




WeConnect PhotoBox --Connect your friends via Photos!
作者 陈怀临 | 2011-12-18 10:28 | 类型 行业动感 | 42条用户评论 »
|
这年头啥是平台?已经是平台的才是和就是平台[有点哲理,大家不要被忽悠了]。 Facebook就是平台。是平台的才是平台。否则是意淫。。。 如何把Killer应用和事实上的平台结合在一起???? WeaverMobile隆重推出: WeConnect PhotoBox!!!!! “Connect Friends via Photos” 几个亮点如下: 1。 方便的,完整的看自己和所有朋友在Facebook上的照片集 2。 可以批量上载你在旅游,[各种]派对,家庭聚会,同学聚会的照片。速度惊人 3。 可以批量下载存档自己和朋友在Facebook上的照片 4。 可以非常方便的repost照片,like it和各种操作! 5。 性能全面超过Facebook app和其他相关app!特别是批量photo的操作! 下载地址: App Store: http://itunes.apple.com/us/app/weconnect-photobox/id487803225?mt=8 Or Search “WeConnect PhotoBox” from App Store in your iPhone/iPad
| |
 (没有打分) (没有打分) |



山石网科 。苏州 。研发基地
作者 陈怀临 | 2011-12-14 18:58 | 类型 行业动感 | 16条用户评论 »
清华创业集中营 。北极光 。邓锋 。谈创业
作者 陈怀临 | 2011-12-14 16:51 | 类型 行业动感 | 2条用户评论 »
《给力吧,x86》专题连载九:英特尔Sandy Bridge平台网络通信性能测试分析
作者 老韩 | 2011-12-14 11:07 | 类型 研发动态, 科技普及, 网络安全, 行业动感, 通讯产品 | 57条用户评论 »
|
本篇是《给力吧,x86》专题的第9篇连载内容,也是截至目前最后一篇。其中性能评估从Atom N270到Sandy Bridge,涵盖了目前主流嵌入式平台(尚缺3420)。后面如果时间、精力、环境允许,会补充针对NIC的独立测试。再次感谢同事与厂商朋友们付出的努力,也感谢弯曲站务组和读者朋友们的支持。 本专题内容原文刊登于《计算机世界》。水平有限,文中定有偏颇之处,希望弯曲网友不吝赐教。 ============================================================== 上一期连载内容中(见本报今年35期第36、37版),我们记录了上海交通大学网络信息中心的老师们通过严谨的测试,选择基于英特尔5520平台的x86服务器打造校园网流量分析与优化系统的全过程。那么,万众瞩目的英特尔新一代Sandy Bridge平台在网络通信应用中又会有怎样的表现?它是否可以将效能推进到一个新的高度?就让测试数据去证明一切吧。
规格放大 体积缩小 FW-8865的核心是英特尔Cougar Point C200芯片组中最高端的型号C206,支持LGA1155接口的Sandy Bridge处理器,包括企业级的Xeon E3和桌面级的Core i3/i5/i7。理论上,LGA1155平台的Sandy Bridge处理器和芯片组可以混合搭配,但前提是使用正确的、高质量的BIOS,因此并不是所有的主板都能良好地兼容两种处理器。FW-8865在这方面显然不存在问题,因为测试中使用的就是一颗四核心、32nm工艺制造的Core i7 2600K。该处理器具有256KB L2缓存(每核)和共8MB容量的通过环形总线和CPU核心连结的共享L3缓存,主频为3.4GHz,最大Turbo Boost频率可以达到3.8GHz。不过从稳定性的角度考虑,该特性在测试中没有被启用。同样的道理,Core i7 2600也支持超线程技术,可以提供8个硬件线程,但在测试中也被关闭。 针对处理器内置PCIe 2.0 Lane数量的差异,FW-8865的主板也分为支持Core i系列的MB-8865A和支持Xeon E3系列的MB-8865B。对于后者来说,Xeon E3系列处理器额外的4个PCIe Lane也连接到左起第三个扩展接口模块,与C206提供的另外4个PCIe Lane共同工作,使接口带宽加倍;另外两个接口扩展模块的规格则没有区别,使用的都是处理器上16个PCIe Lane配成的两个x8接口。内存方面,MB-8865A/B都提供了4个ECC DIMM插槽,最大支持32GB的Unbuffered ECC/Non-ECC DDR-1333内存。而我们测试的这台设备配备了两条2GB容量的DDR3-1333内存,工作在双通道模式。FW-8865的标准配置还包括一个Mini-PCI插槽、一个x4的PCIe Riser(与OPMA远程控制模块复用)、一个CF卡插槽和4个SATA端口,并使用一颗Realtek出品的RTL8110SC千兆网络控制器作为管理配置接口。 作为最新一代的网络通信硬件平台,FW-8865提供了多种高速以太网接口扩展模块(甚至包括万兆电口的型号),可供用户灵活选配。对于这个目前最强大的x86平台来说,千兆级别的负载显然不能充分挖掘其性能,所以本次测试都在搭配双万兆接口扩展模块的FW-8865上进行(使用与处理器直连的槽位)。该模块基于英特尔82599ES打造,它是常见的82599EB的串行版本,主要区别是针对高密度/刀片应用增加了对串行背板总线的支持,功能、性能都极其强大。在T540尚未推出前,它们是英特尔万兆网络控制器产品线中最顶级的型号。82599ES/82599EB使用了5GT/s的PCIe 2.0 x8接口,支持32个PCIe并发请求和512字节的PCIe有效载荷,以及MSI和MSI-X(Extended Message Signaled Interrupt,扩展消息告知中断)特性。单芯片提供双万兆以太网接口是82599ES/82599EB的标准规格,每个接口可以支持128个TX/RX队列,并可根据需要最多划分为64个RSS(Receive Side Scaling,接收方扩展)队列。此外,它们还支持RSC(Receive Side Coalescing,接收方聚合)、低延迟中断等技术,以及包括基于L2 Ethertype、5元组、SYN标识以及英特尔Ethernet Flow Director在内的多种分类/过滤特性。 也许是因为英特尔在芯片层面就开始整合,基于Sandy Bridge平台的FW-8865在设计上显得并不复杂,2U规格的机箱内留有大量空间,对系统散热十分有利。而从最大300W的冗余电源的配置来看,该机的整体功耗也相对较低。有了这样的优势,立华科技也推出了接口数量略低的1U规格产品,在机架空间愈发宝贵的今天相信会有更强的竞争力。 40G:理想照进现实 我们依旧采用了NCPBench 0.8评估软件,依照RFC 2544标准对多达4个万兆接口进行了纯转发模式下的测试(NCPBench的功能介绍和使用方法见本报今年第16/17期51版)。起初我们曾怀疑这个发布已有一段时间的版本不能充分发挥最新硬件平台的性能,但事实证明这种担心是多余的。FW-8865在测试中的表现,足以用震撼二字来形容:当我们将一个扩展模块上的两个万兆接口配置为网桥进行测试时,64Byte帧的整体转发速率达到22.3Mpps,吞吐量达到14.98Gbps;换用128Byte帧时,吞吐量上升为19.37Gbps,已接近线速。有了这样的铺垫,FW-8865在使用256Byte-1518Byte帧的测试中做到线速转发就丝毫不令人惊讶了,这台基于Sandy Bridge架构的网络通信硬件平台就这样轻松刷新了x86平台的性能记录。
表1 FW-8865吞吐量测试结果(1组桥,1组双向流量,同模块) 一直关心本专题的读者朋友们可能记得,在上一篇关于英特尔5520平台的测试记录中,由上一代顶级至强处理器X5690搭配82599万兆网络控制器的系统在同样的测试条件下只达到整机10.24Mpps的64Byte帧转发能力。仅仅更新系统平台就能让性能翻倍,Sandy Bridge的火力未免也太过强劲。为了寻找系统瓶颈,我们开始人为地制造一些障碍。在以往的测试中,我们曾经遇到过一些产品,其跨模块测试时的性能要远低于同模块内测得的性能。为验证这种现象在FW-8865是否存在,我们将隶属不同模块的两个万兆口配置为网桥,重新进行了一次测试,结果不降反升:系统自128Byte帧起就已线速转发,64Byte帧时的整机转发速率更是达到了惊人的28Mpps,吞吐量接近19Gbps。我们猜测之前单模块时的接口资源有限,如PCIe接口的并发请求数量和重传缓冲都可能受到限制;跨模块测试时,可以调用的资源翻倍,从而提升了平台的整体性能。而两个万兆接口模块直接连接到CPU,其间没有了可能成为性能瓶颈的桥片,也许是性能提升的另一个因素。
表2 FW-8865吞吐量测试结果(1组桥,1组双向流量,跨模块) 看来20G已经无法阻止彪悍的Sandy Bridge平台了,感谢立华科技为我们提供了两个万兆接口扩展模块,能让压力测试继续上升到x86从未染指过的40G级别。在巨大的压力下,当同一模块上的两个万兆口分别配置为网桥进行测试时,整机64Byte帧的转发速率为23.3Mpps,较同模块1组桥时略有上升,但大大低于跨模块1组桥时的性能。但在使用128Byte帧的测试中,FW-8865的整机转发速率基本没有下降,吞吐量达到27.54Gbps。并且从256Byte开始,做到40G流量的线速转发。我们随后也在跨模块两组桥的配置下重复了测试,结果没有发生任何变化。老实说,有了之前的测试结果打底,本次测得的多个40G线速转发的结果并没太令人惊讶。照这种情况推断,只要接口带宽不成为瓶颈,Sandy Bridge平台的大包转发能力即便测到60G也不足为奇。相反,64Byte帧时的性能下降是个很意外的情况,在以往测试中很少出现,推断其瓶颈应出现在I/O层面。
表3 FW-8865吞吐量测试结果(两组桥,两组双向流量,同模块)
表4 FW-8865吞吐量测试结果(两组桥,两组双向流量,跨模块) 为了弄清造成这种情况的原因,我们又构造了一个新的测试用例。在刚才的环境中,我们去掉了1组桥中某个方向上的所有数据流,对FW-8865施加共30Gbps的测试流量(1组双向流量+1组单向流量)。这次的结果又高得令人感到意外,该平台在使用128Byte帧测试时吞吐量就基本接近线速;64Byte帧时的整机转发速率更是大幅增加至32.5Mpps,吞吐量达到21.86Gbps。并且无论将同模块还是不同模块中的两个接口配置为网桥,性能都保持一致。虽然这一结果依然无规律可寻,但我们确实是第一次在x86平台上见到64Byte帧转发能力超过20Gbps,就请记住这个由Sandy Bridge创造的里程碑吧。
表5 FW-8865吞吐量测试结果(两组桥,1组双向流量+1组单向流量,同模块)
表6 FW-8865吞吐量测试结果(两组桥,1组双向流量+1组单向流量,跨模块) 需要说明的是,以上所有测试结果都是在NCPBench中设定一个vcpu(即一个物理核)做管理、两个vcpu做I/O时得到的。我们也尝试着使用除了管理核外的其它所有3个vcpu做I/O,但测得的性能并没有像预期那样线性增长,反而会略有下降。但当NCPBench运行在“转发+简单业务”模式时,两个vcpu情况下的性能会有超过20%的下降,3个vcpu时的性能则不受影响。这至少说明在第二种情况下,处理器的负荷仍未达到100%,理论上可以在保证速度的前提下进行更加复杂的业务处理。
测试后记:x86,真的开始给力了 自从2月28日刊登第一篇内容开始,本专题已陆续进行了9期连载。我们与读者朋友们一起,回顾了x86平台在网络通信领域的应用历程,也分析了曾经活跃在市场上的一些产品解决方案。此后,我们开始了网络通信硬件平台的实际测试工作,对几款目前主流的x86解决方案进行了分析,亲眼见证了其规格与性能不断提高的过程。虽然它们与同级别的专用产品解决方案相比仍不占优,但差距已明显缩小,表现出一定的市场竞争力。而英特尔最新的Sandy Bridge平台在测试中表现出的超群实力,完全扭转了之前的被动局面,达到业界领先水平。在用户业务逐步由网络层转向应用层的今天,x86平台凭借I/O与计算能力方面的综合优势,也有机会去赢得更多的市场。如果说以前英特尔在网络通信领域处于追随者的位置,那么Sandy Bridge平台的横空出世,则意味着这个通用领域的巨擘已经站在了该领域的最前沿,抢占了云时代的先机。 链接:“企业级”价值何在? 今年4月,英特尔面向四路及四路以上服务器市场发布了代号为Westmere-EX的Xeon E7系列处理器。一同发布的还有Xeon E3,一类面向单路服务器/工作站市场的产品。实际上,Xeon E3就是1月份发布的Sandy Bridge-DT处理器的Xeon版本,它们非常相似,例如一样都是LGA 1155封装,使用的芯片组也同属Cougar Point PCH系列。甚至在价格上,英特尔官方给出的两类同级别产品的指导价也只有很小的差异。
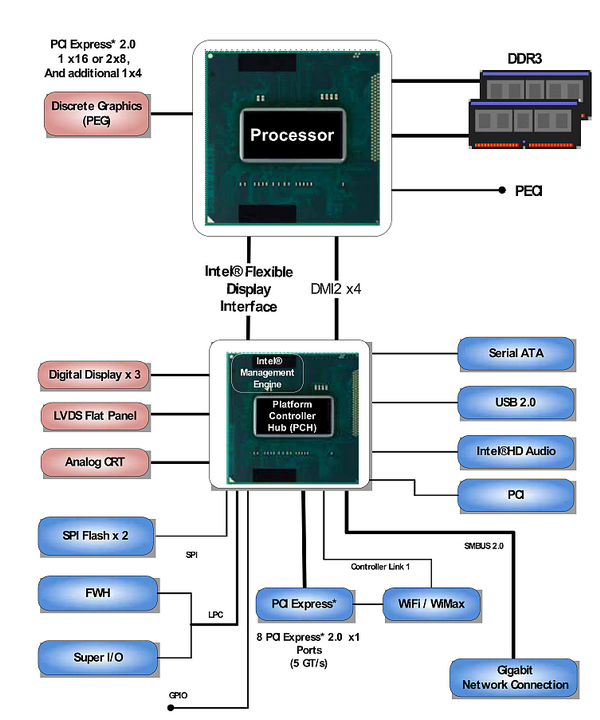
不过,面向企业市场的产品和面向桌面市场的终究还有一些不同。目前,大部分英特尔平台已经走向单芯片组方案,很多功能融合进CPU,因此差异也更多地体现在CPU上。与桌面版本一样,Xeon E3也集成了传统的北桥,提供PCI Express 2.0接口,但它提供了20个Lane,比桌面版本多出4个,较为明显地增强了其综合I/O能力。例如对工作站用户来说,可能需要使用一个x16接口或者两个x8接口连接单显卡/双显卡,同时还需要通过阵列卡连接磁盘系统,并使用高速网卡连接到局域网。这时,桌面级处理器的16个Lane就显得捉襟见肘,虽然设备也可连接到PCH上,但其带宽和延迟均无法与CPU直连的模式相提并论。而对于网络通信应用来说,PCIe Lane的数量直接决定了最大接口数量,自然是多多益善。 第二个差别体现在内存支持上,几乎所有的桌面级处理器都不支持ECC内存。而企业级应用通常都会长期持续运行,它们需要7×24的可靠性,因此所有的Xeon处理器都支持ECC技术。常见的可以检查多位错误并纠正单位错误的ECC内存会自动检测并纠正约99.99%的内存错误,可以消除约1/3的由数据破坏引发的系统出错事件,提升了系统长期运行时的稳定性。 Xeon E3还提供了无内置显卡的版本,这也是一个比较明显但不是所有情形下都能从中获益的区别。笔者在Sandy Bridge测试分析系列连载的第5篇(见本报今年11期第48版)中曾经介绍过,目前所有的桌面版Sandy Bridge处理器中均集成了显卡,它将会与CPU共享L3缓存。如果确定不使用内置显卡,可以通过屏蔽的方式提升CPU可以使用的L3缓存容量,从而提高性能。 Cougar Point PCH的桌面版本是为人所熟知的P67、H67、Z68等芯片组,而其服务器版本则称为C200系列,目前有C206、C204、C202三个型号。它们的区别主要体现在扩展性方面,例如最低端的C202仅能支持CPU提供的16个PCIe Lane,不支持CPU内置显卡,也不支持SATA 6Gb/s端口及Intel AMT 7.0特性。除此之外,C200系列芯片组能够支持更多的TACH/PWM风扇控制信号、PECI(Platform Environmental Control Interface)界面和SST(Simple Serial Transport)总线,C204还可以实现英特尔特有的Node Manager特性,可以监控管理每个节点的能耗。以上多种企业级特性,对提升网络通信产品的可靠性来说有着非常积极的意义。(文/计算机世界实验室 盘骏) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
  (3个打分, 平均:4.67 / 5) (3个打分, 平均:4.67 / 5) |


《给力吧,x86》专题连载八:英特尔5520平台网络通信性能测试分析(下)
作者 老韩 | 2011-12-12 17:16 | 类型 研发动态, 科技普及, 网络安全, 行业动感, 通讯产品 | 26条用户评论 »
|
上一期连载内容中(见本报今年34期第28、29版),我们介绍了上海交通大学网络信息中心的老师们在流量分析与优化系统选型中面临的问题。那么,x86平台在万兆环境下能否稳定工作?现有平台的性能是否又能满足需求?针对种种疑虑,老师们对送测产品进行了长期、细致的测试验证工作。
性能初测通过 在吞吐量测试中,老师们只选择了64Byte和512Byte两种比较具有代表性的帧长。前者是对设备极限性能的考验,现网中绝少出现(个别DDoS攻击会在短时间内产生大量小包,对工作在4层以上的设备造成很大压力);后者则比较接近现网中的平均包长(600-700Byte),测试结果具有比较强的参考价值。考虑到个别设备会在超过极限处理能力后性能大幅下降,丢包率远远超过理论值(通常丢包数量应等于测试流量减去极限处理能力),有着资深运维经验的老师们还特别考察了Panabit在过载时的性能表现。
表注:吞吐量、丢包率测试结果(4层,数据包有IP头/协议类型UDP) 从结果中可以看出,面对一系列苛刻的测试条件,由顶级英特尔5520平台所承载的Panabit应用层流量分析与优化系统还是表现出了不错的性能。在使用64Byte帧进行测试时,系统整体吞吐量达到20%,整体包转发速率为5.96Mpps;当使用512Byte帧时,系统整体吞吐量达到64%,整体包转发速率为3Mpps。测试结束后在Panabit提供的统计信息中可以看到,所有流量也被顺利识别为未知协议。而在使用略高于两个极限值的测试流量进行过载测试时,测试仪统计得到的丢包率也在预定范围内,系统整体运行稳定。
表注:吞吐量、丢包率测试结果(3层,数据包有IP头/协议类型None) 瓶颈究竟出现在哪个环节?是转发层面还是业务层面?老师们利用之前的环境,使用另一组测试用例进行了验证。这次测试仪发出的流量将不包含UDP头部,仅为带有IP头的3层报文。根据Panabit应用层流量分析与优化系统公布的运行逻辑,这样的流量从负责数据转发(I/O)的内核提交到做状态检测与应用协议识别控制的内核后,将只进行连接层面的处理,业务逻辑基本等同于工作在桥模式下的状态检测防火墙。在抛开繁重的应用协议识别的包袱后,系统的整体处理能力是否会有一个飞跃呢?测试得到的结果令人感到意外,当使用64Byte帧进行测试时,整机吞吐量仅比之前高出4个百分点;而当使用512Byte帧测试时,吞吐量没有发生任何变化。虽然目前无法判断状态检测引擎是不是瓶颈所在,但基本可以判定应用协议的识别控制并不是系统整体的瓶颈,x86处理器在计算能力方面的优势还是值得肯定的。而这一阶段的测试数据也让老师们相信,Panabit应用层流量分析与优化系统对于上海交通大学校园网目前的运行情况来说,也是能堪大任的。 5520平台深度分析 在征得老师们的许可后,我们在同样环境下使用久经考验的评估利器NCPBench 0.8进行了测试,得到了可以用做纵向对比的数据。在这个环节中,服务器上的两个万兆接口和每两个相邻的千兆接口被配置为网桥,在纯转发与简单业务两种模式下使用64Byte帧进行测试(NCPBench的功能介绍和使用方法见本报今年第16/17期51版)。
表注:NCPBench吞吐量测试结果 我们又得到了两组几乎一致的数据,无论是纯转发模式还是简单业务模式下,被测平台的吞吐量均为39.163%,包转发速率则接近14Mpps。还有一处值得注意:两种模式下,4个千兆接口间均能达到线速转发,两个万兆接口间则只能达到单向4Mpps、双向共8Mpps的转发速率。我们非常关注前者会对后者造成多大的影响,所以在最后单独对两个万兆接口进行了纯转发测试。此次得到的数据是单向5.12Mpps、双向共10.24Mpps,较之前有所上升,但与整机处理能力仍有不小的差距。需要说明的是,NCPBench允许测试者自行设定要使用处理器内核的数量,上述数据是在使用两个核情况下的测试结果。我们也尝试使用更多的内核数进行了测试,得到的数据基本相同,个别情况下还会略低。 这是个很有意思的现象,对瓶颈定位有着很大帮助。与Panabit“特定内核处理特定业务”的逻辑不同,NCPBench的业务模型采用SMP模式构建,每个内核都进行数据包转发与业务处理操作。理论上如果每个核都达到满负荷工作状态,纯转发模式时的性能会高于简单业务模式。所以我们从测试结果中只能得到这样的结论,即无论在哪种工作模式下,处理器内核的利用率都没有达到极限,即便只使用两个内核时也是如此。 在长期的测试工作中,处理器资源耗尽通常是系统整体瓶颈的惟一原因,而这种“喂不饱”处理器的情况,还是第一次出现。我们也曾怀疑性能瓶颈可能来自于NCPBench自带的网卡驱动,但在稍后进行的对英特尔Sandy Bridge平台的测试中,同样的驱动在一块同样基于英特尔82599EB网络控制器的网卡上带来了28Mpps的纯转发能力。所以,我们只能做出最遗憾的推测,即戴尔PowerEdge R710服务器的某个部分也许存在I/O方面的设计瓶颈。之所以不怀疑5520平台,是因为我们在另一个测试中,在一台采用E5550/4GB/82599EB配置的网络通信硬件平台上得到了两口间16Mpps、4口间超过22Mpps的测试数据。这也与我们经验中侧重于计算的服务器平台,在I/O方面逊于专注于通信业务的网络通信硬件平台的认识相吻合。 其实,即便是同样类型、同样配置的设备,在承载网络通信、安全这种时延敏感型业务时的表现也可能存在很大差异。在之前我们进行的基于Atom D525平台的评测过程中,就出现过来自不同厂商的配置完全一样的产品性能差异达40%的情况。我们无法对此做出更准确的解释,只能提醒广大用户和各厂商负责供应链的人员,在选型时一定要做更加细致的测试工作。 识别准确 稳定可靠 经过一系列测试,由英特尔5520平台承载的Panabit应用层流量分析与优化系统表现出了不错的性能水准,受到上海交通大学网络信息中心老师们的普遍认可。实际上,老师们对该系统在应用协议识别率及稳定性方面的测试早在去年底就已开始,他们使用另一台基于英特尔至强E5620处理器的服务器搭载Panabit,以旁路模式对两个万兆接口镜像而来的所有IPv4出口链路的上、下行流量进行了长期的监控分析。从老师们提供的统计资料中可以看出,未知协议所占流量在累计数据中所占的比重为2.8%,在10分钟统计数据中的所占比例也仅为3%,识别率堪称优秀。而在稳定性方面,资料显示该系统已连续运行超过168天,老师们也坦言没有出现过任何异常,只是在系统更新等人为操作时才会重启。
出于更加稳妥的考虑,老师们还是决定进行更长时间的旁路测试后,再讨论将其部署到网络边界。不过我们认为,在如此复杂的应用场景下长期稳定运行的事实,至少可以适当修正那些“x86架构产品稳定性不如专用系统”的论调。如果决定接入,硬件设备还要在可靠性方面满足更多的要求。例如现在工作在旁路模式下,可以不考虑接口的硬件Bypass,但当接入现网环境时,硬件Bypass特性就成为一条底线。服务器搭配多网卡的方式显然不能满足这一需求,我们建议老师们辅以专用的硬件Bypass设备,或直接选购支持该特性的x86网络通信硬件平台。 站在科研的角度,网络信息中心的老师们还提出了一些颇具价值的建议。例如针对前景被广为看好的OpenFlow,老师们建议Panabit增加在协议识别后输出Syslog信息的能力。这样一来,该系统就可以直接部署在一些基于OpenFlow搭建的网络环境中,为控制器提供基于应用层协议的策略配置能力。网络设备在并发连接方面的限制如今也需要突破,像本次测试版本中限定的600万并发连接数,仅用两台高性能服务器做端口扫描(模拟DDoS攻击)就可以打满,此时协议的正常识别就会受到影响。毫无疑问,这些来自科研领域兼一线用户的真知灼见,对产品的完善提高有着宝贵的指导意义。 测试后记 本次测试时间久、项目多,我们认为其中最有价值的内容当属老师们使用的测试方法。被测设备两端模拟大量MAC及IP地址后随机发送流量,可以快速制造出大量的新建连接和并发连接,对一切基于状态检测机制的设备造成较大的压力。即便是传统防火墙,也可能在连接的建立和拆除过程中遭遇性能瓶颈,其直接表现就是系统假死机(CPU占用率100%导致失去响应)或真死机/重启(如果系统架构有缺陷的话)。当连接信息足够多时,CPU在处理中也不得不频繁更新Cache中的数据,会对性能造成非常大的影响,许多高端x86架构产品选择Cache较大的至强处理器就是为了规避这一瓶颈。此外,如果使用比较少的流进行测试,业务处理时通常会走快速路径,而随机多流测试可以更好地模拟现网模型,充分评估设备处理慢速路径时的性能。根据我们以往的测试经验,不少安全设备在这种测试环境下性能会有数量级上的下降。 另一方面,我们在之前的下一代防火墙专题中曾经讨论过,使用UDP数据包进行吞吐量测试,不太适合于IPS、WAF等设备的评估,却很容易对流控、上网行为管理等一切基于应用层协议识别技术的设备造成极大的压力。因为目前来看,对UDP包的检测通常是应用协议识别引擎中的最长路径,而测试时构造出的UDP包又必然会被判断为未知协议类型,后继流量没有快速路径可走,设备应对其进行逐包分析。这一环节对硬件处理能力的需求,理论上远远超过状态检测,所以用户即便没有很强悍的测试仪表,也可以通过高性能PC/服务器加发包软件的方式自行测试。惟一需要注意的,是一定要在测试前验证协议识别的效果,保证协议识别引擎处于正常工作的状态。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
(3个打分, 平均:3.67 / 5) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


《给力吧,x86》专题连载七:英特尔5520平台网络通信性能测试分析(上)
作者 老韩 | 2011-12-12 17:16 | 类型 研发动态, 科技普及, 网络安全, 行业动感, 通讯产品 | 1条用户评论 »
|
在之前两期连载内容中(见本报今年第21期、29期),我们分别测试分析了目前英特尔面向中低端网络通信市场推出的G41、D525嵌入式解决方案。它们已经被证明在目标市场中有很强的竞争力,被不少通信、安全厂商所使用。但在数据中心、骨干网等万兆网络环境中,x86平台的效能与稳定性仍然有待验证。本期我们就与上海交通大学的老师们一起,对英特尔5520平台在万兆环境下的应用效果进行一次测试分析。
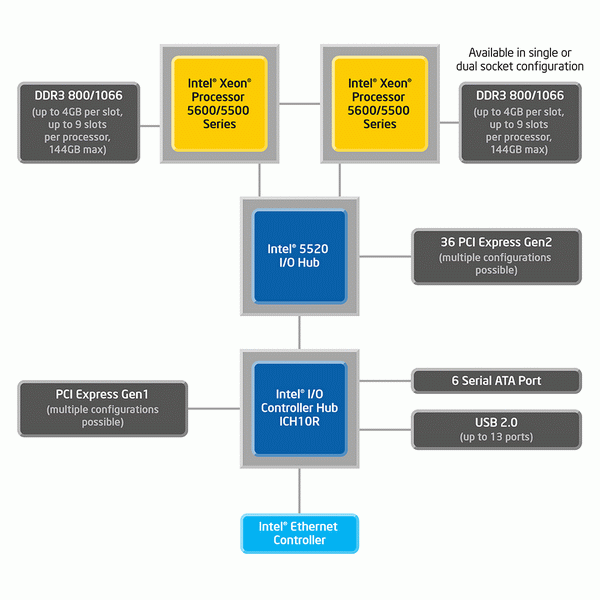
做为中国教育和科研计算机网络(Cernet)华东南地区网、上海教育与科研计算机网(Shernet)和校园网(SJTUnet)的建设、管理单位,上海交通大学网络中心拥有很强的科研实力,长期担负着三大网络运营维护的艰巨任务。在此过程中,该中心充分发挥科研能力上的优势,独立自主地解决了许多难度较大的运维问题。我们在连载中就曾经提到,该校两年前在对校园网出口入侵检测系统的选型中,遇到了市售产品难以满足需求的窘况。在充分分析了业务需求的前提下,网络中心的老师选择了带领团队自行研发的方式,以多组x86服务器分布式处理的方式实现了对万兆链路的实时监测。这样的方式,不仅构建了一个开放的、可以承载多业务的科研平台,更将科研成果转化为实际的安全服务,为校园网的稳定运行提供了保障。 虽然上海交通大学校园网目前拥有多条出口链路、总计超过10Gbps的带宽,但在愈发丰富、模式愈发复杂的网络应用面前,也不是永不拥塞的高速路。目前,流量的可视化与可控性已成为网络中心老师们重点关注的问题,他们需要一个强大的应用流量分析管理系统,为运营维护乃至下一步网络建设规划提供准确的参考依据。经过细致地评估,老师们初步选定了连续两年获得计算机世界年度产品奖的Panabit应用层流量管理系统。不过,与大多数同级别通信、安全产品不同,该系统运行在x86而非MultiCore-MIPS或NP平台上,而老师们(或者说是大多数人)对于x86平台在万兆环境中稳定工作都没有太多信心。 来吧,就让测试去证明一切。 规格全面提升的5520平台 上海交通大学网络中心的老师们为这次测试准备了一台戴尔PowerEdge R710服务器,它是戴尔为第一代Nehalem-EP处理器平台及其后续Westmere-EP处理器平台设计的2U机架式产品。PowerEdge R710基于英特尔5520 IOH芯片(代号Tylersburg-36D)设计,提供了36个PCIe 2.0信道,最多支持两颗英特尔Xeon 5500/5600系列处理器,可以搭配英特尔ICH9或者ICH10使用。在英特尔尚未明确推出Sandy Bridge嵌入式解决方案的今天,基于5520芯片组的产品仍然是目前设备制造商与用户能够获取到的最高端x86平台。 得益于戴尔灵活的定制化销售模式,测试使用的这台PowerEdge R710配置了一颗英特尔Xeon X5690处理器。它支持SMT超线程技术(测试中关闭),具有6个核心、12个硬件线程,主频达到3.46GHz,最大的Turbo Boost频率高达3.73GHz,属于英特尔32nm Westmere-EP处理器家族中的最高端产品。这颗处理器中的每个核心都具有32KB的L1指令缓存和L1数据缓存及256KB的L2缓存,所有核心共享12MB的L3缓存。此外,Xeon X5690还通过两个6.4GT/s的QPI总线和另一颗处理器以5520/5500 IOH芯片通信,QPI总线为一个双向的并行总线,在X5690上,单向带宽为12.8GB/s。 由于集成了较高规格的内存控制器,单颗Xeon X5690可以支持3通道R-ECC DDR3内存,每通道又支持最多3个R-ECC DIMM。在使用能够支持的最高规格的16GB内存条的时候,每颗处理器可拥有144GB的总内存容量,整个系统(双路配置)则可达到288GB的最大容量。X5690支持的最大内存频率规格为DDR3-1333,不过当所有DIMM插槽都插满内存的时候,运行频率将会降低至1066。而本次测试使用的这台PowerEdge R710服务器配置了3条4GB容量的内存,运行在3通道模式。
与时俱进的网络子系统 和桌面级与嵌入式产品不同,在服务器上,所有的高速设备都直接连接到IOH芯片上,而不是相对低速的ICH芯片,理论上减少了性能瓶颈。测试使用的PowerEdge R710服务器上提供了1条PCIe v2.0 x16插槽和两条PCIe v2.0 x4插槽,分别连接到3组顶级网络控制器。其中一组是一块基于英特尔82599EB芯片的英特尔X520双口万兆网卡,另两组是基于英特尔82576EB芯片的双口千兆网卡,一共提供了两个万兆接口和4个千兆接口。实际上,戴尔PowerEdge R710还板载了4个基于Broadcom网络控制器的千兆接口,但在测试中并未用做业务处理。 英特尔X520双口万兆网卡使用的82599EB是一个强大的网络控制器,是目前英特尔在万兆级产品中最顶级的型号。该芯片原生两个万兆接口,每个接口都可以支持128个TX/RX队列,并可以根据情况最多划分为64个RSS(Receive Side Scaling,接收方扩展)队列。此外,82599EB还支持MSI和MSI-X(Extended Message Signaled Interrupt,扩展消息告知中断)特性和一些与数据中心应用密切相关的高级功能。由于万兆环境下的数据传输需要巨大的带宽,82599EB推荐使用PCIe v2.0 x8或以上规格接口进行连接,否则可能会出现瓶颈。 英特尔82576EB也是比较强大的网络控制器,使用PCIe v2.0 x4接口进行连接,是82580出现前千兆级产品中的顶级型号。该芯片原生两个千兆接口,每个接口支持16个TX/RX队列,最多可划分16个RSS队列。和82599EB一样,82576EB也支持MSI和MSI-X,并支持VMDq、VMDc等虚拟化功能。在与英特尔服务器级Tylersburg IOH芯片搭配时,82576EB和82599EB可以通过I/O AT技术加速其DMA的传输性能。 | |
|
(2个打分, 平均:5.00 / 5) |

圣诞节前的市场狂欢?
作者 ibluesea | 2011-12-12 08:14 | 类型 行业动感 | 2条用户评论 »
|
每周都是围绕着欧洲的情况市场上下波动,没有什么进展。市场已经在一个范围内震荡了很长一段时间。欧洲债务危机的炒作已经越来越不新鲜了,可问题是美国经济也缺乏亮点,没有强劲的经济复苏,这些债务危机的话题还会继续炒作下去,市场也还会不断震荡起伏,看不到前进的方向。 | |
|
(2个打分, 平均:1.00 / 5) |
《给力吧,x86》专题连载六:网络通信硬件平台巡览•D525篇
作者 老韩 | 2011-12-11 21:27 | 类型 研发动态, 科技普及, 网络安全, 行业动感, 通讯产品 | 8条用户评论 »
|
在上一期连载内容中,我们测试分析了目前主流的G41网络通信硬件平台。结合其价格定位与性能表现来看,该平台比较适合用来打造中低端产品。而在更低端一些的,也是出货量最大的领域,来自英特尔的Atom平台才是毫无疑问的王者,堪称x86架构真正的杀手级解决方案。
架构精简 配置合理 IEC-516P采用1U规格设计,前面板提供了6个千兆电口(其中两组支持硬件ByPass)、两个USB 2.0接口和一个DB9或RJ45形态的串口。该产品采用了英特尔Atom平台,基于45nm的Atom D525处理器,隶属于PineTrail架构。比起第一代Atom平台,PineTrail从三芯片改进为双芯片设计,在CPU中集成了北桥芯片的部分功能。Atom D525处理器主频为1.80GHz,采用双核四线程设计,集成2 x 512KB L2 Cache,提供了不错的处理能力。其实Atom处理器内核采用的顺序执行机制对于网络业务处理来说并不太合适,双核四线程的D525处理器比起上一代单核双线程的N270会有更大的优势。D525处理器还内置了内存控制器,支持单通道的DDR3-800或DDR2-800内存,最大容量可达4GB。IEC-516P提供了两条DDR3 SO-DIMM插槽,送测样机配备了1条1GB的DDR3内存。 按照英特尔PineTrail平台的规划,D525应该搭配NM10芯片使用,然而NM10仅提供4个PCIe Lanes,限制了通信产品的整体处理能力和部署的灵活性。所以在嵌入式产品线中,英特尔给出了D525与ICH8M的推荐配置。ICH8M可以提供6个PCIe Lanes,以及PCI、IDE、SATA等丰富周边I/O接口。和上一代产品ICH7相比,ICH8比较明显的区别是它支持PCIe v1.1,因此可以支持包括MSI-X在内的一系列新特性。而和面向桌面应用的ICH8相比,面向低功耗移动应用的ICH8M将支持的SATA端口数减少到3个,功耗也有所降低。其实ICH8M内部还整合了1个千兆网络控制器的MAC部分,但其性能无法满足压力较大的网络业务处理,所以包括IEC-516P在内的许多网络通信硬件平台都对其进行了屏蔽处理,转而使用功能、性能更强的独立网络控制器。 IEC-516P通过ICH8M南桥的6个PCIe v1.1信道分别连接到6颗82574L芯片。82574L是沿用已久的嵌入式/服务器千兆以太网控制器,支持两个TX/RX队列和两个RSS队列,是一个成熟稳定、性能尚佳的产品。该芯片使用PCIe v1.1 x1接口,能支持MSI-X等技术,在规格上正好与ICH8M相匹配。ICH8M和Atom D525通过DMI总线连接,实际上就是一个x4的PCIe总线,其单向信号速率/双向信号速率为10Gbps/20Gbps,数据速率则为8Gbps/16Gbps。 在机箱内部,IEC-516P为TDP并不高的Atom D525配备了一个小风扇,并将其安置在机箱出风口的两个风扇附近,因此散热方面完全不成问题。由于整机功耗较低,该产品使用1个180W功率的电源为系统供电,整机功耗不会高于100W,因此180W已经绰绰有余。可靠性方面,IEC-516P内置了支持可编程控制的WatchDog,完善了x86平台的监控机制。存储方面,主板上提供了1个IDE接口和3个SATA接口,可以使用DOM、CF及其他常见的存储介质。送测样机配备了CF接口、IDE界面的1GB DOM,用于安装NCPBench。此外,主板边缘还设计有1个PCI插槽和1个PCIe x1接口的金手指,提供了符合产品定位的扩展性。 性能卓越 低端通吃 考虑到性能数据的可比性,我们依旧使用了NCPBench 0.8对IEC-516P进行测试。按照该软件设定的评估方法,我们将每两个相邻接口配置为桥模式,分别多次考察了1组、2组、3组桥时的整体转发性能,取得稳定后的性能数据(NCPBench的功能介绍和使用方法见本报今年第16/17期51版)。由于IEC-516P只提供了6个千兆接口且不可扩展,在测试3组桥性能时,我们直接将显示器、键盘鼠标插在主板上引出的接口上进行操作。
表格:IEC-516P吞吐量测试结果(百分比形式,NCPBench 0.8/转发模式)
表格:IEC-516P吞吐量测试结果(带宽形式,NCPBench 0.8/转发模式)
表格:IEC-516P吞吐量测试结果(pps形式,NCPBench 0.8/转发模式) 从测试结果中可以看出,当NCPBench运行在转发模式时,IEC-516P的64Byte帧整机最大转发速率超过3.6Mpps,吞吐量达到2.42Gbps;采用1518Byte帧进行测试时,整机的最大转发速率为0.31Mpps,吞吐量达到3.76Gbps。由此可见,Atom平台虽然在网络通信领域被英特尔定位为低端嵌入式解决方案,却也有着不小的潜力。能在纯转发情况下达到这样的性能,也就意味着D525平台在运行一般的防火墙业务时,可以满足高端百兆乃至低端千兆产品的设计需求。或许,我们印象中“低端产品”的概念需要更新了。 通过挖掘,我们还能从有限的测试数据中捕捉到更多的信息。在1组桥和2组桥的测试中,除了前者在1280Byte、1518Byte时达到100%的极限值外,64Byte-1024Byte帧长有着基本相同的百分比数据(蓝色部分)。当我们将其转化为以带宽和pps为单位的数值时,可以看到2组桥时的处理能力基本是1组桥时的两倍,呈线性增长的关系。而在3组桥的测试中,64Byte-1024Byte帧长时的吞吐量数据并不存在这一规律,反倒是在1280Byte和1518Byte两种帧长时,3组桥的性能与2组桥基本保持一致,整体转发能力均为3.7Gbps左右(红色部分)。 要弄清造成这种情况的原因,我们必须深入了解D525平台做数据包纯转发时的业务流程。以IEC-516P为例,D525处理器通过4x DMI通道连接到ICH8M,后者再通过6条PCIe v1.1 1x通道连接板载的6颗英特尔82574L千兆以太网控制器。通常在进行数据包转发操作时,网络控制器先发起DMA请求,将接收缓存中的数据直接传输到内存;CPU经过软件处理定位到目的网络控制器,通过DMA引擎将数据传输到它的发送缓存中,或是让网络控制器自行将数据从内存中取走(82574L整合了DMA引擎)。这是一个逻辑上简单、实现起来复杂的流程(如果要达到高性能),内存子系统、DMA引擎、DMI、ICH8M、PCIe 1x通道、82574L和软件、驱动程序都有可能成为影响整体性能的因素。 再回到我们刚才注意到的两个情况,既然1组桥和2组桥时,64Byte-1024Byte在带宽和pps测试结果上呈线性增长,说明瓶颈不在内存子系统、DMA引擎和DMI。而我们在测试其他更高规格的平台时,基于82574L也得到过更高的性能数据,说明这款网络控制器和PCIe v1.1 1x通道也不是瓶颈。只有在进行3组桥的64Byte-1024Byte帧长测试时,得到的数据才有可能是系统整体的极限。而2组桥与3组桥在1280Byte、1518Byte帧长测试中表现出来基本一样的吞吐量数值,显然是在带宽方面遇到了瓶颈,但可能与DMA引擎、ICH8M、PCIe v1.1 1x通道和82574L关系不大。我们暂时无法再对性能短板做更加精准的定位,不过从完整的测试数据来看,DMI、内存控制器与软件处理逻辑有可能是造成D525平台整体性能瓶颈的关键因素。 无论如何,目前D525平台在NCPBench的驾驭下,已经有着十分优秀的性能表现。随着厂商研发的继续深入和软件技术的不断发展,该平台的性能一定会得到更充分的挖掘,在低端网络通信、信息安全领域有着很好的应用前景。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
(4个打分, 平均:3.25 / 5) |

纽约时报文章《数据里的实力:中国定位科技强国》
作者 高飞 | 2011-12-11 13:40 | 类型 行业动感 | 22条用户评论 »
|
新浪科技翻译如下:http://tech.sina.com.cn/it/2011-12-10/11446468982.shtml。以下为基于新浪科技翻译的文章全文,笔者进行了校订修正。
北京,一间普通的会议室中,吴建平站在一堵巨大的毛玻璃墙面前。他打开了一个开关,玻璃变成了透明的。向下看去,是一个壮观的网络运营中心,里面是巨大的计算机显示器。这些显示器上显示着中国和世界地图,精确地指示出中国的IPv6链接。 中国的网民已经达到美国的两倍。作为中国教育和科研计算机网(CERNET)的一名科学家和网络中心主任,吴建平还指出,中国部署这项新协议的速度快于其他任何国家。 IPv6提供了先进的安全和隐私技术,但更重要的是,目前的IPv4地址已近枯竭,IPv6还可以提供更多的地址。“中国必须转向IPv6,”吴建平说,“在美国,有人不认为这很紧迫,但我们相信这很紧迫。” 如果说互联网的未来已然在中国,那么计算的未来是否也将位于此处? 美国的很多专家认为这种可能性很大。由于劳动力成本低廉,中国已经主导了全球的计算机和消费电子产品的生产。如今,这些专家认为,经济的繁荣和科技基础设施的提升可能会推动中国站在下一代计算技术的最前沿。 对中国而言,开发高端计算中心的需求并不仅仅是国家荣誉问题。中国希望为有创新力的中国企业奠定基础,重塑未来科技版图,而不是仅仅为世界组装台式机。 美国经济战略研究所总裁克莱德·普莱斯托威茨(Clyde V. Prestowitz Jr。)认为,中国可能不会出现史蒂夫·乔布斯(Steve Jobs)式的人才,但没有关系。“创新的形式各有不同。”他说,“美国总是倾向于将创新等同于车库里诞生的基于某个天才想法的创业公司。” “但还有其他形式的创新,比如通过不断改进来达到创新。我们并不精于此道,但这却是他们的长项。”他补充道。 这种观点并不普遍,但其他专家还是认为,如果低估中国快速发展的能力,将是一个错误。 “我1978年第一次去中国时,曾经看到工人们用缝衣服的针来拼装电脑内存。”作为腾讯的早期投资者,IDG创始人帕特里克·麦高文(Patrick J. McGovern)说,“如今创新正在加速。今后,智能手机和平板电脑的专利将由中国人发明。” 新型挑战 时间退回到60年前,彼时,被公认为首台电子计算机的Eniac刚刚诞生,美国已经奠定了现代计算和通讯领域的发展步伐和方向。从大型机到iPhone、从阿帕网(Arpanet)到WiFi,创新如同洛克菲勒一样成为美国的象征。 对于几代人而言,硅谷就是创新的中心。这是一个多元文化的熔炉,不仅支持黑客的独行侠精神,还为企业家的进取精神提供了良好的土壤,从而吸引了全世界羡慕的目光。 硅谷主导地位最严峻的挑战或许来自于1980年代末期的日本。在经济陷入衰退前,日本几乎就要主导全球的半导体和计算机行业。如今,中国却对硅谷构成了一种截然不同的挑战。日本的经济长期依赖出口,中国却很快就将成为全球最大的电子商务和计算市场。 世界突然注意到中国的强大技术实力似乎是在2010年末——中国的“天河一号A”曾经一度成为全球速度最快的超级计算机。尽管这台设备使用的是美国的处理器,并且很快被一台日本机器超越,但这仍然无可争议的表明,中国获得了世界级的计算机设计能力。 时间到了今年(2011年)10月,另外一台中国超级计算机“神威蓝光”也突破了千万亿次(petaflop,即10的15次方)门槛,跻身全球超级计算机20强。 这台计算机还有更令西方惊讶的地方。不仅是因为它采用了中国自主开发的微处理器,还因为它在低能耗运算方面拥有巨大优势。这或许表明,中国现在已经在“每瓦性能”上大幅领先。这一指标是专门用来衡量计算机能耗效率的,对于进入下一代百亿亿次(exascale,即10的18次方)超级计算机时代至关重要。这类计算机预计可在2020年代末出现,届时的计算机运算速度将达到当今全球最快速度的一千倍。 作为中国另外一支微处理器研发团队的首席设计师,中国科学院教授胡伟武说:“这正是中国企业的发展方向。我们可以把飞船送上太空,同样也可以设计出高性能计算机。” 美国官员也认同这一说法,并认为中国政府对超级计算机的投入将收到回报。“关键在于,中国理解高性能计算的重要性。”美国劳伦斯-利弗莫国家实验室计算领域副主任唐娜·克劳福德(Donna Crawford)说,“他们将此视为整个社会发展的关键动力。” 发展障碍 去年,中国国务院总理温家宝曾经在一次采访中表示,中国将打造“物联网”。在美国人不无醋意的想法中,如果是美国总统(而不是中国总理)提出这样的计划,这次采访就堪称完美。 将家庭与智能电网相连已经成为美国下一代互联网的目标。这与“普适计算”(ubiquitous computing)密切相关,后者希望将计算能力转移到智能手机和数字音乐播放器等日常设备中。 但中国在主导这一领域的过程中却并非毫无障碍。近十年来,中国虽然一直在努力打造全球领先的半导体产业,但却未能成功。中国组装的绝大多数产品都依赖进口的芯片。与美国的英特尔和中国台湾的台积电相比,中国大陆最优秀的芯片企业的制造能力仍然落后两三代。 中国最大的弱点或许源于政府的控制过多。中国的创新或许也会将受到知识产权保护力度不足的限制,导致企业难以突破新的领域。 今年9月在北京召开的第13界国际普适计算大会,令美国技术专家感到索然无味。“没有什么真正引发我关注的东西。”曾在1980年代普适计算的理念刚刚提出时,领导施乐帕罗奥尔托研究中心的约翰·西里·布朗(John Seeley Brown)说。 相比而言,他反而看到富士康这样的制造企业展开了一些真正意义的创新。这家台湾企业在中国大陆经营很多家工厂,并且承接大量苹果的组装订单。 “研究和设计文化已经深深植入到富士康这样的企业中,他们会开始尝试一些仅靠他们自己无法完成的事情。”布朗说,“我们如今已经将美国最优秀创意者与世界上最擅长制造的人结合起来。” 其他的投资者也在中国看到了类似的机会。风险投资公司DCM驻北京合伙人卢蓉就描述了这样一家半导体公司:设计师位于加州圣地亚哥,而提供后续支持的工程师则位于上海,从而将成本降低到原先的六分之一。 “正是上海团队为当时的一个问题找到了突破性的解决方案。”她在电子邮件中回忆道。令竞争对手担心的是,中国已经开始培养大量的优秀硬件工程师和软件程序员,不仅在国际竞赛中屡屡获胜,而且开始主导美国最优秀的工程项目。美国加州大学伯克利分校即将宣布一项交易,在上海设立工程园区,这也导致外界担心美国最优秀的工科院校将技术转移到中国。 其他优势 很多贡献都来自计算机科学领域的海归,姚期智就是其中最著名的一位。他从普林斯顿大学辞职后,在清华大学创立了一个研究所,目前已经在博弈论和计算机安全领域实现了突破。“北京的学术活动一夜之间提升了很多。”加州大学伯克利分校计算机科学家克里斯托斯·帕帕迪米特里欧(Christos Papadimitriou)说。 中国的产业结构无疑也在向以创新为导向的方向发展。今年夏天,美国智库东西方中心(East-West Center)高级研究员迪特尔·恩斯特(Dieter Ernst)在美国国会的一次听证会上作证称,中国的专利总数已经超越韩国和欧洲,并且正在追赶美国和日本。 除此之外,《创业亚洲》(Startup Asia)一书的作者丽贝卡·范宁(Rebecca A. Fanin)则表示,中国目前还拥有全球第二大风险投资市场,规模从2005年的22亿美元增长到76亿美元,而美国则基本停滞。 斯坦福大学区域创新和创业精神项目的研究员,最近对769家投资公司在2203家中国企业的投资活动进行了研究,并发现情况与硅谷非常相似。负责该项目的斯坦福商学院教授玛格丽特·龚·汉考克(Marguerite Gong Hancock)说:“很多确立成功地位的硅谷企业和个人都将专业技能转移到了中国,并获得了成功。” 与硅谷的相似性也令部分人感到担忧。北京科技投资公司J Capital Research联席主管杨思安说:“这里显示出各种泡沫的迹象,令人不安。” 与此同时,世界也普遍认同,中国企业家勤奋工作的文化在全世界都无可比拟。十年前从美国加州迁往北京的麦彻同说:“根据我在中国5 家创业公司的经历来看,中国的工作文化让硅谷看起来十分懒散。在北京,如果你想在周五晚上7:30找到一家公司的CEO,肯定能在办公室里找到他。”(高飞注:硅谷的快节奏高强度工作文化已经在全美都有名) 但并不是所有专家都认同这种对比。 “透过美国国力下滑的视角看中国,我们显然看到的是中国的蒸蒸日上,例如现代化的摩天大楼、速度最快的计算机以及新的机场,我们看到的是不可征服的力量。” 美国亚洲协会美中关系中心主任奥威尔·谢尔(Orville Schell)说,“但中国人自己看到的却是巨大的不确定性,他们并未自信满满。” 但风险投资家麦高文(McGovern)认为,这或许正是一种优势。他表示,在美国,他经常会接触到一些过度自信的企业家——如果自己的创意没有得到认可,他们就会愤然离去。 但他所接触的中国企业家却有所不同。“他们会找到我,然后给我展示他们的翻译软件,可以在中英文之间相互转换。”他说,“然后,我会告诉他们,我认为这款产品没有市场,因为知识产权很难得到保护。”但他并不会直接把他们打发走,而是有可能问问对方是否有兴趣参与他正在考虑的另外一个创意。 “他们会回答道,‘我能获利发财吗?’当我告诉他们机会很大时,他们会说,‘好吧,我做!’” (纽约时报记者David Barboza发自北京,John Markoff发自旧金山) | |
|
(1个打分, 平均:3.00 / 5) |

系统软件工程师实战攻略(体系结构篇)--(2)
作者 陈怀临 | 2011-12-11 12:38 | 类型 专题分析 | 4条用户评论 »
|
如何掌握一个CPU的ABI(Application Binary Interface) 在体系结构中,通常会说一个CPU的结构(Architecture),一个CPU的微结构(Micro-Architecture)。 是啥意思呢? 结构的意思就是那些程序员能看见的东东;微结构就是程序员不(太)需要关心的东西。 对能看得见的结构部分(例如,通用寄存器,控制寄存器,状态寄存器,中断或者例外寄存器)的使用方法,或者说编程模式,就是所谓的ABI。 掌握一个CPU的ABI,或者说编程界面,是一个基本功。是必须的。浅显说,就是那些寄存器的用法,分布和使用约定。 定义一个处理器的ABI,也是做编译器设计的第一个环节。笔者曾经设计过一个网络处理器的GCC的后端target。设计的第一个事情其实就是设计寄存器的约定。 这个章节里,主要具体谈如何掌握MIPS,PowerPC,Arm和x86的ABI。 一些相关的中文参考资料如下: 《PowerPC and Linux Kernel Inside》, 陈怀临,2002 《MIPS CPU 体系结构概述,Linux/MIPS内核》(上),陈怀临,张富新,2002 《MIPS CPU 体系结构概述,Linux/MIPS内核》(下),陈怀临,张富新,2002 《Linux PowerPC详解:核心篇》, 王齐, 2008[有没有网上电子版?] 《Arm 体系结构》,李曦 [其他] [待补充] | |
|
(1个打分, 平均:5.00 / 5) |