




思科QuantumFlow处理器及其战略研究(5):体系结构(处理器观点)(续)
作者 陈怀临 | 2009-01-24 19:28 | 类型 专题分析 | 18条用户评论 »
系列目录 思科的QuantumFlow多核处理器
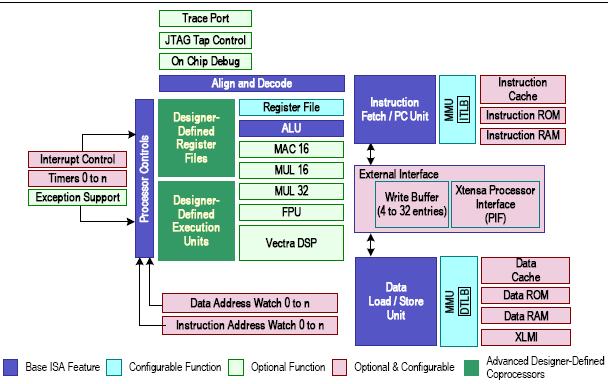
思科的QFP的40个CPU核采用的是Tensilica的Xtensa的ISA。从思科公开的新闻资料中,思科声称是只采用了Xtensa的指令集结构(ISA),而其他部件或子系统的逻辑设计,加上后端设计和封装,都是思科自己研发队伍完成的。 从这些声明,对思科QFP有兴趣的读者可能会误以为思科只是购买了Xtensa的指令集(Instruction Set)。这是不精确的。Xtensa ISA的含义不仅仅包括指令集,也包含Xtensa的一些基本的的微结构,例如基本的流水线结构等。否则,思科没有必要去购买一个非主流的指令集,而从新做一个CPU,用OpenRISC的ISA就可以了。 Tensilica的Xtensa是一个SoC软核,从而第三方可以进行定制和裁剪做出其自己的SoC。也可以同过Tensilica提供的集成环境调试,增加新的指令等等。下图是Xtensa的体系结构略图:
从图中所示,可以得知蓝色模块是Xtensa体系结构ISA中的基本模块。 笔者认为这些基本的流水线模块是思科QFP重用的。
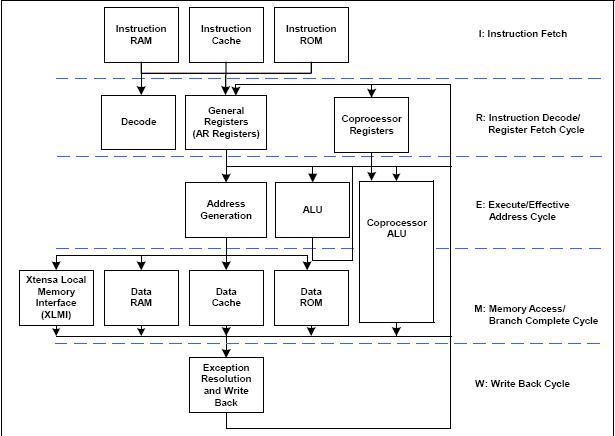
上图 所示为Xtensa的基本流水线结构。读者可以看出,其是单发结构的5级流水线。(思科声称QFP是3发射)。另外,因为Xtensa的核心并没有实现复杂的Out of Order的执行和超标量结构,没有Interlock的处理,因此,在设计内存操作的指令时,仍然会有delay slot等的发生。 从上述Xtensa的ISA微结构,然后比较思科QFP的微结构,特别是每个核有4个硬件线程的结构。我们可以知道思科确实是需要在逻辑和物理设计方面做许多特定设计,才能达到QFP的设计目标。例如,基于FMT的4个硬件线程的微结构的设计需要增加几套寄存器,局部总线(Local Bus)和裁决逻辑(Arbitor)等。 另外,在MMU方面,QFP估计也是基本上会重用Xtensa的结构。但感觉在缓存结构上和内存总线接口方面,思科的QFP研发团队需要对Xtensa做许多修改。例如必须将Xtensa挂到QFP的2维CrossBar或Mesh互连结构上。这都需要巨大的研发工作。 从思科发布的QFP资料,其核的主频可以做到1.2GHz。为了能做到1.2GHz,大量的后端设计和手工调试需要开展,而非简单的流片。笔者曾经在5年前用过Xtensa定制过一款SoC的软核。记得当时的体会是,在缓存方面,只要稍微一加大,主频立刻急剧的下来。 一般而言,思科的QFP里面一定会通过Xtensa的全套工具,加入QFP自己的指令集扩充,并且在gcc tool-chain上直接支持。 除了是可定制的SoC软核,编译器和工具链的强大支持是Xtensa之所以能够10年之久还生存的重要原因之一。 | |
 (2个打分, 平均:5.00 / 5) (2个打分, 平均:5.00 / 5) |
雁过留声
“思科QuantumFlow处理器及其战略研究(5):体系结构(处理器观点)(续)”有18个回复
祝各位新年好, 牛年牛!
我个人认为我是少有的能同时对IA32,Xscale/ARM,MIPS,PowerPC都有一定实践经验的工程师。今天下午,坐在starbucks,手里拿着Tensilica Xtensa的资料。苦苦思考一个问题:为什么思科选择了Xtensa的ISA?我试图把自己放在几年前思科的某个办公室,一群人在讨论CPU的优缺点。。。
做软核的cpu, 处理器不是最重要的,关键是eda tool
做高性能软核的cpu, 处理器不是最重要的,interface和interconnect和memory是最难做的。主要是physical design。SI(Signal Integrity)最难。EDA Tool是没有用的;要手工调。
陈老大,误解了.我觉得tensilica最好的就是eda tool, xplorer工具作系统分析很不错的.具体tensilica cpu的架构和arm, mips不会有革命性差异.
cisco的处理器应该会同时考虑优化静态和动态功耗的,不过没见说明.
知道了。你说24bit(3个Byte)的指令从而使得代码的size会比较小,是不是主要原因之一。这可是比其他CPU的指令短1/3。还是比较不错的。
xtensa内部有一个hardware aligner完成对齐,这样效率不一定高.code size和编译器很有关系.
Tensilica(或者ARC)这类可配置处理器跟Arm, MIPS等处理器IP还是有很大差别的,所以会有争论Tensilica这类公司是究竟是算EDA公司呢还是IP供应商。
使用Tensilica实际上工作量很大,相当于是重新自顶向下设计一个机器了(应用分析,指令集,微架构,逻辑,物理设计…),我觉得它最大的好处是配套工具,由于自动化程度很高(尤其包括自动生成simulator, compiler…),大大降低了architect的工作量。
p.s: 我没有实际使用过tensilica的产品,所以…
我用过Xtensa一阵,但不深。感觉,做小系统,用其tools足够(semi-custom)。例如,加几个core在一个ASIC里。但做大系统,这些EDA工具都不灵,更需要full-custom(全定制)。
可能功耗和自定义指令是关键,传统的arm, mips和PPC都不适合DPI 的密集运算,一点拙见
做一个cisco那样的大芯片,纯asic肯定不行,开发时间太长,不够灵活。在xtensa的基础上做定制是个比较好的办法。ARM, MIPS, PPC估计很难做定制吧,感觉它们比较适合做控制用。
关于QFP是多少发射,为什么不是3而是1?
之前RMI XLR732的微架构与此相似,但XLP架构已经修改,可支持Quad Issue。QFP要支持更高性能,是否在多发射、乱序执行等考虑,仅仅增加核和线程的数目好象很难了?
此微架构是否根据Tensilica推出?ALU负责加、减、逻辑、移位操作,协处理器负责MAC16、MUL16、MUL32。
由于实际网络转发编程中有大量的if…else,因此不知道其分之预测机制如何?如果预测准确率不高,将导致大量的指令流水线flush/fill,注定没性能。
分支预测,个人认为有这么几种
1)手工编写的,比如likely,unlikely之类的宏。它的目的还是指导编译器编译出想象中的程序。这个有时候很有用,比较考验对系统与代码的掌握程度。
2)编译器优化。编译器自动优化,这个看编译器写得怎么样了。
3)CPU动态预测。这个依赖于分支语句的cache。效果要看具体的应用。
小雁,multi-isse and out-of-order execution的后面是芯片有多个function unit。例如,ALU(整数运算器)。QFP是一个NP,而非一个NSP(Network Service Processor) with General Purpose Core(MIPS).XLP一定是有多个ALU,但只能支持8个HWT。那么从芯片设计的角度,如何提高性能呢?多发射,乱序执行。换言之,通过增加Super-Scalar的功能/加强,增强计算。另外,这与pipeline没有关系。pipeline 与Super-scalar是两个正交的概念和机制。换言之,XLP已经是一个Super-Scalar CPU。
但QFP是Tensilica的core,只有一个ALU。支持40个HWT。啥意思呢?
这一切都是芯片设计的角度问题。。。。
多线程要解决的是,当CPU function unit stalled的时候,例如,Load/Store miss的时候,不能浪费计算能力。
所有,QFP是通过大量的,简单的线程来提高计算能力,而非multi-issue和out of order execution。
首席,多谢详细指点。
其实,按照你的分析,QFP是单发射的,4个硬件线程。也就是XLR732的Core Architecture。既然是单发射,ALU在一个时刻只能处理一个线程的指令。请问在线程切换过程中,Pipeline是继续执行(指令头部携带thread id)还是需要清空pipeline然后refill新线程的指令?
楼上,单发射并不是指ALU在同一个时刻只能处理一个线程的指令,甚至也不意味着只有一个ALU,它只意味着说每时钟周期可以发射一个指令到执行单元