,我们目前太缺乏信仰,我想如果我们所有人都有这种信仰,那么“振兴民族科教”这句口号早就可以实现了。 信息存储已经成为了一个时刻影响人们生产、生活的新兴行业,他的发展也代表着世界未来的发展,让我们再来看看国产存储信息产业的发展正在经历着怎样的变革和转变。 我国即将进入“十二五”,“十二五”的提出也就意味着我国要实现三大转变目标:从国强到民富、从外需到内需、从高碳到低碳,这也意味着国家的发展需要依靠科技,需要大力发展新技术,尤其以信息化技术为主轴,信息化技术的发展带动重点工程的推动,势必对国产产品催生更大的需求,我相信存储行业也会有更多的民族产业佼佼者诞生。 IT环境日益复杂,数据量快速膨胀,存储行业也进入了一个技术更新极为活跃的黄金发展时期,行业发展迅速,技术活跃度高,这对国产厂家来说,无疑是一个脱颖而出的良好契机,那我们要如何在这个时代背景下产生代表着民族存储行业的国产佼佼者? 在这个时代,我们应该遵守什么?我们应该坚持什么?商业道德、创新精神、客户意识,我想只有将这些融入到企业性格中才能为企业注入新的活力。作为一家有理想的企业,需要具备一定的时代精神,而在存储技术日新月异的今天,企业打造独有的技术张性,终究才会超越历史,才会产生新时代的民族企业,我相信现在越来越多的企业更正朝这个方向发展。 大话存储正以通俗易懂的语言,风趣的行文手法向读者阐述枯燥难懂的技术精髓,致力于存储信息技术发展的民族企业也同样可以在深刻理解本土文化精髓的前提下为中国写下辉煌的历史篇章,我想这个世界没有什么不可能的,只要有这份热爱,专注和执着,又有什么是不可能实现的呢? 这样的一本特立独行的书,他就是时代的产物,他就是时代的精髓。 爱数软件 总经理贺鸿富 产品总监李基亮 序言4 存储是个大市场,有意向在数据和信息系统上做投资规划的企业逐年提高,这标志着越来越多的企业意识到自身的数据安全问题。 早在十几年前刚刚踏入存储圈子之时,数据安全问题只被金融、电信等少数行业所考虑,而如今,几乎各个行业都存在数据保护与信息安全的需求。随着用户需求的急速增长,无论是硬件设备还是软件产品都是生机一片。但是,多年来我国在这个领域一直被国外产品所垄断,究其原因,是我国存储领域技术相对滞后。 我们在经营企业的过程中,花费了大量的精力进行人才的培养。在国内,计算机行业的传统教育大多集中于软件应用与网络维护上,对于专业存储的技术培训几乎为零,而存储行业又在飞速地发展着,因此,存储市场的需求与人才滞后的落差越拉越大,我们急切渴望拥有存储专业的人才去发展存储领域。“人才为本,教育当先”,人才的培养离不开教育。多年以来,存储领域的教材乃至书籍几乎是一片空白,有的也只是太过于教条以及模式化的书籍,当看到张冬先生的《大话存储》后,我深刻地体会到存储行业开始有了专业的教科书,中国的存储业有了崭新的明天。 之所以赋予《大话存储》如此高的评价是因为他的语言通俗而不失专业,幽默而不失严谨。张冬先生用读者极易接受的语言道出了存储领域的精髓。对于初学者来说,能使存储领域不再陌生,而又充满吸引。我曾了解到,《大话存储》已经成为某院校计算机专业的教材,这不仅是存储业的幸事,同时也是现代教育的幸事。坦率地讲,我们做企业,时刻关心教育的发展,我们需要新鲜的血液来继承和发展我们的事业。《大话存储》作为能够真正做到学以致用的教材之一,使我们倍感欣慰。我为我们选择的存储道路之前景充满信心,为振兴我们的民族工业充满信心,同时,为张冬这样的后继人才而倍感骄傲。 《大话存储》能够成为教材是张冬对于存储领域不懈努力的成果,《大话存储二》的出版,更是他不断追求与探索的结果。《大话存储二》在《一》的基础上更加深入地剖析了存储技术,以及存储对于今天市场的广泛应用。书中不乏出现一些当今企业的存储实例,也包含了国内外软硬件厂家的存储技术应用,加入了更多实际范例,使读者更易理解,同时具有很强的应用性。 我相信《大话存储二》会给广大读者很大的帮助,同时也希望此书能够带领更多的有识青年进入存储领域,为我国民族产业的振兴而奋斗。 认识张冬,是因他的《大话存储》,曾在去年拜读过此书,感觉一个80后的小伙子能用如此通俗的语言诠释存储技术,实属存储行业的一大喜事。这本书,让不了解存储的人认识存储,能够了解到存储并不是高深莫测,即使一个存储行业以外的人去阅读《大话存储》,也一定能够读懂。用什么样的语言和叙述方式不重要,重要的是把要说的说明白。 张冬本人就像他的书一样,饱含着严谨的作风和真诚的态度,而又不乏幽默的风格。看过他的BLOG,人气一直很旺,这个致力于为国产存储行业鞠躬尽瘁的年轻人是我对他更加刮目相看。他在博客中写到:“我所能够做的,只有让中国人,让所有中国存储行业的人,以及中国存储行业本身,有一个扎实的基础。如果能够促进国产存储软件硬件的发展,那鄙人就是鞠躬尽瘁,死而后已,死而无憾!”一个80后年轻人有这样的雄心壮志,我们有什么理由不去努力不去发展国产存储行业呢? 记得十几年前,我刚刚进入存储领域,那个时候相关的书籍非常少,完全要靠自己进行反复的试验。那时(IT行业根本不成形,姑且称作计算机行业)计算机业的从业者都是抱着掌握20世纪末最具科技含量的技术的心态进行工作,从根本上说,对存储技术充满了崇拜,甚至有一丝恐惧。在探索期间,也走了不少弯路,耽误了很多时间。如果那个时候有这样一本关于存储的书籍,那简直是一大幸事!书中并没有把存储看做是多么高深的技术,而是任何一个普通人都能掌握的技术。和张冬开玩笑说,如果你早生10年,你就可以带领我们走向一条存储道路的捷径。 看到张冬最新写作的《大话存储二》时,我就感觉到这又是一本好书。不仅延续了《一》中通俗易懂的语言及“武侠”式的章节回目,在技术深度上,也有很大的挖掘。书中不仅囊括了时下最先进的“云”技术以及持续数据保护(CDP)技术,还牵扯到了很多非常底层的架构。在《一》的基础上,有了更为深刻的剖析。值得一提的是,张冬在最后还加入了Q&A的内容,把几年来读者以及网友提出的问题一一列出,并作出详细的解答,能够体会张冬在这一年多的时间里,对于存储技术的探索花了很大的心思。最可贵的是,年轻人不已如此成就为骄傲,继续着他谦虚而谨慎的态度。 《大话存储二》是一本好书,作者那严谨而真诚的态度以及致力于发展本国存储行业的信心注定能够成就这样一部优秀的作品。我完全有理由相信此书能够给从业者乃至热爱存储的读者带来帮助。从中,你会受益匪浅,并乐意向你的朋友推荐此书 存储是个大市场,有意向在数据和信息系统上做投资规划的企业逐年提高,这标志着越来越多的企业意识到自身的数据安全问题。早在十几年前刚刚踏入存储圈子之时,数据安全问题只被金融、电信等少数行业所考虑,而如今,几乎各个行业都存在数据保护与信息安全的需求。随着用户需求的急速增长,无论是硬件设备还是软件产品都是生机一片。但是,多年来我国在这个领域一直被国外产品所垄断,究其原因,是我国存储领域技术相对滞后。 我们在经营企业的过程中,花费了大量的精力进行人才的培养。在国内,计算机行业的传统教育大多集中于软件应用与网络维护上,对于专业存储的技术培训几乎为零,而存储行业又在飞速地发展着,因此,存储市场的需求与人才滞后的落差越拉越大,我们急切渴望拥有存储专业的人才去发展存储领域。“人才为本,教育当先”,人才的培养离不开教育。多年以来,存储领域的教材乃至书籍几乎是一片空白,有的也只是太过于教条以及模式化的书籍,当看到张冬先生的《大话存储》后,我深刻地体会到存储行业开始有了专业的教科书,中国的存储业有了崭新的明天。 之所以赋予《大话存储》如此高的评价是因为他的语言通俗而不失专业,幽默而不失严谨。张冬先生用读者极易接受的语言道出了存储领域的精髓。对于初学者来说,能使存储领域不再陌生,而又充满吸引。我曾了解到,《大话存储》已经成为某院校计算机专业的教材,这不仅是存储业的幸事,同时也是现代教育的幸事。坦率地讲,我们做企业,时刻关心教育的发展,我们需要新鲜的血液来继承和发展我们的事业。《大话存储》作为能够真正做到学以致用的教材之一,使我们倍感欣慰。我为我们选择的存储道路之前景充满信心,为振兴我们的民族工业充满信心,同时,为张冬这样的后继人才而倍感骄傲。 《大话存储》能够成为教材是张冬对于存储领域不懈努力的成果,《大话存储二》的出版,更是他不断追求与探索的结果。《大话存储二》在《一》的基础上更加深入地剖析了存储技术,以及存储对于今天市场的广泛应用。书中不乏出现一些当今企业的存储实例,也包含了国内外软硬件厂家的存储技术应用,加入了更多实际范例,使读者更易理解,同时具有很强的应用性。 我相信《大话存储二》会给广大读者很大的帮助,同时也希望此书能够带领更多的有识青年进入存储领域,为我国民族产业的振兴而奋斗。 火星高科 总经理龚平 认识张冬,是因他的《大话存储》,曾在去年拜读过此书,感觉一个80后的小伙子能用如此通俗的语言诠释存储技术,实属存储行业的一大喜事。这本书,让不了解存储的人认识存储,能够了解到存储并不是高深莫测,即使一个存储行业以外的人去阅读《大话存储》,也一定能够读懂。用什么样的语言和叙述方式不重要,重要的是把要说的说明白。张冬本人就像他的书一样,饱含着严谨的作风和真诚的态度,而又不乏幽默的风格。看过他的BLOG,人气一直很旺,这个致力于为国产存储行业鞠躬尽瘁的年轻人是我对他更加刮目相看。他在博客中写到:“我所能够做的,只有让中国人,让所有中国存储行业的人,以及中国存储行业本身,有一个扎实的基础。如果能够促进国产存储软件硬件的发展,那鄙人就是鞠躬尽瘁,死而后已,死而无憾!”一个80后年轻人有这样的雄心壮志,我们有什么理由不去努力不去发展国产存储行业呢?记得十几年前,我刚刚进入存储领域,那个时候相关的书籍非常少,完全要靠自己进行反复的试验。那时(IT行业根本不成形,姑且称作计算机行业)计算机业的从业者都是抱着掌握20世纪末最具科技含量的技术的心态进行工作,从根本上说,对存储技术充满了崇拜,甚至有一丝恐惧。在探索期间,也走了不少弯路,耽误了很多时间。如果那个时候有这样一本关于存储的书籍,那简直是一大幸事!书中并没有把存储看做是多么高深的技术,而是任何一个普通人都能掌握的技术。和张冬开玩笑说,如果你早生10年,你就可以带领我们走向一条存储道路的捷径。 看到张冬最新写作的《大话存储二》时,我就感觉到这又是一本好书。不仅延续了《一》中通俗易懂的语言及“武侠”式的章节回目,在技术深度上,也有很大的挖掘。书中不仅囊括了时下最先进的“云”技术以及持续数据保护(CDP)技术,还牵扯到了很多非常底层的架构。在《一》的基础上,有了更为深刻的剖析。值得一提的是,张冬在最后还加入了Q&A的内容,把几年来读者以及网友提出的问题一一列出,并作出详细的解答,能够体会张冬在这一年多的时间里,对于存储技术的探索花了很大的心思。最可贵的是,年轻人不已如此成就为骄傲,继续着他谦虚而谨慎的态度。 《大话存储二》是一本好书,作者那严谨而真诚的态度以及致力于发展本国存储行业的信心注定能够成就这样一部优秀的作品。我完全有理由相信此书能够给从业者乃至热爱存储的读者带来帮助。从中,你会受益匪浅,并乐意向你的朋友推荐此书 火星高科 技术总监黄疆(Win98时代《中文之星》软件作者) 全书目录: 首先对不起各位读者,为了尽量压缩图书页数,尽可能的降低成本,出版社采用了比一般书稍微小一点的字号,有些图片也压缩的比较厉害,终于将原稿1400页压缩到了900页内,虽说浓缩的都是精华,但是可能比较费眼睛,辛苦大家了~ 在此附赠两张19章里的大图,估计印刷后被缩成小图了。
另外,鉴于具有中国特色的国情决定,再有价值的图书,价格也决不能跟着价值往上走,在此出版社和作者自身都做出了巨大的牺牲,定价99元(网店等折后大概80包运费),对我个人收入而言,大家是可以查到的,版税率网络上都是公开的,大家可以查查,绝对不是册数×定价,否则那是暴发户了。正因如此,希望大家体谅作者废寝忘食耗费巨大精力的劳动成果,体谅中国国情,也就是体谅自己,支持正版,反对任何形式的盗版散发!! 北京的同志们,签售时见! 当当网预售链接:(折后¥73) http://product.dangdang.com/product.aspx?product_id=21058708&ref=search-1-pub | |
|
(9个打分, 平均:3.67 / 5) |



关于举行2011年“千人计划专家论坛”会议通知
作者 ss201009 | 2011-04-08 08:08 | 类型 千人计划, 弯曲推荐 | 4条用户评论 »
|
本文来自千人计划专家博客:http://www.1000plan.org/blog/4063_208 关于举行2011年“千人计划专家论坛”会议通知各位“千人计划”特聘专家: 经“千人计划”专家联谊会执委会讨论确定, 2011年6月26日至28日将在武汉召开“千人计划专家论坛”,论坛将和华创会同步进行,届时将有中部6省的领导以及海内外嘉宾500余人参加。下面是我们和湖北省委组织部,省外事侨务办公室等有关部门商量的日程安排,热情邀请各位“千人计划”入选者参加,具体活动安排如下: 6月26日(周日) 下午 2:00__ 6:00 武汉洪山宾馆(五星级,主会场)签到 6月27日(周一) 上午 8:30__11:30 参加华创会开幕式 精彩文艺演出 论坛组织结构 主办单位: “千人计划”专家联谊会 支持单位: 湖北省委组织部 筹备组联系人:魏立梅女士,lmwei@scirp.org, 136-6716-2963 湖北地处中部,链接北京、广州、上海和成都的高铁将相继开通,在“北上广”人力资源和其他成本大幅上涨的时候,中部拥有优质而廉价的人力资源,以及便捷的交通等优势,各位千人可以考虑在中部寻求合作和发展机会。2011年,辛亥革命100周年,武昌起义,现代中国的诞生地,大家回顾历史,抓住机遇,发展自己,复兴中华。湖北省政府将支付各位在武汉期间的食宿等费用。 “千人计划”专家联谊会 论坛组委会 2011年4月8日 | |
|
(1个打分, 平均:5.00 / 5) |
VNXe会给存储系统带来颠覆性变革么?
作者 冬瓜头 | 2011-03-30 19:57 | 类型 弯曲推荐, 行业动感, 通讯产品 | 46条用户评论 »
|
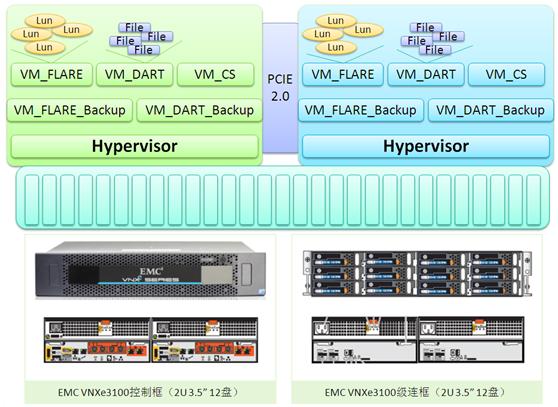
转载请注明作者及出处并不得删减内容,否则会对读者形成误导! 本文作者系网络存储系统领域技术专家张冬(冬瓜头),著有《大话存储》及《大话存储2》,博客http://space.doit.com.cn/35700,QQ 122567712 MSN:myprotein0007@hotmail.com 缘起VNXe 存储巨头EMC最近发布了Clariion和Celerra联合整容之后的VNX以及里程碑VNXe产品,对这两个系列的产品的规格细节功能等就不再做过多介绍了。VNX系列基本上就是新瓶装旧酒,虽然号称“下一代统一存储”,实则奉行不独不统的原则,前端NAS机头与后端SAN机头仍然保持暧昧关系,而这之前,NAS机头被统称为Celerra系列,SAN机头则被统称为Clariion系列。 EMC虽然弄出了个VNX名称把大家忽悠了一下,而且也取得了SPEC SFS2008的顶级成绩,对于其使用了数百块SSD加上8个独立机头来拼搭出这种惊人成绩,请保持淡定,“Just For Fun”。如果查看用总成绩除以8之后得出的数字,你会发现确实也不怎么惊人,单台NAS头跑6万的IO这个成绩在当今用Intel CPU+DDR3内存+SAS2.0的普遍时代已经是家常便饭。 这次实际要引出的,则是VNXe系列。用“fire in the hole”来形容是恰到好处。EMC往IBM、HP、Dell的坑里扔了一颗雷,不到一万美金就能买个便宜实惠好用的一体化存储回来,囊括了基本的软件功能比如Thin、Dedup、Compression、Snapshot、iSCSI、CIFS、NFS等,还带了硬盘。这种形态的一体化存储对于SMB来讲是很受欢迎的。 SMB的需求 在此我们提出两个问题发散思考: 1、SMB除了SAN/NAS统一存储之外还有其他迫切需求么? 2、EMC的VNXe的下一代形态会是什么样? 第一个问题。SMB一般是又想用像样的东西但是又没钱,尤其是占大部分的对IT重视度不足的小企业,由于IT部门不是直接创造价值的,所以预算极度有限。这种压力之下,用最少的钱做最多的事情是一个迫切需求,比如能否少买服务器,以更低的价格购买Exchange Server和SQL Server软件或各种OA软件等。 第二个问题。首先看一下VNXe现在是什么形态。外部形态:双控互备。内部形态(推测):每控制器跑了5个虚拟机(据可靠消息透露),鉴于EMC与VMware的关系,以及VMware在HA方面的强悍表现,推测Hypervisor使用的就是VMware构建。如图所示,每个控制器运行了2个Flare操作系统的虚拟机,其中一个用于处理本控制器的IO,另外一个则作为对对方控制器上主Flare虚拟机的备份机,一旦对方控制器硬件故障、掉电等,那么本地控制器的备份Flare虚拟机就会挂起对方控制器原来的后端资源从而继续提供服务。同样,对于DART虚拟机也是这种工作模式。还有一个Control Station虚拟机。DART会从内部使用虚拟的HBA来挂载经由Flare提供的Lun,从而提供NAS服务,Block服务则直接从Flare中提供。
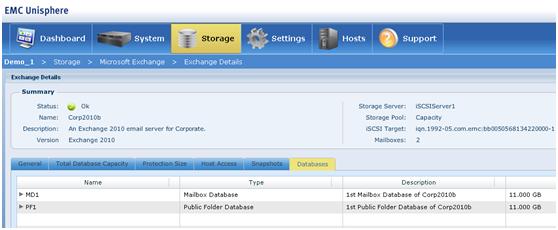
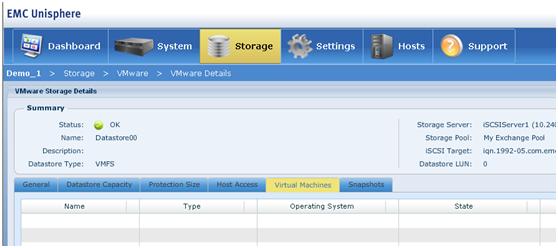
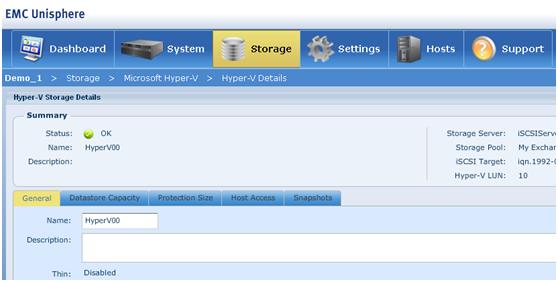
可怕的虚拟机 可以看到EMC这次大肆将虚拟机技术用于低端存储,不能不说算是一次变革。VMware在VM可靠性方面主要有两种技术:HA和(FT)Fault Tolerance。前者本质上就是两个VM的冷备,当受监控的主VM宕机或者宿主服务器故障宕机后,位于另一个宿主机的Hypervisor从共享存储上将故障的VM冷启动起来继续提供服务;而Fault Tolerance则是更加高级的功能,他能实现位于两台不同宿主机上的两个VM之间的CPU指令级别的同步,采用CPU厂商提供的vLockstep技术从而可以做到源VM所作的任何操作都被同步到目标VM上执行,由于两台VM都处于启动状态并且任何操作的实时同步,所以FT能够实现最高级别的切换速度,当然,仅限硬件故障切换,如果遇到软件故障,则双方会同时故障。而FT对资源消耗也是很大的,由于入方向的网络IO、读入内存的磁盘IO数据以及指令等均需要主VM通过高速网络传输到备VM上,所以在遇到大网络或者磁盘吞吐量时,这种同步会导致主VM操作延迟大增,对于磁盘IO,VMware提供了另外一种机制,即可以让备VM与主VM共享存储并且允许备VM对目标存储进行只读操作,从而可以节省一部分带宽消耗,FT本身是极其耗费资源的,成本也非常高。 HA太慢,FT又成本太高,所以VNXe采用一种类似传统服务器所使用的双机HA方式,主备VM上都是启动状态,但是备VM中的Flare/DART核心代码并不会挂载底层资源,仅当检测到主VM中的Flare/DART核心代码发生故障或者主VM自身发生故障,亦或者主VM所在的控制器硬件发生故障时,备VM中的Flare/DART核心代码会立即挂载后端资源继续提供服务。这样相比先冷启动VM,再运行Flare/DART核心代码,再挂载资源的步骤迅速了很多。 应用感知 再来看看VNXe针对应用所作的集成。如图所示,VNXe可以直接在存储配置界面中创建Exchange Server的mailbox文件、HyperV和VMware的datastor。对于直接创建Exchange Server的mailbox,我感觉意义还是比较大的,如遇到大规模邮箱创建,确实可以简化工作量;但是对于在存储端创建HyperV和VMware的datastor,这里EMC又把大家给忽悠了一次。VMware中对于一个Datastor的定义,无非就是一个Lun或者一个NFS协议挂载的目录,也就是说,任何一台普通存储设备,只要你能提供一个Lun出来,那么ESX Server上能够认到,那么Vcenter中就可以将其定义为一个datastor,而看一下图示也可以看出,VNXe在VMware感知方面,无非就是可以感知到VMware所使用的VMFS的格式,可以直接从存储配置界面中看到对应的Lun里都有哪些虚拟机罢了,而这好像真的没有什么太大意义,只能作为一个亮点存在,对于HyperV,如图所示,则更是根本没有去感知对应的Lun中到底有多少虚拟机,完全和一个普通Lun一摸一样对待,所以EMC在HyperV这里,没有任何感知,完全就一大忽悠!
EMC的Unisphere是一个面向对象的GUI,目前各存储厂商似乎越来越务虚了,表面文章做的很花哨,吸引不少眼球,比如IBM的XIV和Storwize V7000的配置界面,具有MAC界面的元素。不得不佩服其美工人员。 应用存储–颠覆传统存储系统 下面该说正事了。应用感知+虚拟机,这意味着什么呢?这次EMC只是去感知应用底层的存储,那么下一步,是不是干脆可以直接把Exchange Server装到VNXe中的Hypervisor上的一个VM里?甚至直接提供裸VM供用户自行安装部署自己的应用系统?之前提到的SMB的迫切需求,如果能用一台设备把存储和应用都解决了,那岂不是很划算么?承载应用的VM和承载存储处理的VM之间的通信使用内存中的虚拟HBA,而不是外部网络了,效率灵活性和速度均会提高,最重要的是,根本不需要购买服务器+HBA卡+交换机硬件了,大幅降低了成本。SMB确实会受到采购成本困扰,但是却又不可能投入部署大规模虚拟化基础架构,因为一两台虚拟机可能就足够他们使用,此时这种一体机就极大了满足了这部分市场的需求。 在远看一步,集成了VM、集成了应用,这不就是一种IAAS和SAAS服务模式了么?那么VNXe将来会不会直接就作为云存储节点而存在了呢?多台VNXe组成一个大云,从SMB开始逐渐向上渗透?如果说这一代VNXe只是fire in the hole,那么EMC的Marketing对下一代VNXe如果真的打算这么搞下去的话,可能会是一场存储领域的核爆。 然而这只是个推测,具体还要静观其变。不过,现在VNXe中所出现的技术基本上在一两年之后估计也不会有大的本质变化,比如Thin、Dedup/Compression、Snapshot、Replication等等,除非再有全新的概念被炒作出来,所以其下一代产品可能会结合主机虚拟化方面的技术来在人们根深蒂固的传统概念上做变革。 从趋势来看,存储想要发展,就必须绑住应用,只做一个傻盒子,在这个时代已经逐渐丧失了其价值,尤其是云的概念被炒起来之后,传统存储系统将永远被云海所埋没的无影无踪。而如果抱紧了云中的两个最主要元素—虚拟化、应用的大腿,那么也就可以继续站稳云巅。 IBM、HP、Dell、Oracle、Cisco,这些厂商相比EMC来讲最大的区别是什么呢?很显然,就是EMC没有服务器,前者依靠服务器大量出货配套存储,EMC岂能不眼红?怎么办呢?EMC有VMware,这就是关键所在。潮流可能将被EMC所引导,但是是否真的成为潮流,恐怕困难重重,IBM、HP等有大量服务器出货的厂商,不可能任凭EMC抢走其饭碗,他们一定会有动作。 也许有一天,我们做了个APPSTORE,上面放满了企业应用软件,买了我们存储的人,只要使用WEB登陆到存储上,就可以在里面选择企业想使用的软件(HR、CMS、ERP、项目管理、财务软件、会议室预定、请假流程、出差管理、报销系统、在线文档、邮件系统…),然后就自动安装使用了,并且备份、容灾等都在后台可以自动做好。此时,存储系统将会变成一个百变金刚,在上面安装NAS模块,他就变成了NAS设备;装了VTL软件,他就是一款VTL,装了备份软件,那他就是一款备份设备。 应用存储领域可能会有一波大行情,Oracle推出数据库一体机,之前是和HP合作,现在有了Sun。HP也推出了Exchange2010一体机。EMC在VNXe上大肆使用虚拟机来架设,后续可以猜想其可能推出集成Exchange、SQL Server、OA、ERP等的一体机产品,甚至可以提供给用户一个裸VM,供用户自己安装应用软件,很可怕,潮流似乎要接着被EMC引导。 国内应用存储厂商动态 这种概念在国内早已有人试水了,国内有两家存储厂商,一个是UIT,另一个是爱数。UIT直接在其Linux系统中安装软件,比如最多被使用的是第三方的备份软件以及一些视频方面的软件,没有使用虚拟机技术来隔离资源,所有模块(包括存储、应用、管理)都安装在同一个Linux操作系统之上,这样任何一个模块不稳定都可导致整体宕机,而且实现QoS也很难。爱数是一家比较激进和创新以及以技术为导向的公司,同时在市场宣传、形象品牌、渠道方面也都非常强。曾经和其总经理贺鸿富聊过一次,纯技术出身,能做出如此有市场竞争力的产品,确实让人钦佩。他们集成了VM到存储阵列中(基于VMware Server免费版本),将自己研发的备份软件集成进去了(但不清楚是否也像UIT一样直接部署在宿主OS中,推测是的)。而且做了虚拟机容灾,也就是物理机down了虚拟机直接接管服务(使用Agent来同步IO给备份VM),应用存储这个概念也是爱数一直推崇的,因为他们是做软件出身的,他们出发的角度就是从上至下。 有没有技术能力把东西整出来、有没有市场能力把东西推出去、有没有整合能力搞个产业小圈子与国内或者国外ISV联合,这是三个需要考虑的问题。另外,想拿这个来弯道超越的话,需要底盘稳,否则恐怕得做好翻车的准备了。 (以上仅代表个人观点,对VNXe架构和作用原理及预测部分属于推测,严禁对号入座!) | |
|
(9个打分, 平均:5.00 / 5) |
拨云见日:FabricPath—从“交换”到“路由”
作者 libing | 2011-03-21 20:36 | 类型 专题分析, 弯曲推荐 | 127条用户评论 »
|
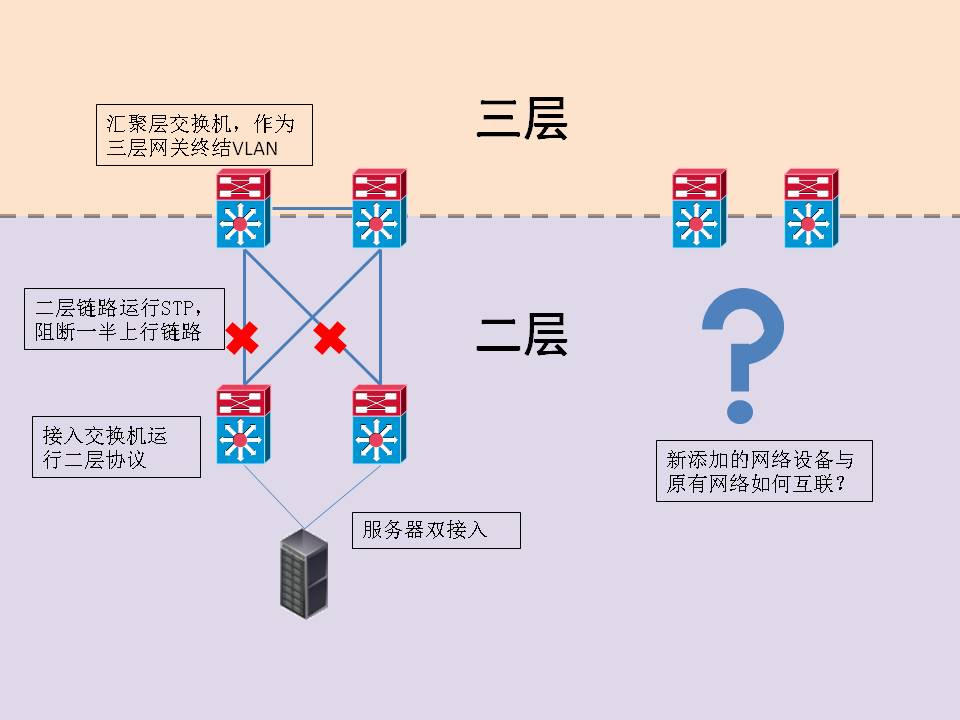
IT行业的发展一日千里,竞争的重点已经从参数、指标的追赶,发展到对标准、概念的主导,市场的领导厂商不再拘泥于设备的具体性能,而是通过掌握最有力的话语权来引导整个行业的发展,最终赢得客户的信任。 在这个争夺话语权的过程中,不计其数的技术名词被制造出来,成百上千的白皮书被PO到网上,如果我们连这些名词的真正含义都不清楚,别说赶英超美,可能被人家忽悠完了都浑然不知,因为至少在目前,信息技术的领军人物还在大洋彼岸,而且这个趋势还将持续很长一段时间。 这也是我写《拨云见日》的本意,就是要拨开表面的浮云,真正探究新技术的本质。在有限的篇幅里,我会以我的理解,尽力说明市场名词背后的技术实现,并摸清新技术产生的商业动机和相应的发展脉络。 今天我们来看看FabricPath是个啥。 关键词:FabricPath 厂商:Cisco 领域:数据中心网络 模糊程度:四星 一、为什么需要FabricPath 缘起 众所周知,Cisco正凭借Nexus产品平定整个数据中心网络市场,2010年,Cisco打出了深藏已久的最后一张王牌—FabricPath,至此,Nexus交换机的主要特性已全部面向公众发布,FabricPath为整个计划添上了最后一块基石,进一步稳固了Nexus作为下一代数据中心网络平台的地位。 大部分人(包括我)第一次阅读FabricPath华丽的白皮书后,只朦胧地知道这是一个“能在大型二层数据中心网络实现多路径的东东”,既然FabricPath解决的是数据中心的问题,我们首先需要弄清楚数据中心到底有什么问题。 今天的大部分数据中心网络是遵循标准的层次化理念建设的,分为接入层和汇聚/核心层,接入层和汇聚层之间为二层链路,三层网关设在汇聚或核心,所有的二层链路上都运行生成树协议(STP),当任意两点间有一条以上路径可达时,STP会block多余的路径,以保证两点间只有一条路径可达,从而防止环路的产生。这种模式在过去很长一段时间被大规模采用,因为其部署起来非常简单,接入层设备不需要复杂的配置,大部分的网络策略只要在汇聚层集中部署就能分发到全网。但随着数据中心的规模不断扩张,这种模型逐渐显得力不从心。
未来数据中心内部的横向流量将越来越大,新加入的设备同原有设备之间仍然要运行STP,如果两台服务器之间只有一条链路可行,其余的万兆交换机端口全被block,不但是投资的极大浪费,也无法支持业务的快速扩展;其次,当交叉链路数量增加时,二层网络的设计会变得非常复杂,哪条链路该保留哪条链路该阻断?三层网关设在何处?类似这样的问题会冒出一大堆,这就失去二层网络配置简单的优势;最后,传统的二层MAC地址没有层次化的概念,同一个二层网络内的接入交换机上存储本网段所有设备的MAC地址,这很容易导致边缘设备的MAC地址空间耗尽,特别是在虚拟化的数据中心内,虚拟机的MAC地址数量可能以千计。
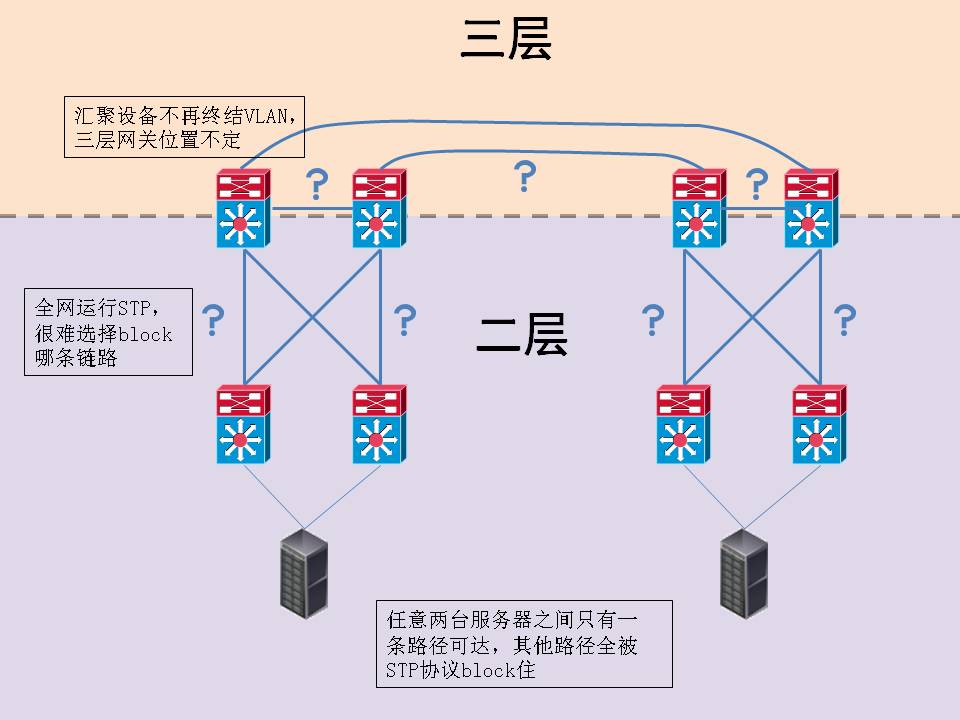
如果二层互联不能解决问题,另一种思路是在汇聚交换机和接入交换机上设置IP网关,通过三层路由将所有交换机连接起来,类似的解决方案还包括将网关设置在核心设备上,通过核心设备集中互联。这个做法以前也许勉强可行,但在虚拟化环境中,二层网络是虚拟机迁移的基础。虚拟化的最大特点是可以将业务动态部署到数据中心的任何计算资源上,如果这些计算资源(也就是服务器)被过多的三层网关隔离开来,也就失去了虚拟化的优势。 同时,采用三层接入设备会产生大量的三层网关以及无数个让网管人员抓狂的地址段。动态路由协议的行为往往难以预测,在重要数据中心,为了保证网络行为的可控性,每台交换机的路由策略都要经过仔细琢磨,这个工作量过于庞大;而如果采用静态路由,一旦后期需要改动某个地址段的范围,可能需要改写一大段接入换机的路由表,更不用提相关访问控制策略的变动。
至此,我们走进了死胡同,虚拟化的应用要求基础网络在扩展时保持一个完整的二层环境,而随之而来的STP和地址空间问题又成为绕不开的坎,在接受二层环境的同时,我们基本上也就同一大堆时髦的字眼say byebye了,这些字眼包括但不仅限于“动态扩展”、“多路径”、“快速收敛”、“层次化寻址”等等,仰望IP路由,二层网络就好象一个生活在原始社会的苦行僧,忍受着种种的考验,传统网络在支持虚拟化数据中心扩张时已经越来越吃力。 为了改变这种尴尬的局面,在烧掉大把银子之后,Cisco的FabricPath终于闪亮登场了! 目标 简单说,FabricPath是Cisco Nexus交换机上的一项技术特性,其目标是在保证二层环境的前提下,修复前文所说的缺陷,这个技术需要做到以下几点:
更准确地说,我们要摆脱传统二层“交换”的弊端,在二层环境中实现类似三层IP的“路由”行为。 二、FabricPath:从“交换”到“路由” L2不给里的原因 我们知道FabricPath的目标是为传统二层环境设计一个增强型方案,以屏蔽原来的缺陷,实现对数据帧的“路由”转发。要明白FabricPath是怎么做到这点的,首先要看看layer 2这些不给力的毛病到底是怎么出来的? 传统二层以太网环境中的数据转发是非常简单的,一台二层交换机一辈子干的活可以用以下几句话概括: 1)收到数据帧–>2)查看目的地址–>3)查看MAC地址表–>4)将数据帧从对应端口送出去 偶尔,当这个流程进行到第三步时,交换机会发现目的地址不在自己的MAC地址表中,它会怎么做呢?这台茫然的交换机就会将这个数据帧从所有的端口广播出去!没错,是整个帧从所有端口发送出去,希望其他交换机能知道正确目的地。且不说,这个方式在今天看来是多没有效率,当设备之间存在环路时,这种帧会被无尽地转发下去,最终形成广播风暴。 为了解决这个问题,交换机厂商引入了STP。STP的机制也极其简单,就是通过阻断二层端口来防止环路,并阻止数据帧从其接收到的端口再转发出去。
广播帧在任意节点只会被转发一次,避免了被永远转发下去。但如前所述,运行STP的代价是非常昂贵的,接入设备只有一条上联链路没被block,而且,在复杂的网络连接中,控制STP的行为变得很困难,一旦出现震荡,其收敛效率也非常低下。 另一方面,二层交换机通过学习接收到的数据帧的源地址建立MAC地址表,所有接收到的数据帧源地址都会被放进MAC地址表中,导致一台交换机可能学习到整个网段内的所有二层地址,就算它大部分时间只跟其中的一小部分有联系。 由此可见,今天的二层网络过于简单,交换机只会学习网络地址,不会基于学到的地址规划出一套转发数据的最优方案,它的问题类似于只有一个数据平面,没有控制平面的概念,这就导致二层交换机不可能有效地进行“路由”,从而引入了STP等一系列问题。 FabricPath的实现:新的控制平面 既然二层网络的问题是控制平面的缺失,FabricPath的思路就清晰了,那就是重塑一个控制平面。 为了能够高效地支持数据中心扩展,这个新的控制平面需要具备几个基本功能,包括
为了构建这样一个控制平面,FabricPath主要做了以下两件事: 1)新增一个二层帧头 2)增加一套简化的IS-IS路由协议 这个新的帧头添加在原有数据帧之外,包含了丰富的信息,其中最重要的三个字段是源地址、目的地址和TTL。 源地址和目的地址来自FabricPath新定义的一个名为switch ID的全新地址空间,任何一个新加入FabricPath网络的设备都会被分配一个1~4094之间的整数,作为唯一的switch ID,用于标识一台交换机的身份,也是节点之间进行路由寻址的依据。 TTL(Time To Live)字段定义了一个数据帧的最长生存周期。当生成一个数据帧时,其TTL字段被写入一个整数,每当其经过一台交换设备TTL就减一,直到TTL为零时,这个帧将被丢弃。TTL的概念是TCP/IP的基础之一,在FabricPath中,TTL承担了同样的任务,保证数据帧不会在成环的链路中被无限次转发,从而使得二层环境不再需要运行STP协议,不再有链路被Block,这是实现两点之间多路径转发的基础。 相较帧结构的变化,FabricPath更重要的改进在于引入IS-IS这样一套完整的路由协议。IS-IS是一个广泛运行于运营商等大型网络的路由协议,同OSPF类似,IS-IS也是一个链路状态协议,会维护一个链路状态数据库,相比MAC寻址这样的距离矢量行为,运行链路状态协议的设备能够在内存中建立一张包含全网设备的拓扑,并且在这个拓扑的基础上挑选当前链路状态下的最短路径来转发数据。IS-IS的效率很高,且IS-IS区域能平滑地平移、分割、合并,但相较OSPF最大的不同在于,IS-IS可以封装在链路层报文中支持多种网络层协议,而OSPF只能封装在IP包中支持IP协议,这就使得IS-IS能够很容易被移植到FabricPath中,为二层数据帧的转发提供路由服务。 FabricPath中实际运行的是一个简化版本的IS-IS协议,不再依赖MAC地址进行寻址,依靠交换机的switch ID工作,在节点之间交换IS-IS信令构建路由表,IS-IS协议会事先计算出最优路径作为数据转发的依据。有了IS-IS的助阵,FabricPath能够轻松地实现两点之间的ECMP、网络拓扑的快速收敛、以及快速的错误诊断等高级路由功能。 新的地址空间加上IS-IS协议,FabricPath基本建立起一个控制平面雏形,数据平面和控制平面各司其职。 如果你是个较真的同学,你的第一个问题该出现了,为什么不延用原有的MAC地址,而要兴师动众地加入一套新地址呢? 问得好! FabricPath中的IS-IS协议会建立一套逻辑树结构,这个结构说明了任意两点间的最优路径,是交换机转发数据的依据。路由协议在计算逻辑树的过程中往往会用到设备的标识号,由于MAC地址在设备出厂时就固定了,不同设备之间的地址没有任何规律,如果使用MAC地址作为唯一标识,生成的将是一个随机结构,这有可能导致最终的转发路径不是当前的最优路径。由于路由协议的算法是写死的,要避免这种情况只能人工调整各个节点的标识大小,这种情况同部署STP时调整交换机的优先级,以保证最优的转发路径是一个道理。然而,FabricPath设计的初衷就是保留二层配置简洁的优势,如果将STP的老毛病一并带过来,无疑大大削弱了对客户的吸引力,不利于现有网络向FabricPath的迁移。 既然是从头设计一套全新的机制,不如追求一把极致,将所有复杂的工作都隐藏到幕后,只呈现给用户最简洁的一面,这就是FabricPath费尽苦心设计一套地址空间的出发点。 FabricPath的工作模式
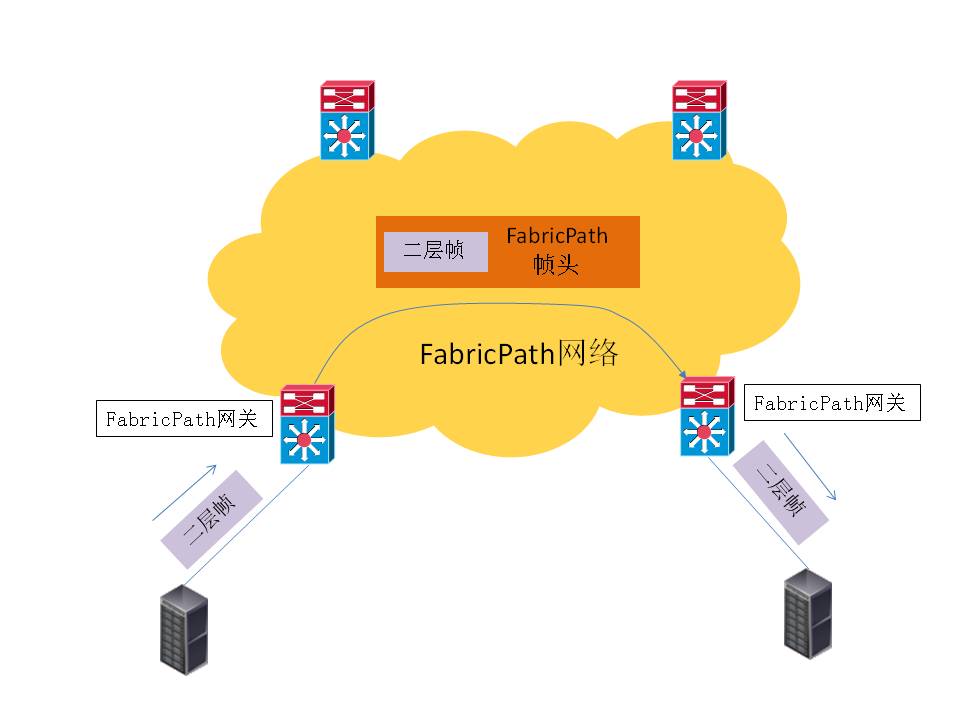
上图中,数据帧在进入FabricPath网络时,会被打上新帧头,在FabricPath网络内根据帧头里的switch ID进行转发,离开Fabric Path网络时,脱去帧头,进入传统的以太网交换环境。要加入FabricPath网络,只需在交换机对应端口上启用FabricPath模式即可,所有的地址分配和路由策略都自动生成,无需繁琐的配置。
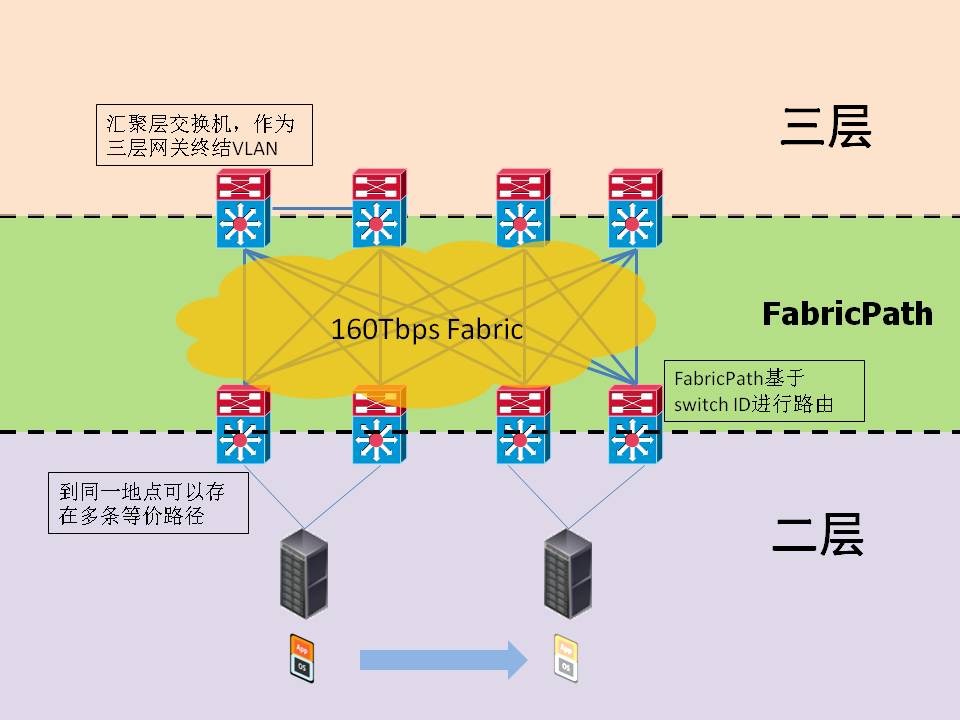
上图是一个典型的FabricPath组网,汇聚设备同接入设备之间为FabricPath网络,FabricPath网络内没有运行STP,多条链路都能够转发数据,目前版本的FabricPath支持16条等价路由,也就是说在使用万兆链路的情况下,任意两点间的带宽可到2.56Tbps(16条等价链路结合,每条等价链路为16个万兆portchannel)。 接入设备作为网关连接了传统以太网络同FabricPath网络,FabricPath网关上可以进行“基于会话的MAC地址学习”,只有那些目的地址为本地设备的数据帧的源地址会被放入网关的MAC地址表,其他数据帧的源地址以及广播帧的源地址都不会被学习,这就保证了边缘网关设备的MAC地址表里只保存与本地有会话关系的MAC地址,这个举措能够大大缩小虚拟化数据中心内接入设备的MAC地址表体积。 基于IS-IS的特性,FabricPath网络设备的switch ID可以动态修改,而不影响流量转发,当数据中心规模不断扩张时,可以利用FabricPath平滑地扩展其汇聚层,并在接入设备间实现高达16条二层多路径(ECMP)。 第二个问题 OK,这一切都看上去很美,但你有没有觉得哪里不对劲?这就是我对FabricPath的第二个问题,以上说的所有这些东西,新增帧头啦、新的选路机制啦,和VPN不是差不多吗?在今天这个技术过剩的时代,难道找不出一个能解决这些问题的现有技术,非要重新折腾出一套新玩意吗? 现有VPN技术种类繁多,但大多数都使用IP包承载,协议开销较大,这与二层具备的快速转发特性是背道而驰的,仅此一项就将IPSec等三层VPN技术屏蔽在可选项之外。剩下的二层VPN中最常见的是类似MPLS+VPLS的实现方式,MPLS是一个2.5层技术,专门用于大量数据的快速转发,但问题是,MPLS的控制平面仍然需要IP报文进行路由,每个节点仍需要进行IP配置,而部署一个MPLS+VPLS网络你觉得容易吗?反正我看着都觉得头大,如果一种局域网技术需要网管人员先学习一遍MPLS,我觉得这种技术基本也没啥戏可演了。 标准化 FabricPath是Cisco近期在数据中心领域最重要的一个发布,同时也预示着基础网络向下一代模型转型的开始。数据中心内不断增长的横向流量推动了二层多路径技术的迅速发展,FabricPath是这股潮流的重要组成部分,但Cisco不是唯一的声音。 目前致力于实现二层多路径的标准化组织主要有IETF和IEEE,两家的标准分别为TRILL和802.1aq,都采用IS-IS作为路由协议,实现方式大同小异。目前,TRILL和802.1aq都已接近完成,预计2011年底就能够正式标准化。 Cisco在TRILL的制定过程中参与极深,虽然FabricPath是Cisco的私有解决方案,但可以看作一个“增强版的TRILL”,是TRILL的基本功能加上“基于会话的MAC地址学习”、“Vpc+”和“多重拓扑”等高级功能的合集。 Cisco已经发布了支持FabricPath的Nexus 7000板卡,并且承诺现有架构与TRILL标准兼容,当TRILL正式标准化之后,只需要升级现有设备的软件,就能够与标准的TRILL交换机互联互通。 三、结语 随着数据中心内虚拟化应用的不断扩张,底层的数据行为也在悄然发生改变,带动了基础架构的演进。未来的数据中心不仅需要大容量、高密度的网络设备,还要能够顺应这种数据行为的变化,并反过来提供经过优化的网络平台,这种从量到质的变化将深刻影响数据中心技术的发展。 FabricPath是Cisco在这个方向的重要布局之一,结合之前发布的FCoE、OTV、VN-LINK等技术,一个新一代数据中心网络平台已经隐约可见,Cisco只待市场大转型的到来,再次一举确立在网络行业的领导地位。 了解FabricPath有助于我们认识数据中心网络的演进方向,把握整个行业的脉搏,从而形成自己的思考,得出自己的结论。 五分钟Q&A 1)什么是FabricPath? FabricPath是思科Nexus交换机上的一项特性,能够实现二层多路径数据转发。FabricPath能够在二层环境实现类似三层的路由功能,帮助虚拟化数据中心网络实现平滑扩展。 2)FabricPath有哪些好处? FabricPath网络不再需要运行生成树协议(STP),没有链路被阻断,大大增加了网络传输带宽,很好地支持了服务器之间迅猛增加的横向流量。同时,FabricPath能够实现类似三层的路由功能,支持二层网络的平滑扩展。 3)FabricPath与现有二层交换冲突吗? FabricPath的前提是不破坏现有的二层交换行为,FabricPath网络对已部署的接入设备来说是一个透明连接。 4)如何部署FabricPath? 在支持FabricPath的设备上将端口配置为FabricPath模式,系统会自动完成地址分配、路由建立等行为,无需手动干预。 5)什么是TRILL? 为了实现二层多路径功能,IETF在RFC5556中定义了一套方法,命名为Transparent Interconnection of Lots of Links,又名TRILL。 6)FabricPath是私有协议吗? FabricPath是Cisco的市场词汇,用来表示思科的二层多路径技术,所以,FabricPath不是一项私有协议,但它是思科的私有技术实现。 7)FabricPath同TRILL的关系? Cisco在TRILL标准制定过程中参与极深,并且积极推动TRILL的最终成型。FabricPath是TRILL正式标准化之前,Cisco推向市场的“Pre-Standard”技术,基本内容与TRILL相同, 增加了“基于会话的MAC地址学习”、“Vpc+”和“多重拓扑”等高级功能。FabricPath架构与TRILL完全兼容,Cisco承诺FabricPath平台将全面支持TRILL协议,TRILL正式标准化之后,通过软件升级,现有FabricPath设备能够与标准的TRILL交换机互联互通。 8)什么设备能够支持FabricPath? 2010年Cisco在Nexus 7000交换机上发布了一块支持FabricPath的32口万兆光纤板卡,以及相应的软件。未来,FabricPath技术会扩展到更多的Nexus 7000和Nexus 5000交换机上。 9)市场上还有那些类似FabricPath的解决方案? 目前没有完全相同的产品,Juniper的QFabric在二层扩展方面与FabricPath类似,但QFabric是一个私有架构,目前也没有开放的时间表。 | |
|
(21个打分, 平均:4.81 / 5) |


工具箱
本文链接 |
|
打印此页 | 127条用户评论 »
NOX – 现代网络操作系统
作者 yeasy | 2011-03-01 08:25 | 类型 互联网, 弯曲推荐, 新兴技术 | 18条用户评论 »
系列目录 Future Internet Technology[注]本系列前面的三篇文章中,介绍了软件定义网络(SDN)的基本概念和相关平台。按照SDN的观点,网络的智能/管理实际上是通过控制器来实现的。本篇将介绍一个代表性的控制器实现——NOX。 现代大规模的网络环境十分复杂,给管理带来较大的难度。特别对于企业网络来说,管控需求繁多,应用、资源多样化,安全性、扩展性要求都特别高。因此,网络管理始终是研究的热点问题。 从操作系统到网络操作系统早期的计算机程序开发者直接用机器语言编程。因为没有各种抽象的接口来管理底层的物理资源(内存、磁盘、通信),使得程序的开发、移植、调试等费时费力。而现代的操作系统提供更高的抽象层来管理底层的各种资源,极大的改善了软件程序开发的效率。 同样的情况出现在现代的网络管理中,管理者的各种操作需要跟底层的物理资源直接打交道。例如通过ACL规则来管理用户,需要获取用户的实际IP地址。更复杂的管理操作甚至需要管理者事先获取网络拓扑结构、用户实际位置等。随着网络规模的增加和需求的提高,管理任务实际上变成巨大的挑战。 而NOX则试图从建立网络操作系统的层面来改变这一困境。网络操作系统(Network Operating System)这个术语早已经被不少厂家提出,例如Cisco的IOS、Novell的NetWare等。这些操作系统实际上提供的是用户跟某些部件(例如交换机、路由器)的交互,因此称为交换机/路由器操作系统可能更贴切。而从整个网络的角度来看,网络操作系统应该是抽象网络中的各种资源,为网络管理提供易用的接口。 实现技术探讨模型NOX的模型主要包括两个部分。 一是集中的编程模型。开发者不需要关心网络的实际架构,在开发者看来整个网络就好像一台单独的机器一样,有统一的资源管理和接口。 二是抽象的开发模型。应用程序开发需要面向的是NOX提供的高层接口,而不是底层。例如,应用面向的是用户、机器名,但不面向IP地址、MAC地址等。 通用性标准正如计算机操作系统本身并不实现复杂的各种软件功能,NOX本身并不完成对网络管理任务,而是通过在其上运行的各种“应用”(Application)来实现具体的管理任务。管理者和开发者可以专注到这些应用的开发上,而无需花费时间在对底层细节的分析上。为了实现这一目的,NOX需要提供尽可能通用(General)的接口,来满足各种不同的管理需求。 架构组件下图给出了使用NOX管理网络环境的主要组件。包括交换机和控制(服务)器(其上运行NOX和相应的多个管理应用,以及1个Network View),其中Network View提供了对网络物理资源的不同观测和抽象解析。注意到NOX通过对交换机操作来管理流量,因此,交换机需要支持相应的管理功能。此处采用支持OpenFlow的交换机。
操作流量经过交换机时,如果发现没有对应的匹配表项,则转发到运行NOX的控制器,NOX上的应用通过流量信息来建立Network View和决策流量的行为。同样的,NOX也可以控制哪些流量需要转发给控制器。 多粒度处理NOX对网络中不同粒度的事件提供不同的处理。包括网包、网流、Network View等。 应用实现NOX上的开发支持Python、C++语言,NOX核心架构跟关键部分都是使用C++实现以保证性能。代码可以从http://www.noxrepo.org获取,遵循GPL许可。 系统库提供基本的高效系统库,包括路由、包分类、标准的网络服务(DHCP、DNS)、协议过滤器等。 相关工作NOX项目主页在http://noxrepo.org。 其他类似的项目包括SANE、Ethane、Maestro、onix、difane等,有兴趣的同学可以进一步研究参考。 | |
|
(4个打分, 平均:5.00 / 5) |
