




龙芯CPU(9)–龙芯2号处理器的微结构
作者 陈怀临 | 2009-04-30 15:04 | 类型 专题分析, 中国龙芯 | 1条用户评论 »
系列目录 中国龙芯CPU的调查与研究
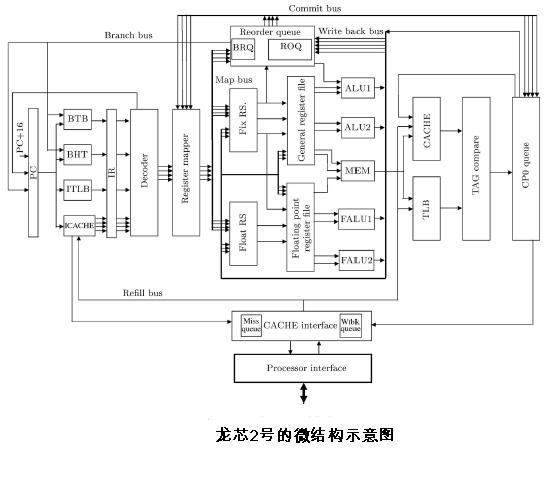
考察一个CPU处理器的设计,通常的方法论为:首先看其结构(Architecture),再看其微结构(Micro-Architecture)。而最重要的是其微结构。 本文是科学院计算所胡伟武与其2个博士生2005年3月发表在Journal of Computer Science and Technology计算机科学技术学报(英文版)的一篇综述文章,较详细的介绍了龙芯2号(编者注:应该是GodSon-2C)的微结构。下面是其英文摘要: Abstract: The Godson project is the first attempt to design high performance general-purpose microprocessors in China. This paper introduces the microarchitecture of the Godson-2 processor which is a 64-bit, 4-issue, out-of-order execution RISC processor that implements the 64-bit MIPS-like instruction set. The adoption of the aggressive out-of-order execution techniques(such as register mapping, branch prediction, and dynamic scheduling) and cache techniqueus(such as non-blocking cache, load speculation, dynamic memory disambiguation) helps the Godson-2 processor to achieve high perfoormance even at not so high frequency. The Godson-2 processor has been physically implemented on a 6-mental 0.18um CMOS technology based on the automatic placing and routing flow with the help of some crafted library cells and macros. The area of the chip is 6,700 micrometers by 6,200 micrometers and the clock cycle at typical corner is 2.3ns. 【编者注:】 从文章的摘要来看,这个CPU本身并没有什么巨大的研究创新突破,当然这也不是计算所做龙芯的目的,例如,其中描述的各种技术都已经是广泛的被采用在现代CPU处理器的设计中。但是对计算所的工程价值是巨大的。这一点是不容置疑的。做龙芯确实不是为了发表几篇文章。这里的4发射在微结构上指的是Godson是一个超标量(superScalar)结构,拥有两个整数加法器(ALU)两个浮点运算器,一个Load/Store MEM部件。 在这个摘要中,对于编者而言,这个“MIPS-like”是非常细微的(subtle)但不容忽略的。在谈论一个处理器的指令集ISA时,MIPS- like还是MIPS-Compatible的ISA是区别很大的。当然,有没有区别,或者区别在哪里,都会在最后编译器,例如gcc,的后端 (backend)被体现出来。那么在这篇发表于2005年的文章中的“MIPS-Like” 里面蕴含了什么奥秘呢?编者通过调研,得出的结论是:MIPS的专利和法律问题。 在2005年,或者说龙芯2C之前,计算所并没有MIPS的许可证。MIPS的ISA中,有4个被专利保护的指令。因此,龙芯是不能实现这4条指令的。不实现这4条被专利保护的指令,在市场上就只能称为MIPS-Like的处理器。这个没法越过的鸿沟就是美国专利 4,814,976。这4个MIPS I的指令分别是:lwl, lwr, swl, and swr。该专利的一些摘要信息如下: Patent Name:RISC computer with unaligned reference handling and method for the same Abstract Patent number: 4814976 2007年,为龙芯流片的欧洲公司 ST Microelectronic买下了MIPS的许可证。MIPS公司与计算所达成协议。从此龙芯可以成为MIPS兼容的处理器。有兴趣的读者可以参阅2007年3月28日MIPS公司的新闻稿。 下载:龙芯2号处理器的微结构 | |
 (2个打分, 平均:5.00 / 5) (2个打分, 平均:5.00 / 5) |
思科核心路由器CRS-1与SPP处理器的研究–交换矩阵与交换平面
作者 陈怀临 | 2009-04-29 16:10 | 类型 专题分析 | 80条用户评论 »
系列目录 思科SPP处理器与核心路由器CRS-1
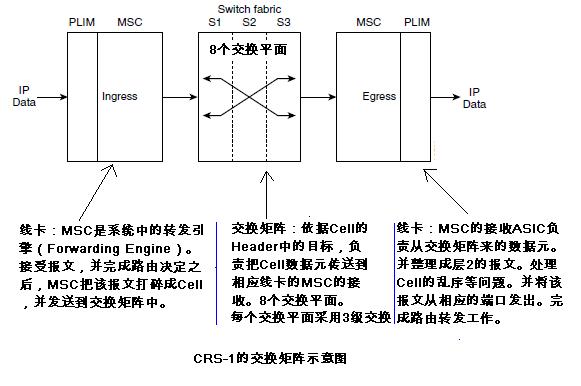
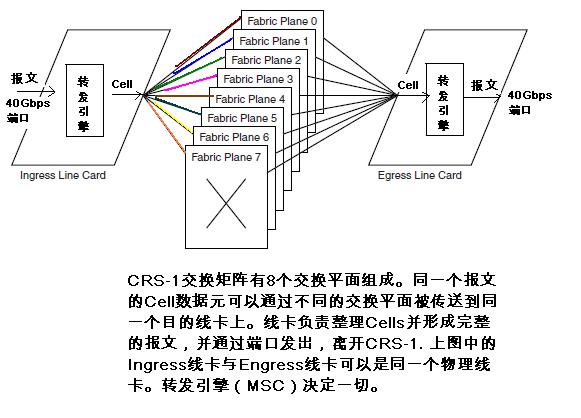
CRS-1最重要的部分可以说就是其交换矩阵和拓扑。交换矩阵把CRS-1的各个组成部分有机的结合在一起,形成一个高速的路由器。CRS-1的交换是CRS-1体系结构里略微复杂和难理解的部分,下面分别对LCC和FCC的交换矩阵和拓扑做一些概念上的解释和阐述。希望读者能通过阅读相应章节之后能从整体上对CRS-1的交换空间有一个清晰的把握。 首先,读者要了解CRS-1交换矩阵(Switch Fabric),交换平面(Switch Plane),交换卡(Switch Fabric Card)和之间的关系。本节介绍交换矩阵和交换平面,这两个逻辑实体。交换卡属于物理实体(实现),将在下一节更详细的介绍。 × CRS-1交换矩阵(Switch Fabric): 交换矩阵由8个或者4个交换平面所组成。其中,16槽和8槽LCC:8个交换平面;4槽LCC:4个交换平面。交换平面之间是并行,没有依赖关系的。换言之,这些交换平面的关系是正交的。 交换矩阵中通信的粒度是大小固定的数据元(Cell)。一个数据报文(Packet)在经过交换矩阵之前,线卡的Ingress MSC卡会把该报文分解为多个数据元。MSC会决定一个数据元被发送到哪个交换平面,并通过这个交换平面到达目标Engress MSC(这个MSC会汇总属于该报文的所有Cell,并恢复成一个Packet, 并通过端口卡(PLIM)上相应的端口(Port)把报文转发出去。一定要注意的是:属于同一个报文的不同的数据元可以(其实是通常)是通过不同的交换平面抵达目的线卡的。但一个特定的Cell会而且只会通过一个选定的交换平面。在CRS-1,Ingress线卡上的MSC通常是通过轮询(RoundRobin)的算法来决定使用哪个交换平面的。这里面的原因很简单直接,可以使得这8个或4个交换平面的负载均匀化,而避免某一个交换平面产生阻塞丢掉数据元的情况。 × CRS-1交换平面(Switch Plane):交换平面是交换矩阵的最小单位。一个交换平面能够实现了一个完整报文交换的功能。其中,每个交换平面采用3级(Stage)交换的体系结构。每个交换平面是通过在LCC机箱后面的交换卡来物理实现的。换言之,每个交换卡就是一个交换平面。 CRS-1系统中,理论上只需要一个交换平面就可以实现CRS-1路由器的转发交换功能。在CRS-1的实际运营上,系统要求至少两个交换平面来保证系统路由转发交换。当然,这时系统已经不是线速的了。换言之,交换的能力不能支持众多40Gbps的线卡了。CRS-1的交换平面的交换率可以使得7个交换平面就可以保证CRS-1系统的线速。 读者阅读到这里的时候,一定要深刻的认识如下的断言:CRS-1系统中的任何(Each)一个线卡,通过中间板(midplane),可以连接到任何(Each)一个交换平面上。换言之,每个交换平面上,有来自所有线卡的输入。 每个交换平面上,都有通向任何一个线卡的输出。 下图是CRS-1交换矩阵和交换平面的逻辑示意图。读者要注意的是,在谈论交换矩阵和交换平面的时候,都是一些逻辑概念和(或)实体。与具体的物理实现是无关的。或者说,可以通过许多技术方式来实现上述的交换矩阵和其组成部分交换平面。
| |
|
(2个打分, 平均:5.00 / 5) |
猪流感(Swine Flu)流行分布图
作者 杰夫 | 2009-04-29 16:09 | 类型 专题分析 | Comments Off
|
当前猪流感的流行有愈演愈烈之势。今天在美国得克萨斯州发现第一例死亡病例,也是墨西哥以外的第一个死亡病例。世界卫生组织(WHO)也将警告级别提高到五级(最高为六级),表示大面积感染(Pandemic)迫在眉睫。 下面的Google Map是猪流感的分布图,每天更新多次。红色标签为确诊病例,黄色为疑似病例,黑色为死亡病例。
| |
|
(1个打分, 平均:5.00 / 5) |
龙芯CPU(8)–龙芯2号处理器设计报告
作者 陈怀临 | 2009-04-29 08:28 | 类型 专题分析, 中国龙芯 | 1条用户评论 »
系列目录 中国龙芯CPU的调查与研究
【编者注:】 这是科学院计算所2004年11月发布(公开)的其关于龙芯2号CPU的一个设计报告。当时的流片为Godson-2C。该设计报告中讨论了Godson-2D的设计提案和将来的Godson-3的设计思想。目前,龙芯的最新流片为Godson-2F。龙芯3目前还没有任何发布日程表。对CPU微结构有兴趣的读者,这个报告一个很值得一读并展开讨论。我们也可以从其2004年的发展目标与现在的状况对比,从而也更加了解设计一个CPU的道路是不容易的。下载龙芯2号处理器设计报告 | |
 (没有打分) (没有打分) |
流量控制,P2P应用的识别与控制系统–Panabit
作者 陈怀临 | 2009-04-28 15:52 | 类型 行业动感 | 114条用户评论 »
|
目前,在网络安全系统,智能化边缘路由器中,对应用层的识别是一个非常重要的指标。 例如,笔者曾经着力分析的思科公司基于QuantumFlow处理器的边缘路由器ASR1000中就把NBAR (Network-Based Application Recognition)作为一个非常重要的性能(Feature)列入其产品规约中。在ASR9000中也是如此。另外,在众多思科的产品中都有NBAR的性能,例如Cisco的重要的ISR1800系列,3000系列和7000系列。 NBAR可以识别许多流行的P2P的应用程序,例如BitTorrent, Gnutella, Kazaa2, eDonkey, Fasttrack, Napster等等。从某种角度而言,这些技术属于QoS(Policing,Shaping,Rate Limiting),也可以被认为是网络安全(Policy,ACL Control)的范畴。 在网络的各个关口(例如,边缘,企业WAN接入)对应用程序的识别是非常重要的。从技术上而言,这就是一个分类器(Classfiier)。了解QoS的读者知道,数据报文只有被Classify分类之后,系统才可以把不同的策略应用上去,例如网络安全策略,流量控制策略(其实就是对多级别,上百个报文队列Queue的算法管理和调度)等等。 应用程序识别和控制系统可以作为边缘路由器,企业WAN接入,独立防火墙系统的一个硬件或者软件模块集成在一起,也可以单独作为一个系统挂在一个企业网络中,例如挂在防火墙的后面。 笔者认为,长远的趋势是被集成在企业网的WAN接入的这个环节。当然,这里面要解决许多技术问题,最主要的就是吞吐率和可扩展性。 国内网络软件和设备市场,在用户程序识别,流量控制系统方面,目前出现一个叫做Panabit的流量控制软件。其发布团体为北京三棱镜软件工作室。其声称能够识别中国国内大量的P2P应用程序,流媒体,VoIP应用,网络游戏等等。其支持的协议之多令笔者是刮目相看。有兴趣的读者可以访问其主页:Panabit主页。Panabit声称的性能指标也非常不错,细节为: 软件性能 在这样的硬件配置下,能做到这样的线速还是不错的。当然,对于这样的系统,其对不同类型(Category)的应用程序能支持多少的pps(Packet Per Second)是更重要的。似乎Panabit没有提供这方面的数据。 在体系结构方面,似乎Panabit是采用软件OEM的方式开拓市场。这在目前的规模下是正确的。但从长远考量,是否需要做出自己的流量控制卡服务模块,例如通过PCI-E,Rapid-IO,SPI等的接口,从而第3方的网络大公司可以通过插卡的方式与其互联是一个值得考虑的问题。当然,Panabit自己做系统就是一个更大的问题了。 另外,笔者认为Panabit最大的挑战在于,如果这个市场足够大而引起国内业界,例如华为,中兴,山石等其他具备资源优势(人力,财力,渠道)的公司的足够重视,Panabit如何在竞争中生存,更重要的是,如何规模的成长,这是一个非常严重的问题。 | |
|
(5个打分, 平均:4.20 / 5) |

工具箱
本文链接 |
|
打印此页 | 114条用户评论 »
ZeniMax
作者 青成 | 2009-04-28 13:47 | 类型 初创公司 | 1条用户评论 »
|
ZeniMax 与一些业界知名的出版商关系密切,并自称得到了足够的资金来完成在开发中的“秘密”项目。这个项目是一款多人网上游戏(MMOG,Massively Multiplayer on-line Game)。ZeniMax 的自信来在于其关键员工的背景:Dark Age of Camelot, Warhammer Online, Star Wars: Galaxies, Ultima Online, 以及The Sims Online。 在全球金融危机的大环境下,各个游戏工作室也面临着生存危机。不久前,微软也停止了自己的Flight Simulator 的开发。ZeniMax 却过得不错,该工作室还在积极寻找在线游戏方面的人才。大型在线游戏的开发是一个漫长的过程。通常来说开发周期越长,风险就越大。不过自从魔兽争霸获取了丰厚的利润,各种大小工作室如雨后春笋般冒了出来。尽管到目前为止,还没有出现类似魔兽争霸玩家规模或者收益规模的产品,ZeniMax 还是是希望能成就一番未来。让我们来祝愿他们好运。 | |
|
(2个打分, 平均:3.00 / 5) |
 ZeniMax
ZeniMax纳米材料太阳能电池板厂商-Nanosolar公司
作者 杰夫 | 2009-04-27 14:58 | 类型 初创公司, 新兴技术, 纳米技术 | 3条用户评论 »
|
从其名字也可以看出,Nanosolar公司的太阳能电池面板产品号称是采用纳米材料制成,成本比传统产品低一个数量级,单位面积的发电量确可以高好几倍。从其融资历史和产品销售情况来看,他们不像是在单纯玩(纳米)概念,技术上确有过人之处。该公司于2002年由两名斯坦福大学的博士候选人(Martin Roscheisen和Brian Sager)创立,初期投资来自创始人和几位天使投资人,其中包括谷歌公司的两位创始人(他们也曾经是斯坦福的博士候选人)。Nanosolar创立后几年内又成功拿到多轮投资,05年Series B投资拿到2千万美元,06年Series C拿到7千5百万美元,08年Series D又拿到3亿美元,总投资超过4亿美元。除此之外,Nanosolar在2007年还获得美国能源部的一笔2千万美元的基金(这也是能源部在新能源方面批准的最大的一笔基金)。Nanosolar目前在圣何塞设有太阳能电池生产厂,还在德国设有组装厂。 Nanosolar的投资商包括Benchmark Capital,Mohr Davidow Ventures,EDF,AES Corporation,和Energy Capital Partners等。有关Nanosolar更全面的介绍,请参见Nanosolar公司网站。 | |
|
(2个打分, 平均:5.00 / 5) |

龙芯CPU(7)–高性能通用微处理器研发现状及发展策略
作者 陈怀临 | 2009-04-26 14:49 | 类型 专题分析, 中国龙芯 | 3条用户评论 »
系列目录 中国龙芯CPU的调查与研究
【编者注:】这是胡伟武博士在2006年1月发表在中国计算机学会通讯杂志创刊号的一篇文章。在该文中,胡伟武阐述了其对目前国内外高性能通用微处理器的研发现状,和对龙芯将来发展的策略的一些观点,例如: 根据目前应用的需求,我们设计的处理器芯片所面向的系统分别为高性能PC、SMP服务器以及高性能计算机系统。根据上述三类系统的要求,我们的高性能通用处理器芯片研制可以分如下三个阶段进行。 第二阶段时间跨度从现在到“十一五”初(2004年~2006年),突破单核、单线程OC实现技术。其中,每个SOC中嵌入一个高性能通用CPU核以及桥控制逻辑和各种口控制逻辑,如存储器控制逻辑DDR、I/O 控制逻辑PCI40、HT、AGP41等。此外还直接支持多处理机互连的SOC,通过多处理器互连网络路由构成支持全局存储访问的多处理机系统,解决服务器用CPU问题。 第三阶段时间跨度为“十一五”初期到“十一五”末(2006年~2010年),突破多多线程SOC技术。到“十一五”结束时设计出主频为2GHz~4GHz,片内峰值运算速为每秒1000亿次浮点运算的多核多线程芯片。基于上述单核和多核高性能SOC芯片,“十一五”初研制成功万亿次高性能计算机系统,在“十一五”末研制成功百万亿次高性能机系统。并下大力推广应用,着力解决国防和国民经济的核心重要应用领域依赖国外微处理器问题。 (全文下载:高性能通用微处理器研发现状及发展策略) | |
|
(没有打分) |

龙芯CPU(6)–李国杰院士谈研制龙芯CPU的策略考虑
作者 陈怀临 | 2009-04-26 13:55 | 类型 专题分析, 中国龙芯 | 1条用户评论 »
系列目录 中国龙芯CPU的调查与研究
【编者注:我曾经详细收集了中国龙芯CPU的许多资料,现开始做一些整理并发布于此。总体而言,龙芯对中国信息技术的发展战略很重要。用李国杰院士的话讲,做龙芯是一个国家战略行为,而非一个单纯的技术 和(或)商业动作。】 李国杰院士谈研制龙芯CPU的策略考虑 2002年10月16日 中科院计算所 李国杰 我国科技界与产业界至今对如何快速而健康地发展我国IC产业,特别是对如何发展CPU产业还没有达成共识。本文以研制龙芯CPU的策略考虑为基础,对发展我国的集成电路设计产业提出一些观点与看法,请教于全国同行,旨在抛砖引玉,希望对决策层尽快做出科学决策有所裨益。 一、跨越与跟踪 IC加工业是资金高度密集的产业,一条0.18微米生产线,一般要投资15亿美元以上,国外对先进IC加工设备出口中国仍有许多限制,因此,我国在芯片加工方面实现跨越式发展难度相当大。相对而言,芯片设计是智力密集型产业,虽然IC设计产业的收入目前只占整个IC产业10%左右,但营业额增长率高于制造业3倍以上。台湾IC设计业1998年、1999年的投资回报率分别为21.6%和39%,比IC制造业的回报率(4.%和12.6%)高几倍。据麦卡锡公司预测,中国国内IC设计业2010年的收入可达100亿美元。我国从事芯片前端设计的人力资源丰富,许多研究所和大学都有不少从事系统和硬件设计的人才。芯片设计的知识产权和专利很多都体现在系统级设计上,尤其是当进入片上系统(SoC)设计时,系统级的创新更加重要。龙芯一号CPU物理设计的成功表明有系统级设计经验的人转入物理设计并不是一件高不可攀的事,入门并不难,只要有一股钻劲,经过几年的积累,我国一定会出现一批物理设计的高手。当然物理设计本身是一门高深的技术,微电子专业的人才是物理设计的主力。因此,我们认为,中国实现IC产业跨越发展的主要希望在芯片设计上。 在分析了计算所系统设计方面的技术储备与优势后,我们在龙芯一号设计开始时,提出了“高起点,一步到位”的要求。所谓高起点是指尽可能采用先进的制造工艺。我们第一次设计和流片生产CPU就跳过了0.35、0.25微米工艺,选用了目前代加工厂主流的0.18微米工艺。做出这种决策不是盲目地碰运气,而是通过与硅谷许多有经验的工程师深入调研分析流片成功的可能性后做出的,从某种意义上讲,这也是利用了“后发优势”,“借树开花”。所谓“一步到位”,当然不是指第一次设计就做出性能超过P4的CPU,而是针对当时国内有些单位还在启动研制386、486的形势,要求我们在微体系结构上有创新,用国际先进水平的体系结构实现64位浮点运算,尽可能实现技术上的跨越式进步,而不是从模仿20世纪80年代技术开始一步一步爬行,并且一开始就强调正向自主设计,不采取解剖别人芯片反向设计的路线。“一步到位”的另一层意思是不做供鉴定用的实验室样片,而是要确保万无一失,经得起产品检验,做成可批量生产的芯片。经过一年多努力,龙芯一号达到了预期目的。 我们真正期盼的跨越式进步的标志性产品是龙芯2号。我们在设计龙芯2号时,已分析了Intel P4、Sun SPARC、HP的Alpha、IBM Power4等多种主流芯片的微体系结构,要求龙芯2号的体系结构有自己明显的特色,以最有效的方法实现四发射,即一时钟周期可同时执行四条指令(P4实现了三发射),而且要为下一步研制超线程CPU和多处理机CPU打下基础。计算所与在美国参加过千万亿次计算机研制的高光荣教授共同成立了先进计算机联合实验室,重点研制多线程机制,争取实现几十个甚至几百个线程并行操作。这项技术各大公司还在研究之中,我们将争取以跨越的技术进入国际前列,在龙芯3号、龙芯4号中采用。 我们主张的跨越式发展还体现在我们对微处理器发展趋势的理解与判断上。国人对于CPU和操作系统有特殊的感情,把这两者称为信息技术的核心技术。实际上随着Interent普及与发展,人们心目中的P3、P4之类的CPU和Windows之类的操作系统的地位正在不断下降。在向科学院领导申请知识创新重大项目时,我曾说过,龙芯微处理器的目标不是传统的“CPU”,而是“DPU”,即Distributed Processor Unit。所谓中央处理器是针对过去的大型计算机取的名,随着网络存储和各式各样的通信与终端设备直接上网,微处理器将分布在各种设备中。以后计算机、通信设备(如智能化的路由器等)和信息家电的界限越来越模糊,新一代的微处理器和现在PC机上的CPU将会有很大区别,创新的空间很大。中国的芯片设计要跨越发展,可能要通过软件和算法的突破来弥补硬件加工的不足。系统设计人员在芯片设计产业中将扮演十分重要的角色。总之,我国的芯片产业不能再走PC产业走过的以组装为主的老路。如果只重视附加值很少的低端芯片或主要用别人的IP“组装”低端SoC芯片,前途不会太美好。 二、通用与专用 我国CPU的研制尚未真正开展起来,863计划集成电路重大专项的高性能CPU项目还处在软课题研究阶段,但关于重点支持所谓通用CPU还是嵌入式CPU的讨论已经进行多次,不幸的是谁要是讲想做通用CPU,马上就有人反驳:你想赶上Intel P4?这肯定不可能,还是先做点电表控制芯片、身份证卡吧。国外公司研制芯片只关心市场有没有需求,不会先浪费时间论证应该做通用还是嵌入式芯片。从各个芯片公司的网页上我们只会看到各种型号芯片的介绍,看不到他们将芯片分成通用和嵌入式。 从语文的角度上讲,“通用”的反义词是“专用”不是“嵌入式”。所谓嵌入式CPU是指安装在不是计算机的路由器、手机、电视机、汽车等设备上的CPU 芯片,而装在PC机、笔记本电脑、工作站、服务器上的CPU一般称为通用CPU,因为它能执行各种各样的程序。嵌入式是CPU的一种应用,一般只要求运行某种确定的程序,很多场合的嵌入式应用都要求低功耗,特别是像手机、PDA这类手持移动设备,低功耗意味着充一次电可运行更长时间,因此,低功耗应用追求更高的MIPS/W(每瓦每秒百万指令),而不是MIPS数。好的嵌入式芯片,如IBM PowerPC750FX每瓦的MIPS数比Intel P4(2.4G)高10倍,但从芯片的指令系统和体系结构而言,所谓通用CPU和嵌入式CPU并没有本质区别。不论是通用CPU还是嵌入式CPU,只要是低档产品都容易做而高档产品都难做。要特别强调的是所谓嵌入式芯片五花八门,但大都采用通用的CPU核,如MIPS核、ARM核等,从这个意义上讲,通用 CPU和嵌入式CPU技术上是完全相通的,不存在只能选其一的问题。 在集成电路的发展历史上,芯片产品在制造与使用的对立统一中发展,随着半导体产业的景气循环,总是沿着通用与专用循环往复不断进步。天同证券公司在网上发表了一篇“半导体产业行业研究报告”,对通用专用芯片交替发展做了一些分析,本文下面引用该文的分析结果。1959年仙童公司推出第一个硅平面晶体管商品,开始了芯片产品第一个通用循环周期。其后不久仙童公司又推出面向计算器、电视机的专用标准构件,标志着IC产品进入第一个专用循环周期。20世纪 70年代Intel公司开发成功微处理器芯片,使IC产品上升到一个新的通用循环。20世纪80年代设计工具的发展推动了一个产品满足一个用户要求的专用集成电路(ASIC)的发展,使IC产品进入高一级的专用循环。20世纪90年代初,又发展出了可编程门阵列(FPGA),用户可进行软编程反复改变硬件功能,又进行新一轮的准通用循环。随着ASIC技术的积累,IC开始向片上系统(SoC)发展,SoC实质上是更高一级的专用系统。随着通用-专用模式的交替发展,硬件软件的界限开始模糊起来,IC设计进入了基于可重用知识产权(IP)库的设计阶段。 IC发展历史已表明,通用CPU是IC技术发展的源头。从几年前开始,最先进的IC制造工艺首先在通用CPU上使用(过去曾经是DRAM)。如果我们不敢碰通用CPU,就只能永远跟着别人走。在2000年计算所酝酿研制CPU时,我们曾反复讨论过是买MIPS或ARM CPU核,针对某个应用做点外围电路,还是自己做一个有自主知识产权的MIPS CPU核或类似ARM的CPU核。我们的结论是没有自己CPU核的芯片产业就如同没有CPU的PC产业一样,而研制通用CPU是形成有市场竞争力的CPU 核的重要途径。因为一个好的CPU核必须经过多种应用的考验,单独为汽车控制等应用做一个较专用的CPU难以扩充成较通用的CPU核。 从网络信息安全的角度出发,我国也需要有自己的通用服务器CPU。服务器相当于电网中的发电站,一旦服务器受到攻击,将会造成大范围的网络瘫痪。服务器的用量少于终端(美国服务器的销售额约为PC机的1/3),但服务器CPU作为涉及国家政治、经济、信息安全的核心技术一定要掌握在自己手里。在龙芯CPU研制时,从硬件设计上采用了防止缓冲区溢出攻击的新技术,可以防止大多数黑客和病毒攻击(即使软件有漏洞也能防攻击),并申请了10项发明专利。龙芯一号流片成功后,曙光公司很快就推出了基于龙芯一号的龙腾服务器,尽管其性能只相当于四五年前的PC服务器,但其与众不同的高安全性对政府、金融、国防等部门用户会有吸引力。 通过以上分析,我们的结论是我们应重点发展量大面广的芯片设计,即较通用的嵌入式芯片,同时要重视高安全性的服务器CPU芯片设计。形成较通用的嵌入式CPU核的一条可行途径是从设计通用CPU入手。通过应用实践再适当裁剪通用CPU比从专用CPU开始不断扩充更合理。虽然国内对低端微控制器芯片仍有一定需求,但从海关统计数字来看,不论是CMOS芯片还是其他数字集成电路,大多数进口芯片是0.25微米以下工艺生产的芯片。是否在落后工艺下生产量小面窄的嵌入式芯片应由企业自己判断决定,国家不能采取只要是嵌入式芯片就支持的短视政策。 龙芯一号CPU研制体现了我们制定的发展战略,一个多月来十多种应用轻松移植,表明龙芯CPU既是一种较通用嵌入式芯片(功耗小于0.5W)可用于网卡网关、网络终端计算机(NC)等,同时也是高安全性的服务器芯片,可用于网络服务等。明年一季度,基于龙芯一号的SoC芯片将问世,更适合于做NC和网络设备。 剩下的一个问题是我们究竟做不做与Intel兼容并与之竞争的通用CPU芯片。我们的意见是暂时不做。我国舆论界有一种误导使许多老百姓认为“信息技术主要是PC机,PC的核心技术是P3、P4芯片,芯片的高技术是高主频。”实际上PC用的CPU只占微处理器数量的1%左右,但销售收入有200多亿美元,占全球1500多亿美元IC总收入的15%左右(有机构统计,PC用IC占IC总市场的30~40%)。PC芯片的高收入高利润是多年来Wintel 联盟的“功绩”,我们暂时不具备实力与Intel比高低。在未来的发展中,各种Internet Appliance(所谓IA产品)增长势头明显大于PC,据IDC公司预测2002年IA产品销售数量将达到1.8亿台,超过PC机销售数量。PC机本身也在变化,用户未必希望PC机主频3G、4G这样升上去。因此我们不能固守“通用CPU=P4”这种思维模式。 三、兼容与另起炉灶 龙芯一号启动时,最重要的决定是要不要与国外主流系统兼容,如果要兼容与哪一家兼容?有人认为选择芯片指令系统是一个政治问题,是受不受制于人的问题。我们则认为,在全球经济一体化的形势下,我们要抛弃所谓“完全自主知识产权”的旧观念,世界上几乎所有芯片公司的产品都是“你中有我,我中有你 ”,连Intel公司都要买别人的IP,为什么刚刚起步的中国IC设计产业就必须全用自己的IP?兼容不兼容完全是市场行为,是我们根据推广龙芯CPU的市场需要决定的。应当说作出必须兼容的决定在很大程度上受到曙光服务器成长过程的启发。曙光一号服务器和曙光1000大规模并行机开始走的是一条不完全兼容的路,我们在AT&T Unix和Mach OS基础上分别研制了自己的并行操作系统。尽管符合POSIX标准,有自主知识产权,可以得国家最高的科技成果奖励,但数据库厂商和第三方应用软件厂商不愿意花功夫为曙光机移植软件,曙光机只能卖给自己有源程序的用户,市场上成千上万种应用软件用不上。冷酷的事实教育了我们,为了充分发挥后发优势,利用已有的巨大软件资源,与主流系统完全兼容是迅速扩大市场份额的良策。我们相信推广龙芯CPU将会遇到与曙光服务器同样的问题,因此毫不犹豫地选择了兼容道路。 经过对X86、PowerPC、MIPS、SPARC等多种指令系统的仔细分析,我们最终选择了MIPS指令系统、在这一选择中,唐志敏研究员起了关键作用。唐志敏研究员是计算所年轻的博士导师、863计划计算机主题专家组成员,也是龙芯CPU课题负责人。他在体系结构方面造诣颇深,对各种RISC指令系统做过深入分析后,认为选用比Alpha功能强又比PowerPC简单的MIPS指令系统具有较好的可行性。选择MIPS指令系统的更重要的原因是出于市场考虑。MIPS公司不同于Intel、SUN和IBM,它不是IDM公司,自己并不生产销售芯片,而是以卖License和服务为营业范围,它不但不像Intel公司那样反对别人做兼容芯片,而是支持其他厂家做MIPS兼容芯片。世界上许多大公司,如生产路由器的CISCO、生产游戏机的SONY等都采用MIPS指令系统。MIPS芯片不仅用于SGI公司的高档工作站与服务器,而且是主流的高档嵌入式CPU,每年MIPS芯片销售量超过7000万片。市面上已有大量MIPS应用软件,龙芯一号流片成功后许多整机厂商一小时内就装上了应用软件,充分证明我们的决策是正确的。 与兼容策略相关还有一件大家十分关心的事,那就是如何避开专利。国内有些专家认为芯片设计专利是我们难以逾越的障碍,我们有些决策者也对此忧心忡忡。专利的确是我们必须高度重视的技术障碍,但也不能把专利看成拦路虎,长他人志气,灭自己威风。我们在研制龙芯一号过程中查阅了所有有关专利,我们发现指令系统本身不是专利,而且几乎没有一项概念性的专利,例如Cache技术、多发射技术等,所有专利几乎都与具体实现技术有关。我们设计CPU是先通过译码器变成自己定义的统一中间代码,所有的功能部件执行中间代码,与原来的指令系统无关。所以对我们而言,回避专利与采用什么指令系统没有关系。我们在设计中没有侵犯任何专利而且自己申请了十余项发明专利。今后做全定制设计,除了我们自己设计一些关键的宏单元外,一定会购买一些IP使用权,包括一些专利使用权。在IC设计中这是十分正常的。今后我们自己的专利与IP越来越多,通过Cross Licencing共享互用IP和专利是必由之路。与计算机产生一样,IC产业的横向分工越来越明显,IP(包括专利)将是IC设计厂商的主要产品,我们要学会如何买卖IP不要谈“专利”色变,作茧自缚。 还有一种看法是认为采用别人的指令系统说明没本事,还不掌握CPU核心技术,不如另起炉灶自己定义指令系统的单位水平高。实际上学过计算机原理与系统结构课的人都知道,自己定义一套指令系统并不是难事。40多年前,计算所就开始自己定义指令系统,几十年来计算所研制的十几种计算机都是自己定义指令系统。一个好的指令系统要经过大量应用反复考验修改才能成为市场接受的主流系统。如同大家用C、VB、JAVA编程序,没有人强调非要自己定义一种语言编程一样,研制CPU的水平并不在于是不是自己定义指令系统,谁能占领市场才是真本事。 四、IC设计的科研与产业化 龙芯一号研制成功后,马上面临研制更高性能的龙芯2号与尽快将龙芯一号产业化的矛盾,这与当时研制曙光机的情形十分类似。我们决不能只以不断研制出新的CPU为目标,置产业化于不顾。在科研人员中要树立一个观念,龙芯一号卖不出去,研制出龙芯2号也没有多大意义。计算所的科研人员已做了计划,全力配合神州龙芯公司打开市场,龙芯1.1、龙芯1.2两款SoC产品的优先级放在龙芯2前面。神州龙芯公司也在大力开拓龙芯CPU的应用,争取较多的定单。我们的体会是在研制龙芯CPU时,为国分忧的激情是一股强大的动力,胡伟武研究员几篇关于龙芯研制过程的文章催人泪下,表明年轻一代科研人员像两弹一星研制人员一样有着高尚的爱国情操和顽强的拼搏精神,计算所有这样一批又红又专的人才才能做出让人眼睛一亮的成果。如果我们一味等待国外的高手回来才开始研制,恐怕今天龙芯CPU还只存在于希望之中。另一方面,根据我们推广曙光机的经验,我们不能把产业化的希望寄托在用户的爱国热情中。CPU虽然是涉及国家安全的特殊产品,但卖产品就是卖产品,不能加上过多政治色彩,必须靠产品本身的可靠性、高性价比和出色的服务取得用户的信任。从某种意义讲,推广龙芯CPU是比研制CPU更艰苦的一场战斗。较通用的嵌入式CPU的用途很广泛,不一定非要性能超过P4才能卖得动,266M 0.5W功耗的MIPS兼容CPU芯片一定有它对应的广阔市场。国家在开始推广国产CPU时做一些扶植是必要的,但关键在自己努力。我们有信心比推广曙光机做得更好,让国产CPU尽快在市场上占有一席之地。 | |
 (4个打分, 平均:4.25 / 5) (4个打分, 平均:4.25 / 5) |
龙芯CPU(5)–再说我们的CPU
作者 陈怀临 | 2009-04-26 06:25 | 类型 专题分析, 中国龙芯 | Comments Off
系列目录 中国龙芯CPU的调查与研究
【编者注:这篇文章是胡伟武在2001年在发表第一篇文章《我们的CPU》后,对网络上许多讨论的答复和一些感想与解释。事情也都是在龙芯1号流片之前。】 没想到《我们的CPU》在网友中引起了一些讨论。我写这篇文章的本意之一是怕一些新闻机构报道时说得不够准确而挨同学或网友的骂,自己把这个事情说清楚挨的骂会少一点。现在看来,这个目标至少部分地达到了。但我没有想到大家对我们自己的CPU如此热心,使我觉得我们不是在孤军奋战,增加了信心。我对网友意见的重视不亚于对鉴定委员会意见的重视,专门让一些学生收集这些意见并进行分类,并在组内告戒对于网友的意见,”有则改之,无则加勉”。因为好多网友是真正在第一线工作的人,是真正把握国际前沿的人。鉴定委员会的意见也很重要,一者他们都是国内专家,二者没有他们的支持,我们都会饿死。这就好比我们写文章得有人审稿一样。 我说过,我们现在做的工作不多,实在不值得写太多的东西来宣传或挨骂后进行解释。但从网友的讨论中,我得到很多启发(很多网友提了很多很好的建议),我想到可以利用网友的智慧一起来推动这个事情。 不管对我们的工作支持的也好,反对的也好,有两点是一致的。一是对我们自己的CPU非常关心,二是对中国科技界目前的浮躁现象深恶痛绝(这其实很难怪科技工作者,这是从上到下全国的风气)。 对于那些对我们的工作加以鼓励的人,我要深深地感谢。看得出来,有不少是行家,功底很深厚。我们一定会继续努力,争取早日投片成功。有些网友提了很好的建议(包括不少技术上的建议),我们会用在我们下一步的工作中。有些网友表示,只要我们投片成功,达到PII的水平,他们愿意用PIV的价钱来买我们机器。对他们除了感谢外还有致敬,我把他们看作我们的朋友。并请他们不要食言,因为我是玩真的。 有一位网友提了很好的建议,让我们开放我们的设计,这个主意很好。只要所里不反对,我肯定开放源代码,至少是C模拟器的源代码,请大家一起帮我们做设计。当然,开放之前,还要加一些东西,因为我写程序没有注解。 有不少网友提到这个和美国研究生的”大作业”有什么区别。这个区别是很大的。想一想,有没有美国的高校把一个双精度、全流水、符合IEEE 754标准的浮点运算部件作为一个”大作业”让学生做,而这只是我们十几个模块中的一个模块(当然是较大的一个)。顺便提一下,我们的浮点运算部件用的算法比较新,是九十年代末提出的。我可以给大家提供一个C程序,用这个程序在PIV的机器上能测出它不符合IEEE 754的地方(这究竟是处理器的问题还是程序或者编译的问题也欢迎行家分析),而在我们的机器上测不出来。另外,说到大作业,我们现在也正准备开一些这方面的课,让我们的博士生做一些大作业,其中一项就是做一个实现MIPS I的指令系统的CPU,或者写一个完整的嵌入式操作系统。其实我在文章中提到我在科大本科论文做8086就是想传递这样一个信息,做CPU设计并不难,本科生就能做,难的是要做好。如果真的是一个大作业,用得着我领着几十个人干吗?至少我的科大8611的同学和以前对我做的软件DSM系统JIAJIA有所了解的同行知道我不是白痴。我的课题组中高手很多,不少是能独当一面的,其中有对Linux内核非常熟悉的,也有工程经验非常丰富的。 关于媒体的报道中关于我们CPU的评价,不管别人怎么说,自己觉得在通用CPU设计方面处于国内领先,和在动态流水线设计上达到国际先进水平还是比较确切的。如果我已经做了多发射和对CACHE作了改进,我还敢说在通用处理器设计方面达到国际先进水平。在动态流水线方面(针对我们的结构)可以说已经接近一个极至,很难再有很大的提高。动态流水线的核心是要解决各种相关,如数据相关、控制相关、例外相关等。做到后来,我们的结构有点象数据驱动或事件驱动,即译码或发射时只是在指令中建立互相的相关关系,并不解决相关,指令到达最后关头才等待(再多走一拍就会出错了)所需的数据或事件,一旦该指令所等待的数据或条件准备好,马上继续前进。至于其中的创新,结构上的大创新是没有的,但具体实现上的一些技巧还是有的,有几点我自己非常得意。记得 Henessy(还是Patterson?)曾经说过,把90年以后所有关于Architecture方面的文章都烧掉,对Architecture的研究没有任何损失。其实,如果大家仔细分析分析一些通用CPU的结构,如Alpha, MIPS, PowerPC, PIV等,发现确实是大同小异,取舍不同而已。我这样说是因为我们最近已经对这些处理器的结构做了较详细的分析和比较。 有些网友对我们的设计在技术上提出了不少建议,尤其是关于CACHE的重要性。关于CACHE,我们是非常重视的,因为我在做DSM时用过除了Alpha工作站以外的几乎所有厂家的计算机,对CACHE对性能的影响是有深刻体会的。在我们投片时容量肯定会增加,组织方式也许会做到二路组相联。不过,CACHE设计是很复杂的,尤其是做non-blocking的CACHE设计更复杂,我们现在最关键的是要投片成功,所以为了保持控制简单我们在CACHE方面不会太 aggressive,好多优化方法可能在目前的阶段不会用。例如,为了做2路组相联,连线会增加很多,而在深亚微米的工艺中连线复杂性和延迟是最主要的。我们目前关于CACHE的预研正在进行,也有一些新的想法。关于多发射,我想以后做到双发射就行了,因为RISC结构现在越来越复杂,做到4发射已经有点违背RISC提出时的初衷。为了提高性能,超流水、多线程、片内SMP等技术倒是我较看好的,上次我提到过,希望做几十个CPU的大SMP结点。当然有好多关键技术没有解决。我对Deleware大学高光荣教授的EARTH技术比较感兴趣(这几天高老师正好在计算所跟我们交流)。自己作了这么多年并行处理,希望以后用户不用并行编程就能用并行机。如果大家觉得上述技术思路有问题,欢迎大家讨论,因为这种决策对于我们是至关重要的。 至于有些人担心我们自己虽然能做设计但生产不了。我想说的是中国目前最缺的是设计,国内最近化了很多钱组建了或正在建不少生产线,0.35, 0.25, 0.18的都有,关键是没东西可以生产。的确,以前是由于生产不了而导致设计队伍垮掉,但现在不同了。此外,ASIC设计很见工夫,象Alpha 21264在0.35的工艺上能做到600多MHz的主频,我看我们最多能做到200MHz就很不错了,这些东西的确是需要积累的。 对于有些觉得凡是中国人做的事情就”[censored]“, 觉得自己的同胞肯定不如洋人,或没有仔细读我的文章就恶意攻击并以此为乐的人,用先人的两句诗奉送:”汉人学得胡儿语,便向墙头骂汉人”。但如果他们能够做到如下两件事情之一,我愿意在我们够得到的所有BBS上向他们道歉,并承担一切费用请他们回来向他们请教。第一件是在两个月之内单独完成一个单双精度、全流水、符合IEEE 754标准的浮点部件的逻辑设计,要求完成除了除法、开方以外的MIPS III指令系统的所有浮点运算。第二件是在我们的处理器中有四条MIPS的地址不对齐的访存指令(LWL,LWR,SWL,SWR)没有实现,处理器碰到它们时产生一个保留指令例外并由操作系统软件模拟,要求一周之内修改LINUX内核完成这一功能。第二件事情做起来并不难,但得知道修改LINUX的什么部分,以及当模拟的指令是转移指令的延迟槽指令时的特殊处理,还要保证核心态发生的保留指令例外处理不影响系统的稳定,此外,由于例外处理是在核心态,要注意别留下安全隐患,使非法用户有机可乘。如果把我们的GodSon比喻成在美国的一个学期的大作业,那么上面的两件事应该在一个星期之内完成. | |
|
(2个打分, 平均:5.00 / 5) |