




VisualThreat发布业界首款抵御汽车攻击的硬件防火墙
作者 yly | 2014-07-27 11:18 | 类型 专题分析, 物联网, 移动互联网, 网络安全 | Comments Off
|
在刚刚结束的SyScan360安全大会上,VisualThreat公司成功演示了如何利用WIFI对汽车进行劫持攻击的方法,同时展示了业界第一款用来抵御汽车黑客攻击的硬件防火墙。防火墙直接插在汽车OBD2接口上,能有效的阻止对汽车的CAN message攻击,包括之前在黑客大会,DEFCON等会议上采用的对汽车攻击的方式。 随着智能汽车时代的到来,汽车成为下一个攻击目标。尤其通过手机和汽车内部的通信,黑客可以利用蓝牙,WIFI,甚至2G/3G对汽车进行恶意攻击。 7月30日,星期三 VisualThreat公司和AUTO HACK公共小组在加州montain view的Hacker Dojo 举办一次讲座,
题目: Defense: Vehicle OBD2 Over-The-Air Attacks 讲座网址: http://www.meetup.com/Autohack/events/196267042/ Wednesday, July 30, 2014 7:00 PM to 8:15 PM Defense: Vehicle OBD2 Over-The-Air Attacks w/ Visual Threat A host of vendors are now offering popular vehicle cloud-connected software and hardware. Loose security puts users at risk of compromised privacy and actual loss of vehicle control. In this talk, speakers from VisualThreat will show how to build the first CAN BUS firewall to defend against OBD auto attacks. This will include reverse engineering OBD2 and CANBUS, a demo of remotely controlling a vehicle via mobile app (w/o DIY hardware), and presenting research findings on security vulnerabilities of current commercial vehicle-related mobile products. | |
 (没有打分) (没有打分) |

华为海思42岁高管王劲猝死:是基带、处理器业务骨干
作者 陈怀临 | 2014-07-26 11:21 | 类型 行业动感 | 24条用户评论 »
|
凤凰科技讯7月26日消息,华为旗下海思公司今日证实,海思无线芯片开发部部长王劲昨晚突发昏迷,不幸于2014年7月26日凌晨离世,享年42岁。 海思通告称,王劲1996年加盟华为,是无线早期的业务骨干,在无线产品线从普通工程师、PL,到BTS30 产品经理、上研副所长,为无线产品的奋斗多年,他曾担任瑞研所长主持工作,并领导创建了华为欧洲研究所,带领海思Balong(华为的基带处理器)及Kirin(麒麟,华为的处理器业务)团队从低谷走向成功。 海思为华为旗下半导体公司,负责芯片等的研发,已经研发出例如海思麒麟920等处理器,该处理器被用于华为荣耀最新旗舰级荣耀6上。 以下为海思公告全文: 海思同事们, 今天凌晨惊闻噩耗,我们大家的好兄弟、海思无线芯片开发部部长王劲昨晚突发昏迷,不幸于7月26日凌晨离世。 我们怀着悲痛心情,缅怀这位与我们并肩奋斗多年的战友。他在海思无线终端芯片业务最困难的时期,从海外返回接过重担,克服重重困难,带领Balong 和Kirin 团队从低谷走向成功。他为人和蔼,笑声爽朗,乐观的面庞音容犹在耳边眼前,实在难以相信在这个普通的宁静凌晨,他猝然离去,从此与家人和同事阴阳相隔,后会无期。 王劲1996 年加入华为,他是无线早期的业务骨干,在无线产品线从普通工程师、PL,到BTS30 产品经理、上研副所长,为无线产品的成功奋斗多年,他曾担任瑞研所长主持工作,并领导创建了华为欧洲研究所,是公司海外业务的重要参与者和贡献者。他在公司十八年的奋斗征程里为无线和终端芯片领域作出的杰出贡献,值得我们每个人致以深深的敬意。 亲戚或余悲,他人亦已歌,死去何所道,托体同山阿。他永远给他的团队以鼓舞和信心,我们也祝愿他往生极乐,一路走好。 海思管理团队 2014年7月26日 | |
|
(没有打分) |
高端招聘(2):著名投行投资分析师(4个); 著名VC投资大数据公司CTO(1)
作者 陈怀临 | 2014-07-24 23:11 | 类型 行业动感 | Comments Off
|
弯曲评论 高端招聘 ————————————————— | |
|
(没有打分) |
Gartner公布2014年十大信息安全技术
作者 陈怀临 | 2014-07-22 10:53 | 类型 网络安全 | Comments Off
|
全球领先的信息技术研究和顾问公司Gartner近日公布了2014年十大信息安全技术,同时指出了这些技术对信息安全部门的意义。
Gartner副总裁兼院士级分析师Neil MacDonald表示:“企业正投入越来越多的资源以应对信息安全与风险。尽管如此,攻击的频率与精密度却越来越高。高阶锁定目标的攻击与软件中的安全漏洞,让移动化、云端、社交与大数据所产生的“力量连结(Nexus of Forces)”在创造全新商机的同时也带来了更多令人头疼的破坏性问题。伴随着力量连结商机而来的是风险。负责信息安全与风险的领导者们必须全面掌握最新的科技趋势,才能规划、达成以及维护有效的信息安全与风险管理项目,同时实现商机并管理好风险。“
十大信息技术分别为:
云端访问安全代理服务(Cloud Access Security Brokers) 云端访问安全代理服务是部署在企业内部或云端的安全策略执行点,位于云端服务消费者与云端服务供应商之间,负责在云端资源被访问时套用企业安全策略。在许多案例中,初期所采用的云端服务都处于IT掌控之外,而云端访问安全代理服务则能让企业在用户访问云端资源时加以掌握及管控。
适应性访问管控(Adaptive Access Control) 适应性访问管控一种情境感知的访问管控,目的是为了在访问时达到信任与风险之间的平衡,结合了提升信任度与动态降低风险等技巧。情境感知(Context awareness)是指访问的决策反映了当下的状况,而动态降低风险则是指原本可能被封锁的访问可以安全的开放。采用适应性访问管理架构可让企业提供不限设备、不限地点的访问,并允许社交账号访问一系列风险程度不一的企业资产。
全面沙盒分析(内容引爆)与入侵指标(IOC)确认 无可避免地,某些攻击将越过传统的封锁与安全防护机制,在这种情况下,最重要的就是要尽可能在最短时间内迅速察觉入侵,将黑客可能造成的损害或泄露的敏感信息降至最低。许多信息安全平台现在都具备在虚拟机(VM)当中运行(亦即“引爆”)执行档案和内容的功能,并且能够观察VM当中的一些入侵指标。这一功能已迅速融入一些较强大的平台当中,不再属于独立的产品或市场。一旦侦测到可疑的攻击,必须再通过其他不同层面的入侵指标进一步确认,例如:比较网络威胁侦测系统在沙盒环境中所看到的,以及实际端点装置所观察到的状况(包括:活动进程、操作行为以及注册表项等)。
端点侦测及回应解决方案 端点侦测及回应(EDR)市场是一个新兴市场,目的是为了满足端点(台式机、服务器、平板与笔记本)对高阶威胁的持续防护需求,最主要是大幅提升安全监控、威胁侦测及应急响应能力。这些工具记录了数量可观的端点与网络事件,并将这些信息储存在一个集中地数据库内。接着利用分析工具来不断搜寻数据库,寻找可提升安全状态并防范一般攻击的工作,即早发现持续攻击(包括内部威胁),并快速响应这些攻击。这些工具还有助于迅速调查攻击范围,并提供补救能力。
新一代安全平台核心:大数据信息安全分析 未来,所有有效的信息安全防护平台都将包含特定领域嵌入式分析核心能力。一个企业持续监控所有运算单元及运算层,将产生比传统SIEM系统所能有效分析的更多、更快、更多元的数据。Gartner预测,至2020年,40%的企业都将建立一套“安全数据仓库”来存放这类监控数据以支持回溯分析。籍由长期的数据储存于分析,并且引入情境背景、结合外部威胁与社群情报,就能建立起“正常”的行为模式,进而利用数据分析来发觉真正偏离正常的情况。
机器可判读威胁智能化,包含信誉评定服务 与外界情境与情报来源整合是新一代信息安全平台最关键的特点。市场上机器可判读威胁智能化的第三方资源越来越多,其中包括许多信誉评定类的选择。信誉评定服务提供了一种动态、即时的“可信度”评定,可作为信息安全决策的参考因素。例如,用户与设备以及URL和IP地址的信誉评定得分就可以用来判断是否允许终端用户进行访问。
以遏制和隔离为基础的信息安全策略 在特征码(Signatures)越来越无法阻挡攻击的情况下,另一种策略就是将所有未知的都当成不可信的,然后在隔离的环境下加以处理并运行,如此就不会对其所运行的系统造成永久损害,也不会将该系统作为矢量去攻击其他企业系统。虚拟化、隔离、提取以及远程显示技术,都能用来建立这样的遏制环境,理想的结果应与使用一个“空气隔离”的独立系统来处理不信任的内容和应用程序一样。虚拟化与遏制策略将成为企业系统深度防御防护策略普遍的一环,至2016年达到20%的普及率,一改2014年几乎未普遍采用的情况。
软件定义的信息安全 所谓的“软件定义”是指当我们将数据中心内原本紧密耦合的基础架构元素(如服务器、存储、网络和信息安全等等)解离并提取之后所创造的能力。如同网络、计算与存储的情况,对信息安全所产生的影响也将发生变化。软件定义的信息安全并不代表不再需要一些专门的信息安全硬件,这些仍是必不可少的。只不过,就像软件定义的网络一样,只是价值和智能化将转移到软件当中而已。
互动式应用程序安全测试 互动式应用程序安全测试(IAST)将静态应用程序安全测试(SAST)与动态应用程序安全测试(DAST)技术进行结合。其目的是要通过SAST与DAST技术之间的互动以提升应用程序安全测试的准确度。IAST集合了SAST与DAST最好的优点于一单一解决方案。有了这套方法,就能确认或排除已侦测到的漏洞是否可能遭到攻击,并判断漏洞来源在应用程序代码中的位置。
针对物联网的安全网关、代理与防火墙 企业都有一些设备制造商所提供的运营技术(OT),尤其是一些资产密集型产业,如制造业与公共事业,这些运营技术逐渐从专属通信与网络转移至标准化网际网络通信协议(IP)技术。越来越多的企业资产都是利用以商用软件产品为基础的OT系统进行自动化。这样的结果是,这些嵌入式软件资产必须受到妥善的管理、保护及配发才能用于企业级用途。OT被视为产业界的“小物联网”,其中涵盖数十亿个彼此相连的感应器、设备与系统,许多无人为介入就能彼此通信,因此必须受到保护与防护。 | |
 (1个打分, 平均:5.00 / 5) (1个打分, 平均:5.00 / 5) |
科技一周~可以测知的世界才更残酷
作者 硅谷寒 | 2014-07-20 17:27 | 类型 硅谷科技周报 | Comments Off
系列目录 科技一周
科技一周~可以测知的世界才更残酷 2014/07/19 自古至今,人们对能够预测未来,并通晓过去的神,都有着敬畏之感。那么,这世上究竟有没有这种神?又或者,现下大行其道的机器学习技术有没有可能成为这种“神”?要回答这个深奥的问题,首先需要弄清楚另一个更深奥的问题,即:世界,究竟是不是一个可以观测(Observable)并可以控制的(Controllable)系统?“可观测”和“可控制”是两个计算机术语,通俗地讲,可控制性,意味着我们可以通过现有的信息预测未来的一切;而可观测性,意味着我们可以通过现有的信息,探知过去所发生的一切。也就是说,如果世界满足上述两个特性,那么它一定会被我们预测并探知。 然而,我却想再问一个略显“人文”气的问题:当我们真地面对一个可以测知的世界,我们人类是会快乐,还是痛苦?或许对于某些人来说,是快乐的,因为他们是这个世界的“成功”人士,当世界被测知出来,他们会看到自己那穷奢极欲享受无边的未来;然而,对于绝大多数人来说,这种可以测知的世界却是相当的残酷,因为在未来,他们依然是普普通通的屌丝,劳苦终日。这个论断是基于“富则愈富,穷则更穷”的大概率假设。 本周的科技新闻,也是从预测未来开始:
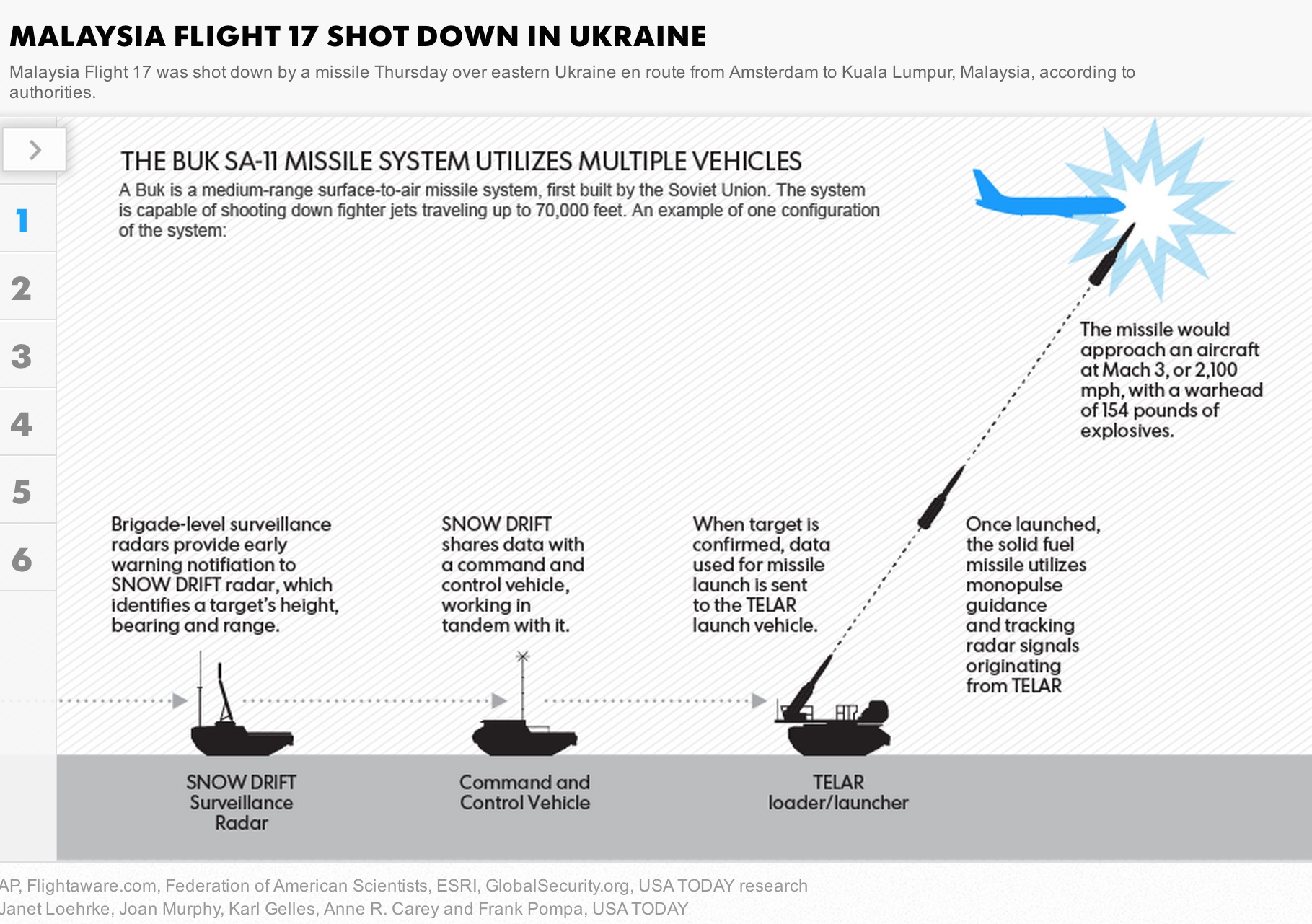
本期的科普,来聊一聊Google预测世界杯的机器学习算法。 对于任何一种机器学习算法,第一步都是要获取训练样本。Google获得的球员和比赛数据来自于一个专业的体育数据网站,Opta Sports。Google通过自己的Cloud Dataflow平台把来自于Opta Sports的原始数据进行预处理,再将预处理之后的数据导入Google Bigquery。第二步,Google Bigquery建立一个多层感知机(MLP,Multilayer Perceptron),通过样本进行学习训练。第三步,便是将下一场比赛的球员信息输入学习好的MLP,由MLP预测出比赛的结果。所谓的“预测”,其实就是一种“分类”,把输入的向量(参赛球员的数据)划分到两个类别里:胜、负。 这次预测世界杯的机器学习算法,是一种在线学习算法(Online Learning)。第四步,也就是最后一步,当该场比赛的结果出来,MLP立刻获知自己的预测是否准确,并根据结果进行自适应更新。之后,循环执行第三、四步,进行迭代,预测模型也将会在概率意义上越来越准确。 以上便是对世界杯预测算法的简介。当然,对于球迷而言,还是不要预测准为好,如果每场比赛都被预测准确,那么比赛就会变得索然无味,预先知道自己要失利的一方将会行尸走肉一样地踢完整场比赛。更甚者,这很有可能导致整个足球运动走向消亡。所以,倘若我们真地身处一个可以测知的世界,那么对于绝大多数人或事而言,就像是上了一列自动行驶的火车,纵然行驶的方向是万丈深渊,我们也无力改变。因为,这残酷,早已“天”注定。 [1]. http://googleblog.blogspot.com/2014/07/google-cloud-platform-predicts-world.html, July 2014. [2]. http://www.goldmansachs.com/our-thinking/outlook/world-cup-sections/world-cup-prediction-model-update-6-26-2014.html, June 2014. 图1. [2]. 图2. http://www.usatoday.com/story/news/nation-now/2014/07/18/malaysian-airlines-mh17-crash/12825433/
| |
 (2个打分, 平均:4.50 / 5) (2个打分, 平均:4.50 / 5) |

大数据计算新贵Spark在腾讯雅虎优酷成功应用解析
作者 陈怀临 | 2014-07-20 10:24 | 类型 大数据, 行业动感 | Comments Off
|
Spark作为Apache顶级的开源项目,项目主页见http://spark.apache.org。在迭代计算,交互式查询计算以及批量流计算方面都有相关的子项目,如Shark、Spark Streaming、MLbase、GraphX、SparkR等。从13年起Spark开始举行了自已的Spark Summit会议,会议网址见http://spark-summit.org。Amplab实验室单独成立了独立公司Databricks来支持Spark的研发。 为了满足挖掘分析与交互式实时查询的计算需求,腾讯大数据使用了Spark平台来支持挖掘分析类计算、交互式实时查询计算以及允许误差范围的快速查询计算,目前腾讯大数据拥有超过200台的Spark集群,并独立维护Spark和Shark分支。Spark集群已稳定运行2年,我们积累了大量的案例和运营经验能力,另外多个业务的大数据查询与分析应用,已在陆续上线并稳定运行。在SQL查询性能方面普遍比MapReduce高出2倍以上,利用内存计算和内存表的特性,性能至少在10倍以上。在迭代计算与挖掘分析方面,精准推荐将小时和天级别的模型训练转变为Spark的分钟级别的训练,同时简洁的编程接口使得算法实现比MR在时间成本和代码量上高出许多。 Spark VS MapReduce 尽管MapReduce适用大多数批处理工作,并且在大数据时代成为企业大数据处理的首选技术,但由于以下几个限制,它对一些场景并不是最优选择:
Spark在很多方面都弥补了MapReduce的不足,比MapReduce的通用性更好,迭代运算效率更高,作业延迟更低,它的主要优势包括:
MapReduce由于其设计上的约束只适合处理离线计算,在实时查询和迭代计算上仍有较大的不足,而随着业务的发展,业界对实时查询和迭代分析有更多的需求,单纯依靠MapReduce框架已经不能满足业务的需求了。Spark由于其可伸缩、基于内存计算等特点,且可以直接读写Hadoop上任何格式的数据,成为满足业务需求的最佳候选者。 应用Spark的成功案例 目前大数据在互联网公司主要应用在广告、报表、推荐系统等业务上。在广告业务方面需要大数据做应用分析、效果分析、定向优化等,在推荐系统方面则需要大数据优化相关排名、个性化推荐以及热点点击分析等。 这些应用场景的普遍特点是计算量大、效率要求高。Spark恰恰满足了这些要求,该项目一经推出便受到开源社区的广泛关注和好评。并在近两年内发展成为大数据处理领域最炙手可热的开源项目。 本章将列举国内外应用Spark的成功案例。 1. 腾讯 广点通是最早使用Spark的应用之一。腾讯大数据精准推荐借助Spark快速迭代的优势,围绕“数据+算法+系统”这套技术方案,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通pCTR投放系统上,支持每天上百亿的请求量。 基于日志数据的快速查询系统业务构建于Spark之上的Shark,利用其快速查询以及内存表等优势,承担了日志数据的即席查询工作。在性能方面,普遍比Hive高2-10倍,如果使用内存表的功能,性能将会比Hive快百倍。 2. Yahoo Yahoo将Spark用在Audience Expansion中的应用。Audience Expansion是广告中寻找目标用户的一种方法:首先广告者提供一些观看了广告并且购买产品的样本客户,据此进行学习,寻找更多可能转化的用户,对他们定向广告。Yahoo采用的算法是logistic regression。同时由于有些SQL负载需要更高的服务质量,又加入了专门跑Shark的大内存集群,用于取代商业BI/OLAP工具,承担报表/仪表盘和交互式/即席查询,同时与桌面BI工具对接。目前在Yahoo部署的Spark集群有112台节点,9.2TB内存。 3. 淘宝 阿里搜索和广告业务,最初使用Mahout或者自己写的MR来解决复杂的机器学习,导致效率低而且代码不易维护。淘宝技术团队使用了Spark来解决多次迭代的机器学习算法、高计算复杂度的算法等。将Spark运用于淘宝的推荐相关算法上,同时还利用Graphx解决了许多生产问题,包括以下计算场景:基于度分布的中枢节点发现、基于最大连通图的社区发现、基于三角形计数的关系衡量、基于随机游走的用户属性传播等。 4. 优酷土豆 优酷土豆在使用Hadoop集群的突出问题主要包括:第一是商业智能BI方面,分析师提交任务之后需要等待很久才得到结果;第二就是大数据量计算,比如进行一些模拟广告投放之时,计算量非常大的同时对效率要求也比较高,最后就是机器学习和图计算的迭代运算也是需要耗费大量资源且速度很慢。 最终发现这些应用场景并不适合在MapReduce里面去处理。通过对比,发现Spark性能比MapReduce提升很多。首先,交互查询响应快,性能比Hadoop提高若干倍;模拟广告投放计算效率高、延迟小(同hadoop比延迟至少降低一个数量级);机器学习、图计算等迭代计算,大大减少了网络传输、数据落地等,极大的提高的计算性能。目前Spark已经广泛使用在优酷土豆的视频推荐(图计算)、广告业务等。 Spark与Shark的原理 1.Spark生态圈 如下图所示为Spark的整个生态圈,最底层为资源管理器,采用Mesos、Yarn等资源管理集群或者Spark自带的Standalone模式,底层存储为文件系统或者其他格式的存储系统如HBase。Spark作为计算框架,为上层多种应用提供服务。Graphx和MLBase提供数据挖掘服务,如图计算和挖掘迭代计算等。Shark提供SQL查询服务,兼容Hive语法,性能比Hive快3-50倍,BlinkDB是一个通过权衡数据精确度来提升查询晌应时间的交互SQL查询引擎,二者都可作为交互式查询使用。Spark Streaming将流式计算分解成一系列短小的批处理计算,并且提供高可靠和吞吐量服务。
2.Spark基本原理 Spark运行框架如下图所示,首先有集群资源管理服务(Cluster Manager)和运行作业任务的结点(Worker Node),然后就是每个应用的任务控制结点Driver和每个机器节点上有具体任务的执行进程(Executor)。
与MR计算框架相比,Executor有二个优点:一个是多线程来执行具体的任务,而不是像MR那样采用进程模型,减少了任务的启动开稍。二个是Executor上会有一个BlockManager存储模块,类似于KV系统(内存和磁盘共同作为存储设备),当需要迭代多轮时,可以将中间过程的数据先放到这个存储系统上,下次需要时直接读该存储上数据,而不需要读写到hdfs等相关的文件系统里,或者在交互式查询场景下,事先将表Cache到该存储系统上,提高读写IO性能。另外Spark在做Shuffle时,在Groupby,Join等场景下去掉了不必要的Sort操作,相比于MapReduce只有Map和Reduce二种模式,Spark还提供了更加丰富全面的运算操作如filter,groupby,join等。 Spark采用了Scala来编写,在函数表达上Scala有天然的优势,因此在表达复杂的机器学习算法能力比其他语言更强且简单易懂。提供各种操作函数来建立起RDD的DAG计算模型。把每一个操作都看成构建一个RDD来对待,而RDD则表示的是分布在多台机器上的数据集合,并且可以带上各种操作函数。如下图所示:
首先从hdfs文件里读取文本内容构建成一个RDD,然后使用filter()操作来对上次的RDD进行过滤,再使用map()操作取得记录的第一个字段,最后将其cache在内存上,后面就可以对之前cache过的数据做其他的操作。整个过程都将形成一个DAG计算图,每个操作步骤都有容错机制,同时还可以将需要多次使用的数据cache起来,供后续迭代使用。 3.Shark的工作原理 Shark是基于Spark计算框架之上且兼容Hive语法的SQL执行引擎,由于底层的计算采用了Spark,性能比MapReduce的Hive普遍快2倍以上,如果是纯内存计算的SQL,要快5倍以上,当数据全部load在内存的话,将快10倍以上,因此Shark可以作为交互式查询应用服务来使用。
上图就是整个Shark的框架图,与其他的SQL引擎相比,除了基于Spark的特性外,Shark是完全兼容Hive的语法,表结构以及UDF函数等,已有的HiveSql可以直接进行迁移至Shark上。 与Hive相比,Shark的特性如下: 1.以在线服务的方式执行任务,避免任务进程的启动和销毁开稍,通常MapReduce里的每个任务都是启动和关闭进程的方式来运行的,而在Shark中,Server运行后,所有的工作节点也随之启动,随后以常驻服务的形式不断的接受Server发来的任务。 2.Groupby和Join操作不需要Sort工作,当数据量内存能装下时,一边接收数据一边执行计算操作。在Hive中,不管任何操作在Map到Reduce的过程都需要对Key进行Sort操作。 3.对于性能要求更高的表,提供分布式Cache系统将表数据事先Cache至内存中,后续的查询将直接访问内存数据,不再需要磁盘开稍。 4.还有很多Spark的特性,如可以采用Torrent来广播变量和小数据,将执行计划直接传送给Task,DAG过程中的中间数据不需要落地到Hdfs文件系统。 腾讯大数据Spark的概况 腾讯大数据综合了多个业务线的各种需求和特性,目前正在进行以下工作: 1.经过改造和优化的Shark和Spark吸收了TDW平台的功能,如Hive的特有功能:元数据重构,分区优化等,同时可以通过IDE或者洛子调度来直接执行HiveSql查询和定时调度Spark的任务; 2.与Gaia和TDW的底层存储直接兼容,可以直接安全且高效地使用TDW集群上的数据; 3.对Spark底层的使用门槛,资源管理与调度,任务监控以及容灾等多个功能进行完善,并支持快速的迁移和扩容。 | |
|
(没有打分) |




高端招聘(1): A轮融资Startup 。上海 。Android研发工程师
作者 陈怀临 | 2014-07-18 22:45 | 类型 高端招聘 | Comments Off
|
A轮公司,工作地点上海,互联网公司,80-100人。 联系方式: valleytalkjobs@gmail.com 职位名称:资深Android开发工程师 职责描述 职位名称:android底层工程师 | |
|
(没有打分) |
TSRC:主流WAF架构分析与探索
作者 陈怀临 | 2014-07-18 14:32 | 类型 网络安全 | 2条用户评论 »
TSRC:主流WAF架构分析与探索 背景: 网站安全漏洞在被发现后,需要修复,而修复需要时间,有些厂商可能无能力修复,甚至部分网站主可能连是否存在漏洞都无法感知(尤其是攻击者使用0day的情况下)。或者刚公开的1day漏洞,厂商来不及修复,而众多黑客已经掌握利用方法四面出击,防不胜防。这个时候如果有统一集中的网站防护系统(WAF)来防护,则漏洞被利用的风险将大大降低,同时也为漏洞修复争取时间! 笔者所在公司的业务较多,光域名就成千上万,同时网络流量巨大,动辄成百上千G。而这些业务部署在数十万台服务器上,管理运维职能又分散在数十个业务部门,安全团队不能直接的管理运维。在日常的安全管理和对抗中,还会经常性或者突发性的遇到0day需要响应,比如更新检测引擎的功能和规则,这些都是比较现实的挑战。 对于WAF的实现,业界知名的网站安全防护产品也各有特色。本文将对主流的WAF架构做一个简单的介绍,和大家分享下。同时结合笔者所在公司业务的实际情况,采用了一种改进方案进行探索,希望本文能达到抛砖引玉的效果。(不足之处请各位大牛多多指教) 特别声明:以下方案无优劣之分,仅有适合不适合业务场景的区别。 业界常见网站安全防护方案 方案A:本机服务器模块模式 通过在Apache,IIS等Web服务器内嵌实现检测引擎,所有请求的出入流量均先经过检测引擎的检测,如果请求无问题则调用CGI处理业务逻辑,如果请求发现攻击特征,再根据配置进行相应的动作。以此对运行于Web服务器上的网站进行安全防护。著名的安全开源项目ModSecurity及naxsi防火墙就是此种模式。 优点: 1、 网络结构简单,只需要部署Web服务器的安全模块 挑战: 1、 维护困难。当有大规模的服务器集群时,任何更新都涉及到多台服务器。 2、 需要部署操作,在面临大规模部署时成本较高。 3、 无集中化的数据中心。针对安全事件的分析往往需要有集中式的数据汇总,而此种模式下用户请求数据分散在各个Web服务器上。 方案B:反向代理模式  使用这种模式的方案需要修改DNS,让域名解析到反向代理服务器。当用户向某个域名发起请求时,请求会先经过反向代理进行检测,检测无问题之后再转发给后端的Web服务器。这种模式下,反向代理除了能提供Web安全防护之外,还能充当抗DDoS攻击,内容加速(CDN)等功能。云安全厂商CloudFlare采用这种模式。 优点: 1、 集中式的流量出入口。可以针对性地进行大数据分析。 2、 部署方便。可多地部署,附带提供CDN功能。 挑战: 1、 动态的额外增加一层。会带来用户请求的网络开销等。 2、 站点和后端Web服务器较多的话,转发规则等配置较复杂。 3、 流量都被捕捉,涉及到敏感数据保护问题,可能无法被接受。 方案C:硬件防护设备  这种模式下,硬件防护设备串在网络链路中,所有的流量经过核心交换机引流到防护设备中,在防护设备中对请求进行检测,合法的请求会把流量发送给Web服务器。当发现攻击行为时,会阻断该请求,后端Web服务器无感知到任何请求。防护设备厂商如imperva等使用这种模式。 优点: 1、 对后端完全透明。 挑战: 1、 部署需改变网络架构,额外的硬件采购成本。 2、 如Web服务器分布在多个IDC,需在多个IDC进行部署。 3、 流量一直在增加,需考虑大流量处理问题。以及流量自然增长后的升级维护成本。 4、 规则依赖于厂商,无法定制化,不够灵活。 我们的探索 笔者所在的公司在不同的场景下,也近似的采纳了一种或者多种方案的原型加以改进使用运营。(比如方案C,其实我们也有给力的小伙伴做了很棒的努力,通过自研的方式解决了不少挑战,以后有机会或许也会和大家分享一些细节) 今天给大家介绍的,是我们有别于业界常见模型的一种思路: 方案D:服务器模块+检测云模式  这种模式其实是方案A的增强版,也会在Web服务器上实现安全模块。不同点在于,安全模块的逻辑非常简单,只是充当桥梁的作用。检测云则承担着所有的检测发现任务。当安全模块接收到用户的请求时,会通过UDP或者TCP的方式,把用户请求的HTTP文本封装后,发送到检测云进行检测。当检测无问题时,告知安全模块把请求交给CGI处理。当请求中检测到攻击特征时,则检测云会告知安全模块阻断请求。这样所有的逻辑、策略都在检测云端。 我们之所以选择这个改进方案来实现防护系统,主要是出于以下几个方面的考虑: 1、 维护问题 假如使用A方案,当面临更新时,无法得到及时的响应。同时,由于安全逻辑是嵌入到Web服务器中的,任何变更都存在影响业务的风险,这是不能容忍的。 2、 网络架构 如果使用方案B,则需要调动大量的流量,同时需要提供一个超大规模的统一接入集群。而为了用户就近访问提高访问速度,接入集群还需要在全国各地均有部署,对于安全团队来说,成本和维护难度难以想象。 使用该方案时,需要考虑如下几个主要的挑战: 1、 网络延时 采用把检测逻辑均放在检测云的方式,相对于A来说,会增加一定的网络开销。不过,如果检测云放在内网里,这个问题就不大,99%的情况下,同城内网发送和接收一个UDP包只需要1ms。 2、 性能问题: 由于是把全量流量均交给集中的检测云进行检测,大规模的请求可能会带来检测云性能的问题。这样在实现的时候就需要设计一个好的后端架构,必须充分考虑到负载均衡,流量调度等问题。 3、 部署问题: 该方案依然需要业务进行1次部署,可能会涉及到重编译web服务器等工作量,有一定的成本。并且当涉及到数千个域名时,问题变的更为复杂。可能需要区分出高危业务来对部署有一个前后顺序,并适时的通过一些事件来驱动部署。 最后,我们目前已灰度上线了这套防御方案,覆盖重要以及高危的业务站点。目前日均处理量约数百亿的规模,且正在快速增长阶段。 本文只是一个粗略的简介,我们在建设过程中也遇到了远高于想象的挑战和技术难题,后续将会有系列文章来深入剖析和介绍,希望对大家有所帮助。 作者:腾讯安全应急响应中心 那个谁 | |
|
(没有打分) |
NFV的行业调查报告
作者 陈怀临 | 2014-07-17 18:23 | 类型 NFV, 行业动感 | Comments Off

A Guide to NFV and SDN
作者 陈怀临 | 2014-07-17 18:06 | 类型 SDN | 1条用户评论 »
