苹果宣布,iPhone支持应用内支付
作者 青成 | 2009-10-26 15:54 | 类型 移动和设备 | Comments Off
|
苹果刚刚宣布,最新的iPhone SDK支持应用内直接购买升级或者支付其他物品的功能。对于在iPhone上开发者来说,这是个改变游戏规则的新闻。对于用户来说,体验也会随之提高很多。 在这之前,iPhone应用通常会有一个试玩版和一个收费版。用户肯定了试玩版之后,需要再次下载收费的完全版才能得到全部体验。对于开发者来说,这是个不得已的办法。如果一个游戏有10级,那么试玩版里放几级才能最优化的吸引更多的玩家,并且又能保持完全版的神秘呢?另外,对于很多内容类的应用,比如书籍、音乐、视频,这种购买方式非常繁琐。而且,整个网上商店的搜索和用户点评等也不能作出这类应用的专门优化。 现在,这些问题都得到了解决。游戏开发者可以提供一个免费的游戏,而里面可以按照每一个级别收费,或者按照武器等虚拟货物收费。而电子书商可以发行一个应用,来管理所有自己发行的书籍。期刊发行商业可以按照每个月份或者发行时间来收费。无论是开发、销售还是维护都简便的多。 | |
 (2个打分, 平均:5.00 / 5) (2个打分, 平均:5.00 / 5) |

Tilera发布多达100个core的芯片–TILE-Gx
作者 陈怀临 | 2009-10-26 15:46 | 类型 行业动感, 通讯产品 | 54条用户评论 »
|
TILE-Gx100可支持多达8个XAUI。XAUI就是一种10G的以太网(Ethernet)网络接口。 另外,TILE-Gx含有4个运行在2133MHz的DDR3控制器。这个比较狠。
TILE-Gx会比较好的适用在中高端的Layer-7的网络设备中,例如,防火墙,VPN和所谓的深度检测等。 但其问题是,在TILE芯片里面,没有什么高级加速器,例如DFA Lookup,压缩和解压缩,Packet Ordering Engine等等。 换言之,如果用TILE芯片,而且还想要其他的硬件加速,可以通过其PCI-E的接口把加速卡挂上来。 当然,如果4个DDR3的System Bus够用了,软件做足够快的话,就不需要什么加速卡了。能做到80G的一个系统,应该已经不错了。例如,通过两个TILE-Gx100,就可以做到160G,通过PCI-E挂到一个高速的控制平面上。就是一个很山寨化的网络系统了。 另外,网络逻辑部分也可以被config(设置)为2个40G的Interlaken接口。许多读者不太了解interlaken是个啥东西。总之,就是为了讨好思科,舔思科的屁股沟(butt)的一个战略举措。例如,在ASR1000的体系结构中,内部的Interconnect就是interlaken 。反正,与思科的东西能集成在一起,这是一个好事情。这年头,即使MIT的的大牌教授(Tilera的创办人,又是印度人)也得看有钱人John Chambers的脸色行事。 之前,《弯曲评论》介绍过Tilera和TILE-64的一些细节。可参阅:Tilera公司与其64核芯片Tile64系列简介 | |
|
(2个打分, 平均:5.00 / 5) |
 今天,
今天,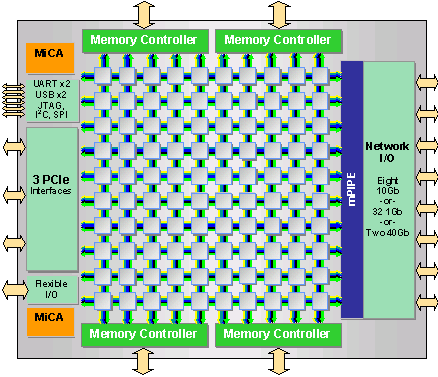
海外学人-习宏伟教授
作者 杰夫 | 2009-10-26 10:37 | 类型 人物评述, 海外学人 | 5条用户评论 »
|
习教授的研究领域包括编程语言,类型理论等。点击这里进入习教授主页。他的联系地址是: Hongwei Xi Computer Science Department | |
|
(4个打分, 平均:5.00 / 5) |

中国(2009)Linux内核开发者和Hello GCC WorkShop大会资料
作者 陈怀临 | 2009-10-25 19:02 | 类型 弯曲推荐, 科学与中国, 行业动感 | 13条用户评论 »
|
主题:Linux 10GbE Development 主讲人:Herbert Xu 主题:Linux中的页面缓存与替换 主讲人:吴峰光 主题:Linux内核性能跟踪和优化 主讲人:张衍民 主题:Git Tutorial 主讲人: Eric Miao 主题: Linux IO控制器 主讲人:归剑峰 主题:File Level Snapshot – reflink 主讲人:马涛 AKA 2008 第三届 Linux 内核开发者大会演讲者PPT下载: 主题:Linux下的快速启动和待机 主讲人:张锐 主题:SMP implementing on Blackfin561 主讲人: Graf Yang 主题:内核面向多核的可扩展性性能分析与优化 主讲人: 陈渝 崔岩(清华大学) 主题: new multi-queue 主讲人: Herbert Xu 主题:资源管理--cgroup 及 子系统 主讲人: 李泽帆 主题: Linux 中的页面回写队列 主讲人: 吴峰光 主题:龙芯 Linux 内核的移植和优化 主讲人: 张福新(龙芯) 另外, HelloGcc Workshop 2009 大会资料如下: 主题:使用 GCC 编译器分析和优化程序的数据局部性 主讲人: 袁鹏 主题:GCC Internals and Porting 主讲人: 邢明杰 主题: GDB reverse debug and process record and replay target 主讲人: 朱辉 | |
|
(5个打分, 平均:5.00 / 5) |

Aresta Networks 。数据中心 。云计算
作者 陈怀临 | 2009-10-24 13:37 | 类型 初创公司, 行业动感, 通讯产品 | 75条用户评论 »
|
Aresta Networks是一家为数据中心提供云计算基础设备的初创公司。他们的产品目前是10GBps的Datacenter Ethernet switches。也就是说,是一个为数据中心而设计的以太网交换机。显然,事情的重点不是端口,一切的精华在于他们的软件–EOS。当然EOS不是一个简单的东西,似乎是一个把数据中心内部虚拟化等等呢个东西都考虑进去的一个东东。 至于为什么说Aresta的交换机和EOS软件系统就更适合于数据中心。读者自己去判断。但是如果看了其创办人和目前的管理团队,确实会觉得Aresta is something。 Aresta的创办人谦逊的个人简历如下: Andy Bechtolsheim:公司目前的CTO。他曾经创办过一家公司叫做Sun MicroSystems。前些日子这家公司被Oracle收购。希望读者们除了巨大中华,也碰巧听说过Sun这家公司。Andy其他的业绩似乎还很多。但似乎都没有必要说了。 David Cheriton:公司目前的首席科学家。斯坦福电子工程系教授。这似乎就够了。他曾经与Adny在一起忽悠了一个公司叫做Granite Systems并在1996年卖给了思科。卖了2亿多美金。从此思科在Switch方面才成了老大。 David自己还身体力行,做思科Catalyst 4×00产品线的首席芯片设计师。 David目前还是Google, Vmware, Tibco, Cisco 和 Sun等等公司的顾问。 Ken Duda:公司目前的软件研发副总裁。当年Granite的第一个工程师。MIT毕业后,投靠斯坦福。显然是David的博士。现在与老师又在一起混。 读到这里,感觉如何?是否比你身边的人要狠一些? 再来看看谁是CEO?答案是:一个印度美女! Aresta的创办人都是斯坦福,MIT等精英人才。大家看了除了郁闷也没有其他办法。您说你非要于前Sun Micro的创办人闹别扭,比优秀,您一定是心理有问题不是?但Jayshree确实是一个英雄不问出身的又一典型。基本上可以与思科目前的CTO也有一拼。另外,大家知道印度人确实比中国人更能混了吧? Jayshree从旧金山州立大学获得本科文凭,从位于硅谷的Santa Clara University获得了她的硕士文凭。 下面是Aresta目前的产品一览:
| |
|
(5个打分, 平均:5.00 / 5) |
 如果您在Cisco,Juniper,Ericcsion等上班,除了IP Header的格式比较熟悉之外,Google,Facebook和twitter的那套东西,例如php编程,mySQL都不会,今天想换一个工作,而且想去startup,为了老婆孩子和房子,拼一把,陈首席推荐一个公司–
如果您在Cisco,Juniper,Ericcsion等上班,除了IP Header的格式比较熟悉之外,Google,Facebook和twitter的那套东西,例如php编程,mySQL都不会,今天想换一个工作,而且想去startup,为了老婆孩子和房子,拼一把,陈首席推荐一个公司–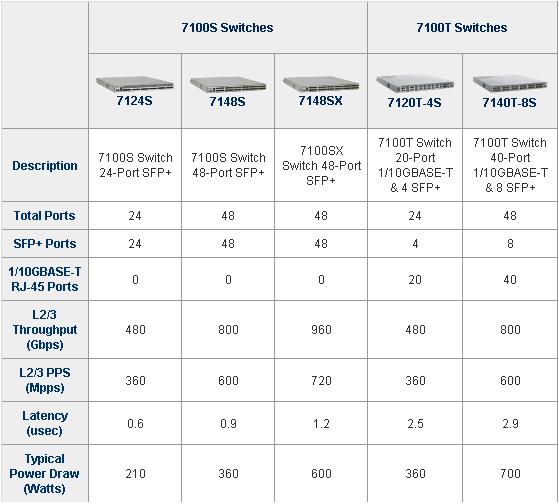
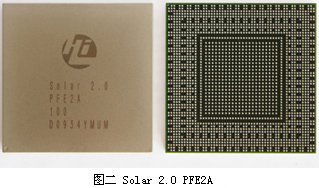
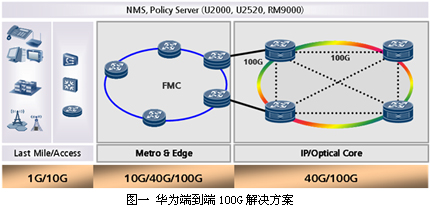
浅谈华为Solar 2.0 PFE2A
作者 陈怀临 | 2009-10-24 10:49 | 类型 弯曲推荐, 行业动感 | 34条用户评论 »
|
华为NS5000E的100G解决方案宣布以后,技术爱好者都非常希望知道其技术内幕。但华为一向对技术细节保密的非常严格,很难找到比较细的细节。本文一定有许多错误之处。但试图抛砖引玉,引起技术爱好者的讨论。 华为的100G的转发芯片在其网站上有一些简单介绍。下面是从华为数通下载的图片。
从芯片的“Hi”标记,应该是海思公司的意思。这可真是比思科和Juniper等都牛叉。一个100G的,看得见,但摸不着的芯片。华为网站上是如此评价这个业界首款100G芯片的“业务灵活性,高性能和低功耗的完美融合:Solar 2.0 PFE2A采用了华为独创的宏指令包处理(MIP,Macro Instruction for Packet Processing)技术。它专为IP/MPLS/ETH应用设计,结合了网络处理器业务灵活和ASIC性能高,功耗低的优点,同时规避了网络处理器处理性能低,功耗大以及ASIC无法支持新业务的缺点,加上其独特的外围器件低功耗一体化设计,实现了业务灵活性,高性能和低功耗的完美结合。”
另外,华为给出了一个100G线卡的逻辑图。
“华为100GE线卡采用两片Solar 2.0 PFE2A作为转发引擎,一片处理100G上行流量,另一片处理100G下行流量。这种设计理念将Solar 2.0 PFE2A的能力发挥至极致,保证了100G流量的线速转发(如图五所示)。PIC(Physical Interface Card)模块基于自研的可编程100GE MAC芯片,支持IEEE 802.3ba、S-Eth、IEEE 1588v2以及ODU4标准。内置的oTM(output Traffic Management)引擎,完美实现下行流量的5级H-QoS(Hierarchical QoS)调度。1×100GE线卡具备4M海量FIB(Forwarding Information Base),充分满足IP网络持续扩展的需要,并且100GE接口支持CFP MSA(Compact Form Factor Pluggable Multi-Source Agreement)封装,实现光模块的即插即用。 ” 从上述逻辑图中,可以看出PFE2A与思科CRS-1线卡结构类似,都采纳2颗转发引擎 (PFE:Packet Forwarding Engine)。一个做Ingress(位于上面的那个PFE2A);一个做Engress(位于下面的那个PFE2A)。思科CRS-1的SPP和ASR1000的QuantumFlow里面采用的都是Tensilica的Xtensa的CPU核。SPP为180多个核;QuantumFlow是40个核。华为的PFE2A里面是什么没有任何透露的消息。从各方面分析,应该是其40G线卡解决方案中的588芯片的升级版。换言之,Solar2.0就是588+–SD5822 ASIC处理器,具备上下行各40G的处理能力。与Solar 2.0挂在一起的MEM就是大量的DRAM和包括TCAM,这都是为了做Routing Lookup FIB的东东。 PFE2A里的TM(Traffic Manager)为5级的H-QoS,思科的ASR1000的QuantumFlow里面也是把TM集成在一起的。QuantumFlow是支持3级的 QoS。一共是128个队列。而思科的CRS-1的SPP内部没有TM部件。CRS-1的线卡是通过另外两个ASIC(Ingress Queuing和Engress Queuing)来实现QoS和TM的。线卡上的两个SPP与相应的Queuing芯片互联。 有兴趣思科CRS-1和ASR-1000体系结构的读者可参阅:《思科核心路由器CRS-1的研究(上)》和《思科QuantumFlow处理器及其战略研究》。 通常而言,在Solar2.0里面应该会集成一些On-Chip Packet Memory,例如,报文进来之后,不是被DMA到DRAM中,而是直接被PIC中的DMA引擎打到PFE2A的On-chip Packet Memory里。但目前无法知道华为芯片的细节。其实这也是华为应该改进的地方。不要什么都藏着,捏着,过分的刻意低调。适当的公开一些技术文档是一种智慧,也是一种社会责任。 为什么说在这个PFE2A里一定应该有CPU核呢?这是大势所趋。许多层2,层3的业务只靠ASIC是没法做的,必须要有可编程引擎阵列来做处理,例如思科的SPP和QuantunFlow的结构就是这样。 CP应该是Control Processor,例如是一款PowerPC 之类的控制CPU。从图中那条从CP引出来的暗红色的线,我们可以看到,这就是100G线卡的Local Bus。或者我们有时说叫做控制总线(Control Bus)。图中的暗红色的线通常应该是PCI Bus或者PCI-E。PCI天生是一个最好的Local Bus。只要PCI总线上一挂,对于主控CPU而言,任何一个设备或芯片,例如PFE2A,CFP,PIC/Mac,都只不过是一个Memrory Mapping Based的一个地址空间。任何一个芯片的控制寄存器,数据寄存器都可以被CPU的监控程序READ和WRITE。100G线卡的一切其实都是这个CP点亮,把驱动也好,微码也好,宏代码也好,从NS5000E的控制平面拿下来,并且安装在线卡的各个环节。然后系统开始接受数据报文。 图中的宽的,橙色的线,就是所谓的数据路径(Data Path) 。就是一个Packet从进来到出去的一个梦幻人生。。。 在橙色的路径中,一定要牢记一点:每个局部都是>=100G。否则就不能线速。 图的最右边的FIC模块就是华为NS5000E中的Fabric Interface Card,或交换接口卡。 在图的最左边的100G的CFP是一个非常重要的部件和芯片。 CFP MSA(Compact Form Factor Pluggable Multi-Source Agreement)就是一个光网数据收发器。100G的另外一个含义其实就是100G的CFP设计成功了。以前是40G的CFP。这也是Solar2.0线卡中的一个重要技术突破。从而NS5000E可以实现100G的互联对接。
| |
|
(5个打分, 平均:5.00 / 5) |


计算机系统中关于数据处理的基础研究
作者 陈怀临 | 2009-10-23 07:56 | 类型 科学与中国 | 20条用户评论 »
|
【编者注】张晓东教授是我非常敬佩之人。这是朋友推荐的其在国防科大的一个课程讲义。 上次,与一个师弟聊天,说这么多年,张晓东就是不换中国护照,坚持要做国籍上的中国人。张老师的IEEE Fellow是去年评上的,真是姗姗来迟。从我个人的浅薄观点,中国计算机学术界最紧缺的就是张晓东这样的人,除了姚期智老师的计算理论。 张晓东是美国俄亥俄州立大学的 Robert M. Critchfield讲席教授,并担任计算机科学与工程系主任。张晓东于1982年在北京工业大学获电气工程学士学位,1989年在美国科罗拉多大学波德(Boulder)主校获计算机科学博士学位。1997年到2005年间,他在威廉玛丽学院(College of William and Mary)任教授、讲座教授及计算机科学系主任。张晓东是国际电气电子工程师协会(IEEE)Fellow。自1992年以来,在张晓东组建的高性能计算机及软件实验室里,他指导了四十多名研究生、博士生和访问学者。张晓东在高性能和分布式系统领域里,针对几个重要基础研究问题取得了一系列开拓性的成果。他主持研究的一些核心算法和系统设计已经或正在被应用到商业和开放系统软件中,有效地优化或更新了计算机和分布式系统中的一些关键技术。比如,他们的存储地址空间的转换方法已被使用在Sun Ultra SPARC IIIi 商业处理器上和Sun的双核处理器上;Linux 和BSD操作系统,以及几个开放数据库系统 (MySQL, Apache Derby, OpenLDAP)也正式或正在采用了他主持研究的几个存储管理新技术。在2001到2004年间,张晓东在美国国家基金会(National Science Foundation)担任高性能计算与系统项目学科主任。他目前是《美国电气电子工程师学会并行和分布式系统期刊》(IEEE Transactions on Parallel and Distributed Systems)的副主编,《美国电气电子工程师学会计算机期刊》(IEEE Transactions on Computers)、《美国电气电子工程师学会微处理机双月刊》(IEEE Micro) 和《并行和分布式计算学报》(Journal of Parallel and Distributed Computing)的编委。他多次担任国际学术会议程序委员会主席,其中包括∶ICPP’07, WWW’08,和ICDCS’09。 张晓东在中国国家自然科学基金会资助的龙星讲座计划委员会与中科院计算所的徐志伟【注:徐志伟是在USC黄铠的博士。也就是说徐其实是倪明选的师弟。】共同担任主任。龙星计划委员会每年组织一批在美国学术界学有所成的中国教授在中国各地大学系统讲授多门研究生课程。龙星讲座计划开办近十年来,免费向成千上万的国内研究生和青年教师授课,这个课程计划已逐渐成为国内计算机研究生教学和科研的一个组成部分。他还担任《中国计算机学报英文版》执行主编,并受聘为中国科学院首批海外评审专家。 授课教师∶张晓东 美国俄亥俄州立大学,计算机科学与工程系 时间∶2009年7月13日至17日 地点∶国防科技大学,计算机学院,湖南长沙 课程概要和大纲 在计算机系统中,数据的存储、访问和传输已成为阻碍系统性能的主要瓶颈,处理数据的速度远远低于计算的速度,而对数据访问的需求已经成为计算机运行的主要部分。 数据在计算机系统中的存储层次也变得越来越深∶ 从硬件快速寄存器(Registers)到快速存储器(Cache)再到主存的DRAM,通过数据总线,系统可以与各种磁盘,如半导体的固态存储器(Solid State Device)或机械的硬磁盘等。通过互联网,计算机之间还可以进行大规模的远程存储、访问和通讯。计算机系统中的数据处理速度和效率是由两个基本要素决定的: (1)点与点之间的传输的速度;(2)在某点读或写数据的时间延迟。 在过去的20多年里,在计算机的各个不同的联结点之间数据的传输速度,有了很大的提高,但数据访问的延迟却没能够有 效地改善。为解决这一对越来越突出的矛盾,在计算机系统设计和实现中,三种最有效的硬件或软件的方法是:缓存,备份和预取。 这门课以上面提到的三个基本技术为核心,全面介绍计算机各个存储层面上的最有代表性和最先进的数据处理方法。课程安排如下∶ (一) 硬件快速存储器(Cache)的设计与改进 (1) 基本结构 (2) 命中率和访问延迟的取舍 (3) 高命中率和低访问延迟Cache的设计 (4) 多核处理器(Multicore)中的Cache管理 (二) 主存DRAM内局部性(Locality)的挖掘 (1) DRAM缓存区(row buffer)的结构 (2) 在DRAM内局部性丢失的原因 (3) 一种保留局部性的内存地址空间的映射方法 (4) 嵌入Cache 的DRAM的设计与系统应用 (三) 内存和磁盘管理中的核心技术: 替换算法 (1) LRU算法优点以及难以解决的问题 (2) LIRS算法是如何解决LRU问题的 (3) Clock-pro: LIRS是如何实现在操作系统内核的 (4) BP-wrapper:消除替换算法在系统实现中的同步竟争 (四) 提高操作系统对磁盘的管理功能和效率 (1) 操作系统对磁盘管理的局限性 (2) 扩大操作系统的视野去获得关键的磁盘数据存储地址信息 (3) 感知磁盘数据分布的缓存和预取方法以及系统实现 (五) 固态闪存系统(Solid State Device Flash Memory) (1) SSD Flash Memory的结构和性能 (2) SmartSaver: 利用闪存来降低磁盘能耗 (3) SSD的读、写,以及缓存的高效管理 (六) 在互联网和无线网上的数据管理和有效传输 (1) 为什么P2P在互联网上是传输多媒体的一种最有效方法? (2) 数据缓存在无线网上的作用 《数据密集型应用的系统基础》课程讲义 (2a)-SE-P2P.pdf (3)-cache-partition–multicore.pdf (7a)-BP-Wrapper.pdf (10)-C-Burst.pdf (11)-scap.pdf | |
 (12个打分, 平均:4.83 / 5) (12个打分, 平均:4.83 / 5) |
海外学人-陈怡玲教授
作者 杰夫 | 2009-10-22 11:20 | 类型 人物评述, 海外学人 | 5条用户评论 »
|
陈教授的研究领域包括人工智能,计算语言学,和电子商务等。她曾获得2008年ACM电子商务会议杰出论文奖。点击这里进入陈教授首页。她的联系地址为: Yiling Chen | |
 (16个打分, 平均:3.88 / 5) (16个打分, 平均:3.88 / 5) |

世界通信设备大展–SuperComm09
作者 陈怀临 | 2009-10-22 09:39 | 类型 行业动感 | Comments Off
|
今年的Eos SPOTLIGHT AWARD WINNER被Juniper Networks获得。Spotlight Award意思就是最亮眼的,或者最拉风,最牛逼等等的意思。除了最拉风之外,Juniper还获得了其他3个大奖,例如其网络安全路由器SRX5800获得了Technological Innovations奖;Intelligent Services Edge portfolio 获得了best backbone/edge solution;E系列产品获得了ongoing achievement(这个好像没啥意思) 。 读者可参阅2009 SuperComm Eos奖的细节。 来自社会主义阵营的华为公司也参加了展览,并且似乎买单作为sponsor之一。华为的展台号为4424。中兴公司(ZTE)似乎不太尿资本主义的展览,没有参加。很有志气。是,我们不要资本主义的苗:-)。 在思科方面,关于SuperComm09,有一个新闻稿,摘要如下: SAN JOSE, Calif. – October 21, 2009 – At SUPERCOMM 2009 in Chicago, Cisco will highlight a variety of announcements that showcase the continued momentum of the Cisco IP Next-Generation Network (IP NGN) architecture and its technology innovation which help enable service providers to deliver an increasing array of innovative ‘Connected Life’ experiences to their customers. The Cisco IP NGN helps enable service providers to deliver differentiated ‘Connected Life’ experiences to their residential and business customers by integrating voice, video and data to create unique “any-play” service offerings, at home, at work or on the move. The ability to deliver these personalized experiences anywhere, anytime, and to virtually any device, creates a host of new ‘Connected Life’ opportunities for accelerating service provider growth and enhancing customer satisfaction. 从上面我们可以看出,ASR9K,ASR1K系列确实将非常重要。Core pushes to edge。Intelligent moves to edge。 在华为方面,华为深圳总部主页和华为北美Futurewei都没有给出任何新闻关于华为参加SuperComm09的消息。这似乎低调的过分。已经作为Sponsor买单了,为什么不能在公司网站上宣传一下呢? | |
|
(2个打分, 平均:5.00 / 5) |
用搜索引擎看看“没有”
作者 高飞 | 2009-10-21 22:48 | 类型 行业动感 | 10条用户评论 »
|
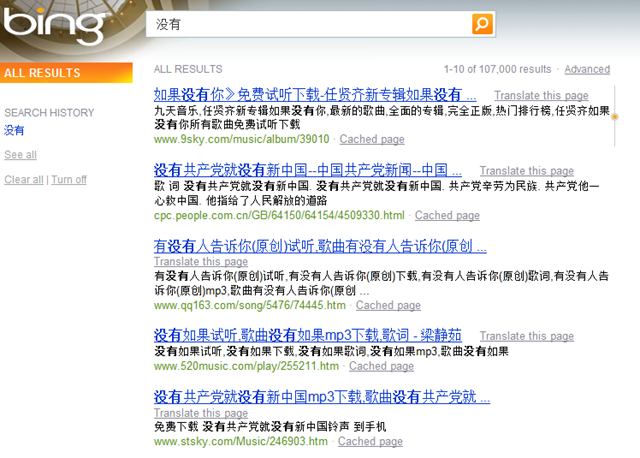
这是2009年10月21日晚上11点42分(加州时间)笔者在各个搜索引擎上搜寻“没有”这个词给出的结果。先看全球老三,微软的必应。真是又红又专啊。
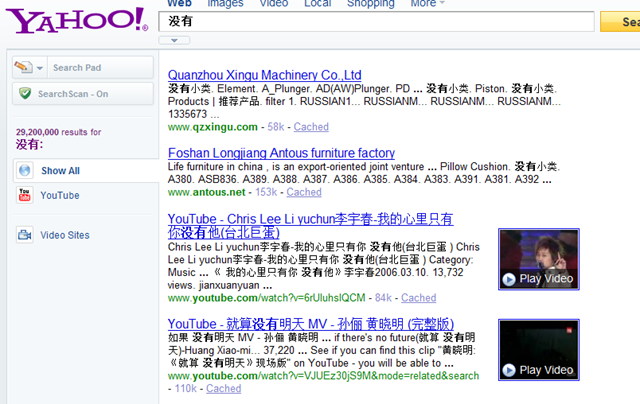
然后是全球老二,雅虎的。时刻不忘八卦娱乐。
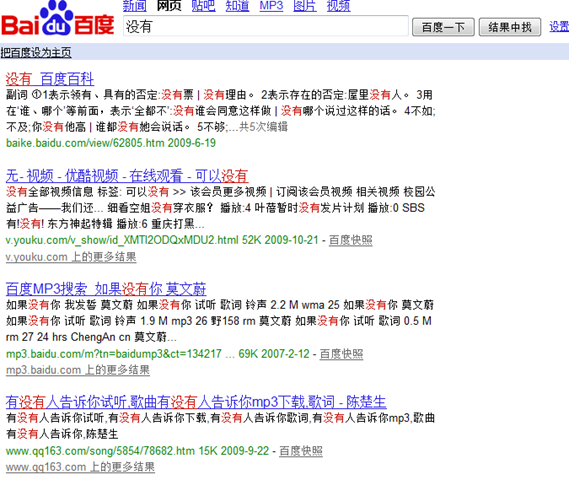
然后是中文老大,百度的。知识外加八卦娱乐。
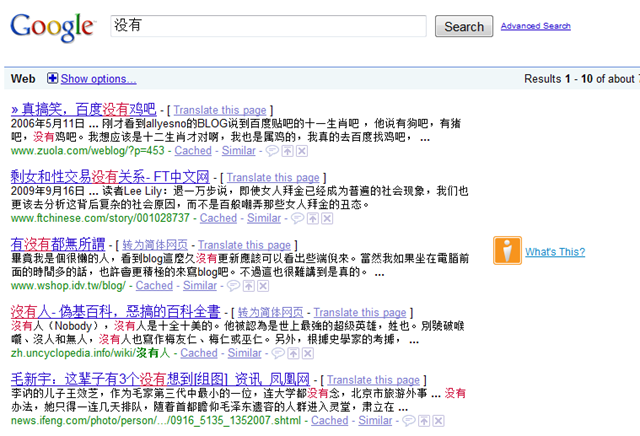
最后是全球老大,谷歌的。我啥都不说了。:-)
| |
|
(6个打分, 平均:4.33 / 5) |